Hi,大家好,欢迎来到维元码簿。
本文属于 《Claude Code 源码 Deep Dive》 系列,专注于上下文工程中的 Prompt Cache 板块。如果你想了解整个系列,可以先看系列开篇 | Claude Code 源码架构概览:51万行代码的模块地图。
本文聚焦一件事:缓存系统作为一个完整的工程闭环------怎么检测断裂、怎么修复、怎么在压缩和缓存之间找到平衡。
读完全文,你将了解缓存从建立到降级的完整生命周期:
- 缓存是什么?为什么一次对话能省 10 倍成本?
- 怎么建立缓存?三层标记 + 四大保障怎么保持前缀稳定?
- 缓存断了怎么发现?省钱不破坏缓存的 cache_edits 怎么工作?
- 缓存冷了怎么办?
缓存是什么?为什么一次对话能省 10 倍成本?
前三篇姊妹篇讲了上下文的三大板块------System Prompt、Messages、Tools。这篇讲"怎么省着用"。
Prompt Caching 是 Anthropic API 提供的 KV cache 机制:如果连续请求的 prompt 前缀相同,可以跳过前缀的处理,直接从缓存读取。Claude Code 的一个典型 System Prompt 约 10K-15K tokens,一次对话可能有 50-100 个 turn。没有缓存时,每个 turn 都重新处理整个 System Prompt,总成本是 15K × 100 = 150 万 tokens 。有了缓存,只有第一个 turn 处理完整 System Prompt,后续 turn 只处理变化部分,成本降到原来的 10-20%。
但缓存不是客户端单方面能完成的------它是一个两端协作的工程:客户端负责"在哪里标记缓存断点",服务端负责"在哪里执行 KV cache 读写"。
但有一个关键约束:缓存是"前缀匹配"------一旦前缀发生变化(哪怕一个字符),从变化点开始的所有缓存全部失效。这就是为什么 Claude Code 花了那么多精力来保持前缀稳定。
上图展示了 KV cache 的工作原理:前缀相同时(绿色部分)直接复用缓存的 KV 向量,只计算新增部分(橙色部分)。一旦前缀变化(红色部分),从变化点开始的缓存全部失效,需要重新计算。
怎么建立缓存?三层缓存标记
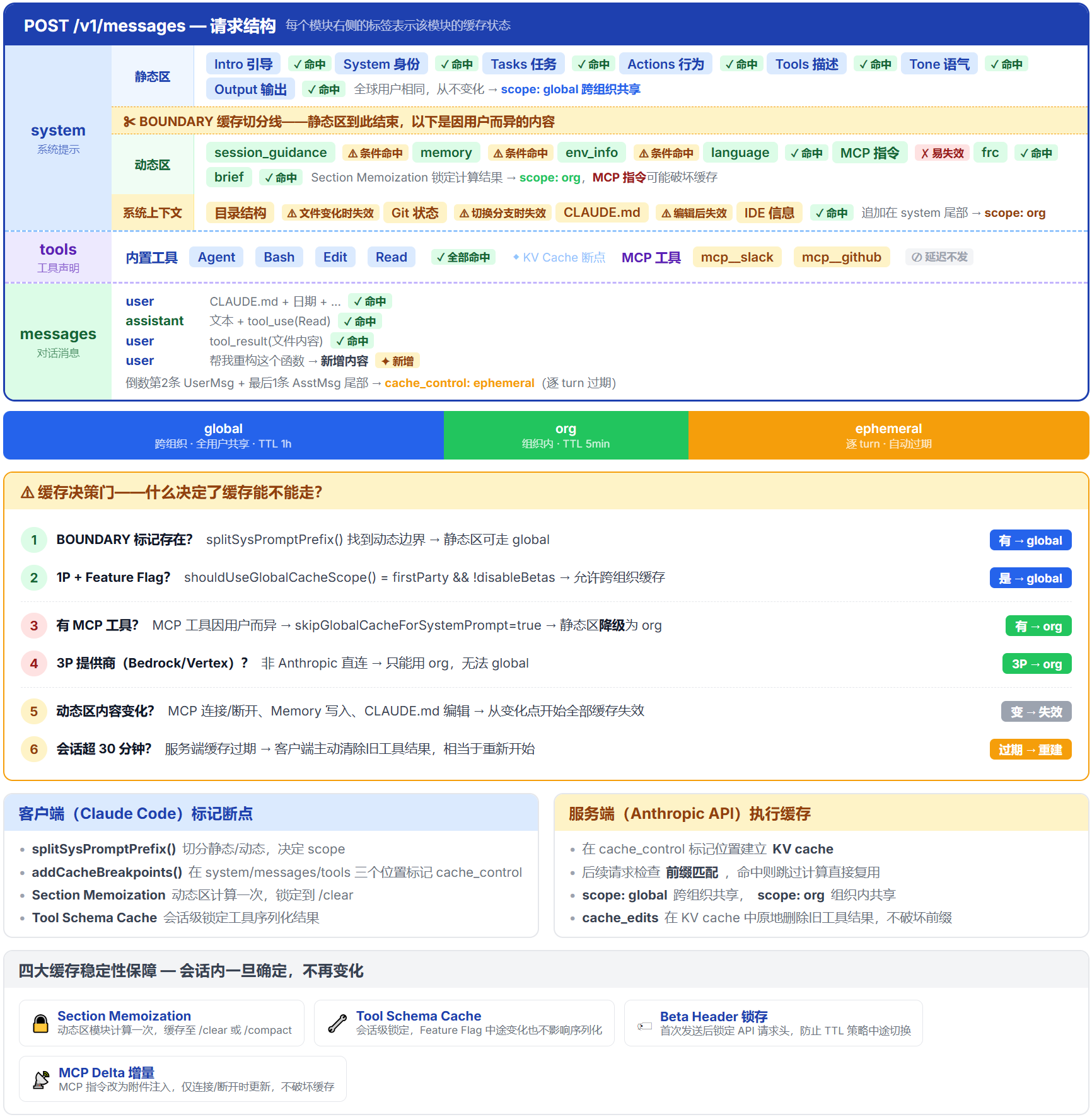
Claude Code 在 prompt 的三个位置标记缓存断点,由 splitSysPromptPrefix()(src/utils/api.ts)处理:
System Prompt 缓存 :设计目标很明确------尽可能让静态区命中最高级别的缓存共享,同时避免不同用户的动态内容互相干扰。

核心思路一句话:能共享就共享,不能共享就降级。
- 有 MCP 工具时------全部降级为 org。不同用户配置的 MCP 工具不同,工具 Schema 会影响 System Prompt 内容,全局缓存不可用,所有内容降级为组织级
- 无 MCP 工具 + 有 boundary marker------静态区命中 global。7 个静态模块对所有用户完全相同,可以跨组织、跨用户共享缓存
- 第三方 API 提供商------回退到 org。Bedrock、Vertex 等平台可能不支持全局缓存
Messages 缓存 :在每条消息上标记一个 ephemeral 断点。新消息追加时,之前的消息从缓存读取------每轮只处理新增的那一条。
Tools 缓存 :工具 Schema 通过会话级缓存锁定(toolSchemaCache.ts,27 行),即使 feature flag 中途变化也不影响序列化结果。
怎么保持缓存?四大稳定性保障
保持前缀稳定是缓存命中的前提。Claude Code 实现了四个机制,核心逻辑一致:会话内一旦确定,不再变化。
| 保障机制 | 保护对象 | 核心思路 |
|---|---|---|
| Section Memoization | 动态区模块 | 计算一次,缓存到 /clear 或 /compact |
| Tool Schema Cache | 工具 JSON Schema | 会话级锁定,feature flag 变化不影响 |
| Beta Header 锁存 | API 请求头 | 首次发送后锁定,防止缓存策略中途切换 |
| MCP Instructions Delta | MCP 使用说明 | 从"每 turn 重算"改为"仅在连接/断开时注入增量" |
其中 MCP Instructions Delta 的收益最直观:50 个 turn 的会话,只有 2 次 MCP 变化。如果用 DANGEROUS_uncached,50 次重写 × 10K tokens = 500K tokens 浪费;改为 delta 后,只有 2 次注入,成本接近零。
缓存还有两种 TTL:5min (默认)和 1h (长间隔对话)。should1hCacheTTL() 通过两层关卡(用户资格 + 来源白名单)决定是否使用 1h TTL。关键决策:资格在首次判断后锁存 到会话状态,即使中途超量也不降级------因为 TTL 切换会改变 cache_control 字段,导致前缀变化,整个缓存失效。锁存策略避免了"好心办坏事"。
缓存断了怎么办?两阶段断裂检测
缓存断裂的直接后果是:这一轮响应变慢、API 费用突增。但断裂的原因可能有很多------system prompt 变了、工具 Schema 变了、模型换了、TTL 过期了......如果只看到"cache_read_tokens 骤降",无从排查。
Claude Code 实现了一个精密的两阶段检测系统 (src/services/api/promptCacheBreakDetection.ts,651 行),核心思路:调用前拍快照、调用后对账、归因到具体维度。
Phase 1:预调用状态快照。 每次 API 调用前,recordPromptState() 记录 12 个可能影响缓存前缀的维度(systemHash、toolsHash、model、betas、cacheControlHash 等)。如果调用前发现某个维度变了,就记录到 pendingChanges------但此时还不能确认缓存真的断裂了。一个重要细节:defer_loading 的工具被排除在哈希计算之外,避免 MCP 工具延迟加载状态变化制造"假阳性"告警。
Phase 2:后调用 token 分析。 API 返回后,checkResponseForCacheBreak() 检查 cache_read_input_tokens 是否骤降(下降 > 5% 且绝对下降 > 2,000 tokens)。如果两个条件都满足,用 Phase 1 的 pendingChanges 来归因。如果 12 个维度都没变但缓存还是断了,系统根据时间间隔推断原因(> 1h → TTL 过期,< 5min → 服务端路由/驱逐)。
这个检测系统的价值不仅在于排查,更在于迭代。 团队可以量化每次变更对缓存命中率的影响:MCP Delta 改造后断裂率降低了多少,Beta Header 锁存上线后"betas changed"类断裂是否归零。
怎么省钱不破坏缓存?cache_edits
对话越久,旧的工具结果(Read 文件内容、Grep 搜索结果等)越占空间。传统的"微压缩"是在本地删除旧工具结果,但这会修改消息数组,导致 prompt 前缀变化,缓存全部失效------省下的 token 还没补回来,缓存失效增加的成本就已经抵消了收益。
Claude Code 用了一个完全不同的思路:cache_edits------不在本地修改消息,而是通过 API 的 Cache Editing 功能在服务端透明删除。本地消息数组不变,prompt 前缀完全一致,缓存完美命中。
完整生命周期分五步:
- 注册 :
cachedMicrocompactPath()扫描消息中所有tool_result,把可压缩工具(Read、Edit、Write、Glob、Grep)的 tool_use_id 注册到cachedMCState - 决策 :
getToolResultsToDelete()根据配置(keepRecent保留最近 N 个,triggerThreshold超过阈值才触发)决定哪些需要删除 - 构建 :
createCacheEditsBlock()生成 JSON 结构,每个cache_reference对应一个待删除的tool_use_id - 插入 :
addCacheBreakpoints()从末尾往前找到最后一条role: 'user'的消息,把 cache_edits block 插入到它的 content 数组中 - Pin/Replay :cache_edits 不是"发一次就永久生效"------它是每 turn 都需要重新发送的指令 。因为服务端 KV cache 是"前缀匹配",下一 turn 不包含同样的 block,服务端会认为前缀不同,缓存失效。
getPinnedCacheEdits()在每 turn 回放之前所有 pin 的 edits
为了让服务端知道哪些 tool_result 可以被删除,位于 cache_control 标记之前的所有 tool_result block 都会被添加一个 cache_reference 字段,值等于 tool_use_id。
缓存冷了怎么办?双路径压缩与 Compact 复用
Microcompact(微压缩)有两条路径,选择哪条取决于缓存状态:
缓存热路径(距离上次调用时间短,服务端缓存仍然有效):走 cache-editing 路径。不修改本地消息,通过 cache_edits 在服务端透明删除------"无损"操作。
缓存冷路径 (距离上次调用时间超过阈值,服务端缓存已过期):maybeTimeBasedMicrocompact() 改为直接在本地替换旧工具结果的内容。缓存已经失效了,修改消息不会再造成额外损失。
这个设计体现了"因地制宜"的工程原则:缓存热的时候保护缓存,缓存冷的时候直接改。
Compact 的缓存复用 遵循同样的思路。Compact(完整压缩)需要调用模型生成摘要,这是一次额外的 API 调用。Claude Code 让 Compact 通过 runForkedAgent() 复用主线程的缓存身份 ,传入 cacheSafeParams(包含了主线程最近一次调用的 system prompt、user context、messages 前缀)。Fork 的请求和主线程共享相同的缓存前缀,可以命中 KV cache。
一个微妙的设计决策:Compact fork 不设置 maxOutputTokens------因为设置后会通过 Math.min(budget, maxOutputTokens-1) 影响 thinking config,导致与主线程的缓存不匹配。
总结
跟着缓存的"人生"走了一遍,我们把本文的核心机制串起来:
| 阶段 | 机制 | 核心设计 |
|---|---|---|
| 建立 | 三层缓存标记 | 能共享就共享(global),不能共享就降级(org/ephemeral) |
| 保持 | 四大稳定性保障 + TTL 锁存 | 会话内一旦确定,不再变化 |
| 检测 | 两阶段断裂检测 | 12 维度预追踪 + token 骤降归因 |
| 修复 | cache_edits pin/replay | 不动本地消息,服务端透明删除,每 turn 重发 |
| 降级 | 双路径微压缩 | 缓存热走 editing,缓存冷走本地替换 |
| 复用 | Compact 缓存复用 | fork 共享 cacheSafeParams,"蹭"主线程缓存 |
每个机制都不是孤立存在的------TTL 锁存防止策略切换导致断裂,cache_reference 为 cache_edits 提供定位依据,双路径切换依赖时间间隔判断缓存冷热,Compact 复用要求 maxOutputTokens 不干扰 thinking config。
缓存工程的终极目标不是"让缓存永远命中",而是"让缓存尽可能多地命中,命中不了时有优雅的降级策略"。
如果你读到这里觉得缓存这块比较难懂------这是正常的。缓存机制不像 System Prompt 或 Messages 那样集中在一个模块,它散布在整个子系统的各个角落:组装时标记缓存断点、调用前拍快照、返回后对账、构建请求时插入 cache_edits、Compact 时复用缓存身份......每一个环节都和上下文的其他板块(System Prompt、Messages、Tools)紧密耦合。
建议搭配姊妹篇一起读:先看 System Prompt 工程(./02-Claude Code深度拆解-上下文里有什么-System Prompt工程.md) 和 消息上下文管理(./02-Claude Code深度拆解-上下文里有什么-消息上下文管理.md) 了解缓存断点是怎么标记的,再看本文,会有更完整的理解。
系列导航:
本文属于 《Claude Code 源码 Deep Dive》 系列中「上下文组成与缓存」命题的子篇章,专注于上下文缓存的工程闭环。
本文是完整版《Claude Code 源码深度解析:拆解上下文的组成与缓存》的子命题之一。如果你想了解上下文编排的全景(System Prompt + Messages + Tools + 缓存工程),推荐阅读完整版。
姊妹篇(可独立阅读):
- Claude Code 深度拆解:上下文里有什么------System Prompt 工程
- Claude Code 深度拆解:上下文里有什么------消息上下文管理
- Claude Code 深度拆解:上下文里有什么------工具能力声明
如果这篇文章对你有帮助,欢迎点赞收藏 支持一下。如果你对 Claude Code 源码感兴趣,欢迎关注本系列 后续更新。有任何想法或疑问,欢迎评论区留言讨论 👋