每一次 LLM 调用都是无状态的。模型读上下文窗口,生成响应然后忘掉一切。这对单轮问答没问题。对下列任何一类 Agent,这都是致命的:
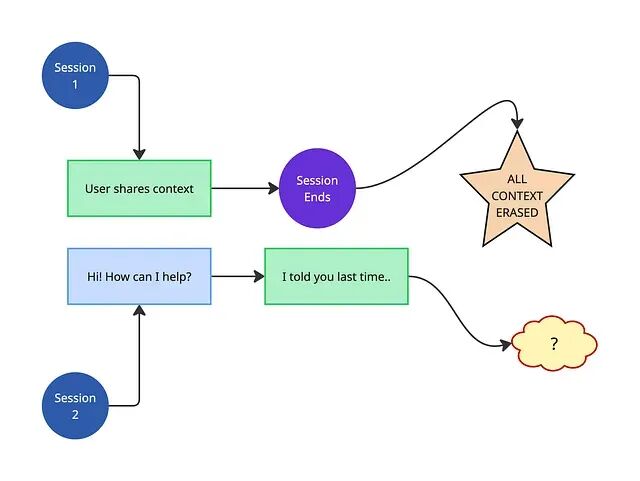
- 保持连续性------"我昨天刚跟人说过这件事,为什么还要再解释一遍?"
- 从交互中学习------Agent 应当知道这个用户的账户、历史问题、首选语言
- 积累组织知识------哪些解决路径能关闭工单,哪些意图预示升级
- 从崩溃中恢复------一个外呼 20 万通电话的批处理 Agent,失败后必须从呼叫者 <#87>,431 续上,而不是重启
我们的第一反应是把整段对话塞进上下文窗口,但是在生产环境中会出现问题:
1成本上满上下文在 LOCOMO 上能拿到 72.9% 的准确率,代价是 p95 延迟 17.12 秒、token 开销翻 14 倍,实时场景根本用不了;质量上窗口越满模型对早先指令的注意力越低,埋在中间的细节开始被忽略,这是长上下文 LLM 一个被反复记录过的弱点;还有误差累积,Databricks 2026 年 4 月的研究发现,Agent 会引用之前运行里错误的输出,再以更高的信心复用,没有策展的记忆会把一次性错误固化成永久谎言。
下图的橙色线是 Agent 需要记住的内容,蓝色线是记忆系统实际交付的内容。两者之间的裂缝正是生产级 Agent 失效的地方;裂缝在收窄但没有合上。
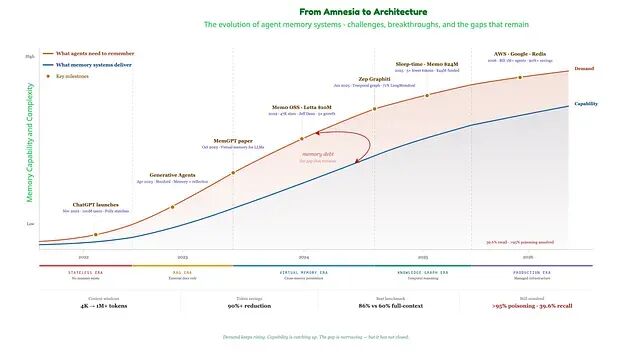
所以我们可以抽取重要的部分,加以整合存到合适的后端,按需智能检索并主动遗忘陈旧内容。拿几个准确率点换来 12 倍的延迟下降和 10 倍的成本下降,这种取舍就是 demo 与能摆到付费用户面前的系统之间的分界线。
把这 10 倍成本差距落到具体数字上:一个中等规模 SaaS,每月 1000 万次 Agent 调用,若走满上下文仅 LLM token 就大约要花 100 万美元(按每次调用约 26K token,GPT-5 混合价估算);同样的工作负载换成选择性记忆会降到约 10 万美元。这是"业务可行"与"成本曲线在用户到场前就杀死产品"之间的差别。
Agent 记忆的四种类型
《Memory in the Age of AI Agents》中提到了标准分类法:框架本身更早由 CoALA 论文(TMLR 2024)形式化;那篇论文显示给 GPT-3.5 加一层认知架构,可以把编码基准的成绩从 48% 拉到 95%。人类记忆不是单一的类型,Agent 记忆也不该是。
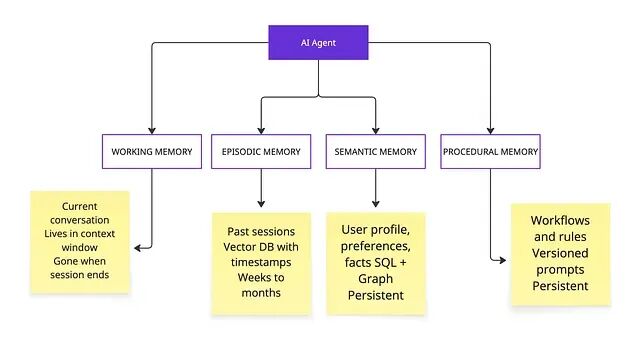
四种记忆类型,各自有独立的后端、生命周期与失效模式。
工作记忆------Agent 当前正在思考的东西。
- 存放什么:当前对话、工具结果、中间推理
- 存在哪里:上下文窗口内部,也就是 prompt 本身
- 生命周期:仅限当前会话
- 典型失效:窗口填满,模型跟丢更早的指令
情景记忆------Agent 的过往交互日记。
- 存放什么:过往具体会话的记录,带时间戳、参与者、结果
- 存在哪里:带元数据的向量数据库(Qdrant、Pinecone、pgvector)
- 生命周期:数周到数月,带衰减
- 典型失效:检索到不相关的旧情景、时间混淆
语义记忆------从原始素材里蒸馏出的事实。
- 存放什么:用户偏好、实体关系、从原始情景抽象出的可复用知识
- 存在哪里:向量数据库、知识图谱(Neo4j、Apache AGE)或混合
- 生命周期:持久化,带冲突解决
- 典型失效:事实过时、条目相互矛盾、随着陈旧信息堆积渐进腐化
过程记忆------学到的行为与规则。
- 存放什么:工作流、决策规则、系统 prompt、few-shot 示例
- 存在哪里:配置文件、prompt 模板、带版本的存储
- 生命周期:持久化,带版本
- 典型失效:政策变了,过程还留在旧版本,没人去更新
它们是协同的不是独立的。
一个真实的 Agent 会同时用上全部四种:工作记忆承载对话;情景记忆召回相关的过往会话;语义记忆加载用户画像与偏好;过程记忆挑出正确的工作流。并非每个框架都覆盖全部类型------情景记忆是基本盘,语义图谱在 2025 年到位,过程记忆仍在前沿地带,目前只有 LangMem 和 Mem0 v1.0 支持自改进工作流。
五阶段记忆
研究界与生产框架都是使用的这个五阶段形态的方法,每个阶段都在解决上一阶段制造出的问题;跳过任何一步,只会出现不同的问题------原始噪声、矛盾、延迟、时间漂移,或者无声的腐化。
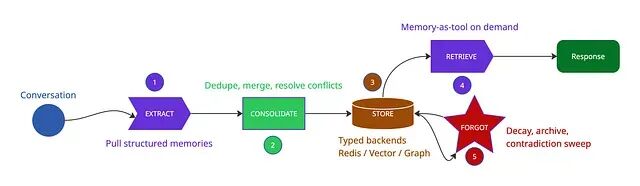
五阶段记忆流水线------每个生产框架都实现了它的某种变体。
- 阶段 1 抽取:把原始对话转成结构化记忆记录
- 阶段 2 整合:去重、合并,并与已有记忆解决冲突
- 阶段 3 存储:把每种记忆类型路由到最合适的后端
- 阶段 4 检索:让 Agent 按需拉取记忆,而不是每轮都拉
- 阶段 5 遗忘:主动衰减、归档、裁剪,防止存储腐烂
阶段 1 抽取:从对话到结构化知识
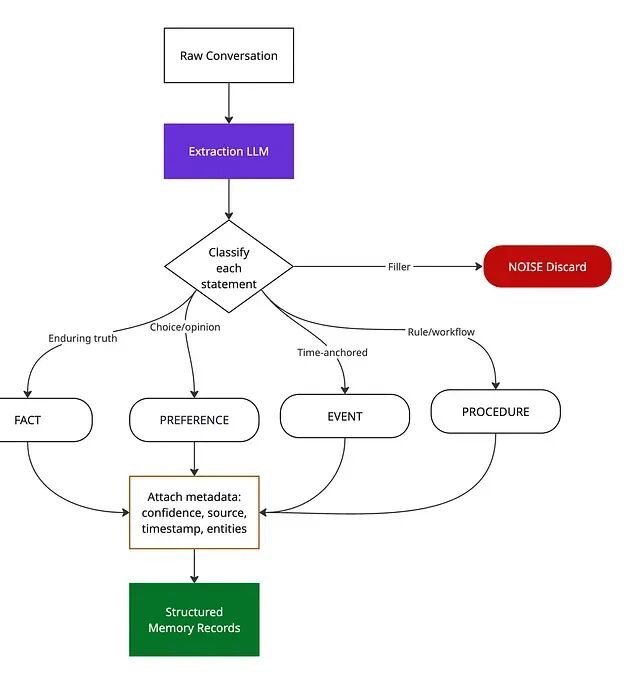
抽取把每一条陈述归入五个桶之一------被说出口的内容大多是噪声。
一个 LLM 读取对话,把每一条信息归入类型化记录:事实、偏好、事件、过程。每条记录带四个属性:置信度分数(0.0--1.0)、关联实体(用于图谱构建)、时间戳,以及来源------是用户直接说的、Agent 推断的,还是工具返回的?
AWS AgentCore Memory 带三种内置策略(semantic、preferences、summary),并行运行。
何时抽取,同步还是异步?
- 同步(每轮)------轻量事实检测,每轮增加 100--300ms,只对高价值抽取使用
- 异步(会话后)------深度整合、情景摘要、图谱更新;对对话内延迟零影响
- 计划(cron)------矛盾扫描、衰减周期、索引重建,非高峰批处理
- Mem0 v1.0.0 把
async_mode=True设成默认;同步写入会阻塞响应流水线,增加用户能感觉到的延迟 - AWS AgentCore 报告抽取在会话结束后 20--40 秒内完成
阶段 2 整合:真正难的部分
新记忆经常会和已存内容重复或冲突。整合正是把生产级记忆和朴素 append-only 存储分开的那一环。
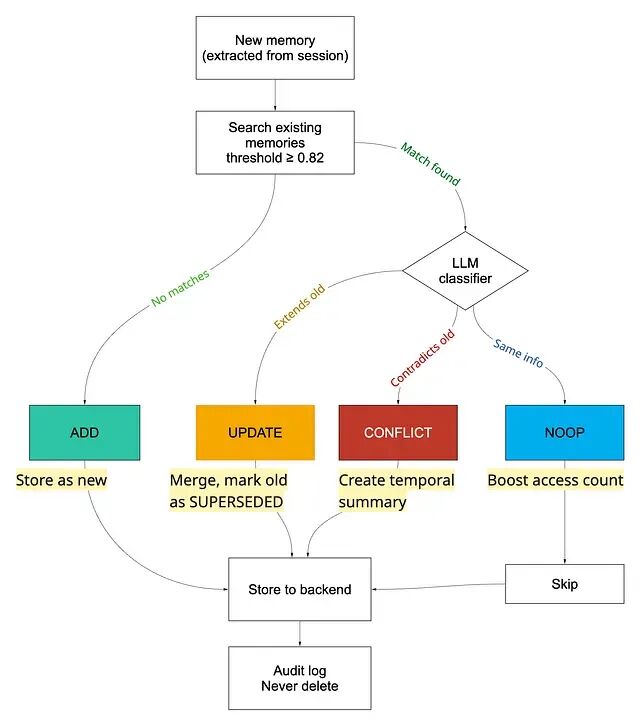
每条新记忆都会被归类为 ADD、NOOP、UPDATE 或 CONFLICT------最后这种最难处理。
对每条从会话里抽出的新记忆,整合跑三步。
先在同一用户、同一类型下搜索已存的最接近匹配(余弦相似度,阈值约 0.82,Mem0 就这么做的)。接着由一个 LLM 判定关系:
- ADD------独立的新信息,单独存储
- NOOP------冗余,跳过并提升访问计数
- UPDATE------扩展或取代,合并并把旧记忆标为
SUPERSEDED - CONFLICT------与已有记忆矛盾,创建一个时间感知的摘要,同时保留新旧两个版本
最后写审计轨迹。过时的记忆标为
SUPERSEDED,从不删除------你需要追踪系统在何时相信了什么。
冲突解决是团队最常弄错的地方。千万不要直接覆盖,那会抹掉历史,把系统变得不可审计。AWS AgentCore 把过时记忆标为
INVALID而不是删除;Zep 的 Graphiti 开创了双时态建模------每个事实带两个时间戳,一个是它在世界中成立的时间,另一个是 Agent 获知它的时间。
阶段 3 存储:类型化的数据需要类型化的后端
把所有记忆类型塞进同一个向量数据库这是团队最常犯的错,不同的记忆类型需要不同的存储。
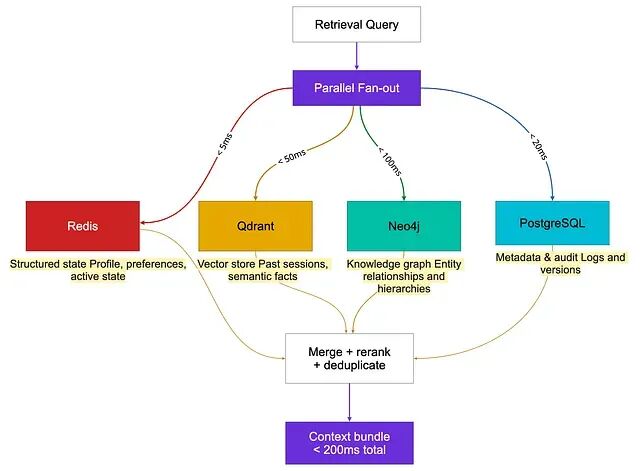
四种后端对应四种记忆类型,并行 fan-out------总预算在 200ms 以内。
四种后端,四项分工。
- 结构化状态(Redis / PostgreSQL JSON)------稳定画像与活跃状态,精确 key-value 查找,小于 5ms,零检索噪声
- 向量存储(Qdrant、Pinecone、pgvector)------需要模糊匹配的语义事实与情景,带元数据过滤的相似度搜索,小于 50ms
- 知识图谱(Neo4j、Apache AGE、FalkorDB)------需要多跳遍历的实体关系,小于 100ms;Zep 的 Graphiti 在 DMR 上拿到 94.8%
- 元数据存储(PostgreSQL)------时间戳、来源追踪、访问计数、审计轨迹
架构原则:查询要并行 fan-out 而不是串行,检索总预算应保持在 200ms 以内。AWS AgentCore 报告语义搜索端到端约 200ms。
阶段 4 检索:把记忆当工具,而不是流水线里的一步
最常见的成本兼质量反模式是每轮都自动检索一遍;生产里通行的做法是 memory-as-a-tool。
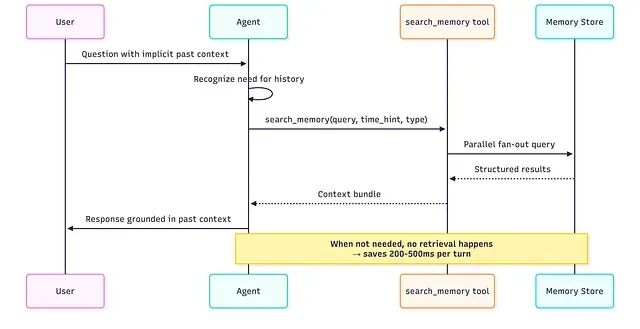
Agent 自己决定什么时候召回,而不是 orchestrator这样可以在不需要记忆的那些轮次里每轮省下 200--500ms。
给 Agent 一个显式函数,让它按需搜索记忆。召回的时机由 Agent 掌握不归 orchestrator 管。Mem0 的选择性方案中位搜索延迟 0.20 秒、准确率 66.9%,对比标准 RAG 的 0.70 秒却只有 61.0%。
memory-as-a-tool 有两种风格。
- 被动检索(Mem0 风格)------系统在后台自动抽取与存储,Agent 按需调用搜索工具;框架无关,能和 LangChain、CrewAI、AutoGen、Mastra 配合,稳定且 token 高效
- 自编辑式(Letta 风格)------Agent 用显式函数调用(
core_memory_append、archival_memory_search)管理自己的记忆,上下文窗口充当 RAM,archival 充当磁盘;适应性更强,但每次记忆决策都要额外 token。截至 2026 年 3 月,Letta 已支持 git 支撑的记忆、skills 和 subagents
阶段 5 遗忘:没人会优先做的那件事
记忆应当是一种导向机制,而不是囤积者的阁楼。
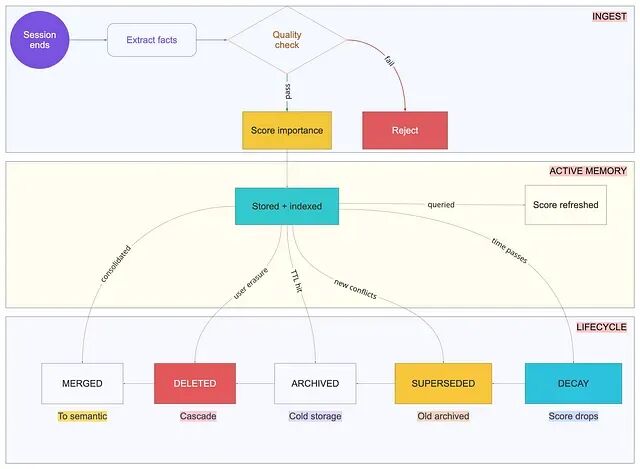
完整的记忆生命周期------从摄入、活跃使用,到衰减、归档、删除。
多数团队上线时只有存储路径没有删除路径。这样在一定时间以后就会检索变慢,无关事实开始主导结果,Agent 运行越久反而越糟。如果你说不清什么会被删除、何时删除、为什么删除,那你拥有的是内存泄漏,不是记忆系统。
三种遗忘机制必须同时工作:基于时间的衰减用指数函数压低更老、更少访问的记忆的检索分数,典型半衰期约 70 天,不删除,只是降低浮现概率;基于 TTL 的归档把 90 天(事件)或 180 天(事实)内未访问的记忆挪进冷存储,仍可显式查询,但默认检索不会碰;矛盾扫描则周期性扫描冲突的活跃记忆并触发整合------少了这一环,Agent 会卡在过时偏好和当前偏好之间。
流水线告诉你每个记忆系统要做什么;设计模式告诉你怎么按具体用例把它组装起来。
四种可行的设计模式
在生产里频繁出现、值得被命名的流水线编排方式有四种。它们沿三条轴有所不同:Agent 自行管理记忆的程度、存储多少历史、检索粒度要多细。
经验法则:从模式 2(结构化状态 + 向量搜索)开始,它能解决 80% 的用例;只在需求清楚要求时再往上加复杂度。

决策树:挑选满足需求的最低复杂度模式。没有明确证据就别越过模式 2。
模式 1 分层记忆(Letta / MemGPT)
核心思路是把上下文窗口当作快而有限的存储,把外部数据库当作大容量、可搜索的存储。Agent 通过函数调用在两者之间搬运事实。
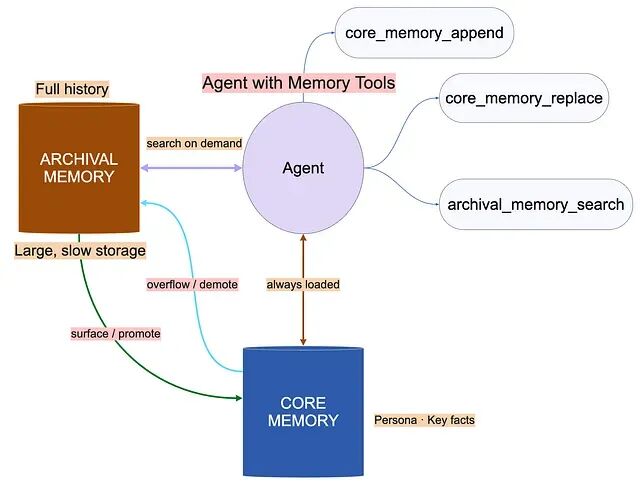
Agent 通过显式函数调用,把事实在 core(类 RAM)和 archival(类磁盘)之间挪动。
core memory 约 500 token 常驻上下文,archival memory 按需搜索;大约 10--15% 的 token 预算会花在记忆管理本身。这类方案适合长期陪伴、心理疗愈机器人、长时间运行的编码助手,代价是明显的架构锁定。
模式 2 结构化状态 + 语义搜索(80/20 法则)
JSON/Redis 负责需要的 80%(零延迟、完美准确率),向量搜索则负责剩下那 20% 需要模糊匹配的部分。
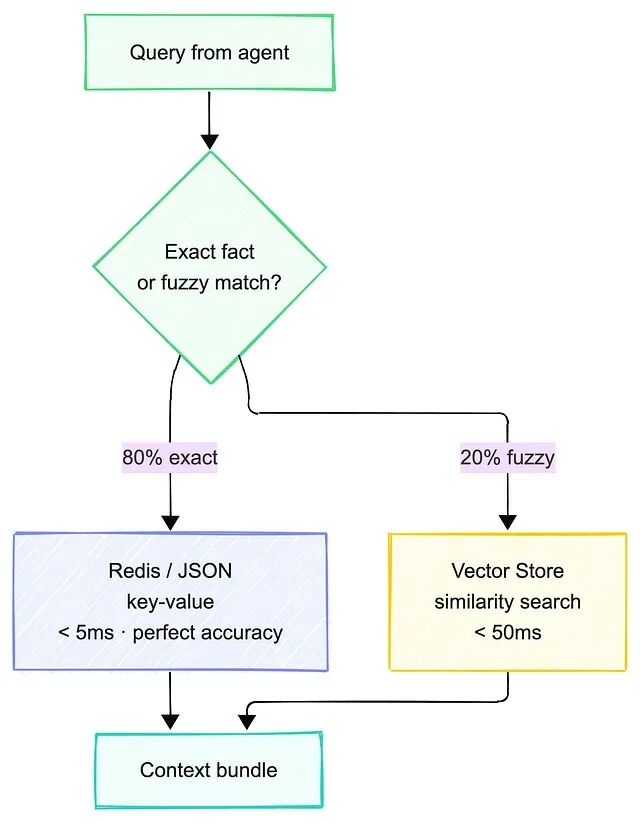
对需要精确事实的 80% 查询用结构化状态,对需要模糊匹配的 20% 回退到向量搜索。
他的优势是没有嵌入质量的问题,存进去什么事实,取出来就是什么事实。几乎所有项目都可以拿它打底,代价是要预先做好显式的 schema 设计。
模式 3 图谱记忆(Zep / Graphiti)
实体作为节点,关系作为边,沿连接链前进。
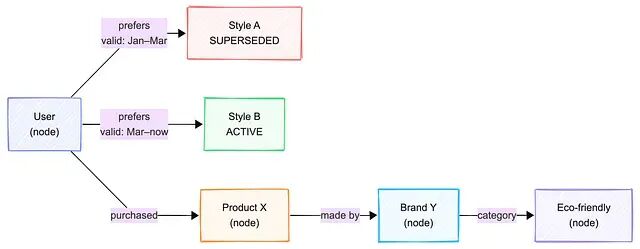
事实是带有效期窗口的边------旧偏好仍可查询,但被标记为 SUPERSEDED。
Zep 在 DMR 上拿到 94.8%;在 LongMemEval 上 63.8% vs Mem0 的 49.0%,15 个点的差距来自双时态架构。它适合企业知识与合规繁重的工作流;代价是运维复杂度明显更高。
模式 4 检查点记忆(崩溃恢复)
在每次重要动作后落一个状态检查点。
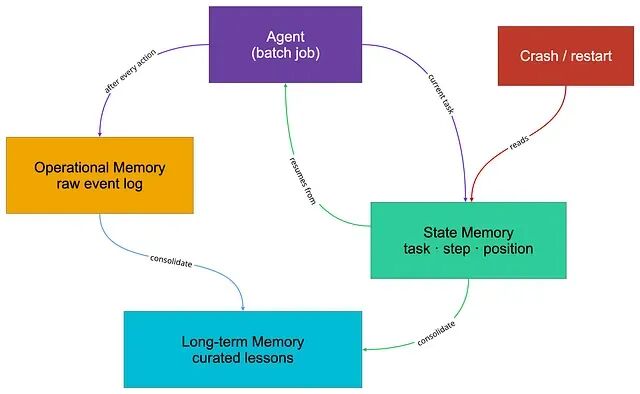
三层:原始日志、当前状态、策展过的经验教训;崩溃后读取状态记忆,从上个检查点续跑。
三层分别是 operational(原始事件日志)、state(当前任务)、long-term(策展过的经验教训)。批处理、CI/CD、无人值守自动化都适用;代价是写密集,需要快速持久化的存储(Redis AOF、DynamoDB)。
选对模式是成功的一半;另一半是知道无论用哪种模式,只要不够小心,都会悄悄潜进来的那批反模式。
生产常见的六个问题
失效的记忆系统,失效原因总跑不出六条;而且它们并不独立,你往往一次上线就顺手带出两三个。六者都能追溯到同一个错误:把记忆当成一个无脑的写入-搜索桶,而不是策展的、时间感知的、来源可追踪的系统。
这六个归为三族:保留太多------囤积者、单体、吸血鬼,让系统膨胀到检索比不检索还吵;信错了对象------时间旅行者、回音室,悄悄污染输出;从不闭环------失忆循环,让你之前搭的一切都打了水漂。
下面每节都用同一套骨架:症状、根因、修复。
1、囤积者(从不遗忘)
向量存储无限增长:跑过 1 万个会话之后,检索会把数月前的矛盾事实和昨天的更新混在一起一并返回。
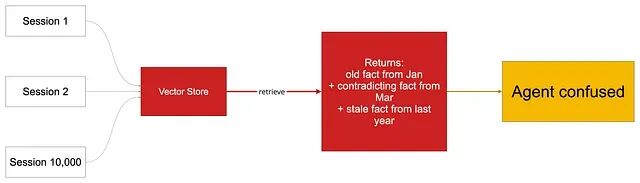
没有 TTL、没有衰减------存储永远膨胀,检索返回来自数月前的矛盾。
根因是没有衰减、没有 TTL、没有计划中的矛盾扫描。Databricks 的真实案例里,Agent 会随时间以越来越高的信心引用先前运行里错误的输出。修复路径是 TTL 归档 + 近因衰减 + 定期矛盾扫描;上线前就把删除路径设计好。
2、吸血鬼(每轮自动检索)
每一轮都多 200--500ms 延迟、500+ 无关 token。
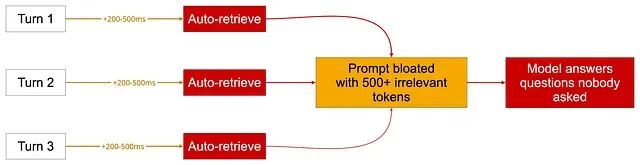
不管这一轮要不要历史,每轮都触发检索------延迟和成本一起堆起来。
根因是"以防万一"式检索:一股脑全拉进来,让模型自己分拣。它为什么比没记忆还糟?因为无关记忆会主动误导模型。修复就是 memory-as-a-tool------参见 Mem0 的选择性做法:由 Agent 自己决定何时召回;主动检索上限控制在 500 token 以内。
3、单体(所有东西堆一个库)
一次查询返回一堆杂糅在一起、互不相干的记忆类型。
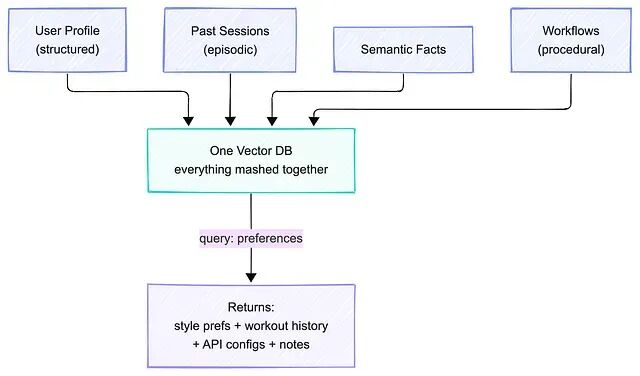
所有记忆类型都倒进同一个存储------检索到的是一锅无关内容的大杂烩。
根因是所有类型都堆进单一数据库、没有分隔。修复办法是按类型拆存储、用独立 schema;只要 schema 在逻辑上分开,用一个 PostgreSQL 也行。
4、时间旅行者(没有时间感知)
Agent 按一个已经不再成立的旧偏好在行动。

相似度搜索按内容而非近因挑最接近的匹配------旧事实把新事实压了下去。
根因是相似度搜索按内容找最接近的条目,不看近因。有证据在:带图谱记忆的 Mem0 在时间类任务上拿到 58.13%,OpenAI 只有 21.71%;把差距拉平的关键正是时间戳和图谱边。修复办法是给每条记忆同时存
created_at和
valid_until,给近期记忆更高权重,对冲突建时间感知摘要而不是覆盖。
5、回音室(跨 Agent 污染)
Agent B 按 Agent A 幻觉出来的"事实"在行动;幻觉就这样变成了 ground truth。

没有来源标签,一个 Agent 的推断会被下一个读到它的 Agent 当成 ground truth。
根因是从没追踪一条记忆到底从哪儿来。HaluMem 基准(2026 年 1 月)显示,每个受测的商业系统(Mem0、Memobase、MemOS、SuperMemory、Zep)都会在记忆操作中产生幻觉;中等上下文下,QA 幻觉率超过 19%。修复路径是给每条记忆贴上来源与置信度标签,并确立信任层级------用户陈述 > 工具返回 > Agent 推断。
6、失忆循环(检索-遗忘-检索)
Agent 反复检索同一批记忆却从不吸收它们,token 成本螺旋上升。

同一条记忆被反复检索,因为系统从来没记录它已经被应用过。
根因是记忆被塞进 prompt、却没被标为"已应用"。修复:在每条记忆上追踪"已应用于会话 X"的状态,同一会话内跳过重复检索。
完整的生产架构示例
示例的场景是一名客户打进客服线路。语音 Agent 必须按姓名问候来电者,并带上相关上下文------过往工单、账户状态、首选语言------响应预算 200ms 以内,对话才自然。没有记忆,来电者要把一切重讲一遍;有了记忆,Agent 从工单中途接手,30 秒搞定,而不是 5 分钟。
语音为什么是最复杂的的记忆场景?200ms 响应预算是人类对话延迟的底线,一旦超过来电者会以为 Agent 卡顿了------Salesforce 的 VoiceAgentRAG 研究就把这一点当作不可谈判的设计约束。电话里没有回滚,来电者没法重新阅读自己说过的话;Agent 忘了,对话就得重来。输入是流式的,来电者 ID 一匹配,检索就可以启动,不必等他说完句子。
单次向量数据库查询本身就要 50--300ms------那是全部 预算。生产架构会再压上一层语义缓存(亚毫秒)和预测性预取,才把整体拉回线以下。
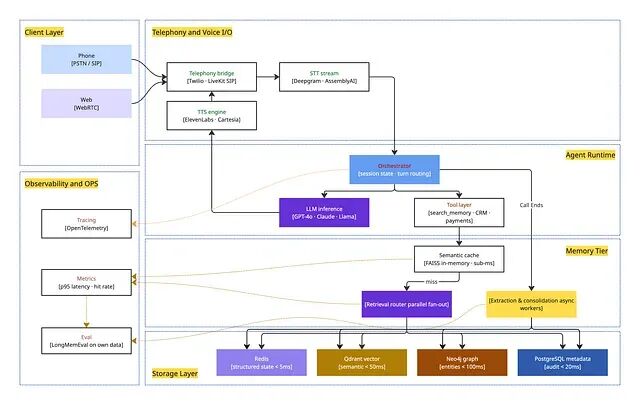
记忆层位于 Agent 与存储之间------不在 Agent 内,也不在存储内;这个分离是最关键的单一架构选择。
电话与语音 I/O 自成一层,Twilio 换成 LiveKit 不必动 Agent,Deepgram 换成 AssemblyAI 不必动记忆。记忆层独立于 Agent 运行时,同一层记忆可以服务销售、客服、引导多个 Agent,不必重复检索逻辑。存储是类型化而非单体的:Redis 存状态、Qdrant 存向量、Neo4j 存实体、PostgreSQL 存审计;AWS AgentCore 报告并行 fan-out 时端到端约 200ms。可观测性本身是一层,不是事后补丁------仪表板上没有 p95 检索延迟、缓存命中率、记忆精确度,就调不了上一节那堆失效模式。
运行时分三个区。
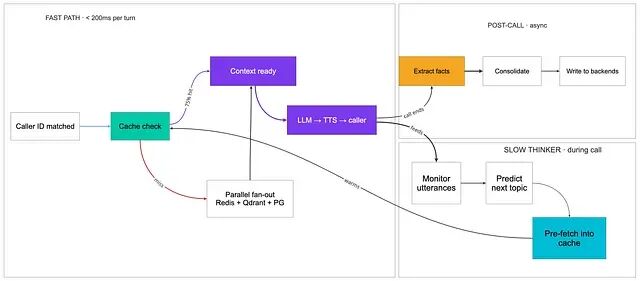
- Fast Path 必须在 200ms 内走完------缓存命中、LLM 推理、TTS;任何更慢的环节都要从这个区踢出去
- Slow Thinker 在通话期间的后台跑,预测下一个可能的问题并预热缓存,让下一轮直接命中
- Post-Call 完全异步,抽取、整合与后端写入都在 TTS 停止之后发生,绝不阻塞来电者
最小数据模型如下:
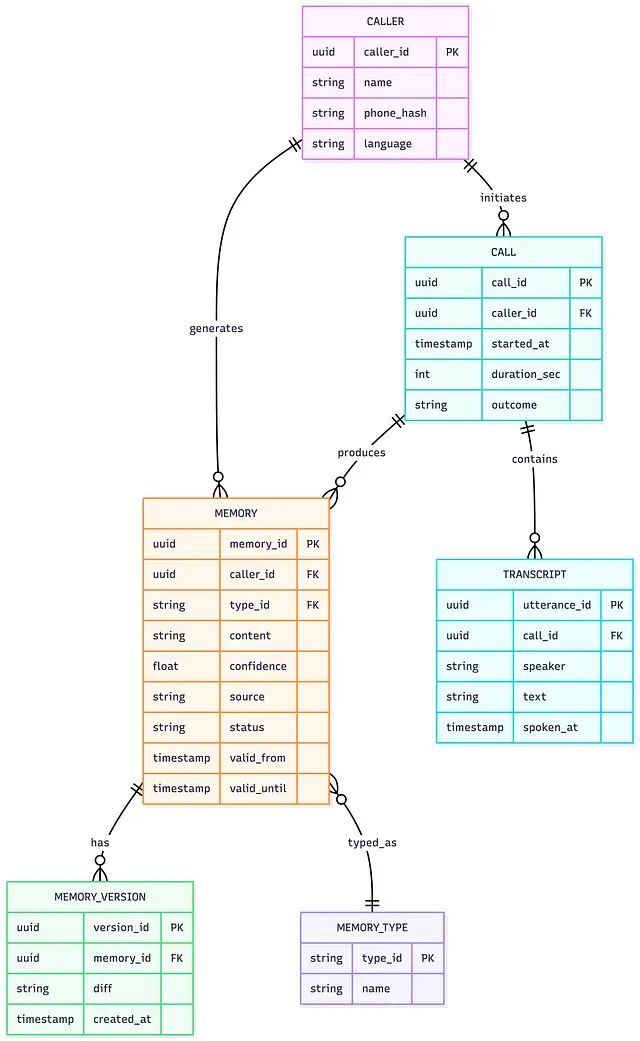
六个实体;用
phone_hash而不是原始号码,把 PII 挡在记忆层之外。
200ms 预算实际长什么样?一次真实通话,一拍一拍地看:
- T+0ms------电话响起,来电者 ID 命中
CALLER.phone_hash - T+1ms------语义缓存命中,返回上下文包(姓名、上次工单、首选语言)
- T+50ms------LLM 开始基于 core memory 流式生成问候
- T+180ms------TTS 播出:"Hi Sarah, your replacement for order <#4821> is in transit --- should arrive Thursday. Is that what you're calling about?"
与此同时,Slow Thinker 已经听到开场静默,在预取可能的下一个话题。当 Sarah 说 "Actually, I wanted to update the delivery address," 时,她的地址历史已经在缓存里热着------下一条响应落地 150ms,而不是 400ms。
代码示例
整件事大约 30 行就装得下。记忆层、缓存和异步抽取器分别挂在三个通话生命周期钩子上------
on_call_start、
on_utterance、
on_call_end:
class VoiceAgent:
async def on_call_start(self, caller_id):
ctx = await self.cache.get(caller_id) \
or await self.memory.retrieve(user_id=caller_id, query="recent calls")
self.slow_thinker.start(caller_id, ctx)
return ctx
async def on_utterance(self, caller_id, utterance, ctx):
response = await self.llm.generate(system=ctx, message=utterance)
self.slow_thinker.observe(caller_id, utterance, response.text)
return response.text
async def on_call_end(self, caller_id, transcript):
asyncio.create_task(self.extractor.extract_and_consolidate(caller_id, transcript))前面讲过的流水线、模式、反模式,全部都是
HybridMemoryStore和
MemoryExtractor内部发生的事。
什么时候不该用这套?这是为实时语音量身定做的。文本聊天机器人可以完全跳过语义缓存和 Slow Thinker------逼出那份复杂度的正是 200ms 预算;聊天场景保留六层、丢掉三区即可。批处理 Agent 要的是模式 4(检查点记忆),不是这套。
200ms、75% 缓存命中率、316× 加速这类数字来自已发表的基准;但基准数字经常被误读。下面讲怎么解读。
总结
目前来看基础模型在原始能力上正在收敛。能把生产级 Agent 和 demo 分开的是记忆问题,不是模型问题。
从简单开始,结构化状态 + 向量搜索覆盖 80% 的真实用例,只有当实体关系主导查询时才加图谱记忆;把检索当工具,先把遗忘路径设计好------召回时机交给 Agent,如果你解释不清记忆怎么失效,数周之内系统就会退化;度量真正重要的量:检索延迟 p95、缓存命中率、记忆精确度,以及写入新记忆所花的时间。没有这些数字,你就是在盲飞。
不是每个 Agent 都需要这一套。如果你的 Agent 只处理单轮事务或无状态查询,这就是过度工程。记忆不是一项特性,它是 Agent 身份、连续性与信任的根基。
https://avoid.overfit.cn/post/2022946d078c47af92cc72b0e20bede4
by Santosh Shinde