基本概念
VLA4AD
**VLA4AD 是"Vision-Language-Action for Autonomous Driving"(视觉-语言-行动自动驾驶)的缩写,它代表一种将大模型应用于自动驾驶的新范式:让车辆不仅能"看懂"路况,还能"听懂"语言指令,并直接做出驾驶动作。**它由清华大学、麦吉尔大学、威斯康星大学等团队在 2025 年提出,被视为自动驾驶与多模态大模型结合的前沿方向。
VLA4AD 的核心理念
-
视觉模块:通过摄像头、激光雷达等传感器获取环境信息,类似人类的"眼睛"。
-
语言模块:基于大型语言模型(LLM),理解自然语言指令,如"前面有救护车,让一让"。
-
行动模块:将视觉和语言信息转化为驾驶动作,包括方向盘转角、油门和刹车控制。
这种架构打破了传统的模块化设计(感知→预测→规划→控制),而是通过一个统一的模型实现"看、说、做"的闭环。
Vision-Action(VA)
直接视觉到行动,关键缺点: 黑盒(不可解释); 对分布变化敏感;无法理解语言或指令
VLA
随着大模型(LLM/VLM)发展,引入语言能力: 核心升级:视觉(看) + 语言(理解/推理) + 行动(驾驶)
VLM
VLM 通常指的是 Vision-Language Model(视觉-语言模型) 。它是把视觉信息(图像、视频、点云)和语言信息(文本、指令、描述)统一到一个模型里进行理解和推理的框架。
VLA的统一框架
典型 VLA 模型抽象为:
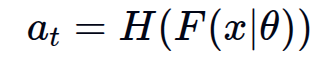
最终输出结果a_t 为t时刻的action
- x:多模态输入(视觉+语言+车辆状态)
- 传感器输入:前视/环视摄像头、LiDAR、雷达等;
- 中间表征:如鸟瞰图(BEV)特征、占据栅格;
- 语言指令:导航指令、规则说明、问答式提示等文本;
- 车辆状态:速度、加速度、转向角等;
- F:视觉-语言骨干 (VLM/LLM)
- 视觉编码器(如 ViT)将图像编码为特征;
- 语言解码器/LLM 接收视觉特征与文本 token,通过"桥接网络"完成模态对齐;
- 输出可用于推理和规划的多模态表示;
- H:动作预测头 , 负责将多模态特征转成具体动作,形式包括:
- 语言输出:如"保持车道"、"左转并减速"等;
- 回归式数值输出:如未来轨迹点、控制量(油门/方向盘);
- 轨迹候选选择或轨迹生成。
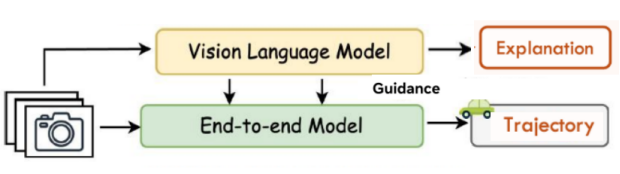
VLA两大主范式
End-to-End VLA(端到端VLA)
- 思想: 一个模型直接完成: 图像 → 推理 → 行动
- 特点: 强统一性 高表达能力 类似"驾驶大脑"
- 问题: 难训练 安全性难保证 实时性压力大

Dual-System VLA(双系统VLA)
- 思想(类人脑结构) 分成两部分:
- 慢系统(LLM/VLM): 推理、规划 类比人类思考
- 快系统(Planner/Controller): 实时执行 类比肌肉反应
- 优点 更安全 更可控 易工程化 中间接口怎么设计
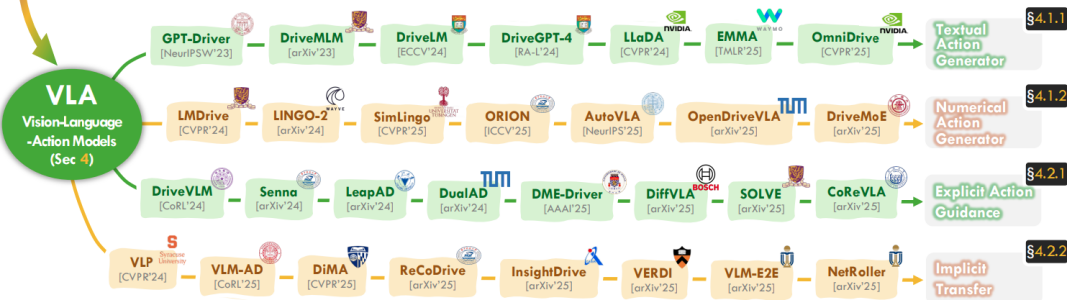
VLA动作生成方式
-
文本动作生成
-
输出是自然语言描述的动作,例如"向左转"、"减速"。
-
优点:可解释性强,便于人机交互。
-
技术:基于 GPT 系列或 DriveLM 等语言模型。
-
-
数值动作生成
-
输出是连续控制量,如方向盘角度、油门百分比。
-
优点:直接可用于控制车辆。
-
技术:强化学习、回归模型、MoE(Mixture of Experts)。
-
-
显式动作指导
-
模型在生成动作时,明确给出推理过程或中间解释。
-
优点:增强透明度,便于调试和安全验证。
-
技术:链式推理(CoT)、多模态融合。
-
-
隐式迁移
-
模型通过预训练或跨任务迁移,隐式学会驾驶策略。
-
优点:泛化能力强,能适应新场景。
-
技术:VLM-AD、ReCoDrive 等跨模态迁移方法。
-
关键点:
-
多样化输出形式:既可以是语言描述,也可以是数值控制,取决于应用场景。
-
可解释性与直接性权衡:文本更易解释,数值更直接控制。
-
研究趋势 :从单一模态到多模态,从显式推理到隐式迁移,逐步提升泛化与安全性。
-
应用启示:未来自动驾驶可能结合两种方式------既能用语言解释决策,又能输出精确数值控制。
文本动作(Textual Action)
- 元动作(Meta-Actions): "减速", "左转", "跟随前车"
- 文本化轨迹点(Trajectory Waypoints via Text): 再转成控制信号
- 优点: 可解释 可对齐人类指令
- 缺点: 精度有限
元动作示例:

文本化轨迹点示例:
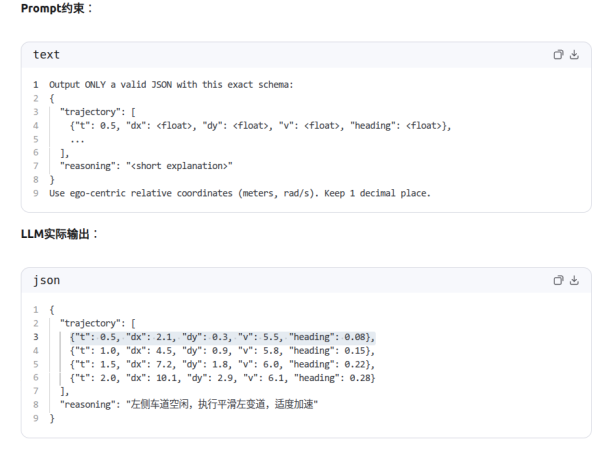
数值动作(Numerical Action)
- 额外动作head:
- 主干网络加head回归方式,输出轨迹或控制信号:
-
steering_angle, throttle, brake \] = \[0.12, 0.25, 0.00
- 额外动作token:
- 把各种轨迹或控制信号离散化一个个标准的动作token,
- " WP_10_35, WP_13_34, WP_16_33, TURN_LEFT, SPEED_20 "
- 优点:精确控制
- 缺点:不可解释
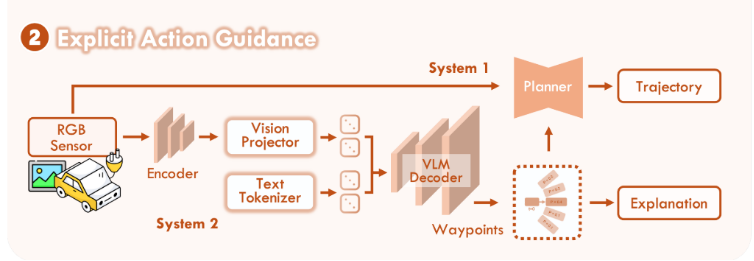
显式引导(Explicit)
- VLM 直接输出高层动作或航迹点,由快系统进一步细化
- 元动作引导: "减速","变道","左转"
- 轨迹点监督: 粗糙的轨迹航点
- 慢系统 直接告诉快系统应该做什么, 更接近传统规划系统
隐式引导(Implicit)
VLM 不在推理时输出行动,而是在训练阶段当"老师/辅助模块",
- 把自己的推理能力"压进"一个小而快的 E2E 模型里。
- 知识蒸馏 特征来自学生 E2E 模型自身的 latent 特征
- 多模态特征融合 一部分特征实时算,一部分特征VLM 提前算
目标:
- 把 VLM 的"懂语义、会推理"迁移给小模型
- 推理阶段只跑小模型,满足车载部署要求
- 保留 VLM 带来的可解释性和稳健性(相对显式方案会弱一些)
对比:
-
显式引导:VLM在推理时直接输出动作并解释,可解释性强,但算力消耗大。
-
隐式引导:VLM只在训练时做"老师",推理时不参与,解释性较弱一些,但仍比纯黑箱模型好。
-
这是一种折中方案:牺牲部分解释性,换取部署吸纳。
小模型会不会输出解释?
-
在隐式引导模式下,推理阶段只是运行小模型,其主要目标是生成驾驶动作(数值控制)。
-
小模型通常只输出动作,是否输出解释,取决于训练时有没有把"解释头"(Text Head )也给予小模型。
-
总体:
-
纯动作添加 →小模型只输出动作,不解释。
-
动作+解释→小模型可以同时计算食谱 →小模型可以同时输出能力表格和简单解释,但解释会比显式引导弱。
-
-
教师模型可以输出更详细的推理过程或解释,小模型在训练时通过修改这些输出,逐渐学会在没有明显式推理链的情况下也能得出正确的答案。
能力迁移:懂推理→会推理
-
这种方法叫做知识增加(知识蒸馏) 或推理增加(推理蒸馏)。
-
大模型的"理智推理"能力可以通过:
-
显着式增加 :直接把推理链作为训练数据的一部分。
-
隐式补充:只给小模型最终答案,但训练过程中利用教师模型的推理来调整梯度。
-
-
结果是,小模型在推理时可能不会输出完整的解释,但它的内部表示已经学会了某种"推理模式",因此能在更少的计算资源下做出合理的推断。
关键数据集与基准介绍
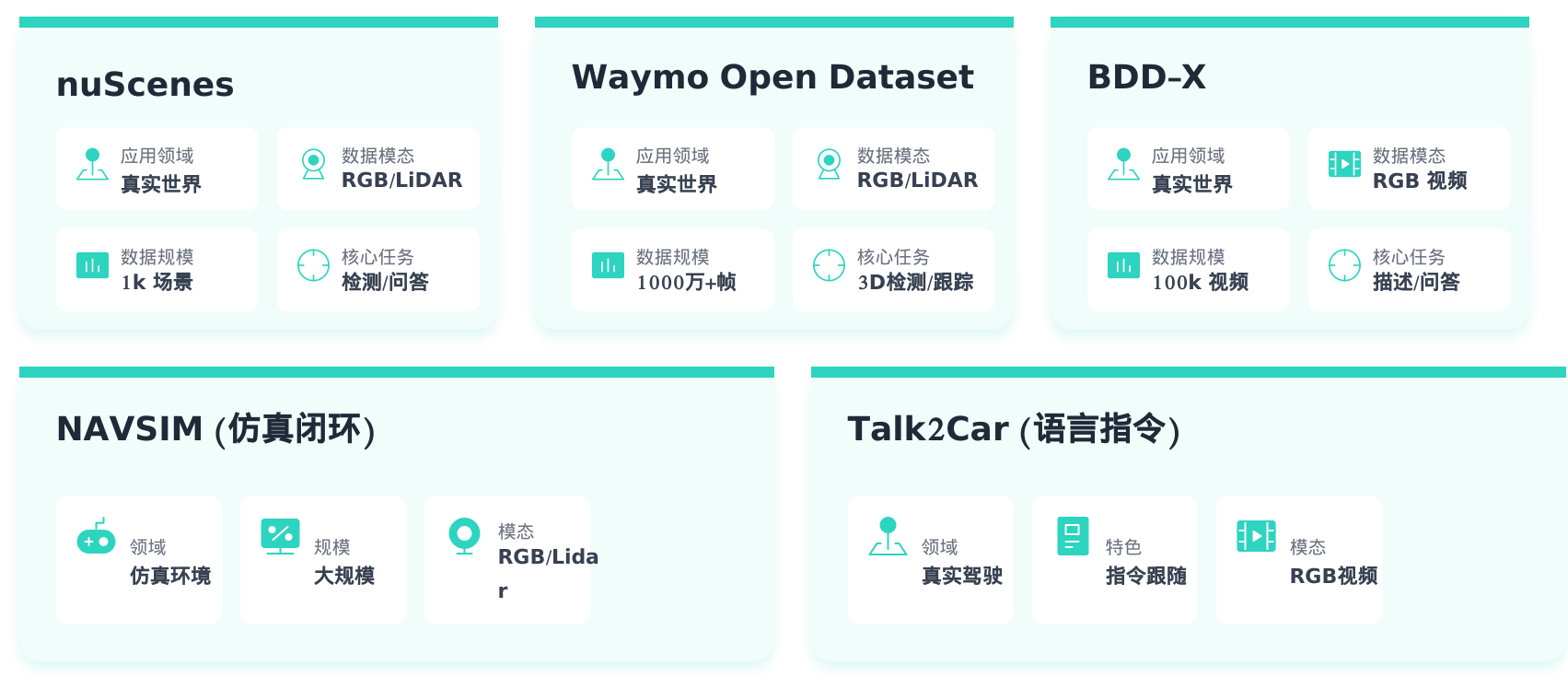
nuScenes
-
领域:真实世界
-
模态:RGB / LiDAR
-
规模:约1k场景
-
核心任务:检测、问答
-
特点 :提供多模式采集数据,适合研究自动驾驶场景下的多任务学习。
Waymo开放数据集
-
领域:真实世界
-
模态:RGB / LiDAR
-
规模:1000万+帧
-
核心任务:3D检测、跟踪
-
特点:数据量极大,覆盖多种驾驶环境,是研究大规模3D采集与跟踪的基准。
BDD-X
-
领域:真实世界
-
模式:RGB视频
-
规模:约100k视频
-
核心任务:描述、问答
-
特点:强调语言与结合,支持对驾驶场景的自然语言解释与交互。
NAVSIM(仿真闭环)
-
领域:仿真环境
-
模态:RGB / LiDAR
-
规模:规模
-
核心任务:仿真闭环
-
特点:提供可控的仿真环境,适合闭环决策研究与模拟训练。
Talk2Car
-
领域:真实驾驶
-
模式:RGB视频
-
核心任务:指令紧随
-
特点:突出语言指令与驾驶行为的结合,支持人机交互研究。