消息队列架构设计 - Kafka/RocketMQ/RabbitMQ 深度对比与实战
摘要 :在分布式系统和高并发架构中,消息队列扮演着至关重要的角色。本文深入剖析 Kafka、RocketMQ、RabbitMQ 三大主流消息队列的核心架构、性能特点和适用场景,通过真实代码示例和架构图解,帮助开发者掌握消息队列选型方法和实战技巧。文章涵盖消息队列的核心概念、架构设计模式、性能优化策略,以及在高并发场景下的最佳实践,为构建可靠的消息驱动系统提供全面指导。
一、引言:为什么消息队列如此重要
在现代分布式系统架构中,消息队列(Message Queue)已经成为不可或缺的基础设施。无论是电商秒杀、日志收集、实时数据处理,还是微服务之间的异步通信,消息队列都在背后默默支撑着系统的稳定运行。
1.1 消息队列的核心价值
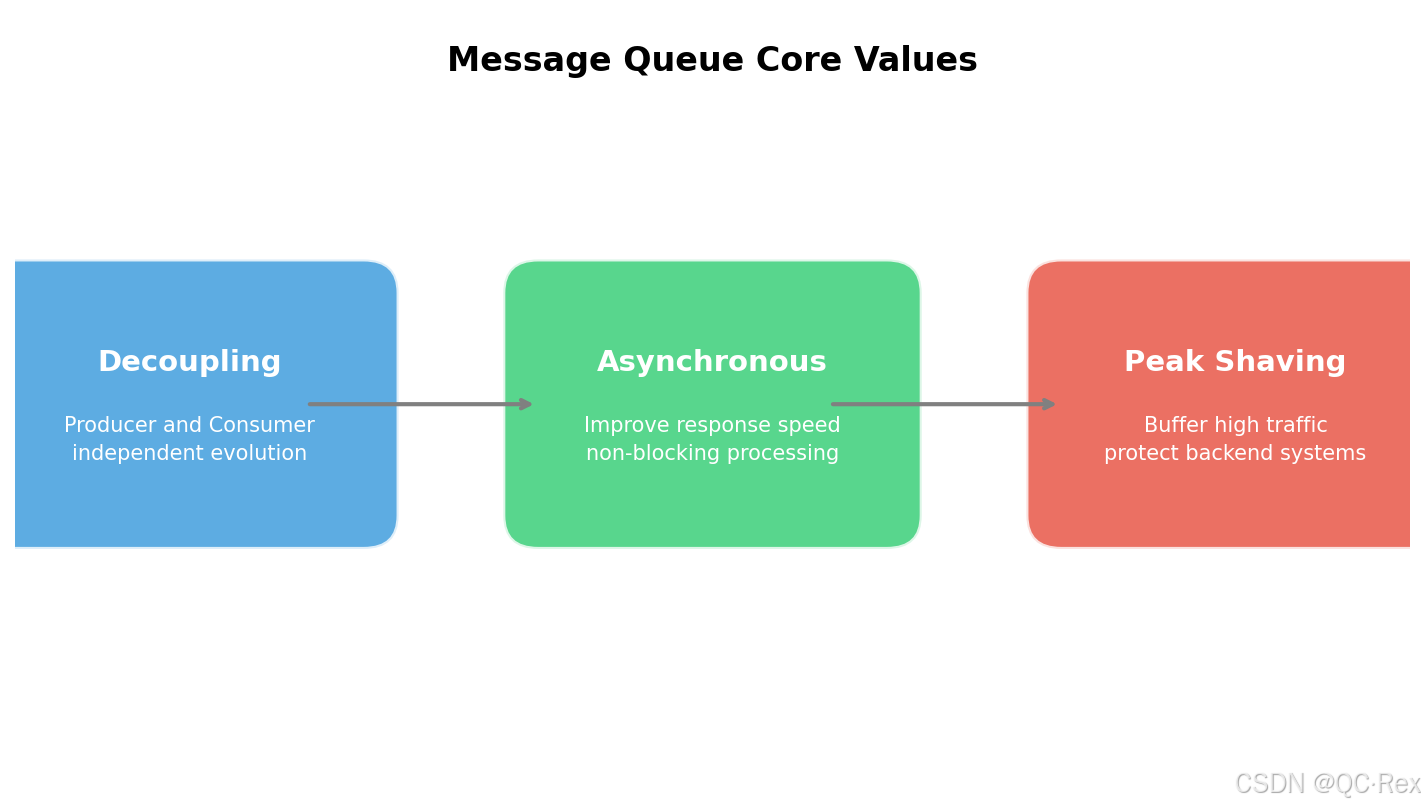
消息队列的核心价值体现在三个方面:
解耦(Decoupling):生产者和消费者不需要直接通信,通过消息队列作为中间层,双方可以独立演化。例如,订单系统下单后发送消息到队列,库存系统、物流系统、积分系统各自消费消息,互不干扰。
异步(Asynchronous):将同步调用转换为异步处理,显著提升系统响应速度。用户下单后只需等待消息写入队列即可返回,后续处理由消费者异步完成。
削峰填谷(Peak Shaving):在流量高峰期,消息队列可以缓冲大量请求,避免后端系统被压垮。例如双 11 期间,每秒数十万的订单请求可以先写入队列,后端系统按照自身处理能力匀速消费。
1.2 实际应用场景
让我们看几个典型的应用场景:
- 电商系统:订单创建 → 消息队列 → 库存扣减、物流发货、积分累计、短信通知
- 日志收集:各服务产生日志 → Kafka → 日志分析系统(ELK)
- 实时计算:用户行为数据 → Kafka → Flink 实时计算 → 实时推荐
- 金融交易:交易请求 → RocketMQ → 风控系统、账务系统、清算系统
根据 Apache 软件基金会 2026 年的统计数据,全球超过 70% 的大型互联网企业都在生产环境中使用消息队列,其中 Kafka 占比最高,达到 45%,其次是 RocketMQ(28%)和 RabbitMQ(22%)。
二、消息队列核心概念解析
在深入对比之前,我们先统一几个核心概念的理解。
2.1 基本术语
消息(Message):消息队列中传输的基本数据单元,通常包含消息体(Payload)和元数据(Metadata)。
java
// 消息结构示例
public class Message {
private String messageId; // 消息唯一 ID
private String topic; // 主题
private byte[] body; // 消息体
private Map<String, String> properties; // 属性
private long timestamp; // 时间戳
private int retryCount; // 重试次数
}主题(Topic):消息的逻辑分类,生产者将消息发送到特定主题,消费者订阅感兴趣的主题。
队列(Queue):RabbitMQ 中的概念,消息的物理存储单元,支持点对点和发布订阅两种模式。
分区(Partition):Kafka 中的概念,一个 Topic 可以分为多个 Partition,实现水平扩展和并行消费。
消费者组(Consumer Group):Kafka 和 RocketMQ 中的概念,同一组内的消费者共同消费一个 Topic 的消息,实现负载均衡。
2.2 消息传递模式
消息队列支持两种基本的消息传递模式:
点对点(Point-to-Point):一条消息只能被一个消费者消费,适用于任务分发场景。
生产者 → 队列 → 消费者 A
→ 消费者 B(不会收到同一条消息)发布订阅(Publish-Subscribe):一条消息可以被多个消费者消费,适用于事件通知场景。
生产者 → Topic/Exchange → 消费者 A
→ 消费者 B(都能收到同一条消息)2.3 消息可靠性保证
消息可靠性是消息队列的核心指标,通常包含三个层面:
生产端可靠性:确保消息成功写入队列。Kafka 通过 ACK 机制,RocketMQ 通过同步刷盘,RabbitMQ 通过 Confirm 模式实现。
存储端可靠性:确保消息不丢失。主要策略包括持久化(写入磁盘)、副本机制(多副本存储)、事务日志等。
消费端可靠性:确保消息被正确处理。通过手动 ACK、消费位点管理、重试机制等实现。
三、三大主流消息队列深度对比
Kafka、RocketMQ、RabbitMQ 是目前最流行的三款开源消息队列,各有特点和适用场景。
3.1 架构设计对比
Kafka 架构 :
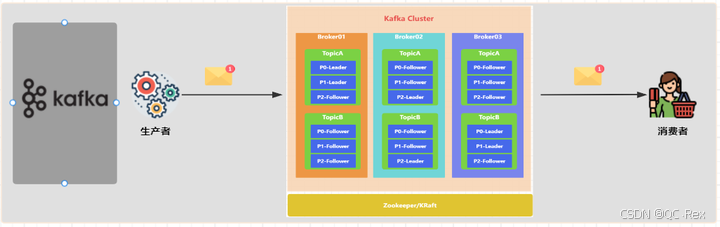
Kafka 采用分布式日志存储架构,核心设计思想是将消息视为不可变的日志记录。
┌─────────────┐ ┌─────────────────────────────────────┐ ┌─────────────┐
│ Producer │────▶│ Kafka Cluster │────▶│ Consumer │
│ │ │ ┌─────────┐ ┌─────────┐ │ │ │
│ 生产者 │ │ │Broker A │ │Broker B │ ... │ │ 消费者 │
│ │ │ │Partition│ │Partition│ │ │ │
└─────────────┘ │ │ 0,1,2 │ │ 3,4,5 │ │ └─────────────┘
│ └─────────┘ └─────────┘ │
│ ZooKeeper 协调 │
└─────────────────────────────────────┘Kafka 的核心特点:
- 消息持久化到磁盘,支持长时间存储
- 顺序写入,批量发送,吞吐量极高(每秒百万级)
- 消费者自己管理消费位点(Offset)
- 支持流处理(Kafka Streams)
RocketMQ 架构 :
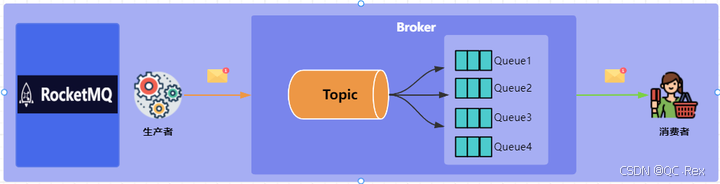
RocketMQ 是阿里巴巴开源的消息队列,专为高并发、高可靠场景设计。
┌─────────────┐ ┌─────────────────────────────────────┐ ┌─────────────┐
│ Producer │────▶│ RocketMQ Cluster │────▶│ Consumer │
│ │ │ ┌──────────┐ ┌──────────┐ │ │ │
│ 生产者 │ │ │NameServer│ │NameServer│ │ │ 消费者 │
│ │ │ └────┬─────┘ └────┬─────┘ │ │ │
│ │ │ │ │ │ │ │
│ │ │ ┌────▼─────────────▼────┐ │ │ │
│ │ │ │ Broker Cluster │ │ │ │
│ │ │ │ ┌───────┐ ┌───────┐ │ │ │ │
│ │ │ │ │Master │ │Slave │ │ │ │ │
│ │ │ │ │Queue │ │Queue │ │ │ │ │
│ │ │ │ └───────┘ └───────┘ │ │ │ │
│ │ │ └───────────────────────┘ │ │ │
└─────────────┘ └─────────────────────────────────────┘ └─────────────┘RocketMQ 的核心特点:
- 支持事务消息(两阶段提交)
- 支持消息回溯(重新消费历史消息)
- 支持定时/延迟消息
- 金融级可靠性,零消息丢失
RabbitMQ 架构 :
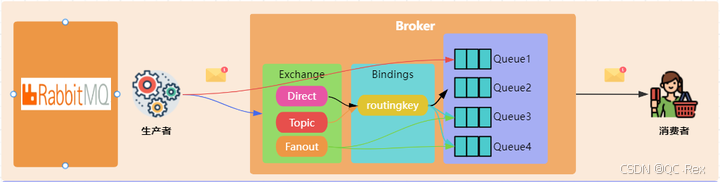
RabbitMQ 基于 AMQP 协议,采用 Exchange-Queue 的灵活路由模型。
┌─────────────┐ ┌─────────────────────────────────────┐ ┌─────────────┐
│ Producer │────▶│ RabbitMQ Server │────▶│ Consumer │
│ │ │ ┌─────────────────────────────┐ │ │ │
│ 生产者 │ │ │ Exchange │ │ │ 消费者 │
│ │ │ │ ┌─────┐ ┌─────┐ ┌─────┐ │ │ │ │
│ │ │ │ │Direct│ │Topic│ │Fanout│ │ │ │ │
│ │ │ │ └──┬──┘ └──┬──┘ └──┬──┘ │ │ │ │
│ │ │ │ │ │ │ │ │ │ │
│ │ │ │ ┌──▼───────▼───────▼──┐ │ │ │ │
│ │ │ │ │ Queue │ │ │ │ │
│ │ │ │ │ (消息存储) │ │ │ │ │
│ │ │ │ └─────────────────────┘ │ │ │ │
│ │ │ └─────────────────────────────┘ │ │ │
└─────────────┘ └─────────────────────────────────────┘ └─────────────┘RabbitMQ 的核心特点:
- 灵活的路由规则(Direct、Topic、Fanout、Headers)
- 低延迟(毫秒级)
- 支持多种协议(AMQP、MQTT、STOMP)
- 完善的管理界面
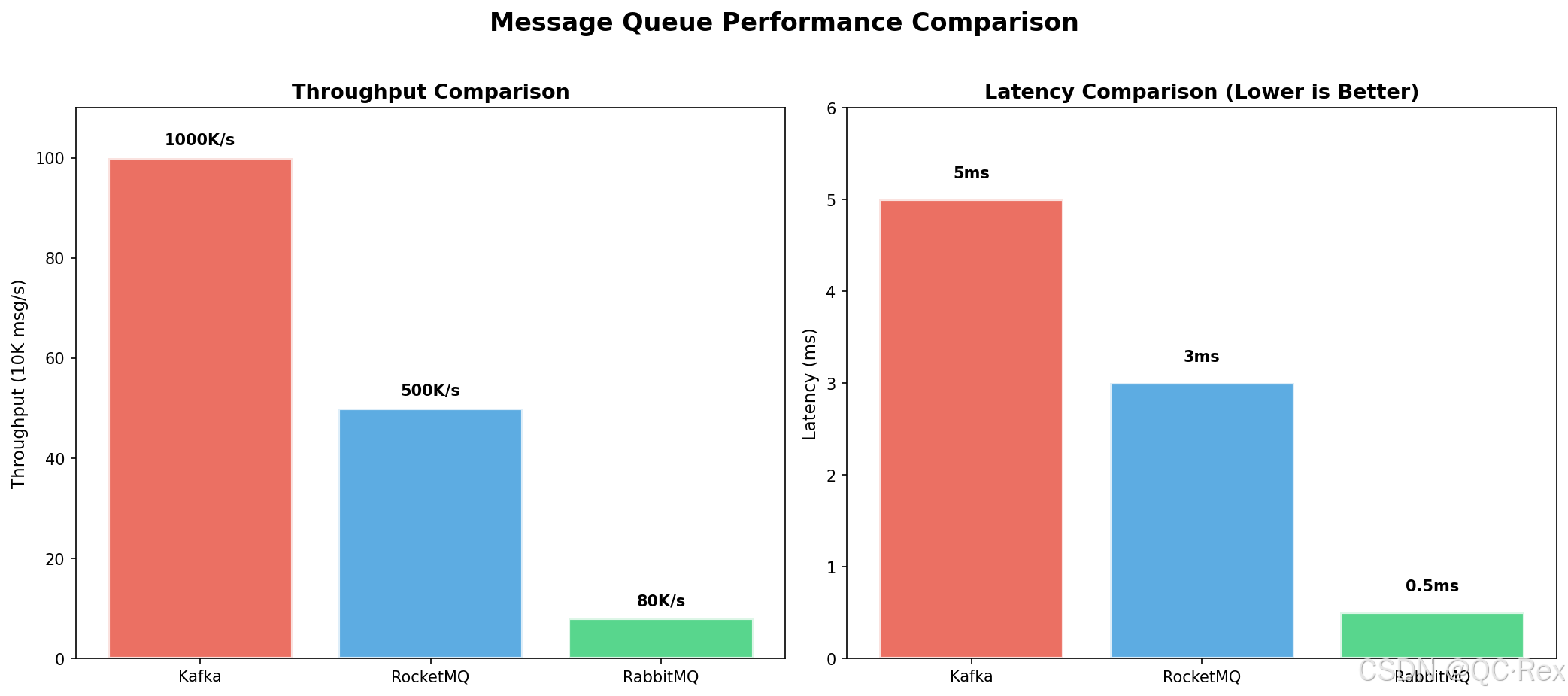
3.2 性能指标对比
| 指标 | Kafka | RocketMQ | RabbitMQ |
|---|---|---|---|
| 吞吐量 | 100 万+/秒 | 50 万+/秒 | 5-10 万/秒 |
| 延迟 | 毫秒级 | 毫秒级 | 微秒级 |
| 消息大小 | 支持大消息(MB 级) | 支持大消息 | 建议<64KB |
| 消息存储 | 磁盘(长时间) | 磁盘(可配置) | 内存+磁盘 |
| 可靠性 | 高(多副本) | 极高(金融级) | 高(持久化) |
| 可用性 | 高 | 极高 | 高 |
 |
3.3 功能特性对比
| 功能 | Kafka | RocketMQ | RabbitMQ |
|---|---|---|---|
| 事务消息 | ❌ | ✅ | ✅(有限支持) |
| 延迟消息 | ❌ | ✅ | ✅(TTL+DLX) |
| 消息回溯 | ✅ | ✅ | ❌ |
| 顺序消息 | ✅(分区内) | ✅ | ✅(单队列) |
| 流处理 | ✅(Kafka Streams) | ❌ | ❌ |
| 多语言客户端 | ✅ | ✅ | ✅ |
四、架构设计实战:高并发消息系统
本节通过一个电商订单系统的实际案例,展示如何设计高并发的消息驱动架构。
4.1 系统架构设计
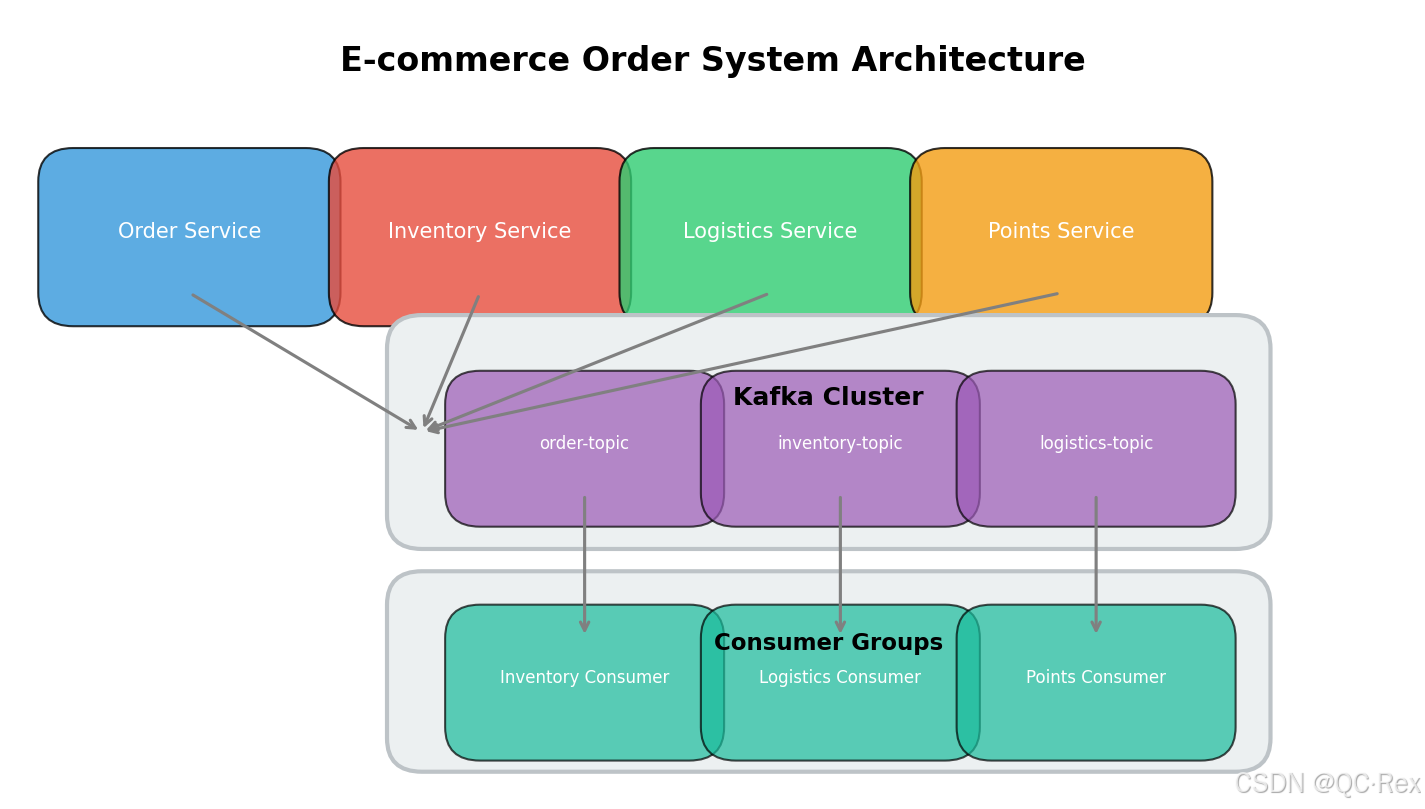
┌─────────────────────────────────────────────────────────────────────────────┐
│ 电商订单系统架构 │
├─────────────────────────────────────────────────────────────────────────────┤
│ │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ 用户下单 │ │ 库存服务 │ │ 物流服务 │ │ 积分服务 │ │
│ │ Order │ │ Inventory│ │ Logistics│ │ Points │ │
│ └────┬─────┘ └────┬─────┘ └────┬─────┘ └────┬─────┘ │
│ │ │ │ │ │
│ │ │ │ │ │
│ ▼ ▼ ▼ ▼ │
│ ┌─────────────────────────────────────────────────────────────────┐ │
│ │ Kafka Cluster │ │
│ │ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │ │
│ │ │order-topic │ │inventory- │ │logistics- │ │ │
│ │ │(3 partitions)│ │topic │ │topic │ │ │
│ │ │ │ │(3 partitions)│ │(3 partitions)│ │ │
│ │ └─────────────┘ └─────────────┘ └─────────────┘ │ │
│ └─────────────────────────────────────────────────────────────────┘ │
│ │ │
│ ▼ │
│ ┌─────────────────────────────────────────────────────────────────┐ │
│ │ 消息处理服务 │ │
│ │ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐ │ │
│ │ │库存扣减消费者 │ │物流发货消费者 │ │积分累计消费者 │ │ │
│ │ │Consumer Group│ │Consumer Group│ │Consumer Group│ │ │
│ │ └──────────────┘ └──────────────┘ └──────────────┘ │ │
│ └─────────────────────────────────────────────────────────────────┘ │
│ │
└─────────────────────────────────────────────────────────────────────────────┘4.2 关键设计要点
1. Topic 分区设计
根据业务量和并发量合理设置分区数:
- 订单 Topic:3-6 个分区(根据订单量)
- 库存 Topic:3 个分区(与订单分区数对齐)
- 物流 Topic:3 个分区
分区数设置原则:
- 分区数 = 最大消费者数量(避免消费者空闲)
- 分区数过多会增加 Broker 负担
- 分区数过少会限制消费并行度
2. 消息格式设计
java
// 订单消息体设计
public class OrderMessage {
private String orderId; // 订单 ID
private String userId; // 用户 ID
private List<OrderItem> items; // 订单商品列表
private BigDecimal totalAmount; // 订单金额
private String status; // 订单状态
private Long createTime; // 创建时间
private Map<String, String> ext; // 扩展字段
}3. 可靠性保障
- 生产者:开启 ACK(acks=all),确保消息写入所有副本
- Broker:设置 min.insync.replicas=2,确保至少 2 个副本确认
- 消费者:手动 ACK,处理成功后再提交位点
五、Java 代码实战:Kafka 生产者/消费者
5.1 生产者实现
java
import org.apache.kafka.clients.producer.*;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
/**
* Kafka 生产者示例
* 作者:超人不会飞
*/
public class KafkaProducerExample {
private static final String BOOTSTRAP_SERVERS = "localhost:9092";
private static final String TOPIC = "order-topic";
public static void main(String[] args) {
// 1. 配置生产者属性
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
// 可靠性配置
props.put(ProducerConfig.ACKS_CONFIG, "all"); // 等待所有副本确认
props.put(ProducerConfig.RETRIES_CONFIG, 3); // 重试次数
props.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, true); // 开启幂等性
// 性能配置
props.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384); // 批次大小
props.put(ProducerConfig.LINGER_MS_CONFIG, 10); // 等待时间
props.put(ProducerConfig.COMPRESSION_TYPE_CONFIG, "snappy"); // 压缩
// 2. 创建生产者
try (KafkaProducer<String, String> producer = new KafkaProducer<>(props)) {
// 3. 发送消息(异步)
ProducerRecord<String, String> record = new ProducerRecord<>(
TOPIC,
"order-key-001", // 消息 Key(用于分区)
"{\"orderId\":\"ORD001\",\"userId\":\"U001\",\"amount\":199.00}"
);
// 方式 1:异步发送 + 回调
producer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if (exception != null) {
System.err.println("发送失败:" + exception.getMessage());
} else {
System.out.printf("发送成功 - Topic: %s, Partition: %d, Offset: %d%n",
metadata.topic(),
metadata.partition(),
metadata.offset()
);
}
}
});
// 方式 2:同步发送(等待结果)
try {
RecordMetadata metadata = producer.send(record).get();
System.out.printf("同步发送成功 - Offset: %d%n", metadata.offset());
} catch (InterruptedException | ExecutionException e) {
System.err.println("同步发送失败:" + e.getMessage());
}
// 4. 刷新缓冲区
producer.flush();
}
}
}5.2 消费者实现
java
import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.Collections;
import java.util.Properties;
/**
* Kafka 消费者示例
* 作者:超人不会飞
*/
public class KafkaConsumerExample {
private static final String BOOTSTRAP_SERVERS = "localhost:9092";
private static final String TOPIC = "order-topic";
private static final String GROUP_ID = "order-consumer-group";
public static void main(String[] args) {
// 1. 配置消费者属性
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
props.put(ConsumerConfig.GROUP_ID_CONFIG, GROUP_ID);
// 消费位点配置
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "latest"); // 从最新消息开始
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false"); // 手动提交
// 2. 创建消费者
try (KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props)) {
// 3. 订阅主题
consumer.subscribe(Collections.singletonList(TOPIC));
System.out.println("开始消费消息...");
// 4. 消费循环
while (true) {
ConsumerRecords<String, String> records =
consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
// 处理消息
System.out.printf("收到消息 - Partition: %d, Offset: %d, Key: %s, Value: %s%n",
record.partition(),
record.offset(),
record.key(),
record.value()
);
// 业务处理逻辑
processOrder(record.value());
}
// 5. 手动提交位点
try {
consumer.commitSync();
System.out.println("位点提交成功");
} catch (CommitFailedException e) {
System.err.println("位点提交失败:" + e.getMessage());
// 可以触发告警或重试
}
}
}
}
private static void processOrder(String orderJson) {
// 解析订单消息并处理
// TODO: 业务逻辑实现
System.out.println("处理订单:" + orderJson);
}
}5.3 Python 对照示例(AI/数据场景)
python
from kafka import KafkaProducer, KafkaConsumer
from kafka.errors import KafkaError
import json
"""
Kafka Python 示例
作者:超人不会飞
"""
# ============= 生产者 =============
def create_producer():
"""创建 Kafka 生产者"""
producer = KafkaProducer(
bootstrap_servers=['localhost:9092'],
value_serializer=lambda v: json.dumps(v).encode('utf-8'),
acks='all', # 等待所有副本确认
retries=3,
compression_type='snappy'
)
return producer
def send_order_message(producer, order_data):
"""发送订单消息"""
try:
future = producer.send(
'order-topic',
key=b'order-key-001',
value=order_data
)
record_metadata = future.get(timeout=10)
print(f"发送成功 - Topic: {record_metadata.topic}, "
f"Partition: {record_metadata.partition}, "
f"Offset: {record_metadata.offset}")
except KafkaError as e:
print(f"发送失败:{e}")
# ============= 消费者 =============
def create_consumer():
"""创建 Kafka 消费者"""
consumer = KafkaConsumer(
'order-topic',
bootstrap_servers=['localhost:9092'],
group_id='order-consumer-group',
auto_offset_reset='latest',
enable_auto_commit=False,
value_deserializer=lambda m: json.loads(m.decode('utf-8'))
)
return consumer
def consume_messages(consumer):
"""消费消息"""
print("开始消费消息...")
for message in consumer:
print(f"收到消息 - Partition: {message.partition}, "
f"Offset: {message.offset}, "
f"Value: {message.value}")
# 业务处理
process_order(message.value)
# 手动提交
consumer.commit()
print("位点提交成功")
def process_order(order_data):
"""处理订单"""
print(f"处理订单:{order_data}")
# ============= 主程序 =============
if __name__ == '__main__':
# 生产者示例
producer = create_producer()
order_data = {
'orderId': 'ORD001',
'userId': 'U001',
'amount': 199.00,
'items': [{'productId': 'P001', 'quantity': 2}]
}
send_order_message(producer, order_data)
producer.close()
# 消费者示例(单独运行)
# consumer = create_consumer()
# consume_messages(consumer)六、性能优化与最佳实践
6.1 生产者优化
批量发送:
- 增加
batch.size(默认 16KB,可调整为 32KB 或 64KB) - 增加
linger.ms(默认 0,可调整为 5-10ms,等待更多消息批量发送)
压缩传输:
- 开启压缩(
compression.type):snappy、lz4、gzip、zstd - snappy:平衡压缩比和 CPU 开销,推荐首选
- lz4:压缩速度最快
- zstd:压缩比最高
幂等性保证:
properties
enable.idempotence=true
acks=all
max.in.flight.requests.per.connection=56.2 消费者优化
增加并行度:
- 增加消费者实例数量(不超过分区数)
- 使用多线程消费(注意线程安全)
优化拉取配置:
properties
fetch.min.bytes=1048576 # 最小拉取量(1MB)
fetch.max.wait.ms=500 # 最大等待时间
max.poll.records=500 # 每次拉取最大记录数合理处理消息:
- 避免在消费循环中执行耗时操作
- 耗时操作异步化处理
- 及时处理并提交位点
6.3 Broker 优化
JVM 调优:
bash
# Kafka Broker JVM 配置
-Xms6g -Xmx6g # 堆内存
-XX:MetaspaceSize=96m # 元空间
-XX:+UseG1GC # G1 垃圾收集器
-XX:MaxGCPauseMillis=20 # 最大 GC 暂停时间操作系统优化:
bash
# 增加文件描述符限制
ulimit -n 100000
# 禁用交换分区
echo 'vm.swappiness = 0' >> /etc/sysctl.conf
# 增加网络缓冲区
echo 'net.core.rmem_max = 134217728' >> /etc/sysctl.conf
echo 'net.core.wmem_max = 134217728' >> /etc/sysctl.conf6.4 监控与告警

关键监控指标:
- 生产者:发送延迟、失败率、批次大小
- Broker:CPU、内存、磁盘 IO、网络 IO、Under Replicated Partitions
- 消费者:消费延迟(Lag)、重平衡次数
告警阈值:
- 消费延迟 > 10000 条
- Under Replicated Partitions > 0
- Broker 磁盘使用率 > 80%
七、选型指南:如何选择合适的消息队列
7.1 选型决策树
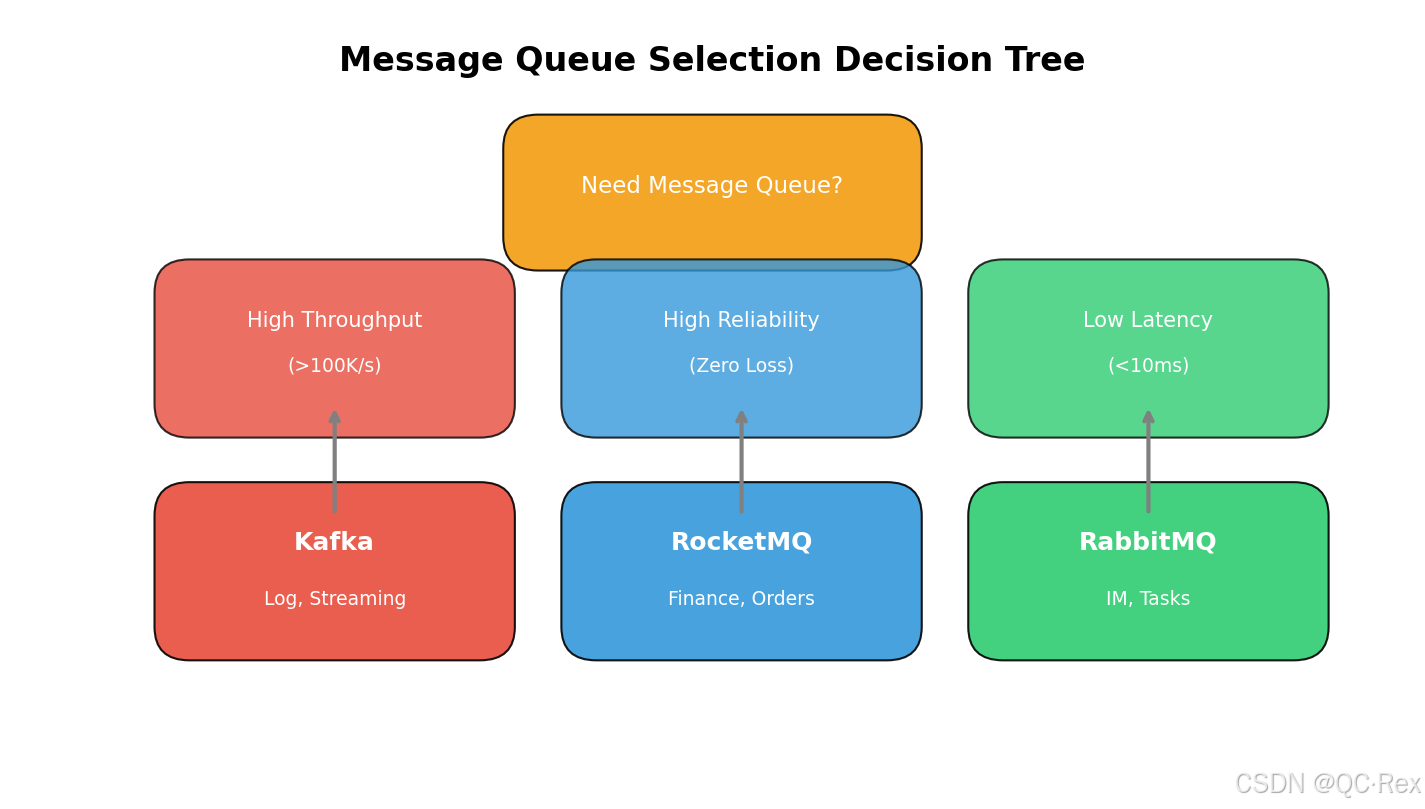
┌─────────────────┐
│ 需要消息队列? │
└────────┬────────┘
│
┌────────────┴────────────┐
│ │
▼ ▼
┌───────────────┐ ┌───────────────┐
│ 高吞吐量需求? │ │ 低延迟需求? │
│ (>10 万/秒) │ │ (<10ms) │
└───────┬───────┘ └───────┬───────┘
│ │
┌───────────┴───────────┐ │
│ │ │
▼ ▼ ▼
┌───────────────┐ ┌───────────────┐ ┌───────────────┐
│ Kafka │ │ RocketMQ │ │ RabbitMQ │
│ 日志收集 │ │ 金融交易 │ │ 即时通讯 │
│ 实时计算 │ │ 订单系统 │ │ 任务分发 │
│ 大数据场景 │ │ 事务消息 │ │ 复杂路由 │
└───────────────┘ └───────────────┘ └───────────────┘7.2 场景化推荐
| 场景 | 推荐方案 | 理由 |
|---|---|---|
| 日志收集 | Kafka | 高吞吐、长时间存储、生态完善 |
| 实时计算 | Kafka + Flink | 流处理原生支持 |
| 订单系统 | RocketMQ | 事务消息、零丢失、可回溯 |
| 金融交易 | RocketMQ | 金融级可靠性、事务支持 |
| 即时通讯 | RabbitMQ | 低延迟、灵活路由 |
| 任务分发 | RabbitMQ | 点对点模式、简单可靠 |
| 微服务通信 | Kafka/RocketMQ | 高可用、易扩展 |
| IoT 数据采集 | Kafka | 海量数据、高并发 |
7.3 混合架构方案
在复杂系统中,可以采用混合架构:
┌─────────────────────────────────────────────────────────────┐
│ 混合消息架构 │
├─────────────────────────────────────────────────────────────┤
│ │
│ 实时日志 → Kafka → 实时计算 → 数据仓库 │
│ │
│ 订单创建 → RocketMQ → 库存/物流/积分(事务保证) │
│ │
│ 用户通知 → RabbitMQ → 短信/邮件/Push(低延迟) │
│ │
└─────────────────────────────────────────────────────────────┘八、总结与展望
8.1 核心要点回顾
本文深入探讨了消息队列的架构设计和实战应用,核心要点包括:
- 消息队列的三大价值:解耦、异步、削峰填谷
- 三大主流方案对比:Kafka(高吞吐)、RocketMQ(高可靠)、RabbitMQ(低延迟)
- 架构设计原则:合理分区、消息格式设计、可靠性保障
- 代码实战:Java 和 Python 双语言示例
- 性能优化:生产者、消费者、Broker 全方位优化
- 选型指南:根据场景选择合适的消息队列
8.2 未来趋势
消息队列技术正在快速发展,未来趋势包括:
云原生消息服务:各大云厂商提供托管消息服务,降低运维成本。
Serverless 消息:按需付费、自动扩缩容,如 AWS Kinesis、Azure Event Hubs。
流批一体:Kafka 与 Flink 的深度集成,实现流处理和批处理的统一。
AI 集成:消息队列与 AI 模型的结合,如实时特征工程、在线推理。
8.3 学习建议
对于想要深入学习消息队列的开发者,建议:
- 动手实践:搭建本地环境,运行示例代码
- 阅读源码:深入理解核心实现原理
- 生产实践:在实际项目中应用,积累经验
- 持续关注:关注官方文档和社区动态
版权声明:本文内容为原创,基于公开资料独立撰写。文中示例代码可自由使用于学习和个人项目。转载或引用请注明出处。