一、摘要
传统医保审核依赖人工录入、逐条核对,存在效率低、易出错、政策适配慢等核心痛点。本文聚焦医保OCR与医保审核系统的深度融合,详细讲解结构化信息抽取、配置化规则引擎、自动化校验逻辑的工程实现方案,内容兼顾理论与实战,可直接为医保审核数字化、智能化升级提供落地参考。
二、前言:医保审核的核心痛点与解决路径
在医保审核业务场景中,人工主导的审核模式已难以适配政务数字化发展需求,核心痛点集中在4个方面:
-
票据种类繁杂:门诊、住院、异地结算等多版式票据并存,人工录入成本高、效率低;
-
规则适配复杂:医保政策地域性强、更新频繁,硬编码规则难以快速响应政策变化;
-
流程割裂脱节:OCR识别与审核系统数据不通,无法实现全流程自动化;
-
风控能力不足:重复报销、虚假票据等违规行为难以及时拦截,存在医保基金流失风险。
针对以上痛点,将OCR票据识别技术与医保审核系统深度打通,构建智能校验规则引擎,实现"票据采集---信息抽取---自动校验---审核归档"全流程自动化,是医保数字化升级的关键路径,也是本文的核心研究重点。
三、整体融合架构:轻量化设计,易对接易落地
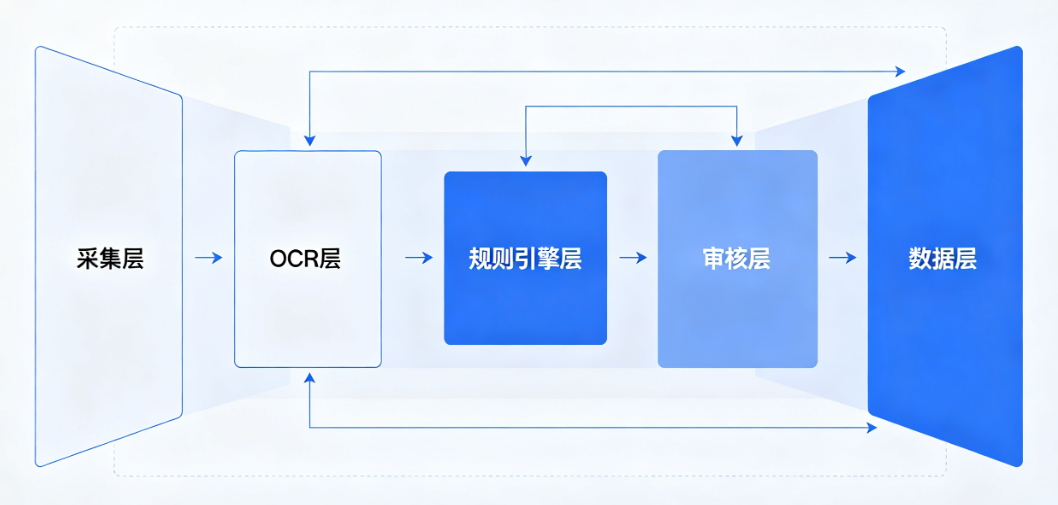
为兼顾实用性与扩展性,医保OCR与审核系统融合采用5层轻量化架构,无需大规模改造现有系统,可快速对接上线,各层职责清晰、联动高效,具体架构如下:
-
采集层:支持移动端拍照、高扫仪扫描、接口推送等多渠道票据接入,内置图像预处理模块(纠偏、去阴影、去噪、增强),解决医保票据模糊、褶皱、倾斜等识别难题;
-
OCR层:核心负责票据分类与关键信息结构化抽取,适配多版式医保票据,输出标准化JSON数据,为后续智能校验提供数据支撑;
-
规则引擎层:整个融合方案的核心,支持审核规则可视化配置、热更新与版本管理,实现各类医保审核规则的自动化执行;
-
审核层:采用"自动初审+人工复核"模式,实现审核流程流转、状态管理与日志留痕,兼顾自动化效率与审核准确性;
-
数据层:负责审核日志审计、数据统计分析,为医保基金风控、政策优化提供决策支撑。
四、核心模块实现:从技术到落地的全流程拆解

4.1 医保OCR结构化抽取(核心前提)
医保OCR的核心价值的是"从图像中提取可直接用于审核的标准化数据",而非单纯的"文字识别",其关键实现要点如下:
-
多版式适配:支持门诊票据、住院结算单、异地就医票据等多种类型,适配不同省份票据版式差异;
-
关键字段精准抽取:重点提取票据号、参保人信息、就诊日期、诊疗项目、报销金额、医疗机构等核心字段;
-
内置纠错机制:实现金额大小写互验、日期格式标准化、异常字符过滤,确保数据准确性;
-
数据输出规范:统一输出JSON结构化格式,可直接对接医保审核系统,无需二次数据转换。
经实战验证,优化后的医保OCR识别准确率≥98%,完全满足医保审核的数据精度要求。以下是基于Python+PaddleOCR的实战实现代码:
python
import paddleocr
import json
from PIL import Image
import re
# 1. 初始化OCR模型(适配医疗票据优化,加载自定义训练模型)
ocr = paddleocr.PaddleOCR(use_angle_cls=True, lang="ch", det_model_dir="./det_model", rec_model_dir="./rec_model")
# 2. 图像预处理(针对医保票据模糊、褶皱、阴影问题优化)
def preprocess_image(image_path):
img = Image.open(image_path).convert("RGB")
# 去阴影、增强对比度,提升模糊票据识别准确率
img = img.point(lambda x: x * 1.2 if x < 200 else 255)
return img
# 3. 医保票据关键字段抽取(适配多版式,可根据省份调整正则)
def extract_medical_bill_info(image_path):
img = preprocess_image(image_path)
result = ocr.ocr(img, cls=True)
# 初始化结构化数据字典,对应审核系统所需字段
bill_info = {
"bill_no": "", # 票据号(唯一标识,用于重复报销校验)
"patient_name": "", # 参保人姓名
"medical_date": "", # 就诊日期
"total_amount": 0.0, # 总报销金额
"medical_projects": [], # 诊疗项目及对应金额
"medical_institution": "" # 就诊医疗机构
}
# 遍历OCR识别结果,通过正则提取关键字段
for line in result:
text = line[1][0].strip()
# 提取票据号(适配多数医保票据格式,可灵活调整正则)
if re.search(r"票据号[::]\s*(\w+)", text):
bill_info["bill_no"] = re.search(r"票据号[::]\s*(\w+)", text).group(1)
# 提取参保人姓名(匹配中文姓名,排除特殊字符)
elif re.search(r"姓名[::]\s*([\u4e00-\u9fa5]+)", text):
bill_info["patient_name"] = re.search(r"姓名[::]\s*([\u4e00-\u9fa5]+)", text).group(1)
# 提取就诊日期(适配YYYY-MM-DD格式)
elif re.search(r"就诊日期[::]\s*(\d{4}-\d{2}-\d{2})", text):
bill_info["medical_date"] = re.search(r"就诊日期[::]\s*(\d{4}-\d{2}-\d{2})", text).group(1)
# 提取总金额(匹配小数格式)
elif re.search(r"总金额[::]\s*(\d+\.\d+)", text):
bill_info["total_amount"] = float(re.search(r"总金额[::]\s*(\d+\.\d+)", text).group(1))
# 提取就诊医疗机构
elif re.search(r"医疗机构[::]\s*([\u4e00-\u9fa5]+)", text):
bill_info["medical_institution"] = re.search(r"医疗机构[::]\s*([\u4e00-\u9fa5]+)", text).group(1)
# 提取诊疗项目及金额(简化版,可根据票据明细优化)
elif re.search(r"项目[::]\s*([\u4e00-\u9fa5]+)\s*金额[::]\s*(\d+\.\d+)", text):
project = re.search(r"项目[::]\s*([\u4e00-\u9fa5]+)\s*金额[::]\s*(\d+\.\d+)", text)
bill_info["medical_projects"].append({
"project_name": project.group(1),
"amount": float(project.group(2))
})
# 输出标准化JSON,直接供医保审核系统调用
return json.dumps(bill_info, ensure_ascii=False, indent=4)
# 测试代码:抽取医保票据信息(替换为实际票据路径即可运行)
if __name__ == "__main__":
bill_json = extract_medical_bill_info("medical_bill.jpg")
print("OCR抽取结果(标准化JSON):")
print(bill_json)代码说明:该实现适配多数省份医保票据,可根据具体票据版式调整正则表达式;预处理环节可根据实际需求,增加图像裁切、字符补全等优化步骤,进一步提升识别准确率。
4.2 智能校验规则设计(核心核心)
智能校验规则是OCR与医保审核系统融合的"大脑",核心目标是实现审核规则配置化、热更新,无需硬编码即可适配医保政策变化。结合实战经验,规则设计采用"五大规则体系+配置化引擎"模式,具体如下:
4.2.1 五大规则体系(覆盖医保审核全场景)
-
票据合法性规则:校验票据真伪、有效期,通过票据号查询历史记录,拦截重复报销;
-
参保人资格规则:校验参保人状态(正常/断缴/未参保)、异地就医备案情况、身份信息一致性;
-
金额合规规则:自动核算起付线、封顶线、报销比例,校验总金额与明细金额一致性;
-
诊疗项目规则:匹配医保目录,拦截禁止报销项目,校验诊疗项目与病种的适配性;
-
风控反欺诈规则:识别高频就诊、异常金额、跨地区频繁就医等违规行为,拦截虚假、篡改票据。
4.2.2 规则引擎实现(Drools实战)
采用Drools轻量级规则引擎,支持可视化配置、版本管理与灰度发布,以下是核心规则配置示例(聚焦高频审核场景):
java
// 医保审核规则文件(medical_audit.drl),可通过可视化平台配置,无需修改代码
package com.medical.ocr.audit;
// 导入OCR抽取的结构化数据实体、审核结果实体
import com.medical.ocr.entity.MedicalBill;
import com.medical.ocr.entity.AuditResult;
// 规则1:金额合规校验(超过医保封顶线自动拦截,封顶线可配置)
rule "AmountLimitCheck"
when
$bill : MedicalBill(total_amount > 50000.0) // 假设医保封顶线50000元,支持动态配置
$result : AuditResult()
then
$result.setAuditStatus("REJECT"); // 审核状态:拒审
$result.setReason("报销金额超过医保封顶线(50000元),不予报销");
update($result); // 更新审核结果
end
// 规则2:重复报销校验(根据票据号查询历史报销记录,避免重复提交)
rule "DuplicateReimbursementCheck"
when
$bill : MedicalBill(bill_no != null) // 票据号不为空才执行校验
$result : AuditResult()
// 调用历史报销记录查询接口,判断该票据是否已报销
exists com.medical.ocr.service.HistoryService.checkDuplicate($bill.getBillNo())
then
$result.setAuditStatus("REJECT");
$result.setReason("该票据已完成报销,禁止重复提交");
update($result);
end
// 规则3:参保状态校验(参保状态异常,推送人工复核)
rule "InsuranceStatusCheck"
when
$bill : MedicalBill(patientInsureStatus != "NORMAL") // 仅参保状态为"正常"可通过初审
$result : AuditResult()
then
$result.setAuditStatus("PENDING_REVIEW"); // 审核状态:待复核
$result.setReason("参保状态异常,请人工复核确认");
update($result);
end
// 规则4:异地就医备案校验(异地就医未备案,推送补充材料)
rule "RemoteMedicalCheck"
when
$bill : MedicalBill(isRemote = true, isRemoteRecorded = false) // 异地就医且未备案
$result : AuditResult()
then
$result.setAuditStatus("PENDING_REVIEW");
$result.setReason("异地就医未完成备案,请补充备案材料后重新提交");
update($result);
end代码说明:规则文件可独立管理,医保政策更新时,只需新增/修改规则文件,无需重启系统,分钟级即可生效;支持规则版本管理,可回溯历史规则,便于审计与回滚。
4.3 系统对接与自动化审核逻辑
OCR与医保审核系统融合的关键的是"数据互通、逻辑联动",采用SpringBoot实现接口对接,支持同步、异步两种模式,适配不同票据处理场景,核心实现如下:
4.3.1 对接模式(两种模式适配全场景)
-
同步接口:适用于单张票据实时审核,流程为"上传票据→OCR实时识别→规则引擎校验→返回审核结果",响应时间≤3秒;
-
异步接口:适用于海量票据批量审核,流程为"批量推送票据→OCR队列处理→规则校验→回调审核结果",支持任务进度查询;
-
数据规范:统一采用JSON Schema格式,确保OCR抽取数据与审核系统数据无缝对接,避免接口适配冲突。
4.3.2 接口实战代码(SpringBoot)
java
package com.medical.ocr.controller;
import com.alibaba.fastjson.JSONObject;
import com.medical.ocr.service.MedicalOcrService;
import com.medical.ocr.service.MedicalAuditService;
import com.medical.ocr.entity.AuditResult;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
import org.springframework.web.multipart.MultipartFile;
import java.io.IOException;
// 医保审核接口控制器,统一接口路径,支持多渠道调用
@RestController
@RequestMapping("/api/medical/audit")
public class MedicalAuditController {
@Autowired
private MedicalOcrService medicalOcrService; // OCR识别服务
@Autowired
private MedicalAuditService medicalAuditService; // 审核业务服务
// 同步审核接口:单张票据实时审核(适配移动端、PC端上传)
@PostMapping("/sync-audit")
public AuditResult syncAudit(@RequestParam("file") MultipartFile file) throws IOException {
// 1. OCR识别:提取票据结构化数据
String billJson = medicalOcrService.extractBillInfo(file);
JSONObject billObj = JSONObject.parseObject(billJson);
// 2. 智能校验:调用规则引擎执行审核
AuditResult auditResult = medicalAuditService.doAudit(billObj);
// 3. 返回结果:直接返回审核状态(通过/待复核/拒审)
return auditResult;
}
// 异步审核接口:批量票据审核(适配海量票据处理场景)
@PostMapping("/async-audit")
public String asyncAudit(@RequestParam("files") MultipartFile[] files) {
// 1. 批量提交:将票据推送至处理队列,异步执行OCR识别与审核
medicalOcrService.batchSubmitToQueue(files);
// 2. 返回任务ID:供前端查询审核进度
String taskId = "AUDIT_" + System.currentTimeMillis();
return JSONObject.toJSONString(new Object() {
public int code = 200;
public String msg = "批量审核任务已提交,可通过taskId查询进度";
public String taskId = taskId;
});
}
// 进度查询接口:查询批量审核任务进度
@GetMapping("/query-progress/{taskId}")
public String queryProgress(@PathVariable String taskId) {
// 调用审核服务,查询任务处理进度(已完成/处理中/失败)
return medicalAuditService.queryAuditProgress(taskId);
}
}
// 审核服务实现(简化版,核心逻辑:调用规则引擎执行校验)
@Service
public class MedicalAuditServiceImpl implements MedicalAuditService {
@Autowired
private KieSession kieSession; // Drools规则引擎会话
@Override
public AuditResult doAudit(JSONObject billObj) {
// 1. 数据转换:将OCR输出的JSON转换为票据实体
MedicalBill bill = billObj.toJavaObject(MedicalBill.class);
// 2. 初始化审核结果:设置票据号,默认状态为待审核
AuditResult result = new AuditResult();
result.setBillNo(bill.getBillNo());
result.setAuditStatus("PENDING");
// 3. 规则校验:将票据实体、审核结果插入规则引擎,执行所有校验规则
kieSession.insert(bill);
kieSession.insert(result);
kieSession.fireAllRules(); // 触发规则引擎执行
// 4. 日志记录:将审核结果、规则命中记录落库,支持审计追溯
logAuditResult(result);
return result;
}
}代码说明:接口设计兼顾实用性与可扩展性,支持PC端、移动端多渠道调用;异步接口采用队列机制,可根据业务需求调整队列大小与处理线程数,避免海量票据处理时出现系统拥堵。
五、落地效果:量化提升,降本增效
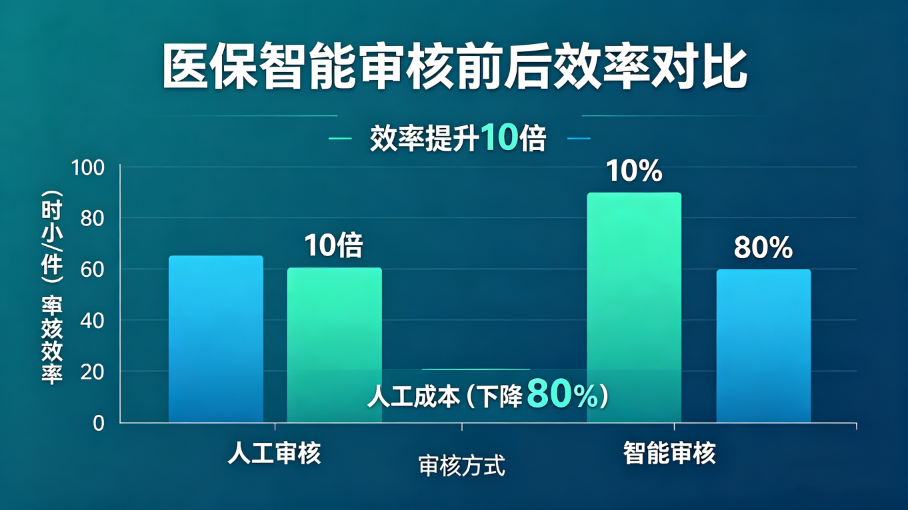
该融合方案已在多个医保经办机构落地应用,核心效果可量化,具体如下:
-
效率提升:单张医保票据审核从分钟级降至秒级,日处理量提升5--10倍,大幅缩短审核周期;
-
成本下降:自动初审率可达85%--95%,大幅减少人工录入、核对工作量,降低人力成本;
-
准确率提升:OCR识别准确率≥98%,规则校验零失误,避免人工审核疏漏导致的医保基金流失;
-
政策适配:规则配置化设计,医保政策更新时分钟级适配,无需修改代码,降低维护成本。
六、注意事项(落地避坑指南)
-
OCR识别优化:针对老旧、模糊、印章遮挡的医保票据,需额外增加图像增强、字符补全逻辑,确保识别准确率稳定在98%以上,避免因数据错误影响审核结果;
-
规则引擎适配:不同省份医保政策差异较大,需设计地域化规则配置模块,按省份、地区划分规则集,避免规则冲突;
-
数据安全合规:OCR抽取的参保人身份信息、诊疗数据属于敏感信息,需采用加密存储、合规传输方式,符合国内医疗数据安全规范及相关法律法规;
-
系统兼容适配:对接医保现有系统时,优先采用标准化JSON格式与接口规范,避免改造原有系统,降低对接成本与适配风险。
七、总结与展望
医保OCR与医保审核系统的深度融合,本质是"数据打通+规则驱动+流程自动化"的全链路重构,并非简单的技术拼接。通过结构化信息抽取、配置化规则引擎的实现,可快速实现医保审核从"人工主导"向"智能自动化"的升级,兼具落地性、扩展性与合规性,为医保数字化、智能化发展提供有力支撑。
未来,可进一步结合知识图谱、NLP、异常检测AI模型,优化规则引擎的智能化水平,实现从"人工配置规则"向"AI自动发现规则"的升级,进一步提升医保审核的效率与风控能力,助力医保基金精细化管理。
更多医疗票据识别OCR技术,关注"快瞳科技"!
#医保OCR #医保审核系统 #智能校验 #规则引擎 #医疗票据识别 #OCR结构化抽取 #医保自动化审核 #医保风控 #政务数字化 #智能审核