在使用 PaddlePaddle 与 PaddleOCR 进行文字识别开发时,库版本冲突是最常见的问题 ------ 旧项目依赖、系统预装库很容易和 Paddle 系列工具包不兼容,导致报错、无法运行甚至环境崩溃。
这篇博客手把手教你:新建独立虚拟环境→配置 PyCharm 解释器→安装无冲突依赖→图片 / 视频实时 OCR 代码实战,彻底解决兼容问题,快速跑通文字识别!
一、为什么必须用虚拟环境?
PaddleOCR 依赖 PaddlePaddle 深度学习框架,对 numpy、opencv-python、pillow 等库的版本有严格要求,而你本地已安装的库版本很可能不匹配,直接安装会:
-
覆盖原有项目依赖,导致旧项目无法运行
-
出现
ImportError、版本不匹配报错 -
模型加载失败、识别功能异常
解决方案:为 PaddleOCR 单独创建虚拟环境,隔离依赖,互不干扰!
二、创建 OCR 专用虚拟环境并建立解释器
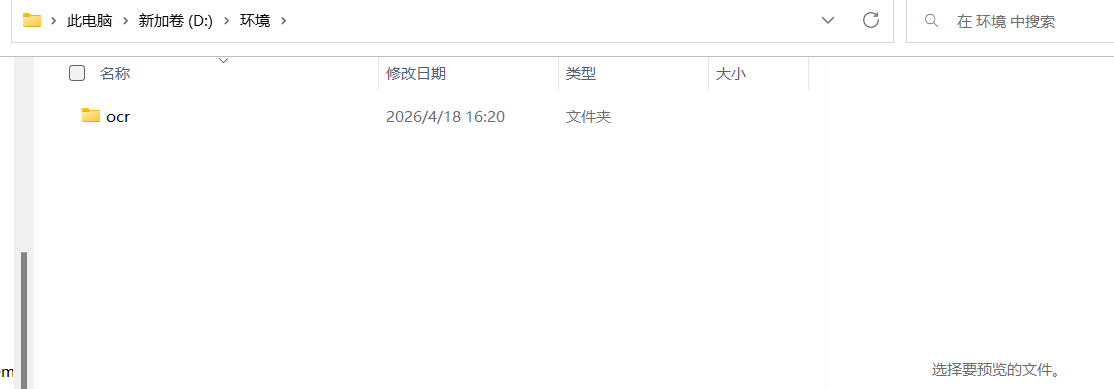
- 在d盘中新建一个文件夹作为ocr专用虚拟环境。
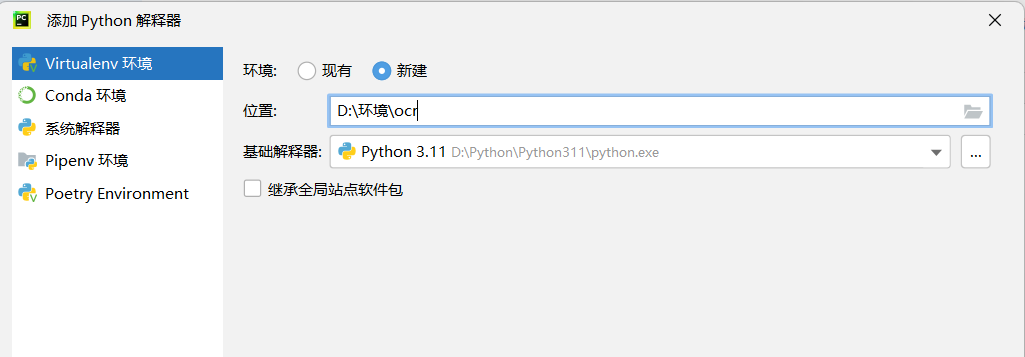
- 新建python虚拟解释器,选择新创建的ocr地址。
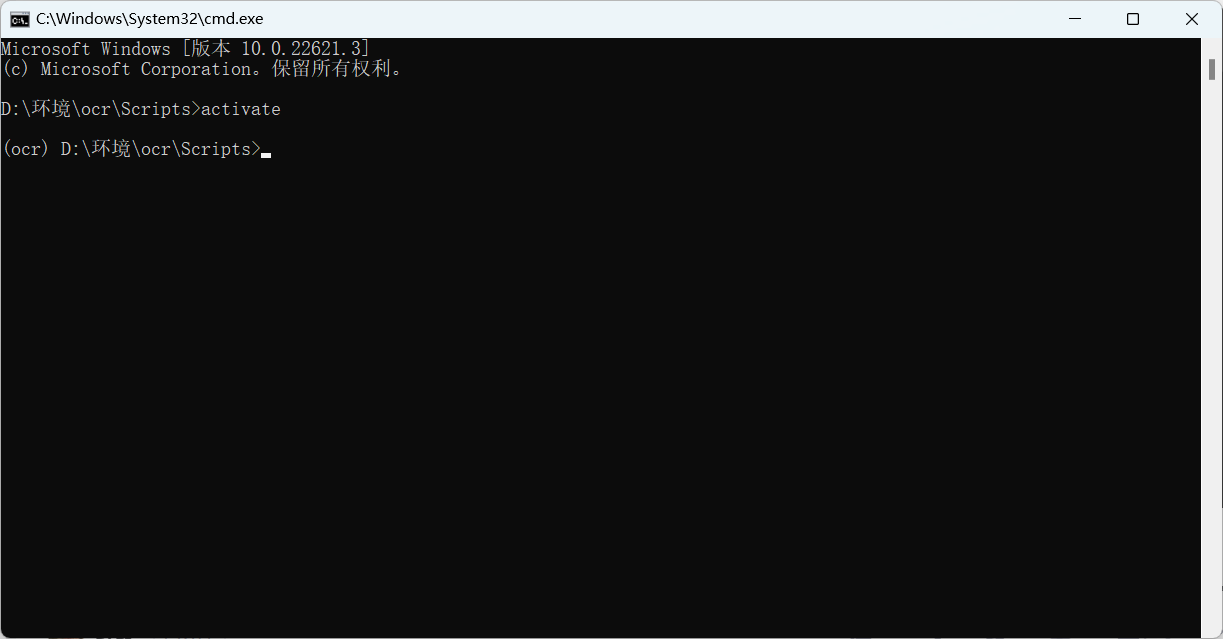
3.激活虚拟环境
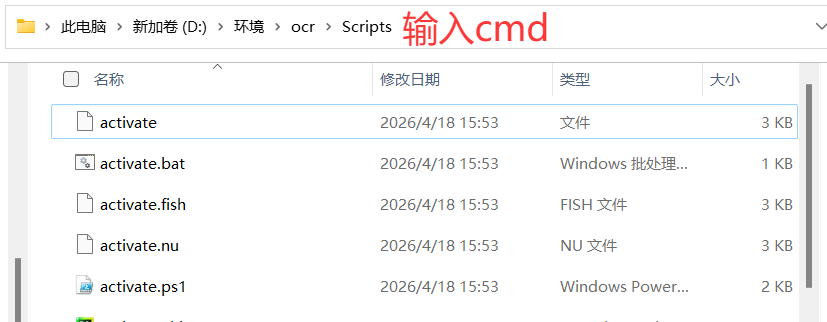
在ocr文件中的Scripts文件地址中输入聪明的,打开命令指令符,输入activite激活。
- 安装PaddlePaddle、PaddleOCR
bash
pip install paddlepaddle==2.6.2
pip install paddleocr==2.8.1三、实战一:图片 OCR 识别
python
from paddleocr import PaddleOCR
#参数介绍:
'''
https://blog.csdn.net/qq_41273999/article/details/135868038?ops_request_misc=%257B%2522request%255Fid%2522%253A%252299FC8A79-771C-4692-BE83-3F3E23AE64AB%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=99FC8A79-771C-4692-BE83-3F3E23AE64AB&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_click~default-1-135868038-null-null.142^v100^pc_search_result_base7&utm_term=paddleocr%E5%8F%82%E6%95%B0&spm=1018.2226.3001.4187
'''
ocr = PaddleOCR(use_angle_cls=True,Use_gpu=False, show_log=False, Lang='ch') #'ch' 是识别中文
img_path = r'img_3.png'
result = ocr.ocr(img_path, cls=True)
print(result)
for line in result[0]:
print(line[1][0])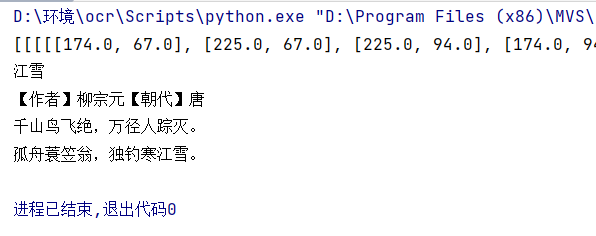
python
from paddleocr import PaddleOCR
import cv2
import numpy as np
ocr = PaddleOCR(use_angle_cls=True, use_gpu=False, show_log=False, lang='en')#'ch'就是识别中文
frame=cv2.imread('img.jpg')
result = ocr.ocr(frame, cls=True)
if not None in result:
for line in result[0]:
pts_int = np.array(line[0],dtype=np.int32)
pts = pts_int.reshape((-1,1,2))
cv2.polylines(frame,[pts],isClosed=True,color=(147,20,255),thickness=2)
cv2.putText(frame,line[1][0],(pts_int[0]),cv2.FONT_HERSHEY_SIMPLEX,1,(0,0,255),3)
cv2.imshow('x',frame)
cv2.waitKey(0)
四、实战二:摄像头实时视频 OCR
功能:实时摄像头识别 + 中文显示 + 自动画框
python
from paddleocr import PaddleOCR
import cv2
import numpy as np
from PIL import Image, ImageDraw, ImageFont
# 解决OpenCV中文乱码
def cv2AddChineseText(img, text, position, textColor=(0, 255, 0), textSize=30):
if isinstance(img, np.ndarray):
img = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
draw = ImageDraw.Draw(img)
fontStyle = ImageFont.truetype("simsun.ttc", textSize, encoding="utf-8")
draw.text(position, text, textColor, font=fontStyle)
return cv2.cvtColor(np.asarray(img), cv2.COLOR_RGB2BGR)
# 初始化OCR
ocr = PaddleOCR(use_angle_cls=True, use_gpu=False, show_log=False, lang='ch')
# 打开摄像头
cap = cv2.VideoCapture(0)
print("===== 实时OCR已启动,按ESC退出 =====")
while True:
ret, frame = cap.read()
if not ret:
break
# 识别
result = ocr.ocr(frame, cls=True)
if result and result[0]:
for line in result[0]:
text = line[1][0]
pts_int = np.array(line[0], dtype=np.int32)
pts = pts_int.reshape((-1, 1, 2))
x, y = pts_int[0]
# 画框
cv2.polylines(frame, [pts], isClosed=True, color=(147, 20, 255), thickness=2)
# 显示中文
frame = cv2AddChineseText(frame, text, (x, y - 30))
# 显示画面
cv2.imshow("Real-Time OCR", frame)
# ESC退出
if cv2.waitKey(1) == 27:
break
cap.release()
cv2.destroyAllWindows()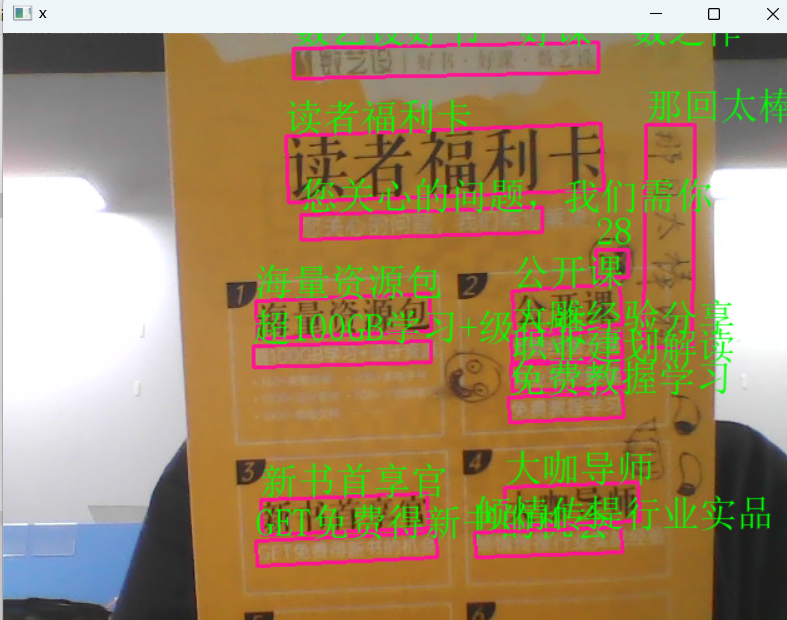
使用说明
- 直接运行
- 摄像头自动打开,实时识别文字并画框
- 按 ESC 退出
五、常见问题
-
中文显示方框确保系统有
simsun.ttc字体,Windows 默认自带。 -
模型下载失败可手动指定模型目录:
ocr = PaddleOCR(
use_angle_cls=True,
use_gpu=False,
show_log=False,
det_model_dir='ch_PP-OCRv3_det_infer',
rec_model_dir='ch_PP-OCRv3_rec_infer',
cls_model_dir='ch_ppocr_mobile_v2.0_cls_slim_infer',
lang='ch'
)
六、总结
通过独立虚拟环境 + 指定版本安装,彻底解决 PaddleOCR 与原有库的兼容问题,一行代码不用改,就能实现图片文字识别、摄像头实时 OCR,新手也能快速上手!