大家好 👋,我是 Moment,目前正在使用 Next.js、NestJS、LangChain 开发 DocFlow。这是一个面向 AI 场景的协同文档平台,集成了基于
Tiptap的富文本编辑、NestJS后端服务、实时协作与智能化工作流等核心模块。在这个项目的持续打磨过程中,我积累了不少实战经验,不只是
Tiptap的深度定制、编辑器性能优化和协同方案设计,也包括前端工程化建设、React 源码理解以及复杂项目架构实践。如果你对 AI 全栈开发、Agent、长期记忆、文档编辑器、前端工程化或者 React 源码相关内容感兴趣,欢迎添加我的微信
yunmz777一起交流。觉得项目还不错的话,也欢迎给 DocFlow 点个 star ⭐
从这一篇开始,用一个简化版计算器 Agent 走一遍 LangGraph 的核心要素。目标很具体:只用节点、边、状态这三个概念,从零定义一张最小的图、让它真正跑起来,在代码里看清楚状态如何在节点之间流转。持久化、本地服务、子图等进阶内容都留到后面,这一章先让你对图式编排有可运行的手感。
用计算器 Agent 认识图
例子的场景是:用户用自然语言描述算式,比如"请帮我把三加四再乘二",模型理解后决定是否调工具,工具负责加减乘除等具体运算,结果回到模型整理成一句友好的回复。
这个场景不复杂,但很好地覆盖了图的三个关键能力:节点之间如何传递状态、条件边如何根据状态决定下一跳、工具节点执行完后如何回到模型节点继续推理。用图来表示整体执行流程,如下图所示。
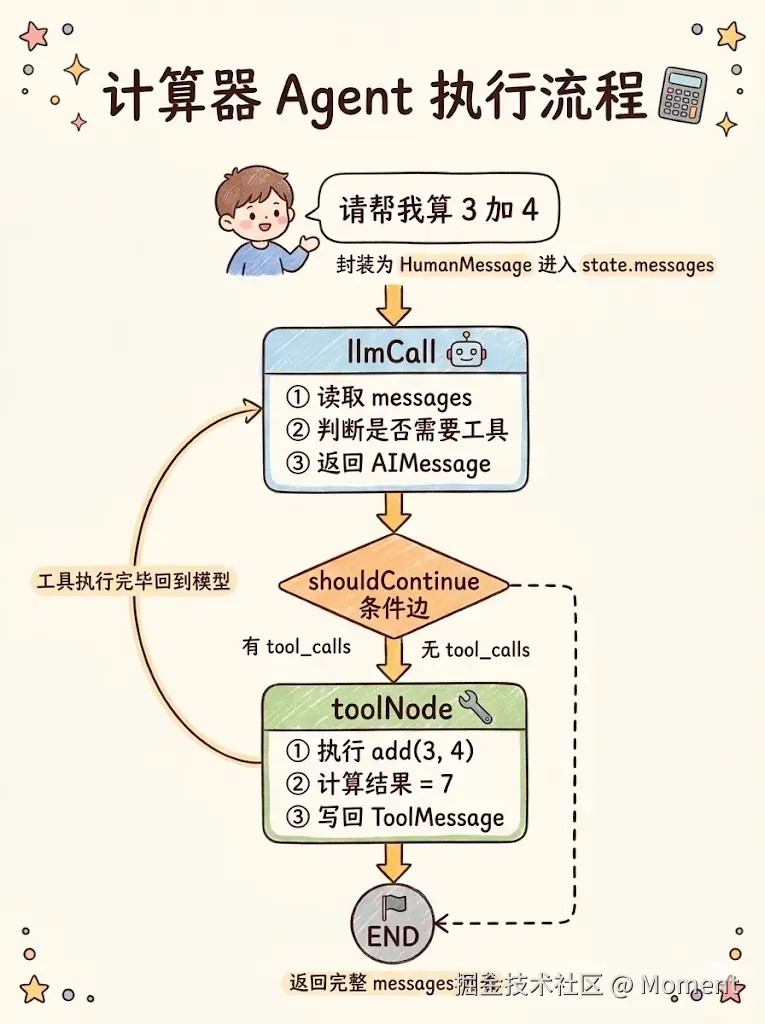
模型节点与工具节点之间的回环,就是 LangGraph 和 LangChain 线性链最本质的区别。下面按这个结构一步步把代码写出来。
准备模型与工具
图要跑起来,先得有一个支持工具调用的聊天模型,再配几个简单的计算工具。这部分仍然由 LangChain 提供,LangGraph 暂时不登场。
模型初始化时加了 temperature: 0,是为了让模型在判断"该不该调工具、该调哪个工具"这类结构化决策时输出更稳定,减少随机性带来的不必要波动。三个计算工具 add、multiply、divide 用 tool 函数定义,schema 用 zod 写,这样模型拿到工具描述后能清楚知道每个参数的类型。最后调 model.bindTools(tools) 把工具列表注入模型,之后每次调用这个模型时,它就知道手边有哪些工具可用。
ts
import { ChatOpenAI } from "@langchain/openai";
import { tool } from "@langchain/core/tools";
import * as z from "zod";
const model = new ChatOpenAI({
model: "deepseek-chat",
apiKey: "sk-60816d9be57f4189b658f1eaee52382e",
configuration: { baseURL: "https://api.deepseek.com" },
temperature: 0,
});
const add = tool(({ a, b }) => a + b, {
name: "add",
description: "Add two numbers",
schema: z.object({
a: z.number().describe("First number"),
b: z.number().describe("Second number"),
}),
});
const multiply = tool(({ a, b }) => a * b, {
name: "multiply",
description: "Multiply two numbers",
schema: z.object({ a: z.number(), b: z.number() }),
});
const divide = tool(({ a, b }) => a / b, {
name: "divide",
description: "Divide two numbers",
schema: z.object({ a: z.number(), b: z.number() }),
});
const toolsByName = {
[add.name]: add,
[multiply.name]: multiply,
[divide.name]: divide,
};
const tools = Object.values(toolsByName);
const modelWithTools = model.bindTools(tools);到这里模型和工具都准备好了,接下来才是 LangGraph 登场的地方。
定义图的状态
任何一张 LangGraph 图都需要一个状态模式,用来描述在节点之间流转的是哪些数据。状态不是普通对象,每个节点不是整体替换状态,而是只返回需要更新的字段,LangGraph 按字段的 reducer 把更新合并进去。
对于对话类应用,最常用的状态定义是 MessagesAnnotation,它内置了消息列表的 reducer 逻辑。节点每次返回 { messages: [newMessage] },状态系统就自动把这条消息追加到已有列表里,不需要手动维护整个消息数组。
ts
import {
StateGraph,
MessagesAnnotation,
START,
END,
} from "@langchain/langgraph";后面定义节点和组装图时都会用到 MessagesAnnotation,它既是状态模式的定义,也给 TypeScript 提供了节点函数参数的类型推断,写 state: typeof MessagesAnnotation.State 就能拿到完整的类型提示。
两个核心节点
这张图里只有两个真正干活的节点。llmCall 负责调用模型,根据当前 messages 生成一条新消息,并判断要不要请求工具。toolNode 根据上一轮模型的工具调用请求执行工具,把结果封装成 ToolMessage 返回。
节点函数可以只接收 state。如果需要流式或回调,可以声明第二个参数 config?: RunnableConfig,图运行时会自动传入。这样 invoke 和 streamEvents 的回调就能一路传到模型和工具里,流式输出才能正常触发。
先写模型节点。它把系统提示和已有消息一起发给模型,只返回本次新生成的那条消息,状态系统负责追加。
ts
import { SystemMessage } from "@langchain/core/messages";
import type { RunnableConfig } from "@langchain/core/runnables";
const llmCall = async (
state: typeof MessagesAnnotation.State,
config?: RunnableConfig
) => {
const response = await modelWithTools.invoke(
[
new SystemMessage(
"你是一个负责做算术的助手,根据用户描述执行加减乘除等运算,需要时调用工具得到结果后再用自然语言回复。"
),
...state.messages,
],
config
);
return { messages: [response] };
};再写工具节点。逻辑分三步:拿到最后一条 AIMessage,根据里面的 tool_calls 逐个执行对应工具,把每个工具的返回值包成 ToolMessage 追加到状态里。tool_call_id 是关键,模型后续要靠它把工具结果和当初的请求对应起来。
ts
import { AIMessage, ToolMessage } from "@langchain/core/messages";
const toolNode = async (
state: typeof MessagesAnnotation.State,
config?: RunnableConfig
) => {
const lastMessage = state.messages.at(-1);
if (!lastMessage || !AIMessage.isInstance(lastMessage)) {
return { messages: [] };
}
const results: ToolMessage[] = [];
for (const toolCall of lastMessage.tool_calls ?? []) {
const t = toolsByName[toolCall.name];
if (!t) continue;
const value = await t.invoke(toolCall.args ?? {}, config);
results.push(
new ToolMessage({
content: String(value),
tool_call_id: toolCall.id ?? "",
})
);
}
return { messages: results };
};如果最后一条不是 AIMessage,或者 AIMessage 里没有工具调用,直接返回空列表,图会照常往下走,不会卡住。
条件边与路由
节点准备好之后,还要告诉图跑完某个节点之后下一步去哪。这里的逻辑很清楚:模型回来的消息里如果带着 tool_calls,说明它想用工具,就走到 toolNode;如果没有 tool_calls,说明模型已经可以直接给用户回复了,图结束。
ts
const shouldContinue = (state: typeof MessagesAnnotation.State) => {
const lastMessage = state.messages.at(-1);
if (!lastMessage || !AIMessage.isInstance(lastMessage)) return END;
if (lastMessage.tool_calls?.length) return "toolNode";
return END;
};这个函数返回的是字符串(节点名)或 END,LangGraph 拿到返回值后就知道下一步跳到哪个节点。条件边是 LangGraph 表达"分支逻辑"的核心机制,比把 if/else 藏在节点函数里要清晰得多,图的结构一眼就能看懂。
组装并运行整张图
把状态、节点和边用 StateGraph 链式调用串在一起,最后调 compile() 得到可执行的图。addConditionalEdges 的第三个参数是允许到达的节点列表,LangGraph 会在编译时验证条件边函数的返回值不会跳到意外的节点,起到一定的安全检查作用。
ts
import { HumanMessage } from "@langchain/core/messages";
const agent = new StateGraph(MessagesAnnotation)
.addNode("llmCall", llmCall)
.addNode("toolNode", toolNode)
.addEdge(START, "llmCall")
.addConditionalEdges("llmCall", shouldContinue, ["toolNode", END])
.addEdge("toolNode", "llmCall")
.compile();
const result = await agent.invoke({
messages: [new HumanMessage("请帮我算一下 3 加 4 等于多少。")],
});
for (const message of result.messages) {
const content = typeof message.content === "string" ? message.content : "";
console.log(message.getType(), content);
}以"请帮我算一下 3 加 4 等于多少"为例,图的完整执行路径如下:
START进入llmCall,模型判断需要调add工具,返回带tool_calls的AIMessageshouldContinue检测到有工具调用,走到toolNodetoolNode执行add(3, 4)得到7,包成ToolMessage追加到状态,沿固定边回到llmCall- 模型拿到工具结果,生成"3 加 4 等于 7"这样的自然语言回复,这次没有工具调用,
shouldContinue返回END,图结束
走完这四步,messages 列表里依次记录了用户消息、模型的工具请求、工具的执行结果、模型的最终回复,完整还原了整条推理过程。
流式输出
invoke 是一次性拿到全部结果,适合脚本和批处理。如果要做"边生成边显示"的体验,用 agent.streamEvents 按事件消费。
ts
import { ChatOpenAI } from "@langchain/openai";
import { tool, type StructuredTool } from "@langchain/core/tools";
import { SystemMessage, AIMessage, ToolMessage, HumanMessage } from "@langchain/core/messages";
import type { RunnableConfig } from "@langchain/core/runnables";
import { StateGraph, MessagesAnnotation, START, END } from "@langchain/langgraph";
import * as z from "zod";
// 模型
const model = new ChatOpenAI({
model: "deepseek-chat",
apiKey: "sk-60816d9be57f4189b658f1eaee52382e",
configuration: { baseURL: "https://api.deepseek.com" },
temperature: 0,
});
// 工具
const add = tool(({ a, b }) => String(a + b), {
name: "add",
description: "Add two numbers",
schema: z.object({ a: z.number(), b: z.number() }),
});
const multiply = tool(({ a, b }) => String(a * b), {
name: "multiply",
description: "Multiply two numbers",
schema: z.object({ a: z.number(), b: z.number() }),
});
const divide = tool(({ a, b }) => String(a / b), {
name: "divide",
description: "Divide two numbers",
schema: z.object({ a: z.number(), b: z.number() }),
});
const toolsByName: Record<string, StructuredTool> = {
add,
multiply,
divide,
};
const modelWithTools = model.bindTools(Object.values(toolsByName));
// 节点
const llmCall = async (
state: typeof MessagesAnnotation.State,
config?: RunnableConfig
) => {
const response = await modelWithTools.invoke(
[
new SystemMessage("你是一个负责做算术的助手,根据用户描述执行加减乘除等运算,需要时调用工具得到结果后再用自然语言回复。"),
...state.messages,
],
config
);
return { messages: [response] };
};
const toolNode = async (
state: typeof MessagesAnnotation.State,
config?: RunnableConfig
) => {
const lastMessage = state.messages.at(-1);
if (!lastMessage || !AIMessage.isInstance(lastMessage)) return { messages: [] };
const results: ToolMessage[] = [];
for (const toolCall of lastMessage.tool_calls ?? []) {
const t = toolsByName[toolCall.name];
if (!t) continue;
const value = await t.invoke(toolCall.args ?? {}, config);
results.push(new ToolMessage({ content: String(value), tool_call_id: toolCall.id ?? "" }));
}
return { messages: results };
};
// 条件路由
const shouldContinue = (state: typeof MessagesAnnotation.State) => {
const lastMessage = state.messages.at(-1);
if (!lastMessage || !AIMessage.isInstance(lastMessage)) return END;
return lastMessage.tool_calls?.length ? "toolNode" : END;
};
// 组装图
const agent = new StateGraph(MessagesAnnotation)
.addNode("llmCall", llmCall)
.addNode("toolNode", toolNode)
.addEdge(START, "llmCall")
.addConditionalEdges("llmCall", shouldContinue, ["toolNode", END])
.addEdge("toolNode", "llmCall")
.compile();
// 流式运行
async function main() {
const stream = agent.streamEvents(
{ messages: [new HumanMessage("请帮我算一下 3 加 4 等于多少。")] },
{ version: "v2" }
);
for await (const event of stream) {
if (event.event === "on_chat_model_stream") {
const chunk = event.data?.chunk?.content;
if (typeof chunk === "string" && chunk) process.stdout.write(chunk);
}
if (event.event === "on_tool_start") {
console.log(`\n[工具调用] ${event.name}`, JSON.stringify(event.data?.input));
}
if (event.event === "on_tool_end") {
console.log(`[工具结果] ${event.name}: ${event.data?.output}`);
}
}
console.log("\n");
}
main().catch(console.error);on_chat_model_stream 是模型逐 token 输出,从 event.data.chunk.content 取片段写到终端就能得到打字机效果。on_tool_start 和 on_tool_end 分别在工具开始和结束时触发,可以用来显示"正在计算......"这样的进度提示。这些事件能正常触发的前提是节点里把 config 传给了 modelWithTools.invoke 和 t.invoke,回调通路才算打通。如果节点没有传 config,这些事件就不会冒出来。
如果只想按节点观察每一步的状态增量,不关心逐字,可以换成 agent.stream 配 streamMode: "updates",每个 chunk 就是"节点名 -> 该节点本次返回的状态更新",调试时很有用。
和 LangChain 传统写法的对比
用 LangChain 写过类似计算器 Agent 的话,会发现两者的逻辑其实差不多,都是模型判断是否需要工具、调用工具、再根据工具结果生成回复。但有几个点上 LangGraph 的优势很明显。
流程可见方面,用 LangChain 的 AgentExecutor,整条执行链路藏在对象内部,从外部很难直接看出走了哪些步骤。用 LangGraph 写,节点、边、条件路由全都显式定义,图的结构就是代码本身,不需要额外文档解释流程。
状态可追方面,LangGraph 图执行过程中,每个节点的输入输出都是状态的一次快照。后面加上 checkpointer 之后,这些快照可以持久化,支持暂停恢复、时间旅行和回放,AgentExecutor 做不到这一点。
扩展性方面,这一章的图很小,只有两个节点。后面加入持久化、人机协同、子图、多 Agent 协作时,只需要在图里加节点和边,不需要重写整个逻辑,扩展起来很自然。
小结
这一章用计算器 Agent 完整走了一遍 LangGraph 的核心三要素,几个值得记住的点:
MessagesAnnotation定义消息列表状态,每个节点只返回增量,框架负责合并,不用手动维护整个数组llmCall节点负责调用模型,toolNode节点负责执行工具,两者通过条件边构成一个可以反复循环的 Agent 推理回路shouldContinue是整张图的路由核心,tool_calls有值走工具、为空走END,分支逻辑和节点实现彻底分开streamEvents打通了逐 token 流式输出和工具事件,前提是节点里把config一路传下去,回调通路才能正常工作addConditionalEdges的第三个参数声明了合法的目标节点,图在编译时会做边界检查,防止条件函数返回意外节点名
下一章会在这张图上引入 checkpointer,给每次执行打快照,为持久化、暂停恢复和时间旅行做准备。