文章目录
-
- [1. 检索系统基础](#1. 检索系统基础)
-
- [1.1 什么是检索系统](#1.1 什么是检索系统)
- [1.2 传统检索系统的三种类型](#1.2 传统检索系统的三种类型)
-
- [① 关系数据库](#① 关系数据库)
- [② 词法搜索引擎](#② 词法搜索引擎)
- [③ 向量数据库](#③ 向量数据库)
- [2. LangChain 检索器(Retrievers)](#2. LangChain 检索器(Retrievers))
-
- [2.1 什么是检索器](#2.1 什么是检索器)
- [2.2 检索器的简单示例](#2.2 检索器的简单示例)
- [3. 使用向量数据库作为检索器](#3. 使用向量数据库作为检索器)
-
- [3.1 基本使用](#3.1 基本使用)
- [3.2 使用 @chain 创建"检索器"](#3.2 使用 @chain 创建"检索器")
- [4. RAG(检索增强生成)](#4. RAG(检索增强生成))
-
- [4.1 什么是 RAG](#4.1 什么是 RAG)
- [4.2 RAG 工作流程](#4.2 RAG 工作流程)
- [4.3 RunnablePassthrough 详解](#4.3 RunnablePassthrough 详解)
- [4.4 完整 RAG 代码实现](#4.4 完整 RAG 代码实现)
- [5. RAG 链的执行流程详解](#5. RAG 链的执行流程详解)
-
- [5.1 链的构建](#5.1 链的构建)
- [5.2 RunnablePassthrough 的作用](#5.2 RunnablePassthrough 的作用)
- [5.3 并行执行的优势](#5.3 并行执行的优势)
- [6. 检索器的高级用法](#6. 检索器的高级用法)
-
- [6.1 检索器的 search_type](#6.1 检索器的 search_type)
- [6.2 元数据过滤](#6.2 元数据过滤)
- [7. RAG 系统的优化建议](#7. RAG 系统的优化建议)
-
- [7.1 文档分割优化](#7.1 文档分割优化)
- [7.2 检索数量优化](#7.2 检索数量优化)
- [7.3 提示词优化](#7.3 提示词优化)
- [8. 总结](#8. 总结)
-
- [8.1 核心要点](#8.1 核心要点)
- [8.2 完整工作流程](#8.2 完整工作流程)

1. 检索系统基础
1.1 什么是检索系统
检索系统(Information Retrieval System, IR System) 是一个万亿美元级的用户信息需求、从大规模数据集合中、自动、非结构化的数据检索合适、排序并返回相关文档技术。指导用户返回相关文档的计算机系统。
它的核心任务有三:在正确的时间,以正确的方式,将正确的信息提供给正确的人。最常见的例子是:搜索引擎(如Google、百度)。
1.2 传统检索系统的三种类型
根据图片内容,随着大语言模型的兴起,检索系统已成为人工智能应用(例如 RAG)的重要组成部分。目前存在多种【不同类型】的检索系统,包括:
① 关系数据库
关系数据库是许多应用程序中使用的结构化数据库存储的基本类型。数据库储存行(记录)和列(字段)的表格形式,可以通过 SQL(结构化查询语言)进行高效的查询操作。关系数据库值得维护数据完整性,支持复杂查询以及不同表之间关系之间的关系。
特点:
- 结构化数据存储
- 支持 SQL 查询
- 适合精确匹配和复杂关联查询
② 词法搜索引擎
许多搜索引擎基于词法搜索的单词与每个文档中的单词进行匹配,这种方法为词法方法为词法方法。即一个单词搜索引擎基于词法搜索的单词与每个文档中的单词进行匹配,这种方法为词法方法。这种常用【同义词引用】实现。
特点:
- 基于关键词匹配
- 使用倒排索引加速搜索
- 适合精确关键词查询
③ 向量数据库
向量存储不使用字词,而是使用【嵌入模型】将文本描述为高维向量。这允许使用向量相似度搜索对同义词对同义词进行有效的相似性搜索。这允许使用向量相似度搜索对同义词进行有效的相似性搜索。
特点:
- 基于语义相似度
- 使用向量嵌入表示文档
- 适合语义搜索和相似内容检索
2. LangChain 检索器(Retrievers)
2.1 什么是检索器
检索器是检索系统中的一个核心组件,它接收用户的接口(Query),检索出包含相关信息的候选文档集合。
检索器的工作流程如下:
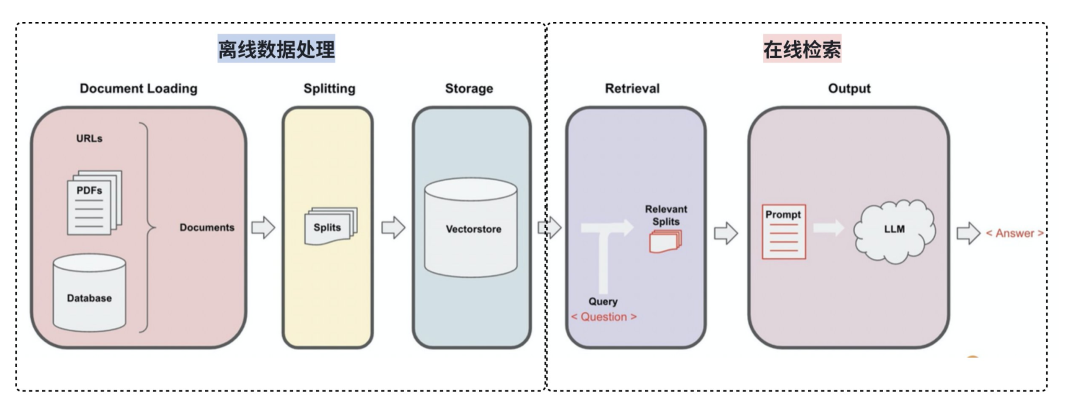
我们可以使用上面提到的任何检索系统构建检索器。如关系数据库、向量数据库等。由于其更性能和多样性,LangChain 提供了一个统一的接口来不同类型的检索系统进行交互。LangChain 的检索器接口非常简单:
- 输入:查询字符串
- 输出:文档列表(标准化的 LangChain 文档对象 Document)
2.2 检索器的简单示例
检索器的工作流程可以简化为:
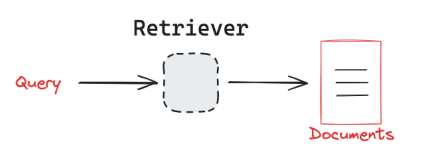
例如,使用向量数据库的检索器,检索器可以将向量转换为 SQL 语句,并执行查询,最后返回结果给用户。
下面,我们将演示如何使用向量数据库作为检索器。
3. 使用向量数据库作为检索器
3.1 基本使用
向量存储是最引人注目和最常用的结构化数据库的一种通过向量相似度搜索的方法。可以认为通过向量数据库的 as_retriever 方法,将向量存储用作检索器。在这里我们使用 Redis 向量存储。
代码示例:
python
from langchain_redis import RedisConfig, RedisVectorStore
from langchain_google_genai import GoogleGenerativeAIEmbeddings
# 初始化嵌入模型
embeddings = GoogleGenerativeAIEmbeddings(model="gemini-embedding-001")
# 配置 Redis 客户端(这里我容器端口映射主机6378端口的)
redis_url = "redis://localhost:6378"
config = RedisConfig(
index_name="qa",
redis_url=redis_url,
metadata_schema=[
{"name": "category", "type": "tag"},
{"name": "num", "type": "numeric"},
],
)
# 创建向量存储
vector_store = RedisVectorStore(embeddings, config=config)
# 构建检索器 - Runnable 对象
retriever = vector_store.as_retriever()
# LangChain 的检索器通常会返回 search_kwargs 中指定数量(默认为 4)的文档参数说明:
as_retriever():将向量存储转换为检索器- 默认返回 4 个最相关的文档
- 检索器是一个 Runnable 对象,可以直接调用
invoke()
3.2 使用 @chain 创建"检索器"
除了使用 as_retriever 方法,我们还可以自行创建一个"检索器"。回想一下检索器的特点:
- LangChain 检索器是一个 Runnable 的对象
- LangChain 检索器输入为查询字符串,输出为文档列表(标准化的 LangChain 文档对象 Document)
综上所述,我们可以:
使用 @chain 装饰器创建自定义检索器:
python
from typing import List
from langchain_core.runnables import chain
from langchain_core.documents import Document
@chain
def custom_retriever(query: str) -> List[Document]:
return vector_store.similarity_search(
query=query,
k=4,
)
# 调用
docs = custom_retriever.invoke("Claude skill是什么")
for doc in docs:
print(doc.page_content)
print("-----------------")上面定义了一个函数,使用 @chain 修饰,该修饰可以使其成为 Runnable 函数,且满足检索器输入输出的要求。在函数中,我们依旧使用向量数据库的相似性搜索方法,这样灵活性也更高,想要进行元数据筛选也更方便。
注意 :这并不是真正的检索器,检索器是一个 Runnable 对象,而我们定义的只是一个函数,具备其特点罢了,但是后期可以适当当做runnable对象特征使用,比如连接成chain(在 LangChain 的语境下,Retriever(检索器)通常特指实现了 _get_relevant_documents 接口的特定类)。
4. RAG(检索增强生成)
4.1 什么是 RAG
RAG 是当前大语言模型应用的核心模式。当用户向 LLM 提问时,系统首先使用嵌入模型在知识库中进行语义搜索,找到最相关的内容,然后将这些内容和问题一起交给 LLM 来生成答案。这极大地提高了答案的准确性和时效性。
RAG 的核心优势:
- 解决 LLM 的幻觉问题
- 提供最新的、特定领域的知识
- 无需重新训练模型
- 答案可追溯来源
4.2 RAG 工作流程
- 根据 Query 搜索最相关的 4 篇文档
- 将相关的文档转换为字符串,以便后续发送给聊天模型
- 将 Query 与文档字符串发送给聊天模型
- 聊天模型依据输入输出解析器格式化输出内容
由于 LangChain 检索器是一个 Runnable 的对象,我们便可以方便的使用链完成相关的调用。下面我们来完成一个最简单的 RAG 案例,将会完成:
- 根据 Query 搜索最相关的 4 篇文档
- 将相关的文档转换为字符串,以便后续发送给聊天模型
- 将 Query 与文档字符串发送给聊天模型
- 聊天模型依据输入输出解析器格式化输出内容
4.3 RunnablePassthrough 详解
RunnablePassthrough 我们之前还没有见过,简单来说,RunnablePassthrough 是一个"伪" Runnable,它的主要作用是在链(Chain)中透明地传递输入数据,而不做任何修改。
当我们需要将原始输入和另一个处理过程的输出一起传递给下一个步骤时,就需要 RunnablePassthrough。就例如代码中,我们需要将【Query】与【通过检索出来的文档转换的字符串】同时发送给提示词模板。
上面进过检索器不提供任何流式处理。但这里可以使用流式输出。我们可以把像 RAG 这样的链的执行过程想象成两个阶段:
- 阶段一:准备阶段(同步、阻塞):接收输入、检索文档、构建提示
- 阶段二:生成阶段(可流式):调用LLM
流式输出的是最终答案,而非中间过程。
4.4 完整 RAG 代码实现
基于 Redis 向量存储实现的完整 RAG 系统:
python
# 基于redis作为向量存储实现RAG
import os
from langchain_google_genai import GoogleGenerativeAIEmbeddings
from langchain_redis import RedisConfig, RedisVectorStore
from langchain_text_splitters import CharacterTextSplitter
from langchain_community.document_loaders.markdown import UnstructuredMarkdownLoader
from langchain_core.prompts import PromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough, RunnableLambda
from langchain_deepseek import ChatDeepSeek
# 配置代理(如果需要)
os.environ["http_proxy"] = "http://192.168.100.238:7890"
os.environ["https_proxy"] = "http://192.168.100.238:7890"
# 定义嵌入模型
embeddings = GoogleGenerativeAIEmbeddings(model="gemini-embedding-001")
# 配置 Redis 客户端
redis_url = "redis://localhost:6378"
config = RedisConfig(
index_name="qa",
redis_url=redis_url,
metadata_schema=[
{"name": "category", "type": "tag"},
{"name": "num", "type": "numeric"},
],
)
# 创建向量存储
vector_store = RedisVectorStore(embeddings, config=config)
# 加载文档(让 Markdown 按结构解析)
loader = UnstructuredMarkdownLoader("test.md", mode="elements")
documents = loader.load()
# 设置基于token的文本分割器
splitter = CharacterTextSplitter.from_tiktoken_encoder(
encoding_name="cl100k_base",
chunk_size=200,
chunk_overlap=50,
)
# 分割文档
chunks = splitter.split_documents(documents)
# 修改文档元数据
for i, chunk in enumerate(chunks, start=1):
chunk.metadata["category"] = "qa"
chunk.metadata["num"] = i
# 添加文档到向量存储
ids = vector_store.add_documents(chunks)
# 构建检索器 - Runnable对象
retriever = vector_store.as_retriever()
# 把文档转换为字符串的函数
def docs_to_str(docs) -> str:
return "\n".join([x.page_content for x in docs])
# 提示词模板
prompt = PromptTemplate(
input_variables=["context", "question"],
template="""根据对应的文档:{context} 结合问题:{question},请根据下面的 Context 来回答 Question 并用最多两句话简单回答。如果两者无关,无法总结出答案就说"抱歉,臣妾做不到"。
Question: {question}
Context: {context}
Answer:"""
)
# 定义LLM
llm = ChatDeepSeek(model="deepseek-chat")
# 构建链
# RunnablePassthrough() 是为了传递问题参数到提示词中
# {"context": retriever | docs_to_str, "question": RunnablePassthrough()} 的逗号两边是同时进行的
# 右边 RunnablePassthrough 拿到输入后立刻自己喂给 question,同时给 retriever
# 等待这个链完成后返回结果做 context
chain = {
"context": retriever | RunnableLambda(docs_to_str),
"question": RunnablePassthrough()
} | prompt | llm | StrOutputParser()
# 调用链 - 交互式问答
while True:
question = input("请输入问题:")
if question == "exit":
break
result = chain.invoke(question)
print(result.strip())运行示例:
请输入问题:skills 是啥
Skills 是 Claude 中用于固化与复用标准化工作流程的功能单元,每个 Skill 以一个包含核心文件 SKILL.md 的文件夹形式存在。
请输入问题:苹果之父是谁
抱歉,臣妾做不到。
提供的 Context 内容是关于文档管理与更新的常见问题,与"苹果之父是谁"这一问题无关。5. RAG 链的执行流程详解
5.1 链的构建
python
chain = {
"context": retriever | RunnableLambda(docs_to_str),
"question": RunnablePassthrough()
} | prompt | llm | StrOutputParser()这个链的执行流程可以分解为:
第一步:并行执行(字典部分)
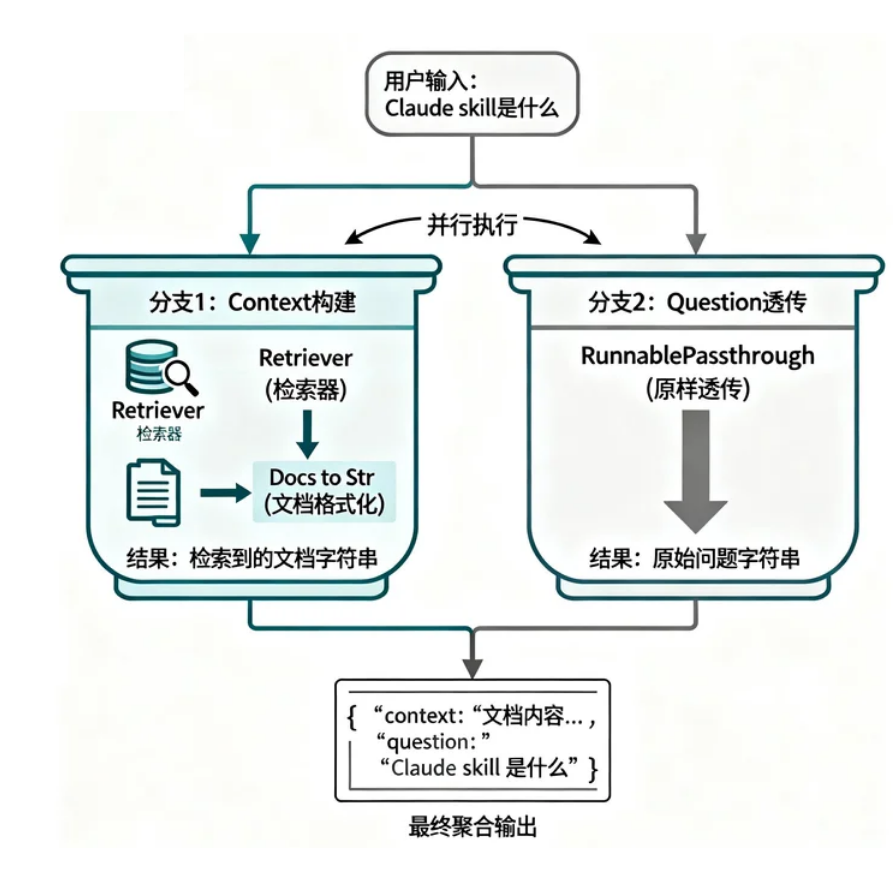
第二步:提示词模板
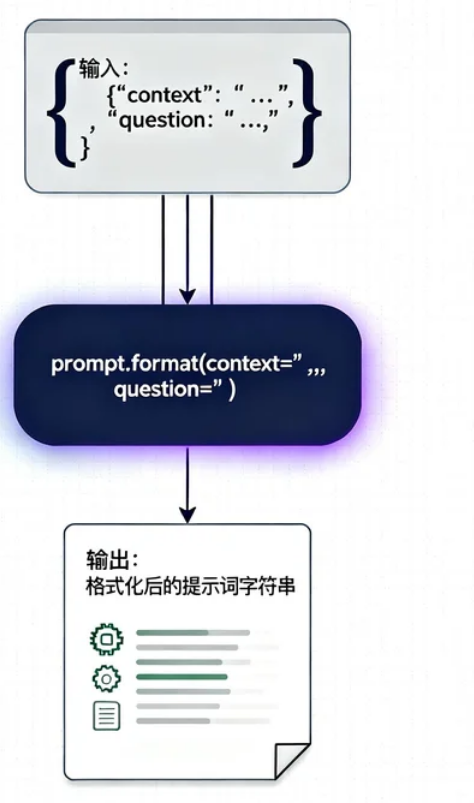
第三步:LLM 生成
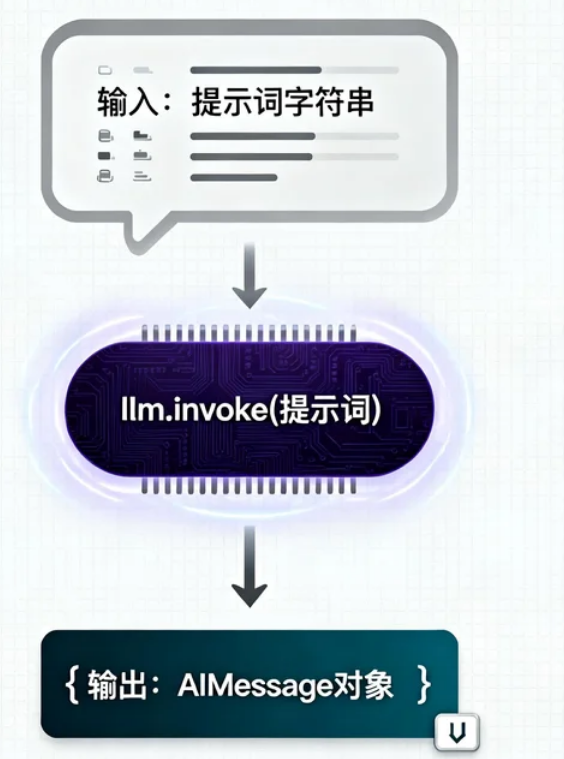
第四步:输出解析
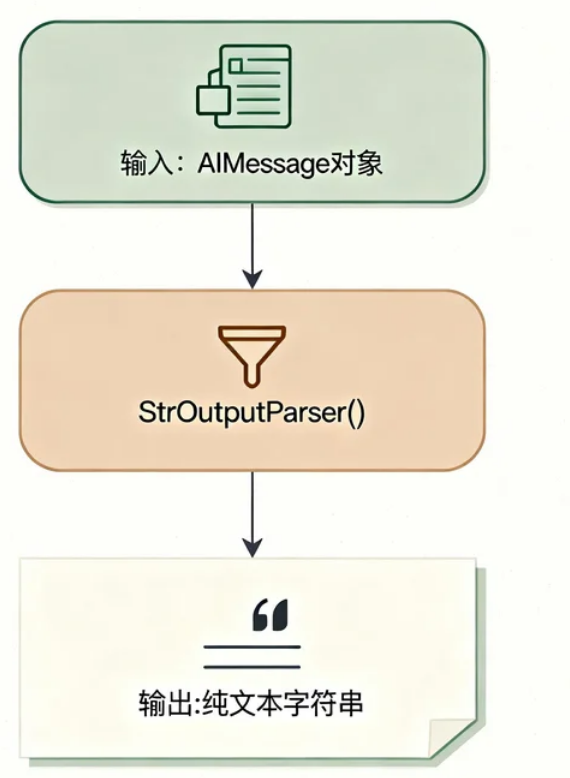
5.2 RunnablePassthrough 的作用
RunnablePassthrough 在链中的作用是透明传递输入数据:
python
# 示例1:直接传递
RunnablePassthrough().invoke("hello") # 输出: "hello"
# 示例2:在字典中使用
chain = {
"original": RunnablePassthrough(),
"processed": some_function
}
chain.invoke("input")
# 输出: {"original": "input", "processed": some_function("input")}在 RAG 链中,我们需要同时传递:
- 原始问题(给 question 参数)
- 检索到的文档(给 context 参数)
所以使用 RunnablePassthrough() 来保留原始问题。
5.3 并行执行的优势
字典形式的链会并行执行所有分支:
python
{
"context": retriever | docs_to_str, # 分支1:检索文档
"question": RunnablePassthrough() # 分支2:传递问题
}这意味着:
- 检索文档和传递问题同时进行
- 提高了执行效率
- 两个分支完成后,结果合并为字典
6. 检索器的高级用法
6.1 检索器的 search_type
LangChain 检索器支持多种搜索类型:
python
# 1. 相似度搜索(默认)
retriever = vector_store.as_retriever(
search_type="similarity",
search_kwargs={"k": 4}
)
# 2. MMR(最大边际相关性)搜索
retriever = vector_store.as_retriever(
search_type="mmr",
search_kwargs={"fetch_k": 10, "k": 4}
)
# 3. 相似度分数阈值(注意:Redis 不支持)
# retriever = vector_store.as_retriever(
# search_type="similarity_score_threshold",
# search_kwargs={"score_threshold": 0.5, "k": 4}
# )注意:不同的向量存储支持的 search_type 不同:
- Redis:支持
similarity和mmr - Chroma:支持
similarity、mmr和similarity_score_threshold - Pinecone:支持
similarity和mmr
6.2 元数据过滤
可以在检索时添加元数据过滤条件:
python
from redisvl.query.filter import Tag, Num
# 创建过滤器
filter_func = Tag("category") == "qa"
filter_func = filter_func & (Num("num") <= 10)
# 使用过滤器检索
docs = vector_store.similarity_search(
query="Claude skill是什么",
k=4,
filter=filter_func
)7. RAG 系统的优化建议
7.1 文档分割优化
python
# 合理设置 chunk_size 和 chunk_overlap
splitter = CharacterTextSplitter.from_tiktoken_encoder(
encoding_name="cl100k_base",
chunk_size=200, # 每块 200 tokens
chunk_overlap=50, # 重叠 50 tokens
)建议:
chunk_size:200-500 tokens 为宜chunk_overlap:chunk_size 的 10-20%
7.2 检索数量优化
python
# 设置合适的 k 值
retriever = vector_store.as_retriever(
search_kwargs={"k": 4} # 返回 4 个最相关文档
)建议:
- k 太小:可能遗漏相关信息
- k 太大:增加 token 消耗,可能引入噪音
- 推荐:3-5 个文档
7.3 提示词优化
python
prompt = PromptTemplate(
input_variables=["context", "question"],
template="""根据以下文档回答问题。如果文档中没有相关信息,请明确说明。
文档:
{context}
问题:{question}
回答:"""
)建议:
- 明确指示 LLM 如何处理无关问题
- 要求 LLM 引用来源
- 限制回答长度
8. 总结
8.1 核心要点
- 检索器是 RAG 系统的核心组件,负责从知识库中检索相关文档
- LangChain 提供统一的检索器接口,支持多种向量数据库
- RAG 通过检索增强生成,解决 LLM 的幻觉问题
- RunnablePassthrough 用于在链中透明传递数据
- 字典形式的链支持并行执行,提高效率
8.2 完整工作流程
文档加载
Loader
文本分割
Splitter
向量嵌入
Embeddings
向量存储
VectorStore
构建检索器
Retriever
构建 RAG 链
Chain
交互式问答
Invoke