开篇介绍:
hello 大家,本篇博客我们将承接上篇博客的内容,给大家解析库的原理,相信我,当大家看完这篇文章之后,就会被库的原理所深深震撼到。
OK,话不多说,我们开始啦~
库的原理:
开篇:为什么一定要学 Linux 下的手动编译链接?
Windows 上的 Visual Studio、Dev-C++ 就像 "全自动洗衣机"------ 放进去源码,按个按钮就出可执行程序,方便但 "黑箱"。你永远不知道里面的 "洗衣步骤"(编译、链接)是怎么回事,一旦衣服洗坏了(链接错误),你根本不知道问题出在 "进水"(编译)还是 "脱水"(链接)。
而 Linux 下的 gcc 编译器,就像 "手动洗衣机"------ 你得自己加洗衣粉(参数)、控制水位(编译选项)、手动脱水(链接),虽然步骤多,但能看清整个过程。学会它,你就掌握了 "程序运行的本质":原来源码不是直接变成可执行文件的,中间要经过 "预处理→编译→汇编→链接" 四步,而动静态库就是链接阶段的 "核心工具"。
5. 目标文件:编译后的 "半成品零件箱"(细节到符号表每一字段)
目标文件(.o)是 "预处理→编译→汇编" 三步后的产物,相当于你组装乐高时,厂家按说明书切好的 "单个零件"------ 能直接用,但不能单独拼成成品,必须和其他零件(其他.o 文件)、工具(库文件)拼起来(链接)才行。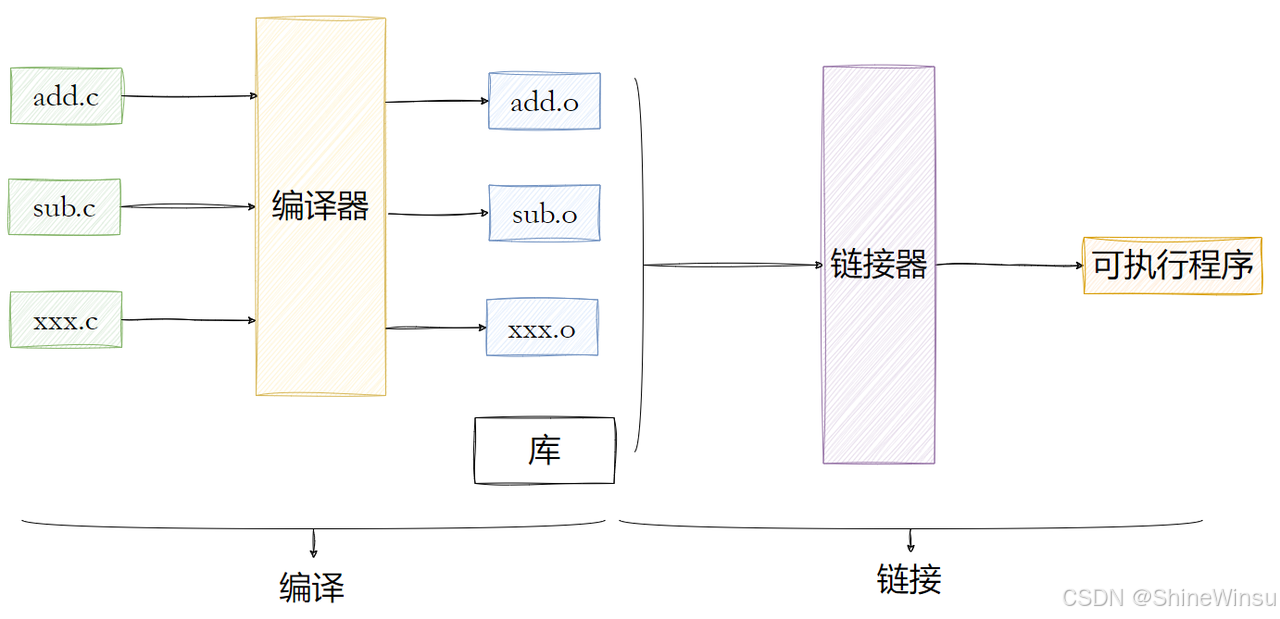
5.1 先搞懂:编译的完整流程(之前简化了,现在详细说!)
很多人以为 "编译" 是一步到位,其实 gcc 的 "编译" 包含三个隐藏步骤:预处理→编译→汇编 ,最终才生成目标文件。我们用hello.c为例,一步步拆解每个步骤的作用:
5.1.1 步骤 1:预处理(替换宏、展开头文件)
预处理的本质是 "文本替换",编译器(cpp)会处理源码中的#include、#define、//注释等,生成.i文件。
实操命令:
gcc -E hello.c -o hello.i # -E:只做预处理,不编译
cat hello.i # 查看预处理结果关键变化(逐句解释):
#include<stdio.h>会被替换成stdio.h头文件的所有内容(几千行代码),而不是保留这一行;- 注释
// 声明run函数会被删除,编译器不认识注释; - 如果有
#define MAX 10,会把源码中所有MAX替换成 10。
5.1.2 步骤 2:编译(翻译成汇编语言)
编译的本质是 "把预处理后的 C 代码,翻译成 CPU 能看懂的'汇编语言'",生成.s文件。汇编语言是 "机器语言的人类可读版",比如push %rbp、mov %rsp,%rbp,对应 CPU 的具体操作。
实操命令:
gcc -S hello.i -o hello.s # -S:只编译到汇编,不汇编
cat hello.s # 查看汇编代码关键输出(简化版):
.file "hello.c"
.text
.section .rodata
.LC0:
.string "hello world!"
.text
.globl main
.type main, @function
main:
.LFB0:
.cfi_startproc
endbr64
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
leaq .LC0(%rip), %rdi
call puts@PLT
movl $0, %eax
call run@PLT
movl $0, %eax
popq %rbp
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE0:
.size main, .-main
.ident "GCC: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0"
.section .note.GNU-stack,"",@progbits.string "hello world!":字符串常量存在.rodata 节;call puts@PLT:调用 puts 函数(printf 被优化),通过 PLT 桩调用;call run@PLT:调用 run 函数,同样通过 PLT 桩。
5.1.3 步骤 3:汇编(翻译成机器指令,生成目标文件)
汇编的本质是 "把汇编语言翻译成 CPU 能直接执行的机器指令(二进制)",生成.o目标文件。这一步会同时生成符号表、重定位表等关键信息,但不会进行链接 ------ 编译器依然不知道run和puts函数的实际地址。
实操命令:
gcc -c hello.s -o hello.o # -c:只汇编,不链接到这里,目标文件就生成了!它不是可执行程序,而是 "带零件清单 + 待修正位置的半成品"。
5.2 目标文件(.o文件)的 "五脏六腑":每个字节都有它的作用
目标文件是二进制文件,但内部结构非常规整(ELF 格式),我们用 "快递盒 + 零件箱" 的比喻,拆解它的 6 个核心组成部分,每个部分都讲清楚 "存什么、有什么用、怎么看":
| 组成部分 | 通俗比喻 | 核心作用 | 查看命令(关键参数) |
|---|---|---|---|
| 机器指令(.text) | 零件的 "组装步骤" | 存储函数的二进制指令(比如 main、run 的执行步骤),CPU 能直接跑 | objdump -d 文件名(反汇编) |
| 已初始化数据(.data) | 零件的 "配件"(比如螺丝) | 存储已初始化的全局变量、静态变量(如int g_val=10),占文件空间 |
readelf -x .data 文件名 |
| 未初始化数据(.bss) | 零件的 "预留安装位" | 存储未初始化的全局变量、静态变量(如int g_uninit),不占文件空间,加载时操作系统分配内存并置 0 |
size 文件名(看 bss 大小) |
| 只读数据(.rodata) | 零件的 "标签"(不可改) | 存储字符串常量(如"hello world!")、const 变量,权限只读,防止修改 |
readelf -x .rodata 文件名 |
| 符号表(.symtab) | 零件清单(有什么 + 要什么) | 记录文件中 "已定义的符号"(如 main、run)和 "未定义的符号"(如 puts、run) | readelf -s 文件名 |
| 重定位表(.rel.text) | 待修正的 "螺丝位置" | 记录.text 节中需要链接时修正的地址(如 call run 的地址) | readelf -r 文件名 |
5.2.1 符号表(.symtab):最关键的 "零件清单"
符号表是链接器的 "核心参考",没有它,链接器就不知道该怎么拼接零件。我们用readelf -s hello.o的输出,逐字段解释每个符号的含义:
readelf -s hello.o关键输出:
Num: Value Size Type Bind Vis Ndx Name
# 序号: 地址值 大小 类型 绑定 可见性 所在节 符号名
0: 0000000000000000 0 NOTYPE LOCAL DEFAULT UND
# 0号:空符号,ELF标准要求,占位用
1: 0000000000000000 0 FILE LOCAL DEFAULT ABS hello.c
# 1号:文件符号,记录这个目标文件来自hello.c
2: 0000000000000000 0 SECTION LOCAL DEFAULT 1
# 2号:节符号,对应第1个节(.text)
3: 0000000000000000 0 SECTION LOCAL DEFAULT 3
# 3号:节符号,对应第3个节(.data)
4: 0000000000000000 0 SECTION LOCAL DEFAULT 4
# 4号:节符号,对应第4个节(.bss)
5: 0000000000000000 0 SECTION LOCAL DEFAULT 6
# 5号:节符号,对应第6个节(.rodata)
6: 0000000000000000 37 FUNC GLOBAL DEFAULT 1 main
# 6号:main函数(重点!)
# Size=37:函数占用37字节;Type=FUNC:类型是函数;Bind=GLOBAL:全局符号(其他文件能调用);Ndx=1:在.text节
7: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND puts
# 7号:puts函数(重点!)
# Type=NOTYPE:无具体类型;Bind=GLOBAL:全局符号;Ndx=UND:未定义(需要从其他文件/库中找)
8: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND run
# 8号:run函数(重点!)
# Ndx=UND:未定义(需要从code.o中找)3 个符号属性:
- Ndx=UND:未定义符号 ------ 当前文件需要,但自己没有,得从其他.o 或库中找(比如 puts、run);
- Ndx = 数字:已定义符号 ------ 当前文件有,存在对应的节中(比如 main 在.text 节,Ndx=1);
- Bind=GLOBAL:全局符号 ------ 可以被其他文件调用(比如 main、run);
- Bind=LOCAL:局部符号 ------ 只能在当前文件中使用(比如静态函数、静态变量)。
5.2.2 重定位表(.rel.text):"待修正的螺丝位置"(逐字段解读)
目标文件中的函数调用地址都是 "占位符"(比如 call run 的地址是 0),重定位表就是记录这些 "占位符位置" 的清单,告诉链接器 "这里需要修正成实际地址"。
用readelf -r hello.o查看重定位表:
readelf -r hello.o关键输出:
Relocation section '.rel.text' at offset 0x308 contains 2 entries:
Offset Info Type Sym. Value Sym. Name + Addend
# 偏移量 信息 类型 符号值 符号名 + 偏移修正
00000000000f 000700000002 R_X86_64_PC32 0000000000000000 puts - 4
# 重点1:Offset=0x0f:.text节中偏移0x0f的位置需要修正
# 重点2:Sym. Name=puts:修正的符号是puts
# 重点3:Type=R_X86_64_PC32:64位x86架构的PC相对寻址重定位(最常见的类型)
# 重点4:Addend=-4:地址计算时需要减去4(PC相对寻址的偏移修正)
000000000019 000800000002 R_X86_64_PC32 0000000000000000 run - 4
# 同理:Offset=0x19的位置,修正run符号的地址,减去4链接器修正地址的公式(新手不用记,了解即可):修正后的地址 = 符号的实际地址 - 当前指令地址 - Addend比如修正 call run 的地址时,链接器会用 run 在合并后.text 节的实际地址,减去当前 call 指令的地址,再减去 4,得到最终的跳转地址。
5.3 目标文件为什么不能直接运行?
很多新手会犯的错误:以为.o文件能直接运行,其实不行,核心原因有 3 个,每个都用生活例子解释:
- 缺少 "零件拼接":hello.o 需要 run 函数的代码,但自己没有,就像你有 "桌腿" 但没有 "桌面",拼不成完整的桌子,没法用;
- 地址都是 "占位符":hello.o 中 call run、call puts 的地址都是 0,就像你知道要 "拧螺丝",但不知道螺丝该拧在哪个位置,没法组装;
- 缺少 "运行环境":目标文件没有程序头表(Program Header Table),操作系统不知道该怎么把它加载到内存(比如哪些部分放内存的哪个位置、权限是什么),就像快递盒上没有 "收货地址",快递员不知道该送哪里。
只有经过 "链接" 步骤,把这些问题都解决,目标文件才能变成 "可执行程序"。
6. ELF 文件:Linux 下的 "万能快递盒"
所有目标文件、可执行程序、动态库、静态库(.a 中的.o),本质上都是 "ELF 文件"------ 它是 Linux 系统下的 "统一文件格式标准",就像全世界的快递都用标准尺寸的盒子,不管里面装的是零件(.o)、成品(可执行程序)还是工具包(.so),快递员(编译器)、仓库管理员(链接器)、收件人(操作系统)都能看懂。
6.1 ELF 文件的 "身份证":魔数(Magic Number)
每个 ELF 文件的最开头,都有 4 个字节的 "魔数":0x7f 0x45 0x4c 0x46,对应 ASCII 码的^?ELF------ 这是 ELF 文件的 "身份证",操作系统一看到这 4 个字节,就知道 "这是 ELF 文件,我认识,可以处理"。
用hexdump命令查看 ELF 文件的魔数:
hexdump -C hello.o | head -1输出:
00000000 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00 |.ELF............|- 前 4 个字节
7f 45 4c 46:魔数,确认是 ELF 文件; - 第 5 个字节
02:ELF 文件类别(01=32 位,02=64 位); - 第 6 个字节
01:数据编码方式(01 = 小端序,02 = 大端序); - 第 7 个字节
01:ELF 版本(当前版本都是 1)。
6.2 字节序:小端序 vs 大端序
很多新手看到 "小端序""大端序" 就头疼,其实很简单,用 "数字存储方式" 比喻:
- 小端序(Little Endian):低字节存低地址,高字节存高地址 ------ 就像你写数字 "1234",按 "4、3、2、1" 的顺序存(先存个位,再存十位);
- 大端序(Big Endian):高字节存低地址,低字节存高地5址 ------ 就像你写数字 "1234",按 "1、2、3、4" 的顺序存(先存千位,再存百位)。
x86-64 架构(我们常用的电脑 CPU)都是小端序,ELF 文件默认也是小端序 ------ 这就是为什么你在反汇编时看到的地址是 "0x4005d0",而不是 "0xd00540"。
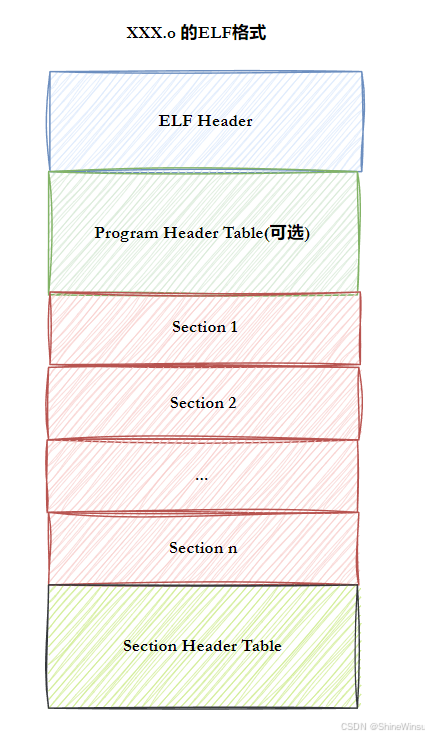
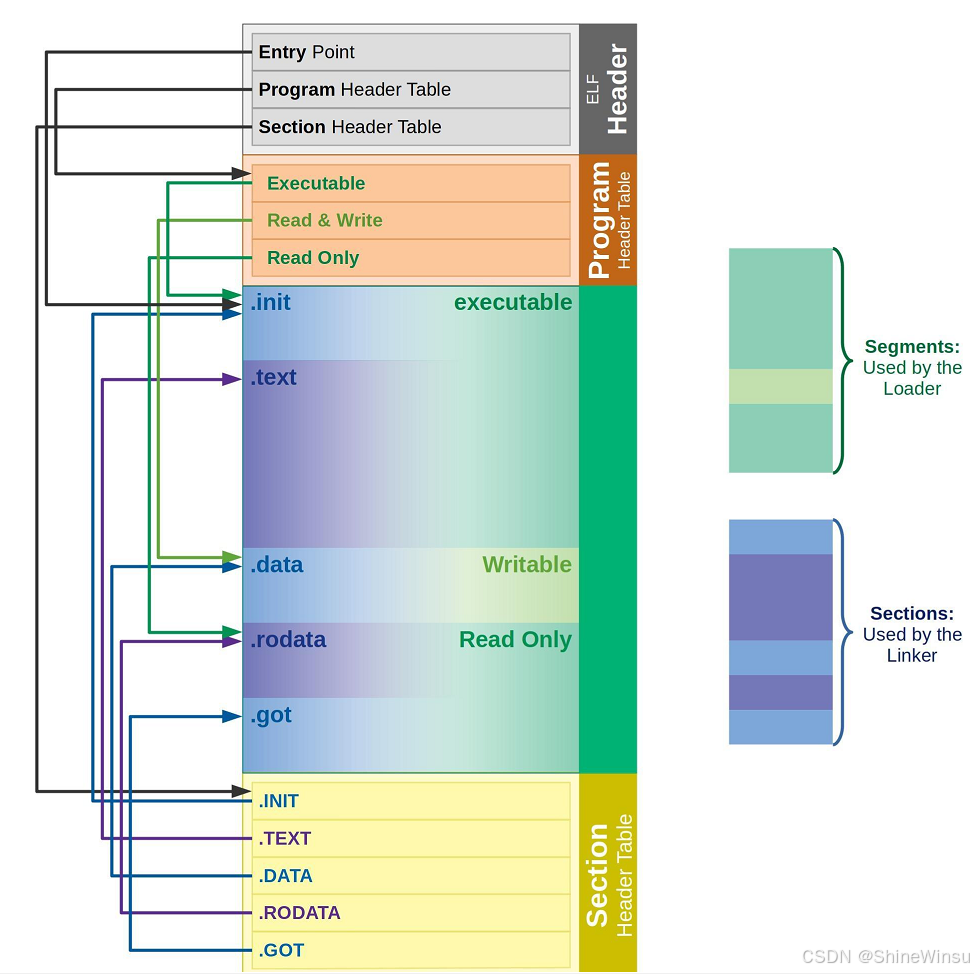
ELF文件结构:
如果把 ELF 文件比作一本 "带索引的技术手册",那么这四部分的关系就像:
- ELF 头 = 手册封面 + 目录页(告诉你这是本什么书、关键内容在哪一页);
- 程序头表 = "阅读指南" 索引(给读者 / 操作系统看的,告诉你哪些内容要放一起读、怎么读);
- 节头表 = "编辑指南" 索引(给编辑 / 链接器看的,告诉你每个章节的具体位置、长度、类型);
- 节 = 手册的具体章节(实际内容,比如代码、数据、符号表等)。
一、ELF 头(ELF Header):ELF 文件的 "封面 + 目录"
作用:位于 ELF 文件的最开头(前 64 字节,64 位系统),相当于文件的 "身份证"+"总目录"。它会告诉你:这是个 ELF 文件(魔数)、是 32 位还是 64 位、是可执行文件还是动态库(类型)、用什么 CPU 架构(x86/arm)、程序头表和节头表在文件中的位置(偏移)、有多少个程序头 / 节头条目等。没有 ELF 头,操作系统和工具根本不知道这是个 ELF 文件,更没法解析。
核心结构(64 位 ELF 头字段):
用readelf -h 文件名可以查看,每个字段都有明确含义,我们挑关键的 10 个字段解释(结合输出看更直观):
# 以可执行文件a.out为例
readelf -h a.out输出:
ELF Header:
Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00 # 魔数:确认是ELF文件
Class: ELF64 # 类型:64位ELF(32位是ELF32)
Data: 2's complement, little endian # 字节序:小端序(x86架构都是这)
Version: 1 (current) # ELF版本:固定为1
OS/ABI: UNIX - System V # 目标OS:Linux属于System V
ABI Version: 0 # ABI版本:通常为0
Type: EXEC (Executable file) # 文件类型:可执行文件(REL是.o,DYN是.so)
Machine: Advanced Micro Devices X86-64 # 机器架构:x86_64
Version: 0x1 # 对象文件版本:固定为1
Entry point address: 0x400430 # 程序入口地址:CPU开始执行的第一个指令地址(.text节里)
Start of program headers: 64 (bytes into file) # 程序头表在文件中的偏移:从文件开头数64字节处
Start of section headers: 6520 (bytes into file) # 节头表在文件中的偏移:6520字节处
Flags: 0x0 # 处理器特定标志:通常为0
Size of this header: 64 (bytes) # ELF头自身大小:64位是64字节,32位是52字节
Size of program headers: 56 (bytes) # 每个程序头条目的大小:64位56字节,32位32字节
Number of program headers: 9 # 程序头表条目数:有9个段
Size of section headers: 64 (bytes) # 每个节头条目的大小:64位64字节,32位40字节
Number of section headers: 31 # 节头表条目数:有31个节
Section header string table index: 30 # 节头字符串表的索引:第30个节是.shstrtab(存节的名称)关键字段为什么重要?
- 魔数(Magic) :前 4 字节
7f 45 4c 46(对应^?ELF)是 "ELF 通行证"------ 操作系统打开文件时先看这 4 字节,不是这个就不认; - Type:决定文件用途(.o/.so/ 可执行程序),链接器和操作系统会根据类型做不同处理;
- Entry point address:可执行文件特有,操作系统加载后,CPU 从这个地址开始执行(比如 main 函数之前的初始化代码地址);
- Start of program headers/section headers:告诉工具 "程序头表 / 节头表在文件的哪个位置",没有这两个偏移,后面的表根本找不到。
二、程序头表(Program Header Table):给操作系统看的 "段索引"
作用:仅存在于可执行文件(.out)和动态库(.so)中(.o 文件没有),是操作系统加载程序时的 "操作指南"。它把 ELF 文件中的内容划分为 "段(Segment)"------ 段是多个 "权限相同的节" 的集合(比如把可执行的.text 和只读的.rodata 合并成 "只读可执行段"),程序头表会记录每个段的位置(文件偏移)、加载到内存后的地址、大小、权限(读 / 写 / 执行)等。操作系统加载程序时,只认程序头表,不管节。
核心结构(每个程序头条目字段):
用readelf -l 文件名查看,每个条目对应一个段,关键字段如下:
# 还是以a.out为例
readelf -l a.out输出(简化后,挑 2 个关键段解释):
Program Headers:
Type Offset VirtAddr PhysAddr
FileSiz MemSiz Flags Align
# 类型 文件中偏移 内存虚拟地址 物理地址(通常和虚拟地址相同)
# 文件中大小 内存中大小 权限(R=读,W=写,E=执行) 对齐要求
LOAD 0x0000000000000000 0x0000000000400000 0x0000000000400000
0x0000000000000744 0x0000000000000744 R E 200000
# 类型LOAD:需要加载到内存的段
# Offset=0:从文件开头0字节处开始
# VirtAddr=0x400000:加载到内存的0x400000地址
# FileSiz=0x744:在文件中占0x744字节
# MemSiz=0x744:加载到内存后也是0x744字节(无未初始化数据)
# Flags=R E:只读可执行(存放.text、.rodata等节)
LOAD 0x0000000000000e10 0x0000000000600e10 0x0000000000600e10
0x0000000000000218 0x0000000000000220 RW 200000
# Flags=RW:可读可写(存放.data、.bss等节)
# MemSiz=0x220 > FileSiz=0x218:差值是.bss节的大小(只占内存,不占文件)
INTERP 0x0000000000000238 0x0000000000400238 0x0000000000400238
0x000000000000001c 0x000000000000001c R 1
[Requesting program interpreter: /lib64/ld-linux-x86-64.so.2]
# 类型INTERP:动态链接器路径(动态可执行文件特有,告诉系统用哪个程序加载自己)为什么需要 "段" 而不是直接用 "节"?
内存管理的最小单位是 "页(通常 4KB)",如果每个节单独加载,一个 3KB 的.text 节和 1KB 的.rodata 节会占用 2 个页(8KB),但合并成一个段后只占 1 个页(4KB),节省内存。操作系统只关心 "这段内存能不能读 / 写 / 执行",不关心里面具体是哪个节,所以用段更高效。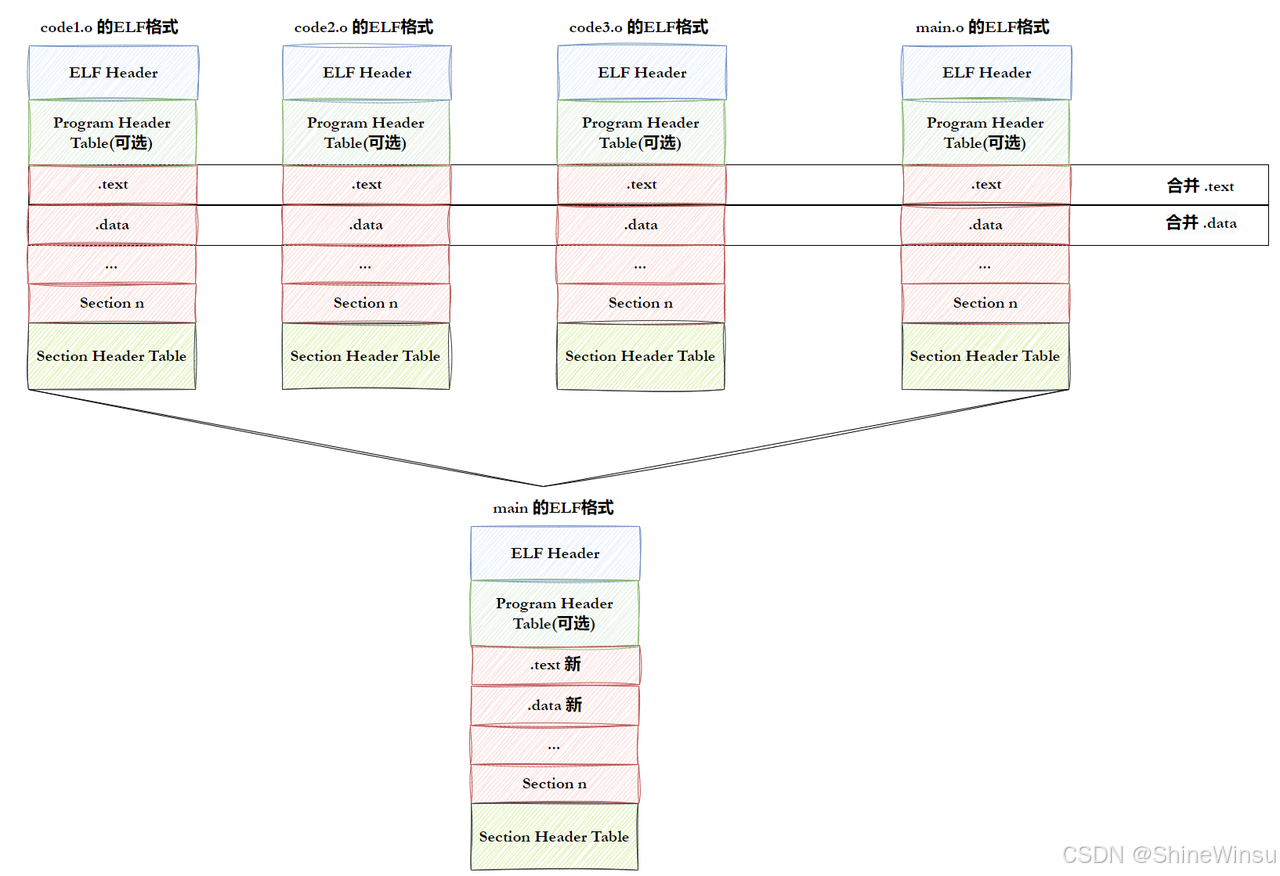
三、节头表(Section Header Table):给链接器看的 "节索引"
作用:存在于所有 ELF 文件中(.o/.so/.out),是链接器拼接目标文件时的 "地图"。它记录了文件中所有 "节(Section)" 的信息:每个节的名称(比如.text)、类型(比如代码 / 数据)、在文件中的位置(偏移)、大小、权限、关联的其他节(比如符号表节关联字符串表节)等。链接器合并目标文件时,靠节头表找到每个节,再按名称合并(比如所有.text 节合并成一个)。
核心结构(每个节头条目字段):
用readelf -S 文件名查看,每个条目对应一个节,关键字段如下:
# 以目标文件hello.o为例
readelf -S hello.o输出(简化后,挑关键节解释):
Section Headers:
[Nr] Name Type Address Offset
Size EntSize Flags Link Info Align
# 序号 节名称 类型 内存地址(.o文件中为0,链接后分配) 文件偏移
# 大小 条目大小(节内每个元素的大小) 权限标志 链接的节索引 附加信息 对齐要求
[ 0] NULL 0000000000000000 00000000
0000000000000000 0000000000000000 0 0 0
# 0号节:空节,ELF标准要求,占位用
[ 1] .text PROGBITS 0000000000000000 00000040
0000000000000025 0000000000000000 AX 0 0 16
# 节名称.text:代码节(存放函数指令)
# Type=PROGBITS:存放程序数据(代码/数据都是这种类型)
# Flags=AX:A=可分配,X=可执行(代码需要执行权限)
# Offset=0x40:在文件中从0x40字节处开始
# Size=0x25:大小0x25字节(main函数的指令长度)
[ 3] .data PROGBITS 0000000000000000 00000065
0000000000000000 0000000000000000 WA 0 0 4
# 节名称.data:已初始化数据节(如果有全局变量int g=10,就存在这)
# Flags=WA:W=可写,A=可分配(数据需要读写)
[ 4] .bss NOBITS 0000000000000000 00000065
0000000000000000 0000000000000000 WA 0 0 1
# 节名称.bss:未初始化数据节(全局变量int g;存在这,不占文件空间)
# Type=NOBITS:无实际数据(所以Size在文件中为0)
[ 5] .rodata PROGBITS 0000000000000000 00000065
000000000000000d 0000000000000000 A 0 0 1
# 节名称.rodata:只读数据节(存放"hello world!"等字符串常量)
# Flags=A:可分配,无W(只读)
[ 6] .symtab SYMTAB 0000000000000000 00000072
0000000000000180 0000000000000018 7 8 8
# 节名称.symtab:符号表(记录函数/变量的符号信息)
# Link=7:关联第7个节(.strtab,符号名称字符串表)
[ 7] .strtab STRTAB 0000000000000000 000001f2
0000000000000039 0000000000000000 0 0 1
# 节名称.strtab:字符串表(存放符号的名称,比如"main"、"run")
[10] .shstrtab STRTAB 0000000000000000 00000308
0000000000000059 0000000000000000 0 0 1
# 节名称.shstrtab:节头字符串表(存放节的名称,比如".text"、".data")关键字段为什么重要?
- Name:节的名称(比如.text),链接器靠名称合并节(所有.text 节合并);
- Offset:节在文件中的位置,链接器靠这个找到节的内容;
- Flags:节的权限(比如 AX = 可执行,WA = 可读写),链接器合并后会保留权限;
- Link:关联的节(比如.symtab 关联.strtab),符号表中的名称实际存在字符串表中,靠 Link 字段找到。
四、节(Section):ELF 文件的 "实际内容"
作用:ELF 文件中存储数据的最小单位,所有代码、数据、符号表等信息都放在不同的节中。节的类型由用途决定,比如代码放.text,字符串放.rodata,符号表放.symtab 等。节是链接器处理的基本单位,最终会被合并到段中供操作系统加载。
常见节的分类和作用:
| 节名称 | 类型 | 存储内容 | 权限 | 通俗比喻 |
|---|---|---|---|---|
| .text | PROGBITS | 函数的二进制指令(如 main、run) | AX(可执行) | 说明书中的 "操作步骤" |
| .data | PROGBITS | 已初始化的全局变量、静态变量(如 int g=10) | WA(可读写) | 说明书中的 "已知数据" |
| .bss | NOBITS | 未初始化的全局变量、静态变量(如 int g) | WA(可读写) | 说明书中的 "预留空白区" |
| .rodata | PROGBITS | 字符串常量(如 "hello")、const 变量 | A(只读) | 说明书中的 "固定标签" |
| .symtab | SYMTAB | 符号表(函数 / 变量的名称、地址、大小等) | - | 说明书中的 "术语表" |
| .strtab | STRTAB | 符号名称字符串(如 "main"、"g_val") | - | 术语表中的 "文字说明" |
| .shstrtab | STRTAB | 节名称字符串(如 ".text"、".data") | - | 章节名列表 |
| .rel.text | REL | .text 节的重定位表(需要修正的地址) | - | 操作步骤中的 "待填空位置" |
| .plt | PROGBITS | 过程链接表(动态库函数调用桩) | AX | 动态工具的 "临时接口" |
| .got | PROGBITS | 全局偏移表(动态库函数的实际地址) | WA | 动态工具的 "实际地址记录" |
如何查看节的实际内容?
- 查看.text 节的机器指令:
objdump -d 文件名(反汇编); - 查看.rodata 节的字符串:
readelf -x .rodata 文件名(十六进制查看); - 查看.data 节的数据:
readelf -x .data 文件名; - 查看符号表节:
readelf -s 文件名(.symtab 的内容)。
举例查看.rodata 节的字符串:
readelf -x .rodata hello.o输出(十六进制和 ASCII 对应):
Hex dump of section '.rodata':
0x00000000 68656c6c 6f20776f 726c6421 00 hello world!.
# 0x68656c6c6f20776f726c642100 对应 ASCII 就是 "hello world!\0"总结:四大组成的关系链
- ELF 头在文件最开头,告诉你 "程序头表和节头表在文件中的位置";
- 程序头表(针对可执行文件 /.so)根据 ELF 头的偏移找到,告诉操作系统 "如何把段加载到内存";
- 节头表根据 ELF 头的偏移找到,告诉链接器 "每个节的位置和属性";
- 节是实际内容,链接器根据节头表合并节,操作系统根据程序头表把合并后的节(段)加载到内存。
这样一套 "定位 - 索引 - 内容" 的结构,让 ELF 文件既能被链接器拼接(靠节头表),又能被操作系统加载(靠程序头表),这也是它能成为 Linux 下 "万能格式" 的核心原因。
6.3 ELF 文件的两大视图:链接视图 vs 执行视图
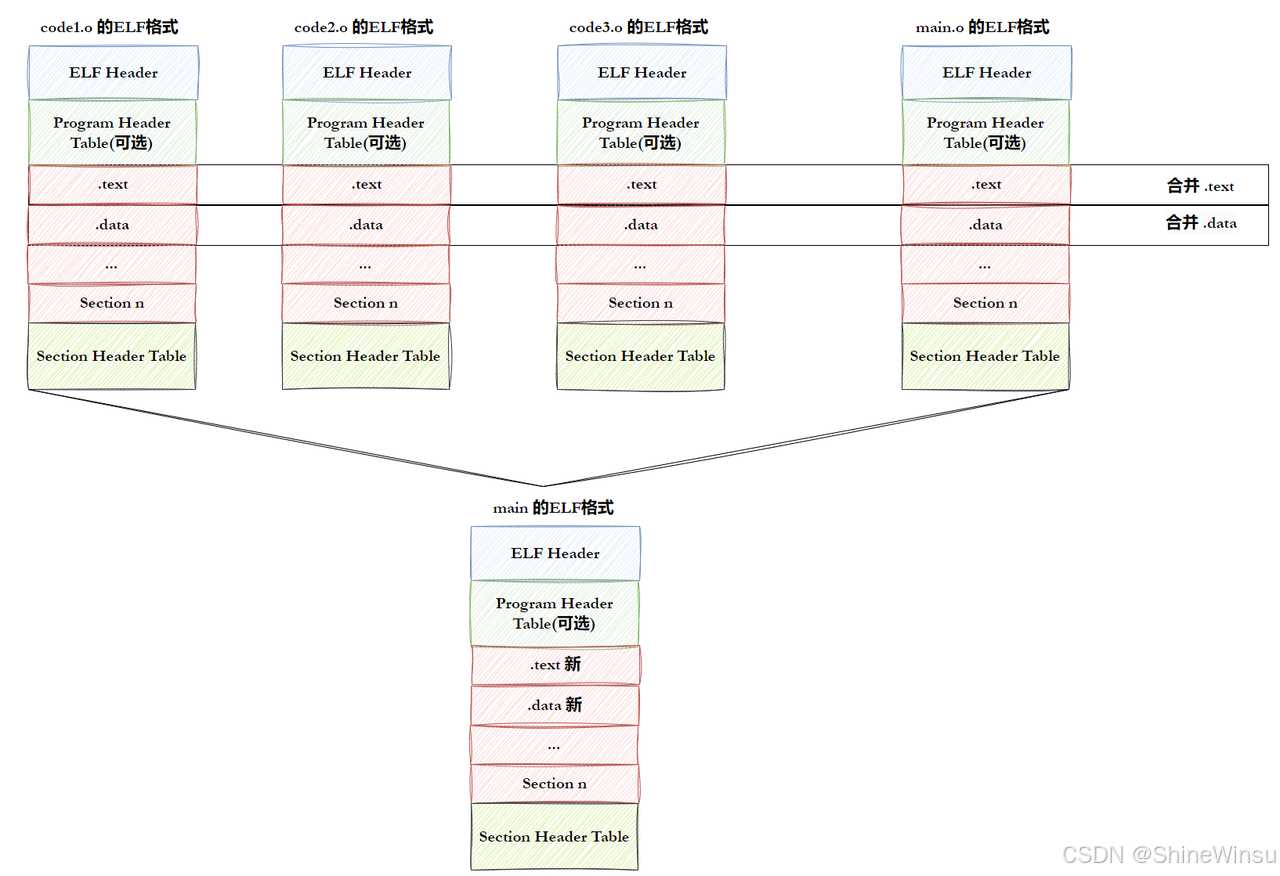
ELF 文件有两个 "视角",分别对应 "链接时" 和 "运行时",就像同一本书,编辑看的是 "章节结构"(链接视图),读者看的是 "阅读顺序"(执行视图),两者都很重要,我们详细拆解:
6.3.1 链接视图(Linking View):给链接器看的 "章节结构"
- 核心单位 :节(Section)------ 比如
.text、.data、.symtab; - 核心作用 :链接器拼接目标文件时,按 "节" 合并 ------ 比如把所有.o 的
.text节合并成一个大的.text节,把.data节合并成一个大的.data节; - 关键组成:节头表(Section Header Table)------ 记录所有节的名称、位置、大小、权限,链接器靠它找到每个节;
- 查看命令 :
readelf -S 文件名(-S 大写,查看节头表)。
实操查看a.out的节头表(简化输出):
readelf -S a.out | grep -E "Name|.text|.data|.bss|.rodata|.symtab|.rel.text"输出:
[Nr] Name Type Address Offset
Size EntSize Flags Link Info Align
[ 1] .interp PROGBITS 0000000000400238 00000238
[ 2] .note.ABI-tag NOTE 0000000000400254 00000254
[ 3] .note.gnu.build-id NOTE 0000000000400274 00000274
[ 4] .gnu.hash GNU_HASH 0000000000400298 00000298
[ 5] .dynsym DYNSYM 00000000004002b8 000002b8
[ 6] .dynstr STRTAB 0000000000400300 00000300
[ 7] .gnu.version VERSYM 0000000000400338 00000338
[ 8] .gnu.version_r VERNEED 0000000000400340 00000340
[ 9] .rela.dyn RELA 0000000000400360 00000360
[10] .rela.plt RELA 0000000000400378 00000378
[11] .init PROGBITS 0000000000400390 00000390
[12] .plt PROGBITS 00000000004003c0 000003c0
[13] .plt.got PROGBITS 00000000004003f0 000003f0
[14] .text PROGBITS 0000000000400400 00000400
00000000000001a5 0000000000000000 AX 0 0 16
# .text节:合并后的机器指令,地址0x400400,大小0x1a5字节,权限AX(可执行)
[15] .fini PROGBITS 00000000004005a8 000005a8
[16] .rodata PROGBITS 00000000004005b0 000005b0
000000000000001c 0000000000000000 A 0 0 4
# .rodata节:只读数据,大小0x1c字节(存储"hello world!"等字符串)
[17] .eh_frame_hdr PROGBITS 00000000004005cc 000005cc
[18] .eh_frame PROGBITS 00000000004005f8 000005f8
[19] .init_array INIT_ARRAY 0000000000600e10 00000e10
[20] .fini_array FINI_ARRAY 0000000000600e18 00000e18
[21] .jcr PROGBITS 0000000000600e20 00000e20
[22] .dynamic DYNAMIC 0000000000600e28 00000e28
[23] .got PROGBITS 0000000000600fc8 00000fc8
[24] .got.plt PROGBITS 0000000000601000 00001000
[25] .data PROGBITS 0000000000601020 00001020
0000000000000010 0000000000000000 WA 0 0 8
# .data节:已初始化数据,大小0x10字节,权限WA(可读写)
[26] .bss NOBITS 0000000000601030 00001030
0000000000000008 0000000000000000 WA 0 0 1
# .bss节:未初始化数据,大小0x8字节,权限WA(可读写),不占文件空间
[27] .comment PROGBITS 0000000000000000 00001030
[28] .symtab SYMTAB 0000000000000000 00001058
[29] .strtab STRTAB 0000000000000000 000016a0
[30] .shstrtab STRTAB 0000000000000000 000018b86.3.2 执行视图(Execution View):给操作系统看的 "阅读顺序"
- 核心单位 :段(Segment)------ 把多个 "权限相同" 的节合并成一个段(比如把
.text(可执行)和.rodata(只读)合并成 "只读可执行段"); - 核心作用:操作系统加载程序时,按 "段" 加载 ------ 内存是按 "页面"(默认 4KB)分配的,合并节能减少内存浪费(比如 3KB 的.text 和 1KB 的.rodata 合并后,只占 1 个 4KB 页面,而不是 2 个);
- 关键组成:程序头表(Program Header Table)------ 记录所有段的虚拟地址、大小、权限、文件偏移,操作系统靠它加载程序;
- 查看命令 :
readelf -l 文件名(-l 小写,查看程序头表)。
实操查看a.out的程序头表(简化输出):
readelf -l a.out | grep -A 10 "Program Headers:"输出:
Program Headers:
Type Offset VirtAddr PhysAddr
FileSiz MemSiz Flags Align
PHDR 0x0000000000000040 0x0000000000400040 0x0000000000400040
0x00000000000001f8 0x00000000000001f8 R E 8
INTERP 0x0000000000000238 0x0000000000400238 0x0000000000400238
0x000000000000001c 0x000000000000001c R 1
[Requesting program interpreter: /lib64/ld-linux-x86-64.so.2]
# INTERP段:指定动态链接器路径(如果是动态链接程序)
LOAD 0x0000000000000000 0x0000000000400000 0x0000000000400000
0x0000000000000744 0x0000000000000744 R E 200000
# LOAD段1:只读可执行(R E),包含.text、.rodata、.plt等节
# VirtAddr=0x400000:虚拟地址起始位置;FileSiz=0x744:文件中大小;MemSiz=0x744:内存中大小
LOAD 0x0000000000000e10 0x0000000000600e10 0x0000000000600e10
0x0000000000000218 0x0000000000000220 RW 200000
# LOAD段2:可读可写(RW),包含.data、.bss、.got等节
# MemSiz=0x220 > FileSiz=0x218:差值是.bss节的大小(只占内存,不占文件)
DYNAMIC 0x0000000000000e28 0x0000000000600e28 0x0000000000600e28
0x00000000000001d0 0x00000000000001d0 RW 8
# DYNAMIC段:存储动态链接相关信息(依赖的库、符号表位置等)
NOTE 0x0000000000000254 0x0000000000400254 0x0000000000400254
0x0000000000000044 0x0000000000000044 R 4
GNU_EH_FRAME 0x00000000000005cc 0x00000000004005cc 0x00000000004005cc
0x000000000000004c 0x000000000000004c R 4
GNU_STACK 0x0000000000000000 0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000 RW 10
# GNU_STACK段:指定栈的权限(RW,可读可写)
GNU_RELRO 0x0000000000000e10 0x0000000000600e10 0x0000000000600e10
0x00000000000001f0 0x00000000000001f0 R 1
# GNU_RELRO段:只读重定位段,防止重定位后的数据被修改6.3.3 节到段的映射:
操作系统加载程序时,不会关心 "节",只关心 "段"------ 链接器已经在生成可执行程序时,把 "权限相同、用途相近" 的节合并成了段。常见的合并规则如下:
| 段类型 | 包含的节 | 权限 | 用途 |
|---|---|---|---|
| 只读可执行段 | .text、.rodata、.plt 等 | R E | 存储代码和只读数据,不能修改 |
| 可读可写段 | .data、.bss、.got 等 | RW | 存储数据和可修改的地址表 |
| 动态链接段 | .dynamic、.dynsym 等 | RW | 存储动态链接相关信息 |
| 栈段 | 无(运行时分配) | RW | 存储函数栈帧、局部变量 |
6.4 ELF 文件的类型:4 种核心类型(新手不会混淆)
ELF 文件根据用途,分为 4 种类型,我们用 "快递盒里的东西" 来比喻,清晰区分:
| ELF 类型 | 后缀名 | 通俗比喻 | 核心用途 | 关键特征(readelf -h 查看) |
|---|---|---|---|---|
| 可重定位文件(Relocatable) | .o | 单个零件 | 源码编译后的中间产物,可与其他.o 或库链接 | Type=REL;无程序头表(Program Headers=0) |
| 可执行文件(Executable) | 无(如 a.out) | 成品家具 | 链接后的最终产物,可直接运行 | Type=EXEC;有程序头表;有入口地址 |
| 共享目标文件(Shared) | .so | 共享工具店 | 动态库,运行时被多个程序共享加载 | Type=DYN;有程序头表;地址无关(PIC) |
| 核心转储文件(Core) | .core | 事故现场快照 | 程序崩溃时生成,包含内存数据、寄存器状态,用于调试 | Type=CORE;无程序头表;包含进程快照 |
用readelf -h查看不同 ELF 文件的类型:
# 查看目标文件(.o)
readelf -h hello.o | grep "Type:"
# 输出:Type: REL (Relocatable file)
# 查看可执行文件(a.out)
readelf -h a.out | grep "Type:"
# 输出:Type: EXEC (Executable file)
# 查看动态库(.so)
readelf -h libmyrun.so | grep "Type:"
# 输出:Type: DYN (Shared object file)7. 编译链接全流程:从源码到可执行程序
之前我们简化了 "编译链接" 的流程,现在详细拆解 "预处理→编译→汇编→链接" 四步
7.1 完整流程:以 hello.c 和 code.c 为例(全程实操)
我们用之前的两个源码文件,一步步执行命令,查看每一步的输出,验证流程:
7.1.1 步骤 1:预处理(cpp)------ 文本替换,生成.i 文件
命令:
gcc -E hello.c -o hello.i
gcc -E code.c -o code.i编译器做的事:
- 替换
#include:把stdio.h的内容全部复制到 hello.i 中; - 删除注释:把
// 声明run函数这类注释删除; - 处理
#define:如果有宏定义,直接替换(比如#define MAX 10替换成 10); - 保留预处理指令:比如
#line(记录行号)、#pragma(编译器指令)。
验证:查看 hello.i 的末尾,能看到 main 函数的源码(没有注释,#include已展开):
tail -20 hello.i7.1.2 步骤 2:编译(cc1)------ 翻译成汇编,生成.s 文件
命令:
gcc -S hello.i -o hello.s
gcc -S code.i -o code.s编译器做的事:
- 语法分析:检查代码语法(比如少分号、括号不匹配);
- 语义分析:检查代码逻辑(比如变量未定义、函数参数不匹配);
- 中间代码生成:把 C 代码翻译成中间代码(IR);
- 优化:优化代码(比如把
printf优化成puts,删除无用代码); - 汇编生成:把中间代码翻译成汇编语言。
验证:查看 hello.s,能看到汇编指令(比如pushq %rbp、call puts@PLT):
cat hello.s7.1.3 步骤 3:汇编(as)------ 翻译成机器指令,生成.o 文件
命令:
gcc -c hello.s -o hello.o
gcc -c code.s -o code.o编译器做的事:
- 指令翻译:把汇编指令翻译成二进制机器指令(比如
pushq %rbp翻译成55); - 生成节:把机器指令存到.text 节,数据存到.data/.bss 节;
- 生成符号表:记录已定义和未定义的符号;
- 生成重定位表:记录需要修正的地址。
验证:用objdump -d查看 hello.o 的机器指令:
objdump -d hello.o输出(main 函数的机器指令):
hello.o: file format elf64-x86-64
Disassembly of section .text:
0000000000000000 <main>:
0: f3 0f 1e fa endbr64
4: 55 pushq %rbp
5: 48 89 e5 movq %rsp, %rbp
8: 48 8d 3d 00 00 00 00 leaq 0(%rip), %rdi # f <main+0xf>
f: e8 00 00 00 00 callq 14 <main+0x14>
14: b8 00 00 00 00 movl $0, %eax
19: e8 00 00 00 00 callq 1e <main+0x1e>
1e: b8 00 00 00 00 movl $0, %eax
23: 5d popq %rbp
24: c3 retq7.1.4 步骤 4:链接(ld)------ 拼接零件,生成可执行程序
命令:
gcc hello.o code.o -o a.out链接器(ld)做的 5 件关键事:
- 收集输入文件 :收集所有.o 文件和依赖的库文件(默认链接 C 标准库
libc.so); - 符号解析:匹配所有未定义符号(比如 hello.o 的 run、puts)和已定义符号(比如 code.o 的 run、libc.so 的 puts);
- 节合并:把所有.o 的同名节合并(比如.text 合并、.data 合并);
- 地址分配 :为合并后的节分配虚拟地址(比如.text 节起始地址
0x400400); - 地址重定位 :根据重定位表,修正所有待修正的地址(比如把 hello.o 中 call run 的地址从 0 改成
0x4005d0)。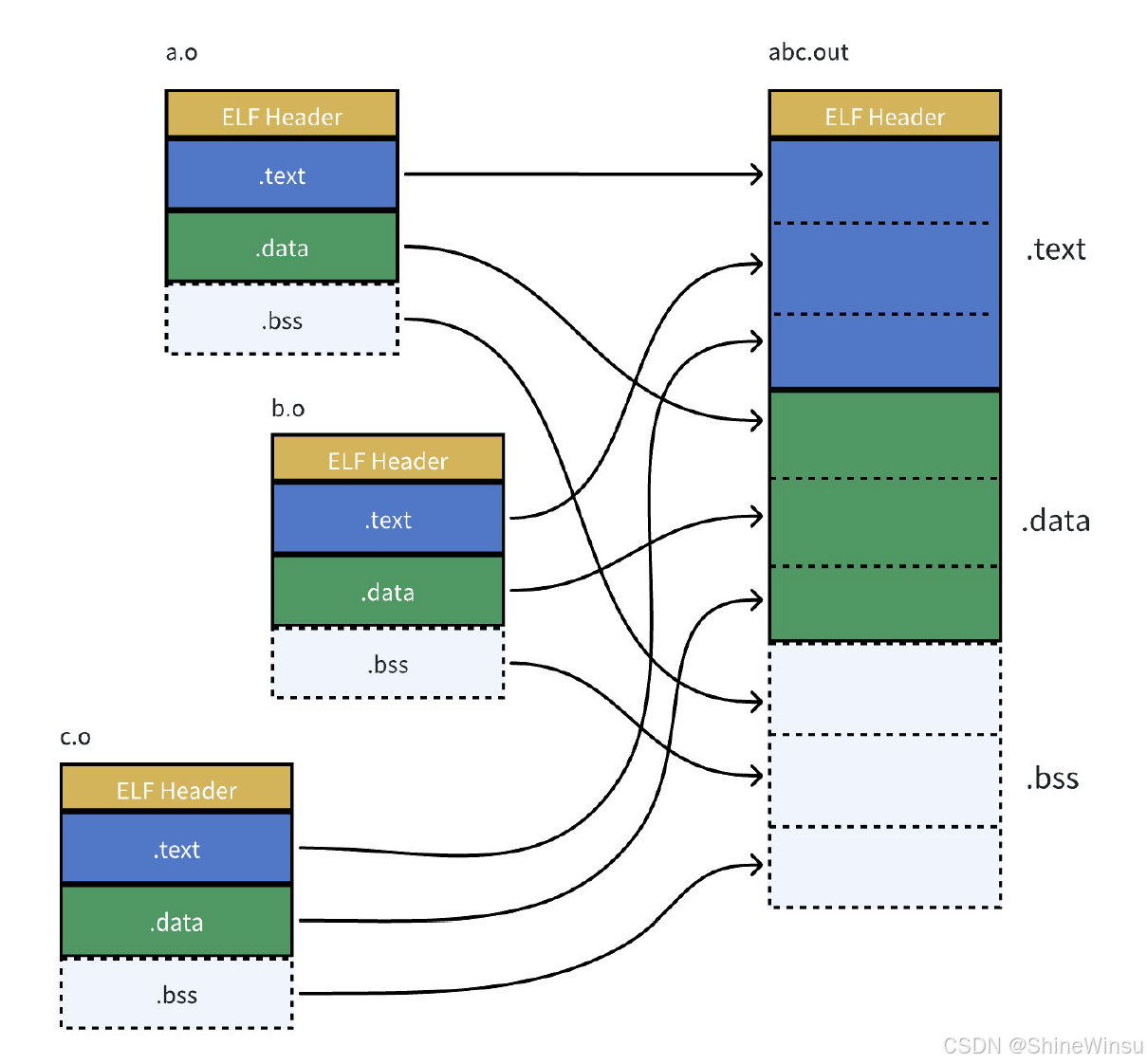
验证:查看链接后的可执行程序的机器指令,地址已修正:
objdump -d a.out | grep -A 15 "main:"输出(main 函数的机器指令,地址已修正):
00000000004005e6 <main>:
4005e6: f3 0f 1e fa endbr64
4005ea: 55 pushq %rbp
4005eb: 48 89 e5 movq %rsp, %rbp
4005ee: 48 8d 3d 1b 0a 20 00 leaq 0x200a1b(%rip), %rdi # 601010 <_IO_stdin_used+0x10>
4005f5: e8 b6 fe ff ff callq 4004b0 <puts@plt> # puts的地址已修正为0x4004b0
4005fa: b8 00 00 00 00 movl $0, %eax
4005ff: e8 cc fe ff ff callq 4005d0 <run> # run的地址已修正为0x4005d0
400604: b8 00 00 00 00 movl $0, %eax
400609: 5d popq %rbp
40060a: c3 retq
40060b: 0f 1f 44 00 00 nopl 0x0(%rax,%rax,1)7.2 链接器的 "小秘密":静态库的索引
静态库(.a)是多个.o 文件的 "归档包",用ar命令打包生成。但链接器怎么快速找到库中需要的.o 文件(比如程序调用了 add 函数,怎么找到 add.o)?答案是 "静态库索引"。
7.2.1 静态库索引的生成:ar -s 命令
打包静态库时,ar rcs命令中的s参数,就是生成 "索引"(也叫 "符号表")------ 相当于给静态库做了一个 "目录",链接器不用遍历所有.o 文件,直接查目录就能找到需要的符号。
实操验证:
# 1. 编译两个工具.o文件
gcc -c add.c -o add.o # add.c:int add(int a,int b){return a+b;}
gcc -c sub.c -o sub.o # sub.c:int sub(int a,int b){return a-b;}
# 2. 打包静态库(不加-s,不生成索引)
ar rc libmath.a add.o sub.o
# 3. 查看静态库的内容(无索引)
ar t libmath.a
# 输出:add.o sub.o(只有.o文件名,无索引)
# 4. 生成索引(-s参数)
ar s libmath.a
# 5. 查看静态库的内容(有索引)
ar t libmath.a
# 输出:add.o sub.o (索引是隐藏的,用ar -x解压能看到)
# 6. 解压静态库,查看索引文件
mkdir temp && cd temp
ar x ../libmath.a
ls -l
# 输出:会看到add.o、sub.o,以及一个隐藏的索引文件(.SYMDEF)7.2.2 链接器查找静态库的顺序:
链接器查找静态库的顺序是 "从左到右",如果库 A 依赖库 B,库 B 必须放在库 A 的右边,否则会报 "undefined reference" 错误,这也就是我们上篇博客反复强调的一个点,大家依然要牢牢记住。
比如:程序调用了 add 函数(在 libmath.a 中),add 函数调用了 printf(在 libc.a 中),链接命令必须是:
gcc main.o -lmath -lc # 正确:libmath.a在左,libc.a在右如果写成gcc main.o -lc -lmath(libc.a 在左),链接器先处理 libc.a,再处理 libmath.a,此时 add 函数调用的 printf 还未被解析,会报错 "undefined reference to printf"。
ELF 加载与进程地址空间:
如果把ELF 可执行文件 比作 "小区建设设计图",那么进程地址空间 就是 "按图建成的小区",操作系统就是 "施工队"。
一、先解决核心问题:ELF 未加载时,到底有没有地址?
答案:有!不仅有,而且是 "虚拟地址"(逻辑地址),是编译器和链接器在编译链接时就给 ELF "预分配" 好的。
为什么未加载就需要地址?
当代计算机采用 "平坦地址空间" 模式 ------ 程序认为自己拥有一块连续的内存(从 0 到某个最大值),所有代码、数据都在这块空间里按地址排列。编译器和链接器必须提前给 ELF 的代码、数据 "编址",否则程序里的 "函数调用""变量访问"(比如call 0x400520、mov 0x601000, %rax)就没有目标地址可写,加载到内存后也无法正确执行。
怎么证明 ELF 未加载时有地址?
用objdump -S反汇编 ELF 文件,最左侧的就是 "预分配的虚拟地址":
# 反汇编可执行文件a.out
objdump -S a.out | head -10输出(重点看最左侧的地址):
a.out: file format elf64-x86-64
Disassembly of section .text:
0000000000400520 <_start>: # _start是程序真正的入口(在main之前)
400520: f3 0f 1e fa endbr64
400524: 31 ed xor %ebp,%ebp
400526: 49 89 d1 mov %rdx,%r9
400529: 5e pop %rsi- 最左侧的
0000000000400520就是_start函数的虚拟地址,这个地址在 ELF 文件生成时就确定了,和是否加载到内存无关; - 程序里的指令(比如
call 4004b0 <puts@plt>)直接使用这些地址,加载到内存后,操作系统会通过页表将这些虚拟地址映射到物理内存,程序无需修改。
补充:逻辑地址 vs 虚拟地址
严格来说,ELF 里的地址是 "逻辑地址"(相对于某个起始点的偏移),但在平坦模式下,起始点被设为 0,逻辑地址就等价于 "虚拟地址"(程序认为的内存地址)。比如.text节的起始地址是0x400400,意味着程序认为自己的代码从虚拟地址0x400400开始。
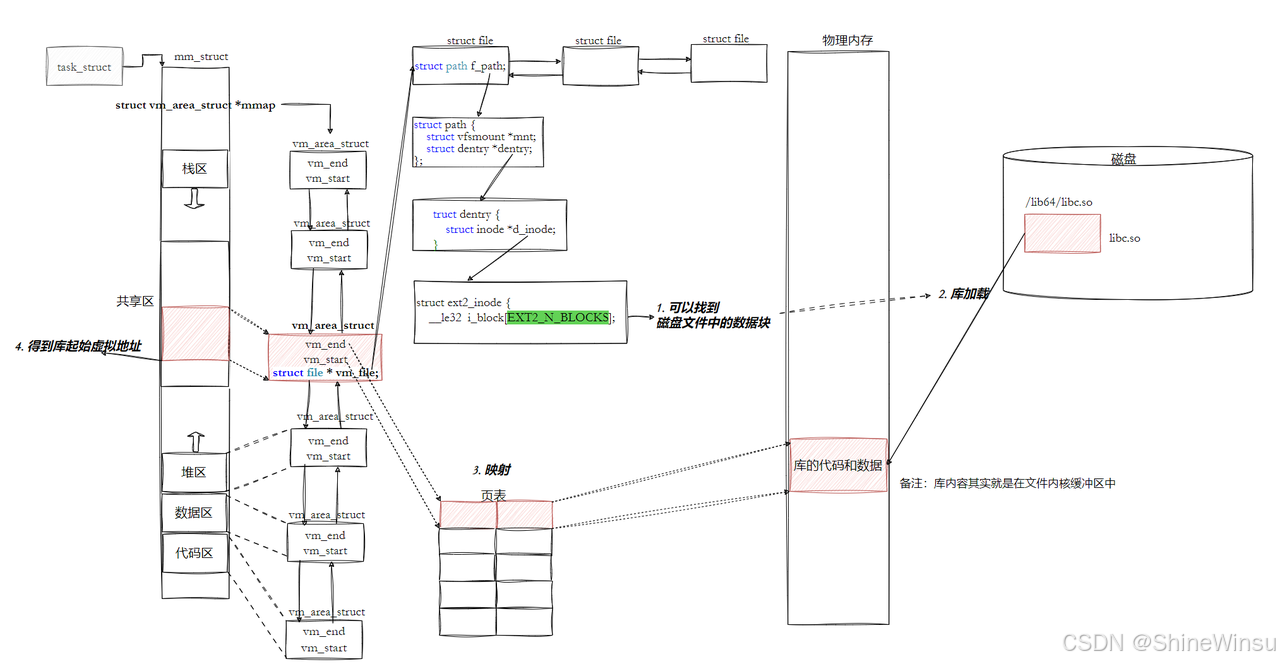
二、进程地址空间的 "骨架":mm_struct 和 vm_area_struct 从哪来?
当你执行./a.out时,操作系统会创建一个新进程,其中最核心的就是初始化mm_struct(进程地址空间的总描述)和vm_area_struct(地址空间中的 "分区")。这些结构的初始化数据,全部来自 ELF 的 "程序头表"(Program Header Table)。
类比理解:
mm_struct= 小区总规划图(记录整个小区的范围、分区数量等);vm_area_struct= 小区里的 "分区"(比如 "住宅区""商业区""绿地"),每个分区有自己的范围、权限(比如住宅区可进入,商业区可营业);- ELF 的 "程序头表" = 给施工队的 "分区说明书"(告诉施工队要建哪些分区、每个分区多大、有什么权限)。
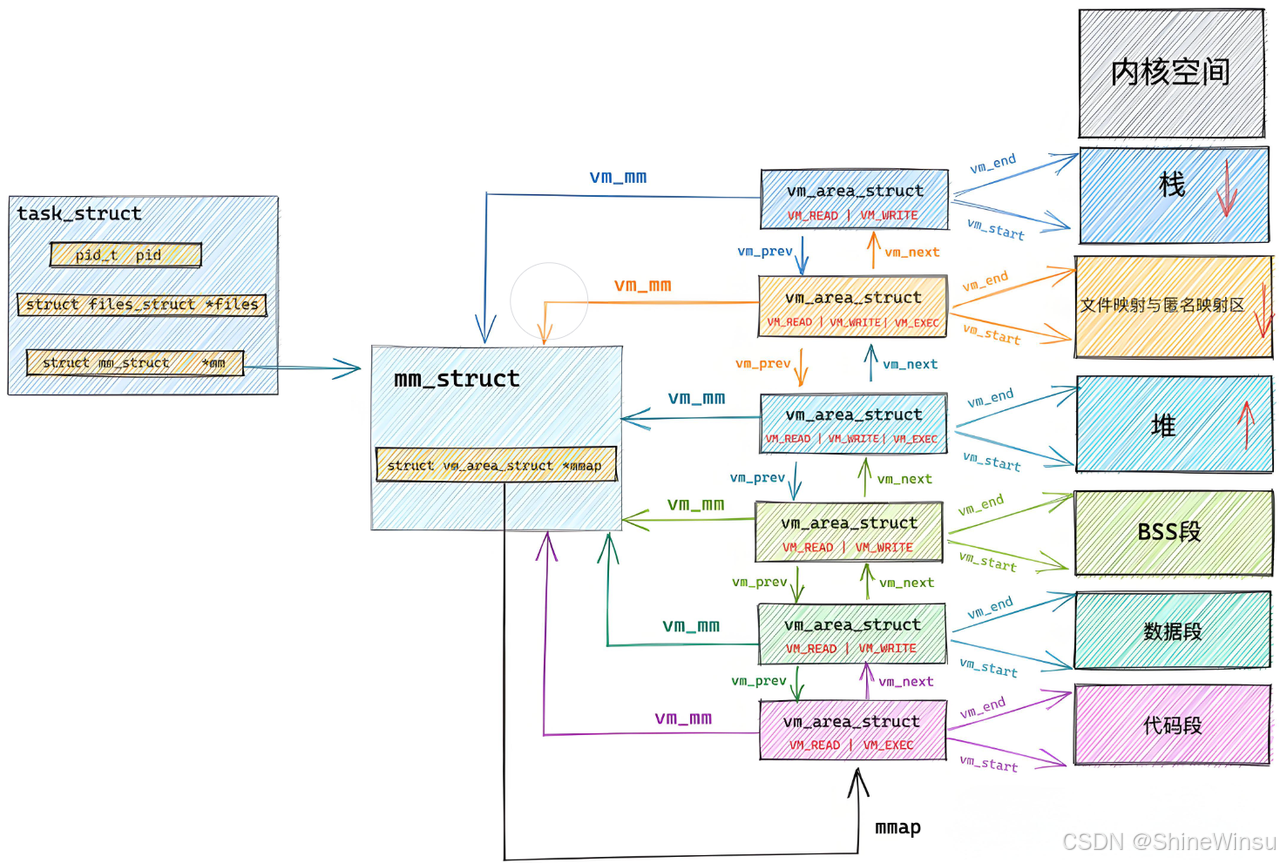
具体初始化过程:
-
读取 ELF 程序头表 :操作系统打开 ELF 文件后,先读 ELF 头,找到程序头表的位置(
Start of program headers字段),然后解析每个段(Segment)的信息:- 段的虚拟地址(
VirtAddr):这个段在进程虚拟地址空间中的起始位置; - 段的大小(
MemSiz):在内存中占用的大小; - 段的权限(
Flags):R(读)、W(写)、E(执行); - 段在 ELF 文件中的偏移(
Offset):从文件哪里读取数据加载到内存。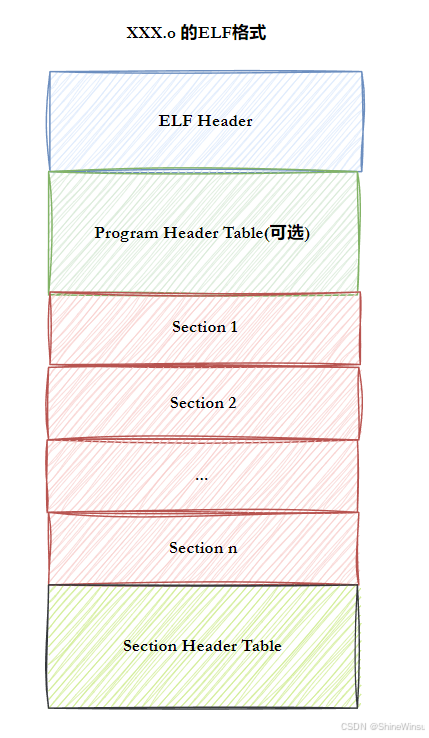
- 段的虚拟地址(
-
创建 vm_area_struct :每个段对应一个
vm_area_struct,操作系统会根据段的VirtAddr和MemSiz设置vm_area_struct的vm_start(分区起始)和vm_end(分区结束),根据Flags设置权限(vm_page_prot)。比如 ELF 中两个关键的 LOAD 段:
- 只读可执行段(R E):对应
vm_area_struct的vm_start=0x400000,vm_end=0x400744,权限为 "可读可执行"(代码段、只读数据段); - 可读可写段(RW):对应
vm_area_struct的vm_start=0x600e10,vm_end=0x601030,权限为 "可读可写"(数据段、BSS 段)。
- 只读可执行段(R E):对应
-
组装 mm_struct :把所有
vm_area_struct链表挂到mm_struct的mmap字段下,同时设置mm_struct的start_code(代码段起始)、end_code(代码段结束)、start_data(数据段起始)等字段,这些字段的值也来自 ELF 程序头表的段信息。 -
初始化页表:操作系统会为进程创建页表,将
vm_area_struct描述的虚拟地址范围,映射到物理内存(或暂时不映射,用 "请求分页" 延迟分配)。比如.text段的虚拟地址0x400400会被映射到物理内存的某个页框,程序执行时通过页表找到实际物理地址。
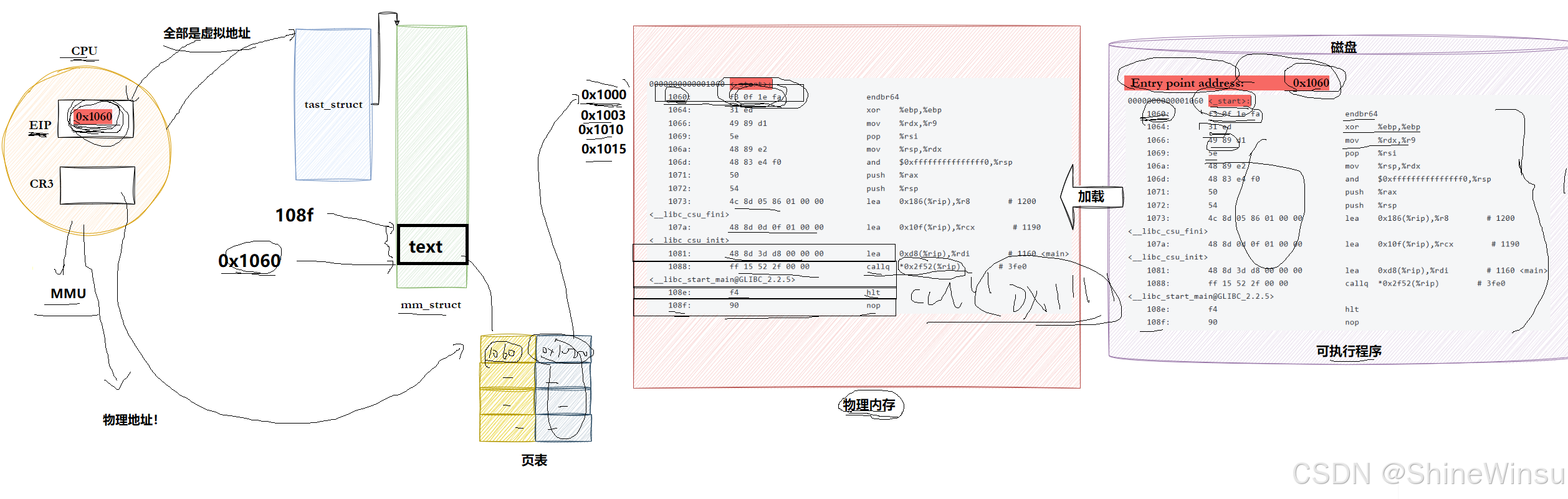
三、重新理解进程虚拟地址空间:ELF 如何 "填" 进地址空间?
进程的虚拟地址空间(以 x86_64 为例)是一个从0x0000000000000000到0xFFFFFFFFFFFFFFFF的巨大范围,被划分为多个区域。ELF 的段会被 "填" 到其中的特定区域,我们结合 ELF 的 Entry 入口地址,用 "分区图" 来描述:
进程虚拟地址空间分区(从低到高):
| 区域 | 虚拟地址范围(示例) | 对应 ELF 的段 / 节 | 权限 | 作用 |
|---|---|---|---|---|
| 代码段 | 0x400000 - 0x400744 | LOAD 段(R E):.text、.rodata | R E | 存放可执行指令、只读数据 |
| 数据段 | 0x600e10 - 0x601020 | LOAD 段(RW):.data | R W | 存放已初始化的全局 / 静态变量 |
| BSS 段 | 0x601020 - 0x601030 | LOAD 段(RW):.bss | R W | 存放未初始化的全局 / 静态变量 |
| 堆 | 0x602000 - 向上增长 | 无对应 ELF 段(运行时分配) | R W | 动态内存分配(malloc) |
| 共享库 | 0x7ffff7a00000 左右 | 动态库的 LOAD 段 | R E / R W | 存放共享库的代码和数据 |
| 栈 | 0x7fffffffdf00 左右 | 无对应 ELF 段(运行时分配) | R W | 存放函数栈帧、局部变量 |
ELF 的 Entry 入口地址如何起作用?
ELF 头的Entry point address字段(比如0x400520)记录的是程序第一个执行指令的虚拟地址(通常是_start函数,在 main 之前,由 glibc 提供)。当进程创建后,操作系统会把 CPU 的程序计数器(PC)设置为这个 Entry 地址,进程从此处开始执行,相当于 "小区建成后,第一个住户从入口进入"。
关键:ELF 的虚拟地址与进程地址空间的关系
ELF 在编译时预分配的虚拟地址,直接对应进程地址空间中的地址。比如 ELF 中.text节的起始地址是0x400400,加载后,这个地址就属于进程地址空间的 "代码段" 区域,vm_area_struct会覆盖这个范围,页表也会将其映射到物理内存。程序执行时,访问0x400400就会找到对应的代码指令 ------ 这就是 "平坦地址空间" 的好处:程序用的地址和加载到内存后的地址一致,无需修改。

四、总结:虚拟地址是编译器和操作系统的 "约定"
- ELF 未加载时有地址:编译器和链接器按 "平坦模式" 给 ELF 的代码、数据分配虚拟地址(反汇编能看到),这些地址是程序运行时的 "目标地址";
- 进程地址空间初始化靠 ELF 段 :操作系统通过解析 ELF 的程序头表,用段的
VirtAddr、MemSiz、Flags初始化mm_struct和vm_area_struct,构建地址空间的 "分区"; - Entry 地址是执行起点:ELF 头记录的入口地址,是进程开始执行的第一个虚拟地址,由操作系统设置到 CPU 的 PC 寄存器中。
简单说:编译器画好 "地址蓝图"(ELF 的虚拟地址),操作系统按蓝图 "盖楼"(进程地址空间),程序按蓝图 "入住"(执行时用蓝图地址访问内存)。这就是虚拟地址机制的核心 ------ 编译器和操作系统合作,让程序 "以为自己独占内存",实际通过页表映射到物理内存,既安全又高效。
8. 动静态链接深度解析:从 "买工具" 到 "租工具"
动静态链接是核心中的核心,之前已经讲过基本原理,现在补充 "新手不知道的细节":静态库的链接优化、动态库的 SONAME 和 RPATH、GOT 和 PLT 的详细交互、延迟绑定的实现,每个点都用 "生活例子 + 实操验证" 讲透。
8.1 静态链接:"买工具回家"(补充 5 个关键细节)
静态链接的核心是 "复制 - 合并",但还有很多新手不知道的细节,比如 "链接器只复制需要的.o 文件""静态库的链接优化" 等,我们逐一拆解:
8.1.1 细节 1:链接器只复制 "需要的.o 文件"(不复制整个静态库)
静态库是多个.o 的归档包,链接器会 "按需提取"------ 只复制程序用到的.o 文件,不用的.o 文件不会复制到可执行程序中,避免冗余。
实操验证:
# 1. 静态库libmath.a包含add.o(add函数)和sub.o(sub函数)
ar t libmath.a # 输出:add.o sub.o
# 2. 程序main.c只调用add函数,不调用sub函数
cat main.c
#include<stdio.h>
int add(int a, int b);
int main() {
printf("1+2=%d\n", add(1,2));
return 0;
}
# 3. 编译链接
gcc -c main.c -o main.o
gcc main.o -lmath -L./ -o main_static.exe
# 4. 查看可执行程序中的符号(只有add,没有sub)
readelf -s main_static.exe | grep -E "add|sub"
# 输出:52: 00000000004005d0 17 FUNC GLOBAL DEFAULT 16 add
# 没有sub的符号------说明sub.o没被复制到可执行程序中8.1.2 细节 2:静态链接的 "重定位类型"(新手不用记,但要懂)
之前提到重定位表的类型是R_X86_64_PC32,这是 64 位 x86 架构最常见的重定位类型,还有其他类型,比如R_X86_64_32(绝对地址重定位)、R_X86_64_GOT32(GOT 相关重定位)等。
R_X86_64_PC32:PC 相对寻址 ------ 修正后的地址是 "符号实际地址 - 当前指令地址 - 偏移",适合代码段(.text);R_X86_64_32:绝对地址 ------ 修正后的地址是 "符号实际地址",适合数据段(.data)。
8.1.3 细节 3:静态库的 "链接优化"(--gc-sections 参数)
链接器可以通过--gc-sections参数,删除 "未使用的节"(比如程序没调用的函数所在的.text 节),进一步减小可执行程序的体积。
实操验证:
# 1. 编译时添加-fdata-sections和-ffunction-sections,让每个函数/数据放在独立的节
gcc -c -fdata-sections -ffunction-sections add.c -o add.o
gcc -c -fdata-sections -ffunction-sections sub.c -o sub.o
ar rcs libmath.a add.o sub.o
# 2. 链接时添加--gc-sections,删除未使用的节
gcc main.o -lmath -L./ -o main_static_opt.exe --gc-sections
# 3. 对比优化前后的体积
ls -l main_static.exe main_static_opt.exe
# 输出:优化后的main_static_opt.exe体积更小8.1.4 细节 4:静态链接的 "符号冲突"(新手容易踩的坑)
如果两个.o 文件定义了同名的全局符号(比如 hello.o 和 code.o 都定义了int g_val=10),静态链接时会报 "多重定义" 错误:
# 1. hello.c定义g_val
cat hello.c
#include<stdio.h>
int g_val=10; // 全局变量
void run();
int main() { printf("g_val=%d\n", g_val); run(); return 0; }
# 2. code.c也定义g_val
cat code.c
int g_val=20; // 同名全局变量
void run() { printf("code: g_val=%d\n", g_val); }
# 3. 编译链接
gcc -c hello.c code.c
gcc hello.o code.o -o main.exe
# 报错:code.o:(.data+0x0): multiple definition of `g_val'; hello.o:(.data+0x0): first defined here解决方法:把其中一个变量改成静态变量(static int g_val=10),静态变量是局部符号,即只在本文件内生效,其他的文件和他都没有关系,不会冲突。
8.1.5 细节 5:静态库的 "调试信息"(-g 参数)
编译时添加-g参数,会在目标文件中保留调试信息(比如行号、变量名),链接后的可执行程序也会包含调试信息,方便用 gdb 调试。
实操验证:
# 1. 编译时添加-g,保留调试信息
gcc -c -g hello.c code.c
gcc hello.o code.o -o main_debug.exe -g
# 2. 用gdb调试,能看到行号和变量名
gdb main_debug.exe
(gdb) break main # 设置断点
(gdb) run # 运行
(gdb) print g_val # 查看变量值(如果有g_val)8.2 动态链接:"租工具用"
动态链接比静态链接复杂,但更常用
8.2.1 细节 1:动态库的 "SONAME"(共享库的 "身份证")
动态库有一个 "SONAME"(Shared Object Name),用于标识库的 "兼容版本"------ 比如libmyrun.so.1,其中 "1" 是主版本号,只要主版本号相同,就表示兼容(可以替换)。
为什么需要 SONAME?比如你开发的程序依赖libmyrun.so.1,后续库升级到libmyrun.so.1.2(修复 bug),只要 SONAME 还是libmyrun.so.1,程序就能直接使用新库,不用重新编译。
实操生成带 SONAME 的动态库:
# 1. 生成动态库,指定SONAME为libmyrun.so.1
gcc -fPIC -shared -Wl,-soname,libmyrun.so.1 -o libmyrun.so.1.0 code.c
# 2. 创建符号链接:libmyrun.so -> libmyrun.so.1 -> libmyrun.so.1.0
ln -s libmyrun.so.1.0 libmyrun.so.1
ln -s libmyrun.so.1 libmyrun.so
# 3. 查看动态库的SONAME
readelf -d libmyrun.so.1.0 | grep "SONAME"
# 输出:0x000000000000000e (SONAME) Library soname: [libmyrun.so.1]8.2.2 细节 2:动态库的 "RPATH"(程序自带的 "库路径")
**动态链接程序运行时,动态链接器会按 "RPATH → LD_LIBRARY_PATH → 系统目录" 的顺序查找动态库,这也是我们上篇博客中,说可以改变这个环境变量去让系统找到我们的自定义库,**RPATH 是程序自带的库路径,编译时可以通过-Wl,-rpath参数指定,避免设置环境变量。
实操验证:
# 1. 动态库放在./lib目录下
mkdir lib
mv libmyrun.so.1.0 lib/
ln -s lib/libmyrun.so.1.0 lib/libmyrun.so.1
ln -s lib/libmyrun.so.1 lib/libmyrun.so
# 2. 编译程序时,指定RPATH为./lib(程序运行时会先找./lib目录)
gcc hello.o -lmyrun -L./lib -Wl,-rpath,./lib -o main_rpath.exe
# 3. 运行程序,不用设置LD_LIBRARY_PATH,能找到库
./main_rpath.exe
# 输出:hello world! running...如果把可执行程序 比作 "手机",动态库 (比如libc.so)比作 "共享充电宝",那么动态链接的本质就是:手机(程序)不自带充电宝(静态库代码),而是出门在外 "租" 充电宝用 ------ 既节省手机重量(程序体积),又能让多个手机共用一个充电宝(内存共享)。
下面我们跟着你的材料,一步步拆解这个 "租赁过程" 的底层逻辑:
一、先搞懂:为什么动态链接比静态链接更常用?
静态链接是 "买充电宝回家"------ 把库代码直接焊进程序,优点是不用依赖外部,但缺点致命:
- 体积大 :每个程序都带一份
libc.so代码,100 个程序就有 100 份,浪费磁盘 / 内存; - 升级难 :
libc.so修复 bug 后,所有依赖它的程序都要重新编译链接。
动态链接是 "租充电宝"------ 程序只带 "租赁接口",运行时才加载库代码,优点刚好互补:
- 体积小 :程序只存库的 "引用",不存代码,100 个程序共用一份
libc.so内存副本; - 升级易 :
libc.so升级后,所有程序直接用新库,不用重新编译; - 灵活 :动态库可随时替换(只要接口不变),比如换个优化版的
libmath.so,程序不用改。
用ldd命令验证程序的动态依赖:
# 查看ls命令的动态依赖
ldd /usr/bin/ls
# 输出会显示ls依赖libc.so.6、libselinux.so.1等多个动态库
# 查看我们的main.exe依赖
ldd main.exe
# 输出:只依赖libc.so.6(C标准库)和动态链接器ld-linux.so.2这说明:几乎所有 Linux 程序都是动态链接的,动态库是系统 "共享资源"。
二、关键前提:程序入口不是 main!是_start
我们写的main函数根本不是程序的第一个执行指令,真正的入口是_start(由 glibc 提供)。_start的核心任务是 "初始化环境,为 main 函数铺路",其中最关键的一步就是触发动态链接。
_start 的完整初始化流程:
我们把_start比作 "手机开机后的初始化",步骤如下:
- 设置堆栈:给程序分配栈空间(存放局部变量、函数参数),就像手机开机后初始化内存;
- 初始化数据段 :把 ELF 里的
.data(已初始化全局变量)复制到内存,把.bss(未初始化全局变量)清零,就像手机加载系统配置; - 动态链接(核心) :调用动态链接器(
ld-linux.so.2),解析程序依赖的所有动态库(比如libc.so.6),加载到内存并完成地址映射; - 调用__libc_start_main:glibc 的核心函数,做最后初始化(比如设置信号处理、线程库初始化);
- 调用 main 函数 :终于把执行权交给我们写的
main,就像手机初始化完成,打开你要的 APP; - 处理返回值 :main 返回后,
__libc_start_main调用_exit终止进程,释放资源。
动态链接器是什么?
动态链接器(ld-linux.so.2)是 "充电宝管理员"------ 它的作用是:
- 按顺序查找动态库(通过
LD_LIBRARY_PATH、/etc/ld.so.conf、系统默认路径); - 把动态库加载到进程地址空间(动态分配地址);
- 解析库中的符号(函数 / 变量),修正程序中的调用地址(GOT 表填充)。
三、动态库的核心:地址无关代码(PIC)
动态库的加载地址是 "不固定" 的 ------ 操作系统会根据当前内存使用情况,给它分配任意一段连续地址(比如这次加载到0x7f0000000000,下次可能是0x7f1000000000)。
问题来了:动态库的代码怎么做到 "加载到任意地址都能正常运行"?答案是PIC(Position Independent Code)------ 地址无关代码。
PIC 的本质:相对编址,不是绝对编址
动态库编译时加了-fPIC参数,编译器会把库中的所有地址都变成 "相对地址"(相对于库的加载起始地址),而不是固定的绝对地址。
举个例子(看动态库的反汇编):
# 反汇编libc.so,查看puts函数的指令
objdump -S /lib/x86_64-linux-gnu/libc-2.31.so | grep -A 5 "puts@@GLIBC_2.2.5"输出(简化):
00000000000765a0 <puts@@GLIBC_2.2.5>:
765a0: f3 0f 1e fa endbr64
765a4: 41 54 push %r12
765a6: 49 89 f4 mov %rsi,%r12
765a9: 55 push %rbp
765aa: 48 89 e5 mov %rsp,%rbp- 这里的
00000000000765a0是puts在库中的相对偏移地址,不是绝对地址; - 当库被加载到
0x7f0000000000时,puts的实际绝对地址是0x7f0000000000 + 0x765a0 = 0x7f0000765a0; - 下次加载到
0x7f1000000000时,实际地址就是0x7f1000000000 + 0x765a0 = 0x7f1000765a0; - 库中的代码用 "相对寻址" 访问自己的函数 / 变量,所以不管加载到哪,都能正确找到。
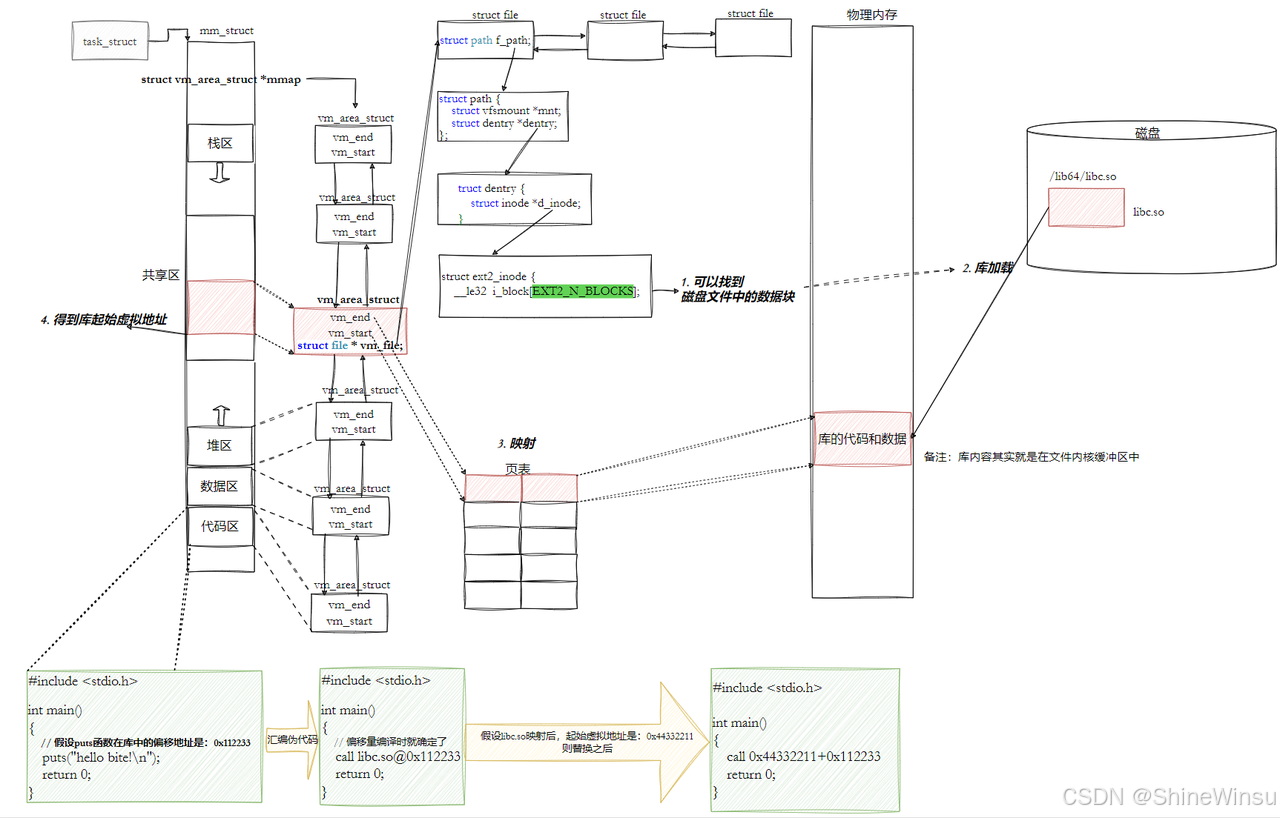
四、程序与动态库的映射:把 "充电宝" 接入 "手机"
动态库是文件,要被程序调用,必须先 "加载到进程地址空间"------ 就像把共享充电宝接入手机,步骤如下:
- 动态链接器打开动态库文件:读取库的 ELF 头和程序头表(和加载可执行程序一样);
- 分配虚拟地址空间 :在当前进程的地址空间中,给动态库分配一块连续的虚拟地址(比如
0x7f0000000000到0x7f0000800000); - 加载库的段到内存:把库的 "只读可执行段"(.text+.rodata)加载到分配的地址,"可读可写段"(.data+.bss)也加载到对应位置;
- 记录库的起始地址 :动态链接器会保存库的 "加载起始地址"(比如
0x7f0000000000),后续调用库函数时用 "起始地址 + 相对偏移" 定位。
关键:映射后,库和程序在同一个地址空间
就像充电宝接入手机后,手机能直接用充电宝的电,程序能直接通过虚拟地址访问库的代码 ------ 整个调用过程都在进程自己的地址空间里,不用跨进程,速度很快。
进程如何看到动态库?------ 从 "找充电宝" 到 "接入手机"
进程本身看不到 "动态库文件(.so)",它只能看到 "映射到自己地址空间的虚拟地址"------ 就像手机看不到充电宝的实体,只看到 "接入后能充电的接口"。整个过程由 "动态链接器 + 内核" 配合完成,分 5 个关键步骤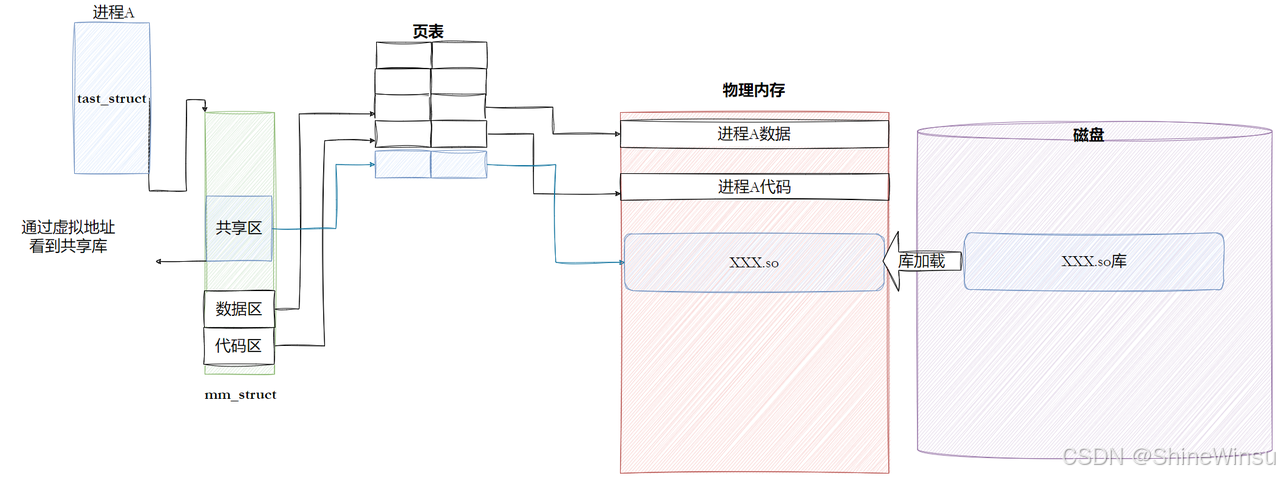
核心前提:进程的 "地址空间" 是 "专属房间"
每个进程都有独立的 "虚拟地址空间"(比如 x86_64 是 0x0000000000000000 到 0xFFFFFFFFFFFFFFFF),相当于 "专属房间"。动态库要让进程 "看到",必须先 "搬进这个房间"(映射到虚拟地址空间),变成房间里的 "可用设备"。
步骤 1:动态链接器 "按规则找库"------ 手机找共享充电宝的 "搜索范围"
进程启动后,_start函数会调用动态链接器(ld-linux.so.2),动态链接器按以下固定顺序查找动态库(比如libc.so.6),找不到就报错 "cannot open shared object file":
| 查找顺序 | 对应场景(比喻) | 具体说明 | 实操验证命令 | |
|---|---|---|---|---|
| 1 | 手机优先看 "口袋里的充电宝" | 环境变量LD_LIBRARY_PATH指定的路径(临时生效,适合测试) |
echo $LD_LIBRARY_PATH(查看当前路径) |
|
| 2 | 手机看 "常用充电宝缓存" | 系统缓存文件/etc/ld.so.cache(记录已找到的库路径,加速查找) |
`ldconfig -p | grep libc.so.6`(查看缓存) |
| 3 | 手机看 "公共充电宝存放点" | 配置文件/etc/ld.so.conf及/etc/ld.so.conf.d/下的路径(全局共享) |
cat /etc/ld.so.conf(查看配置) |
|
| 4 | 手机看 "默认充电宝存放点" | 系统默认路径(/lib、/lib64、/usr/lib、/usr/lib64) |
ls /lib64/libc.so.6(查看系统库) |
关键:缓存的作用
/etc/ld.so.cache是动态库的 "快捷方式列表",动态链接器先查缓存,不用每次都遍历所有路径 ------ 就像你记了常用充电宝的位置,不用每次都满大街找,大大提升查找速度。修改LD_LIBRARY_PATH或ld.so.conf后,要执行sudo ldconfig更新缓存。
步骤 2:动态链接器 "验证库的合法性"------ 检查充电宝是否能兼容
找到.so文件后,动态链接器会打开文件,读取 ELF 头:
- 验证魔数(
7f 45 4c 46):确认是 ELF 格式的动态库(不是文本文件、Windows 的.dll); - 验证架构(x86_64/arm):确保库和进程的 CPU 架构一致(比如 64 位进程不能用 32 位库);
- 验证 SONAME:确认库的版本兼容(比如程序依赖
libmyrun.so.1,就不能用libmyrun.so.2)。
步骤 3:内核 "分配虚拟地址"------ 给充电宝在房间里找个位置
动态链接器向内核发起 "内存映射请求"(mmap系统调用),内核会做两件事:
- 在进程的虚拟地址空间中,分配一块连续的虚拟地址范围(比如
0x7f0000000000到0x7f0000800000),专门给这个动态库用 ------ 就像在你的房间里腾出一块地方放充电宝; - 记录这个 "虚拟地址起始地址"(比如
0x7f0000000000),后续告诉动态链接器。
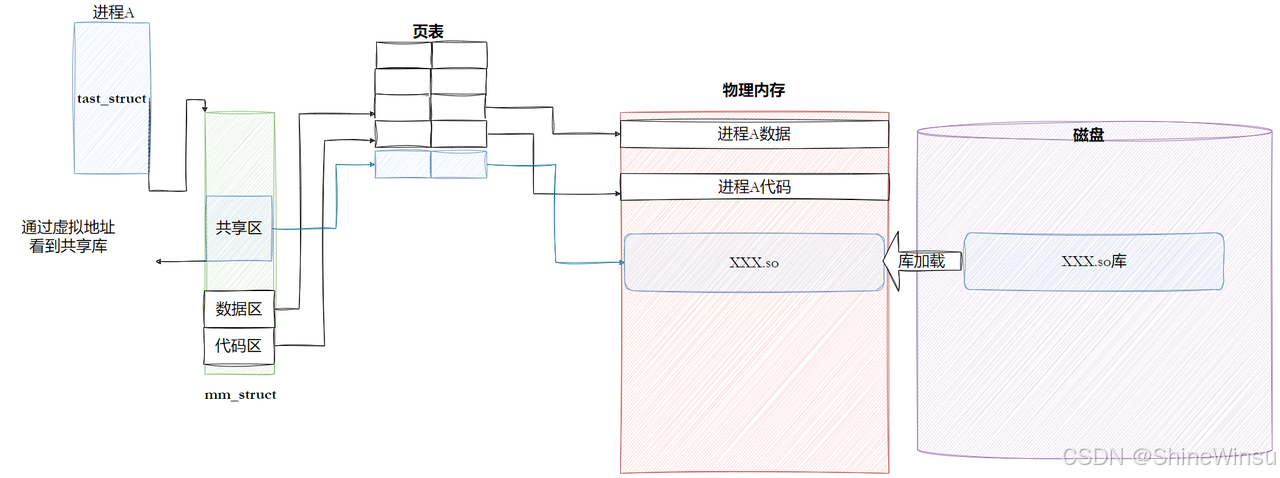
步骤 4:内核 "加载并映射库到内存"------ 把充电宝接入房间的电源
内核会把动态库的 ELF 文件内容,按程序头表的指示加载到物理内存,再通过页表建立 "虚拟地址→物理地址" 的映射:
- 库的
text节(代码段)、rodata节(只读数据段):加载到物理内存的 "只读页",页表标记 "只读可执行"; - 库的
data节(数据段)、bss节(未初始化数据段):加载到物理内存的 "可写页",页表标记 "可读可写"; - 映射完成后,进程的虚拟地址空间中,
0x7f0000000000开始的地址,就对应库的代码和数据 ------ 相当于充电宝接入了房间的电源,手机(进程)能通过这个 "虚拟地址接口" 访问库。
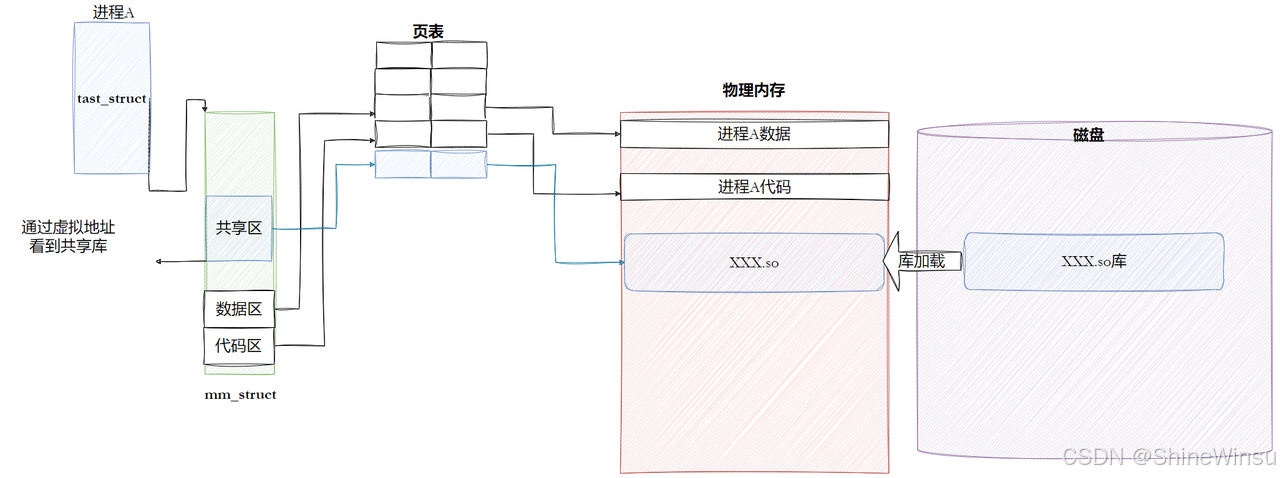
实操验证:查看进程地址空间中的动态库映射
运行程序后,用/proc/[pid]/maps查看进程的地址空间,能看到动态库的虚拟地址范围:
# 1. 运行程序(比如main.exe),后台执行
./main.exe &
# 2. 查看进程PID(比如PID是1234)
ps aux | grep main.exe
# 3. 查看进程的地址空间映射
cat /proc/1234/maps | grep libc.so.6输出(关键部分):
7f0000000000-7f0000080000 r-xp 00000000 08:01 1234 /lib64/libc-2.31.so
# 虚拟地址范围:7f0000000000-7f0000080000;权限r-xp(只读可执行,对应text+rodata)
7f0000080000-7f0000280000 ---p 00080000 08:01 1234 /lib64/libc-2.31.so
7f0000280000-7f0000284000 r--p 00080000 08:01 1234 /lib64/libc-2.31.so
7f0000284000-7f0000286000 rw-p 00084000 08:01 1234 /lib64/libc-2.31.so
# 权限rw-p(可读可写,对应data+bss)这就是进程 "看到" 的动态库 ------ 一段段有明确权限的虚拟地址。
步骤 5:动态链接器 "修正地址"------ 告诉手机怎么用充电宝
映射完成后,库的代码是 "地址无关(PIC)" 的,但进程调用库函数时需要 "实际虚拟地址",动态链接器会做最后一步:
- 读取库的 ELF 符号表,找到
puts、printf等函数的相对偏移地址(比如puts在库中的偏移是0x765a0); - 结合库的 "虚拟地址起始地址"(
0x7f0000000000),计算出函数的实际虚拟地址(0x7f0000000000 + 0x765a0 = 0x7f0000765a0); - 把这个实际地址填充到进程的GOT 表中(.data 节,可读写);
- 进程调用
puts时,通过PLT桩→GOT表→实际虚拟地址,就能找到库函数 ------ 相当于手机知道了 "按哪个接口能充电"。
总结:进程 "看到" 动态库的本质
进程看不到.so文件本身,只看到 "映射到自己地址空间的虚拟地址段",而这个地址段是内核通过mmap映射的,动态链接器负责 "找库→验证→填地址",最终让进程能通过虚拟地址调用库函数。
进程间如何共享库?------ 多个手机共用一个充电宝,还不抢电
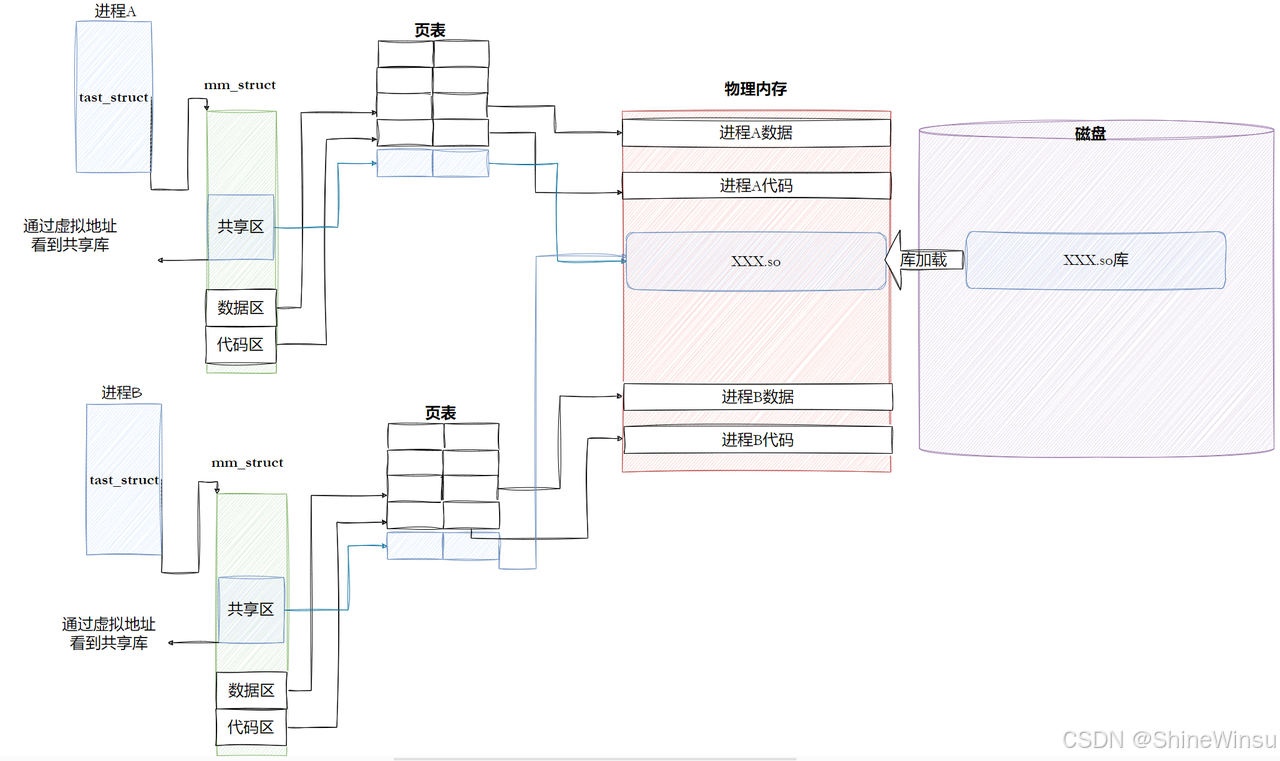
核心结论:进程间共享的是动态库的 "代码段(.text)和只读数据段(.rodata)",不共享 "数据段(.data)、BSS 段、GOT 表" ------ 就像多个手机共用同一个充电宝的 "外壳(代码段)和充电电路(只读数据)",但每个手机用的是自己专属的 "电量(数据段)",互不干扰。
为什么能共享?------ 代码段 "只读" 是关键
- 动态库的
text节(代码)和rodata节(只读数据)是只读 的,编译时加了-fPIC,是地址无关代码; - 内核加载动态库时,会把这些 "只读段" 加载到物理内存的一块固定区域,然后让多个进程的页表,都把 "自己地址空间中的库虚拟地址" 映射到这块物理内存 ------ 相当于多个手机都通过 "数据线" 连接到同一个充电宝的充电接口,共享同一个充电电路。
实操验证:多个进程共享同一物理内存的代码段
用两个进程运行同一个动态链接程序,查看它们的libc.so代码段映射:
# 1. 运行两个main.exe,后台执行
./main.exe &
./main.exe &
# 2. 查看两个进程的PID(比如1234和5678)
ps aux | grep main.exe
# 3. 查看两个进程的libc.so映射
cat /proc/1234/maps | grep libc.so.6 | grep r-xp
cat /proc/5678/maps | grep libc.so.6 | grep r-xp输出(示例):
# 进程1234的libc代码段
7f0000000000-7f0000080000 r-xp 00000000 08:01 1234 /lib64/libc-2.31.so
# 进程5678的libc代码段
7f1000000000-7f1000080000 r-xp 00000000 08:01 1234 /lib64/libc-2.31.so- 两个进程的
libc.so虚拟地址不同(7f0000000000 vs 7f1000000000)------ 每个进程的地址空间独立; - 但它们对应的物理内存是同一块(通过内核页表映射验证)------ 因为
libc.so的代码段只读,不会被修改,所以内核让它们共享。
为什么不共享数据段?------ 写时复制(COW)保证数据独立
动态库的data节(已初始化全局变量)、BSS节(未初始化全局变量)是可写 的,每个进程的这些数据可能不同(比如进程 A 把库的全局变量g_val改成 10,进程 B 可能改成 20),所以不能共享,内核用 "写时复制(COW)" 机制保证数据独立:
写时复制(COW)的通俗流程(以库的全局变量为例):
- 初始状态:进程 A 和进程 B 的
libc.so数据段,都映射到物理内存的同一块地址(比如0x12345678),g_val的初始值是 0; - 进程 A 修改
g_val = 10:- 内核检测到 "写操作",且该物理页是 "共享页";
- 内核立刻复制一份该物理页(新地址
0x87654321),把g_val改成 10; - 把进程 A 的页表中,"数据段虚拟地址" 对应的物理地址,从
0x12345678改成0x87654321;
- 进程 B 的
g_val仍为 0:它的页表还映射到原物理地址0x12345678,不受进程 A 的修改影响; - 后续进程 A 再修改
g_val,只会操作自己的物理页,进程 B 的页表不变。
核心:写时复制的好处
- 未修改时共享物理内存,节省资源(比如 100 个进程共用
libc.so,数据段只占 1 份物理内存,修改后才复制); - 修改后数据独立,保证进程间互不干扰(每个进程的 "电量" 不互通)。
哪些部分绝对不共享?
除了数据段和 BSS 段,以下部分每个进程都独立,不共享:
- GOT 表 :每个进程的库加载地址可能不同(比如进程 A 的
libc.so起始地址是0x7f0000000000,进程 B 是0x7f1000000000),GOT 表中填充的函数实际地址不同,必须私有; - 栈和堆 :栈存储函数局部变量、堆存储
malloc分配的动态内存,是进程专属的,和库无关; - 进程控制块(PCB)和 mm_struct:每个进程的 PCB(进程信息)、mm_struct(地址空间描述)都是独立的,记录自己的映射关系。
总结:进程间共享库的本质
- 共享的是 "只读的代码和只读数据":内核通过 "多进程页表映射到同一块物理内存" 实现,节省磁盘和内存资源;
- 不共享的是 "可写的数据和地址相关表":通过 "写时复制" 保证数据独立,通过独立 GOT 表保证地址正确;
- 核心是 "只读段共享,可写段私有",既利用了共享的高效性,又保证了进程的独立性。
五、库函数调用的核心:GOT+PLT(解决 "代码段只读" 问题)
这是动态链接最绕的部分,代码段是只读的,不能修改,怎么动态修正库函数的调用地址?
答案是:用 "GOT(全局偏移表)+ PLT(过程链接表)" 的组合,把 "地址修改" 转移到可读写的.data 节,完美避开代码段只读的限制。
我们用 "手机 - 充电宝" 比喻升级:
- GOT:手机里的 "充电宝接口地址本"(在.data 节,可读写),记录每个共享充电宝(库函数)的实际接口地址;
- PLT:手机上的 "接口桩"(在.text 节,只读),负责 "查地址本→连接充电宝",自己不存地址,只做转发。
1. GOT(全局偏移表):可读写的 "地址本"
- 位置:在程序的.data 节(或库的.data 节),权限是 "可读可写";
- 内容:每个条目对应一个需要调用的库函数 / 全局变量,存储它们的实际虚拟地址(加载后由动态链接器填充);
- 特点:每个进程的 GOT 表是独立的(因为不同进程的动态库加载地址可能不同),但库的.text 节是共享的 ------ 这就实现了 "代码共享,地址独立"。
2. PLT(过程链接表):只读的 "接口桩"
- 位置:在程序的.text 节(或库的.text 节),权限是 "只读可执行";
- 内容:每个库函数对应一个 "桩函数"(stub),比如
puts@plt,本质是一段短小的跳转指令; - 作用:代码段不能直接访问 GOT 表的绝对地址,PLT 用 "相对寻址" 找到 GOT 表,再根据 GOT 表中的地址跳转 ------ 相当于 "接口桩查地址本,再连接充电宝"。
3. 结合反汇编,逐行解释调用过程
反汇编代码:
0000000000001050 <puts@plt>: # PLT桩:puts的接口桩
1050: f3 0f 1e fa endbr64
1054: f2 ff 25 75 2f 00 00 bnd jmpq *0x2f75(%rip) # 跳转到GOT表中的条目
# 0x2f75(%rip):RIP是当前指令地址(1054+6=105a),105a+2f75=3fd0 → GOT表中0x3fd0的位置
# *表示"取地址中的值":即GOT[3fd0]存储的地址
0000000000001149 <main>: # 我们的main函数
1149: f3 0f 1e fa endbr64
114d: 55 push %rbp
114e: 48 89 e5 mov %rsp,%rbp
1151: 48 8d 3d ac 0e 00 00 lea 0xeac(%rip),%rdi # 加载字符串地址到rdi(puts的参数)
1158: e8 f3 fe ff ff callq 1050 <puts@plt> # 调用puts@plt桩我们拆解main调用puts的过程,分 "第一次调用" 和 "后续调用":
(1)第一次调用 puts:触发动态链接(延迟绑定)
main执行callq 1050 <puts@plt>:跳转到 PLT 桩puts@plt;- PLT 桩执行
jmpq *0x2f75(%rip):通过相对寻址找到 GOT 表中puts对应的条目(GOT 3fd0); - 此时 GOT 3fd0 还没被填充,默认指向 PLT 桩的下一条指令(
105a); - 程序跳回 PLT 桩的下一条指令,这条指令会触发动态链接器的
_dl_runtime_resolve函数("地址解析函数"); - 动态链接器做两件事:
- 查找
puts函数在libc.so中的实际地址(比如0x7f0000765a0); - 把这个实际地址填充到 GOT 3fd0 中(更新地址本);
- 查找
- 动态链接器跳转到
puts的实际地址,执行打印逻辑; puts执行完,返回main。
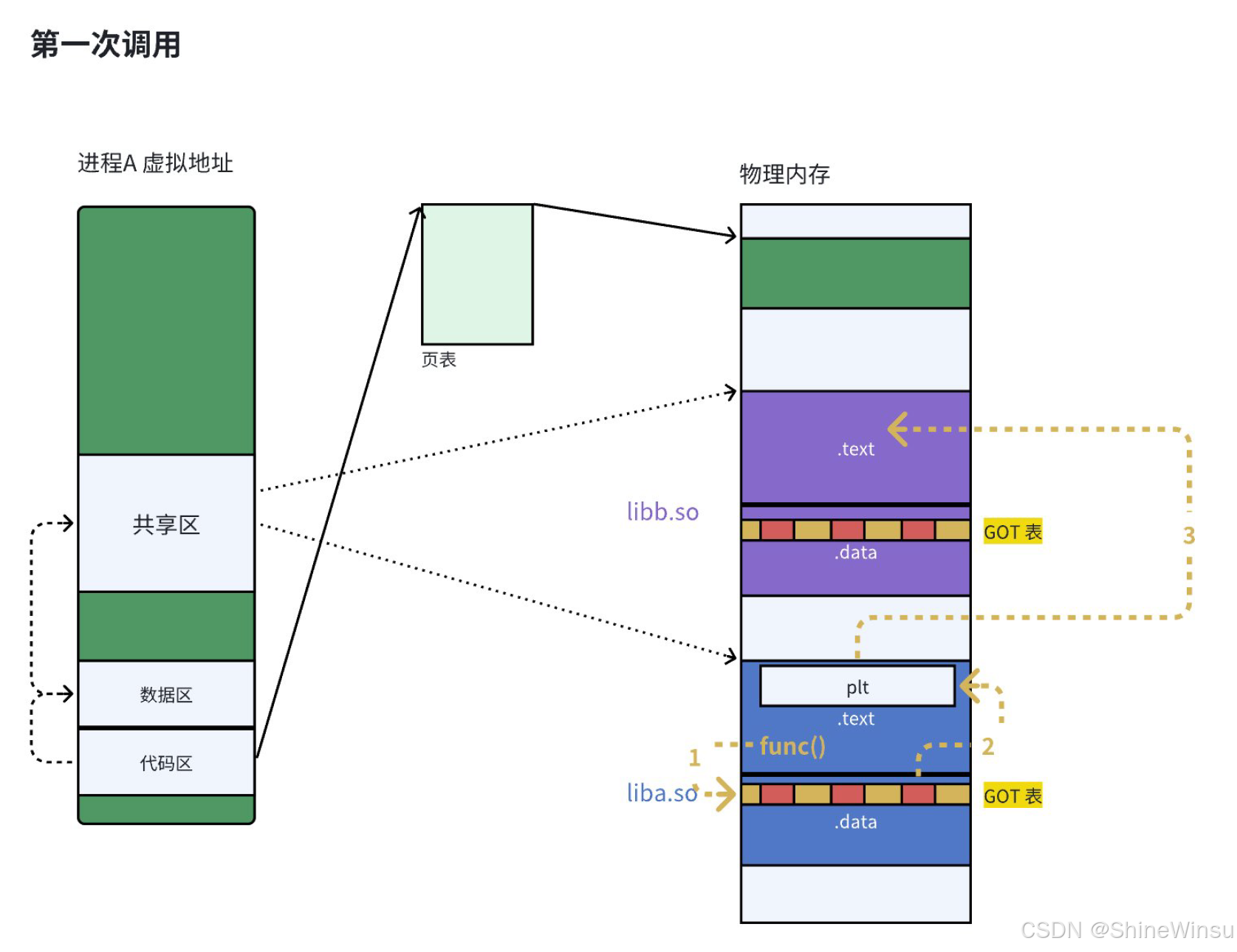
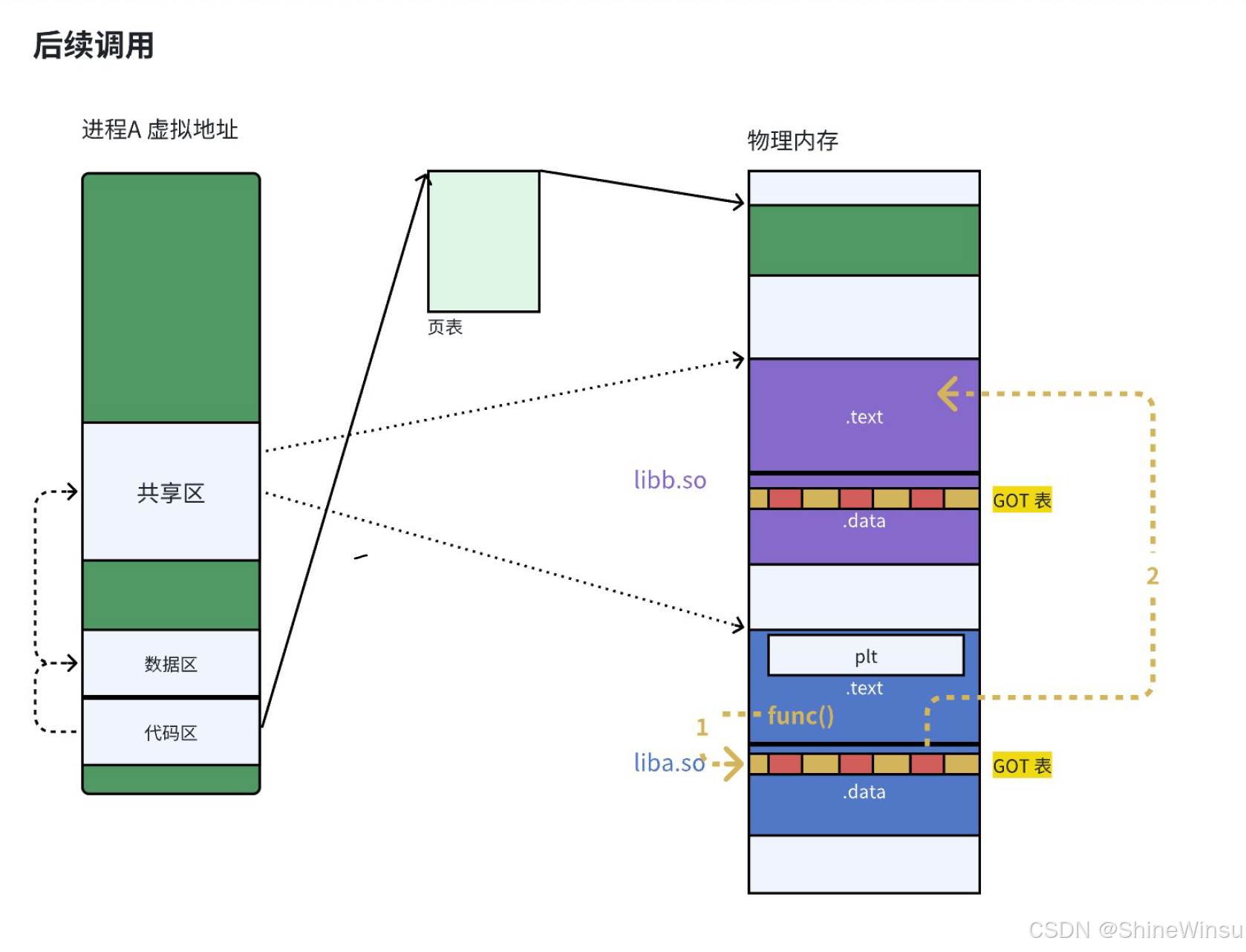
(2)后续调用 puts:直接跳转(无需解析)
main再次执行callq 1050 <puts@plt>:跳转到 PLT 桩;- PLT 桩执行
jmpq *0x2f75(%rip):查找 GOT 3fd0; - 此时 GOT 3fd0 已经存储了
puts的实际地址(0x7f0000765a0); - 程序直接跳转到
0x7f0000765a0,执行puts,无需再调用动态链接器; - 执行完返回
main。
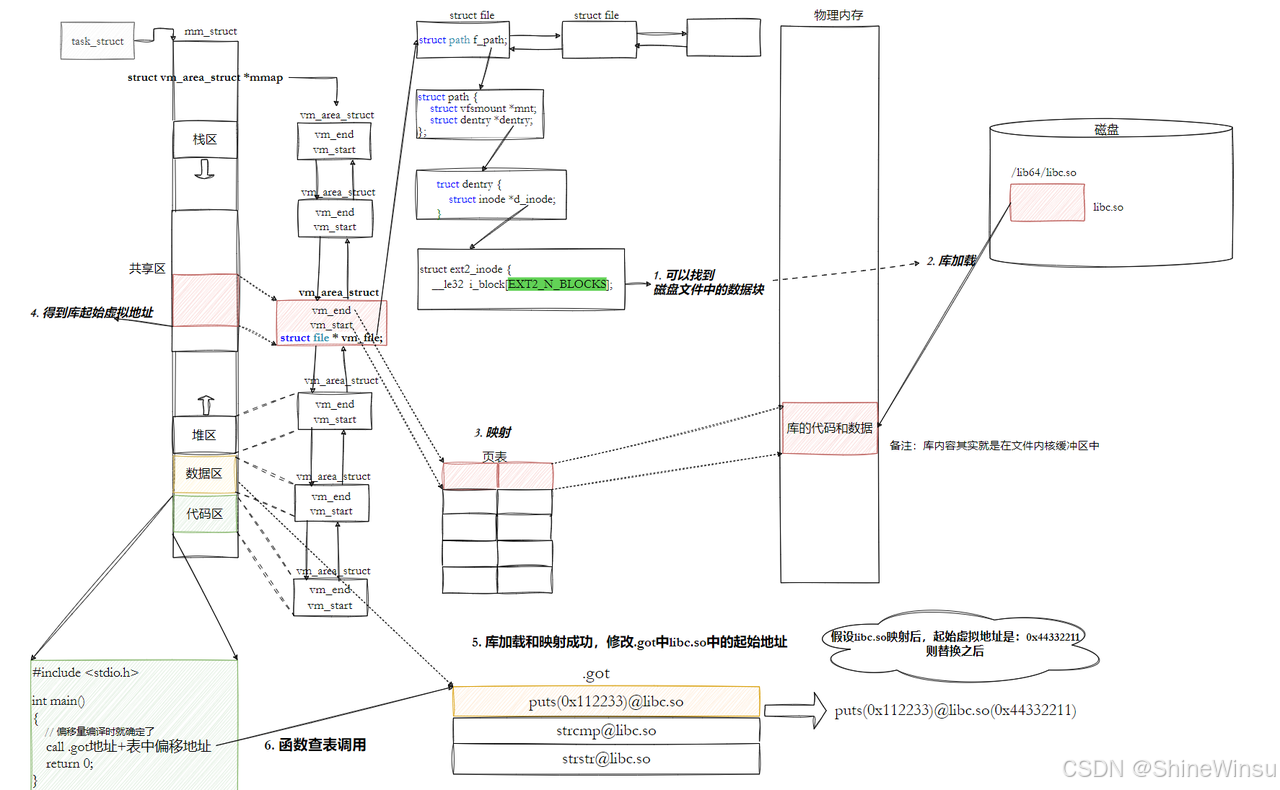
4. 为什么要这么设计?(延迟绑定的优势)
如果程序一开始就解析所有库函数的地址,会浪费时间 ------ 很多函数可能全程都不用调用(比如libc.so里的sin、cos函数,程序没用到)。
延迟绑定(Lazy Binding)的核心是:函数第一次被调用时才解析地址,后续直接用 GOT 表中的地址------ 大大减少程序启动时间,提升效率。
六、PIC 的完整实现:相对编址 + GOT
之前说 PIC 是 "地址无关代码",现在结合 GOT,就能明白它的完整逻辑:
- 库内部的函数 / 变量调用:用 "相对编址"(比如
call 0x100,相对于当前指令的偏移),不需要 GOT; - 库外部的函数 / 变量调用(比如库调用另一个库的函数):用 "GOT+PLT",通过 GOT 表中的绝对地址跳转 ------ 因为外部函数的地址不确定,只能靠动态链接器填充 GOT。
这就是为什么编译动态库必须加-fPIC:-fPIC会告诉编译器 "生成相对编址的代码,并预留 GOT 表条目",让库能加载到任意地址,还能调用外部函数。
七、库间依赖:充电宝也能租充电宝(对应材料 8-3-3-7)
"库也会调用其他库"------ 比如libselinux.so.1(ls 依赖的库)可能调用libc.so.6的函数,这就是库间依赖。
库间依赖的实现很简单:每个动态库都有自己的 GOT 和 PLT,和可执行程序完全一样!
- 库 A 调用库 B 的函数时,库 A 的 PLT 桩会查自己的 GOT 表;
- 动态链接器加载库 A 时,会同时加载库 B,填充库 A 的 GOT 表中对应函数的地址;
- 整个过程和 "程序调用库" 完全一致,因为所有库都是 ELF 格式,遵循同样的 GOT/PLT 规则。
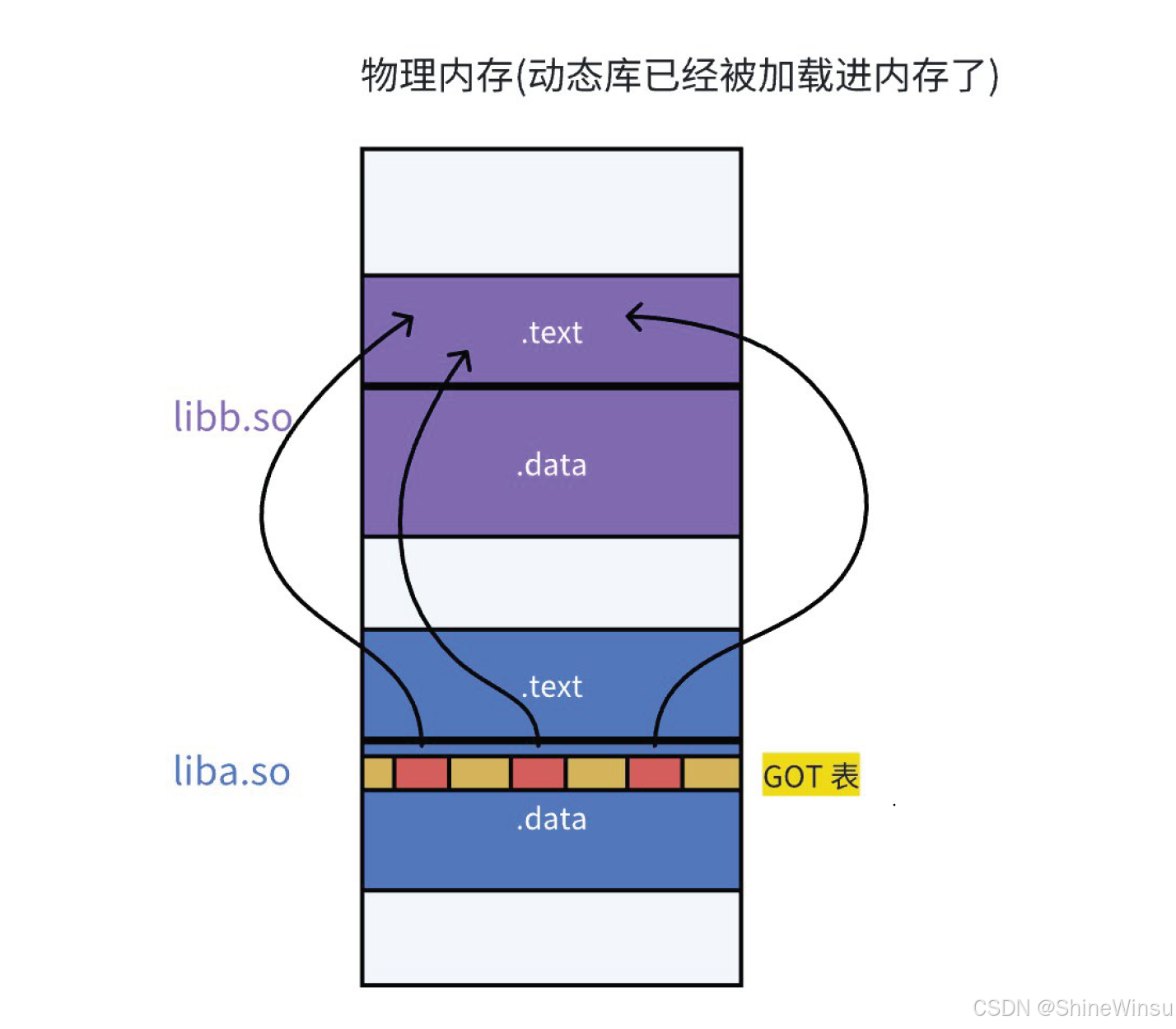
总结:动态链接的完整流程(一张 "文字图" 看懂)
程序启动 → 操作系统创建进程 → _start函数初始化 → 调用动态链接器(ld-linux.so.2)
→ 动态链接器按路径查找依赖的动态库(如libc.so.6)
→ 加载动态库到进程地址空间(动态分配起始地址)
→ 初始化库的GOT表(填充内部函数的相对地址)
→ 程序执行main函数 → 第一次调用puts:
main → puts@PLT(桩) → GOT表(未填充) → 动态链接器解析puts地址 → 填充GOT表 → 执行puts
→ 第二次调用puts:
main → puts@PLT(桩) → GOT表(已填充puts实际地址) → 直接执行puts
→ main返回 → __libc_start_main → _exit终止进程8.3 动静态链接的常见错误:5 个新手高频错误(原因 + 解决方法)
新手在动静态链接时,经常遇到各种错误,我们整理了 5 个高频错误,每个都讲清楚 "原因 + 解决方法 + 实操验证",让你遇到错误不再慌:
错误 1:undefined reference to xxx(未定义引用)
原因 :程序调用的函数 / 变量未定义,或未链接包含该符号的.o/ 库。解决方法:
- 检查是否遗漏了.o 文件(比如忘记链接 code.o);
- 检查是否链接了正确的库(比如调用 math 库的 sin 函数,需要加
-lm); - 检查库路径是否正确(用
-L指定库目录); - 检查库的链接顺序(依赖库放在后面)。
实操例子:
# 错误:忘记链接code.o,run函数未定义
gcc hello.o -o main.exe
# 报错:hello.o: In function `main': hello.c:(.text+0x19): undefined reference to `run'
# 解决:链接code.o
gcc hello.o code.o -o main.exe错误 2:cannot open shared object file: No such file or directory(找不到动态库)
原因 :动态链接器找不到依赖的动态库。解决方法:
- 用
LD_LIBRARY_PATH指定库目录(临时); - 编译时用
-Wl,-rpath指定 RPATH(永久); - 把动态库拷贝到系统目录(/usr/lib);
- 配置 /etc/ld.so.conf(全局)。
实操例子:
# 错误:动态库在./lib目录,未指定路径
gcc hello.o -lmyrun -L./lib -o main.exe
./main.exe
# 报错:error while loading shared libraries: libmyrun.so: cannot open shared object file: No such file or directory
# 解决:设置LD_LIBRARY_PATH
export LD_LIBRARY_PATH=./lib:$LD_LIBRARY_PATH
./main.exe错误 3:multiple definition of xxx(多重定义)
原因 :多个.o 文件定义了同名的全局符号(函数 / 变量)。解决方法:
- 把其中一个符号改成静态符号(
static); - 重命名其中一个符号;
- 把符号封装到不同的命名空间(C++)。
实操例子:
# 错误:hello.o和code.o都定义了g_val
gcc hello.o code.o -o main.exe
# 报错:code.o:(.data+0x0): multiple definition of `g_val'; hello.o:(.data+0x0): first defined here
# 解决:把code.o的g_val改成static
cat code.c
static int g_val=20; // 静态变量,局部符号
void run() { printf("code: g_val=%d\n", g_val); }错误 4:relocation error: symbol xxx, version GLIBC_2.34 not defined in file libc.so.6 with link time reference(GLIBC 版本不匹配)
原因 :程序编译时依赖的 GLIBC 版本(比如 2.34)高于运行时系统的 GLIBC 版本(比如 2.31)。解决方法:
- 在低版本 GLIBC 的系统上编译(比如 Ubuntu 20.04,GLIBC 2.31);
- 静态链接 GLIBC(
-static); - 用
patchelf修改程序的 GLIBC 依赖。
实操例子:
# 错误:Ubuntu 22.04(GLIBC 2.35)编译的程序,在Ubuntu 20.04(GLIBC 2.31)上运行
./main.exe
# 报错:relocation error: symbol __printf_chk, version GLIBC_2.34 not defined in file libc.so.6 with link time reference
# 解决:静态链接
gcc hello.o code.o -o main_static.exe -static
./main_static.exe # 正常运行错误 5:file format not recognized(文件格式不识别)
原因 :链接的文件不是 ELF 格式(比如是 Windows 的.exe 文件,或文本文件)。解决方法:
- 检查文件是否是正确的 ELF 文件(用
file命令查看); - 重新编译生成正确的.o/ 库文件。
实操例子:
# 错误:把文本文件当作.o文件链接
gcc hello.c -o hello.txt # 生成文本文件(不是.o)
gcc hello.txt code.o -o main.exe
# 报错:hello.txt: file not recognized: file format not recognized
# 解决:重新编译生成.o文件
gcc -c hello.c -o hello.o
gcc hello.o code.o -o main.exe结语:于底层逻辑中,见编程世界的秩序之美
当你读到这里,想必已经熬过了 ELF 文件结构的 "细节轰炸",挺过了 GOT/PLT 机制的 "绕弯子",也摸清了动静态链接的 "底层套路"。我完全能想象你最初面对 "符号表""重定位表" 时的茫然,面对 "虚拟地址""写时复制" 时的困惑,甚至在看到 "undefined reference" 报错时的烦躁 ------ 毕竟,这些藏在程序运行背后的底层逻辑,从来都不是 "一眼就能懂" 的知识,而是需要沉下心拆解、实操、复盘才能真正吃透的硬骨头。
但你坚持下来了。从 "预处理→编译→汇编→链接" 的四步流程,到 ELF 文件 "头→表→节" 的四大组成;从静态链接 "买工具回家" 的简单直接,到动态链接 "租工具用" 的灵活高效;从 GOT+PLT 巧妙解决 "代码段只读" 的核心难题,到进程间 "只读段共享、可写段私有" 的资源优化;从 ELF 未加载时的虚拟地址预分配,到进程地址空间由程序头表初始化的完整链路 ------ 你一步步揭开了 "程序从源码到运行" 的神秘面纱,把那些曾经抽象的 "黑箱" 变成了清晰的 "白盒"。
其实,我们通篇讲的核心逻辑,从来都不是零散的知识点,而是一条贯穿始终的主线:编程世界的一切底层行为,都遵循 "效率与灵活的平衡"。编译器将源码拆分为四步编译,是为了在 "分步处理" 中实现 "精准优化";ELF 文件设计成 "头 + 表 + 节" 的结构,是为了让编译器、链接器、操作系统都能 "各取所需";静态链接的 "复制合并" 与动态链接的 "共享加载",是在 "运行效率" 与 "资源占用" 之间找平衡;GOT+PLT 的延迟绑定,是在 "启动速度" 与 "内存使用" 之间做取舍;而写时复制的共享机制,则是把 "资源复用" 做到了极致。
这些底层逻辑,就像搭建编程世界的 "钢筋骨架",看似离日常开发很远,实则无处不在。当你以后遇到 "动态库找不到" 的报错时,不会再只会盲目百度,而是会想起 "LD_LIBRARY_PATH→ld.so.cache→系统目录" 的查找顺序;当你需要优化程序体积时,会记得静态链接的 "按需提取" 和动态链接的 "共享副本";当你调试底层 bug 时,能通过readelf查看 ELF 头,用objdump反汇编代码,从符号表和重定位表中找到问题根源;当你接触嵌入式开发或性能优化时,虚拟地址、进程地址空间、地址无关代码这些知识,会成为你突破瓶颈的关键。
或许你会问:"我只是写业务代码,有必要懂这么深吗?" 答案是:懂底层,不是为了 "炫技",而是为了拥有 "看透问题本质" 的能力。就像我们学会 "手动洗衣机" 的原理,不是为了拒绝全自动洗衣机,而是当洗衣机出故障时,能判断是 "进水问题" 还是 "脱水问题";我们摸清库的底层机制,不是为了每写一行代码都纠结 "用静态库还是动态库",而是当程序出现性能瓶颈、依赖冲突或诡异 bug 时,能快速定位根源,而不是在表层现象中打转。
回顾整个学习过程,你会发现一个很有趣的规律:所有复杂的底层机制,最终都能拆解成 "通俗易懂的逻辑"。ELF 文件的四大组成,不过是 "封面 + 索引 + 内容" 的组合;动态链接的 GOT+PLT,本质是 "地址本 + 接口桩" 的配合;进程间共享库,核心是 "只读共享、可写私有" 的取舍。这也正是编程世界的魅力所在 ------ 再复杂的系统,都建立在简洁的底层逻辑之上,再难的知识点,都能通过 "拆解 + 比喻 + 实操" 逐步攻克。
当然,这篇文章只是底层知识的 "入门钥匙"。还有更多细节值得探索:比如 GDB 调试中如何观察 GOT 表的动态填充,比如动态库的版本管理如何通过 SONAME 实现更精细的控制,比如位置无关代码的深层编译原理,比如内核如何更高效地管理进程地址空间。但请相信,你已经打下了坚实的基础,后续的探索只会是 "顺水推舟"。
学习底层知识的过程,就像爬山。初期的路陡峭难行,每一步都要付出额外的努力,但当你站在山顶,俯瞰编程世界的全貌时,会发现曾经看似孤立的知识点,都变成了相互关联的 "网络"------ 编译链接是 ELF 文件的应用,ELF 文件是动静态链接的载体,动静态链接是进程地址空间的延伸,而这一切,最终都服务于 "程序高效、稳定运行" 的核心目标。
最后,我想对你说:编程的道路没有捷径,但每一次对底层的探索,都会让你变得更强大。不要害怕遇到 "看不懂" 的知识点,不要畏惧 "绕不开" 的难题,就像我们拆解 ELF 文件那样,把复杂的问题拆成一个个小模块,逐个突破;就像我们验证动静态链接那样,多动手敲命令、看输出、做实验,让抽象的知识变得具体可感。
编程世界从来都不缺少 "会写代码的人",但永远需要 "懂底层、明逻辑、能攻坚" 的开发者。你今天在 ELF 文件、编译链接、动静态库上付出的时间和精力,终会变成你职业生涯中的 "底气"------ 当别人还在为底层 bug 焦头烂额时,你能一眼看穿本质;当别人只会套用框架时,你能理解框架背后的实现逻辑;当技术迭代时,你能快速掌握新工具、新语言的核心原理。
愿你保持这份对底层逻辑的探索欲,在编程的道路上,既能仰望星空(追逐新技术、新框架),也能脚踏实地(深耕底层、夯实基础)。相信终有一天,你会感谢今天这个 "啃硬骨头" 的自己 ------ 因为正是这些看似枯燥的底层知识,构建起了你编程世界的 "护城河",让你在纷繁复杂的技术浪潮中,始终保持清醒的认知和坚定的方向。
编程的旅程没有终点,底层的探索永无止境。愿你带着这份 "看透本质" 的能力,继续在代码的世界里乘风破浪,去发现更多底层逻辑的秩序之美,去创造属于自己的精彩!