大白话讲解架构逻辑:
先用 Flink 做实时数据摄入,对刚上传的药材图像和成分报告做初步的格式校验、特征提取和脏数据过滤,把处理好的数据实时写入 ClickHouse 做在线分析;再用 Spark 做 T+1 的离线批量处理,对全量数据做更复杂的质量核查、标签计算和关联挖掘,把加工好的宽表写入 Hive 做长期存储。另外我会在 Flink 和 Spark 之间加一层 Kafka 做数据缓冲,削平流量峰值,同时保证数据不丢失。
第一站:Kafka 缓冲------样品暂存区 你在质检中心门口设了一个大型货架区,所有送来的样品先放在货架上,贴上标签,按顺序排好。 这个货架的作用: 削峰填谷:就算一天来了10吨样品,货架都能暂时存下,不会把后面的工人压垮 保证不丢:样品放在货架上,不会莫名其妙消失 灵活取用:快通道的工人随时可以从货架拿样品处理,慢通道的工人晚上也可以从同一个货架取样品复查 这就是 Kafka 缓冲层------一个可靠的消息队列,上游只管往里放,下游按自己的节奏取。
第二站:Flink 实时处理------快通道 你安排了一组快速质检员(Flink),他们守在货架旁边,样品一上架就拿走处理,绝不拖延。 每个快速质检员做三件事: 步骤 做什么 打个比方 1. 格式校验 检查样品是否合格 照片糊不糊?报告单字迹清不清楚?药材标签有没有贴错?不合格的直接扔进"废品筐" 2. 特征提取 记录关键信息 拍张照片记录药材颜色、形状;把报告单上的成分含量抄下来 3. 脏数据过滤 筛掉明显异常 比如报告写"含量120%"这种不可能的数据,直接剔除 做完这三步,快速质检员会立刻把结果写在一张快查板上,供一线人员随时查看。 这块"快查板"就是 ClickHouse------一个专门做快速查询的数据库。
第三站:ClickHouse------快查板 这块板子有几个特点: 写上去就立刻能看到:实时质检员写完,大屏马上刷新 查询飞快:你想看"最近1小时哪个药材不合格最多",一秒钟就出结果 适合做统计:汇总、排序、求平均值都非常快
第四站:Spark 离线处理------慢通道 每天晚上,另一组深度质检员(Spark)开始工作。他们不抢快,而是踏踏实实地做细致活。 他们从货架上把当天所有样品(甚至更早的)都翻出来,做三件更深入的事: 步骤 做什么 打个比方 1. 质量核查 全量复核 不光看单份报告,还要比对历史记录------这个药材供应商最近10批货质量是稳定还是下滑? 2. 标签计算 打标签 综合各项指标给药材打标签:"优质""常规""待评估",方便以后筛选 3. 关联挖掘 找规律 把药材数据和采购记录、产地信息、气候数据关联起来------比如"云南产的当归质量普遍高于其他产地" 做完这些,他们会整理成一份正式档案,存入档案室。这个流程对吗 按照这个流程具体讲一下技术实现
详细技术: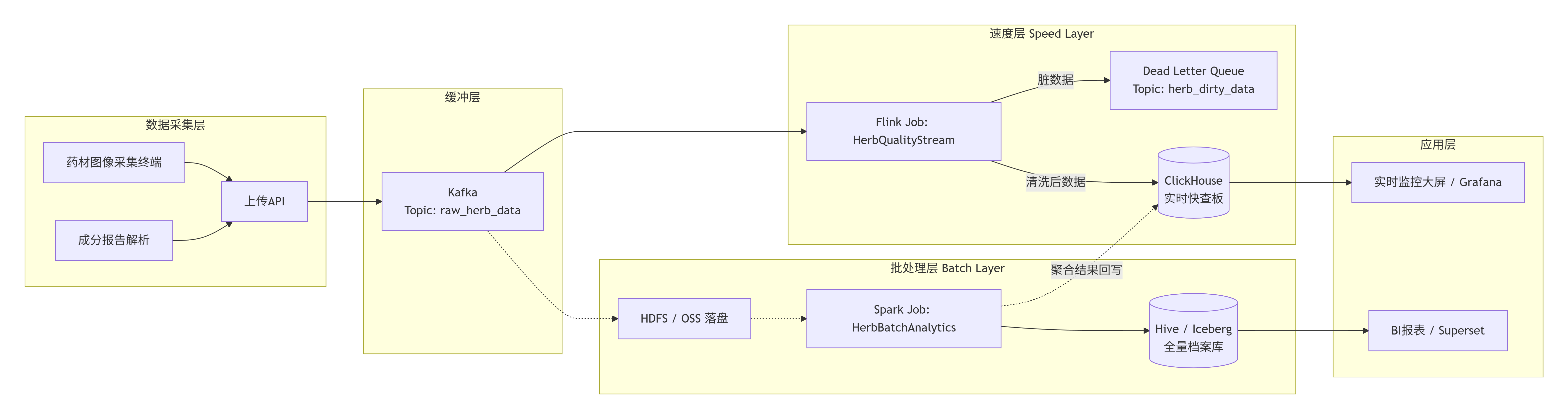
第一站:Kafka 缓冲层技术实现
核心作用:解耦采集端与计算端,应对突发的上传峰值(例如每天下午5点集中上传)。
Topic 规划
python
# 建议创建 3 个 Topic 实现数据分流
raw_herb_data: # 原始数据主通道,3个分区,保留7天
partitions: 6
retention.ms: 604800000
herb_dirty_data: # 脏数据死信队列,便于后续人工审核
partitions: 2
retention.ms: 2592000000 # 保留30天
herb_processed: # 处理后的标准化数据(可选)
partitions: 3消息体设计 (JSON Schema)
python
{
"message_id": "uuid-xxxx-xxxx",
"event_time": "2026-04-20T10:35:22.123Z",
"source": "image_scanner_03",
"data_type": "herb_inspection",
"payload": {
"batch_id": "BATCH20260420",
"herb_name": "当归",
"supplier_id": "SUP_0882",
"images": [
{
"url": "https://oss.xxx.com/herb/img001.jpg",
"type": "appearance"
}
],
"report": {
"moisture": 12.5,
"ash": 4.2,
"active_ingredient": 0.85
}
}
}第二站:Flink 实时处理层技术实现
这是整个架构的速度层,需要对每条数据做毫秒级响应。
Flink Job 核心代码结构
python
public class HerbQualityStreamJob {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 1. 配置 Checkpoint(保证 Exactly-Once 语义)
env.enableCheckpointing(60000); // 每分钟做一次快照
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
// 2. 消费 Kafka
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers("kafka:9092")
.setTopics("raw_herb_data")
.setGroupId("flink-herb-quality-group")
.setStartingOffsets(OffsetsInitializer.latest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
DataStream<String> rawStream = env.fromSource(source,
WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofSeconds(10)),
"Kafka Source");
// 3. 数据处理管线
DataStream<HerbQualityRecord> processedStream = rawStream
.map(new JsonParserMapFunction()) // JSON 解析
.filter(new FormatValidationFilter()) // 格式校验
.map(new FeatureExtractionMapFunction()) // 特征提取
.filter(new DirtyDataFilter()) // 脏数据过滤
.assignTimestampsAndWatermarks(...); // 事件时间处理
// 4. 分流:脏数据写入死信队列
OutputTag<String> dirtyOutputTag = new OutputTag<String>("dirty-data"){};
SingleOutputStreamOperator<HerbQualityRecord> mainStream = processedStream
.process(new DirtyDataSplitFunction(dirtyOutputTag));
// 脏数据单独输出到 Kafka
mainStream.getSideOutput(dirtyOutputTag)
.sinkTo(KafkaSink.<String>builder()
.setBootstrapServers("kafka:9092")
.setRecordSerializer(...)
.build());
// 5. 写入 ClickHouse
mainStream.addSink(new ClickHouseSinkFunction());
env.execute("Herb Quality Inspection Stream");
}
}
python
-- 实时表:采用 ReplacingMergeTree 支持数据更新
CREATE TABLE herb_quality_realtime (
event_time DateTime64(3),
batch_id String,
herb_name String,
supplier_id String,
moisture Float32,
ash Float32,
active_ingredient Float32,
image_features Array(Float32), -- 存储特征向量
quality_flag Enum8('pending'=0, 'qualified'=1, 'rejected'=2),
process_time DateTime DEFAULT now()
) ENGINE = ReplacingMergeTree()
PARTITION BY toYYYYMMDD(event_time)
ORDER BY (herb_name, supplier_id, event_time);
-- 预聚合物化视图:1分钟窗口统计
CREATE MATERIALIZED VIEW herb_minute_stats
ENGINE = SummingMergeTree()
ORDER BY (window_time, herb_name)
AS SELECT
toStartOfMinute(event_time) as window_time,
herb_name,
count() as sample_count,
avg(moisture) as avg_moisture,
countIf(quality_flag = 'rejected') as rejected_count
FROM herb_quality_realtime
GROUP BY window_time, herb_name;第三站:Spark 离线处理层技术实现
这是 批处理层,负责全量数据的深度加工。
Spark Job 核心代码结构
python
object HerbBatchAnalytics {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName("HerbBatchAnalytics")
.enableHiveSupport()
.getOrCreate()
// 1. 读取前一天的全量数据
val yesterday = LocalDate.now().minusDays(1).toString
val rawDF = spark.read
.parquet(s"hdfs://datalake/raw/herb/dt=$yesterday")
// 2. 质量核查:对比历史趋势
val qualityCheckDF = rawDF
.groupBy("supplier_id", "herb_name")
.agg(
avg("moisture").as("avg_moisture"),
stddev("moisture").as("std_moisture"),
count("*").as("batch_count")
)
.withColumn("quality_trend",
when(col("std_moisture") < 0.5, "stable").otherwise("volatile"))
// 3. 标签计算:综合打分
val labeledDF = rawDF.join(qualityCheckDF, Seq("supplier_id", "herb_name"))
.withColumn("score",
// 评分公式:水分占比30% + 灰分占比20% + 有效成分占比50%
lit(0.3) * (col("moisture") / lit(15.0)) +
lit(0.2) * (lit(5.0) / col("ash")) +
lit(0.5) * (col("active_ingredient") / lit(0.9))
)
.withColumn("label",
when(col("score") > 0.85, "premium")
.when(col("score") > 0.70, "standard")
.otherwise("review"))
// 4. 关联挖掘:与产地/气候数据关联
val supplierDF = spark.table("dim_supplier") // 维度表
val weatherDF = spark.table("fact_weather") // 气象事实表
val enrichedDF = labeledDF
.join(supplierDF, "supplier_id")
.join(weatherDF,
labeledDF("harvest_date").between(weatherDF("date_start"), weatherDF("date_end")))
// 5. 写入 Hive 分区表(Iceberg 格式更优)
enrichedDF.write
.mode(SaveMode.Overwrite)
.partitionBy("dt")
.format("iceberg") // 或 parquet
.saveAsTable("dwd_herb_quality_daily")
spark.stop()
}
}