论文:Reinforced Embodied Planning with Verifiable Reward for Real-World Robotic Manipulation
这篇技术博客面向希望系统理解论文方法与实验的读者。即使没有读过原文,也可以通过本文把论文的研究问题、方法设计、数学原理、训练流程与实验结果整体串起来。
相关好文推荐:【具身任务规划】Reinforced Embodied Planning with Verifiable Reward for Real-World Robotic Manipulation
1. 基本信息
1.1 全文摘要
这篇论文关注的是一个非常具体但又非常难的问题:如何让机器人面对开放式自然语言指令时,先做出正确的长时程规划,再由底层控制器逐步执行,并在执行过程中持续判断当前步骤是否完成。
作者指出,现有视觉语言模型(VLM)虽然已经具备很强的感知与推理能力,但在真实机器人操控中,尤其是在长时程、多步骤、开放语义的任务中,仍然存在三大障碍:
- 缺少大规模、真实世界、顺序化、语言条件的规划数据。
- 缺少适合强化微调的、可验证且可扩展的奖励函数。
- 即使能离线生成计划,也往往缺少在线执行中的完成判断 与失败后重规划能力。
为了解决这些问题,论文提出了 REVER (Reinforced Embodied Planning with Verifiable Reward)框架,并训练出具身规划模型 RoboFarseer。其整体思路是:
- 基于真实世界的 UMI 示教数据,自动构建长时程规划数据集 LEAP;
- 设计一种面向规划输出的可验证奖励,把开放式计划生成变成可强化学习的问题;
- 使用 GRPO 对 VLM 进行强化微调,使其既能生成完整计划,也能做执行监控;
- 在真实机器人上构建"高层规划器 + 低层控制器 + 完成验证器"的闭环系统。
最终,RoboFarseer 在多个规划基准和真实世界实验中表现出强竞争力,尤其在开放式计划生成上显著优于强大的通用闭源模型。
1.2 作者
论文作者来自 Xiaomi Robotics Lab 与 浙江大学计算机科学与技术学院,作者列表为:
Zitong Bo、Yue Hu、Jinming Ma、Mingliang Zhou、Junhui Yin、Yachen Kang、Yuqi Liu、Tong Wu、Diyun Xiang、Hao Zhou。
1.3 发布时间
当前公开版本为 2025 年 9 月 30 日 发布的 arXiv / CoRR 预印本。
1.4 会议 / 期刊
截至本文撰写时,公开可确认的版本主要是 arXiv 预印本。
1.5 开发框架与系统组成
从论文与公开资料可以确认,该系统的核心工程栈包括:
- 高层规划 backbone:Qwen2.5-VL-7B
- 强化微调算法:GRPO
- 低层控制器:Diffusion Policy
- 语言条件融合:冻结语言编码器 + FiLM
- 示教与轨迹恢复:UMI(Universal Manipulation Interface)
- 真实机器人平台:Dobot Nova5 6-DoF 机械臂 + GoPro10 相机
1.6 论文信息相关地址
- 论文地址(arXiv):https://arxiv.org/abs/2509.25852
- 论文 HTML 阅读页(ar5iv):https://ar5iv.org/html/2509.25852v1
- LEAP 数据集地址:https://huggingface.co/datasets/zitong86/LEAP
- UMI GitHub 地址:https://github.com/real-stanford/universal_manipulation_interface
2. 研究背景
长时程具身操作不是单一问题,而是至少同时包含四层挑战:
- 感知:从图像中理解对象类别、位置、关系、状态。
- 语言理解:把"我口渴了,给我拿点喝的"这类抽象请求映射到具体目标对象。
- 规划:把高层目标拆成一串逻辑连贯、物理可行、可执行的子技能序列。
- 执行与纠错:执行过程中环境会变化,机器人需要知道某一步是否做完,失败后是否应该重规划。
现有 VLM 已经能在许多视觉问答、空间推理和选择题 benchmark 上表现很好,但当它们真正面对机器人长时程任务时,问题开始暴露出来:
- 它们可能能"说对方向",但输出不符合机器人可执行格式;
- 它们可能能离线列步骤,但执行中一旦偏离原计划就容易崩;
- 它们缺少适合强化学习优化的可靠奖励,从而很难真正通过 RL 训练成高质量 planner。
传统的监督微调(SFT)更多是在模仿专家示例,适合"训练分布内"的静态回答,但不擅长处理真实执行中的偏差恢复。而在机器人规划里,偏差是常态。
因此,这篇论文要解决的根本矛盾是:
如何把真实世界示教数据变成适合训练规划模型的结构化语料,并进一步用可验证奖励把 VLM 训练成真正可部署的机器人高层规划器?
3. 相关研究
3.1 具身规划
已有许多工作尝试用 LLM / VLM 做高层规划,例如 few-shot prompting、冻结大模型作为 planner、再接低层控制器等。但这类方法往往有几个局限:
- 很多评测仍然停留在模拟器或静态 benchmark;
- 很多输出是自然语言解释,不一定可直接执行;
- 对真实世界开放指令、多步组合任务的泛化仍然有限。
3.2 视觉推理与强化微调
近年大模型强化微调(RLHF、RLAIF、RLVR、GRPO 等)在数学推理、代码生成、视觉问答等场景中取得了明显进展。但对机器人规划来说,困难在于:
- 奖励不是简单的正确 / 错误;
- 输出不是数学答案,而是一串结构化技能计划;
- 需要奖励函数同时兼顾格式合法性 、语义对齐 和序列完整性。
REVER 的重要性就在于,它把 RLVR 一类"基于可验证规则的强化微调"扩展到了具身规划这个更接近真实系统的问题上。
3.3 真实世界机器人数据
RT-1、RT-2、Open-X、UMI、ShareRobot 等工作为机器人学习提供了大量真实数据与训练基础。但这些数据通常偏向:
- 动作轨迹学习;
- 任务执行数据;
- 或空间推理 / 导航类问题。
而本文真正需要的是:
从图像和自然语言输入,生成结构化长时程计划,并做在线完成验证。
这要求数据不仅有动作,还必须有:
- 高层自然语言指令;
- 步骤级技能序列;
- 每一步的起始 / 完成状态;
- 完成判断的真假标签。
也正是因此,作者不是直接拿现成数据来训,而是自己构建了 LEAP。
4. 本文方法
4.1 本文方法概述
4.1.1 以往方法的痛点
以往方法主要有三类核心痛点:
- 没有足够多的真实世界长时程规划数据;
- 没有适合开放式计划生成的可验证奖励;
- 缺少在线执行中的完成验证与闭环重规划能力。
4.1.2 本文方法解决的问题
给定:
- 当前场景图像;
- 用户高层自然语言请求;
系统需要:
- 生成一串机器人可执行的子任务计划;
- 调用低层控制器执行每一步;
- 在执行过程中判断当前步骤是否完成;
- 如有必要,基于新观测重规划。
4.1.3 本文方法的核心思路与主要创新点
REVER 的核心思路可概括为三部分:
- 从真实示教自动构造规划数据:把 UMI 的原子技能示教转换为结构化的 Vision--Instruction--Plan 样本。
- 设计可验证奖励:用技能语法检查和二分图匹配给计划打分。
- 通过 GRPO 强化微调 VLM:让模型不仅会生成计划,还会做执行监控。
本文的主要创新点包括:
- 自动构造真实世界长时程规划数据集 LEAP;
- 提出基于技能语法 + 二分图匹配的可验证奖励;
- 用 GRPO 在规划任务上做强化微调;
- 将同一个 VLM 同时用作 planner 与 execution monitor。
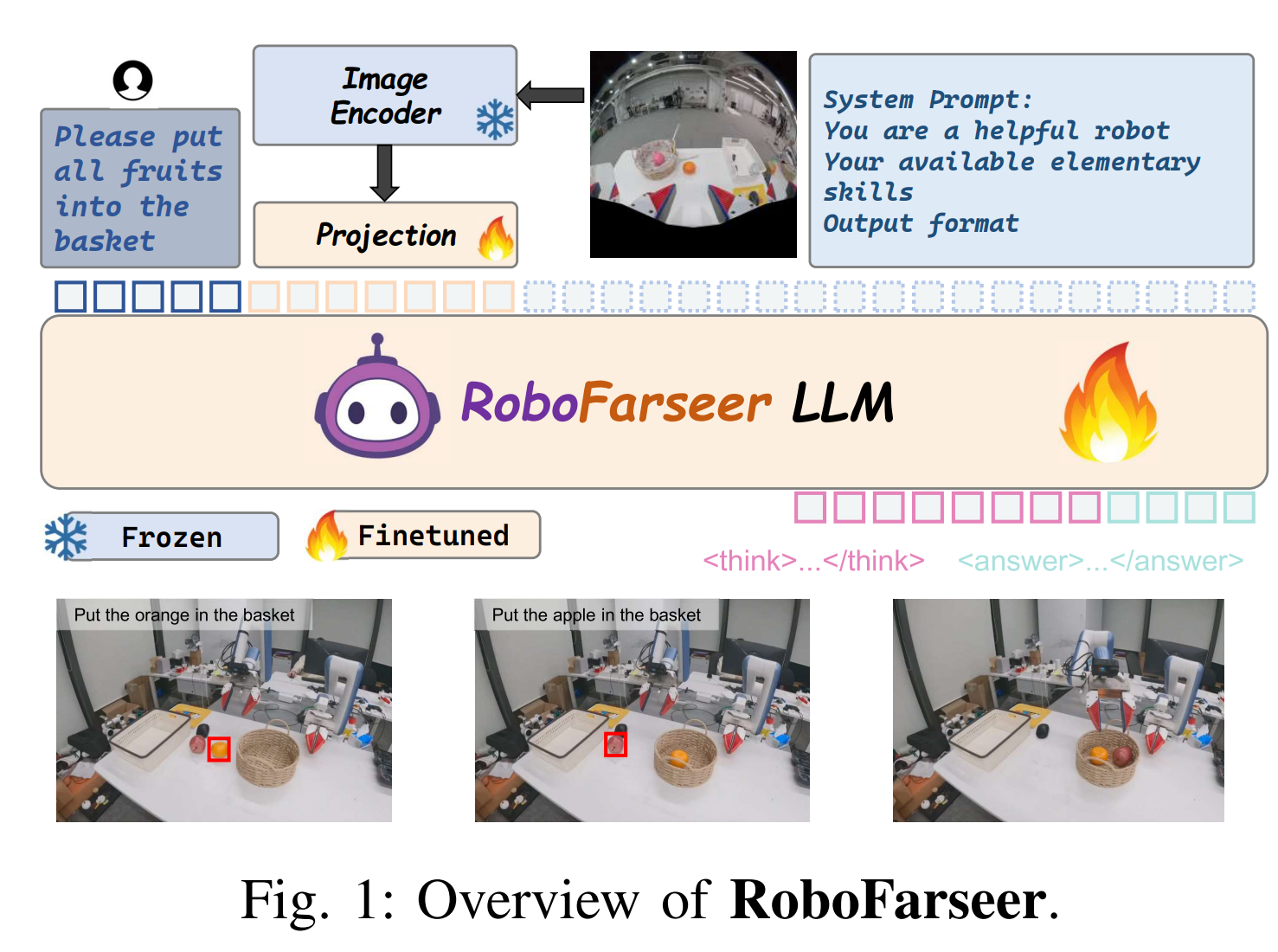
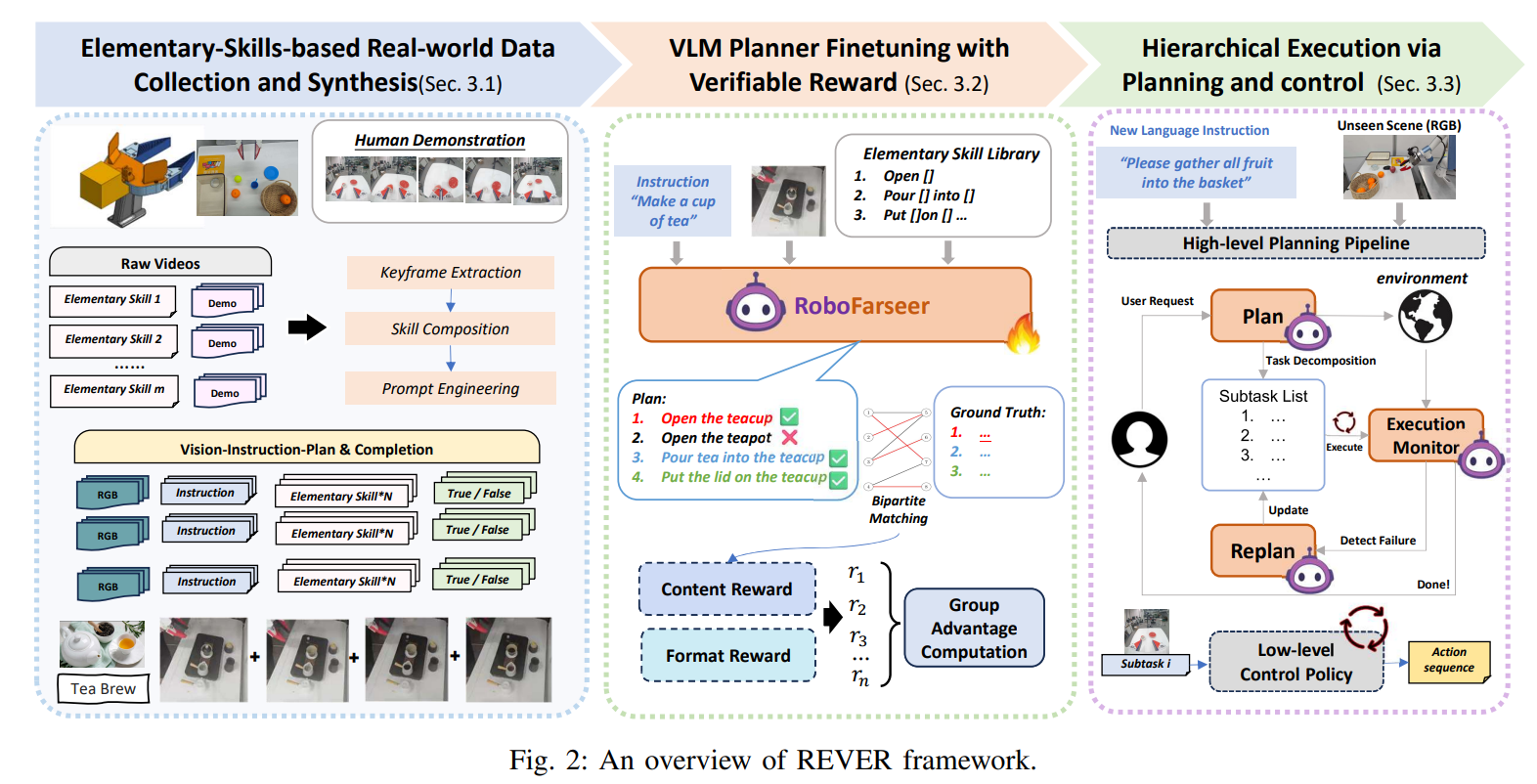
4.2 本文方法详述
4.2.1 从现实世界示教到 LEAP:数据收集与自动合成
REVER 的一个关键前提是:系统不能只依赖人工撰写的规划语料,而必须从真实世界机器人演示中自动构造出适合 VLM 训练的结构化数据。
论文的做法是先定义一个原子技能库:
\\mathcal{S}={s_1,s_2,\\dots,s_N}
其中每个 s_i 表示一个原子技能,例如拾取、放置、倒入、打开、推动等。
随后,一个长时程任务被表示为:
T=(s^{(1)},s^{(2)},\\dots,s\^{(K)}),\\quad s\^{(k)}\\in\\mathcal{S}
这表示复杂任务不是直接从零人工写出的自由文本,而是由原子技能组合而成的程序化技能序列。
(1)数据收集
作者基于 UMI(Universal Manipulation Interface) 采集真实世界的 kinesthetic demonstrations。UMI 的优势在于,它能够方便地收集硬件无关的原子操作示教,同时通过 SLAM 管线恢复执行轨迹,从而为后续训练低层策略与高层规划提供基础数据。
示教采集完成后,系统并不会直接使用整段视频,而是进一步执行:
- 视频分段
- 关键帧提取
- 鱼眼校正
- 原子技能标签对齐
- 起始 / 结束观测抽取
也就是说,原始"连续视频流"会被结构化成一段段对应具体技能的片段。
(2)从演示到结构化标注
对每个长任务 T=(s^{(1)},\\dots,s^{(K)}) ,系统会为每个技能步骤提取关键观测:
- 该步开始时的观测: o\^{(k)}_{init}
- 该步结束后的观测: o\^{(k)}_{final}
基于这些观测,系统自动生成两类监督:
第一类是 Plan Annotation,即:
- 输入:初始场景观测 o\^{(1)}*{init} 与用户高层指令 I*{user}
- 输出:完整技能序列
y_{\\text{plan}}=(s^{(1)},s^{(2)},\\dots,s\^{(K)})
第二类是 Completion Annotation,即:
- 输入:某一步的起始观测、当前观测、当前技能描述
- 输出:该技能是否完成
y_{\\text{comp}}\\in{\\text{True},\\text{False}}
这样,同一段原始示教数据就被转换成了两类 VLM 可学习的任务:
- 计划生成任务
- 完成验证任务
(3)负样本构造
Completion 数据中的负样本并不是任意随机错误图像,而是从执行中途抽取的未完成状态,例如:
- 起始图像: o\^{(k)}_{init}
- 中途图像: o'_{uncomp}
这意味着模型学习到的不是"明显错误"与"明显正确"的粗糙区分,而是更接近真实运行条件的判断:
当前这一步是不是已经完成,而不是仅仅在进行中。
(4)统一的数据格式
最终,每个训练样本都可以写成:
d=(q,\\mathcal{O},y)
其中:
- q :问题或 prompt
- \\mathcal{O} :一张或多张观测图像
- y :对应答案
对于 planning, \\mathcal{O} 通常是一张初始图像;
对于 completion, \\mathcal{O} 通常是"起始图 + 当前图"。
(5)为什么这一步极其关键
这条自动化数据流水线,本质上完成了一件非常重要的事情:
把机器人真实世界的操作经验,翻译成了 VLM 可以学习的结构化推理数据。
原始视频是连续动作;
分段后得到技能;
配上语言得到技能程序;
再引入完成验证,就得到了闭环执行所需的状态判断样本。
这正是 REVER 整个方法能够成立的基础。
4.2.2 Prompt、Response 与技能格式约束
论文和 LEAP 数据卡都明确显示,REVER 并不是让模型自由输出自然语言,而是把规划任务组织成一种带有角色设定、技能集合、输出格式约束的结构化 prompt。
这样做的目的有三个:
- 让模型输出落在机器人可执行的技能 DSL 上;
- 让 reward 能够检查输出格式是否合法;
- 让模型在训练中形成"显式思考 + 结构化答案"的稳定模式。
4.2.2.1 规划任务的 Prompt / Response 示例
下面给出来自作者公开 LEAP 数据卡的示例。该示例是一个桌面整理场景的计划生成任务。
Prompt(摘自 LEAP 数据卡,保留关键结构):
latex
You are a helpful assistant that can perform action in the real world using your gripper.
Your available skills:
Put [object] into [location].
Pick up [object] and pour into [location].
Put [object] on [location].
The user request is: clean up desktop, please.
...
First output the thinking process in '<think> </think>' tags and then output the final answer in '<answer> </answer>' tags.这个 prompt 展示了规划任务中非常关键的四个组成部分:
- 角色说明:你是一个能在真实世界抓取和操作物体的助手;
- 可用技能集:只能从预定义技能模板中选择;
- 用户指令:例如"clean up desktop";
- 输出协议:必须先写
<think>,再写<answer>。
Response(摘自 LEAP 数据卡中的 expected response format):
latex
<think>
I can see several items on the desktop: a mouse, an orange, a cup, and tape. ...
</think>
<answer>
1. Put the mouse on mouse pad.
2. Put the orange into the basket.
3. Put the cup on the saucer.
4. Put the tape into the box.
</answer>这个示例非常有代表性,因为它说明模型不是只要"说出一个合理计划"就够了,而是必须:
- 看懂场景里的对象;
- 将对象映射到合适的技能模板;
- 以编号步骤形式输出;
- 保持严格技能语法。
LEAP 数据卡中还公开了一个更细粒度的原子技能版 planning 示例,其中技能集是:
Pick up [object]Place on [location]Place into [location]Pour into [location]Open [object]Push [object]
对应的 response 也会变成更细的原子动作序列,例如:
latex
1. Pick up the mouse
2. Place the mouse on mouse pad
...这说明 LEAP 不仅包含较粗粒度的复合技能计划,也支持原子动作级别的计划表示。
4.2.2.2 完成验证任务的 Prompt / Response 示例
完成验证任务比 planning 更简洁,但在系统运行中极其关键。
来自 LEAP 数据卡的 completion 示例中,prompt 直接是一条动作描述:
latex
Put the mouse on mouse pad.它的输出格式只有两种:
latex
True或
latex
False论文公开文本中还给出了一个更接近论文图示风格的 completion prompt。下面是公开文本中出现的示意例子:
latex
Pick up the teacup and place it on the saucer.
Output ONLY True if the second image clearly shows the object is in the target location as described in the action.
Otherwise, output ONLY False.可以看到,completion 任务不是开放生成,而是一个严格受约束的真假判断问题:
- 输入:起始图像 + 当前图像 + 当前技能指令
- 输出:当前技能是否完成
这类样本最终让 RoboFarseer 具备了在线执行监控能力。
4.2.2.3 为什么 Prompt 设计如此重要
对机器人系统来说,高层 planner 的输出不是写给人看的自然语言,而更像是一个可执行接口协议。
如果模型随意输出自然语言描述,那么:
- 低层控制器难以消费;
- reward 难以验证;
- 长时程规划很难稳定训练。
而通过技能集合与格式约束,作者实际上把规划任务压缩成了一个"机器人 DSL 上的程序生成问题"。
4.2.3 可验证奖励:REVER 的技术核心
我认为,REVER 真正最核心的技术贡献,就是它把开放式具身规划的奖励问题,变成了一个可验证、可分解、可扩展的规则化打分问题。
论文把生成计划记为:
P_g=(p_1,p_2,\\dots,p_M)
把真实计划记为:
P_{gt}=(p'_1,p'_2,\\dots,p'_N)
然后定义总奖励:
R(P_g,P_{gt})=w_fR_{\\text{format}}(P_g)+w_cR_{\\text{content}}(P_g,P_{gt})
其中:
- R_{\\text{format}} :格式 / 语法是否合法
- R_{\\text{content}} :内容上是否与真实计划对齐
4.2.3.1 格式奖励
格式奖励首先检查输出是否满足规定结构,例如:
- 是否包含
<think>...</think>和<answer>...</answer>标签; - 是否以编号步骤输出;
- 是否符合技能模板语法。
其本质作用是:
先把输出拉进"可被机器人解析和执行"的合法空间。
如果没有这一层,模型很可能学会输出一堆"看起来合理但不可执行"的自然语言描述。
4.2.3.2 单步相似度
论文将单步匹配分数定义为:
\\operatorname{Sim}(p_i,p'*j)=w_a\\operatorname{Sim}* {act}(p_i,p'*j)+w_o\\operatorname{Sim}*{obj}(p_i,p'_j)
其中:
- \\operatorname{Sim}_{act} :动作词是否匹配
- \\operatorname{Sim}_{obj} :对象 / 目标位置是否匹配
- w_a=0.3
- w_o=0.7
也就是说,论文显式地把对象与目标位置的匹配看得比动作词更重要。
这个设计非常符合具身操作场景的直觉:
- 动词模板往往较少;
- 真正决定任务是否正确的,很多时候是"对哪个对象做""放到哪里去"。
例如:
Put the cup on the saucer与Put the teacup on the saucer应该高度相似;Put the cup on the saucer与Put the cup into the basket虽然动词相近,但目标完全不同,不能视为相近计划。
4.2.3.3 二分图匹配:为什么不是逐步对齐
如果直接按顺序逐位比较,比如第 1 步对第 1 步,第 2 步对第 2 步,那么当模型只是在可交换步骤上调整了顺序时,会被错误地惩罚过重。
为此,论文引入最大权二分图匹配:
$ R_{bm}(P_g,P_{gt})=
\frac{1}{\max(M,N)}
\max_{\pi\in\Pi}\sum_{i=1}^{M}\operatorname{Sim}(p_i,p'_{\pi(i)}) $
其中:
- M :生成计划长度
- N :真实计划长度
- \\Pi :所有可能匹配方式
- \\pi(i) :第 i 个生成步骤匹配到的真实步骤
随后加入长度惩罚:
R_{\\text{content}}(P_g,P_{gt})=R_{bm}(P_g,P_{gt})-w_l\|M-N\|
其中论文给出:
w_l=0.1
这意味着 REVER 的内容奖励不是简单 exact match,而是一个连续、柔性的全局对齐分数。
4.2.4 二分图匹配奖励的详细举例
最大权二分匹配简介
论文没有展开具体求解器实现,但从问题形式看,就是标准的最大权二分匹配:
给定权重矩阵 W[i,j],求一个匹配集合 M,使得:
max_{M} \\sum_{(i,j)\\in M} W\[i,j\]
约束是:
- 每个
gi至多出现一次 - 每个
pj至多出现一次
你可以把它理解成"从权重矩阵里选若干个格子",但要求:
- 任何两格不能在同一行
- 任何两格不能在同一列
- 总和最大
下面给出一个完整例子,逐步说明奖励如何计算。这个计算过程是根据论文公式展开的说明性示例。
设真实计划为:
$ P_{gt}=\begin{cases}
p'_1=\text{Put the apple into the basket}\
p'_2=\text{Put the banana into the basket}\
p'_3=\text{Put the cup on the saucer}
\end{cases} $
情况 A:完全正确且顺序一致
模型输出:
$ P_g=\begin{cases}
p_1=\text{Put the apple into the basket}\
p_2=\text{Put the banana into the basket}\
p_3=\text{Put the cup on the saucer}
\end{cases} $
对应匹配矩阵为:
\\mathbf S_A= \\begin{bmatrix} 1 \& 0.3 \& 0.3\\ 0.3 \& 1 \& 0.3\\ 0.3 \& 0.3 \& 1 \\end{bmatrix}
解释一下这个矩阵:
- 第 1 行第 1 列:苹果放进篮子,对应苹果放进篮子,完全匹配,得 1
- 第 1 行第 2 列:苹果 vs 香蕉不同,但动作同为
Put,所以给 0.3 - 第 1 行第 3 列:苹果放进篮子 vs 杯子放在茶托上,对象和目标都不同,但动作仍是
Put,这里按前文简化仍记 0.3
最优匹配就是对角线:
$ \operatorname{Sim}(p_1,p'_1)=1,\quad
\operatorname{Sim}(p_2,p'_2)=1,\quad
\operatorname{Sim}(p_3,p'_3)=1 $
所以:
R_{bm}=\\frac{1+1+1}{\\max(3,3)}=1
长度一致,惩罚项为 0,于是:
R_{\\text{content}}=1
这是满分情形。
情况 B:顺序交换,但语义完全正确
模型输出:
$ P_g=\begin{cases}
p_1=\text{Put the banana into the basket}\
p_2=\text{Put the apple into the basket}\
p_3=\text{Put the cup on the saucer}
\end{cases} $
如果做逐位比较,第 1 步和第 2 步都会被判错;
但 REVER 做的是全局最大匹配,对应匹配矩阵为:
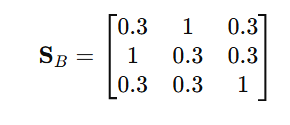
解释:
- 第 1 行第 2 列:
banana -> basket与真实第 2 步完全一致,得 1 - 第 2 行第 1 列:
apple -> basket与真实第 1 步完全一致,得 1 - 第 3 行第 3 列:
cup -> saucer完全一致,得 1
最优匹配不是主对角线,而是:
- p_1 \\leftrightarrow p'_2 ,得分 1
- p_2 \\leftrightarrow p'_1 ,得分 1
- p_3 \\leftrightarrow p'_3 ,得分 1
因此:
R_{bm}=\\frac{3}{3}=1
R_{\\text{content}}=1
这体现了二分图匹配的核心优势:
对于"可交换步骤"的局部重排,不会过度惩罚。
情况 C:漏掉一步
模型输出:
$ P_g=\begin{cases}
p_1=\text{Put the apple into the basket}\
p_2=\text{Put the banana into the basket}
\end{cases} $
现在生成计划只有 2 步,所以匹配矩阵是一个 2×32\times 32×3 矩阵:
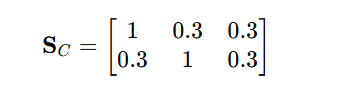
最大匹配总分为 2,因此:
R_{bm}=\\frac{2}{\\max(2,3)}=\\frac{2}{3}\\approx 0.667
长度差:
\|M-N\|=\|2-3\|=1
长度惩罚为:
0.1\\times 1=0.1
所以:
R_{\\text{content}}=0.667-0.1=0.567
这说明 REVER 会给"部分正确但不完整"的输出中等分数,而不是简单判零。
情况 D:多写一步无关动作
模型输出:
$ P_g=\begin{cases}
p_1=\text{Put the apple into the basket}\
p_2=\text{Put the banana into the basket}\
p_3=\text{Put the cup on the saucer}\
p_4=\text{Put the tape into the box}
\end{cases} $
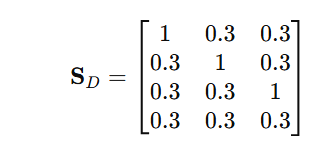
前三步都可以匹配到真实计划,总和为 3,因此:
R_{bm}=\\frac{3}{\\max(4,3)}=\\frac{3}{4}=0.75
长度惩罚仍为 0.1,因此:
R_{\\text{content}}=0.75-0.1=0.65
这说明多写无关步骤也会扣分,但前面正确的步骤仍然保留贡献。
情况 E:对象和位置对了,但动作模板错了
模型输出:
$ P_g=\begin{cases}
p_1=\text{Put the apple into the basket}\
p_2=\text{Put the banana into the basket}\
p_3=\text{Pick up the cup and pour into the saucer}
\end{cases} $
匹配矩阵:
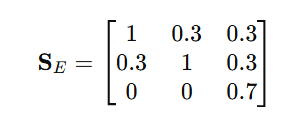
前两步仍然是满分匹配,各得 1。
第三步中:
- 动作不匹配,因此 \\operatorname{Sim}_{act}=0
- 对象与目标位置都匹配,因此可认为 \\operatorname{Sim}_{obj}=1
于是第三步相似度为:
\\operatorname{Sim}(p_3,p'_3)=0.3\\times 0+0.7\\times 1=0.7
因此总和为:
1+1+0.7=2.7
归一化后:
R_{bm}=\\frac{2.7}{3}=0.9
长度一致,无惩罚,所以:
R_{\\text{content}}=0.9
这说明 REVER 允许一定程度的"部分语义正确",尤其是在对象和目标位置对齐时,会给出较高但非满分的奖励。
这个例子说明了什么
REVER 的二分图匹配奖励本质上在做三件事:
- 允许局部重排:避免把可交换步骤的顺序变化判得太差;
- 允许部分正确:为 RL 提供连续奖励;
- 允许受控柔性匹配:对象、位置、介词可以做有限语义对齐。
当然,它也有边界:
- 对"先开盖、再倒茶、最后盖回去"这类强因果顺序依赖任务,最大匹配可能比人类直觉更宽松;
- 因而它更像"柔性全局对齐",而不是严格拓扑因果验证器。
但从工程角度看,这种设计在"稳定、可验证、可扩展"之间做了一个很实用的平衡。
4.2.5 用 GRPO 进行强化微调
在有了可验证奖励后,论文使用 GRPO(Group Relative Policy Optimization) 对 VLM 进行强化微调。
其核心思想是:
- 对同一个 prompt,一次采样多个回答;
- 用 reward 对这些回答打分;
- 根据组内相对表现计算 advantage;
- 让高奖励回答更可能在后续被生成。
4.2.5.1 组内标准化 Advantage
论文给出的 advantage 写法为:
$ \hat{A}_i=
\frac{r_i-\operatorname{mean}({r_1,\dots,r_B})}
{\operatorname{std}({r_1,\dots,r_B})} $
其中:
- r_i :第 i 个候选回答的奖励
- B :同一个 prompt 下采样出的回答个数
在论文实验中,每个 prompt 会采样 8 个 completions。
这条公式的含义很直观:
- 比组内平均更好的回答, \\hat A_i \> 0
- 比组内平均更差的回答, \\hat A_i \< 0
这样就不需要额外训练一个 value model。
4.2.5.2 GRPO 目标函数
论文采用了类似 PPO 的裁剪优化目标:
$ J_{\text{GRPO}}(\theta)=
\mathbb{E}{{o_i}\sim\pi {\theta_{\text{old}}}(q)}
\left[
\frac{1}{N}\sum_{i=1}^{N}
\Big(
\min(s_1\hat A_i,s_2\hat A_i)
-\beta D_{KL}\\pi_\\theta\|\\pi_{ref}
\Big)
\right] $
其中:
s_1=\\frac{\\pi_\\theta(o_i\|q)}{\\pi_{\\theta_{\\text{old}}}(o_i\|q)}
$ s_2=\operatorname{clip}\left(
\frac{\pi_\theta(o_i|q)}{\pi_{\theta_{\text{old}}}(o_i|q)},
1-\epsilon,
1+\epsilon
\right) $
这里:
- \\theta :当前策略参数
- \\theta_{\\text{old}} :旧策略参数
- \\pi_{ref} :参考策略
- \\beta :KL 正则系数
- \\epsilon :裁剪范围
其目的有两个:
- 防止策略更新幅度过大;
- 保持训练稳定,不至于偏离原始语言模型分布太远。
4.2.5.3 为什么 GRPO 适合本文
GRPO 特别适合 REVER 的原因在于:
- reward 可直接计算,不需要训练 judge model;
- 输出是长文本结构化计划,组内相对比较很自然;
- 规划任务中"接近正确"的输出也很常见,适合用相对优势去优化。
从直觉上讲,GRPO 在这里做的事情就是:
同一个机器人任务采样 8 个计划,用规则奖励给它们打分,让模型逐渐更偏向那些既合法又语义正确的计划。
4.2.6 规划---执行---监控闭环
如果论文只做到"离线生成计划",它的意义会小很多。REVER 真正走向系统级价值的关键,在于它把 planner 放进了真实机器人执行闭环中。
整个系统被分为三层:
- Planner:给定高层用户指令和当前观测,生成技能计划;
- Control Policy:执行当前步骤;
- Execution Monitor:检查当前步骤是否已经完成。
4.2.6.1 Planner
Planner 就是强化微调后的 RoboFarseer。它输入:
- 当前场景图像;
- 用户自然语言目标;
输出:
- 一串结构化技能步骤。
4.2.6.2 Control Policy
低层控制器基于 Diffusion Policy,并结合:
- 视觉编码器;
- 冻结语言编码器;
- FiLM 条件融合;
- 本体状态输入;
以生成实际动作序列。
从结构上看,高层 planner 输出的是"做什么",而低层控制器负责"具体怎么做"。
4.2.6.3 Execution Monitor
这是 REVER 与许多只会"列计划"的工作真正拉开差距的地方。
在执行每个子任务时,monitor 会以 5Hz 的频率检查该步骤是否已经完成。它输入:
- 当前步骤开始前的图像;
- 当前时刻图像;
- 当前技能指令;
输出:
True:该步已完成False:该步未完成
一旦 monitor 输出 True:
- 当前步骤终止;
- 系统推进到下一步。
如果长时间未完成或步骤失败:
- 系统会以新的当前场景为输入;
- 重新调用 planner 生成更新后的剩余计划。
4.2.6.4 这套闭环最重要的意义
这个设计最重要的一点在于:
它把完成判断定义为"相对状态变化识别",而不是绝对图像分类。
例如,对于"把杯盖打开":
- 关键不在于当前图像里有没有杯盖;
- 而在于相对于该步开始时,杯盖是否已经从"盖上"变成"打开"。
这使得 monitor 更接近真实执行所需的 progress estimation。
4.3 本文所有公式及其符号解读
下面将论文中的关键公式统一整理并解释。
4.3.1 原子技能集合
\\mathcal{S}={s_1,s_2,\\dots,s_N}
- \\mathcal{S} :原子技能库
- N :技能总数
- s_i :第 i 个原子技能
4.3.2 长时程任务表示
T=(s^{(1)},s^{(2)},\\dots,s\^{(K)}),\\quad s\^{(k)}\\in\\mathcal{S}
- T :长时程任务
- K :任务步数
- s\^{(k)} :第 k 步技能
4.3.3 计划标注
y_{\\text{plan}}=(s^{(1)},s^{(2)},\\dots,s\^{(K)})
- planning 任务的标准答案,即完整技能序列。
4.3.4 完成验证标签
y_{\\text{comp}}\\in{\\text{True},\\text{False}}
- completion 任务的真假标签。
4.3.5 统一样本形式
d=(q,\\mathcal{O},y)
- q :prompt
- \\mathcal{O} :观测图像集合
- y :答案
4.3.6 总奖励
R(P_g,P_{gt})=w_fR_{\\text{format}}(P_g)+w_cR_{\\text{content}}(P_g,P_{gt})
- P_g :生成计划
- P_{gt} :真实计划
- w_f :格式奖励权重
- w_c :内容奖励权重
4.3.7 单步相似度
\\operatorname{Sim}(p_i,p'*j)=w_a\\operatorname{Sim}* {act}(p_i,p'*j)+w_o\\operatorname{Sim}*{obj}(p_i,p'_j)
- p_i :生成计划中的第 i 步
- p'_j :真实计划中的第 j 步
- w_a=0.3 :动作相似度权重
- w_o=0.7 :对象 / 位置相似度权重
4.3.8 二分图匹配分数
$ R_{bm}(P_g,P_{gt})=
\frac{1}{\max(M,N)}
\max_{\pi\in\Pi}\sum_{i=1}^{M}\operatorname{Sim}(p_i,p'_{\pi(i)}) $
- M :生成计划长度
- N :真实计划长度
- \\Pi :所有可能匹配
- \\pi(i) :生成步骤 p_i 匹配到的真实步骤索引
4.3.9 内容奖励
R_{\\text{content}}(P_g,P_{gt})=R_{bm}(P_g,P_{gt})-w_l\|M-N\|
- w_l=0.1 :长度惩罚系数
4.3.10 Completion 奖励
对于 completion 任务,内容奖励更简单:
- 输出与标签完全一致,则奖励为 1;
- 否则奖励为 0。
4.3.11 组内标准化 Advantage
$ \hat{A}_i=
\frac{r_i-\operatorname{mean}({r_1,\dots,r_B})}
{\operatorname{std}({r_1,\dots,r_B})} $
- r_i :第 i 个样本奖励
- B :组内回答个数
4.3.12 GRPO 目标函数
$ J_{\text{GRPO}}(\theta)=
\mathbb{E}{{o_i} {i=1}^{N}\sim\pi_{\theta_{\text{old}}}(q)}
\left[
\frac{1}{N}\sum_{i=1}^{N}
\left(
\min(s_1\hat A_i,s_2\hat A_i)
-\beta D_{KL}\\pi_\\theta\|\\pi_{ref}
\right)
\right] $
4.3.13 PPO 风格裁剪项
s_1=\\frac{\\pi_\\theta(o_i\|q)}{\\pi_{\\theta_{\\text{old}}}(o_i\|q)}
$ s_2=\operatorname{clip}\left(
\frac{\pi_\theta(o_i|q)}{\pi_{\theta_{\text{old}}}(o_i|q)},
1-\epsilon,
1+\epsilon
\right) $
这些公式串起来,实际上形成了 REVER 的完整数学闭环:
- 用技能序列表示任务;
- 用规则奖励衡量输出;
- 用 GRPO 优化模型;
- 最终把模型部署进真实闭环系统。
5. 实验
5.1 实验设置
高层 planner 采用强化微调后的 Qwen2.5-VL-7B ;
低层控制器采用 Diffusion Policy ;
真实机器人平台为:
- Dobot Nova5 六自由度机械臂
- GoPro10 相机
低层控制器训练数据来自 UMI 示教与轨迹恢复结果。
5.2 训练过程
论文给出了较完整的训练细节:
- 训练硬件:8 张 H100 80GB
- 每个 epoch 大约:28 小时
- 训练数据:合并清洗 LEAP-L、LEAP-U、EgoPlan、ShareRobot、ERQA planning 数据
- 总计约:57,000 个 triplets
- 训练轮数:3 epochs
- per-device batch size:8
- gradient accumulation:12
- 学习率:1e-5,并做 cosine decay
- KL 系数:0.04
- 每个 prompt 采样:8 个 completions
- 最大生成长度:2048 tokens
5.3 基准与基线
论文评测覆盖多个 benchmark:
- LEAP-L
- LEAP-U
- ShareRobot-Planning
- EgoPlan-Bench2
- RoboVQA
其中 LEAP-L / LEAP-U 强调真实世界开放式规划,作者还将 LEAP 测试集转换成 655 条 MCQ 评测样本。
对比模型包括:
- 闭源模型:Gemini-2.5-Pro、Gemini-2.5-Flash、GPT-4.1、GPT-4o、Claude-Sonnet-4
- 开源通用 VLM:Qwen2.5-VL-72B / 32B
- 具身模型:RoboBrain2-7B / 32B
5.4 实验结果及其逐图表解读
5.4.1 Fig. 4:规划 benchmark 上的准确率
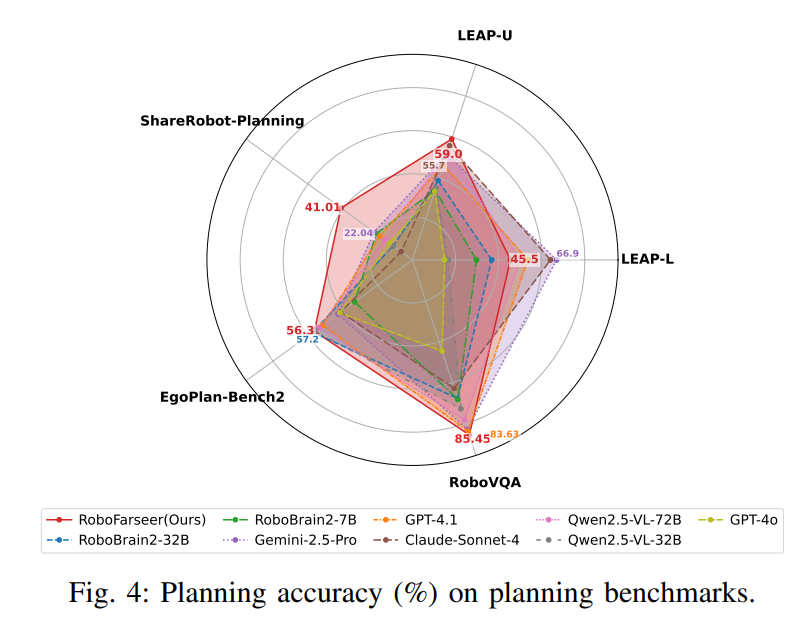
先说这张图到底在测什么
这里的任务是:
给候选答案,让模型选择一个正确的答案。这里是 MCQ问题
Fig. 4 比较了各模型在多个 planning benchmark 上的 MCQ/ top-1 accuracy。
Fig.4 比较了各模型在多个 planning benchmark 上的 Planning accuracy(%) ,本质上就是 top-1 accuracy,也就是:
\\text{Planning Accuracy} = \\frac{#\\text{模型第一答案正确的样本数}}{#\\text{总测试样本数}} \\times 100%
论文指出:
- 在 LEAP-U(MCQ) 、RoboVQA 、ShareRobot-Planning 上,RoboFarseer 取得最佳成绩;
- 在 EgoPlan2 上,RoboFarseer 取得 56.4% ,仅次于 RoboBrain2-32B 的 57.2%。
解读:
这张图说明,REVER 并不只是把一个 7B 模型调得"勉强能用",而是真正把它推到了与更大、更强模型竞争的水平。
尤其值得注意的是:
- RoboFarseer 对开源基线的领先幅度很大;
- 即使在闭源模型面前,也能保持很强竞争力;
- 这说明强化微调带来的收益不只是输出格式变好,而是视觉理解、目标分解与序列规划能力整体被增强了
这个指标测到了什么,没测到什么?
它测到的是:模型是否能在给定备选/标准评估协议下,识别出最合理的计划答案 。
它没完全测到的是:模型是否真的能自己生成一个长而可执行的完整计划。这也是为什么作者紧接着又做了 open-ended evaluation,并在 Fig.5 里用 bipartite matching score 来补这一块。
5.4.2 Fig. 5:LEAP 开放式规划测试集上的二分图匹配分数
Fig. 5 是整篇论文最关键的一张结果图之一。
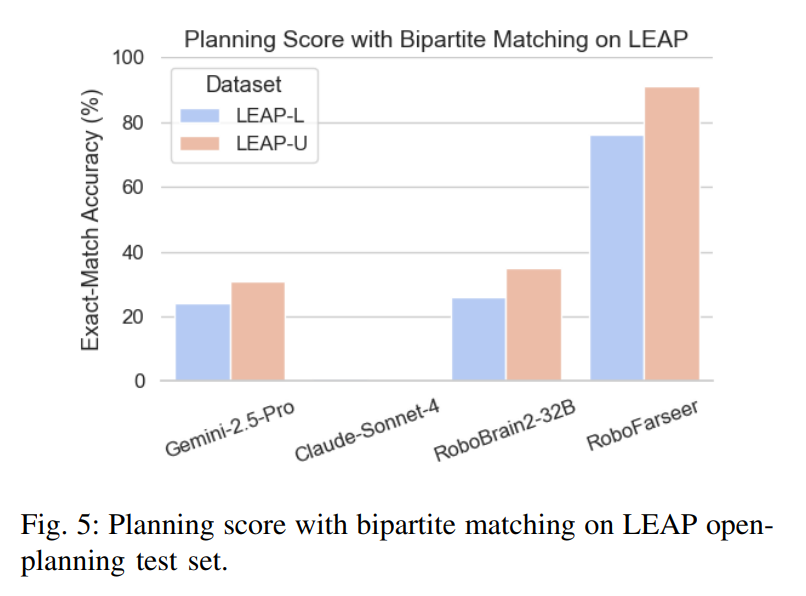
先说这张图到底在测什么
这里的任务是:
不给候选答案,让模型自己生成完整技能序列计划。这里不再是 MCQ,而是要求模型直接生成完整计划,再用论文提出的二分图匹配分数评估。
论文中提到的关键信息包括:
- 在 LEAP-L open planning 上:
- RoboFarseer:76%
- Gemini-2.5-Pro:24%
- RoboBrain2-32B:26%
- Claude-Sonnet-4 因为经常偏离技能语法,分数接近 0。
- LEAP-U 上也有同样趋势,优势达到 45--60 个百分点。
解读:
这张图真正证明的不是"RoboFarseer 会做题",而是:
RoboFarseer 更会以机器人真正能执行的格式输出正确计划。
许多强大通用模型在 MCQ 上可以依靠常识和视觉理解拿高分,但一旦要求它们:
- 严格遵守技能模板;
- 输出编号步骤;
- 保持多步计划的结构一致性;
- 避免自然语言跑偏;
它们的表现就明显下降。
而这正是 REVER 的训练目标所在。
5.4.3 Fig. 6:In-context examples 对开放式规划的影响
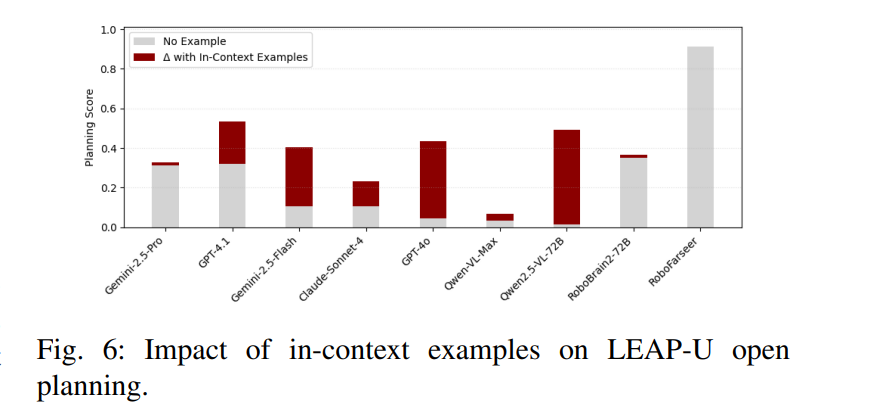
1. 这张图怎么读
图里的含义是:
- 灰色柱 :No Example,也就是不给示例、直接 zero-shot 生成计划时的分数。
- 红色部分 :Δ with In-Context Examples ,表示在 prompt 里加入两个示例之后,分数相对 zero-shot 增加了多少。
- 所以每个模型的最终 few-shot 分数 = 灰色底座 + 红色增量。
横轴是不同模型,纵轴是规划分数。结合论文正文,这张图主要是在看开放式规划里对技能格式的遵守 / 可执行计划输出能力,不是 Fig. 4 那种 MCQ top-1 accuracy。
Fig. 6 研究的是:
基线在开放式规划上表现差,是否只是因为 prompt 没调好?
论文的结论是:
- 给基线增加 两个 in-context examples 后,所有模型表现都会提升;
- 但 RoboFarseer 依然显著领先;
- 并且 RoboFarseer 仍保持 92% exact-match。
解读:
这张图排除了一个很常见的质疑:
"是不是基线只是没给 enough few-shot?"
结果表明,即使给了 few-shot,普通通用模型仍然难以稳定地产生合法、完整、时序一致的技能计划。
也就是说,RoboFarseer 的优势不只是 prompt engineering,而是:
- 技能语法真正被学进了模型;
- 输出格式忠实度被强化微调稳定塑形了;
- 模型已经"内化"了规划协议。
5.4.4 Fig. 7:真实世界实验场景

Fig. 7 展示了三类真实机器人评测场景:
- Tidy up Desktop
- Brew Tea
- Bring Food & Drinks
作者强调:
- 场景仅搭建一次;
- 物体位置和姿态随机;
- 指令是高层自然语言,而非模板化步骤。
解读:
这三类场景分别对应三种本质不同的能力:
- 桌面整理:测试空间归位与类别组织能力;
- 泡茶:测试强顺序依赖与精细操作能力;
- 拿食物饮料:测试开放语义 grounding 能力。
因此 Fig. 7 的价值不只是"展示 demo",而是说明:
REVER 不是只会某一种单场景任务,而是覆盖了多种具身操作难度。
5.4.5 Table I:10 条真实指令的量化结果
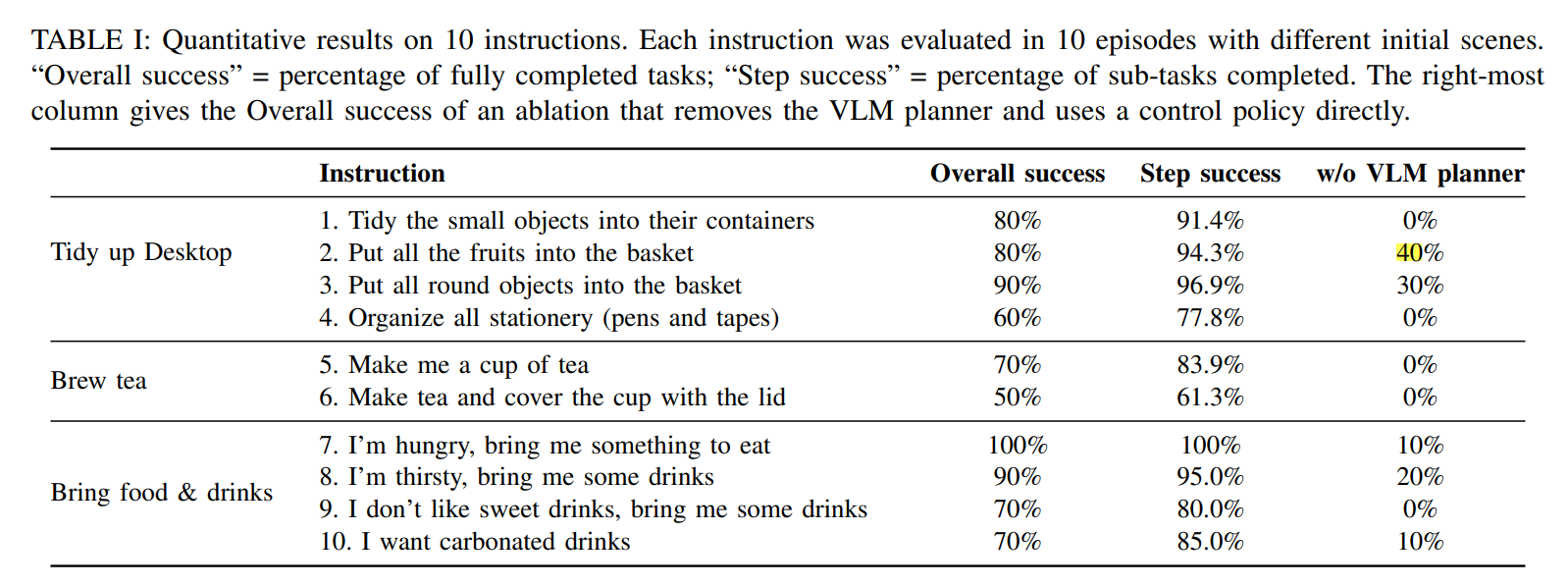
Table I 中统计了 3 个家庭场景下的 10 条自然语言指令 ,每条指令都在不同初始场景下跑了 10 个 episode 。表里的三个指标分别是:
Overall success = 整个任务完整完成的比例;
Step success = 子任务完成比例;
w/o VLM planner = 去掉高层 VLM planner、只靠低层控制策略时的整体成功率。
解读:
这张表非常有价值,原因有三:
第一,Bring Food & Drinks 表现最好。因为这类任务高层语义约束清晰,动作链相对短,因此规划与执行都更稳定。
第二,Brew Tea 表现最难。因为它要求精细操作、严格步骤顺序、毫米级倒水和盖杯盖等高精度动作,这对低层控制与感知提出了更高要求。
第三,右侧的"w/o VLM planner"对照列非常关键。论文总结说,没有 VLM planner 时,整体 overall success 只有 14% ,并且茶任务为 0%。
这说明:
高层 planner 不是锦上添花,而是长时程组合任务能否成立的必要条件。
5.4.6 Fig. 8:失败原因分析

Fig. 8 对所有失败案例做了归因统计:
- 43.6%:下游控制失败
- 26.9%:感知错误
- 16.2%:推理错误
- 3.3%:输出格式等其他问题
解读:
这张图的重要性在于,它说明经过 REVER 训练后,系统的最大短板已经不再是规划本身,而是:
- 抓取与位姿控制精度;
- 液体操作与插入动作的稳定性;
- 视觉感知对小物体、透明物体、遮挡场景的鲁棒性。
换句话说:
REVER 已经把高层规划做到了"不是系统最大瓶颈"的程度。
这对一篇真实机器人系统论文来说,是非常强的信号。
5.5 实验总结
综合所有实验,可以得出三个核心结论:
- RoboFarseer 真正强的不是 MCQ,而是开放式、可执行计划生成。
- 技能语法 + 可验证奖励的组合,是性能提升的关键。
- 真实机器人系统中的主要瓶颈已经下沉到执行层,而非规划层。
这说明 REVER 不只是做了一个更会"回答规划题"的 VLM,而是把 VLM 真正推进到了机器人高层决策模块的位置。
6.相关思考
1)如何理解开环 task decomposition 和闭环 task decomposition?什么是闭环?
先给最直观的定义。
开环 task decomposition :
机器人在任务开始时,根据初始图像和用户指令,一次性 把高层任务拆成若干子任务,然后按这个计划往下执行。执行过程中,高层规划本身不持续接收反馈,也不负责判断"这一步到底做成没有"。如果中途环境变了、抓取失败了、某一步没放准,系统往往还是机械地继续往后跑,或者只能靠底层控制器自己"硬扛"。这正是传统很多"VLM 先出 plan,低层 policy 再执行"的范式。论文在 related work 里也把这类方法概括为:VLM 负责生成可解释子任务,随后由低层策略执行。
闭环 task decomposition :
不仅要"拆任务",还要把执行反馈重新接回高层规划 。也就是:
先规划;
执行当前子任务;
持续监控这一步是否真的完成;
如果没完成,或者执行偏了,就基于当前最新观测 重新规划。
这篇论文里的闭环,不是抽象口号,而是很具体的算法流程:Plan -> Execute -> Verify -> Replan。论文明确说运行时,RoboFarseer 同时扮演 planner 和 monitor 两个角色;在 monitored execution loop 中,低层控制器异步执行当前技能,而 VLM 以固定频率检查当前子任务是否完成;若失败,则抓取当前观测重新规划。
2)如何理解开放式问题和非开放式问题
"开放式 "最核心的意思其实是:不是给你几个候选计划让你选,而是让模型自己把完整计划生成出来。
论文在实验里明确把评测分成 MCQ(多选题) 和 open-ended question(开放式问题) 两类;在开放式评测中,模型必须自己生成 complete plans,而不是做判别式选择。
你可以先把它和"多选题规划"对照着理解:
多选题规划像这样:
"下面 4 个计划,哪个对?"
模型主要是在做识别。
开放式规划像这样:
"请你自己把这个任务拆成若干步,并按机器人可执行的格式写出来。"
模型这时做的是构造。
注意:
这篇论文里的"开放式" 不是完全无限制的自由生成 ,而是:
输入开放 + 输出生成式 + 语义上开放,但执行空间不是无限的,而是被机器人技能语法约束住的。
3)mcq与top-1 accuracy
**MCP:**Multiple-choice question:多选题
MCQ 规划评测:用的是 top-1 accuracy
论文在 planning benchmarks 上明确写的是 top-1 accuracy 。
也就是:给模型一个题目和候选答案,模型选出的第一答案是否等于标准答案,统计正确率。用于 LEAP-L(MCQ)、LEAP-U(MCQ)、ShareRobot-Planning、RoboVQA、EgoPlan-Bench2 等 benchmark。
这个指标测什么?
它测的是:
模型能不能在候选计划中,选出最合理的那个。
它的优点
容易比较不同模型,尤其是闭源模型,因为大家都可以统一做选择题。
它的局限
它不完全等价于"会自己规划"。
因为 MCQ 更多测的是判别能力,不是自由生成能力。模型有时并不会完整写出计划,但能从给定选项里挑对。所以这也是为什么论文专门又做了 open-ended 评测。这个局限是我对指标性质的解释,但和论文把 benchmark 分成 MCQ 与 open-ended 两类是一致的。
4)论文的方法用了 SFT 吗,还是只用了 RFT / RLVR?
RoboFarseer 的核心训练阶段是 RFT / RLVR(基于 verifiable reward 的强化微调),不是"论文先做了一轮专门的 planning SFT 再做 RL
不是"只用了纯 RL 从零训模型",而是"在 Qwen2.5-VL-7B 底座上,论文贡献的任务适配主要通过 RLVR/GRPO 完成,而不是额外报告一个 planning-SFT 阶段"
RLVR:可验证奖励的强化学习
5)基座模型
论文的核心 planner / monitor 模型是 Qwen2.5-VL-7B,也就是 约 70 亿参数 的视觉语言模型;作者把强化微调后的这个模型称为 RoboFarseer。
高层模型:RoboFarseer = fine-tuned Qwen2.5-VL-7B,负责 plan 和 verify。
低层模型:一个 diffusion policy 加 frozen language encoder 的控制策略,负责把单步技能落成动作。论文没有在这篇文里给出这个低层控制器的参数总量,所以通常大家说"这篇论文用了 7B 模型",指的是高层 VLM planner。
6)数据集
plain
UMI(上游采集框架/演示来源)
├─ 采集原子技能演示
│ └─ 自动标注引擎
│ └─ LEAP
│ ├─ LEAP-L:长时序顺序规划
│ └─ LEAP-U:指令对齐规划
│
└─ 另一路用于低层控制器训练
└─ diffusion policy + frozen language encoder
高层 planner 训练数据
= LEAP-L + LEAP-U + EgoPlan(训练集) + ShareRobot + ERQA
└─ 用 GRPO / RLVR 微调 Qwen2.5-VL-7B
└─ 得到 RoboFarseer
高层 planner 评测数据
├─ LEAP-L
├─ LEAP-U
├─ ShareRobot-Planning
├─ EgoPlan-Bench2
└─ RoboVQA
真实机器人执行
└─ RoboFarseer(planner + monitor)
+ 低层 controller
= 闭环执行系统| 类别 | 数据集 | 在论文里的作用 | 是否公开 |
|---|---|---|---|
| 上游来源 | UMI | 采集原子技能演示;也是低层控制器数据来源 | 是 (umi-gripper.github.io) |
| 核心自建 | LEAP(LEAP-L / LEAP-U) | 训练 + 评测核心数据 | 是 (huggingface) |
| 外部训练增强 | EgoPlan-IT | 高层 planner 训练 | 是,但底层视频需按原数据源规则获取 (GitHub) |
| 外部训练增强 | ShareRobot | 高层 planner 训练;其 planning 子集也用于评测 | 是 (GitHub) |
| 外部训练增强 | ERQA | 高层 planner 训练 | 是 (GitHub) |
| 评测 | EgoPlan-Bench2 | planning benchmark | 是,底层视频依赖 Ego4D/EPIC-Kitchens 体系 (GitHub) |
| 评测 | RoboVQA | planning + completion verification benchmark | 是 (RoboVQA) |
8)一个很重要的局限
这里你一定要看懂一个细节:
论文摘要里写的是"ordered bipartite matching overlap",但方法正文又明确说这个分数"稳健处理重排步骤"。这意味着,它并没有对顺序施加特别强的硬约束,至少从正文给出的匹配定义看,更强调的是"语义覆盖"而不是"严格位置一致"。
这会带来一个后果:
如果任务是"先拿杯子,再把杯子放托盘",而模型写成"先放杯子到托盘,再拿杯子",那么从严格执行逻辑上看,这明显不对;但如果只看步骤集合,它们可能仍然能匹配得不错。
也就是说,这个 reward 更像是在评估:
"你是否找到了正确的动作组件和目标对象?"
而不是严格评估:
"你是否按唯一正确的时序组织了这些动作?"
这也是它强大但不完美的地方。
7. 总结
这篇论文最值得肯定的地方,是它没有把"具身规划"停留在 benchmark 级别,而是完整回答了四个系统问题:
- 数据从哪来;
- 奖励怎么算;
- 模型怎么训;
- 真实机器人上怎么闭环跑。
如果用一句话总结 REVER,我会这样说:
它把长时程机器人规划重写成了一个受限技能语言上的程序生成问题,再用可验证奖励把 VLM 真正训练成了可部署的高层规划器。
从系统角度看,REVER 的完整闭环是:
- UMI 原子示教
- 自动构造 LEAP 数据
- 技能语法与二分图匹配奖励
- GRPO 强化微调
- 同一 VLM 兼任 planner 与 monitor
- 真实机器人闭环执行
这套设计的真正价值,不在于"又训练出一个会列步骤的大模型",而在于:
它第一次较完整地展示了,如何让 VLM 通过可验证奖励,进入真实机器人控制栈,并在闭环中承担高层规划职责。
当然,这篇论文也并非没有边界:
- 奖励函数更偏柔性全局对齐,而非严格因果顺序验证;
- 技能空间仍然依赖人工设计;
- 低层控制与感知仍是系统主要短板。
但即便如此,它仍然是当前"真实世界示教 + 可验证奖励 + 机器人闭环执行"这一交叉方向中非常重要的一步。
如果把未来方向再往前推,这篇论文自然引出的后续问题包括:
- 更大的技能词表;
- 更强的在线 reactive replanning;
- 双臂与移动操控;
- planner 与 low-level policy 的更紧耦合训练。
这也正是 REVER 最值得关注的地方:
它不是一个终点,而更像是一个方法论起点。
参考资料
- 论文 arXiv:https://arxiv.org/abs/2509.25852
- 论文 HTML:https://ar5iv.org/html/2509.25852v1
- LEAP 数据集:https://huggingface.co/datasets/zitong86/LEAP
- UMI GitHub:https://github.com/real-stanford/universal_manipulation_interface
- 论文公开镜像页(便于检索公开片段):https://www.researchgate.net/publication/396048560_Reinforced_Embodied_Planning_with_Verifiable_Reward_for_Real-World_Robotic_Manipulation