Note:强化学习(三)
2026 | ming

八. DQN
通过第七章的实验,我们可以发现朴素版本的神经网络Q学习是非常不稳定的。不稳定的原因可以回看第七章。
2013年,DeepMind的Mnih等人发表了一篇名为《Playing Atari with Deep Reinforcement Learning》的论文,用两个看似简单却极为深刻的工程技巧,漂亮地解决了上述两个问题。这项工作后来被称为深度Q网络(Deep Q‑Network, DQN),它标志着深度强化学习时代的真正开启。而这两个技巧如下:
- 经验回放 :每一个转移样本 (s,a,r,s′) 只用一次就被丢弃。在真实机器人或昂贵模拟环境中,每一步交互都可能耗费大量时间或金钱,如此浪费宝贵的经验显然不是明智之举。用一个缓冲区把智能体经历过的转移样本 (s,a,r,s′) 存储起来,训练时随机抽取一个小批量(mini‑batch)来计算梯度。这打破了样本之间的时序相关性,让每次更新更像是从整个"记忆库"中均匀采样,极大提升了训练的稳定性。
- 目标网络 :额外维护一个结构完全相同但参数更新更"慢"的目标Q网络 Q^,用它来计算TD目标 y=r+γmaxa′Q^(s′,a′;θ′)。目标网络的参数 θ′ 每隔固定步数才从当前Q网络拷贝一次。这样一来,在一段时间内目标值是相对固定的,网络有了一个稳定的"追赶方向",不再被自己制造的变化牵着鼻子走。
8.1 经验回放
经验回放的核心思想朴素而优雅:把智能体在环境中走过的每一步都存入一个回放缓冲区 ,训练时不再使用当前这一步的数据,而是从缓冲区里随机抽取一小批历史经验来计算梯度。这种做法一举打破了样本之间的时间相关性,也让每一条经验有机会被反复利用多次,显著提升了数据效率。
在代码层面,经验回放缓冲区的实现并不复杂。Python内置的 collections.deque 是一个天然的环形队列,我们可以利用它的 maxlen 参数来自动丢弃最旧的经验,保持缓冲区大小恒定。下面就来亲手实现一个 ReplayBuffer 类。
python
from collections import deque
import random
import numpy as np
class ReplayBuffer:
"""
经验回放缓冲区,用于存储和采样智能体的历史转移样本。
参数:
buffer_size: 缓冲区的最大容量,超出后自动丢弃最旧的经验。
batch_size: 每次采样时返回的样本数量。
"""
def __init__(self, buffer_size, batch_size):
self.batch_size = batch_size
# deque 设定了 maxlen 后,当长度超过限制时会自动从左侧弹出旧元素
self.buffer = deque(maxlen=buffer_size)
# 可选:为复现性固定一个随机数生成器
self.rng = np.random.default_rng(42)
def add(self, state, action, reward, next_state, done):
"""
向缓冲区添加一条经验转移。
参数:
state: 当前状态 (通常为 numpy 数组或标量)
action: 执行的动作
reward: 获得的即时奖励
next_state: 转移后的下一状态
done: 布尔值,表示是否进入终止状态
"""
data = (state, action, reward, next_state, done)
self.buffer.append(data)
def __len__(self):
"""返回缓冲区当前存储的经验数量。"""
return len(self.buffer)
def get_batch(self):
"""
从缓冲区中随机采样一个批次的经验。
返回:
state_batch: 形状为 (batch_size, *state_shape) 的数组
action_batch: 形状为 (batch_size,) 的数组
reward_batch: 形状为 (batch_size,) 的数组
next_state_batch: 形状为 (batch_size, *state_shape) 的数组
done_batch: 形状为 (batch_size,) 的整型数组 (1 表示终止, 0 表示未终止)
"""
# 从缓冲区中随机抽取 batch_size 条经验
data = random.sample(self.buffer, self.batch_size)
# 将抽取的元组列表转换为各成分的 numpy 数组,方便后续批量处理
state = np.array([x[0] for x in data])
action = np.array([x[1] for x in data])
reward = np.array([x[2] for x in data])
next_state = np.array([x[3] for x in data])
done = np.array([x[4] for x in data]).astype(np.int32)
return state, action, reward, next_state, done这里的 add 方法会在智能体每执行一步后被调用,将完整的转移信息压入队列;get_batch 则负责在训练时提供一批打乱顺序的经验。值得注意的是,我们将 done 标志转换成了整数类型,这在后续计算TD目标时会很方便------如果 done=1,我们只需简单地将目标值设为 reward 即可。
在实际训练开始前,我们通常需要先让智能体在环境中随机"游荡"一段时间,用纯粹探索产生的数据把缓冲区填满(或至少达到一个能支撑批量训练的下限)。这个过程被称为预热 或填充阶段。下面的代码演示了如何用随机策略收集 10 个完整回合的经验,并存入刚刚定义好的缓冲区中。
python
import gymnasium as gym
from tqdm import tqdm # 用于显示进度条,非必需
# 创建环境和缓冲区实例
env = gym.make("CartPole-v1")
replay_buffer = ReplayBuffer(buffer_size=1000, batch_size=32)
# 收集 10 个回合的经验(实际应用中通常需要更多,这里仅为演示)
pbar = tqdm(range(10), desc="Filling replay buffer", ncols=100, leave=True)
for episode in pbar:
state, info = env.reset()
done = False
while not done:
# 随机选择一个动作(纯探索)
action = env.action_space.sample()
next_state, reward, terminated, truncated, info = env.step(action)
done = terminated or truncated
# 将每一步的经验存入缓冲区
replay_buffer.add(state, action, reward, next_state, done)
state = next_state
# 检查采样得到的批次形状
state_batch, action_batch, reward_batch, next_state_batch, done_batch = replay_buffer.get_batch()
print(f"state batch shape: {state_batch.shape}") # (32, 4)
print(f"action batch shape: {action_batch.shape}") # (32,)
print(f"reward batch shape: {reward_batch.shape}") # (32,)
print(f"next_state batch shape: {next_state_batch.shape}") # (32, 4)
print(f"done batch shape: {done_batch.shape}") # (32,)8.2 目标网络
目标网络的思想异常简洁:额外维护一个结构完全相同但参数更新频率更低的神经网络,记作 Qθ′。在计算TD目标时,我们用这个目标网络来估计下一状态的最大Q值:
y=r+γa′maxQθ′(s′,a′)
注意,这里的参数写作 θ′,以区别于主网络(也叫在线网络)的参数 θ。主网络 Qθ 依然是那个每步都要被训练更新的网络,而目标网络 Qθ′ 则保持冻结,只在每隔一定的训练步数(例如每1000步)之后,才从主网络那里拷贝一次最新的参数。
这样一来,在一段不短的时间窗口内,目标值 y 的计算依据是固定不变的。主网络的更新方向因此变得清晰而稳定:它不再去追一个和自己一起移动的影子,而是在追逐一个被"锚定"在几秒前状态的清晰目标。等到目标网络再次同步参数时,这个锚点会向前跃迁一次,然后再次保持静止,如此往复。这种机制在数学上显著减缓了自举过程中反馈回路的增益,有效抑制了振荡。
目标网络的参数同步方式通常有两种实现策略:硬更新 与软更新。理解它们的区别对于调参和实际部署都很有帮助。
硬更新
硬更新是最直观、也是原始DQN论文所采用的方式。它每隔固定的 C 步(例如 C=1000次梯度更新),直接将主网络的所有参数完整拷贝到目标网络上:
θ′←θ
在PyTorch中,这一操作可以通过 load_state_dict 轻松实现:
python
# 假设 q_net 是主网络,target_net 是目标网络
if update_step % target_update_freq == 0:
target_net.load_state_dict(q_net.state_dict())硬更新的优点在于它完全阻断了目标网络与主网络之间在大部分时间内的关联,目标值极其稳定。但它的缺点也很明显:更新是"跳跃式"的,如果更新频率设置不当,可能会引入较大的波动。
软更新
软更新则是一种更平滑的替代方案。它不是每隔许久进行一次全量拷贝,而是在每一个训练步 都将目标网络的参数向主网络的参数微微靠近一点,通过指数移动平均来实现:
θ′←τθ+(1−τ)θ′
其中 τ∈(0,1) 是一个很小的混合系数,典型取值如 0.005。这个公式的含义是:保留目标网络自身 1−τ 的旧信息,只吸收主网络 τ 的新信息。由于 τ 很小,目标网络的参数变化极其缓慢,如同冰川移动一般,从而提供了持续且平滑的锚定效果。
在PyTorch中,软更新需要我们手动遍历两个网络的所有参数张量,执行加权求和:
python
tau = 0.005 # 软更新系数
for target_param, online_param in zip(target_net.parameters(), q_net.parameters()):
target_param.data.copy_(tau * online_param.data + (1.0 - tau) * target_param.data)软更新的好处在于训练过程更加平滑,不需要费心调整更新频率这个超参数,因此在许多后续的强化学习算法(如DDPG、TD3、SAC)中被广泛采用。
8.3 代码实现
如下是经典DQN的代码实现,代码和注释都非常清晰:
python
import random
from collections import deque
import gymnasium as gym
import matplotlib.pyplot as plt
import numpy as np
import torch
import torch.nn as nn
from tqdm import tqdm
# ---------- Q网络 ----------
class QNetwork(nn.Module):
"""
简单的三层全连接神经网络,用于近似 Q(s, a)。
输入状态 s,输出每个可能动作的 Q 值。
"""
def __init__(self, state_dim, action_dim):
"""
参数:
state_dim (int): 状态空间的维度(例如 CartPole 为4)。
action_dim (int): 动作空间的维度(例如 CartPole 为2)。
"""
super().__init__()
# 使用 Sequential 容器堆叠层,结构可根据任务调整
self.net = nn.Sequential(
nn.Linear(state_dim, 64), # 输入层 -> 隐藏层1 (64个神经元)
nn.LeakyReLU(), # 激活函数,LeakyReLU 避免神经元"死亡"
nn.Linear(64, 32), # 隐藏层1 -> 隐藏层2 (32个神经元)
nn.LeakyReLU(),
nn.Linear(32, action_dim), # 隐藏层2 -> 输出层 (action_dim个Q值)
)
def forward(self, x):
"""
前向传播。
参数:
x (Tensor): 状态张量,形状为 (batch_size, state_dim)
返回:
Tensor: 每个动作的Q值,形状为 (batch_size, action_dim)
"""
return self.net(x)
# ---------- DQN智能体 ----------
class DQNAgent:
"""
DQN 智能体
"""
def __init__(self, state_dim=4, action_dim=2, lr=0.0005, gamma=0.99,
epsilon=0.4, epsilon_min=0.01, epsilon_decay=0.82,
buffer_size=10000, batch_size=32):
"""
参数:
state_dim (int): 状态维度
action_dim (int): 动作数量
lr (float): 学习率
gamma (float): 折扣因子,控制未来奖励的重要性
epsilon (float): 初始探索概率
epsilon_min (float): 探索概率下限
epsilon_decay (float): 每次衰减的乘性因子(0~1之间)
buffer_size (int): 经验池容量
batch_size (int): 每次更新的样本批次大小
"""
self.state_dim = state_dim
self.action_dim = action_dim
self.gamma = gamma
self.epsilon = epsilon
self.epsilon_min = epsilon_min
self.epsilon_decay = epsilon_decay
self.batch_size = batch_size
# 初始化两个网络:Q网络(在线网络)和目标网络
self.q_net = QNetwork(state_dim, action_dim)
self.target_net = QNetwork(state_dim, action_dim)
# 优化器,用于更新Q网络的参数
self.optimizer = torch.optim.Adam(self.q_net.parameters(), lr=lr)
# 均方误差损失,因为Q学习的目标是回归问题
self.loss_fn = nn.MSELoss()
# 经验回放缓冲区,沿用第8.1小节的ReplayBuffer类
self.memory = ReplayBuffer(buffer_size, batch_size)
# 初始时将目标网络的参数与Q网络同步
self.sync_target_network()
def sync_target_network(self):
"""
硬更新(Hard Update):将在线Q网络的参数完整复制给目标网络。
"""
self.target_net.load_state_dict(self.q_net.state_dict())
def get_action(self, state, eval_mode=False):
"""
根据当前状态选择动作,遵循 ε-贪婪策略。
参数:
state (np.array): 当前环境状态,形状为 (state_dim,)
eval_mode (bool): 若为True,则始终选择最优动作(ε=0),用于评估。
返回:
int: 选择的动作索引
"""
# 探索:以概率 epsilon 随机选择一个动作
if not eval_mode and np.random.rand() < self.epsilon:
return np.random.randint(self.action_dim)
# 利用:使用Q网络计算各个动作的Q值,选择Q值最大的动作
state_tensor = torch.FloatTensor(state).unsqueeze(0) # 增加 batch 维度 (1, state_dim)
with torch.no_grad(): # 关闭梯度计算,节省内存和计算
q_values = self.q_net(state_tensor)
return q_values.argmax().item() # 返回最大Q值对应的动作索引
def update(self):
"""
执行一步Q-learning更新:
1. 从经验池采样一个批次。
2. 计算当前Q值(由在线网络给出)。
3. 计算目标Q值(使用目标网络和贝尔曼方程)。
4. 计算损失并反向传播更新在线网络。
"""
# 当缓冲区中的样本不足一个批次时,不进行更新
if len(self.memory) < self.batch_size:
return
# 从经验池获取一个批次的转移样本
states, actions, rewards, next_states, dones = self.memory.get_batch()
# 将 numpy 数组转换为 PyTorch 张量
states = torch.FloatTensor(states) # (batch, state_dim)
actions = torch.LongTensor(actions).unsqueeze(1) # (batch, 1) 用于 gather 操作
rewards = torch.FloatTensor(rewards) # (batch,)
next_states = torch.FloatTensor(next_states) # (batch, state_dim)
dones = torch.FloatTensor(dones) # (batch,)
# ----- 当前Q值 -----
# q_net(states) 输出形状 (batch, action_dim)
# gather(1, actions) 沿着动作维度取出对应动作的Q值,结果形状 (batch, 1)
# squeeze() 去掉多余的维度,得到 (batch,)
current_q = self.q_net(states).gather(1, actions).squeeze()
# ----- 目标Q值 -----
with torch.no_grad():
# 使用目标网络计算下一状态的最大Q值 max_a' Q_target(s', a')
next_q = self.target_net(next_states).max(1)[0] # (batch,)
# 贝尔曼方程: target = r + gamma * max_next_q * (1 - done)
# 如果 episode 结束 (done=1),则没有后续状态,目标仅为即时奖励 r
target_q = rewards + (1 - dones) * self.gamma * next_q
# ----- 损失计算与反向传播 -----
loss = self.loss_fn(current_q, target_q)
self.optimizer.zero_grad() # 清空过往梯度
loss.backward() # 计算梯度
self.optimizer.step() # 更新网络参数
def decay_epsilon(self):
"""
衰减探索率 epsilon,使其逐步减小,但不会低于 epsilon_min。
通常每隔一定回合调用一次,使智能体逐渐从探索转向利用。
"""
self.epsilon = max(self.epsilon * self.epsilon_decay, self.epsilon_min)
# ---------- 训练主循环 ----------
def train_dqn(episodes=200, sync_interval=20):
"""
执行完整的 DQN 训练过程。
参数:
episodes (int): 训练的回合总数。
sync_interval (int): 每隔多少回合同步一次目标网络并衰减 epsilon。
返回:
list: 每个回合获得的总奖励记录。
"""
# 创建 CartPole-v1 环境
env = gym.make("CartPole-v1")
agent = DQNAgent() # 使用默认参数初始化智能体
reward_history = [] # 记录每个回合的总奖励
# 使用 tqdm 显示训练进度条
for episode in tqdm(range(episodes), desc="Training", ncols=100):
state, _ = env.reset() # 重置环境,获得初始状态
done = False
total_reward = 0
# 一个回合内的交互循环
while not done:
action = agent.get_action(state) # 1. 选择动作
next_state, reward, terminated, truncated, _ = env.step(action)
done = terminated or truncated # 判断回合是否结束
# 2. 存储经验到回放缓冲区
agent.memory.add(state, action, reward, next_state, done)
# 3. 执行一次学习更新(如果缓冲区足够大)
agent.update()
state = next_state
total_reward += reward
# 每隔 sync_interval 个回合,同步目标网络并衰减 epsilon
if episode % sync_interval == 0:
agent.sync_target_network()
agent.decay_epsilon()
reward_history.append(total_reward)
env.close()
return reward_history
# ---------- 运行并绘图 ----------
if __name__ == "__main__":
# 训练300个回合(可根据需要调整)
rewards = train_dqn(episodes=300)
# 绘制学习曲线
plt.figure(figsize=(10, 5))
plt.plot(rewards, label="Episode Reward", alpha=0.7)
# 计算并绘制10回合滑动平均,使曲线更平滑
moving_avg = np.convolve(rewards, np.ones(10)/10, mode='same')
plt.plot(moving_avg, label="10-episode Moving Average", linewidth=2)
plt.xlabel("Episode")
plt.ylabel("Total Reward")
plt.title("DQN on CartPole-v1")
plt.legend()
plt.grid(True)
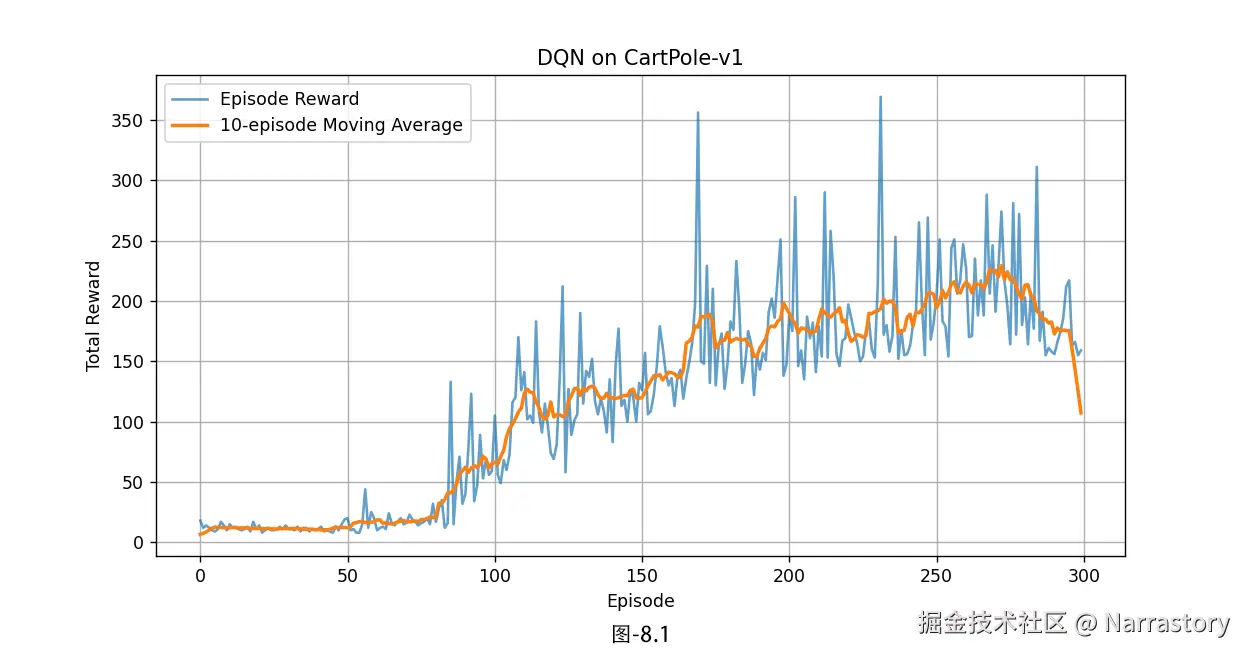
plt.show()运行结果如图8.1,可以看到,这个曲线比之前单纯的神经网络Q学习要好不少,变稳定了很多。
九. DQN的现代优化
DQN是深度强化学习中最著名的算法之一。自从DQN发表以来,人们提出了许多为DQN量身定制的优化方法。下面只介绍三种知名的DQN优化算法。
下面这些优化我没有配上具体的代码实现,不过如果你看懂了上面的DQN的原始代码,以及下面的这些优化算法的数学原理,那么你完全可以在几分钟内修改DQN算法来实现下面的优化算法。
9.1 Double DQN
在上一节里,我们看到 DQN 通过目标网络 大幅稳定了训练。它把 TD 目标里的 Q 值交给一个"慢半拍"的参数副本 θ′ 去算,避免了自举(bootstrapping)时的麻烦。
但这里其实藏着一个微妙的结构问题:DQN 的目标网络同时干了两件事------既负责挑动作,又负责给这个动作打分。具体来说,DQN 的 TD 目标长这样:
ytDQN=Rt+γamaxQθ′(St+1,a)
注意,这里目标网络先在自己的估计值里挑出一个最大的动作,然后再用这个网络自己去评估这个动作有多好。如果 Qθ′ 对某些动作的估计恰好因为噪声或函数近似误差而偏高, max 算子会系统性地偏爱这些正向误差 ,导致期望估计值被放大。这个问题在统计上被称为最大化偏差,在传统的表格型 Q-learning 里就已经被注意到了。
更有意思的是,这个偏差不是静态的,它会通过 TD 更新递归地传播。今天高估一点,明天自举的时候基准就更高,后天就更高------久而久之,Q 值会被系统性地顶到不现实的水平,策略也可能因此被误导到次优动作上。
Double DQN的思路非常干净:既然问题出在"同一个网络既当裁判又当运动员",那我们干脆把动作选择 和动作评估拆开。
DQN 其实已经给了我们两个网络:在线网络(online network,参数 θ)和目标网络(target network,参数 θ′)。Double DQN 的做法是:
-
让在线网络 θ 来选动作 :它看状态 St+1,挑一个它当下觉得最好的动作:
a∗=aargmaxQθ(St+1,a)
-
让目标网络 θ′ 来评估这个动作 :它只负责回答"这个动作 a∗ 到底值多少":
Qθ′(St+1,a∗)
于是 TD 目标变成了:
ytDouble=Rt+γQθ′(St+1,aargmaxQθ(St+1,a))
对比 DQN 的 ytDQN,唯一的区别是 max 变成了 argmax 套在外面,而且 argmax 内部用的是在线网络 θ 而不是目标网络 θ′。这个改动在代码上往往只需要改一行,但概念上却很深刻------它把经典的 Double Q-learning 思想无缝嫁接到了深度网络框架里,而且巧妙地复用了 DQN 已有的目标网络结构,不需要额外再搭一套网络。
9.2 优先级经验回放
在经验回放缓冲区里,每一条历史经验数据真的都同等重要吗?
DQN 原版的经验回放是"雨露均沾"式的------每次从缓冲区里均匀随机抽出一批数据。这种做法打破了样本间的时间相关性,对稳定性帮助很大,但在数据效率上却相当奢侈。试想,模型对某些状态转移已经估得很准(TD 误差很小),反复把它们喂进网络,带来的边际收益极低;而另一些 transition 则让模型"大吃一惊"(TD 误差很大),这些才是它真正需要补习的功课。
优先级经验回放的核心就在于此:让 TD 误差充当一种"惊讶度"的代理指标,优先去采样那些模型还没搞懂的样本。
δt= Rt+γamaxQθ′(St+1,a)−Qθ(St,At)
这个式子大家都很熟悉了------它就是在算当前 Q 网络输出与 TD 目标之间的差距。 δt 越大,说明模型对这条经验的预期和现实偏差越大,参数需要修正的步幅就越大;反之,如果 δt 趋近于零,说明这条经验已经被模型吃透了,暂时不需要再花时间。
在实现上,当一条新经验 Et=(St,At,Rt,St+1) 被塞进回放缓冲区时,我们就顺手把它的 δt 也存进去。采样的时候,不再是闭着眼睛随机抓,而是让每条经验被抽到的概率正比于它的"惊讶度"。
于是我们就可以自然而然的得出概率分配公式:
pi=∑k=0Nδkδi
但如果真的严格按这个线性比例去采样,实践中会遇到一个麻烦:那些早期误差特别大的"刺头"样本会被反复抽到,而误差小的样本可能永远坐冷板凳。这不仅会造成过拟合,还会让训练失去多样性------毕竟,有时候看似"简单"的样本也能提供有价值的梯度信号。
在原始的工作中,人们通常不会这么"铁面无私"。更常见的做法是引入一个小的常数 ϵ(保证每条经验至少有点被抽到的机会),再用一个指数 α∈0,1 来控制优先级的"陡峭程度":
pi=∑k(δk+ϵ)α(δi+ϵ)α
这里 α=0 就退化回均匀采样, α=1 则接近纯粹的贪婪优先级采样。实际调参时, α 通常取个中间值(比如 0.6 左右),既能重点关注高价值样本,又不至于把低优先级数据完全打入冷宫。
好,现在我们已经不再是均匀采样了,但这带来了一个隐蔽的副作用。DQN 的 Q 值更新本质上是在估计一个期望,而期望对分布是敏感的 。当你故意提高高 δ 样本的采样概率时,你实际上是在用一个非均匀的、有偏的分布去近似原始的目标分布。如果不做任何处理,梯度更新会被这些"明星样本"牵着鼻子走,导致收敛到错误的地方。
解决这个问题的标准工具是重要性采样 。既然采样概率变成了 pi,我们就要给每条样本的梯度乘上一个权重,把分布偏差"扳回来":
wi=(N⋅pi1)β
然后通常还会做归一化,让权重缩放到一个合理的范围:
wi←maxjwjwi
这里的 β∈0,1 是另一个超参数,负责控制重要性采样修正的强度。有意思的是,在训练初期,模型对几乎所有东西的估计都很粗糙,修正可以轻一点( β 较小),让高优先级样本尽情释放学习信号;随着训练推进,我们逐渐把 β 往 1 拉,确保最终的无偏性。这种从"有偏但高效"到"无偏且稳健"的过渡,通常能在保持快速学习的同时,不牺牲渐近性能。
9.3 Dueling DQN
到了 DQN 这一步,我们已经知道用一个神经网络来拟合 Q 值是个可行的思路。但普通 DQN 有一个挺隐晦的问题:它对每个状态-动作对都一视同仁地输出一个 Q 值,哪怕在某些状态下,各个动作的好坏其实都差不多。
举个例子:你在玩游戏,面前飞来一个障碍物。这时候无论是向左闪还是向右跳,只要躲开了,结果都挺好;真正重要的是"这个状态很危险,得做点什么"。但标准 DQN 会埋头学习 Q(s, 左) 和 Q(s, 右) 的细微差别,把它们当成完全独立的数值去拟合。这显然有点浪费算力,也让学习过程更颠簸。
Dueling DQN (DeepMind, 2015)的核心就来自这里:既然 Q(s,a) 本身可以拆成"状态有多好"加上"动作比平均好多少",那我们何不干脆让网络也这么拆?
我们先回顾一下优势函数(Advantage Function)的定义。对于某个策略 π,我们有:
Aπ(s,a)=Qπ(s,a)−Vπ(s)
这意味着, Q 值可以被自然分解为:
Qπ(s,a)=Vπ(s)+Aπ(s,a)
直觉上 , V(s) 回答的是"走进这个状态,平均来讲能赚多少";而 A(s,a) 回答的是"在这个状态下,我硬选动作 a,会比'随大流'好多少(或者差多少)"。
有意思的是,对于很多状态,知道 V(s) 远比知道每个动作的精确 Q 值更有用。比如刚才说的避障场景:向左和向右的 Q 值可能极其接近,但 V(s) 会明确告诉你"这个状态很值钱,因为躲开了就能活"。Dueling DQN 正是利用这一点,让网络显式地、分别地学习 V(s) 和 A(s,a),而不是闷头去学它们的和。
具体怎么做?网络结构上的改动其实非常简洁。
在神经网络输出层,原本 DQN 是直接把特征展平后丢进几个全连接层,输出一个 ∣A∣ 维的 Q 值向量。Dueling DQN 则在这里把全连接层劈成两路,如图9.1:
- 状态价值流 :一路全连接最后输出一个标量 V(s)。这一路只关心状态本身的价值,完全不看动作。
- 优势流:另一路全连接输出一个 向量** A(s,a),维度就是动作空间的大小 ∣A∣。这一路关心的是每个动作相对平均水平的"优势"。
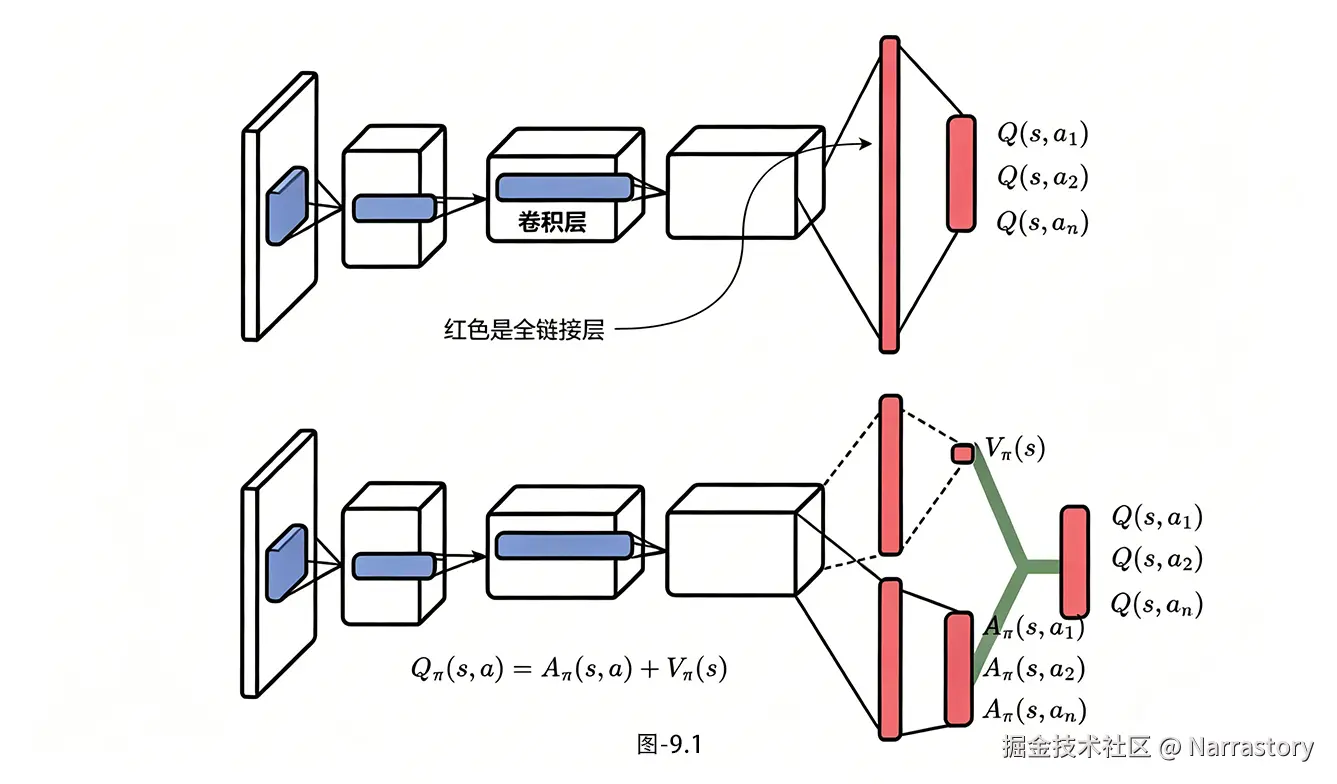
两路共享前面的卷积特征提取器,这一点很重要------它保证了视觉层面的表征学习不会分裂,只是在最后的决策层做了分工。
现在我们有 V(s) 和 A(s,a) 了,直觉上直接把它们相加就好:
Q(s,a)=V(s)+A(s,a)
但这里有个可识别性 问题。假设我给 V(s) 加上一个常数 c,再从所有的 A(s,a) 里减去同一个 c,最后得到的 Q(s,a) 完全不变。换句话说,给定一个 Q,存在无穷多组 (V,A) 的组合都能产生它。这会让训练过程很混乱:网络今天把压力放在 V 上,明天又把压力移回 A 上,更新信号不稳定。
解决方案也很简单:我们强制让优势函数在该状态下均值为零。
论文里提出的原始聚合形式是:
Q(s,a)=V(s)+(A(s,a)−a′maxA(s,a′))
不过实际使用中,大家发现另一种形式训练起来更稳定、效果更鲁棒:
Q(s,a)=V(s)+(A(s,a)−∣A∣1a′∑A(s,a′))
第二项括号里的东西,就是把每个动作的优势值减去该状态下所有动作优势的平均值 。这样一减,那"多余的常数"就被消掉了, A 的均值被锚定在了 0。
这个设计还有一个很漂亮的性质:当所有动作的优势都相等时(也就是在这个状态下选啥都差不多),括号里变成 0,于是 Q(s,a)=V(s)。这完全符合我们的直觉------如果动作之间没有优劣之分,那动作的期望回报就等于状态本身的价值。
以上,就是Dueling DQN全流程,Dueling DQN 并不是在所有任务上都能碾压原始 DQN------如果动作空间很小,或者不同动作的回报差异本来就很大,优势函数能带来的增益就有限。但在动作空间较大、且很多状态具有"动作同质化"特点的场景下(比如 Atari 里的很多游戏),它通常能带来一致性的提升。
9.4 其它优化算法
到这一节,我们已经聊了 Double DQN、优先级经验回放和 Dueling DQN 这三个最常被提及的改进。它们分别从目标值估计 、数据采样 和网络结构 三个维度修正了原始 DQN 的缺陷。不过,2015 到 2017 年这段时间,DQN 的改进是全方位的------探索策略、回报估计、甚至对 Q 值本身的数学假设都被重新思考了一遍。这一节我们就把视野放宽一点,简要过一遍其它几个影响深远的工作,最后看看把它们全部拼在一起的 Rainbow 算法。
Noisy Networks:把探索交给网络自己学
原始 DQN 用的是 ε-greedy:以 ε 的概率随机乱动,剩下的时间跟着 Q 网络走。这种做法实现简单,但有个明显的毛病------探索强度是全局统一、手动调参的,与当前状态无关。你可能在某些已经学得很熟的状态上依然无脑随机探索,又在真正需要试探的陌生状态上过于保守。
Noisy Networks (Fortunato et al., 2017)的思路是:与其在动作层面掷骰子,不如直接在网络参数层面注入噪声。具体来说,给全连接层的权重和偏置加上一组可学习的噪声项:
y=(Wx+b)+(Wnoisy⊙εW)x+(bnoisy⊙εb)
其中 εW,εb 是从某个固定分布(比如正态分布)中采样的随机噪声,而 Wnoisy,bnoisy 则是通过网络梯度下降自适应学习的噪声强度。
好处很明显 :网络自己会决定哪些参数需要多抖一抖、哪些参数应该保持稳定。状态空间里的不同区域可以拥有不同的探索风格------这远比一个全局的 ε 要灵活。更妙的是,它完全消除了 ε-greedy 那个让人头疼的衰减调度表。
N-step Returns:把自举的视野拉长一点
我们在前面一直用单步 TD 目标:
yt=rt+γamaxQ(st+1,a)
这叫自举(bootstrapping),它方差低,但偏差高------因为你把未来所有回报都压缩进了下一步的 Q 值估计里。蒙特卡洛方法刚好相反:用完整回合的累计回报,无偏但方差爆炸。
N-step DQN 取了个折中。顾名思义,它往前看 n 步再回头 bootstrap:
Gt(n)=k=0∑n−1γkrt+k+γnamaxQ(st+n,a)
直观上, n 越大,目标值越接近真实的回报序列,偏差越小,但方差也会跟着涨; n=1 就是标准 DQN, n→∞ 就趋近蒙特卡洛。在实际调参里, n=3 或 n=5 通常是个不错的甜点------它让目标值包含了更多真实的奖励信号,同时又不至于让方差失控。
Categorical DQN (C51):别只学期望值,去学分布
从 Bellman 方程到 DQN,我们始终在做同一件事:估计期望值 Q(s,a)。但期望这个东西有个问题:它把未来所有可能性的信息压缩成了一个标量,完全丢掉了回报的不确定性。
Categorical DQN (Bellemare et al., 2017,也常叫 C51)提出:为什么不直接学习回报的完整分布呢?
定义一个随机变量 Z(s,a) 表示在 (s,a) 下未来折扣回报的分布,那么:
Q(s,a)=EZ(s,a)
C51 假设这个分布是离散的,被支撑在 N=51 个(这也是它名字里 51 的来源)均匀分布的 atoms 上:
zi=Vmin+i⋅N−1Vmax−Vmin,i=0,...,N−1
网络不再输出一个 Q 值,而是输出这 51 个 atoms 上的概率分布。Bellman 方程也随之变成了分布层面的 Bellman 算子:
Z(s,a)=DR(s,a)+γZ(s′,a∗)
这里 =D 表示分布意义上的相等。训练时,我们最小化两个分布之间的投影 KL 散度。因为网络对整个回报的形状有了感知,它在某些非平稳或具有多峰回报结构的环境中表现得比普通 DQN 稳定得多。
值得一提的是,C51 开启了一整个叫 Distributional RL 的子领域。后来的 QR-DQN、IQN 都是在它基础上把分布估计做得更好更灵活。
Rainbow:把最好的配料全部倒进一碗面里
到了 2017 年,DeepMind 的研究者看着眼前这一堆相互正交的改进,产生了一个非常自然的念头:如果我把这些优化算法全加在一起,效果会好吗?
答案是:不仅好,而且好得惊人。他们把这六种改进------
- Double DQN(解决 Q 值过估计)
- Prioritized Experience Replay(高效采样)
- Dueling DQN(价值与优势分离)
- Noisy Networks(自适应参数化探索)
- N-step Returns(多步目标值)
- Categorical DQN(分布学习)
------全部堆叠到同一个智能体上,起了个名字叫 Rainbow(Hessel et al., 2018)。之所以叫 Rainbow,大概是因为算法的示意图里五颜六色的改进模块拼在一起,像一道彩虹。
实验结果相当漂亮:在 Atari 57 款游戏的标准测试上,Rainbow 的数据效率(达到某个性能所需的交互步数)比原始 DQN 提升了大约 200 倍 ,而最终的渐进表现也远超任何单一改进的独立版本。更有趣的是消融实验:他们发现这六个组件里,优先级回放 和多步回报对性能的贡献最大;拿掉任何一个,整体都会掉点,但很少出现"不兼容"的情况------说明这些改进确实是从不同维度解决了 DQN 的问题。
当然,Rainbow 也不是没有代价。它的代码复杂度、超参数敏感度和显存占用都比原始 DQN 高了一个量级。如果你在工业界落地,可能需要根据实际情况做减法------比如去掉 C51 换成普通 Q 值,或者放弃 Noisy Nets 回到简单的 ε-greedy。但在研究层面,Rainbow 是一个很重要的里程碑:它证明了这些看似零散的 patch 是可以协同工作的,也为后来的 Agent57(再后来解决全部 57 款 Atari 游戏)打下了基础。
END~
