强烈推荐的更好的阅读体验
Perceptron
Linear Classifiers
我们在上次的Note19中提及到了Naive Bayes中的提取feature的思想,我们在这里尝试把一个数据点的所有特征提取出来,提取成为一个向量的形式
text
f(x) = [f1(x), f2(x), ..., fn(x)]与之对应的,每个feature还有一个权重
text
w = [w1, w2, ..., wn]线性分类器的基本思想是利用特征的线性组合来进行分类,我们把这个值叫做激活值激活函数之前的值即activation 。具体公式如下
activation w ( x ) = h w ( x ) = ∑ i w i f i ( x ) = w ⊤ f ( x ) = w ⋅ f ( x ) \large \begin{align*} \text{activation}_w(x) &= h_w(x) = \sum_i w_i f_i(x) = \mathbf{w}^\top \mathbf{f}(x) = \mathbf{w}\cdot\mathbf{f}(x) \end{align*} activationw(x)=hw(x)=i∑wifi(x)=w⊤f(x)=w⋅f(x)
我们来着重看一下 h w ( x ) h_w(x) hw(x)这个值:
如果我们只有两个lable,可以回忆一下之前提及到的垃圾邮件的例子,这就是只有两个标签--只有ham和spam。
- 这时候 h w ( x ) h_w(x) hw(x)如果为正,我们就把数据点标记为正类。
- 如果 h w ( x ) h_w(x) hw(x)值为负,我们就把数据点标记为负类
Decision Boundary
我们用数学的角度来看一下 h w ( x ) h_w(x) hw(x)的值:
h w ( x ) = w ⋅ f ( x ) = ∥ w ∥ ∥ f ( x ) ∥ cos ( θ ) \begin{align*} h_{\mathbf{w}}(\mathbf{x}) &= \mathbf{w}\cdot\mathbf{f}(\mathbf{x}) = \|\mathbf{w}\|\;\|\mathbf{f}(\mathbf{x})\|\cos(\theta) \end{align*} hw(x)=w⋅f(x)=∥w∥∥f(x)∥cos(θ)
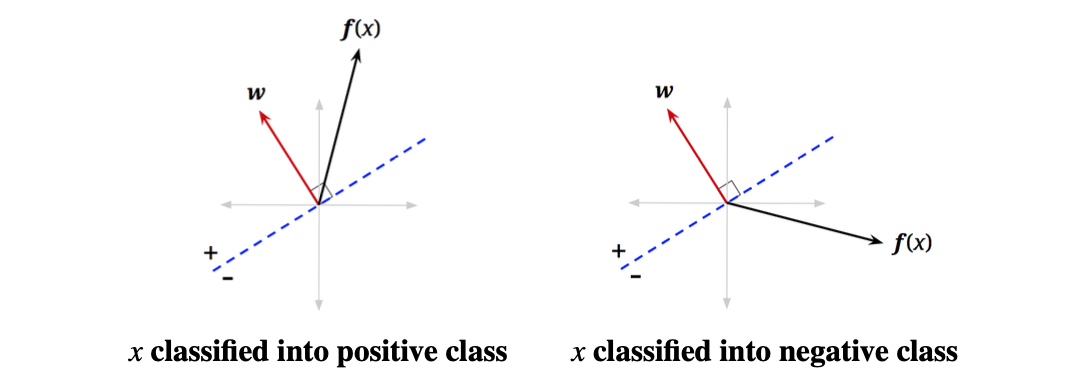
看最后一串,决定 h w ( x ) h_w(x) hw(x)值正负的是cosθ,因为两个向量的模是正的。也就是说
classify ( x ) = { + if θ < π 2 − if θ > π 2 \large \begin{align*} \text{classify}(\mathbf{x}) &= \begin{cases} +& \text{if }\ \theta < \dfrac{\pi}{2}\\6pt -&\text{if }\ \theta > \dfrac{\pi}{2} \end{cases} \end{align*} classify(x)=⎩ ⎨ ⎧+−if θ<2πif θ>2π
我们已知了向量w,那我们是不是可以画一条与向量w垂直的虚线,任何位于这条线上的特征向量其 h w ( x ) h_w(x) hw(x)的值都为0,即满足式子 w T f ( x ) = 0 \mathbf{w}^T\mathbf{f}(\mathbf{x}) = 0 wTf(x)=0,我们把这条线叫做决策边界即Decision Boundary
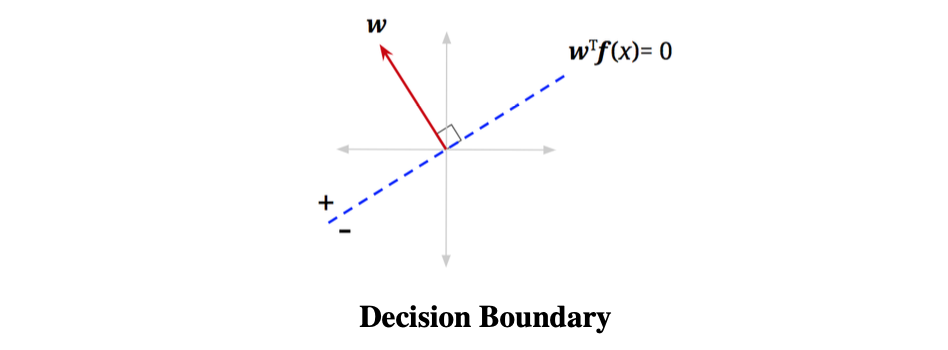
我们可以根据决策边界来判断 h w ( x ) h_w(x) hw(x)的值
Binary Perceptron
二分类感知机是一个简单的线性分类器,它的目的是为了找到一个权重向量w让训练集中的样本都可以正确分类。
Perceptron Algorithm
text
1. Initialize weights: w = 0
2. For each training example (x, y*):
a. Compute prediction:
y = classify(x)
b. If y == y*, do nothing
c. If y != y*, update weights:
w ← w + y* f(x)
3. Repeat until all samples are classified correctly in one pass其中:
y*是真实的labley是模型预测的lablef(x)是样本特征向量
算法正确性验证
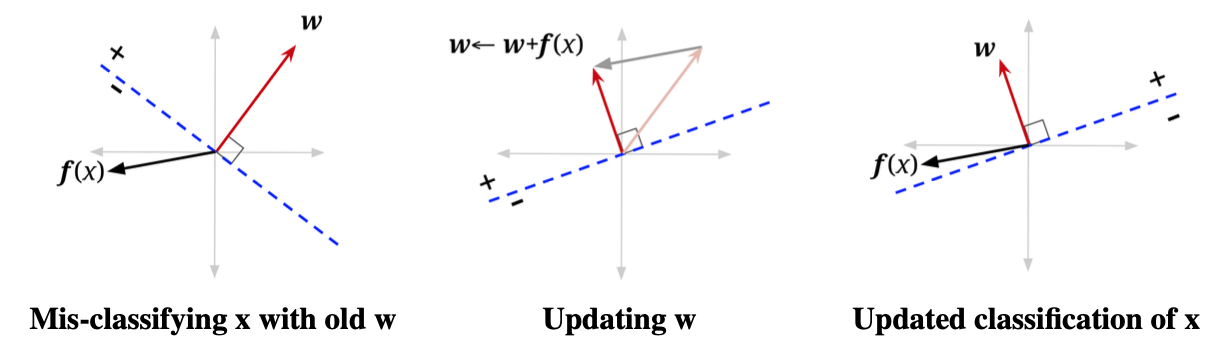
核心的更新规则就是 w ← w + y ∗ f ( x ) w ← w + y^* f(x) w←w+y∗f(x)
1.我们假设 y ∗ = 1 y^* = 1 y∗=1, y = − 1 y = -1 y=−1。即原本为正类的数据点被分错分到负类里去了
2.我们可以推断的是:当前的 h w ( x ) h_w(x) hw(x)是偏小的,我们期望是让 h w ( x ) h_w(x) hw(x)变大
3.更新后的权重为
w ′ = w + f ( x ) \large \begin{align*} w' &= w + f(x) \end{align*} w′=w+f(x)
4.更新后的激活值为
h w ′ ( x ) = ( w + f ( x ) ) T f ( x ) = w T f ( x ) + f ( x ) T f ( x ) = h w ( x ) + f ( x ) T f ( x ) \large \begin{align*} h_{w'}(x) &= (w + f(x))^{T} f(x) = w^{T} f(x) + f(x)^{T} f(x) = h_w(x) + f(x)^Tf(x) \end{align*} hw′(x)=(w+f(x))Tf(x)=wTf(x)+f(x)Tf(x)=hw(x)+f(x)Tf(x)
5.因为
f ( x ) T f ( x ) ≥ 0 \large \begin{align*} f(x)^Tf(x) \ge 0 \end{align*} f(x)Tf(x)≥0
即激活值会变大,这也就表明了这种更新法则是符合我们的预期--让 h w ( x ) h_w(x) hw(x)变大
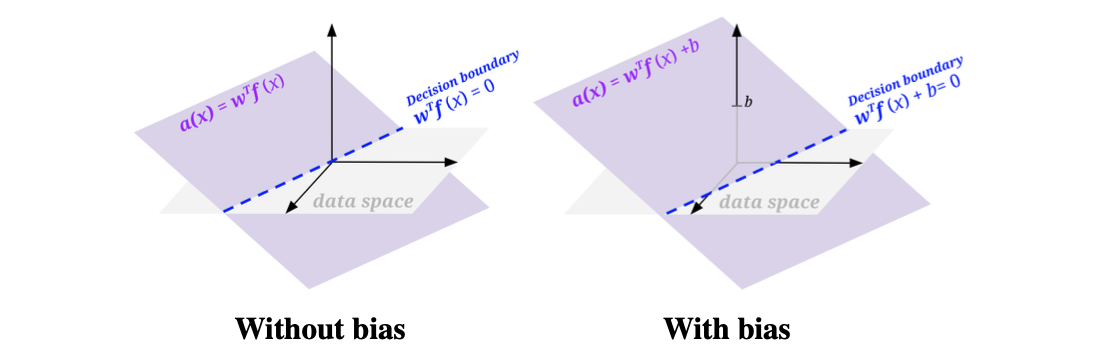
Bias
如果我们的决策边界模型只有 w T f ( x ) w^Tf(x) wTf(x),那么我们的决策边界就必须经过原点,这非常限制模型的能力,因为很多不同lable的数据点虽然能被一条直线分开,但那条直线不一定经过原点。我们就参考着一次函数的样式加入了bias term,让它变成
w T f ( x ) + b = 0 \large \begin{align*} w^{T} f(x) + b &= 0 \end{align*} wTf(x)+b=0
实现方法通常是给每个特征向量额外加一个恒等于1的feature,然后通过控制权重w来控制大小,这样模型仍然可以写成点积的形式:
h w ( x ) = w T f ( x ) \large \begin{align*} h_w(x) &= w^{T} f(x) \end{align*} hw(x)=wTf(x)
Multiclass Perceptron
多个类别的和binary非常类似,如果有K个lable,那么就有K个权重。与二分类感知机对应的是,二分类感知机只有一个权重,因为可以用正负来区别两个lable.
对于输入样本,计算它的每个lable的score:
score k = w k T f ( x ) \large \begin{align*} \text{score}_k &= w_k^{\!T}\, f(x) \end{align*} scorek=wkTf(x)
选择分数最高的lable:
y ^ = arg max k w k T f ( x ) \large \begin{align*} \hat{y} &= \arg\max_{k} w_k^{T} f(x) \end{align*} y^=argkmaxwkTf(x)
多分类感知机更新规则
同样的:
y*是真实的并且正确的labley是被错误预测的lablef(x)是样本特征向量
那么就可以得到:
w y ∗ ← w y ∗ + f ( x ) w y ← w y − f ( x ) \large \begin{align*} w_{y^*} &\leftarrow w_{y^*} + f(x)\\ w_{y} &\leftarrow w_{y} - f(x) \end{align*} wy∗wy←wy∗+f(x)←wy−f(x)
给正确类别的权重加上这个样本,给错误类别减去这个样本
Linear Regression
和前面不同的是:
Regression预测的是连续的数值,比如房价温度销量等等Classification预测的是类别
和前面相同的是:- 模型相同,即权重和特征向量的格式相同
特征向量是
x = 1 , x 1 , x 2 , ... , x n \large \begin{align*} x &= 1, x_1, x_2, \\dots, x_n \end{align*} x=1,x1,x2,...,xn
对应的权重也是和之前的格式,注意特征向量的第一项1是bias term,那么我们可以得到 h w ( x ) h_w(x) hw(x)为:
h w ( x ) = w 0 + w 1 x 1 + w 2 x 2 + ⋯ + w n x n = w T x \large \begin{align*} h_w(x) &= w_0 + w_1 x_1 + w_2 x_2 + \cdots + w_n x_n = \mathbf{w}^T\mathbf{x} \end{align*} hw(x)=w0+w1x1+w2x2+⋯+wnxn=wTx
L2 Loss
训练线性回归时,我们希望预测值接近真实值
对于第 j 个样本:
error j = y j − h w ( x j ) \large \begin{align*} \text{error}_j &= y_j - h_w(x_j) \end{align*} errorj=yj−hw(xj)
L2 Loss是误差平方:
( y j − h w ( x j ) ) 2 \large \begin{align*} (y_j - h_w(x_j))^2 \end{align*} (yj−hw(xj))2
整个训练集上的loss:
L o s s ( h w ) = 1 2 ∑ j = 1 N ( y j − h w ( x j ) ) 2 \large \begin{align*} Loss(h_w)\; &=\; \frac{1}{2}\sum_{j=1}^{N}\big(y_j - h_w(x_j)\big)^2 \end{align*} Loss(hw)=21j=1∑N(yj−hw(xj))2
前面加上1/2是为了求导时抵消平方项前面的2,让整体公式更加整洁
Matrix Form矩阵形式
将所有的训练样本堆起来:
y = y 1 y 2 ⋮ y N \large \begin{align*} \mathbf{y} &= \begin{bmatrix} y_1\\4pt y_2\\4pt \vdots\\4pt y_N \end{bmatrix} \end{align*} y= y1y2⋮yN
设计矩阵:
X = 1 x 1 1 ⋯ x n 1 1 x 1 2 ⋯ x n 2 ⋮ ⋮ ⋱ ⋮ 1 x 1 N ⋯ x n N \large \begin{align*} \mathbf{X} &= \begin{bmatrix} 1 & x_{1}^{1} & \cdots & x_{n}^{1} \\ 1 & x_{1}^{2} & \cdots & x_{n}^{2} \\ \vdots & \vdots & \ddots & \vdots \\ 1 & x_{1}^{N} & \cdots & x_{n}^{N} \end{bmatrix} \end{align*} X= 11⋮1x11x12⋮x1N⋯⋯⋱⋯xn1xn2⋮xnN
权重为:
w = w 0 w 1 ⋮ w n \large \begin{align*} \mathbf{w} &= \begin{bmatrix} w_0\\4pt w_1\\4pt \vdots\\4pt w_n \end{bmatrix} \end{align*} w= w0w1⋮wn
那么loss可以写成:
Loss ( h w ) = 1 2 ∥ y − X w ∥ 2 2 \large \begin{align*} \operatorname{Loss}(h_w) &= \tfrac{1}{2}\left\lVert \mathbf{y} - \mathbf{X}\mathbf{w} \right\rVert_2^2 \end{align*} Loss(hw)=21∥y−Xw∥22
线性回归最重要的一个特点是它有闭式解( closed-form solution )
我们对loss求梯度:
∇ w 1 2 ∥ y − X w ∥ 2 2 = − X T y + X T X w \large \begin{align*} \nabla_w \frac{1}{2}\|y - Xw\|_2^2 &= -X^{T}y + X^{T}Xw \end{align*} ∇w21∥y−Xw∥22=−XTy+XTXw
令梯度为0:
X T X w = X T y \large \begin{align*} X^{T} X w &= X^{T} y \end{align*} XTXw=XTy
如果 X T X X^TX XTX可逆的话,那么就可以得到:
w ^ = ( X ⊤ X ) − 1 X ⊤ y \large \begin{align*} \hat{\mathbf{w}} &= (X^\top X)^{-1} X^\top \mathbf{y} \end{align*} w^=(X⊤X)−1X⊤y
Logistic Regression
Logistic Regression用logistic function把线性模型输出转成概率,需要注意的是
Logistic Regression名字里有regression,但它主要用于classification
Logistic Function / Sigmoid Function
Logistic Function:
g ( z ) = 1 1 + e − z \large \begin{align*} g(z) &= \frac{1}{1+e^{-z}} \end{align*} g(z)=1+e−z1
其中
z = w T x \large \begin{align*} z &= \mathbf{w}^{T} \mathbf{x} \end{align*} z=wTx
h w ( x ) = 1 1 + e − w T x . \large \begin{align*} h_{\mathbf{w}}(\mathbf{x}) &= \frac{1}{1 + e^{-\mathbf{w}^T \mathbf{x}}}. \end{align*} hw(x)=1+e−wTx1.
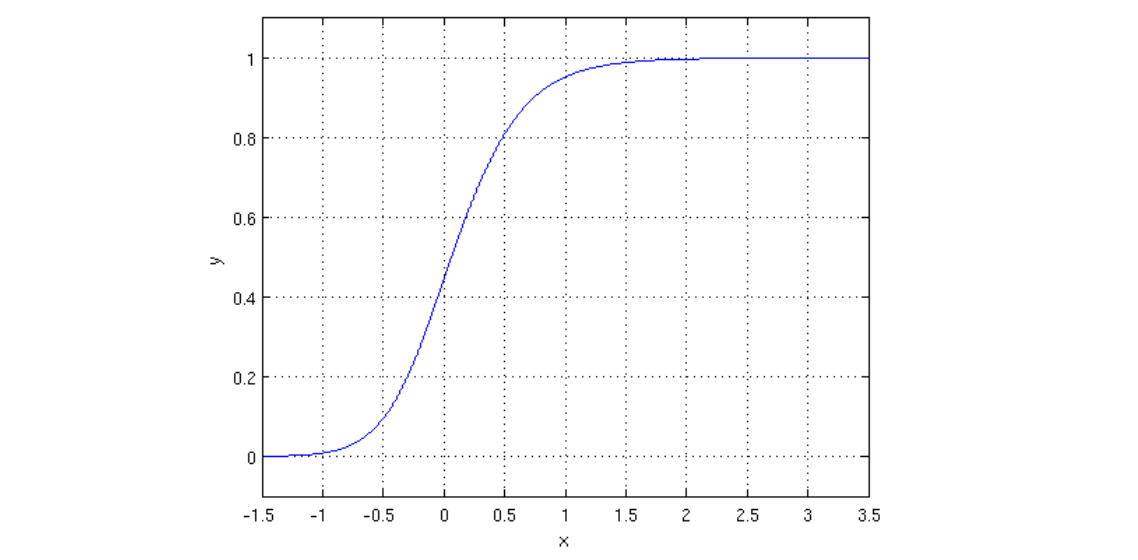
它的输出一定在0到1之间,因此可以解释为:
当 h w ( x ) > 0.5 h_w(x) > 0.5 hw(x)>0.5时预测为正类,下面的式子为样本属于正类的概率
P ( y = + 1 ∣ f ( x ) ; w ) = 1 1 + e − w ⊤ f ( x ) \large \begin{align*} P\bigl(y=+1\mid \mathbf{f}(x);\mathbf{w}\bigr) &= \frac{1}{1+e^{-\mathbf{w}^\top \mathbf{f}(x)}} \end{align*} P(y=+1∣f(x);w)=1+e−w⊤f(x)1
和当 h w ( x ) < 0.5 h_w(x) < 0.5 hw(x)<0.5时预测为负类,下面的式子属于样本属于负类的概率
P ( y = − 1 ∣ f ( x ) ; w ) = 1 − 1 1 + e − w ⊤ f ( x ) \large \begin{align*} P\!\left(y=-1\mid f(\mathbf{x});\mathbf{w}\right) &= 1 - \frac{1}{1 + e^{-\mathbf{w}^\top f(\mathbf{x})}}\, \end{align*} P(y=−1∣f(x);w)=1−1+e−w⊤f(x)1
Logistic Regression的损失函数和梯度
首先有一个数学小性质
g ′ ( z ) = g ( z ) ( 1 − g ( z ) ) \large \begin{align*} g'(z) &= g(z)\bigl(1 - g(z)\bigr) \end{align*} g′(z)=g(z)(1−g(z))
然后我们看L2 Loss的函数:
L o s s ( w ) = 1 2 ( y − h w ( x ) ) 2 \large \begin{align*} Loss(w) &= \tfrac{1}{2}\bigl(y - h_w(x)\bigr)^2 \end{align*} Loss(w)=21(y−hw(x))2
然后对第i个权重求偏导
∂ ∂ w i 1 2 ( y − h w ( x ) ) 2 = ( y − h w ( x ) ) ∂ ∂ w i ( y − h w ( x ) ) = − ( y − h w ( x ) ) h w ( x ) ( 1 − h w ( x ) ) x i \begin{align*} \frac{\partial}{\partial w_i}\frac{1}{2}\big(y-h_w(x)\big)^2 &= \big(y-h_w(x)\big)\frac{\partial}{\partial w_i}\big(y-h_w(x)\big) = -\big(y-h_w(x)\big)h_w(x)\big(1-h_w(x)\big)x_i \end{align*} ∂wi∂21(y−hw(x))2=(y−hw(x))∂wi∂(y−hw(x))=−(y−hw(x))hw(x)(1−hw(x))xi
因为logistic regression没有简单的closed-form solution, 所以通常用gradient descent来估计权重
Multi-Class Logistic Regression
和之前Perceptron的思路一样,都是从binary变成多类别的,对于多分类逻辑回归我们希望模型输出一个概率分布:
text
P(y=1|x), P(y=2|x), ..., P(y=K|x)
其中需要满足:
每个概率都 ≥ 0
所有概率加起来 = 1我们用的模型是Softmax Function,Softmax是logistic function的多分类拓展:
对于类别i我们有:
P ( y = i ∣ f ( x ) ; w ) = e w i ⊤ f ( x ) ∑ k = 1 K e w k ⊤ f ( x ) . \large \begin{align*} P\bigl(y=i\mid \mathbf{f(x)};\mathbf{w}\bigr) &= \frac{e^{\mathbf{w}i^{\top} \mathbf{f(x)}}}{\sum{k=1}^K e^{\mathbf{w}_k^{\top} \mathbf{f(x)}}}. \end{align*} P(y=i∣f(x);w)=∑k=1Kewk⊤f(x)ewi⊤f(x).
其中:
- 每个类别都有自己的权重向量
w_i; - 每个类别都会得到一个 score;
- 对 score 做指数变换;
- 再除以所有类别指数分数之和;
- 得到每个类别的概率
Likelihood
我们在这里用Likelihood方法来表示参数w以使观测到的数据有最大的可能性,我们的训练目标就是最大化这个likelihood:
ℓ ( w 1 , ... , w K ) = ∏ i = 1 n P ( y i ∣ f ( x i ) ; w ) \large \begin{align*} \ell(\mathbf{w}_1,\dots,\mathbf{w}K) &= \prod{i=1}^n P\big(y_i\mid f(x_i);\mathbf{w}\big) \end{align*} ℓ(w1,...,wK)=i=1∏nP(yi∣f(xi);w)
注意一下区分:
Softmax负责算每个类别的概率;
Likelihood负责把每个样本"真实类别的概率"拿出来乘在一起
然后我们为了写出多分类的likelihood,定义下面:
t i , k = { 1 , y i = k 0 , y i ≠ k \large \begin{align*} t_{i,k} &= \begin{cases} 1, & y_i = k\\4pt 0, & y_i \neq k \end{cases} \end{align*} ti,k=⎩ ⎨ ⎧1,0,yi=kyi=k
即:
- 如果第
i个样本真实类别是k,那么t_{i,k}=1; - 否则
t_{i,k}=0
这里举个例子更容易理解,对于某个样本x_i,Softmax会输出:
text
P(猫 | x_i)
P(狗 | x_i)
P(鸟 | x_i)但是真实标签只有一个,比如真实标签是狗,我们只想保留:
text
P(狗 | x_i)我们就用 t i , k t_{i, k} ti,k来表示:
text
如果第 i 个样本真实类别是 k,那么 t_{i,k} = 1
否则 t_{i,k} = 0所以就可以得到如果真实类别是狗,也就是第二类那么:
text
t_i = [0, 1, 0]所以说:
P ( 猫 ∣ x i ) 0 × P ( 狗 ∣ x i ) 1 × P ( 鸟 ∣ x i ) 0 = P ( 狗 ∣ x i ) \large \begin{align*} P(\mathrm{猫}\mid x_i)^{0}\times P(\mathrm{狗}\mid x_i)^{1}\times P(\mathrm{鸟}\mid x_i)^{0} = P(\mathrm{狗}\mid x_i) \end{align*} P(猫∣xi)0×P(狗∣xi)1×P(鸟∣xi)0=P(狗∣xi)
然后我们的likelihood公式就可以写成:
ℓ ( w 1 , ... , w K ) = ∏ i = 1 n ∏ k = 1 K ( e w k T f ( x i ) ∑ ℓ = 1 K e w ℓ T f ( x i ) ) t i , k \large \begin{align*} \ell(\mathbf{w}1,\dots,\mathbf{w}K) &= \prod{i=1}^n \prod{k=1}^K \left(\frac{e^{\mathbf{w}k^{\!T} \mathbf{f}(\mathbf{x}i)}}{\sum{\ell=1}^K e^{\mathbf{w}\ell^{\!T} \mathbf{f}(\mathbf{x}i)}}\right)^{t{i,k}} \end{align*} ℓ(w1,...,wK)=i=1∏nk=1∏K ∑ℓ=1KewℓTf(xi)ewkTf(xi) ti,k
对应的log- likelihood就是:
l o g ℓ ( w 1 , ... , w K ) = ∑ i = 1 n ∑ k = 1 K t i , k log ( e w k T f ( x i ) ∑ ℓ = 1 K e w ℓ T f ( x i ) ) \large \begin{align*} log\ell(\mathbf{w}1,\dots,\mathbf{w}K) &= \sum{i=1}^n \sum{k=1}^K t_{i, k}\log\left(\frac{e^{\mathbf{w}k^{\!T} \mathbf{f}(\mathbf{x}i)}}{\sum{\ell=1}^K e^{\mathbf{w}\ell^{\!T} \mathbf{f}(\mathbf{x}_i)}}\right) \end{align*} logℓ(w1,...,wK)=i=1∑nk=1∑Kti,klog ∑ℓ=1KewℓTf(xi)ewkTf(xi)
Softmax的梯度
∇ w j log ℓ ( w ) = ∑ i = 1 n ∇ w j ∑ k = 1 K t i , k log ( e w k ⊤ f ( x i ) ∑ ℓ = 1 K e w ℓ ⊤ f ( x i ) ) = ∑ i = 1 n ( t i , j − e w j ⊤ f ( x i ) ∑ ℓ = 1 K e w ℓ ⊤ f ( x i ) ) f ( x i ) \begin{align*} \nabla_{\mathbf{w}j}\log \ell(\mathbf w) &= \sum{i=1}^n \nabla_{\mathbf{w}j}\sum{k=1}^K t_{i,k}\log\!\left(\frac{e^{\mathbf{w}k^{\top}\mathbf{f}(\mathbf{x}i)}}{\sum{\ell=1}^K e^{\mathbf{w}\ell^{\top}\mathbf{f}(\mathbf{x}i)}}\right) = \sum{i=1}^n\left(t_{i,j}-\frac{e^{\mathbf{w}j^{\top}\mathbf{f}(\mathbf{x}i)}}{\sum{\ell=1}^K e^{\mathbf{w}\ell^{\top}\mathbf{f}(\mathbf{x}_i)}}\right)\mathbf{f}(\mathbf{x}_i) \end{align*} ∇wjlogℓ(w)=i=1∑n∇wjk=1∑Kti,klog(∑ℓ=1Kewℓ⊤f(xi)ewk⊤f(xi))=i=1∑n(ti,j−∑ℓ=1Kewℓ⊤f(xi)ewj⊤f(xi))f(xi)