学习项目 Github 地址: github.com/huhaochi221...
智扫通 Agent 地址: github.com/huhaochi221...
LangChain 简介
LangChain 由 Harrison Chase 创建于2022年10月,它是围绕LLMs(大语言模型)建立的一个框架。
LangChain自身并不开发LLMs,它的核心理念是为各种LLMs实现通用的接口,把LLMs相关的组件"链接"在一起, 简化LLMs应用的开发难度,方便开发者快速地开发复杂的LLMs应用。
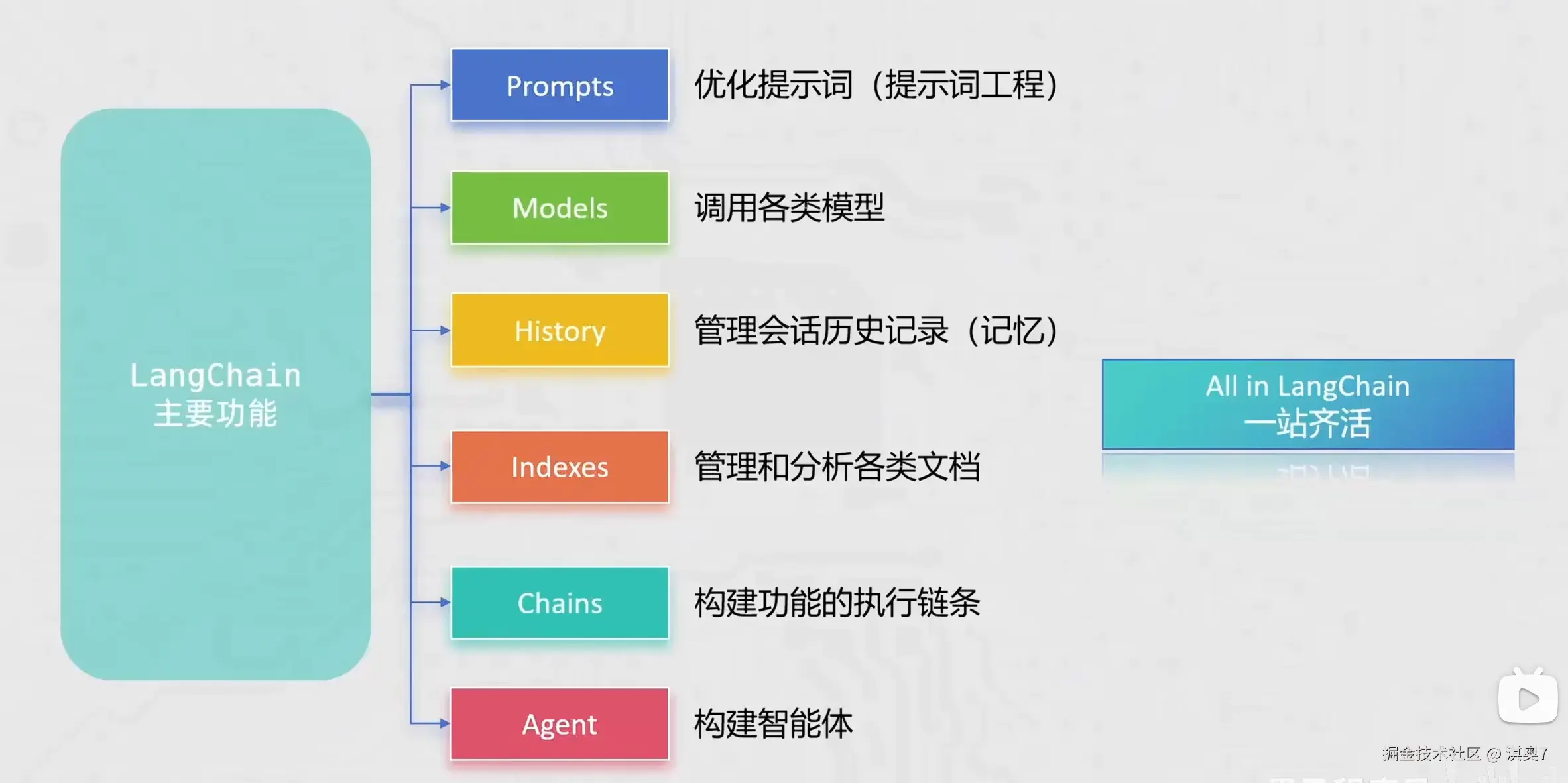
LangChain是后续学习RAG开发的主力框架
安装
本质上是 Python 的 SDK (第三方包)
一行命令: pip install langchain langchain-community langchain-ollama dashscope chromadb
- langchain:核心包
- langchain-community:社区支持包,提供了更多的第三方模型调用(我们用的阿里云干问模型就需要这个包)
- langchain-ollama:0llama支持包,支持调用ollama托管部署的本地模型
- dashscope:阿里云通义千问的Python SDK
- chromadb:轻量向量数据库(后续使用)
RAG 介绍
通用的基础大模型存在一些问题:
- LLM的知识不是实时的,模型训练好后不具备自动更新知识的能力,会导致部分信息滞后
- LLM领域知识是缺乏的,大模型的知识来源于训练数据,这些数据主要来自公开的互联网和开源数据集,无法覆盖特定领域或高度专业化的内部知识
- 幻觉问题,LLM有时会在回答中生成看似合理但实际上是错误的信息
- 数据安全性
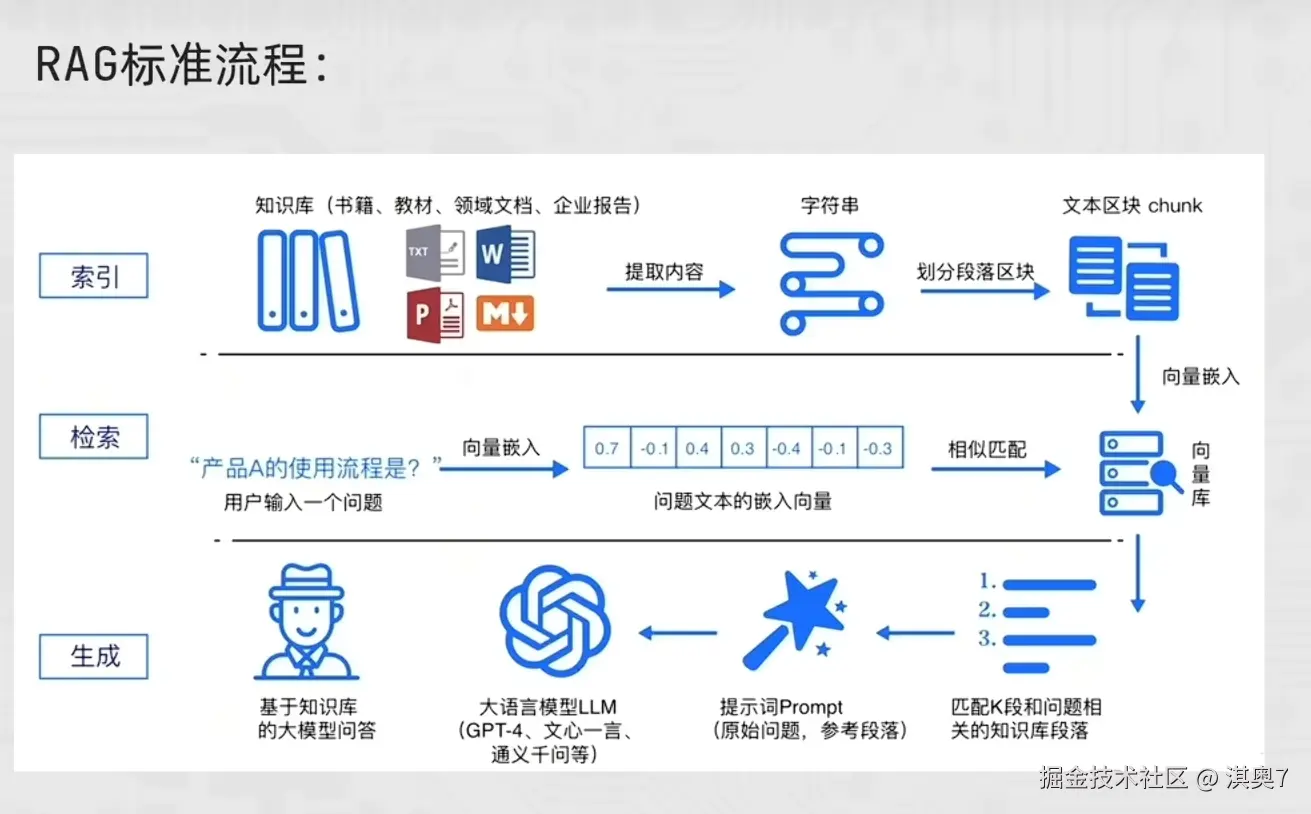
RAG (Retrieval-Augmented Generation)即检索增强生成,为大模型提供了从特定数据源检索到的信息,以此来修正和补充生成的答案。可以总结为一个公式:RAG = 检索技术 + LLM 提示。
向量的基础概念
RAG流程中,向量库是一个重要的节点。
- 离线流程:知识和信息→向量嵌入(向量化)→ 存入向量库
- 在线流程:用户的提问→向量嵌入(向量化)→ 在向量库中匹配
向量(Vector)就是文本的"数学身份证":它把一段文字的语义信息 ,转换成一串固定长度的数字列表,让计算机能"看懂"文字的含义并做相似度计算。
在向量匹配的过程中,如何识别2段文本是否表述相似的含义,主要可以通过如余弦相似度等算法来完成 比如(下列案例中向量为示例,仅描述概念,非真实向量):

如text-embedding-v1模型,可以生成1536维的向量(一段文本固定得到1536个数字序列),比较实用。 1536个数字表示,这段文本在1536个主题(抽象的语义特征)方向上的得分(强度)。
余弦相似度
向量的数字序列,共同决定了向量在高维空间中的方向和长度.而余弦相似度主要就是撇除长度的影响,得到方向的夹角。夹角越小越相似,即方向相同。

LangChainRAG 组件
LangChain目前支持三种类型的模型:LLMs(大语言模型)、Chat ModeLs(聊天模型)、Embeddings ModeLs(嵌入模型)。
- LLMs:是技术范畴的统称,指基于大参数量、海量文本训练的 Transformer 架构模型,核心能力是理解和生成自然语言,主要服务于文本生成场景
- 聊天模型:是应用范畴的细分,是专为对话场景优化的 LLMs,核心能力是模拟人类对话的轮次交互,主要服务于聊天场景
- 文本嵌入模型:文本嵌入模型接收文本作为输入,得到文本的向量。
LangChain支持的三类模型,它们的使用场景不同,输入和输出不同,开发者需要根据项目需要选择相应。
LangChain 访问大模型
Python
from langchain_community.llms.tongyi import Tongyi
model = Tongyi(model="qwen-max")
# 调用invoke向模型提问
res =model.invoke(input="你是谁?")
print(res)模型的流式输出
Python
from langchain_community.llms.tongyi import Tongyi
model = Tongyi(model="qwen-max")
# 调用invoke向模型提问
res =model.stream(input="你是谁?")
for chunk in res:
print(chunk,end="", flush=True)LangChain 调用聊天模型
Python
from langchain_community.chat_models.tongyi import ChatTongyi
from langchain_core.messages import HumanMessage, SystemMessage, AIMessage
model = ChatTongyi(model="qwen3-max", streaming=True)
messages = [
SystemMessage(content="你是李白"),
HumanMessage(content="给我写一首唐诗"),
AIMessage(content="""
《月下独酌·其二》
金樽对月饮长空,
万里江天一色同。
醉踏青崖云作伴,
笑邀白鹿访仙翁。
星垂大野浮银汉,
浪卷千峰入玉虹。
莫问明朝何处去,
且将肝胆照苍穹!
"""),
HumanMessage(content="就按你上一个回复的格式,输出诗句")
]
res = model.stream(input=messages)
for chunk in res:
print(chunk.content, end="", flush=True)LangChain 的消息简写
Python
from langchain_community.chat_models.tongyi import ChatTongyi
from langchain_core.messages import HumanMessage, SystemMessage, AIMessage
model = ChatTongyi(model="qwen3-max", streaming=True)
messages = [
("system", "你是李白"),
("human", "给我写一首唐诗"),
("ai", """
《月下独酌·其二》
金樽对月饮长空,
万里江天一色同。
醉踏青崖云作伴,
笑邀白鹿访仙翁。
星垂大野浮银汉,
浪卷千峰入玉虹。
莫问明朝何处去,
且将肝胆照苍穹!
""" ),
("human", "就按你上一个回复的格式,输出诗句")
]
res = model.stream(input=messages)
for chunk in res:
print(chunk.content, end="", flush=True)
LangChain 调用嵌入模型
Embeddings ModeLs嵌入模型的特点:将字符串作为输入,返回一个浮点数的列表(向量)。 在NLP中,Embedding的作用就是将数据进行文本向量化
Python
from langchain_community.embeddings import DashScopeEmbeddings
model = DashScopeEmbeddings()
print(model.embed_query("我喜欢你"))
print(model.embed_documents(["我喜欢你", "我稀饭你", "晚上吃啥"]))LangChain 通用提示词模板
Python
from langchain_core.prompts import PromptTemplate
from langchain_community.llms.tongyi import Tongyi
# zero-shot
prompt_template = PromptTemplate.from_template(
"我的邻居姓{lastname},刚生了{gender},你帮我取个名字,简单回答"
)
model = Tongyi(model="qwen-max")
# 调用format方法
# prompt_text = prompt_template.format(lastname="胡",gender="男孩")
# print(prompt_text)
# res = model.invoke(input=prompt_text)
# print(res)
# 构建执行链条的方法
chain = prompt_template | model
res = chain.invoke(input={"lastname": "胡", "gender": "女儿"})
print(res)FewShot 提示词模板
ini
from langchain_community.llms.tongyi import Tongyi
from langchain_core.prompts import FewShotPromptTemplate, PromptTemplate
# 示例模板
example_template = PromptTemplate.from_template("单词:{word}, 反义词:{antonym}")
# 示例的数据
example_data = [
{"word": "大", "antonym": "小"},
{"word": "高", "antonym": "低"}
]
few_shot_template = FewShotPromptTemplate(
example_prompt=example_template, # 示例数据的模板
examples=example_data, # 示例数据(动态注入),list内嵌字典
prefix="告诉我单词的反义词,我提供如下示例:", # 示例之前的提示词
suffix="基于前面的示例告诉我:{input_word}的反义词是?", # 示例之后的提示词
input_variables=['input_word'] # 声明在前缀或后缀中需要注入的变量名
)
prompt_text = few_shot_template.invoke(input={"input_word": "左"}).to_string()
print(prompt_text)
model = Tongyi(model="qwen-max")
print(model.invoke(input=prompt_text))模板类的 format 和 invoke 方法
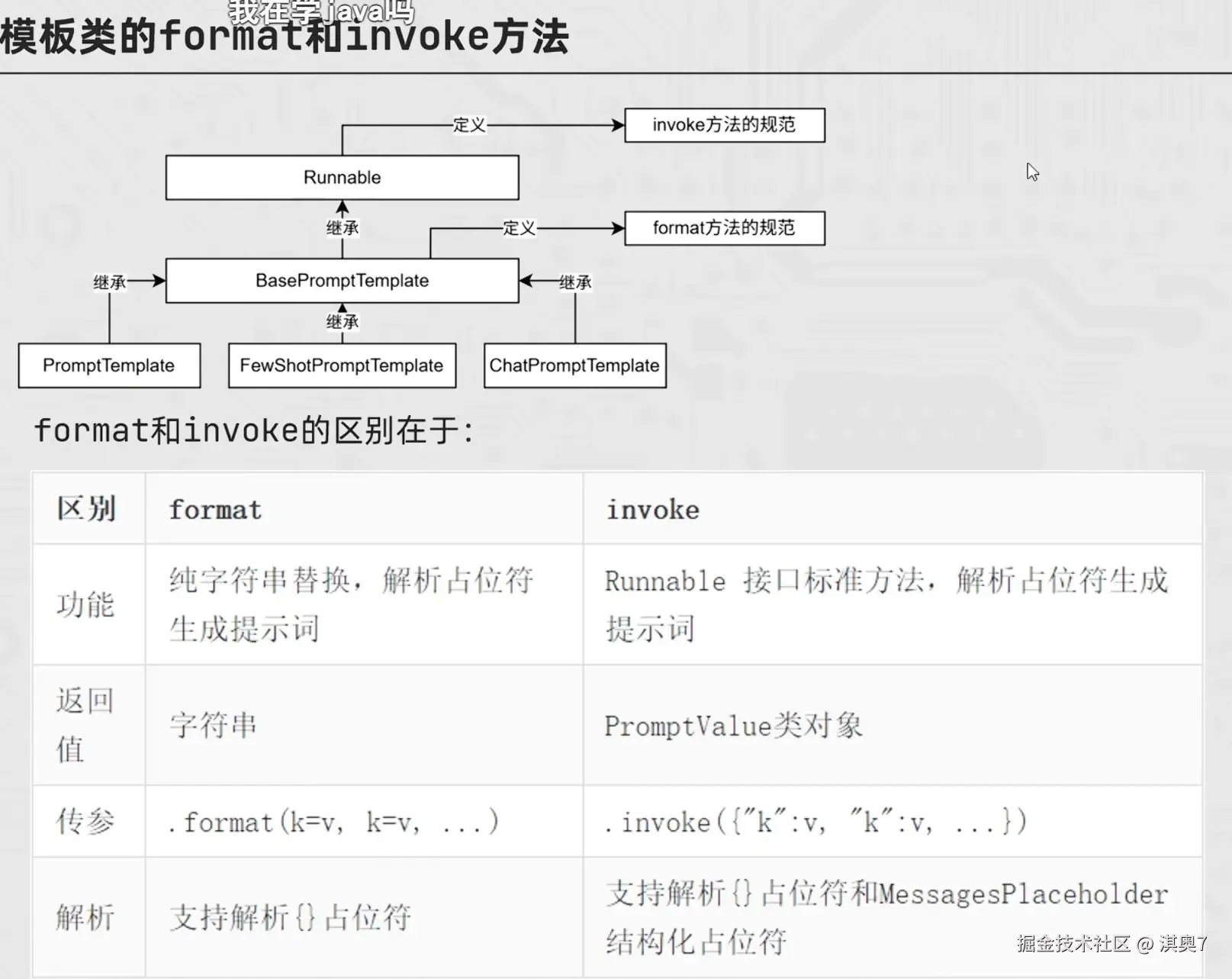
Python
from langchain_core.prompts import PromptTemplate
template = PromptTemplate.from_template("我的邻居是:{name}, 最喜欢:{hobby}")
res = template.format(name="狗蛋", hobby="看电影")
print(res,type(res))
res = template.invoke({"name": "乔奕磊", "hobby": "旅游"})
print(res,type(res))输出
arduino
我的邻居是:狗蛋, 最喜欢:看电影 <class 'str'>
text='我的邻居是:乔奕磊, 最喜欢:旅游' <class 'langchain_core.prompt_values.StringPromptValue'>ChatPromptTemplate 的使用
PromptTemplate:通用提示词模板,支持动态注入信息。 FewShotPromptTempLate:支持基于模板注入任意数量的示例信息。 ChatPromptTemplate:支持注入任意数量的历史会话信息。
Python
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_deepseek import ChatDeepSeek
chat_prompt_template = ChatPromptTemplate.from_messages(
[
("system","你是一个边塞诗人,可以作诗"),
MessagesPlaceholder("history"),
("human","请再来一首唐诗")
]
)
history_data = [
("human","你来写一首唐诗"),
("system", "床前明月光,疑是地上霜.举头望明月,低头思故乡.")
]
#StringPrompt Value
prompt_text = chat_prompt_template.invoke({"history": history_data}).to_string()
print(prompt_text)
model = ChatDeepSeek(model="deepseek-v4-flash")
res = model.invoke(prompt_text)
print(res.content)chain 的基础使用
「将组件串联,上一个组件的输出作为下一个组件的输入!是LangChain链(尤其是丨管道链)的核心工作 原理,这也是链式调用的核心价值:实现数据的自动化流转与组件的协同工作,如下。
chain = prompt_template l model 核心前提:即Runnable子类对象才能入链(以及callable、Mapping接口子类对象也可加入(后续了解用的不多))。
我们目前所学习到的组件,均是Runnable接口的子类,如下类的继承关系:
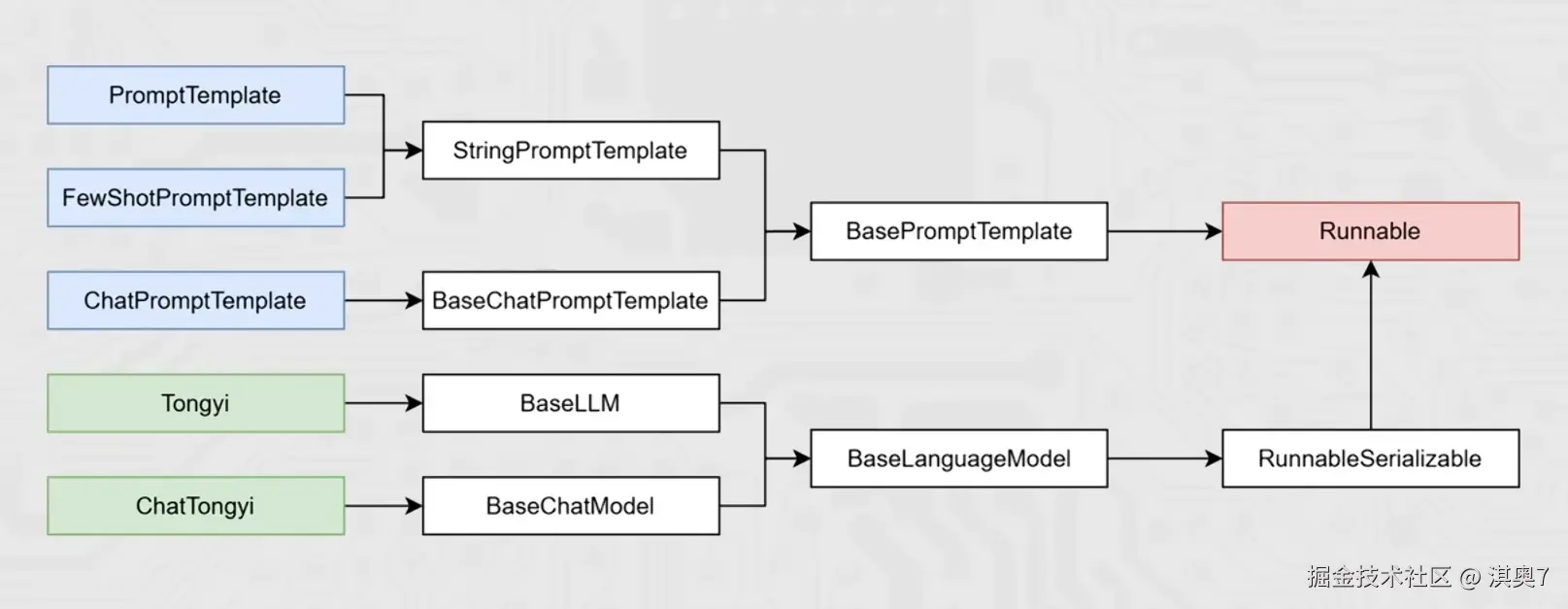
组成的链在执行上有:上一个组件的输出作为下一个组件的输入的特性。
所以有如下执行流程:

简单理解 Runnable 接口
LangChain 中的绝大多数核心组件都继承了 Runnable 抽象基类(位于 langchain_core.runnables.base)。 代码:
chain = prompt | model
chain变量是RunnableSequence (RunnableSerializable子类) 类型
而得到这个类型的原因就是Runnable基类内部对__or__魔术方法的改写。
同时,在后面继续使用「添加新的组件,依旧会得到RunnableSequence,这就是链的基础架构.
StrOutputParser 字符串输出解析器
StrOutputParser是LangChain内置的简单字符串解析器
- 可以将AIMessage解析为简单的字符串,符合了模型invoke方法要求(可传入字符串,不接收 AIMessage类型)
- 是Runnable接口的子类(可以加入链)
Python
chain = prompt | model | model会报错,错误的主要原因是:
- prompt的结果是PromptValue类型,输入给了model
- modeL的输出结果是AIMessage
所以需要做类型转换,可以借助LangChain 内置的解析器
Python
parser = StroutputParser()
chain = prompt | model 丨 parser 丨 modelJsonOutputParser&多模型执行链
在前面我们完成了这样的需求去构建多模型链,不过这种做法并不标准,因为:
上一个模型的输出,没有被处理就输入下一个模型。
正常情况下我们应该有如下处理逻辑:

我们要把 AIMessage 对象转化为dict 对象,StrOutputParser就不能使用了,这时候就要用到 JsonOutputParser
Python
from langchain_core.output_parsers import JsonOutputParser
from langchain_deepseek.chat_models import ChatDeepSeek
from langchain_core.prompts import PromptTemplate
json_paser = JsonOutputParser()
model = ChatDeepSeek(model="deepseek-v4-flash")
first_prompt = PromptTemplate.from_template(
"我邻居姓:{lastname},刚生了{gender},请帮忙起名字,并封装为 JSON 格式。要求key是name,value是你你起的名字"
)
second_prompt = PromptTemplate.from_template(
"姓名:{name},请帮我解析含义。"
)
chain = first_prompt | model | json_paser | second_prompt | model
for chunk in chain.stream({"lastname": "王", "gender": "男"}):
print(chunk.content, end="", flush=True)自定义函数加入链
前文我们根据JsonoutputParser完成了多模型执行链条的构建。
除了JsonOutputParser这类固定功能的解析器之外我们也可以自己编写Lambda匿名函数来完成自定义逻辑的数据转换,想怎么转换就怎么转换,更自由。
想要完成这个功能,可以基于RunnableLambda类实现。
RunnableLambda类是LangChain内置的,将普通函数等转换为Runnable接口实例,方便自定义函数加入chain。 语法:
RunnabLeLambda(函数对象或Lambda匿名函数)
Python
from langchain_core.output_parsers import JsonOutputParser, StrOutputParser
from langchain_core.runnables import RunnableLambda
from langchain_deepseek.chat_models import ChatDeepSeek
from langchain_core.prompts import PromptTemplate
json_paser = JsonOutputParser()
model = ChatDeepSeek(model="deepseek-v4-flash")
str_parser = StrOutputParser()
first_prompt = PromptTemplate.from_template(
"我邻居姓:{lastname},刚生了{gender},请帮忙起名字,并封装为 JSON 格式。要求仅输出姓名,不要其他内容"
)
second_prompt = PromptTemplate.from_template(
"姓名:{name},请帮我解析含义。"
)
my_func = RunnableLambda(lambda ai_msg : {"name": ai_msg.content})
chain = first_prompt | model | my_func | second_prompt | model | str_parser
for chunk in chain.stream({"lastname": "王", "gender": "男"}):
print(chunk, end="", flush=True)Memory 临时会话记忆
如果想要封装历史记录,除了自行维护历史消息外,也可以借助LangChain内置的历史记录附加功能。
LangChain提供了History功能,帮助模型在有历史记忆的情况下回答。
- 基于RunnableWithMessageHistory在原有链的基础上创建带有历史记录功能的新链(新Runnable实例)
- 基于InMemoryChatMessageHistory为历史记录提供内存存储(临时用)
Python
from langchain_core.chat_history import InMemoryChatMessageHistory
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_core.runnables import RunnableWithMessageHistory
from langchain_deepseek import ChatDeepSeek
model = ChatDeepSeek(model="deepseek-v4-flash")
prompt = PromptTemplate.from_template(
"你需要根据会话历史回应用户问题。对话历史:{chat_history},用户提问:{input},请回答"
)
str_parser = StrOutputParser()
base_chain = prompt | model | str_parser
store = {}
# 实现通过会话 id 获取 InMemoryChatMessageHistory 类对象
def get_history(session_id):
if session_id not in store:
store[session_id] = InMemoryChatMessageHistory()
return store[session_id]
# 创建一个新的链,对原有的链增强功能:自动附加历史消息
conversion_chain = RunnableWithMessageHistory(
base_chain, # 原有链
get_history, # 通过会话id获取历史消息
input_messages_key="input", #表示用户输入在模板中的占位符
history_messages_key="chat_history"
)
if __name__ == '__main__':
session_config = {
"configurable": {
"session_id": "user_001"
}
}
res = conversion_chain.invoke({"input": "这里有一只猫"}, session_config)
print("第1次执行:", res )
res = conversion_chain.invoke({"input": "这里有两只狗"}, session_config)
print("第2次执行:", res)
res = conversion_chain.invoke({"input": "这里有多少个宠物"}, session_config)
print("第3次执行:", res)Memory 长期会话
使用InMemoryChatMessageHistory仅可以在内存中临时存储会话记忆,一旦程序退出,则记忆丢失。 InMemoryChatMessageHistory 类继承自 BaseChatMessageHistory
我们可以自行实现一个基于Json格式和本地文件的会话数据保存
FileChatMessageHistory类实现,核心思路:
- 基于文件存储会话记录,以session_id为文件名,不同session_id有不同文件存储消息
继承BaseChatMessageHistory实现如下3个方法:
- add_messages:同步模式,添加消息
- messages:同步模式,获取消息
- clear:同步模式,清除消息
Python
import os, json
from typing import Sequence
from langchain_core.chat_history import BaseChatMessageHistory
from langchain_core.messages import message_to_dict, messages_from_dict, BaseMessage
from langchain_core.chat_history import InMemoryChatMessageHistory
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_core.runnables import RunnableWithMessageHistory
from langchain_deepseek import ChatDeepSeek
# message_to_dict: 将message对象转换为字典
# message_from_dict: 将字典转换为message对象
class FileChatMessageHistory(BaseChatMessageHistory):
def __init__(self,session_id, storage_path):
self.session_id = session_id # 会话id
self.storage_path = storage_path # 不同会话id的存储文件路径
self.file_path = os.path.join(self.storage_path, session_id)
os.makedirs(os.path.dirname(self.file_path), exist_ok=True)
def add_messages(self, messages: Sequence[BaseMessage]) -> None:
all_messages = list(self.messages) # 已有的消息列表
all_messages.extend(messages) # 新的和已有的融合成一个list
# 将数据同步写入本地文件
# 类对象写入文件 -> 一堆二进制
# 为了方便, 可以将BaseMessage消息转换为字典(借助JSON模块以json字符串写入文件)
new_messages = []
for message in all_messages:
d = message_to_dict(message)
new_messages.append(d)
# 将数据写入文件
with open(self.file_path, "w", encoding="utf-8") as f:
json.dump(new_messages, f)
@property #@property 装饰器将message方法变成成员属性用
def messages(self) -> list[BaseMessage]:
try:
with open(self.file_path, "r", encoding="utf-8") as f:
messages_data = json.load(f) # 返回值就是:list[字典]
return messages_from_dict(messages_data)
except FileNotFoundError:
return []
def clear(self) -> None:
with open(self.file_path, "w", encoding="utf-8") as f:
json.dump([], f)
model = ChatDeepSeek(model="deepseek-v4-flash")
prompt = PromptTemplate.from_template(
"你需要根据会话历史回应用户问题。对话历史:{chat_history},用户提问:{input},请回答"
)
str_parser = StrOutputParser()
base_chain = prompt | model | str_parser
store = {}
# 实现通过会话 id 获取 InMemoryChatMessageHistory 类对象
def get_history(session_id):
return FileChatMessageHistory(session_id, "./chat_history")
# 创建一个新的链,对原有的链增强功能:自动附加历史消息
conversion_chain = RunnableWithMessageHistory(
base_chain, # 原有链
get_history, # 通过会话id获取历史消息
input_messages_key="input", #表示用户输入在模板中的占位符
history_messages_key="chat_history"
)
if __name__ == '__main__':
session_config = {
"configurable": {
"session_id": "user_001"
}
}
# res = conversion_chain.invoke({"input": "这里有一只猫"}, session_config)
# print("第1次执行:", res )
#
# res = conversion_chain.invoke({"input": "这里有两只狗"}, session_config)
# print("第2次执行:", res)
res = conversion_chain.invoke({"input": "这里有多少个宠物"}, session_config)
print("第3次执行:", res)CSVLoader 的使用
Python
from langchain_community.document_loaders import CSVLoader
loader = CSVLoader(
file_path="./data/stu.csv",
csv_args={
"delimiter": ",", # 指定分隔符
"quotechar": '"', # 指定带有分隔符文本的引号包围是单引号还是双引号
# 如果数据有表头,就不要下方代码
"fieldnames": ['a','b','c','d']
},
encoding="utf-8"
)
documents = loader.load()
print(documents)
# 懒加载
for document in loader.lazy_load():
print(document)JSONLoader
JSONLoader用于将JSON数据加载为Document类型对象。 使用JSONLoader需要额外安装:pip install jq

Python
from langchain_community.document_loaders import JSONLoader
loader = JSONLoader(
file_path="./data/stu_json_lines.json",
jq_schema=".name",
text_content=False,
json_lines=True
)
document = loader.load()
print(document)
JSON
{"name": "周杰伦", "age": 11, "gender": "男"}
{"name": "蔡依林", "age": 12, "gender": "女"}
{"name": "王力鸿", "age": 11, "gender": "男"}TextLoader 和文档分割器

Python
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
loader = TextLoader("./data/我的学习笔记.txt", encoding="utf-8")
docs = loader.load()
splitter = RecursiveCharacterTextSplitter(
chunk_size=500, # 片段长度
chunk_overlap=50, # 片段重叠长度
# 文本自然段落分隔的依据符号
separators=["\n\n", "\n", " ", "", "", "。", "?", "!", ",", "、"],
length_function=len
)
split_docs = splitter.split_documents(docs)
print(len(split_docs))
for doc in split_docs:
print(doc)
print("=" * 80)PyPDFLoader
LangChain内支持许多PDF的加载器,我们选择其中的PyPDFLoader使用。
PyPDFLoader加载器,依赖PyPDF库,所以,需要安装它:pip install pypdf
Python
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader(
file_path="./data/咏鹅.pdf",
mode="single", # single 只返回一个Document对象
password="123456"
)
i = 0
for doc in loader.lazy_load():
i += 1
print(doc)
print("=" * 80)Vector Store 向量存储
基于LangChain的向量存储,存储嵌入数据,并执行相似性搜索。
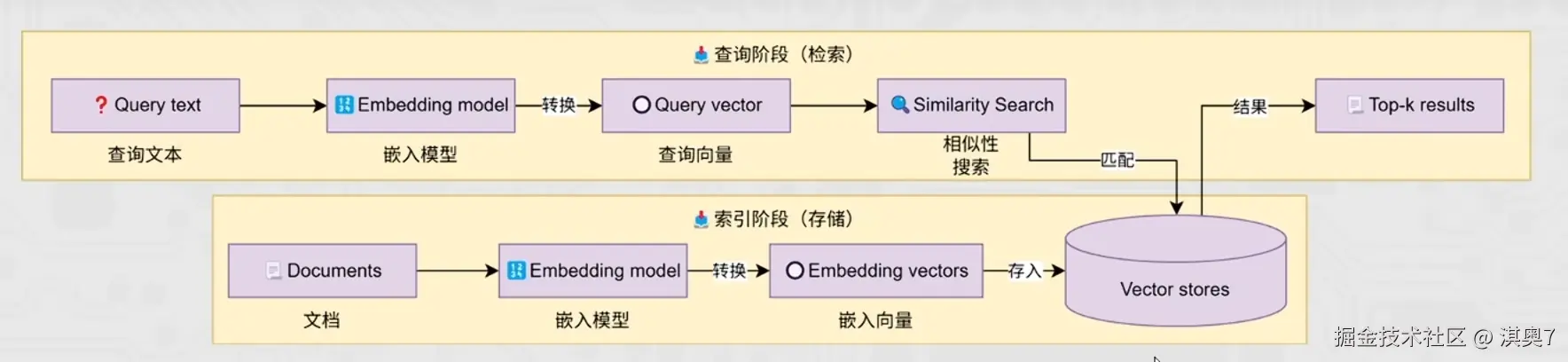
1. 内存向量存储
Python
from langchain_core.vectorstores import InMemoryVectorStore
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_community.document_loaders import CSVLoader
vector_store = InMemoryVectorStore(
embedding=DashScopeEmbeddings()
)
loader = CSVLoader(
file_path="./data/info.csv",
encoding="utf-8",
source_column="source", # 指定本条数据来源是哪路
)
documents = loader.load()
print(documents[1])
# 向量存储的新增,删除,检索
vector_store.add_documents(
documents=documents, # 添加的文档, 类型为list[Document]
ids=["id" + str(i) for i in range(1, len(documents) + 1)] # 给添加的文档提供id
)
vector_store.delete(["id1", "id2"])
result = vector_store.similarity_search(
"Python是不是简单易学",
3
)
print(result)2.外部向量持久化存储
Python
from langchain_chroma import Chroma
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_community.document_loaders import CSVLoader
# Chroma 轻量级向量数据库
# 下载LangChain-chroma chromaDB
vector_store = Chroma(
collection_name="test", # 表名
embedding_function=DashScopeEmbeddings(), # 嵌入模型
persist_directory="./chroma_db" # 文件夹
)
# loader = CSVLoader(
# file_path="./data/info.csv",
# encoding="utf-8",
# source_column="source", # 指定本条数据来源是哪路
# )
#
# documents = loader.load()
#
# print(documents[1])
#
# # 向量存储的新增,删除,检索
#
# vector_store.add_documents(
# documents=documents, # 添加的文档, 类型为list[Document]
# ids=["id" + str(i) for i in range(1, len(documents) + 1)] # 给添加的文档提供id
# )
#
# vector_store.delete(["id1", "id2"])
result = vector_store.similarity_search(
"Python是不是简单易学",
3,
filter={"source": "黑马程序员"}
)
print(result)基于向量检索构建提示词
Python
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.vectorstores import InMemoryVectorStore
from langchain_deepseek import ChatDeepSeek
model = ChatDeepSeek(model="deepseek-v4-flash")
prompt = ChatPromptTemplate.from_messages(
[
("system", "以我提供的已知参考资料为主,简洁和专业的回答用户问题。参考资料:{context}。"),
("user", "用户提问:{input}")
]
)
vector_store = InMemoryVectorStore(embedding=DashScopeEmbeddings(model="text-embedding-v1"))
vector_store.add_texts(["减肥就是要少吃多练","在减脂期间吃东西很重要,清淡少油控制卡路里摄入并运动起来","跑步是很好的运动哦"])
input_text = "怎么减肥?"
result = vector_store.similarity_search(input_text, 2)
reference_text = "["
for doc in result:
reference_text += doc.page_content
reference_text += "]"
print(reference_text)
def print_prompt(prompt):
print(prompt.to_string())
print("=" * 20)
return prompt
chain = prompt | print_prompt | model | StrOutputParser()
res = chain.invoke({"input": input_text, "context": reference_text})
print(res)RunnablePassThrought 的使用
向量检索加入链
Python
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_core.documents import Document
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_core.vectorstores import InMemoryVectorStore
from langchain_deepseek import ChatDeepSeek
def print_prompt(prompt):
print(prompt.to_string())
print("=" * 20)
return prompt
model = ChatDeepSeek(model="deepseek-v4-flash")
prompt = ChatPromptTemplate.from_messages(
[
("system", "以我提供的已知参考资料为主,简洁和专业的回答用户问题。参考资料:{context}。"),
("user", "用户提问:{input}")
]
)
vector_store = InMemoryVectorStore(embedding=DashScopeEmbeddings(model="text-embedding-v1"))
vector_store.add_texts(["减肥就是要少吃多练","在减脂期间吃东西很重要,清淡少油控制卡路里摄入并运动起来","跑步是很好的运动哦"])
input_text = "怎么减肥?"
retriever = vector_store.as_retriever(search_kwargs={"k": 2})
def format_func(docs: list[Document]):
if not docs:
return "无相关参考资料"
formatted_str = "["
for doc in docs:
formatted_str += doc.page_content
formatted_str += "]"
return formatted_str
chain = (
{"input": RunnablePassthrough(), "context": retriever | format_func} | prompt | print_prompt | model | StrOutputParser()
)
res = chain.invoke(input_text)
print(res)RAG 项目
RAG即检索、增强和生成,其主要分为2条线:
- 离线处理:向私有知识库(向量存储)源源不断添加私有知识文档
- 向知识库添加来自未来的知识文档(基于模型训练完成时间)
- 向模型添加私有知识文档
- 给出模型参考资料,规避模型幻觉(一本正经的胡说八道)
- 在线处理:用户提问会先基于私有知识库做检索,获取参考资料,同步组装新提示词询问大模型获取结果。
本次项目以"某东商品衣服"为例,以衣服属性构建本地知识。使用者可以自由更新本地知识,用户问题的答案也是基于本地知识生成的。

文本上传 WEB 服务
使用 streamlit 包快速构建简单的 web 服务
Python
import streamlit as st
st.title("知识库更新服务")
uploader_file = st.file_uploader(
"请上传txt文件",
type=["txt"],
accept_multiple_files=False
)
if uploader_file is not None:
file_name = uploader_file.name
file_type = uploader_file.type
file_size = uploader_file.size / 1024
st.subheader(f"文件名: {file_name}")
st.write(f"格式: {file_type} | 大小 {file_size:.2f}KB")
# get_value -> byte -> decode('utf-8')
text = uploader_file.getvalue().decode('utf-8')
st.write(text)md5 工具函数开发
Python
import os
import config_data as config
import hashlib
def check_md5(md5_str: str):
"""检查传入的MD5字符是否已经被传入过了
return False表示md5未处理过 True表示md5已处理过
"""
if not os.path.exists(config.md5_path):
# if 进入表示文件不存在
open(config.md5_path, 'w', encoding="utf-8").close()
return False
else:
for line in open(config.md5_path, 'r', encoding="utf-8").readlines():
line = line.strip() # 处理字符串前后的空格和回车
if line == md5_str:
return True
return False
def save_md5(md5_str: str):
"""保存传入的MD5字符"""
with open(config.md5_path, "a", encoding="utf-8") as f:
f.write(md5_str + '\n')
def get_string_md5(input_str: str, encoding="utf-8"):
"""获取传入的字符串的MD5"""
# 将字符串转换为byte字节数组
str_bytes = input_str.encode(encoding= encoding)
# 创建MD5对象
md5_obj = hashlib.md5()
md5_obj.update(str_bytes)
return md5_obj.hexdigest()
class KnowledgeBaseService(object):
def __init__(self):
self.chroma = None
self.spliter = None
def upload_by_str(self, data, filename):
"""将传入的字符串进行向量化,存入向量数据库中"""
pass
if __name__ == '__main__':
# save_md5("7a8941058aaf4df5147042ce104568da")
print(check_md5("7a8941058aaf4df5147042ce104568da"))知识库更新服务
Python
import os
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
from datetime import datetime
import config_data as config
import hashlib
from langchain_chroma import Chroma
def check_md5(md5_str: str):
"""检查传入的MD5字符是否已经被传入过了
return False表示md5未处理过 True表示md5已处理过
"""
if not os.path.exists(config.md5_path):
# if 进入表示文件不存在
open(config.md5_path, 'w', encoding="utf-8").close()
return False
else:
for line in open(config.md5_path, 'r', encoding="utf-8").readlines():
line = line.strip() # 处理字符串前后的空格和回车
if line == md5_str:
return True
return False
def save_md5(md5_str: str):
"""保存传入的MD5字符"""
with open(config.md5_path, "a", encoding="utf-8") as f:
f.write(md5_str + '\n')
def get_string_md5(input_str: str, encoding="utf-8"):
"""获取传入的字符串的MD5"""
# 将字符串转换为byte字节数组
str_bytes = input_str.encode(encoding= encoding)
# 创建MD5对象
md5_obj = hashlib.md5()
md5_obj.update(str_bytes)
return md5_obj.hexdigest()
class KnowledgeBaseService(object):
def __init__(self):
# 创建保存向量数据库的目录,已存在则跳过
os.makedirs(config.persist_directory, exist_ok=True)
self.chroma = Chroma(
collection_name=config.collection_name, # 表名
embedding_function=DashScopeEmbeddings(model="text-embedding-v1"),
persist_directory=config.persist_directory # 指定向量数据库的保存目录
)
self.spliter = RecursiveCharacterTextSplitter(
chunk_size=config.chunk_size, # 块大小
chunk_overlap=config.chunk_overlap, # 块重叠
separators=config.separators, # 文本分隔符
length_function=len # 获取文本长度的函数
)
def upload_by_str(self, data: str, filename):
"""将传入的字符串进行向量化,存入向量数据库中"""
md5_hax = get_string_md5(data)
if check_md5(md5_hax):
return "[跳过]数据已处理过"
if len(data) > config.max_splite_char_number:
knowledge_chunks: list[str] = self.spliter.split_text(data)
else:
knowledge_chunks = [data]
metadata = {
"source": filename,
"create_time": datetime.now().strftime("%Y-%m-%d %H:%M:%S"),
"operator": "hhc",
}
self.chroma.add_texts(
knowledge_chunks,
metadatas=[metadata for _ in knowledge_chunks]
)
save_md5(md5_hax)
return "[成功]数据处理完成"
if __name__ == '__main__':
service = KnowledgeBaseService()
r = service.upload_by_str("周杰伦", "textfile")
print(r)完成离线流程开发
python
"""
Streamlit: 当WEB页面元素改变时, 会自动触发页面更新
"""
import time
import streamlit as st
from knowledge_base import KnowledgeBaseService
st.title("知识库更新服务")
uploader_file = st.file_uploader(
"请上传txt文件",
type=["txt"],
accept_multiple_files=False
)
service = KnowledgeBaseService()
if "service" not in st.session_state:
st.session_state["service"] = KnowledgeBaseService()
if uploader_file is not None:
file_name = uploader_file.name
file_type = uploader_file.type
file_size = uploader_file.size / 1024
st.subheader(f"文件名: {file_name}")
st.write(f"格式: {file_type} | 大小 {file_size:.2f}KB")
# get_value -> byte -> decode('utf-8')
text = uploader_file.getvalue().decode('utf-8')
with st.spinner("正在处理数据..."):
time.sleep(1)
result = st.session_state["service"].upload_by_str(text, file_name)
st.write(result)在线流程开发
Python
from re import search
from langchain_chroma import Chroma
from langchain_community.embeddings import DashScopeEmbeddings
import config_data as config
class VectorStoreService(object):
def __init__(self, embedding):
self.embedding = embedding
self.vector_store = Chroma(
collection_name=config.collection_name,
embedding_function=embedding,
persist_directory=config.persist_directory,
)
def get_retriever(self):
return self.vector_store.as_retriever(search_kwargs={"k": config.similarity_threshold})
if __name__ == '__main__':
service = VectorStoreService(DashScopeEmbeddings(model="text-embedding-v1"))
retriever = service.get_retriever()
result = retriever.invoke("我的体重150斤,尺码推荐")
print(result)rag 核心服务开发
Python
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_core.documents import Document
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate, format_document
from langchain_core.runnables import RunnablePassthrough
from langchain_deepseek import ChatDeepSeek
import config_data as config
from vector_store import VectorStoreService
def print_prompt(prompt):
print(prompt.to_string())
print("=" * 20)
return prompt
class RagService(object):
def __init__(self):
self.vector_service = VectorStoreService(
embedding=DashScopeEmbeddings(model=config.embeddings_model_name)
)
self.prompt_template = ChatPromptTemplate(
[
("system", "以我提供的已知参考资料为主,简洁和专业的回答用户问题。参考资料:{context}。"),
("user", "请回答用户提问: {input}")
]
)
self.chat_model = ChatDeepSeek(model=config.chat_model_name)
self.chain = self.__get_chain()
def __get_chain(self):
retriever = self.vector_service.get_retriever()
def format_document(docs: list[Document]):
if not docs:
return "无相关参考资料"
formatted_str = ""
for doc in docs:
formatted_str += f"文档片段:{doc.page_content}\n文档元数据:{doc.metadata}\n\n"
return formatted_str
chain = (
{
"input": RunnablePassthrough(),
"context": retriever | format_document
} | self.prompt_template | print_prompt | self.chat_model | StrOutputParser()
)
return chain
if __name__ == '__main__':
res = RagService().chain.invoke("我的体重150斤,尺码推荐")
print(res)历史会话记录功能
Python
import json
import os
from typing import Sequence
from langchain_core.chat_history import BaseChatMessageHistory
from langchain_core.messages import BaseMessage, message_to_dict, messages_from_dict
def get_history(session_id):
return FileChatMessageHistory(session_id, "./chat_history")
class FileChatMessageHistory(BaseChatMessageHistory):
def __init__(self,session_id, storage_path):
self.session_id = session_id # 会话id
self.storage_path = storage_path # 不同会话id的存储文件路径
self.file_path = os.path.join(self.storage_path, session_id)
os.makedirs(os.path.dirname(self.file_path), exist_ok=True)
def add_messages(self, messages: Sequence[BaseMessage]) -> None:
all_messages = list(self.messages) # 已有的消息列表
all_messages.extend(messages) # 新的和已有的融合成一个list
# 将数据同步写入本地文件
# 类对象写入文件 -> 一堆二进制
# 为了方便, 可以将BaseMessage消息转换为字典(借助JSON模块以json字符串写入文件)
new_messages = []
for message in all_messages:
d = message_to_dict(message)
new_messages.append(d)
# 将数据写入文件
with open(self.file_path, "w", encoding="utf-8") as f:
json.dump(new_messages, f)
@property #@property 装饰器将message方法变成成员属性用
def messages(self) -> list[BaseMessage]:
try:
with open(self.file_path, "r", encoding="utf-8") as f:
messages_data = json.load(f) # 返回值就是:list[字典]
return messages_from_dict(messages_data)
except FileNotFoundError:
return []
def clear(self) -> None:
with open(self.file_path, "w", encoding="utf-8") as f:
json.dump([], f)这个 chain 太狗屎了, 第48行开始, 全是为了拼成链写了很多冗余代码
Python
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_core.documents import Document
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate, format_document, MessagesPlaceholder
from langchain_core.runnables import RunnablePassthrough, RunnableWithMessageHistory, RunnableLambda
from langchain_deepseek import ChatDeepSeek
import config_data as config
from RAG项目案例.file_history_store import get_history
from vector_store import VectorStoreService
def print_prompt(prompt):
print(prompt.to_string())
print("=" * 20)
return prompt
class RagService(object):
def __init__(self):
self.vector_service = VectorStoreService(
embedding=DashScopeEmbeddings(model=config.embeddings_model_name)
)
self.prompt_template = ChatPromptTemplate(
[
("system", "以我提供的已知参考资料为主,简洁和专业的回答用户问题。参考资料:{context}。"),
("system", "并且我提供用户的对话历史记录,如下"),
MessagesPlaceholder("history"),
("user", "请回答用户提问: {input}")
]
)
self.chat_model = ChatDeepSeek(model=config.chat_model_name)
self.chain = self.__get_chain()
def __get_chain(self):
retriever = self.vector_service.get_retriever()
def format_document(docs: list[Document]):
if not docs:
return "无相关参考资料"
formatted_str = ""
for doc in docs:
formatted_str += f"文档片段:{doc.page_content}\n文档元数据:{doc.metadata}\n\n"
return formatted_str
def temp1(value: dict) -> str:
return value["input"]
def temp2(value):
# {input, context, history}
new_value = {}
new_value["input"] = value["input"]["input"]
new_value["context"] = value["context"]
new_value["history"] = value["input"]["history"]
return new_value
chain = (
{
"input": RunnablePassthrough(),
"context": RunnableLambda(temp1) | retriever | format_document
} | RunnableLambda(temp2) | self.prompt_template | print_prompt | self.chat_model | StrOutputParser()
)
conversation_chain = RunnableWithMessageHistory(
chain,
get_history,
input_messages_key="input",
history_messages_key="history"
)
return conversation_chain
if __name__ == '__main__':
# sessionid 配置
session_config = {
"configurable":{
"session_id": "user_001",
}
}
res = RagService().chain.invoke({"input": "我的身高185cm,尺码推荐"}, session_config)
print(res)聊天页面开发
Python
import time
from rag import RagService
import streamlit as st
import config_data as config
st.title("智能客服")
st.divider()
rag_service = RagService()
if "message" not in st.session_state:
st.session_state["message"] = [{"role": "assistant", "content": "你好,我是智能客服,请开始提问吧!"}]
if "rag" not in st.session_state:
st.session_state["rag"] = RagService()
for message in st.session_state["message"]:
st.chat_message(message["role"]).write(message["content"])
prompt = st.chat_input()
if prompt:
st.chat_message("user").write(prompt)
st.session_state["message"].append({"role": "user", "content": prompt})
ai_res_list = []
with st.spinner("AI 思考中..."):
res_stream = st.session_state["rag"].chain.invoke({"input": prompt}, config.session_config)
def capture(generator, cache_list):
for chunk in generator:
cache_list.append(chunk)
yield chunk
st.chat_message("assistant").write_stream(capture(res_stream, ai_res_list))
st.session_state["message"].append({"role": "assistant", "content": "".join(ai_res_list)})Agent 智能体
智能体(Agent)是一种能够自主规划、决策、执行任务的组件,核心是让大语言模型(LLM)根据任务需求,选择并调用 工具,完成单靠模型自身无法解决的复杂问题。
- 没有Agent时,LLM 只能基于自身训练数据回答问题,遇到需要实时数据、复杂计算、外部工具调用的场景就会卡壳。
- 有了Agent后,LLM 就像一个"指挥官",能思考任务步骤>选择合适工具>执行工具调用>根据结果调整策略,直到完成任务
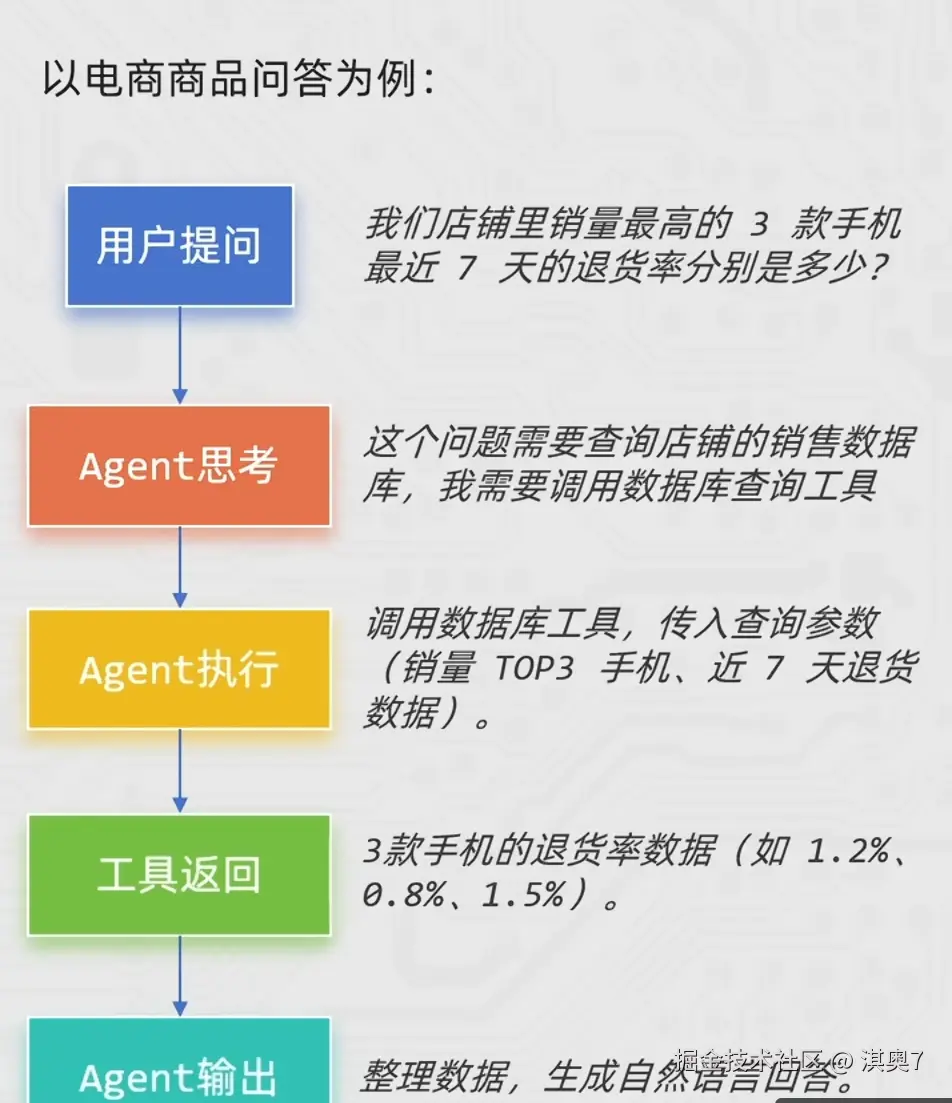
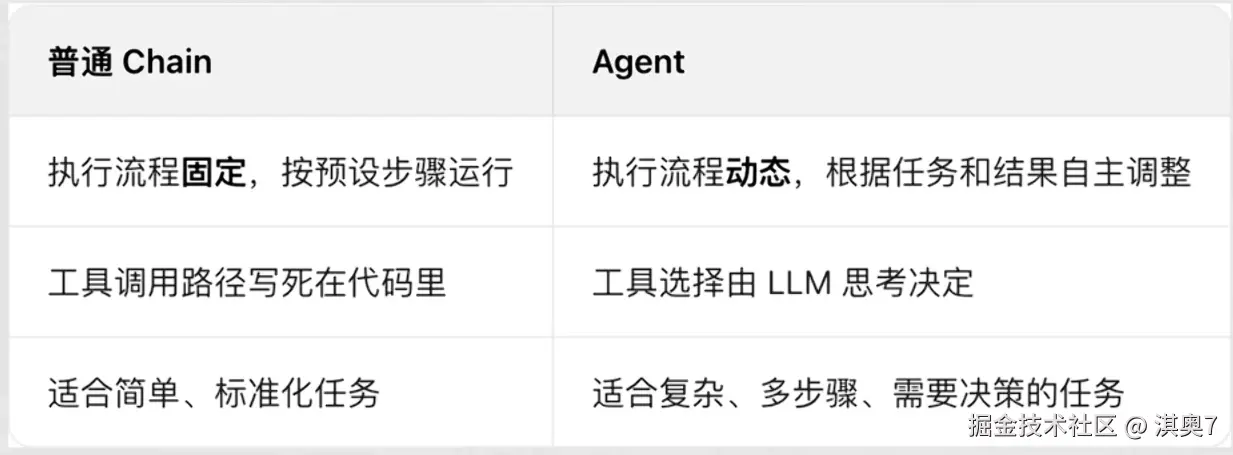
初体验
Python
from langchain.agents import create_agent
from langchain_deepseek import ChatDeepSeek
from langchain_core.tools import tool
@tool(description="查询天气")
def get_weather() -> str:
return "晴天"
agent = create_agent(
model=ChatDeepSeek(model="deepseek-v4-flash"),
tools=[get_weather],
system_prompt="你是一个聊天助手,可以回答用户问题"
)
res = agent.invoke(
{
"messages": [
{"role": "user", "content": "明天太原天气如何?"}
]
}
)
for msg in res["messages"]:
print(type(msg).__name__, msg.content)agent 的流式输出
Python
from langchain.agents import create_agent
from langchain_deepseek import ChatDeepSeek
from langchain_core.tools import tool
@tool(description="获取股票价格")
def get_price(name: str) -> str:
return f"股票{name}价格为20元"
@tool(description="查询股票信息")
def get_info(name: str) -> str:
return f"{name}是一家A股上市的公司,专注于教育"
agent = create_agent(
model=ChatDeepSeek(model="deepseek-v4-flash"),
tools=[get_info, get_price],
system_prompt="""
你是一个股票查询助手,你需要根据用户的指令进行股票查询
""",
)
for chunk in agent.stream(
{"messages":[{"role": "user", "content": "传智教育股价多少?并介绍一下"}]},
stream_mode="values"
):
latest_message = chunk['messages'][-1]
print(latest_message)ReAct
Agent ReAct 是大模型智能体的核心思考与行动框架,全称 Reasoning+Acting(推理+行动),是让Agent 像人 类一样「思考问题→制定策略→执行行动→验证结果」的关键逻辑。
简单来说:ReAct让Agent 不再是"直接回答问题",而是通过"自然语言思考过程"指导工具调用,一步步解决复杂问题,完美适配需要多步推理、工具协作的场景(如智能客服、报告生成、任务规划等)
一个典型的ReAct范式的Agent如图所示:
- 思考Reasoning:分析问题,判断现有信息是否足够,明确下一步
即模型决策是否需要调用外部工具获取更多信息用来回答
- 行动Action:执行思考阶段指定的策略
即基于模型决策结果,调用工具获取信息
- 观察observation:获取行动的结果,提取有效信息
即获取工具返回值即判断工具是否正常工作为下一轮思考提供信息
(再)思考→(再)行动→(再)观察→循环往复直到结束
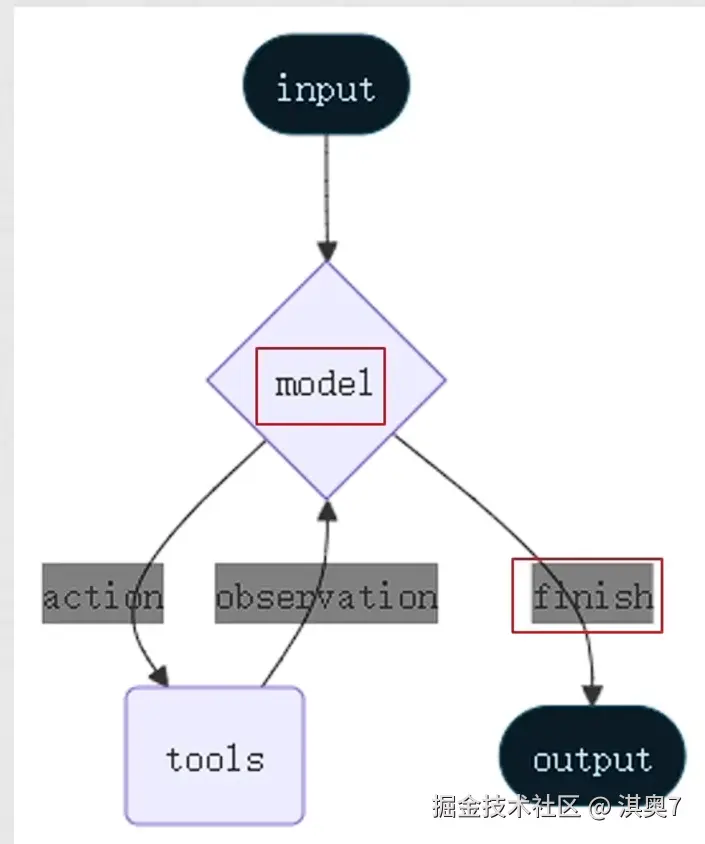
LangChain的Agent对象遵循ReAct框架要求,在执行的过程中会持续的自我思考、自我行动、自我观察。
middleware 中间件
中间件的作用是对智能体的每一步工作进行控制和自定义的执行
作用场景:
- 日志记录、分析、调试
- 转换提示词、工具选择
- 重试、备用、提前终止等逻辑控制
- 安全防护、个人身份检测等
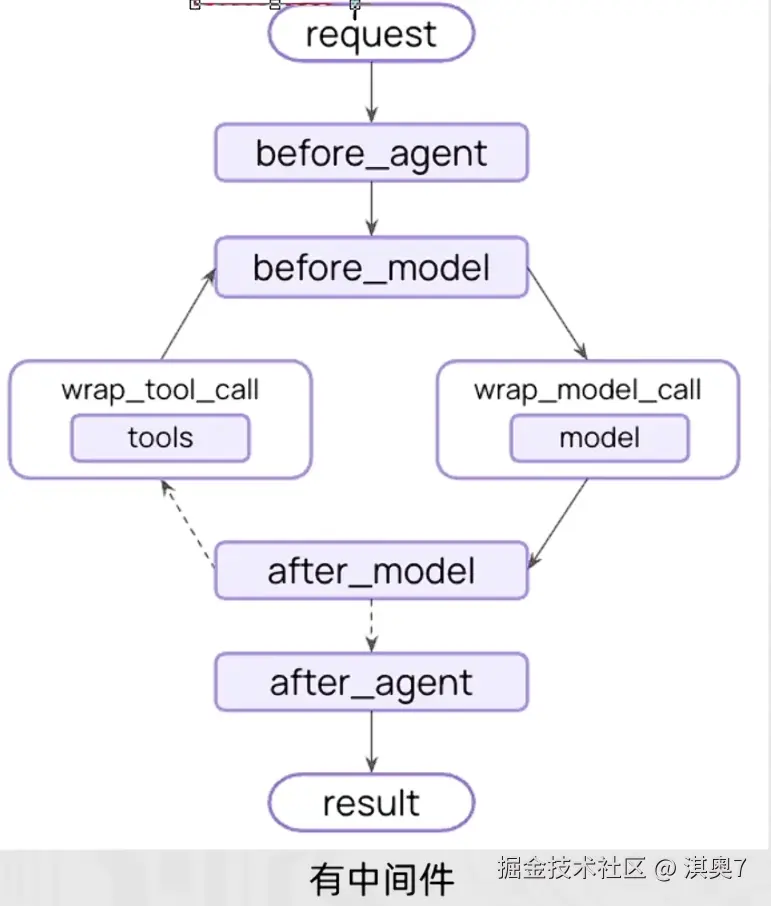
LangChain中内置了一些基础的中间件,参见:docs.langchain.com/oss/python/... 中间件通过Hooks钩子来实现拦截,自定义中间件可以简单的使用装饰器来定义
节点式钩子(执行点顺序拦截):
- before_agent:agent执行之前拦截
- after_agent:agent执行后拦截
- before_model:模型执行前拦截
- after_model:模型执行后拦截
针对工具和模型的包装式钩子
- wrap_model_call:每个模型调用时候拦截
- wrap_tool_call:每个工具调用时候拦截
Python
from langchain.agents import create_agent, AgentState
from langchain_deepseek import ChatDeepSeek
from langchain_core.tools import tool
from langchain.agents.middleware import before_agent, after_agent, before_model, wrap_model_call, after_model, \
wrap_tool_call
from langgraph.runtime import Runtime
@tool(description="查询天气")
def get_weather() -> str:
return "晴天"
"""
agent执行前
agent执行后
model执行前
model执行后
工具执行中
模型执行中
"""
@before_agent
def log_before_agent(state: AgentState, runtime: Runtime) -> None:
# agent执行前会调用这个函数并传入state和runtime两个对象
print(f"[before agent]agent启动,并附带{len(state['messages'])}消息")
@after_agent
def log_after_agent(state: AgentState, runtime: Runtime) -> None:
print(f"[after agent]agent结束,并附带{len(state['messages'])}消息")
@before_model
def log_before_model(state: AgentState, runtime: Runtime) -> None:
print(f"[before_model]模型即将调用,并附带{len(state['messages'])}消息")
@after_model
def log_after_model(state: AgentState, runtime: Runtime) -> None:
print(f"[after_model]模型调用结束,并附带{len(state['messages'])}消息")
@wrap_model_call
def model_call_hook(request, handler):
print("模型调用啦")
return handler(request)
@wrap_tool_call
def monitor_tool(request, handler):
print(f"工具执行:{request.tool_call['name']}")
print(f"工具执行传入参数:{request.tool_call['args']}")
return handler(request)
agent = create_agent(
model=ChatDeepSeek(model="deepseek-v4-flash"),
tools=[get_weather],
middleware=[log_before_agent, log_after_agent, log_before_model, log_after_model, model_call_hook, monitor_tool]
)
res = agent.invoke({"messages": [{"role": "user", "content": "深圳今天的天气如何呀,如何穿衣"}]})
print("**********\n", res)智扫通 Agent 项目
智扫通Agent项目是一个面向消费者(toC)的智能客服系统,旨在为用户提供全周期的扫地机器人相关服务。
(1)智能问答服务:
- 处理购买前的产品咨询(如功能、价格、对比等)。
- 解决购买后的使用问题(如操作指导、故障处理、维护建议等)。
- 基于RAG技术,从知识库中检索准确信息并生成自然语言回答,确保响应及时且可靠。
(2)使用报告与优化建议生成:
- 针对已购买用户,自动分析扫地机器人的使用数据(如清洁频率、耗材状态、错误日志等)。
- 生成个性化报告,总结使用情况并提供优化建议(如清洁计划调整、部件更换提醒等)。
- 支持用户主动查询报告或系统定期推送,帮助用户最大化产品价值。
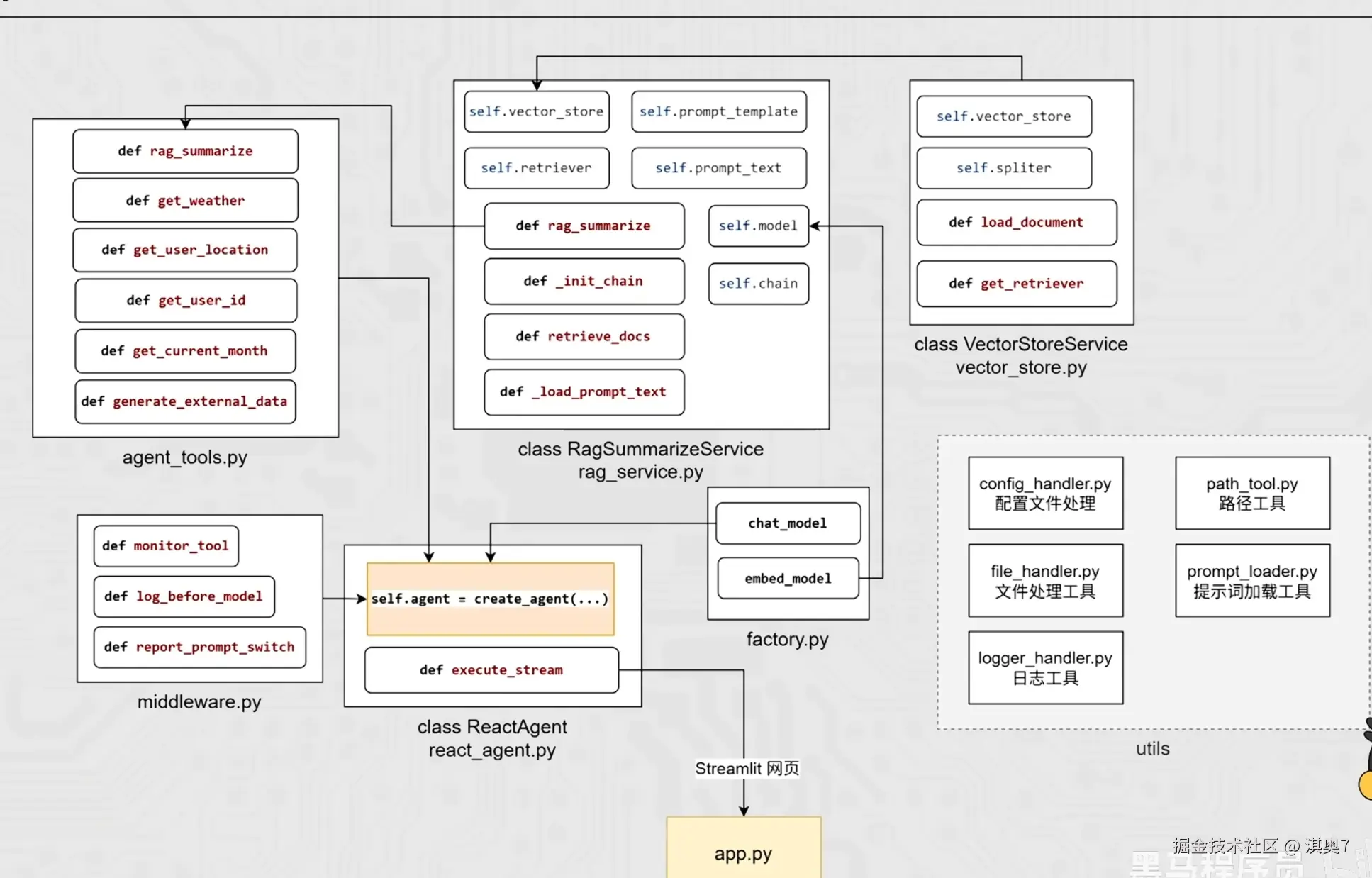
工具类
路径工具
Python
"""
为整个工程提供统一的绝对路径
"""
import os
def get_project_root() -> str:
"""
获取项目根目录
:return: 项目根目录
"""
current_file = os.path.abspath(__file__)
# 获取工程根目录
current_dir = os.path.dirname(current_file)
# 获取项目根目录
project_root = os.path.dirname(current_dir)
return project_root
def get_abs_path(relative_path: str) -> str:
"""
获取绝对路径
:param relative_path: 相对路径
:return: 绝对路径
"""
project_root = get_project_root()
return os.path.join(project_root, relative_path)
if __name__ == '__main__':
print(get_abs_path("config/config.txt"))日志工具类
Python
from datetime import datetime
import logging
import os
from utils.path_tool import get_abs_path
# 日志保存的根目录
LOG_ROOT = get_abs_path("logs")
# 确保日志的目录存在
os.makedirs(LOG_ROOT, exist_ok=True)
# 创建日志目录
DEFAULT_LOG_FORMAT = logging.Formatter(
"%(asctime)s - %(name)s - %(levelname)s - %(filename)s:%(lineno)d - %(message)s"
)
def get_logger(
name: str = "agent",
console_level: int = logging.INFO,
file_level: int = logging.DEBUG,
log_file: str = "agent.log",
) -> logging.Logger:
logger = logging.getLogger(name)
logger.setLevel(logging.DEBUG)
# 避免重复添加Handler
if logger.handlers:
return logger
# 创建控制台Handler
console_handler = logging.StreamHandler()
console_handler.setLevel(console_level)
console_handler.setFormatter(DEFAULT_LOG_FORMAT)
logger.addHandler(console_handler)
# 文件handler
if not log_file:
log_file = os.path.join(LOG_ROOT, f"{name}_{datetime.now().strftime('%Y-%m-%d')}.log")
file_handler = logging.FileHandler(log_file, encoding="utf-8")
file_handler.setLevel(file_level)
file_handler.setFormatter(DEFAULT_LOG_FORMAT)
logger.addHandler(file_handler)
return logger
# 快捷获取日志器
logger = get_logger()
if __name__ == "__main__":
logger.debug("调试日志")
logger.info("信息日志")
logger.warning("警告日志")
logger.error("错误日志")