vLLM v1 Attention --- 系统级架构深度分析
分析范围:
vllm/v1/attention/目录,53个Python文件,~25.8K行代码。Attention 是 v1 推理系统的"计算核心"------所有 GPU 上实际发生的 Attention 计算都由本模块驱动。
Dark Terminal 风格架构图 10 张,见
diagrams/子目录。
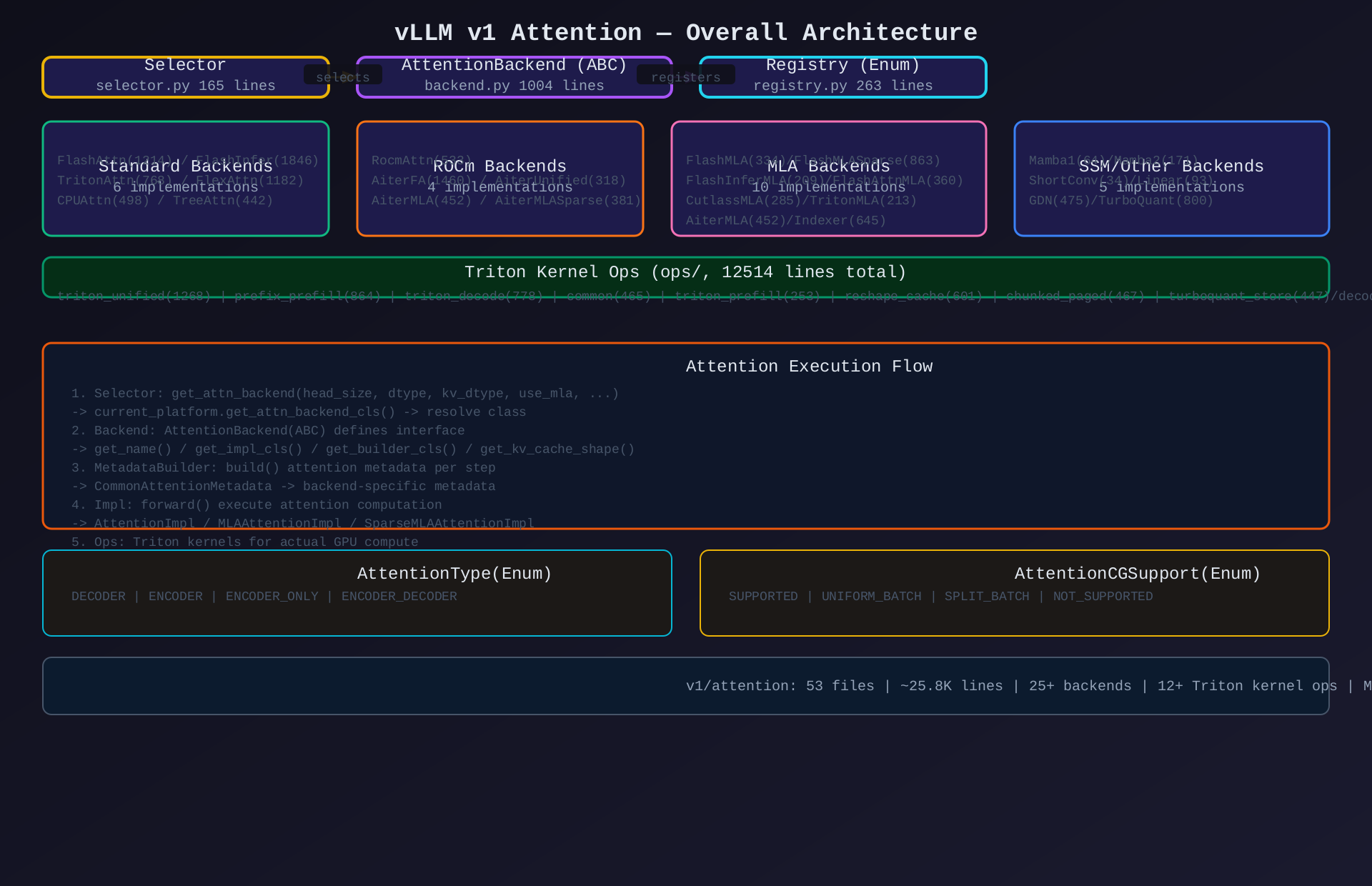
一、整体架构概览
1.1 设计思路
v1 Attention 采用 插件式架构 + 策略选择 设计:
- 抽象基类统一接口 :
AttentionBackend(ABC)定义所有 Attention 后端的契约 - 25+后端可插拔:FlashAttention / FlashInfer / Triton / MLA / ROCm / CPU / SSM 等
- 自动选择机制 :
get_attn_backend()根据硬件/模型/配置自动选择最优后端 - 三层分离:Backend(接口)→ MetadataBuilder(元数据构建)→ Impl(执行)→ Ops(Triton内核)
- 运行时可覆盖 :
register_backend()支持运行时替换任意后端实现
核心设计哲学:
- 硬件适配:不同 GPU 平台(NVIDIA/AMD/Intel/CPU)有不同最优后端
- 模型适配:MLA / Mamba / GDN / TurboQuant 等特殊注意力机制有专属后端
- 性能优先:FlashInfer(1846行)和FlashAttn(1214行)是最优化的两个后端
- 可扩展性 :
AttentionBackendEnum.CUSTOM+register_backend()支持第三方扩展
1.2 架构模式
| 模式 | 应用 |
|---|---|
| 策略模式 | 25+ AttentionBackend 实现,按场景选择 |
| 插件式架构 | 每个后端独立文件,可插拔注册 |
| 工厂方法 | get_attn_backend() 自动选择最优后端 |
| 模板方法 | AttentionMetadataBuilder.build() 统一流程 |
| 注册表模式 | AttentionBackendEnum + register_backend() 运行时注册 |
| 三层分离 | Backend → MetadataBuilder → Impl → Ops |
| 适配器模式 | RayWorkerWrapper 适配不同后端到统一接口 |
1.3 整体运行流程
Model.__init__()
├── get_attn_backend(head_size, dtype, use_mla, ...)
│ ├── Build AttentionSelectorConfig
│ ├── current_platform.get_attn_backend_cls()
│ └── resolve_obj_by_qualname() -> AttentionBackend subclass
├── backend.get_impl_cls() -> AttentionImpl
└── backend.get_builder_cls() -> MetadataBuilder
Model.forward()
├── builder.build(common_attn_metadata) -> backend-specific metadata
├── impl.forward(query, key, value, kv_cache, attn_metadata)
│ ├── Prefill: batch prefill kernel
│ ├── Decode: batch decode kernel
│ └── KV cache update: rope + cache store
└── Return attention output二、子模块划分
模块1:AttentionBackend ABC(backend.py,1004行)
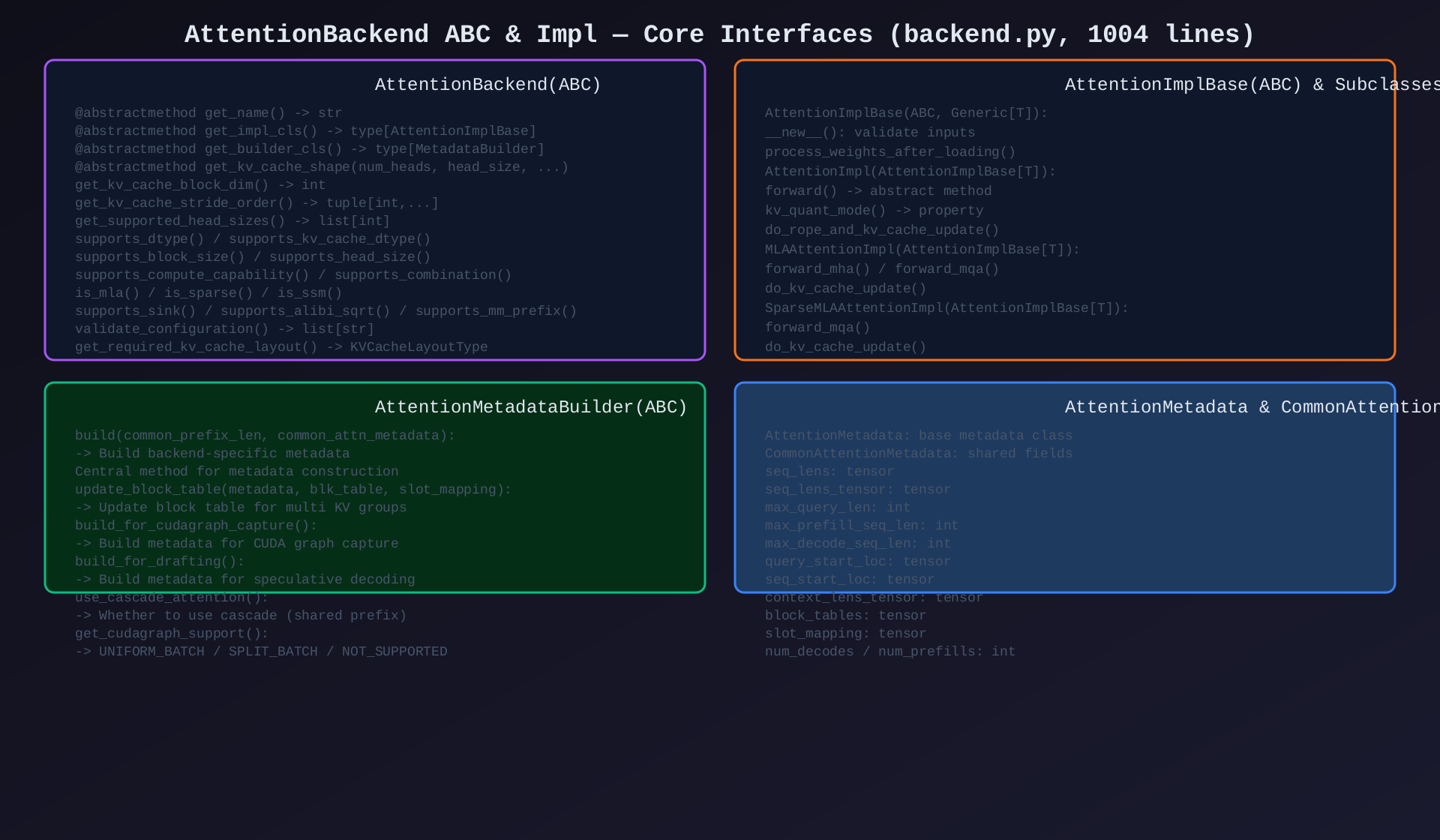
核心作用:所有 Attention 后端的抽象基类------定义统一接口、元数据构建器、执行实现三层契约。
关键类/方法:
| 类/方法 | 类型 | 说明 |
|---|---|---|
AttentionType(str, Enum) |
枚举 | DECODER / ENCODER / ENCODER_ONLY / ENCODER_DECODER |
MultipleOf |
工具类 | Block size 约束(必须是某数的倍数) |
AttentionBackend(ABC) |
抽象类 | 所有后端的基类 |
AttentionMetadata |
数据类 | Attention 元数据基类 |
CommonAttentionMetadata |
数据类 | 公共元数据(seq_lens, block_tables 等) |
AttentionCGSupport(Enum) |
枚举 | CUDA Graph 支持级别 |
AttentionMetadataBuilder(ABC) |
抽象类 | 元数据构建器基类 |
AttentionLayer(Protocol) |
协议 | Attention 层接口 |
AttentionImplBase(ABC) |
抽象类 | Attention 实现基类 |
AttentionImpl |
类 | 标准 Attention 实现(支持 kv_quant) |
MLAAttentionImpl |
类 | MLA Attention 实现(forward_mha/forward_mqa) |
SparseMLAAttentionImpl |
类 | 稀疏 MLA 实现(top-k 路由) |
subclass_attention_backend() |
函数 | 动态创建后端子类 |
subclass_attention_backend_with_overrides() |
函数 | 带覆盖的子类创建 |
AttentionBackend 抽象方法:
| 方法 | 说明 |
|---|---|
get_name() |
返回后端名称字符串 |
get_impl_cls() |
返回 AttentionImpl 子类 |
get_builder_cls() |
返回 MetadataBuilder 子类 |
get_kv_cache_shape() |
返回 KV Cache 的 tensor 形状 |
AttentionMetadataBuilder 核心方法:
| 方法 | 说明 |
|---|---|
build() |
构建后端特定元数据(核心方法) |
update_block_table() |
更新 block table |
build_for_cudagraph_capture() |
CUDA Graph 捕获用元数据 |
build_for_drafting() |
投机解码用元数据 |
use_cascade_attention() |
是否使用级联注意力 |
get_cudagraph_support() |
CUDA Graph 支持级别 |
架构图 :见 02-backend-abc.svg
模块2:Attention Selector(selector.py,165行)
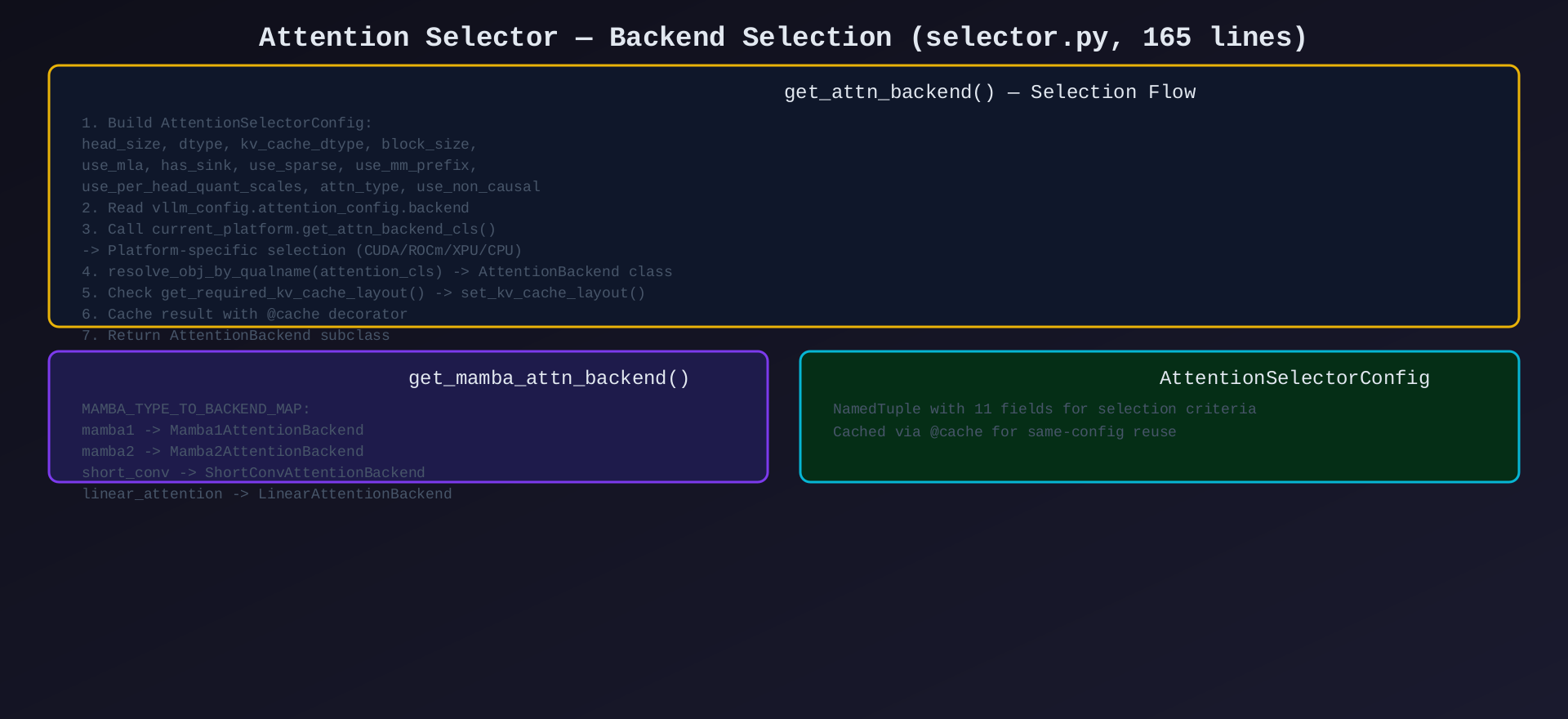
核心作用:自动选择最优 Attention 后端------根据硬件能力、模型配置、运行时参数选择。
关键函数/类:
| 函数/类 | 说明 |
|---|---|
AttentionSelectorConfig(NamedTuple) |
选择器配置:11个字段的命名元组 |
get_attn_backend() |
主选择函数:构建配置 → 平台选择 → 解析类 |
_cached_get_attn_backend() |
缓存版本:@cache 避免重复选择 |
get_mamba_attn_backend() |
Mamba 后端选择:按 mamba_type 映射 |
_cached_get_mamba_attn_backend() |
缓存版本 |
选择流程:
- 构建
AttentionSelectorConfig(head_size, dtype, kv_cache_dtype, block_size, use_mla, has_sink, use_sparse, ...) - 读取
vllm_config.attention_config.backend - 调用
current_platform.get_attn_backend_cls()(平台特定选择逻辑) resolve_obj_by_qualname()→ 实际后端类- 检查
get_required_kv_cache_layout()→ 设置 KV Cache 布局 @cache缓存结果,同配置不重复选择
架构图 :见 03-selector.svg
模块3:Backend Registry(registry.py,263行)
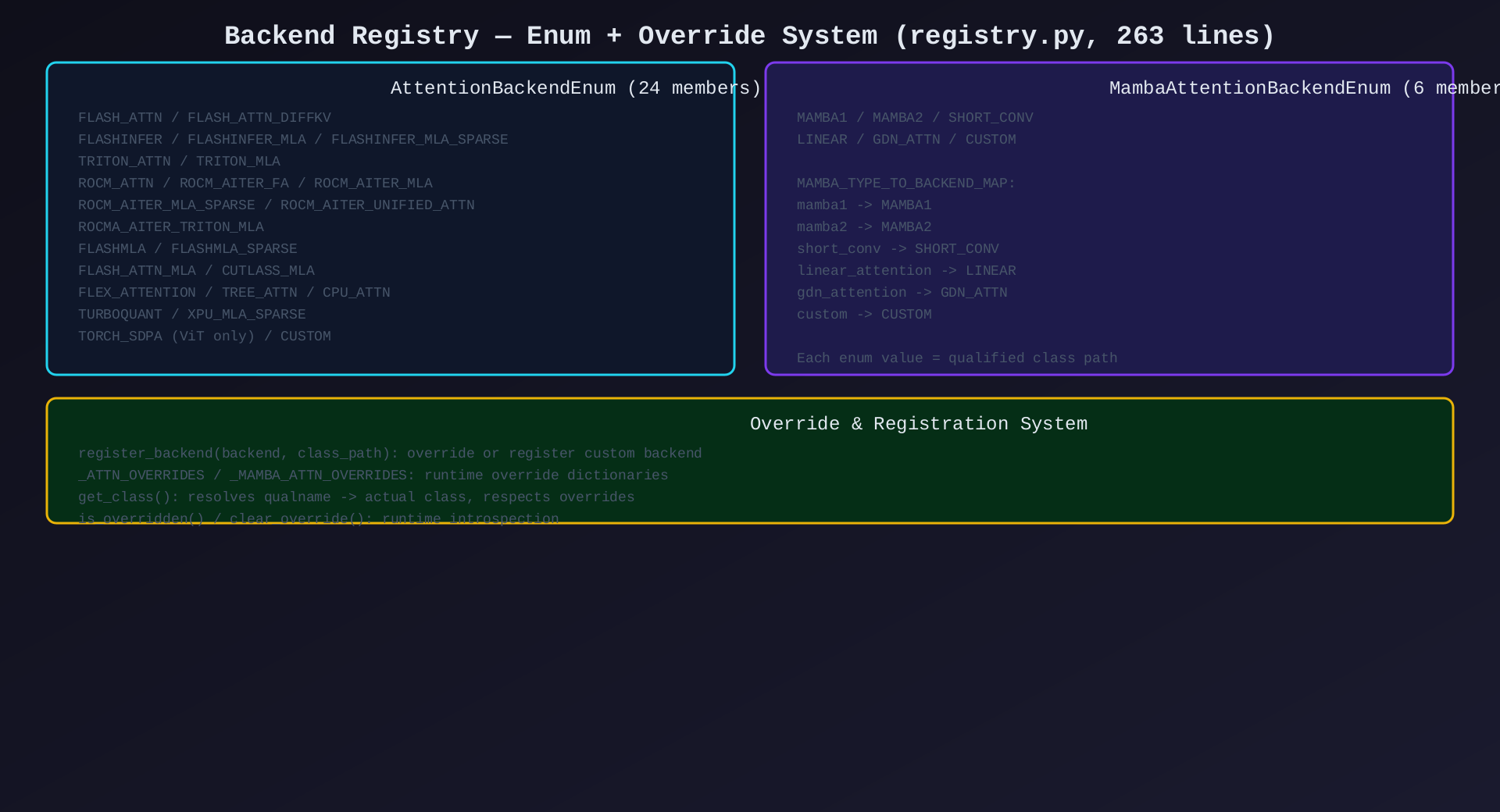
核心作用:Attention 后端注册表------枚举所有支持的后端 + 运行时覆盖机制。
关键类/函数:
| 类/函数 | 说明 |
|---|---|
AttentionBackendEnum(Enum) |
24个标准后端枚举(FLASH_ATTN, FLASHINFER, ...) |
MambaAttentionBackendEnum(Enum) |
6个 Mamba 后端枚举 |
MAMBA_TYPE_TO_BACKEND_MAP |
mamba_type → 枚举名映射 |
register_backend() |
注册/覆盖后端(支持装饰器用法) |
_ATTN_OVERRIDES |
运行时覆盖字典 |
_MAMBA_ATTN_OVERRIDES |
Mamba 运行时覆盖字典 |
枚举成员:
| 类别 | 后端 |
|---|---|
| 标准 | FLASH_ATTN, FLASH_ATTN_DIFFKV, FLASHINFER, TRITON_ATTN, FLEX_ATTENTION, TREE_ATTN, CPU_ATTN, TORCH_SDPA |
| MLA | FLASHMLA, FLASHMLA_SPARSE, FLASH_ATTN_MLA, FLASHINFER_MLA, FLASHINFER_MLA_SPARSE, TRITON_MLA, CUTLASS_MLA |
| ROCm | ROCM_ATTN, ROCM_AITER_FA, ROCM_AITER_MLA, ROCM_AITER_MLA_SPARSE, ROCM_AITER_UNIFIED_ATTN, ROCM_AITER_TRITON_MLA |
| XPU | XPU_MLA_SPARSE |
| 量化 | TURBOQUANT |
| SSM | MAMBA1, MAMBA2, SHORT_CONV, LINEAR, GDN_ATTN |
| 自定义 | CUSTOM(需注册后使用) |
架构图 :见 04-registry.svg
模块4:FlashInfer Backend(backends/flashinfer.py,1846行)
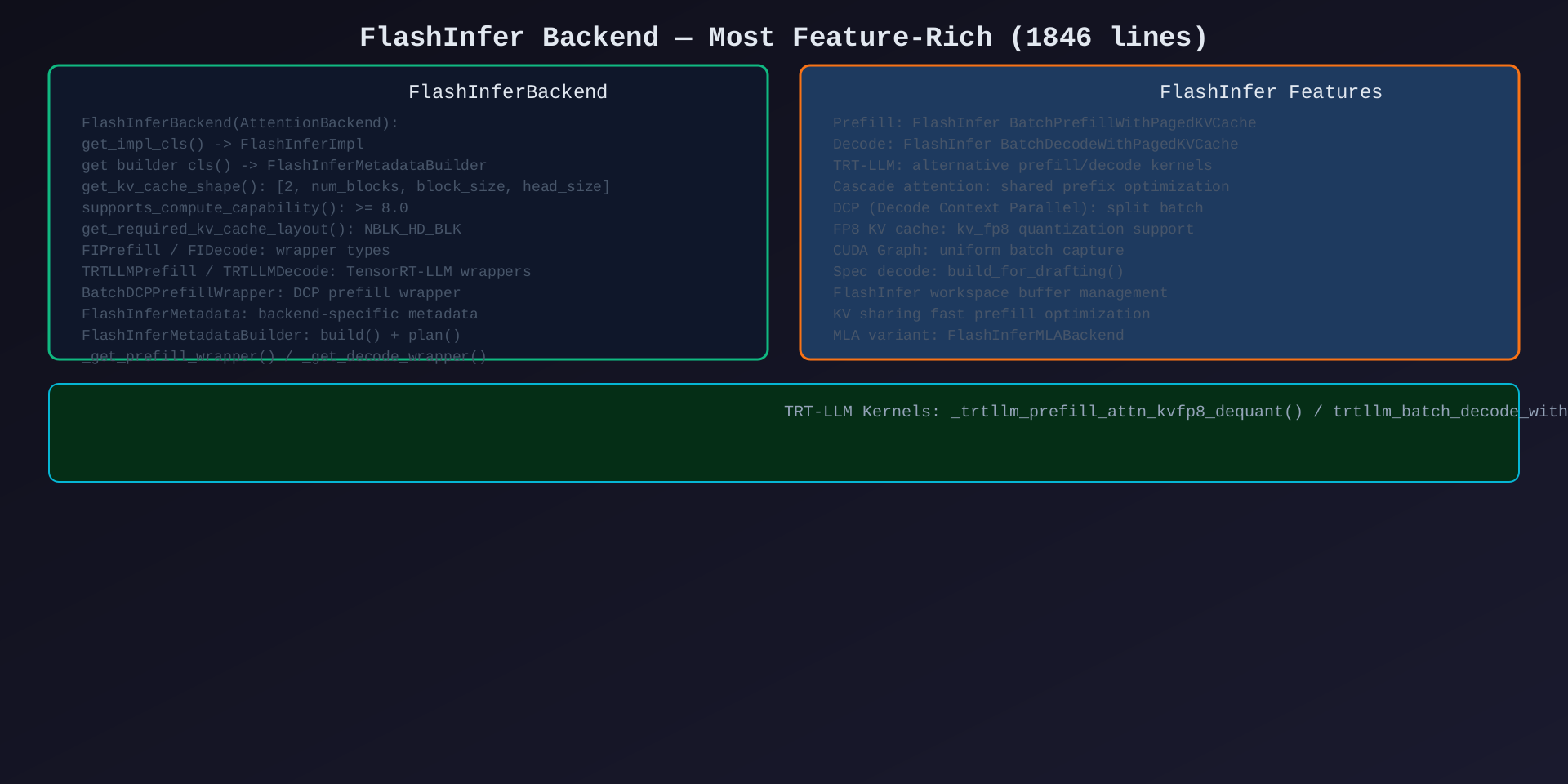
核心作用:最功能丰富的 Attention 后端------基于 FlashInfer 库,支持 prefill/decode/TRT-LLM/cascade/FP8。
关键类/方法:
| 类/方法 | 说明 |
|---|---|
FlashInferBackend(AttentionBackend) |
后端定义 |
FlashInferImpl(AttentionImpl) |
实现类 |
FlashInferMetadata |
后端特定元数据 |
FlashInferMetadataBuilder |
元数据构建器(700+行,最复杂) |
FIPrefill / FIDecode |
FlashInfer 预填充/解码包装器类型 |
TRTLLMPrefill / TRTLLMDecode |
TensorRT-LLM 内核包装器 |
BatchDCPPrefillWrapper |
DCP 预填充包装器 |
FlashInferMetadataBuilder 关键方法:
| 方法 | 说明 |
|---|---|
build() |
构建元数据(plan + 分配 workspace) |
_get_prefill_wrapper() |
获取/创建 FlashInfer prefill wrapper |
_get_decode_wrapper() |
获取/创建 FlashInfer decode wrapper |
_get_cascade_wrapper() |
获取 cascade attention wrapper |
_compute_flashinfer_kv_metadata() |
计算 KV 元数据 |
_make_buffer() |
创建 workspace buffer |
get_cudagraph_support() |
UNIFORM_BATCH |
特色功能:
- FlashInfer BatchPrefillWithPagedKVCache / BatchDecodeWithPagedKVCache
- TRT-LLM FP8 MLA decode 内核
- Cascade attention(共享前缀优化)
- DCP(Decode Context Parallel)支持
- KV sharing fast prefill 优化
- FP8 KV cache(e5m2/e4m3)
架构图 :见 05-flashinfer-backend.svg
模块5:FlashAttention Backend(backends/flash_attn.py,1214行 + fa_utils.py 236行)
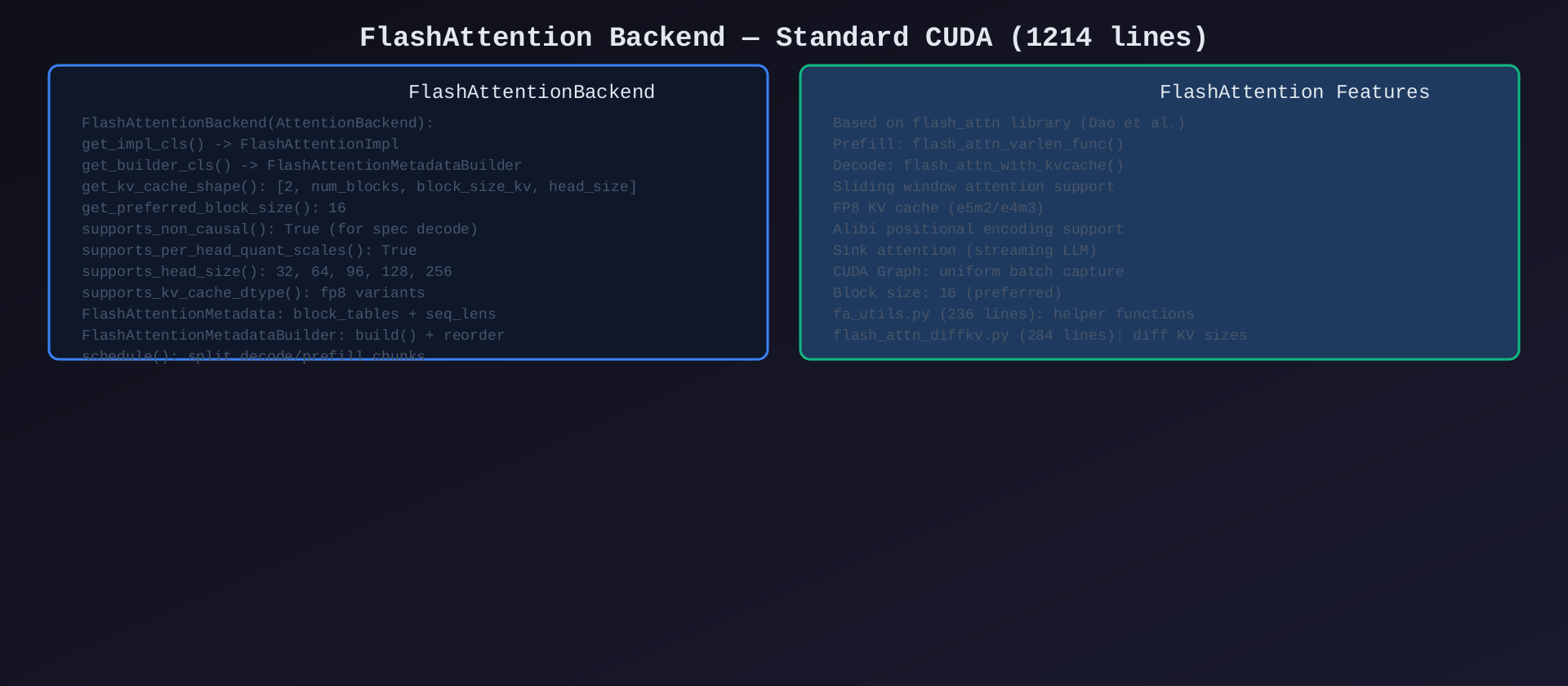
核心作用:标准 CUDA Attention 后端------基于 flash_attn 库,最广泛使用的后端。
关键类/方法:
| 类/方法 | 说明 |
|---|---|
FlashAttentionBackend(AttentionBackend) |
后端定义 |
FlashAttentionImpl(AttentionImpl) |
实现类 |
FlashAttentionMetadata |
元数据(block_tables + seq_lens) |
FlashAttentionMetadataBuilder |
元数据构建器 |
FlashAttentionMetadataBuilder 特色:
schedule():内部函数,将 decode/prefill 分块调度- 支持滑动窗口注意力配置
- Block size = 16(preferred)
- FP8 KV cache 支持
- Alibi 位置编码支持
- Sink attention(StreamingLLM)支持
关联文件:
fa_utils.py(236行):FlashAttention 辅助函数flash_attn_diffkv.py(284行):支持不同 KV head 数的变体
架构图 :见 06-flashattn-backend.svg
模块6:MLA Backends(backends/mla/,9文件,~3.7K行)
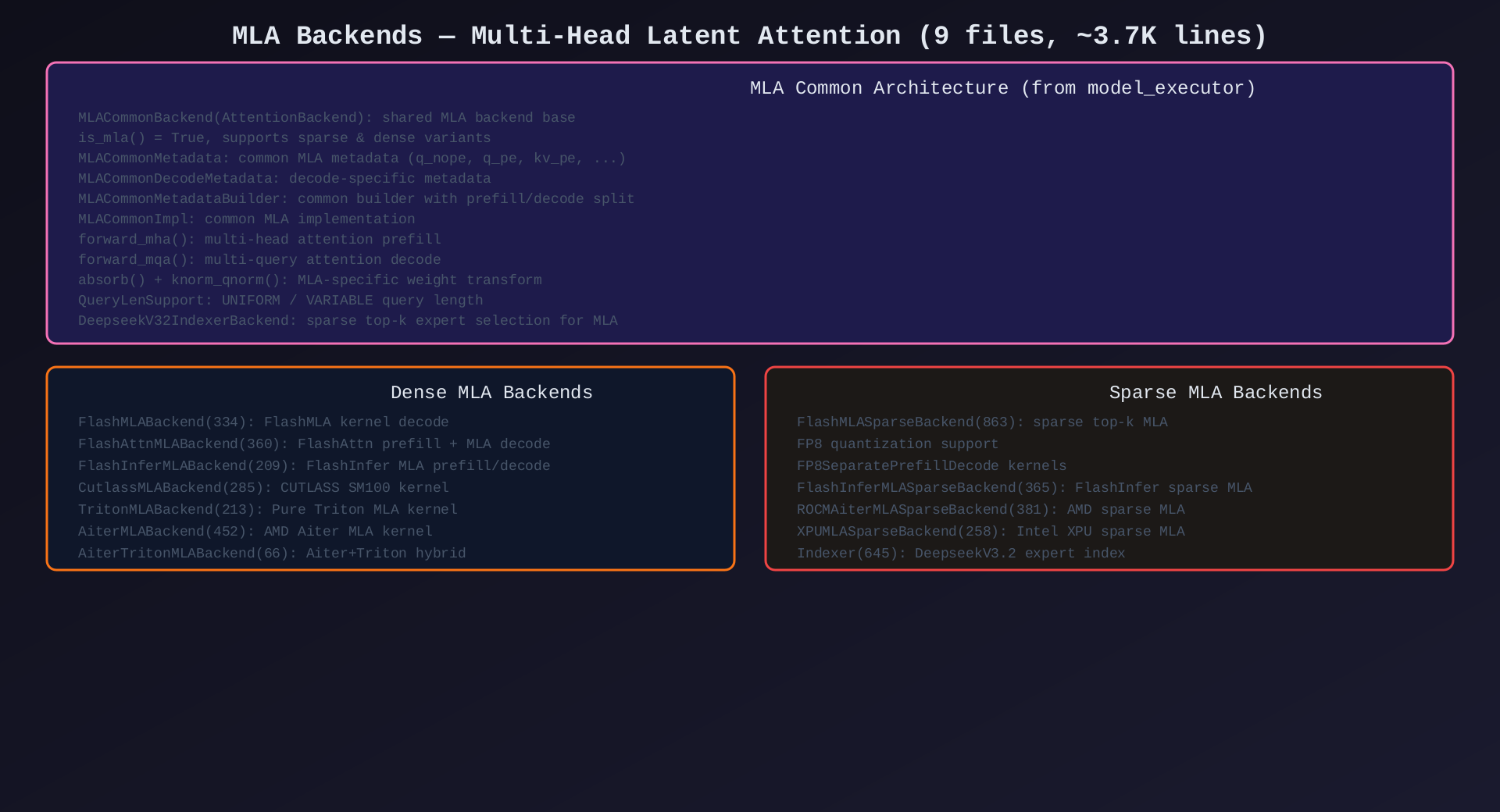
核心作用:Multi-Head Latent Attention 后端------Deepseek V3.2 风格的低秩注意力,支持 dense 和 sparse 两种模式。
公共基类(来自 model_executor):
| 基类 | 说明 |
|---|---|
MLACommonBackend |
MLA 公共后端基类(is_mla=True) |
MLACommonMetadata |
MLA 公共元数据 |
MLACommonDecodeMetadata |
MLA 解码特定元数据 |
MLACommonMetadataBuilder |
MLA 公共构建器 |
MLACommonImpl |
MLA 公共实现(forward_mha/forward_mqa) |
QueryLenSupport |
UNIFORM / VARIABLE 查询长度支持 |
Dense MLA 实现(7个):
| 后端 | 行数 | 内核 | 说明 |
|---|---|---|---|
| FlashMLABackend | 334 | FlashMLA | FlashMLA 内核(decode 最优) |
| FlashAttnMLABackend | 360 | FlashAttn prefill + MLA decode | 混合内核 |
| FlashInferMLABackend | 209 | FlashInfer MLA | FlashInfer + TRT-LLM |
| CutlassMLABackend | 285 | CUTLASS SM100 | NVIDIA SM100 专用 |
| TritonMLABackend | 213 | 纯 Triton | 纯 Triton 实现 |
| AiterMLABackend | 452 | AMD Aiter | AMD ROCm 专用 |
| AiterTritonMLABackend | 66 | Aiter+Triton | AMD 混合实现 |
Sparse MLA 实现(4个):
| 后端 | 行数 | 说明 |
|---|---|---|
| FlashMLASparseBackend | 863 | 最完整的 sparse MLA(FP8 量化支持) |
| FlashInferMLASparseBackend | 365 | FlashInfer sparse MLA |
| ROCMAiterMLASparseBackend | 381 | AMD sparse MLA |
| XPUMLASparseBackend | 258 | Intel XPU sparse MLA |
Indexer(645行):DeepseekV3.2 风格的 sparse expert index------top-k 路由选择相关 KV 块。
架构图 :见 07-mla-backends.svg
模块7:其他标准后端
TritonAttention(backends/triton_attn.py,768行):
- 纯 Triton 内核实现,不依赖外部库
TritonAttentionImpl:使用triton_unified_attention和triton_decode_attention
FlexAttention(backends/flex_attention.py,1182行):
- 基于 PyTorch
torch.nn.attention.flex_attention - 支持 BlockSparsityHint
- 最灵活但性能略低
TreeAttention(backends/tree_attn.py,442行):
- 树状 Attention,用于投机解码验证
CPUAttention(backends/cpu_attn.py,498行):
- CPU 后端,基于
torch.nn.functional.scaled_dot_product_attention
ROCm 后端(4个文件):
RocmAttentionBackend(533行):ROCm 基础后端AiterFlashAttentionBackend(1460行):AMD Aiter FARocmAiterUnifiedAttention(318行):统一 ROCm 后端
TurboQuant(backends/turboquant_attn.py,800行):
- FP8 量化 Attention,配合 Triton decode 内核
SSM 后端(5个文件,总计 ~326行):
- Mamba1 / Mamba2 / ShortConv / LinearAttention / GDN
模块8:Triton Kernel Ops(ops/,12文件,~12.5K行)
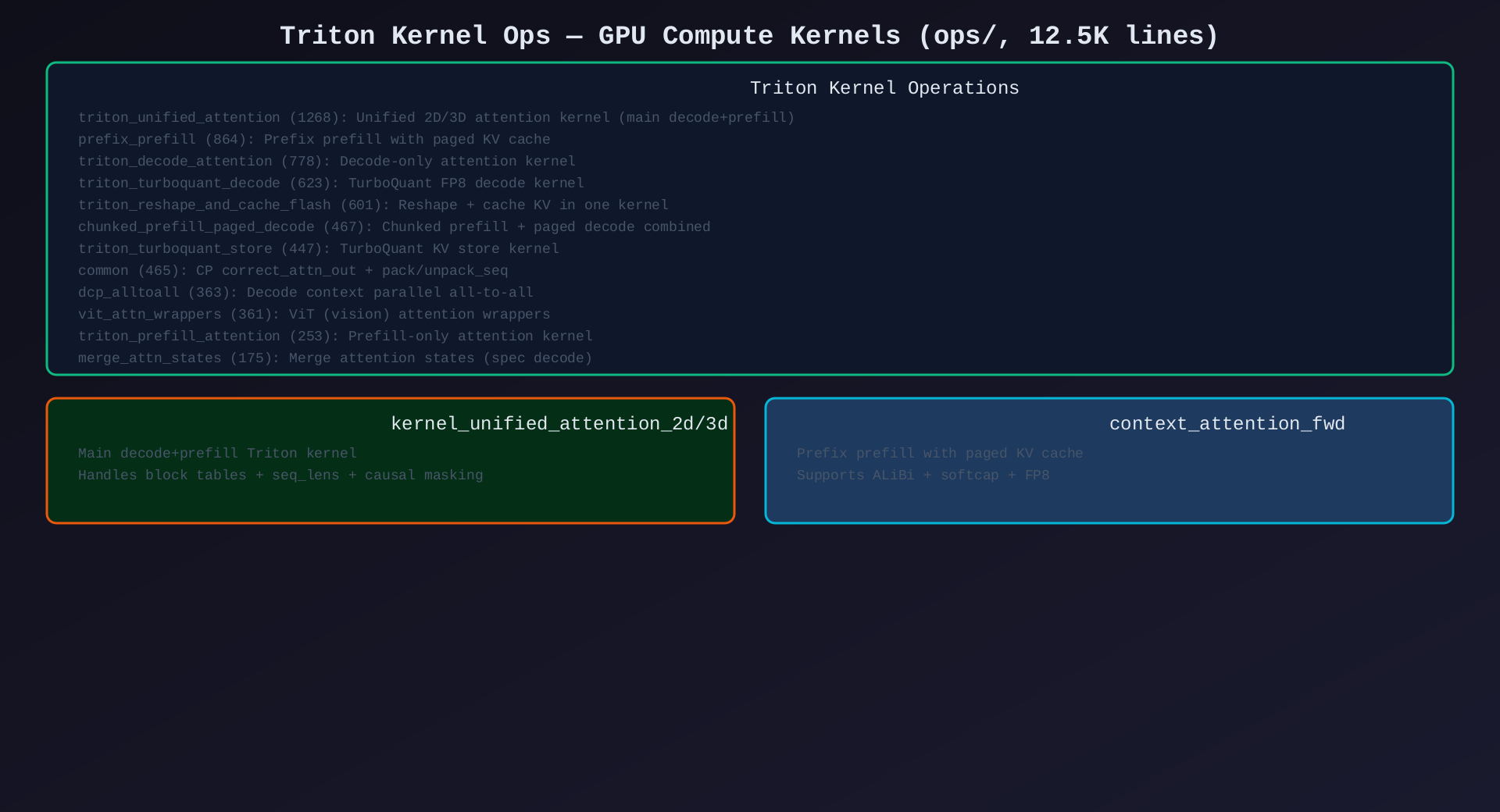
核心作用:Triton GPU 内核------Attention 计算的实际执行者,纯 GPU 编程。
关键内核:
| 文件 | 行数 | 内核函数 | 说明 |
|---|---|---|---|
triton_unified_attention.py |
1268 | kernel_unified_attention_2d/3d |
统一 decode+prefill 内核 |
prefix_prefill.py |
864 | context_attention_fwd |
Prefix prefill + paged KV |
triton_decode_attention.py |
778 | decode 内核 | 解码专用内核 |
triton_turboquant_decode.py |
623 | TurboQuant decode | FP8 量化解码 |
triton_reshape_and_cache_flash.py |
601 | reshape+cache | KV reshape + cache store |
chunked_prefill_paged_decode.py |
467 | chunked prefill | 分块 prefill + paged decode |
common.py |
465 | correct_attn_out + pack_seq |
CP 修正 + 序列打包 |
triton_turboquant_store.py |
447 | TurboQuant store | FP8 KV store |
dcp_alltoall.py |
363 | DCP all-to-all | Decode Context Parallel 通信 |
vit_attn_wrappers.py |
361 | ViT wrappers | 视觉 Transformer 注意力 |
triton_prefill_attention.py |
253 | prefill 内核 | 纯 prefill 内核 |
merge_attn_states.py |
175 | merge states | Attention 状态合并(spec decode) |
flashmla.py |
153 | FlashMLA 内核 | FlashMLA 调用 |
paged_attn.py |
51 | paged attention | 分页注意力辅助 |
架构图 :见 08-triton-ops.svg
模块9:Utils & Helpers(backends/utils.py,892行)
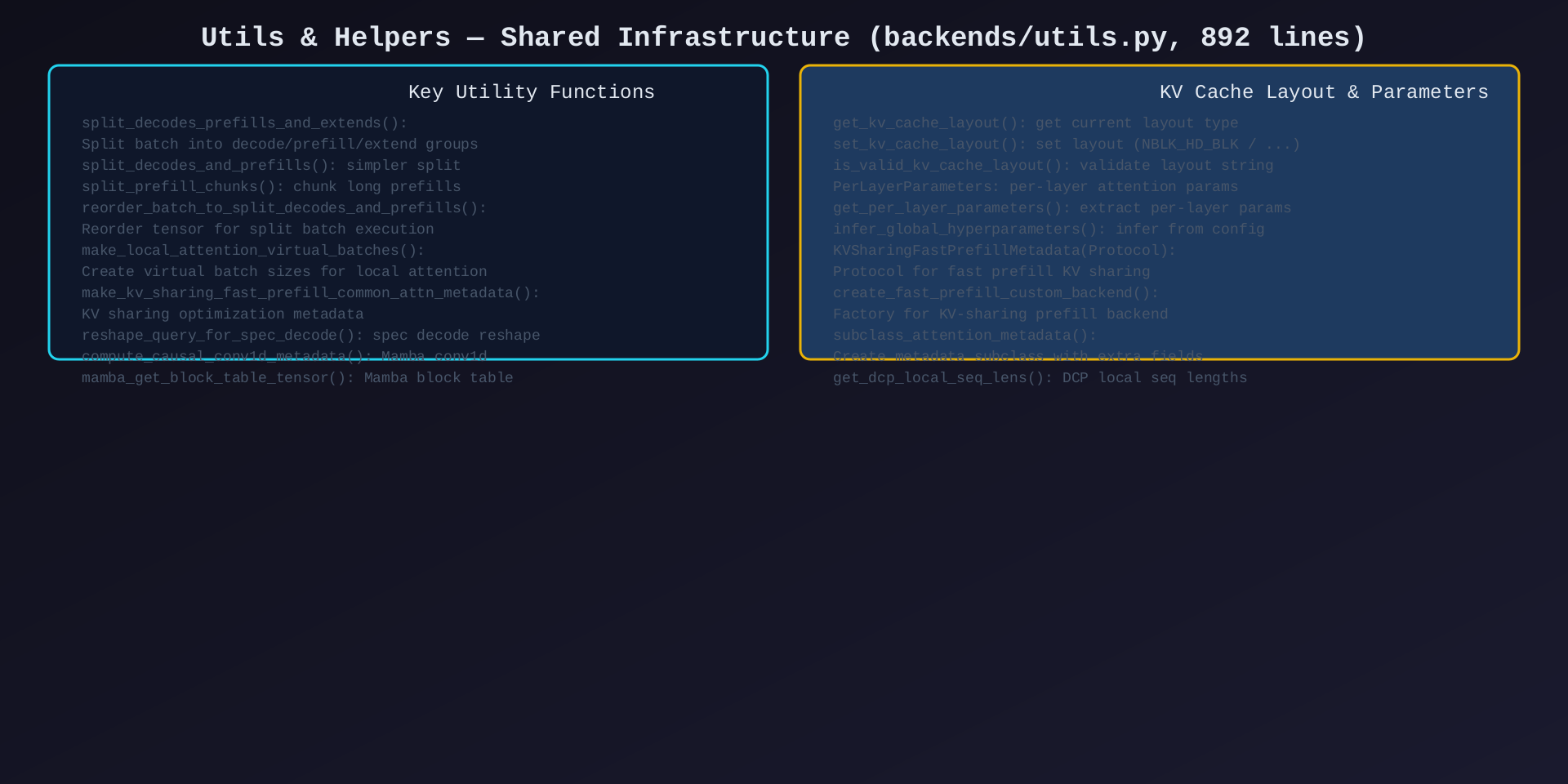
核心作用:共享基础设施------batch 分割、KV 布局管理、参数推断、快速 prefill 优化。
关键函数:
| 函数 | 说明 |
|---|---|
split_decodes_prefills_and_extends() |
将 batch 分为 decode/prefill/extend 三组 |
split_decodes_and_prefills() |
简化版:decode/prefill 两组 |
split_prefill_chunks() |
将长 prefill 分块 |
reorder_batch_to_split_decodes_and_prefills() |
重排 tensor 适配分割执行 |
make_local_attention_virtual_batches() |
创建虚拟 batch 大小 |
make_kv_sharing_fast_prefill_common_attn_metadata() |
KV 共享快速 prefill 元数据 |
reshape_query_for_spec_decode() |
投机解码 query 重塑 |
compute_causal_conv1d_metadata() |
Mamba causal conv1d 元数据 |
mamba_get_block_table_tensor() |
Mamba block table |
get_kv_cache_layout() / set_kv_cache_layout() |
KV Cache 布局管理 |
PerLayerParameters |
每层 Attention 参数 |
get_per_layer_parameters() |
提取每层参数 |
infer_global_hyperparameters() |
推断全局超参数 |
create_fast_prefill_custom_backend() |
工厂:创建 KV 共享 prefill 后端 |
subclass_attention_metadata() |
动态创建元数据子类 |
get_dcp_local_seq_lens() |
DCP 本地序列长度 |
架构图 :见 09-utils-helpers.svg
三、模块调用关系与数据流
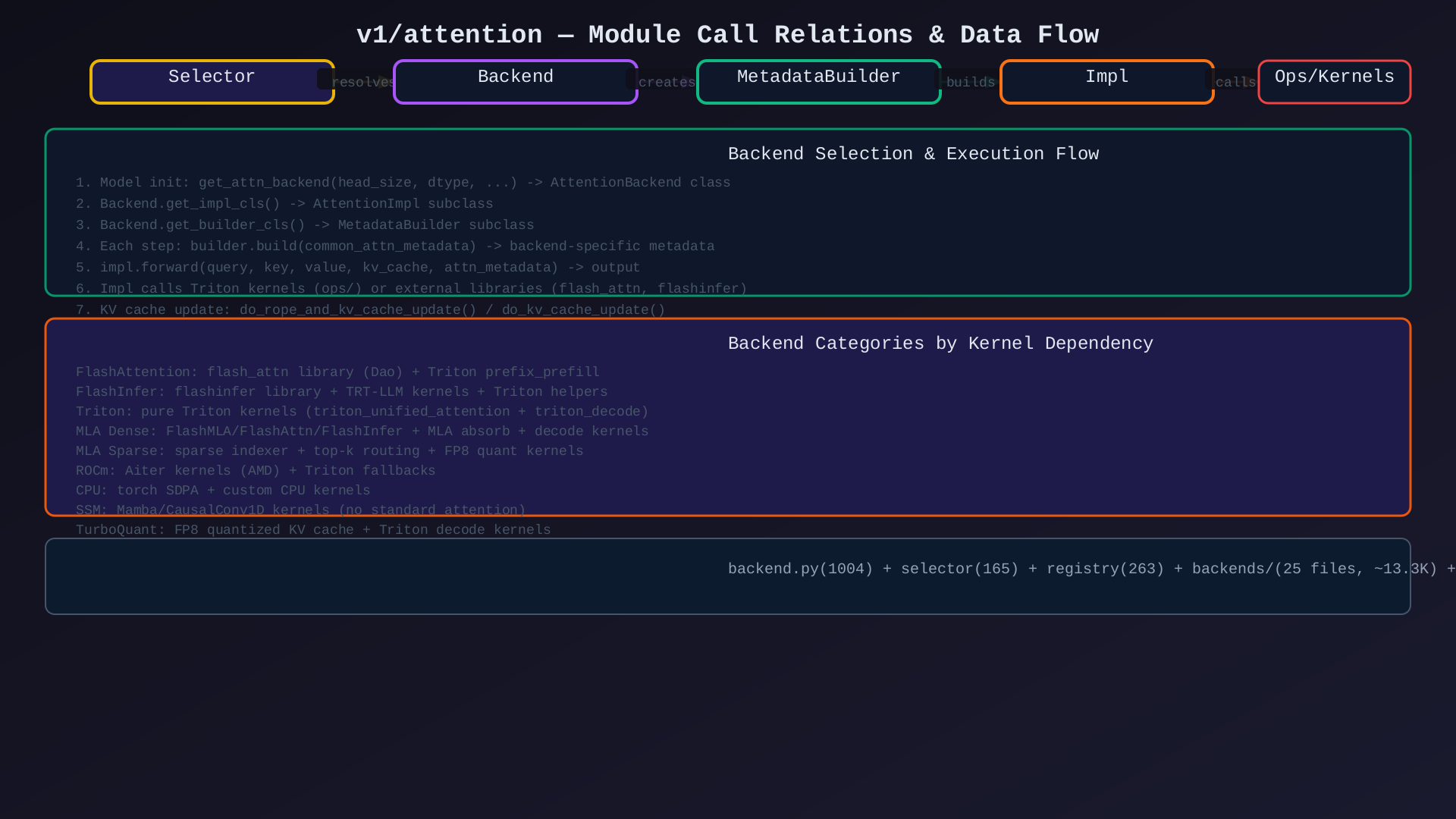
3.1 主要调用链
Model.__init__()
↓
get_attn_backend(head_size, dtype, use_mla, ...)
↓
AttentionSelectorConfig → current_platform.get_attn_backend_cls()
↓
resolve_obj_by_qualname() → AttentionBackend subclass
↓
backend.get_impl_cls() → AttentionImpl
backend.get_builder_cls() → MetadataBuilder
Model.forward()
↓
builder.build(common_prefix_len, common_attn_metadata)
↓ backend-specific metadata
impl.forward(query, key, value, kv_cache, attn_metadata)
├── Prefill: batch prefill kernel (FlashInfer/FlashAttn/Triton)
├── Decode: batch decode kernel
├── MLA: forward_mha() (prefill) / forward_mqa() (decode)
├── Sparse MLA: indexer → top-k routing → sparse decode
└── KV cache update: do_rope_and_kv_cache_update()
↓
Attention output tensor3.2 后端选择链
Platform (CUDA/ROCm/XPU/CPU)
↓
get_attn_backend_cls(backend_name, config)
↓
AttentionBackendEnum[backend_name].get_class()
↓ (respects overrides)
resolve_obj_by_qualname(class_path)
↓
AttentionBackend subclass (e.g., FlashInferBackend)3.3 关键交互
| 调用方 | 被调用方 | 数据 | 方式 |
|---|---|---|---|
| Model | Selector | config参数 | 函数调用 |
| Selector | Platform | backend_name + config | 方法调用 |
| Platform | Registry | enum → class_path | qualname解析 |
| Model | Backend | 接口查询 | 方法调用 |
| Model | MetadataBuilder | common_attn_metadata | build() |
| Model | Impl | query/key/value/kv_cache/metadata | forward() |
| Impl | Triton Ops | tensor + metadata | kernel launch |
| Impl | flash_attn/flashinfer | tensor + metadata | library call |
| MetadataBuilder | Utils | batch分割/重排 | 函数调用 |
四、设计模式总结
| 模式 | 应用位置 | 说明 |
|---|---|---|
| 策略模式 | 25+ AttentionBackend | 按硬件/模型选择最优实现 |
| 插件式架构 | backends/ 目录 | 每个后端独立文件,可插拔 |
| 工厂方法 | get_attn_backend() | 自动选择后端 |
| 模板方法 | MetadataBuilder.build() | 统一构建流程 |
| 注册表模式 | AttentionBackendEnum | 运行时注册+覆盖 |
| 三层分离 | Backend→Builder→Impl | 接口/构建/执行解耦 |
| 装饰器注册 | register_backend() | 装饰器方式注册自定义后端 |
| 缓存策略 | @cache | 同配置不重复选择 |
五、关键指标
| 指标 | 数值 |
|---|---|
| Attention 总代码量 | ~25.8K 行(53 文件) |
| backend.py | 1004 行(核心 ABC) |
| FlashInfer 后端 | 1846 行(最大单文件) |
| Triton Ops 总量 | ~12.5K 行 |
| Attention 后端数量 | 25+ |
| MLA 后端数量 | 11(7 dense + 4 sparse) |
| ROCm 后端数量 | 5 |
| SSM 后端数量 | 5 |
| Triton 内核数量 | 14+ |
| AttentionType 类型 | 4(DECODER/ENCODER/ENCODER_ONLY/ENCODER_DECODER) |
| CUDA Graph 支持级别 | 4(SUPPORTED/UNIFORM/SPLIT/NOT_SUPPORTED) |
六、架构亮点与设计权衡
亮点
- 25+后端可插拔:覆盖 NVIDIA/AMD/Intel/CPU 全平台 + MLA/Mamba/GDN/TurboQuant 全模型
- 自动选择机制 :
get_attn_backend()根据硬件能力自动选择最优后端 - 运行时覆盖 :
register_backend()支持第三方后端无侵入式替换 - 三层分离:Backend(接口)→MetadataBuilder(构建)→Impl(执行),职责清晰
- MLA 系列完整:7个 dense + 4个 sparse + Indexer,覆盖所有 MLA 场景
- FlashInfer 功能最全:1846行,支持 cascade/DCP/TRT-LLM/FP8/spec-decode
- Triton 内核自研:12.5K行纯 Triton 内核,不依赖外部库时也能高效运行
权衡
- 后端数量爆炸:25+后端增加维护成本,MLA 单独就有11个
- MetadataBuilder 最复杂:FlashInferMetadataBuilder 700+行,承担过多职责
- 选择逻辑分散:Platform.get_attn_backend_cls() 在各平台独立实现,逻辑不统一
- MLA 公共基类在外部:MLACommonBackend 等定义在 model_executor 而非 attention 模块
- Sparse MLA 重复:4个 sparse 实现有大量重复逻辑
- Kernel 调度复杂:Triton unified attention 1268行,一个内核处理所有场景
报告生成时间:2026-04-19 | 代码版本:vllm main branch