利用KNN算法分类鸢尾花
使用Conda来管理项目环境
为什么使用Conda来管理项目环境
-
在多个项目间切换时,不同的依赖版本很容易引发冲突,Conda可以为每一个项目单独创建一个环境,这个环境不受系统环境和Conda创建的其他环境的干扰。
-
pip(python自带的包管理工具)在下载非python编写的包时,只会下载这些包,而不会下载这些包的依赖,而Conda 会自动解析并安装这些非python所依赖的底层库,并把它们放到同一个环境目录下。
-
conda通过
conda env export命令将环境的完整配置导出为一个environment.yml文件,其他人只需要执行conda env create -f environment.yml命令,就能在你的项目环境中一键复现出一模一样的运行环境。 -
Conda 对 Windows、macOS 和 Linux 都提供了一致的体验你可以在不同操作系统间使用同一套
environment.yml文件,无缝还原开发环境,极大地降低了跨平台开发和团队协作的门槛。
Miniconda的下载和安装
Miniconda,Anaconda和Conda的区别
| 特性 | Miniconda | Anaconda | Conda 核心工具 |
|---|---|---|---|
| 定位 | 轻量级、灵活的发行版 | 全功能、预装大量科学包的发行版 | 包管理与环境管理工具 |
| 包含内容 | conda + Python + 几个核心依赖包 |
conda + Python + 超过1500个预装科学包 |
无独立安装包,是二者的核心组件 |
| 预装包 | 几乎为零 ,只有 pip, zlib 等极少数的必需包 |
超过1500个,含 NumPy, Pandas, Jupyter 等 | N/A |
| 安装包大小 | 非常小 (~50-100 MB) | 非常大 (~3 GB)) | N/A |
| 安装后占用 | 低 (~几百 MB) | 高 (可达 10 GB+) | N/A |
| 目标用户 | 有经验的开发者、追求极致灵活和轻量的用户 | 新手、希望快速搭建完整数据科学环境的用户 | N/A |
| 是否包含图形界面 | 否,主要通过命令行操作 | 是 ,提供 Anaconda Navigator 图形界面 |
N/A |
这里我们只展示Miniconda使用
Miniconda的安装
并配置环境变量
下载完成后再powershell中输入conda --version,输出版本号Miniconda就安装完成
Miniconda的基本使用
1. 更换 Channel 源(解决下载慢问题)
Conda 默认使用国外源,国内用户建议换成清华源或中科大源,能大幅提升下载速度。
bash
# 添加清华源(主通道、免费通道、conda-forge)
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/2. 创建环境
bash
# 基本语法:conda create -n 环境名 python=版本号
conda create -n myenv python=3.9
# 创建时同时安装多个包
conda create -n myenv python=3.9 numpy pandas matplotlib
# 指定包版本
conda create -n myenv python=3.8 numpy=1.213. 激活环境
bash
conda activate myenv4. 查看当前激活的环境
bash
conda info --envs # 列表前带 * 号的为当前环境
# 或
conda env list5. 退出当前环境
bash
conda deactivate6. 在激活的环境下安装库
激活环境后,安装的包只属于该环境,不影响其他环境。
bash
# 安装单个包
conda install numpy
# 安装多个包
conda install numpy pandas matplotlib
# 指定版本
conda install numpy=1.21.0在Vscode中使用创建的环境来运行项目
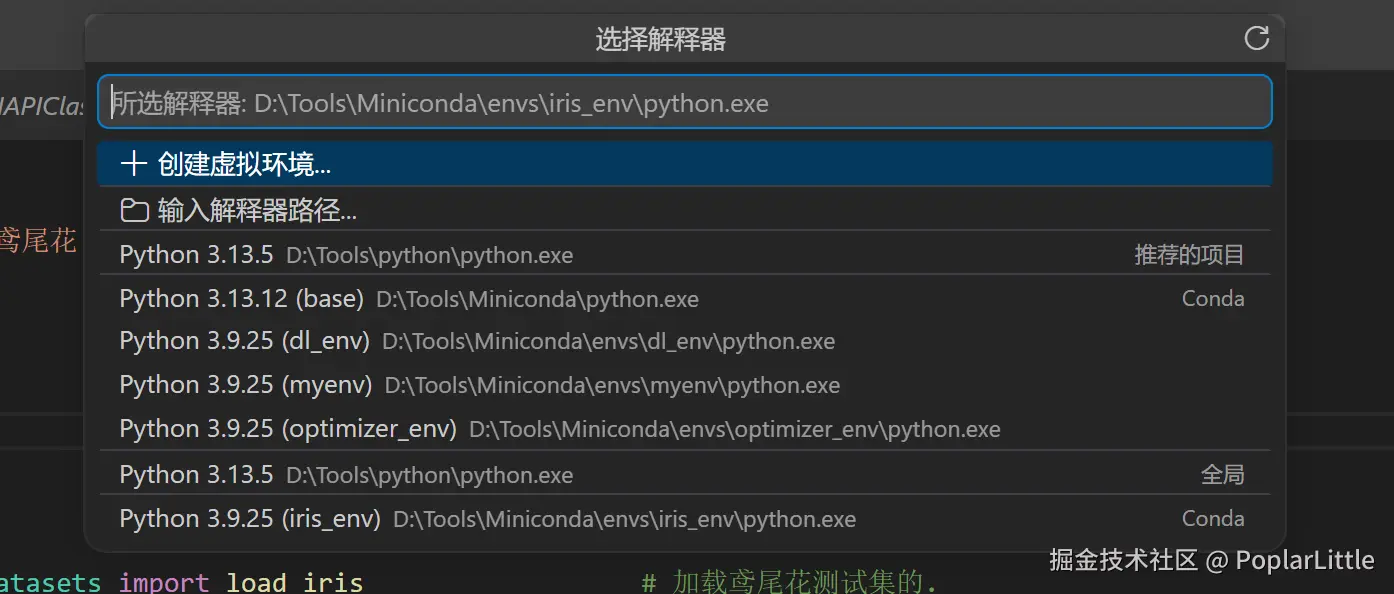
输入Python:Select Interpreter 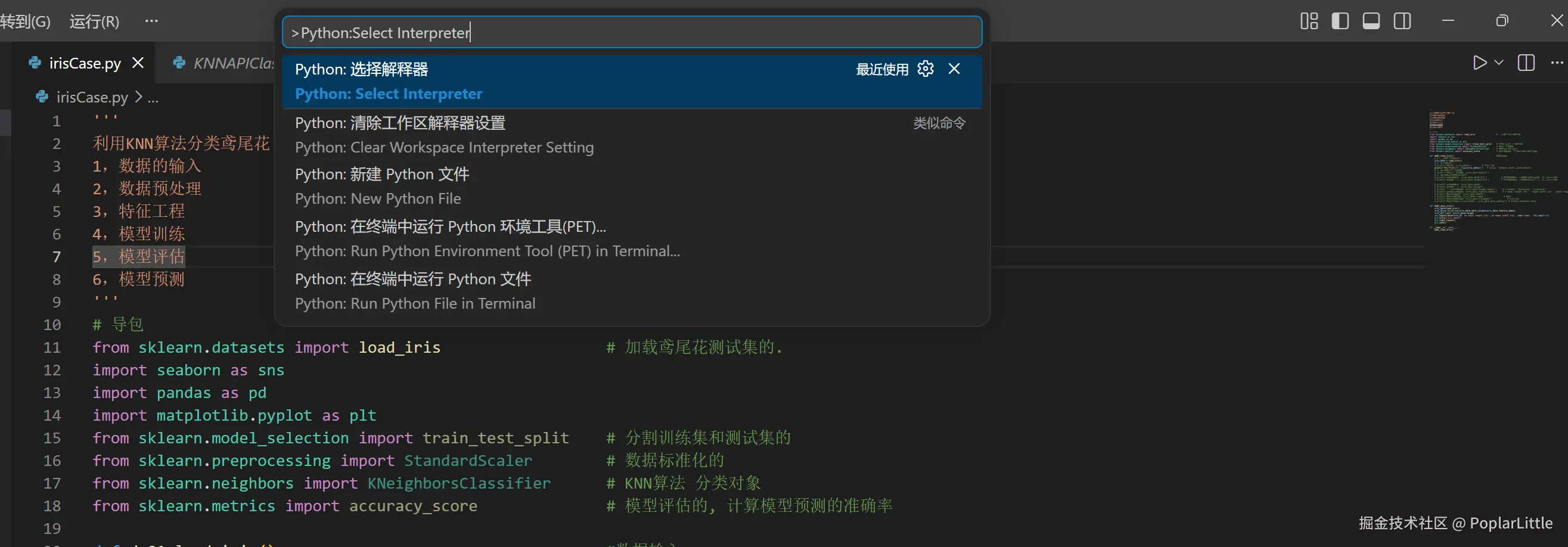 选择你为这个项目创建的环境的名字
选择你为这个项目创建的环境的名字
鸢尾花案例
创建项目环境
bash
conda create -n iris_case python=3.9 scikit-learn seaborn pandas matplotlib数据集的数据结构
python
def dm01_load_iris(): #数据输入
# 1. 加载鸢尾花数据集.
iris_data = load_iris()iris_data=load_iris()有复杂的数据结构,下面我们来一一讨论
-
打印数据集的所有的键
pythonprint(f'数据集所有的键: {iris_data.keys()}')数据集的所有键
bashdict_keys(['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names', 'filename', 'data_module']) -
data:
pythonprint(f'具体的数据: {iris_data.data}')//打印所有数据打印一个150*4的矩阵,每一列代是一个样本的特征,每一行是一个特征
这里展示前5个样本
bash具体的数据: [[5.1 3.5 1.4 0.2] [4.9 3. 1.4 0.2] [4.7 3.2 1.3 0.2] [4.6 3.1 1.5 0.2] [5. 3.6 1.4 0.2]] -
target:
pythonprint(f'具体的标签: {iris_data.target}')//打印所有的标签打印一个1*150的矩阵,每一列是列号对应样本矩阵的行号的标签的编号(这个案例的编号是0,1,2对应于不同的鸢尾花)
-
frame:
内容:通常为
None,除非在加载时指定as_frame=True。pythoniris_data=load_iris(as_frame=True) # 返回的 Bunch 中 frame 是一个 DataFrame用途:如果希望直接获得
pandas.DataFrame形式的数据(特征+标签合并),可以设置as_frame=True,此时frame就是完整的数据表。 -
target_names:
pythonprint(f'标签对应的名称: {iris_data.target_names}')//打印标签名打印一个1*4的矩阵,每一列是列号对应的标签编号的标签的名称
bash标签对应的名称: ['setosa' 'versicolor' 'virginica'] -
DESCR:
pythonprint(f'数据集的描述: {iris_data.DESCR}')//数据集的详细描述包含数据集的详细描述来源、样本数、特征说明、类别分布、引用
-
feature_names:
pythonprint(f'特征对应的名称: {iris_data.feature_names}')\\打印特征名和data关联
bash特征对应的名称: ['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)'] -
filename:
pythonprint(f'数据集的文件名: {iris_data.filename}')bash数据集的文件名: iris.csv -
data_module:
pythonprint(f'数据集的模型(在哪个包下): {iris_data.data_module}')bash数据集的模型(在哪个包下): sklearn.datasets.data
绘制数据集的散点图
python
def dm02_show_iris():
# 1. 加载数据集.
iris_data = load_iris()
# 2. 把 鸢尾花数据集封装成 DataFrame对象.
iris_df = pd.DataFrame(iris_data.data, columns=iris_data.feature_names)
# 3. 给df对象新增1列 -> 标签列.
iris_df['label'] = iris_data.target
# print(iris_df)
# 4. 通过 Seaborn绘制散点图.
# 参1: 数据集. 参2: x轴. 参3: y轴. 参4: 分组字段. 参5: 是否显示拟合线.
sns.lmplot(data=iris_df, x='sepal length (cm)', y='sepal width (cm)', hue='label', fit_reg=True)
# 5. 设置标题, 显式.
plt.title('iris data')
plt.tight_layout() # 自动调整子图参数, 以使整个图像的边界与子图匹配.
plt.show()-
封装成DataFrame对象
python# 2. 把 鸢尾花数据集封装成 DataFrame对象. iris_df = pd.DataFrame(iris_data.data, columns=iris_data.feature_names) # 3. 给df对象新增1列 -> 标签列. iris_df['label'] = iris_data. print(iris_df)bashsepal length (cm) sepal width (cm) petal length (cm) petal width (cm) label 0 5.1 3.5 1.4 0.2 0 1 4.9 3.0 1.4 0.2 0 2 4.7 3.2 1.3 0.2 0 3 4.6 3.1 1.5 0.2 0 4 5.0 3.6 1.4 0.2 0 .. ... ... ... ... ... 145 6.7 3.0 5.2 2.3 2 146 6.3 2.5 5.0 1.9 2 147 6.5 3.0 5.2 2.0 2 148 6.2 3.4 5.4 2.3 2 149 5.9 3.0 5.1 1.8 2 [150 rows x 5 columns]所以相比于
iris_data.data,iris_df添加了样本的序号,样本的特征名,样本的标签和名称。这里提到的
DataFrame对象和上面提到的DataFrame对象是差不多的pythoniris_data=load_iris(as_frame=True) iris_df=iris_data.frame但是由于
iris_data.frame的标签列的名字默认是target,也可以选择修改一下标签列的名称。pythoniris_data=load_iris(as_frame=True) iris_df=iris_data.frame.rename(columns={'target': 'label'}) -
通过Seaborn绘制散点图
pythonsns.lmplot(data=iris_df, x='sepal length (cm)', y='sepal width (cm)', hue='label', fit_reg=True)-
绘制带拟合线的散点图:使用 Seaborn 的
lmplot函数。-
data=iris_df:指定数据来源。 -
x='sepal length (cm)':横坐标为花萼长度。 -
y='sepal width (cm)':纵坐标为花萼宽度。 -
hue='label':根据label列(即类别)将数据点着以不同颜色,并自动生成图例。 -
fit_reg=True:为每个类别单独拟合一条线性回归线(散点图上的直线),用于展示两个变量之间的关系趋势。 -
该函数会创建一个
FacetGrid对象,并在当前图形上绘制散点图和回归线。
-
这里为什么不需要给这个对象取名,不然后面设置标题,调整布局的时候程序怎么知道是对哪一个对象的?
不需要取名:因为 Matplotlib 内部维护了"当前图形/坐标轴"的栈,pyplot函数默认操作当前对象,而lmplot会更新当前对象。建议取名:当需要后续精细控制图形时,保存返回值并显式操作,避免状态机带来的隐式依赖。
取名的版本:
pythong = sns.lmplot(data=iris_df, x='sepal length (cm)', y='sepal width (cm)', hue='label', fit_reg=True) g.fig.suptitle('iris data') g.fig.tight_layout() plt.show()这里的
plt.show()为什么没有指定哪个对象显示?
plt.show()的作用是显示所有当前已创建的 Matplotlib 图形(Figure 对象)。也可以显式调用g.fig.show(),但plt.show()是更通用的做法,尤其当只有一个图形时,两者效果相同。pythonplt.title('iris data') plt.tight_layout() plt.show()plt.title('iris data')设置标题。tight_layout()会自动调整子图(或图形)的边距和间距,避免标题、轴标签、图例等元素重叠或溢出边界,使图形显示更紧凑美观。plt.show()显示图像 -
切分训练集和测试集
python
def dm03_split_train_test():
# 1. 加载数据集.
iris_data = load_iris()
# 2. 数据的预处理: 从150个特征和标签中, 按照 8:2的比例, 切分训练集和测试集.
# 参1: 特征数据. 参2: 标签数据. 参3: 测试集的比例. 参4: 随机种子(种子一致, 每次生成的随机数据集都是固定的)
# 返回值: 训练集的特征数据, 测试集的特征数据, 训练集的标签数据, 测试集的标签数据.
x_train, x_test, y_train, y_test = train_test_split(iris_data.data, iris_data.target, test_size=0.2, random_state=23)
# 3. 打印切割后的结果.
print(f'训练集的特征: {x_train}, 个数: {len(x_train)}') # 120条, 每条4列(特征)
print(f'训练集的标签: {y_train}, 个数: {len(y_train)}') # 120条, 每条1列(标签)
print(f'测试集的特征: {x_test}, 个数: {len(x_test)}') # 30条, 每条4列(特征)
print(f'测试集的标签: {y_test}, 个数: {len(y_test)}') # 30条, 每条1列(标签)-
切分训练集和测试集
pythonx_train, x_test, y_train, y_test = train_test_split(iris_data.data, iris_data.target, test_size=0.2, random_state=23)x_train训练集特征x_test测试集特征y_train训练集标签y_test测试集标签iris_data.data添加数据集的特征iris_data.target添加数据集的标签test_size=0.2测试集/数据集=0.2random_state=23随机种子,是拆分训练集和测试集的规则,当种子固定时每次拆分就都是固定的
机器学习流程
python
def dm04_iris_evaluate_test():
# 1. 加载数据集.
iris_data = load_iris()
# 2. 数据的预处理, 这里是把150条数据, 按照 8:2的比例, 切分训练集和测试集.
x_train, x_test, y_train, y_test = train_test_split(iris_data.data, iris_data.target, test_size=0.2, random_state=23)
# 3. 特征工程(提取, 预处理...)
# 思考1: 特征提取: 因为源数据只有4个特征列, 且都是我们用的, 所以这里无需做特征提取.
# 思考2: 特征预处理: 因为源数据的4列特征差值不大, 所以我们无需做特征预处理, 但是, 加入特征预处理会让我们的代码更完善, 所以加入.
# 3.1 创建标准化对象.
transfer = StandardScaler()
# 3.2 对特征列进行标准化, 即: x_train: 训练集的特征数据, x_test: 测试集的特征数据.
# fit_transform: 兼具fit和transform的功能, 即: 训练, 转换. 该函数适用于: 第一次进行标准化的时候使用. 一般用于处理: 训练集.
x_train = transfer.fit_transform(x_train)
# transform: 只有转换. 该函数适用于: 重复进行标准化动作时使用, 一般用于对测试集进行标准化.
x_test = transfer.transform(x_test)
# 4. 模型训练.
# 4.1 创建模型对象.
estimator = KNeighborsClassifier(n_neighbors=3)
# 4.2 具体的训练模型的动作.
estimator.fit(x_train, y_train) # 传入: 训练集的特征数据, 训练集的标签数据
# 5. 模型预测.
# 场景1: 对刚才切分的 测试集(30条) 进行测试.
# 5.1 直接预测即可, 获取到: 预测结果
y_pre = estimator.predict(x_test) # x_test: 测试集的特征数据
# 5.2 打印预测结果.
print(f'预测值为: {y_pre}')
# 场景2: 对新的数据集(源数据150条 之外的数据) 进行测试.
# 5.1 自定义测试数据集.
my_data = [[7.8, 2.1, 3.9, 1.6]]
# 5.2 对数据集进行标准化处理.
my_data = transfer.transform(my_data)
# 5.3 模型预测.
y_pre_new = estimator.predict(my_data)
print(f'预测值为: {y_pre_new}')
# 5.4 查看上述数据集, 每种分类的预测概率.
y_pre_proba = estimator.predict_proba(my_data)
print(f'(各分类)预测概率为: {y_pre_proba}') # [[0, 0.66666667, 0.33333333]] -> 0分类的概率, 1分类的概率, 2分类的概率.
# 6. 模型评估.
# 方式1: 直接评分, 基于: 测试集的特征 和 测试集集的标签.
print(f'正确率(准确率): {estimator.score(x_test, y_test)}') # 0.9666666666666667
# 方式2: 基于 测试集的标签 和 预测结果 进行评分.
print(f'正确率(准确率): {accuracy_score(y_test, y_pre)}') # 0.9666666666666667-
加载数据
pythoniris_data = load_iris() -
数据预处理
pythonx_train, x_test, y_train, y_test = train_test_split(iris_data.data, iris_data.target, test_size=0.2, random_state=23)把数据集拆分为训练集和测试集,测试集数量/数据集数量=0.2。
-
特征工程
pythontransfer = StandardScaler()//创建标准化对象 x_train = transfer.fit_transform(x_train)//把训练集数据列转化为一个均值为0,标准差为1的标准正态分布 x_test = transfer.transform(x_test)//把测试集数据列进行训练集数据列一样的操作为什么要把训练集的数据列转化为均值为0,标准差为1的标准正态分布?
因为有些特征的单位或大小相差(如身高和体重,身高一般都是大于150cm的而体重大部分小于100kg)较大,或者某特征的方差相比其他的特征要大出几个数量级,容易支配目标结果,使一些模型无法学习到其他特征。
为什么要对测试集的数据列进行和训练集数据列一样的操作?首先看看训练集数据列进行了什么操作:
-
算这个数据列的均值b和标准差c
-
数据列的每一个数据a,a=(a-b)/c
然后看
transfer.transform(x_test)做了什么操作,对x_test的对应数据列的每一个数据d,d=(d-b)/c。这里的目的是什么:对训练集和测试集进行同样的平移和拉伸,使训练集和测试集各个数据行的列数据相对距离不会改变。
-
-
模型训练
pythonestimator = KNeighborsClassifier(n_neighbors=3) estimator.fit(x_train, y_train) -
模型预测
pythony_pre = estimator.predict(x_test) print(f'预测值为: {y_pre}') my_data = [[7.8, 2.1, 3.9, 1.6]] my_data = transfer.transform(my_data)//进行标准化处理 y_pre_new = estimator.predict(my_data) print(f'预测值为: {y_pre_new}') y_pre_proba = estimator.predict_proba(my_data) print(f'(各分类)预测概率为: {y_pre_proba}') -
模型评估
pythonprint(f'正确率(准确率): {estimator.score(x_test, y_test)}') print(f'正确率(准确率): {accuracy_score(y_test, y_pre)}')