翻译自 THINKING MACHINES 博客原文。
LLM 能够在特定领域实现专家级表现,这得益于多种能力叠加:输入感知、知识检索、计划选择和可靠执行(perception of input, knowledge retrieval, plan selection, and reliable execution)。这需要一套训练方法,我们可以将其分为三个大致阶段:
- 预训练教授通用能力,如语言使用、广泛推理和世界知识。
- 中期训练教授领域知识,如代码、医疗数据库或公司内部文件。
- 后训练触发特定行为,比如指令遵循、数学推理或聊天。
较小且训练更强的模型在其训练领域通常表现优于大型通用模型。使用较小模型有许多好处:它们可以本地部署以保障隐私或安全,能够持续训练并更轻松地更新,并节省推理成本。为了利用这些优势需要在训练后期选择合适的方法。
"学生"模型的后训练方法可分为两类:
- On-policy training:从学生模型中采样 rollouts,并给予他们一些奖励。
- Off-policy training:依赖于外源目标输出,学生通过学习进行模仿。
例如,我们可能希望训练一个小模型来解决如下数学问题:
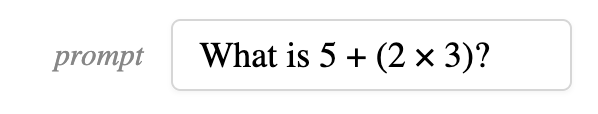
通过给每个学生的 rollout 是否解决了问题打分,我们可以通过强化学习进行 on-policy training。这种打分可以由人工完成,也可以由可靠获得正确答案的"教师"模型完成。

on-policy training 的优势在于,通过从自身采样的样本进行训练,学生学会以更直接的方式避免错误。但强化学习有一个主要缺点:它提供的反馈非常稀疏,无论使用多少令牌,每训练一个 episode 都教授固定的比特数 。在我们上面的例子中,学生发现"21"是错误的答案,于是更新远离当前的尝试的rollout。但它无法准确知道错误发生在哪里,无论是运算符顺序错误还是算术本身的错误。这种反馈的稀疏性使得强化学习在许多应用中效率低下。
Off-policy training 通过监督微调(SFT)进行:即在一组精心策划的任务特定标注示例上进行训练。这些标注示例的来源可以是经过验证、在当前任务中表现良好的教师模型。
我们可以使用一种称为蒸馏的机制:训练学生匹配教师模型的输出分布 。我们在教师轨迹上进行训练:包括中间思考步骤在内的完整序列。我们可以使用教师在每个步骤的完整下一个 token 分布(通常称为"logit 蒸馏"),或者 sampled token 序列。实际上,抽样序列(sampling sequences)提供了教师分布的无偏估计,并达到相同的目标。学生根据生成该 token 的可能性比例,更新序列中的每个 token,以下示例中以较深颜色表示:

从大模型教师中蒸馏,已被证明在训练小模型指令遵循,数学科学推理,从医疗记录中抽取临床诊断信息,促进多轮对话方面非常有效。用于这些及其他应用的蒸馏数据集通常是开源并公开发布的。
off-policy training 的缺点是学生在教师常去的环境中学习,而非学生自己经常身处的环境。这可能导致叠加误差:如果学生早期犯错而老师从未犯错,学生会发现自己越来越偏离训练中观察到的状态。当我们关心学生在长序列中的表现时,这个问题尤其严重。为了避免这种偏离,学生必须学会从自身错误中恢复。
另一个观察到的 off-policy distillation 问题是,学生可以学会模仿老师的风格和自信,但不一定能模仿其事实准确性。
如果你正在学下棋,on-policy RL 就像没有教练的情况下玩棋。胜负反馈直接关联到你自己的对局,但每场比赛只收到一次反馈,且不会告诉你哪些走法对结果贡献最大。Off-policy distillation 类似于观看一位特级大师下棋------你会看到极其强劲的棋步,但这些棋子是在新手很少遇到的棋盘状态下。
我们希望将 on-policy relevance of RL 与 dense reward signal of distillation 结合起来。对于学习国际象棋,这应该是一个老师,他会用"失误"到"精彩"的尺度来评分你每一步。对于 LLM 的后训练,则是 on-policy distillation。
On-policy distillation --- best of both worlds
On-policy distillation 的核心思想是从学生模型中抽样轨迹,并由更强的教师对每个轨迹的 token 进行评分。回到我们上面的数学例子,策略提炼会对解题的每一步进行评分,惩罚导致学生得出错误答案的失败轨迹,同时强化那些正确执行的轨迹。

本文探讨了 on-policy distillation 在诸如训练数学推理模型和训练结合领域知识与指令跟随的辅助模型等任务中的应用。我们在具备培训前期和中期能力基础的模型上应用 on-policy distillation。我们发现这是一种廉价且高效的后训练方法,结合了 on-policy training 与密集的奖励信号的两种优点。
我们在 on-policy distillation 方面的工作灵感来自 DAGGER,一种迭代 SFT 算法,包含教师对学生访问状态的评估。它也类似于过程奖励建模,这是一种对学生思维链每一步进行评分的强化学习方法。我们推广了 Agarwal 等人,Gu 等人,Qwen3团队之前的 on-policy distillation 工作,利用 Tinker training API,我们复制了 Qwen3 在推理 benchmarks 中通过 on-policy distillation 实现等效性能的结果,成本仅为强化学习的一小部分。
Implementation
细节在:Tinker cookbook
=>拓展知识:正向KL散度、反向KL散度、对称KL散度 <=
Loss function: reverse KL
在线策略蒸馏可以使用多种损失函数来评分学生轨迹。为简单起见,我们选择每 token 反向 KL 散度 ------在相同先验轨迹条件下,学生模型( π θ \pi_\theta πθ)与教师模型( π teacher \pi_{\text{teacher}} πteacher)分布之间的散度:
KL ( π θ ∣ ∣ π teacher ) = E x ∼ π θ log π θ ( x t + 1 ∣ x 1.. t ) − log π teacher ( x t + 1 ∣ x 1.. t ) \text{KL}\Bigl(\pi_\theta \lvert\rvert \pi_{\text{teacher}}\Bigr) = \mathbb{E}{x \sim {\pi\theta}} \Bigl \\log \\pi_\\theta(x_{t+1} \| x_{1..t}) - \\log \\pi_{\\text{teacher}}(x_{t+1} \| x_{1..t}) \\Bigr KL(πθ∣∣πteacher)=Ex∼πθlogπθ(xt+1∣x1..t)−logπteacher(xt+1∣x1..t)
我们的奖励函数最小化反向 KL,推动学生模型在其所处的每个状态中逼近教师模型的行为。当学生模型与教师模型行为一致时,反向 KL 为零。为简单起见,我们使用折扣因子为零:在任何给定时间步,学生模型只优化即时下一个 token,不考虑未来 token。
反向 KL 与强化学习有天然的协同效应,后者通常优化由奖励模型诱导的序列级反向 KL 形式。然而,与实践中大多数奖励模型不同,反向 KL 是"unhackable"------低 KL 总是对应于从教师模型角度看期望行为的高概率 。反向 KL 的另外两个有用特性是:它是"model-seeking"的------它学习一种特定行为(教师的),而不是将分布分散在几个次优选项上;它减少了曝光偏差 exposure bias。
这种方法提供了显著的计算节省。由于不需要等待采样完成就能计算奖励,我们可以使用更短或部分的轨迹进行训练。查询教师模型的对数概率也只需要大型模型的单次前向传播,而轨迹由更小更便宜的学生模型生成。
我们也不需要单独的奖励或标注模型。将基于蒸馏的每 token 奖励与序列级环境奖励结合可能具有优势,这是未来研究的有趣方向。
Illustration
下面我们看到一个老师评分错误学生轨迹的真实例子。这个例子来自 SimpleBench,依赖于模型的一个关键观察:问题的前提很重要:正确答案是"B. 0",因为冰块会在煎锅里融化。学生 Qwen3-4B-Instruct-2507 错误地把这看作是纯数学问题,没有考虑物理背景。

【教师模型评分的轨迹示例。深红色的标记对应更高的反向 KL。】
较深颜色代表在教师模型 Qwen3-235B-A22B-Instruct-2507 中受到较高惩罚的标记,该模型正确解决了这个问题。我们看到它惩罚那些引导学生误入歧途的词组起始词组,直觉上对应于用于引导推理的重要"分叉词"。