第 18.5 篇:特征工程的数学视角------为什么特征一变,模型能力就变了
在第十八篇里,我们主要从实战角度讲了特征工程:
- 原始数据不一定是好特征
- 时间可以拆分
- 数值可以变换
- 特征可以组合
- 好特征往往比换模型更重要
如果只从项目经验看,这些都已经很有说服力了。
但如果你想再往深一点问,就会碰到一个非常关键的问题:
为什么只是把特征换一种表达,模型效果就可能明显变化?
模型不是没变吗?
这个问题其实非常重要。
因为它会把你对特征工程的理解,从"经验技巧"推进到"模型表达能力"。
这一篇我们就从数学角度把这件事讲清楚。
1. 先说结论:特征工程本质上是在改造模型看到的数据空间
这一篇最核心的一句话:
特征工程不是在改模型本身,而是在改模型看到问题的方式。
模型做判断,靠的不是原始世界本身,而是你喂给它的特征空间。
换句话说:
- 现实世界长什么样,不重要
- 模型"眼里"看到的世界长什么样,更重要
而特征工程,做的就是这件事:
改变输入空间的表达,让原本难学的关系变得更容易学。
2. 为什么同一个模型,换个特征就像换了脑子
很多初学者都会有个错觉:
模型能力是模型自己决定的,和特征没那么大关系。
其实不是。
模型能学到什么,永远取决于两部分:
- 模型本身的表达能力
- 你给它什么特征
比如最简单的线性模型:
y^=w1x1+w2x2+b \hat{y} = w_1x_1 + w_2x_2 + b y^=w1x1+w2x2+b
这个模型表面上看能力很有限。
因为它只能学"线性关系"。
但问题来了:
如果你把特征从原来的 xxx,换成:
- xxx
- x2x^2x2
- x3x^3x3
那这个模型虽然形式上还是"线性组合",它实际上已经能拟合非线性的函数了:
y^=w1x+w2x2+w3x3+b \hat{y} = w_1x + w_2x^2 + w_3x^3 + b y^=w1x+w2x2+w3x3+b
你看,模型形式没变,还是线性模型。
但因为特征空间变了,它的表达能力也跟着变了。
这就是特征工程最根本的数学意义:
不是所有能力都来自模型本身,很多能力来自你怎么表示输入。
3. 什么叫"特征空间"
如果想把这件事讲得更清楚,就得引入一个很重要的词:
特征空间(feature space)
你可以先把它理解成:
模型拿来判断问题的坐标系。
比如你只有两个特征:
- 学习时长
- 作业完成率
那每个样本都可以看成平面上的一个点:
x=(x1,x2) x = (x_1, x_2) x=(x1,x2)
这就是二维特征空间。
如果你再加一个特征:
- 是否参加辅导班
那样本就进入三维特征空间:
x=(x1,x2,x3) x = (x_1, x_2, x_3) x=(x1,x2,x3)
如果再加更多特征,就进入更高维空间。
模型并不是直接理解"学生"或者"用户"本身,
它看到的,其实就是这些点在特征空间里的分布。
所以当你做特征工程时,你其实是在改:
- 点怎么摆
- 点之间距离怎么变
- 不同类别怎么分布
- 边界是不是更容易画
这也是为什么特征工程经常会直接影响模型效果。
4. 线性不可分的问题,为什么加特征后可能突然可分
这件事特别适合拿来解释特征工程的数学意义。
假设我们有一个一维问题:
- 当 x>0x > 0x>0 时,类别不一定固定
- 当 x<0x < 0x<0 时,类别也不一定固定
比如更具体一点:
- x=−2x=-2x=−2 属于正类
- x=−1x=-1x=−1 属于负类
- x=1x=1x=1 属于负类
- x=2x=2x=2 属于正类
你会发现,在原始一维空间里,这些点很难用一个简单阈值分开。
但如果你加一个新特征:
z=x2 z = x^2 z=x2
那情况就变了。
原来:
- x=−2x=-2x=−2 和 x=2x=2x=2 看起来很远
- 但它们的 x2x^2x2 都是 4
原来在原始空间里不好分的结构,在新特征空间里可能突然变得更规整。
这就是为什么"非线性问题"经过特征映射后,有时能变成"线性可分问题"。
所以特征工程不只是为了"多做几个字段",
它本质上是在做:
特征映射(feature mapping)
把原空间里的问题,搬到一个更容易表达的空间里。
5. 从数学上看,特征工程其实是在做映射
更正式一点说,特征工程常常可以写成一个映射:
ϕ(x):Rn→Rm \phi(x): \mathbb{R}^n \rightarrow \mathbb{R}^m ϕ(x):Rn→Rm
意思是:
把原始输入 xxx 从原来的 nnn 维空间,映射到一个新的 mmm 维空间。
这里:
- 原始特征维度是 nnn
- 新特征维度是 mmm
- ϕ(x)\phi(x)ϕ(x) 是新的特征表示
比如:
原来只有一个特征:
x x x
你做多项式扩展以后,变成:
ϕ(x)=(x,x2,x3) \phi(x) = (x, x^2, x^3) ϕ(x)=(x,x2,x3)
这就是从 1 维映射到了 3 维。
原来模型只能画一条直线,
现在模型虽然形式还是线性组合,但因为输入空间换了,它就能表达更复杂的关系。
6. 为什么说"线性模型也不一定真的弱"
这也是理解特征工程特别重要的一点。
很多人刚学完一圈模型以后,会觉得:
- 线性模型简单
- 树模型复杂一点
- 核方法更高级
- 神经网络最强
这个排序当然大体没问题。
但如果只这么理解,会漏掉一个非常关键的事实:
一个线性模型到底强不强,取决于你给了它什么特征。
如果你只给原始特征,它可能确实很弱。
但如果你给它:
- 多项式特征
- 交叉特征
- 对数变换后的特征
- 经过业务提炼后的比例特征
那它未必就真的弱。
这也是为什么在很多结构化数据任务里,
一个做好特征工程的逻辑回归,能打出相当不错的效果。
所以不是"线性模型天生不行",而是:
线性模型对特征表达特别敏感。
你给得好,它能学得很漂亮。
你给得差,它就会显得很无力。
7. 特征组合为什么经常特别有效
这一点在数学上也很好解释。
假设原始特征有两个:
- x1x_1x1
- x2x_2x2
而真实规律可能不是看它们单独作用,而是看它们之间的互动,比如:
y∼x1⋅x2 y \sim x_1 \cdot x_2 y∼x1⋅x2
如果你只把 x1x_1x1 和 x2x_2x2 单独喂给一个简单线性模型:
y^=w1x1+w2x2+b \hat{y} = w_1x_1 + w_2x_2 + b y^=w1x1+w2x2+b
那它很难直接表示这种乘积关系。
但如果你手工加一个交叉特征:
x3=x1x2 x_3 = x_1x_2 x3=x1x2
那模型就能写成:
y^=w1x1+w2x2+w3x1x2+b \hat{y} = w_1x_1 + w_2x_2 + w_3x_1x_2 + b y^=w1x1+w2x2+w3x1x2+b
这时它对复杂关系的表达能力就明显增强了。
所以很多特征组合之所以有效,不是因为"信息突然变多了",而是因为:
你把原本隐藏在特征关系里的模式,显式交给模型了。
8. 分箱为什么有时也会提高表达效果
前面正文里提过分箱,这里可以从更数学一点的角度再解释一下。
假设年龄这个特征原本是连续值:
x=18,19,20,...,60 x = 18, 19, 20, \dots, 60 x=18,19,20,...,60
如果真实规律不是"年龄每增加 1 岁,影响线性变化",而是:
- 18-24 岁是一类行为
- 25-34 岁是一类行为
- 35-44 岁又是一类行为
那连续值本身对某些模型来说,未必是最自然的表达。
这时候你把它分成区间,本质上是在做一种分段映射:
ϕ(x)=所属年龄段 \phi(x) = \text{所属年龄段} ϕ(x)=所属年龄段
这会让某些离散边界更明显,也让模型更容易捕捉"阶段性变化"。
当然,分箱也会损失精细信息。
所以它不是永远更好,而是:
当真实规律本来就更接近分段结构时,分箱会更贴近问题本身。
9. 标准化为什么也算特征工程
很多人把标准化只当成"预处理步骤",
但从数学角度看,它其实也是在改变特征空间。
标准化常见形式是:
x′=x−μσ x' = \frac{x-\mu}{\sigma} x′=σx−μ
它做的事情是:
- 平移特征中心
- 缩放特征尺度
这在数学上会直接影响:
- 特征空间里的距离
- 梯度下降的路径
- 某些模型对特征重要性的感知
比如 KNN、SVM、逻辑回归这些模型,本身就对尺度敏感。
所以标准化并不只是"把数变小一点",而是在改:
模型眼里,两个样本彼此相差多少。
所以从这个角度说,标准化也是一种非常基础但很重要的特征空间变换。
10. 为什么树模型对特征变换有时没那么敏感
这一点也很值得讲,因为它能帮读者建立模型差异感。
像线性模型、KNN、SVM 这些模型,对特征表达方式往往很敏感。
但决策树、随机森林、GBDT 这一类树模型,很多时候对一些简单变换没那么敏感。
为什么?
因为树模型的基本操作不是算距离,也不是算加权和,
它更像是在问:
某个特征是不是小于某个阈值?
比如:
- 年龄 < 30?
- 收入 > 10000?
- 作业完成率 <= 67.5?
所以如果你把一个特征做单调变换,比如从收入变成对数收入,
树模型很多时候依然能找到类似的分裂结构。
这也是为什么树模型在结构化数据里经常让人觉得"比较省特征工程"。
但注意,这不是说树模型完全不需要特征工程。
而是说:
它对某些数值形式的变化,没有线性模型那么敏感。
真正有价值的业务特征、组合特征、历史统计特征,对树模型依然很重要。
11. 从核方法角度看,特征工程和 SVM 其实也有共通性
前面你写过 SVM 和核函数。
这里正好可以顺手把这条线串起来。
核函数本质上就是在做一件事:
把原始输入映射到一个更高维、更容易分开的特征空间。
比如:
K(xi,xj)=ϕ(xi)⋅ϕ(xj) K(x_i, x_j) = \phi(x_i)\cdot\phi(x_j) K(xi,xj)=ϕ(xi)⋅ϕ(xj)
这里的 ϕ(x)\phi(x)ϕ(x) 就是隐式特征映射。
你会发现,这和特征工程的精神其实是一样的:
- 原始空间里不好分
- 换个特征表示以后更容易分
所以你可以说:
手工特征工程和核方法,虽然技术路线不同,但本质上都在做一件事:
改造数据的表示,让模型更容易学到规律。
这会让前面的内容突然连起来。
12. 从深度学习角度看,神经网络某种程度上是在"自动做特征工程"
传统机器学习里,很多时候需要人手工设计特征:
- 比例
- 组合
- 分箱
- 统计量
- 交叉特征
而深度学习里,一个很核心的能力就是:
自动从原始输入里学习更高层的表示。
也就是说,神经网络不只是学一个最终映射,
它中间很多层其实都在学:
- 更抽象的特征
- 更适合任务的表示
所以某种意义上你可以说:
- 传统机器学习:人手工做大量特征工程
- 深度学习:模型自动学习表示
当然,现实里深度学习也不是完全不要特征工程,
但这种"表示学习"的思想,和这一篇讲的特征映射其实是连着的。
13. 一个简单的代码例子:为什么加平方项以后线性模型能力会变
python
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import PolynomialFeatures
from sklearn.pipeline import make_pipeline
# 构造数据
np.random.seed(42)
X = np.linspace(-3, 3, 50).reshape(-1, 1)
y = X[:, 0]**2 + np.random.normal(0, 0.8, 50)
# 普通线性回归
linear_model = LinearRegression()
linear_model.fit(X, y)
# 加入二次特征后的线性回归
poly_model = make_pipeline(
PolynomialFeatures(degree=2, include_bias=False),
LinearRegression()
)
poly_model.fit(X, y)
# 画图
X_plot = np.linspace(-3, 3, 200).reshape(-1, 1)
plt.scatter(X, y, label="data")
plt.plot(X_plot, linear_model.predict(X_plot), label="linear")
plt.plot(X_plot, poly_model.predict(X_plot), label="linear + x^2")
plt.legend()
plt.title("特征变换如何改变模型表达能力")
plt.show()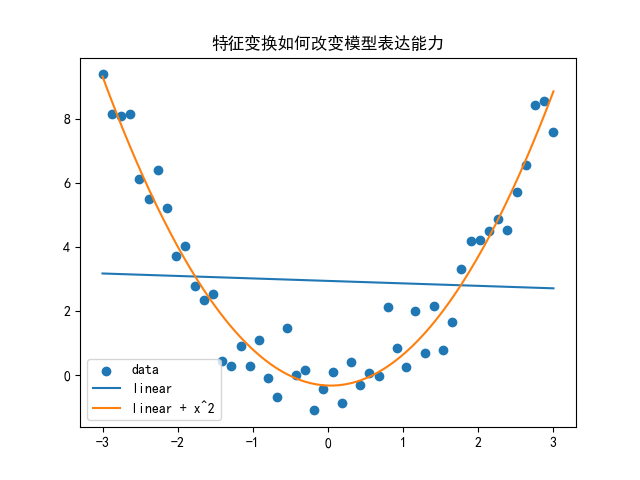
- 左边那条普通直线,不够表达二次关系
- 右边加了 x2x^2x2 特征以后,虽然模型还是线性回归,但已经能拟合弯曲趋势了
模型没有换,还是线性回归。
真正变化的是特征空间。
而特征空间一变,模型能表达的函数形状也就变了。
14. 特征工程其实是在做"归纳偏置"的设计
这个点稍微偏理论一点,但很有味道,你可以用比较轻的方式讲。
任何模型都不是在真空里学世界。
它都有自己的归纳偏置(inductive bias),也就是:
它更倾向于学到哪种类型的规律。
比如:
- 线性模型偏好线性关系
- 树模型偏好分段规则
- KNN 偏好局部相似性
- SVM 偏好间隔最大边界
而特征工程,某种意义上是在帮模型:
把问题改造成更符合它偏好的样子。
比如:
- 给线性模型加入交叉项、多项式项
- 给树模型加入更有业务意义的统计特征
- 给距离模型先做尺度统一
这样模型就更容易在自己的表达偏好内,把问题学好。
所以特征工程并不是"额外修补",
而是在主动设计模型更适合学习的表示。
15. 为什么说"好特征"本质上是在降低学习难度
如果你把机器学习想成"从数据中找规律",
那特征工程其实是在降低这个过程的难度。
比如原来模型面对的是:
- 混乱、原始、关系隐含的数据
而经过特征工程以后,模型面对的是:
- 更结构化
- 更接近任务机制
- 更容易分离
- 更容易被表达
也就是说,特征工程不是替模型做决定,
而是在帮模型把原本难学的问题变得更容易学。
从这个角度看,一个好特征最重要的标准,不是"看起来高级",而是:
它有没有让真正的规律更容易被模型捕捉。
16. 这一篇真正想补上的,是"为什么特征工程不只是经验活"
很多人提起特征工程,会觉得它有点像经验活,
好像是靠:
- 做久了
- 业务熟了
- 多试试
当然,这些都重要。
但这一篇真正想补上的,是:
特征工程背后其实有非常明确的数学意义。
它不是在随便加工字段,而是在:
- 变换输入空间
- 改变模型可表达的函数形式
- 改变样本之间的几何关系
- 提高某些模式的可分性
- 降低模型学习真正规律的难度
这样一来,你再看特征工程,就不会只觉得它是"经验技巧",而会看到:
它其实是在主动设计模型看世界的方式。
17. 这一篇收束成一句话
如果第十八篇主线是在说:
特征工程很重要,因为很多时候数据比模型更重要。
那这一篇补充篇更想说的是:
特征工程之所以重要,是因为它直接改变了模型看到的数据空间,进而改变了模型能学到什么。
这才是它真正底层的原因。