目录
[什么是 fork()?](#什么是 fork()?)
[fork() 的返回值](#fork() 的返回值)
[独立的实现机制:写时复制(Copy-on-Write, COW)](#独立的实现机制:写时复制(Copy-on-Write, COW))
一.什么是进程?
从用户的视角来看,进程是一个程序的运行实例;从操作系统的视角来看,进程是一个拥有资源分配能力的实体。
进程 = 内核数据结构对象(PCB) + 自己的代码和数据
在Linux中进程可以看做是PCB(task struct)和自己的代码和数据 组成的。PCB中包含该进程的所有属性,与代码以及数据共同组成进程,PCB中存在指向其他进程的指针,通过指针的指向,进程通过双向链表 的数据结构来进行链接,而进程的管理就是对链表的增删查改。并且每个进程都有独立的地址空间,以避免相互干扰。
PCB主要内容(PCB 被实现为一个名为task_struct的结构体)
- 标识符:如进程 ID (PID),用于唯一标识进程。
- 状态:包括进程当前的运行状态(运行、就绪、阻塞等)。
- 优先级:用于调度时比较不同进程的重要性。(CPU计算的优先级)
- 程序计数器:存储下一条将要执行的指令地址。
- 内存指针:指向进程的代码段、数据段以及共享内存块。
- 上下文数据:包括处理器寄存器中的数据。
- I/O 状态信息:描述进程使用的文件和 I/O 设备。
- 记账信息:记录进程使用的资源总量和时间。
所有进程的 PCB 以链表形式组织。通过 task_struct 中的 next 和 prev 指针,形成一个双向链表,对进程进行遍历和管理。
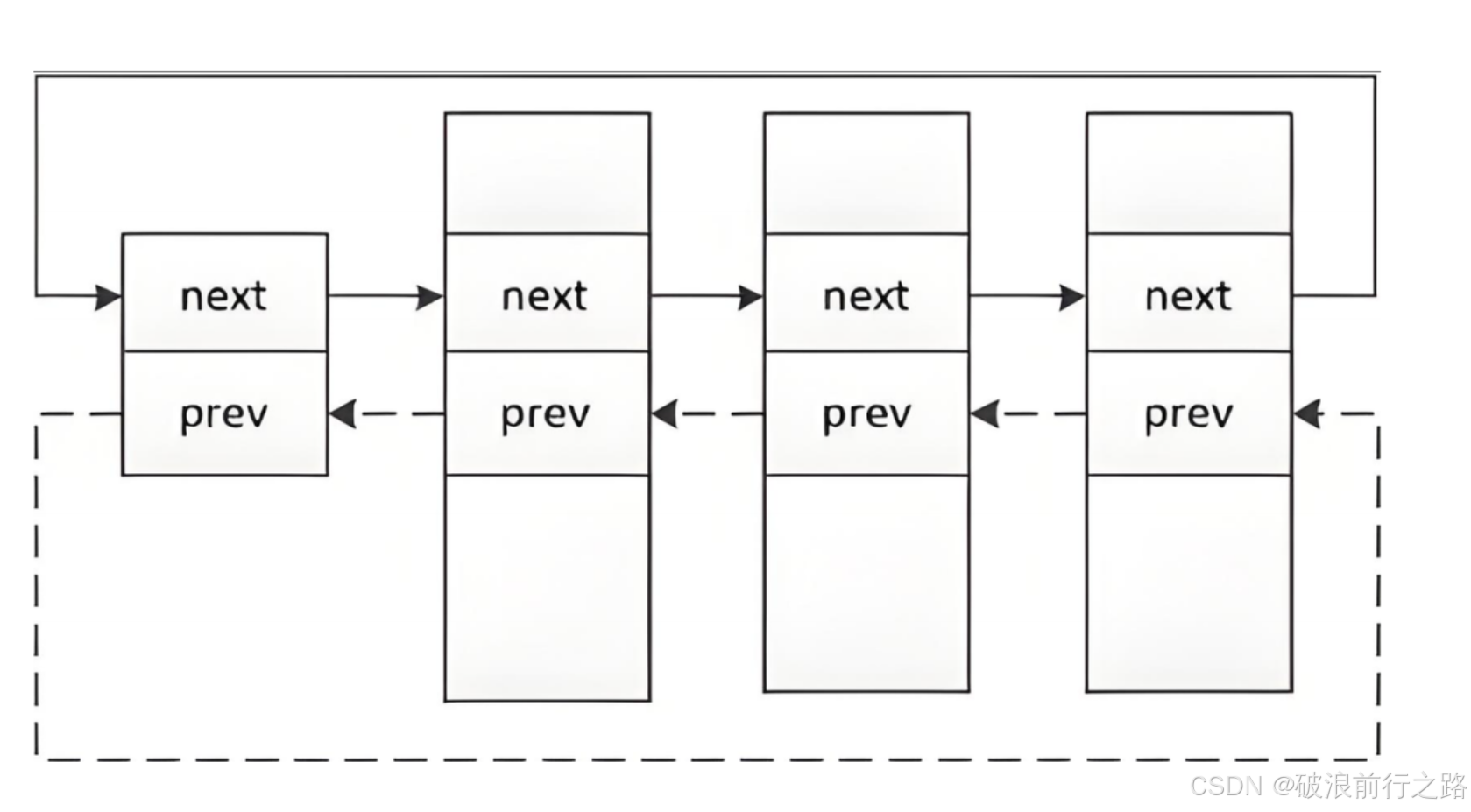
1.1查看进程
我们可以通过查看/proc/文件,来查看我们目前正在执行的全部进程
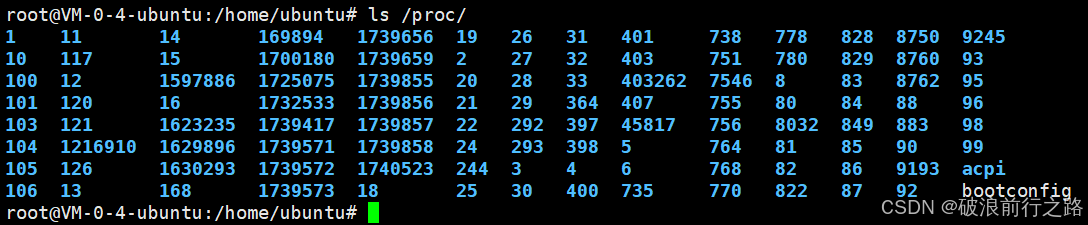 上面蓝色的数字就是进程的PID,每个进程都会有一个对应的PID,PID就是我们上面所说的进程ID,也叫做进程标识符,我们可以通过这些进程标识符来查看每个进程具体的信息,比如查看1号进程
上面蓝色的数字就是进程的PID,每个进程都会有一个对应的PID,PID就是我们上面所说的进程ID,也叫做进程标识符,我们可以通过这些进程标识符来查看每个进程具体的信息,比如查看1号进程

除了上面的这个方法外,我们还可以通过ps axj这个指令,不仅可以看到所有的进程,还可以看到它们的进程的属性信息
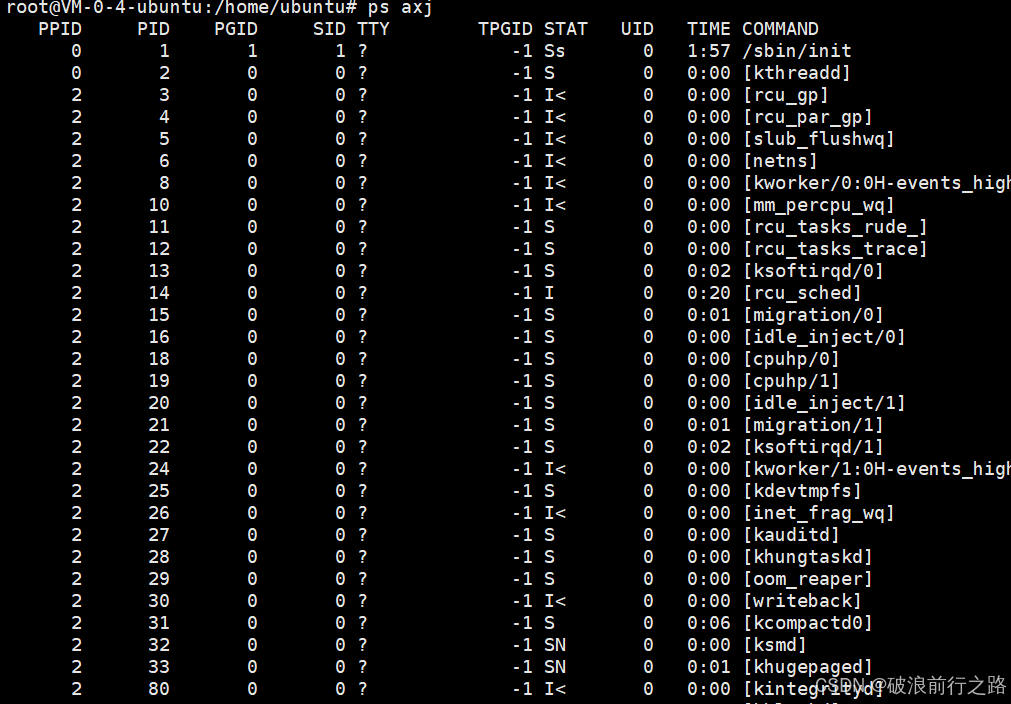
我们可以只打印出一行来看一下进程属性的内容(利用管道 | 和打印行数head)

这里要注意的点就是PPID指的是父进程标识符,PID知道是当前进程标识符、
我们可以查看下我们自己创建的这个进程的相关信息(注意只有当我们的程序在跑着的时候它才叫进程,所以我们可以将我们的程序写成一个死循环,然后让它执行起来)
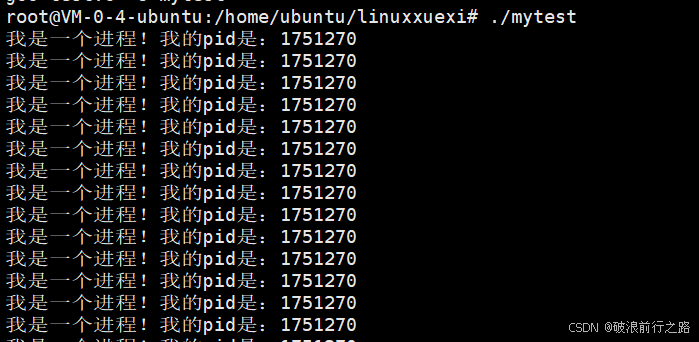
ps axj | head -1 && ps axj | grep mytest
1.2进程的cwd与exe

cwd是一个符号链接,指向进程的当前工作目录。当前工作目录是指进程在执行过程中,其相对路径的基准目录。就好比你在终端中切换到某个目录,然后运行一个程序,这个被切换到的目录就是程序的当前工作目录。
例如,假设你在/home/user/projects目录下启动了一个名为my_app的程序,那么/proc/[PID]/cwd就会指向/home/user/projects目录。
exe是一个符号链接,指向启动该进程的可执行文件的路径。这个可执行文件是进程运行的主体,包含了程序的机器代码和资源。
例如,如果你使用命令/usr/bin/my_app启动了一个程序,那么/proc/[PID]/exe就会指向/usr/bin/my_app。
二.认识fork-系统调用创建进程
- 回值为
pid_t类型- 包含在头文件
<unistd.h>

可以通过以下代码获取进程的 PID 和其父进程的 PPID:
cpp
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main() {
printf("pid: %d\n", getpid());
printf("ppid: %d\n", getppid());
return 0;
}fork() 是 Linux 中用于创建新进程的函数,我们先来看下面的一个小程序:
cpp
1 #include<stdio.h>
2 #include<unistd.h>
3 #include<sys/types.h>
4 int main()
5 {
6
7 | printf("我是父进程!!,我的pid:%d\n",getpid());
8 | fork();
9 | printf("我是子进程!!,我的pid:%d\n",getpid());
10 return 0;
11 }
可以看出,在fork();执行后出现了两个进程,其中一个进程的pid是fork前的进程的pid,一个是新进程的pid。
cpp
1 #include<stdio.h>
2 #include<unistd.h>
3 #include<sys/types.h>
4 int main()
5 {
6 pid_t id = fork(); // 父子进程的独立过程是在调用 fork() 函数时完成,之后父子进程独立
7
8 if(id < 0)
9 {
10 | perror("fork");
11 | return 1;
12 }|
13 else if(id == 0)
14 {
15 | // child
16 |
17 |
18 |
19 | printf("我是一个子进程!我的pid:%d,我的父进程id:%d\n",getpid(), getppid());
20 |
21 }
22 else
23 {
24 | // father
25 |
26 |
27 |
28 | printf("我是父进程!我的pid:%d,我的父进程id:%d\n",getpid(), getppid());
29 |
30 }
31
32 printf("返回结束\n");
33
34 return 0;
35 }
~ 子进程和父进程的执行流从 fork() 的返回值处分叉:
父进程 继续运行时,fork() 返回子进程的 PID。子进程 继续运行时,fork() 返回 0。

什么是 fork()?
fork()是用于创建进程的系统调用。
它会从当前运行的进程(称为父进程)中复制出一个几乎完全相同的新进程(称为子进程)。
父子进程几乎完全独立,但共享相同的代码段。
父子进程拥有不同的内存空间,彼此之间不影响。
fork() 的返回值
- 在父进程中 ,
fork()返回子进程的 PID(进程 ID),这是一个正整数(> 0)。- 在子进程中 ,
fork()返回0。- 创建子进程失败返回-1。
独立的实现机制:写时复制(Copy-on-Write, COW)
现代操作系统使用了一种优化机制,叫做 写时复制(COW),以减少不必要的资源浪费:
- 在
**fork()**刚返回时,父子进程共享相同的物理内存页(只读),因此复制过程很快。 - 当父进程或子进程试图修改内存时 :
- 操作系统会为需要修改的部分分配新的物理内存。
- 修改后的内存空间对父子进程来说是独立的。
因此,只有在需要时,内存的独立性才真正实现,也就是需要对对内存中数据进行修改的时候,但逻辑上,父子进程从 fork() 返回后就已经被视为完全独立了。