1.提示词模板
1.1定义
当需要动态、批量、或有结构地向⼤语⾔模型【发送请求】的地⽅,⼏乎都会⽤到提⽰词模板。我们可以将重复的部分形成一个框架模板,我们只需要将核心字段进行实例化从而达到目的。
例如:
我们想根据⼀个城市名询问 LLM 其历史,按照之前的做法,我们可以定义
HumanMessage("请介绍上海的历史") 、 HumanMessage("请介绍西安的历史") 消息等等。可 以发现每次询问都会描写重复的消息内容: 请介绍xxx的历史
所以有以下模板:
提示词模板作用:(1)避免重复性动作:: 只需定义⼀个模板,就可以⽤于⽆数个类似的查询;
(2)将提示词逻辑的构建和具体的内容数据解耦合;
(3)用固定统一的模板保证输出的稳定性和可预测性
(4)便于整个提示词的维护工作

1.2用法
1.2.1字符串模板 PromptTemplate
形式1
python
prompt_template = PromptTemplate(
input_variables=["language1", "language2"],
template="Please translate {language1} to {language2}",
)
形式2
除去上面的标准写法,我们还可以使用PromptTemplate的内置方法from_template()进行简写

python
prompt_template = PromptTemplate.from_template("Please translate {language1} to {language2}")
1.2.2聊天消息模板 ChatPromptTemplate
除了字符串替换模板,对于LLM中常用的聊天模板,LangChain专门设计了ChatPromptTemplate 模板,帮助我们形成我们前面的消息列表
可以⽅便地构建包含 SystemMessage 、 HumanMessage 、 AIMessage 的消息模板
python
#构建模板
chat_template = ChatPromptTemplate(
[
("system","Please translate {language1} to {language2}"), #系统提示词
("user","{text}"), #用户输入
]
)
#填充消息列表
messages = chat_template.invoke(
{
"language1": "English",
"language2": "Chinese",
"text": "hi,how are you today?",
}
)
print(messages)
LLM调用
由于模板生成的是Runnable实例所以我们可以构建链进行LLM调用
python
import os
from langchain_core.prompts import PromptTemplate, ChatPromptTemplate
from langchain_openai import ChatOpenAI
model = ChatOpenAI(
model = "deepseek-v4-flash",
api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url=os.getenv("DEEPSEEK_BASE_URL"),
)
#聊天消息模板
#构建模板
chat_template = ChatPromptTemplate(
[
("system","Please translate {language1} to {language2}"), #系统提示词
("user","{text}"), #用户输入
]
)
chain = chat_template | model
chain.invoke(
{
"language1": "English",
"language2": "Chinese",
"text": "hi,how are you today?",
}
).pretty_print()
1.2.3消息占位符 MessagesPlaceholder
在上⾯的 ChatPromptTemplate 中,我们看到了如何格式化两条消息,每条消息都是⼀个字符串。但如果我们希望将消息插⼊特定位置怎么办?使⽤ MessagesPlaceholder
形式1显式
python
#消息占位符
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.messages import HumanMessage, AIMessage
prompt_template = ChatPromptTemplate(
[
("system", "你是⼀个聊天助⼿"),
MessagesPlaceholder("msgs") # 消息占位符
]
)
messages_to_pass = [
HumanMessage(content="中国⾸都是哪⾥?"),
AIMessage(content="中国⾸都是北京。"),
HumanMessage(content="那法国呢?")
]
formatted_prompt = prompt_template.invoke({"msgs": messages_to_pass})
print(formatted_prompt)形式2隐式
python
prompt_template = ChatPromptTemplate(
[
("system", "你是⼀个聊天助⼿"),
("placeholder", "{msgs}"),
]
)LLM调用
python
prompt_template = ChatPromptTemplate(
[
("system", "你是⼀个聊天助⼿"),
("placeholder", "{msgs}"),
]
)
messages_to_pass = [
HumanMessage(content="中国⾸都是哪⾥?"),
AIMessage(content="中国⾸都是北京。"),
HumanMessage(content="那法国呢?")
]
# formatted_prompt = prompt_template.invoke({"msgs": messages_to_pass})
# print(formatted_prompt)
chain = prompt_template | model
chain.invoke(
{
"msgs": messages_to_pass,
}
).pretty_print()
2.少样本提示 few-shotting
使用LLM时,在某些复杂情况下仅有提示词还是不够的,这时我们可以为大模型提供一些案例进行学习,从而更好的达到我们期望的结果。
比如:
- 强制要求模型以特定的格式(如JSON、XML、特定的列表样式)输出结果。样例可以当作格式样板。
- 有些任务很难⽤⽂字指令清晰描述(例如:"请⽤莎⼠⽐亚的⻛格写作")。提供⼏个例⼦⽐写⻓ 篇⼤论的指令更有效。
- 对于需要多步推理的复杂任务,⽰例可以展⽰出思考链,引导模型遵循类似的推理路径。
2.1定义
少样本提⽰是⼀种通过向 LLM 提供少量具体⽰例或样本,来教会它如何执⾏某项特定任务的技术。提⾼模型性能的最有效⽅法之⼀是给出⼀个【模型⽰例】指导⼤模型你想做什么、怎么做。
2.2实现少样本提示
对于 LangChain 就需要创建⼀个FewShotChatMessagePromptTemplate 对象来实例化⽰例集
FewShotChatMessagePromptTemplate 类对象含有两个参数:
examples:样本实例
example_prompt:ChatPromptTemplate,⽤于格式化单个⽰例
返回的也是一个Runnable实例,所以可以使用常见类方法:
.invoke() ⽅法:此⽅法与其他 Runnable 实例的 .invoke() ⽅法类似。输⼊⼀个字典给
它,返回完整的提⽰内容 PromptValue :
PromptValue 的 to_string() ⽅法可以将提⽰值作为【字符串】返回。
PromptValue 的 to_messages() ⽅法可以将提⽰作为【消息列表】返回。
从而形成含有示例的消息列表传给LLM进行学习使用。
构建含示例集的模板
python
examples = [
{"input": "2 🦜 2", "output": "4"},
{"input": "2 🦜 3", "output": "5"},
]
example_prompt = ChatPromptTemplate(
[
("human","{input}"),
("ai","{output}"),
]
)
few_shot_template = FewShotChatMessagePromptTemplate(
examples=examples,
example_prompt=example_prompt,
)
print(few_shot_template.invoke({}).to_messages())形成消息列表

向LLM发送请求
python
final_prompt = ChatPromptTemplate(
[
("system","你是一个数学推理计算学者。"),
few_shot_template,
("human","{input}"),
]
)
chain = final_prompt | model
chain.invoke({"input": "2 🦜 9"}).pretty_print()
3.示例选择器
当我们不断补充案例集合去完成一个大型项目时,超出大模型限制的案例会导致不可控 的幻觉,混淆问题,从而使效果愈加降低。为了合理高效利用案例,LangChain按照不同的策略进行示例选择,保证结果的稳定性。
在定义少量样本提示时,我们会构建示例集合传给模板构成消息列表,在示例选择器这里就是在其基础上将样本传入时将样本传给选择器后再导入进模板里。
策略类型
3.1长度 LengthBasedExampleSelector
实现按⻓度选择⽰例的⽰例选择器是:
class langchain_core.example_selectors.length_based.LengthBasedExampleSelector 类,其参数如下:
example_prompt :PromptTemplate,⽤于格式化⽰例的提⽰模板。
examples :模板所需的⽰例列表。
max_length :提⽰的最⼤⻓度,超过该⻓度将剪切⽰例。
get_text_length :测量提⽰⻓度的⽅法。默认为字数统计。
内置⽅法:
add_example(example: dictstr, str) :将新⽰例添加到列表中。
输⼊:⼀个字典,其中键作为输⼊变量,值作为其值。
select_examples(input_variables: dictstr, str) **→**listdict :
根据输⼊⻓度选择要使⽤的⽰例。
输⼊:⼀个字典,其中键作为输⼊变量,值作为其值。
输出:要包含在提⽰中的⽰例列表。
python
# 长度Length
# 反义词⽰例集合
# 示例集合
examples = [
{"input": "happy", "output": "sad"},
{"input": "tall", "output": "short"},
{"input": "energetic", "output": "lethargic"},
{"input": "sunny", "output": "gloomy"},
{"input": "windy", "output": "calm"},
]
# 提示词模板
example_prompt = PromptTemplate.from_template("Input:{input}\nOutput:{output}")
# 定义长度选择器
examples_selector = LengthBasedExampleSelector(
examples=examples,
example_prompt=example_prompt,
# 格式化⽰例的最⼤⻓度。
# ⻓度由下⾯的get_text_length函数测量。
max_length=6,
# ⽤于获取字符串⻓度的函数,⽤于确定包含哪些⽰例。
# 如果没有指定,它是作为默认值提供的。
# 该函数返回⼀个整数,表⽰字符串中由换⾏符或空格分隔的"单词"数量
# get_text_length: Callable[[str], int] = lambda x: len(re.split("\n| ",x))
)
# 定义少样本提示
few_shot_prompt = FewShotPromptTemplate(
example_selector=examples_selector, #将示例集切换为选择器
example_prompt=example_prompt,
prefix="给出每个输入的反义词",
suffix="Input:{adjective}\nOutput:",
input_variables=["adjective"],
)
print(few_shot_prompt.invoke({"adjective": "big"}).to_messages()[0].content)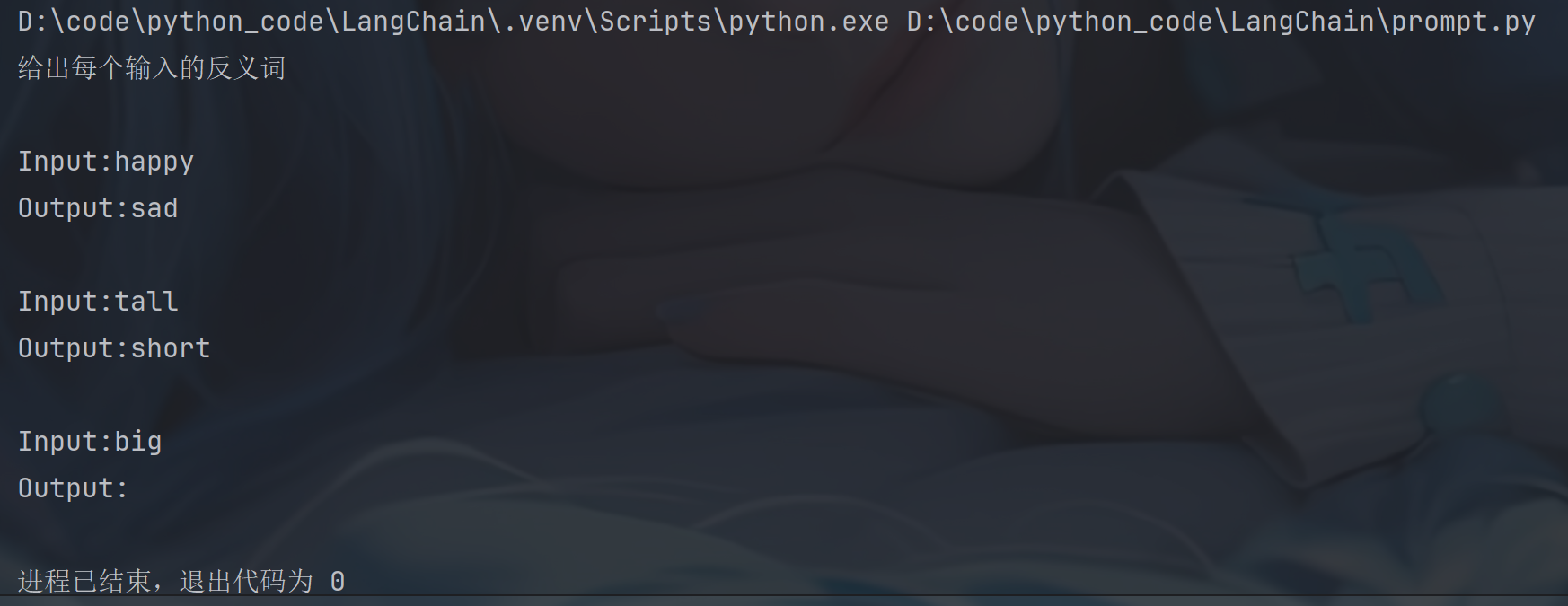
3.2语义相关性 SemanticSimilarityExampleSelector
LLM有一个概念是将字符串转化为向量,通过向量的余弦相关性进行语义的近似匹配。
LangChain 能根据输⼊和⽰例之间的语义相似性来决定选择哪些⽰例,它通过查找与输⼊具有最⼤余弦相似性的嵌⼊⽰例来实现这⼀点
实现按语义相似性选择⽰例的⽰例选择器是:
class langchain_core.example_selectors.semantic_similarity.SemanticSimilarity ExampleSelector 类,
内置⽅法:
from_examples() :根据⽰例集⽣成语义相似⽰例选择器
输⼊:
examples :⽰例列表
embeddings :初始化的嵌⼊ API 接⼝,如 OpenAIEmbeddings()
vectorstore_cls :向量存储数据库接⼝类。
k :最终要选择的⽰例的数量。默认值为 4。
输出:语义相似性⽰例选择器
add_example(example: dictstr, str) :将新⽰例添加到列表中。
输⼊:⼀个字典,其中键作为输⼊变量,值作为其值。
select_examples(input_variables: dictstr, str) **→**listdict :
根据输⼊选择要使⽤的⽰例。
输⼊:⼀个字典,其中键作为输⼊变量,值作为其值。
输出:要包含在提⽰中的⽰例列表。
python
# 定义语义相关性选择器
examples_selector = SemanticSimilarityExampleSelector.from_examples(
examples, #示例集
OpenAIEmbeddings(model = "text-embedding-3-large"), # 嵌⼊类⽤于⽣成⽤于度量语义相似度的嵌⼊。
Chroma, # 向量库存储向量。
k=1, # ⽣成⽰例的数量。
)3.3最大边际相关性 MaxMarginalRelevanceExampleSelector
MMR是一种基于语义相关性的重排算法,对语义相关性得到的分组进行去重排序,从⼀个候选集中 挑选出⼀组既能代表查询主题⼜彼此多样化的结果。
LangChain 提供了按最⼤边际相关性选择⽰例的能⼒,该⽰例选择器是:
class langchain_core.example_selectors.semantic_similarity.MaxMarginalRelevan
ceExampleSelector 类,
内置⽅法:
from_examples() :根据⽰例集⽣成 MMR ⽰例选择器
输⼊:
examples :⽰例列表
embeddings :初始化的嵌⼊ API 接⼝,如 OpenAIEmbeddings()
vectorstore_cls :向量存储数据库接⼝类。
▪
k :最终要选择的⽰例的数量。默认值为 4。
输出:MMR ⽰例选择器
add_example(example: dictstr, str) :
将新⽰例添加到列表中。
输⼊:⼀个字典,其中键作为输⼊变量,值作为其值。
select_examples(input_variables: dictstr, str) **→**listdict :
根据输⼊选择要使⽤的⽰例。
输⼊:⼀个字典,其中键作为输⼊变量,值作为其值。
输出:要包含在提⽰中的⽰例列表

python
# 定义最大边际选择器
# 就是对语义相关习性的排序,代码不变
examples_selector = MaxMarginalRelevanceExampleSelector.from_examples(
examples, #示例集
OpenAIEmbeddings(model = "text-embedding-3-large"), # 嵌⼊类⽤于⽣成⽤于度量语义相似度的嵌⼊。
Chroma, # 向量库存储向量。
k=2, # ⽣成⽰例的数量。
)3.4语义ngram 重叠
传统的Ngram重叠是两个词或两句话重合的字母或单词的数目的多少从而判断两者是否近似
但这种面对同义词替换后就有点问题,导致判断失误
所以有了语义Ngram重叠,⽐较词背后的语义向量(Embedding)来判断是否近似
语义 ngram 重叠常⽤于需要更精准语义评估的场景,例如剽窃检测 , 能够发现那些改换了词汇但保留了核⼼思想的"智能"剽窃。
LangChain 实现按语义 ngram 重叠选择⽰例的⽰例选择器是:
class
langchain_community.example_selectors.ngram_overlap.NGramOverlapExample
Selector 类,其参数如下:
example_prompt :PromptTemplate,⽤于格式化⽰例的提⽰模板。
examples :模板所需的⽰例列表。
threshold :算法停⽌的阈值。默认设置为 -1.0。
对于负阈值:按 重叠分数 对⽰例进⾏排序,但不排除任何⽰例。
对于等于 0.0 的阈值:按 重叠分数 进⾏排序,并排除与输⼊没有 ngram 重叠的⽰例。
对于⼤于 1.0 的阈值:排除所有⽰例,并返回⼀个空列表。
内置⽅法:
add_example(example: dictstr, str) :将新⽰例添加到列表中。
输⼊:⼀个字典,其中键作为输⼊变量,值作为其值。
select_examples(input_variables: dictstr, str) **→**listdict :
返回 根据输⼊得到的重叠分数排序的降序⽰例列表。
输⼊:⼀个字典,其中键作为输⼊变量,值作为其值。
输出:要包含在提⽰中的⽰例列

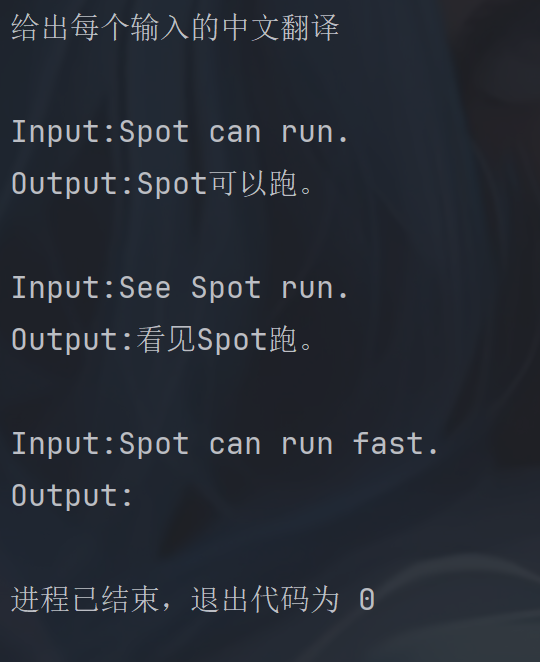
python
examples = [
{"input": "See Spot run.", "output": "看⻅Spot跑。"},
{"input": "My dog barks.", "output": "我的狗叫。"},
{"input": "Spot can run.", "output": "Spot可以跑。"},
]
# 提示词模板
example_prompt = PromptTemplate.from_template("Input:{input}\nOutput:{output}")
examples_selector = NGramOverlapExampleSelector(
examples=examples,
example_prompt=example_prompt,
threshold=-1.0,
# 对于负阈值:按 [重叠分数] 对⽰例进⾏排序,但不排除任何⽰例。
# 对于等于 0.0 的阈值:按 [重叠分数] 进⾏排序,并排除与输⼊没有 ngram 重叠的⽰例。
# 对于⼤于 1.0 的阈值:排除所有⽰例,并返回⼀个空列表。
)
few_shot_prompt = FewShotPromptTemplate(
example_selector=examples_selector, #将示例集切换为选择器
example_prompt=example_prompt,
prefix="给出每个输入的中文翻译",
suffix="Input:{sentence}\nOutput:",
input_variables=["sentence"],
)
print(few_shot_prompt.invoke({"sentence": "Spot can run fast."}).to_messages()[0].content)threshold = -1.0
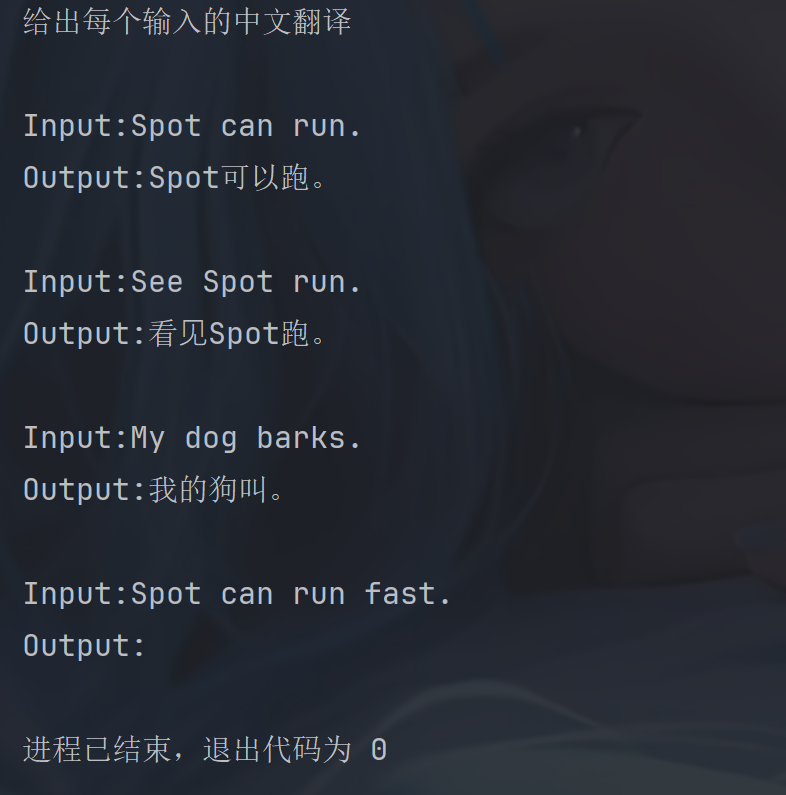
threshold=1.0
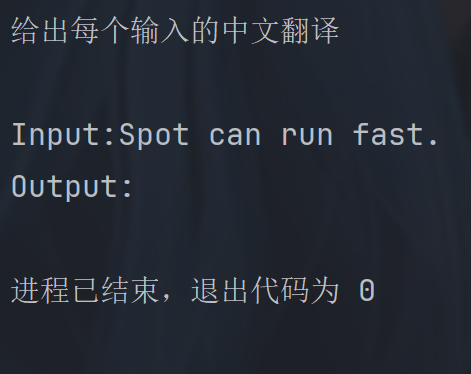
threshold=0.0