问题
最近需要将AWS Catalog数据库中的数据,进行清洗到另外一个AWS Catalog中。
解决
创建目标数据库
bash
CREATE DATABASE dev_xxx_silver;这里使用bronze (raw), silver (validated) and gold (enriched)这种大数据架构,进行命名的。这里是直接使用AWS Athena创建的数据库,AWS Athena创建数据库不支持连字符 (-)。
创建目标S3桶
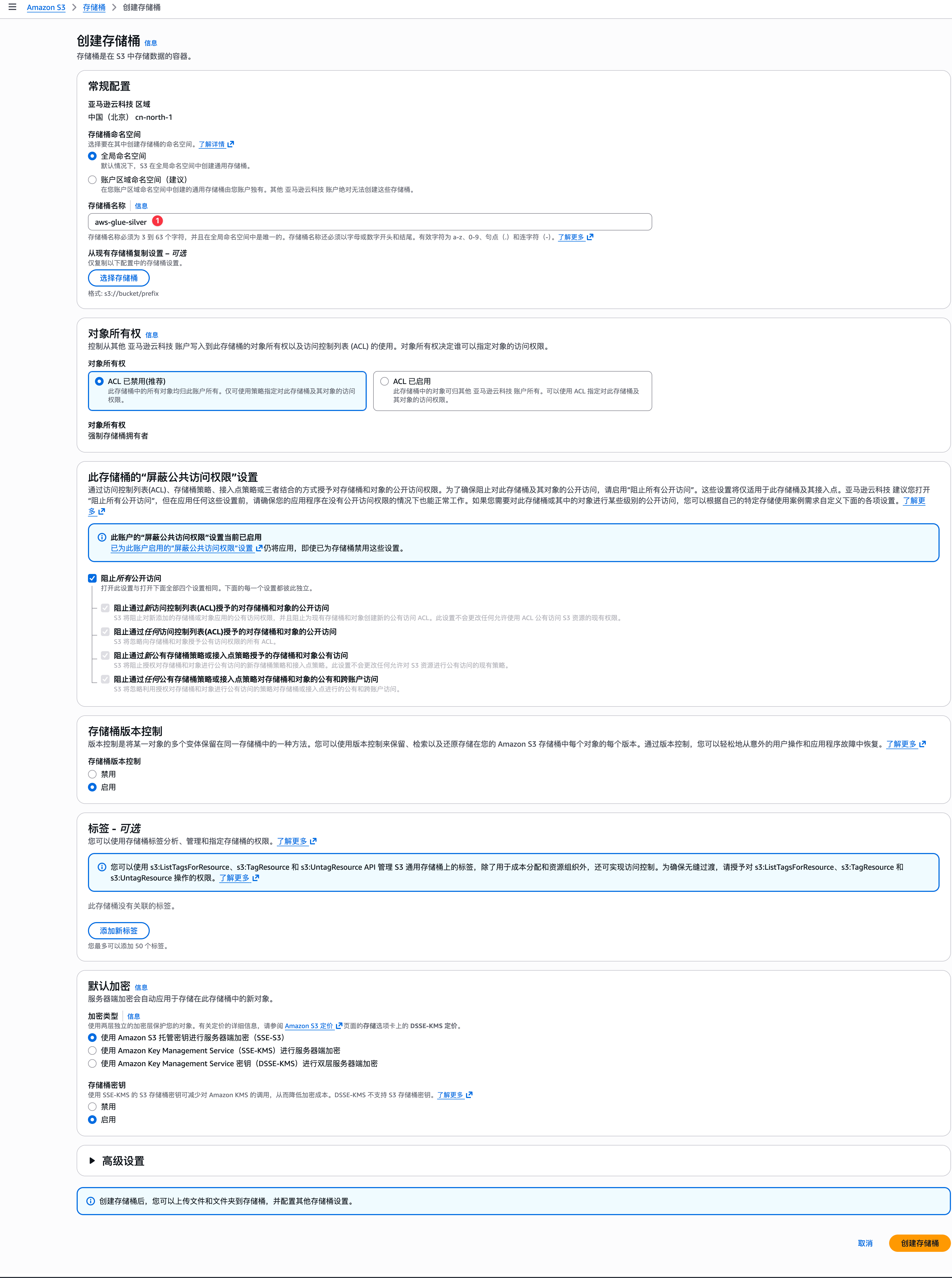
创建目标表
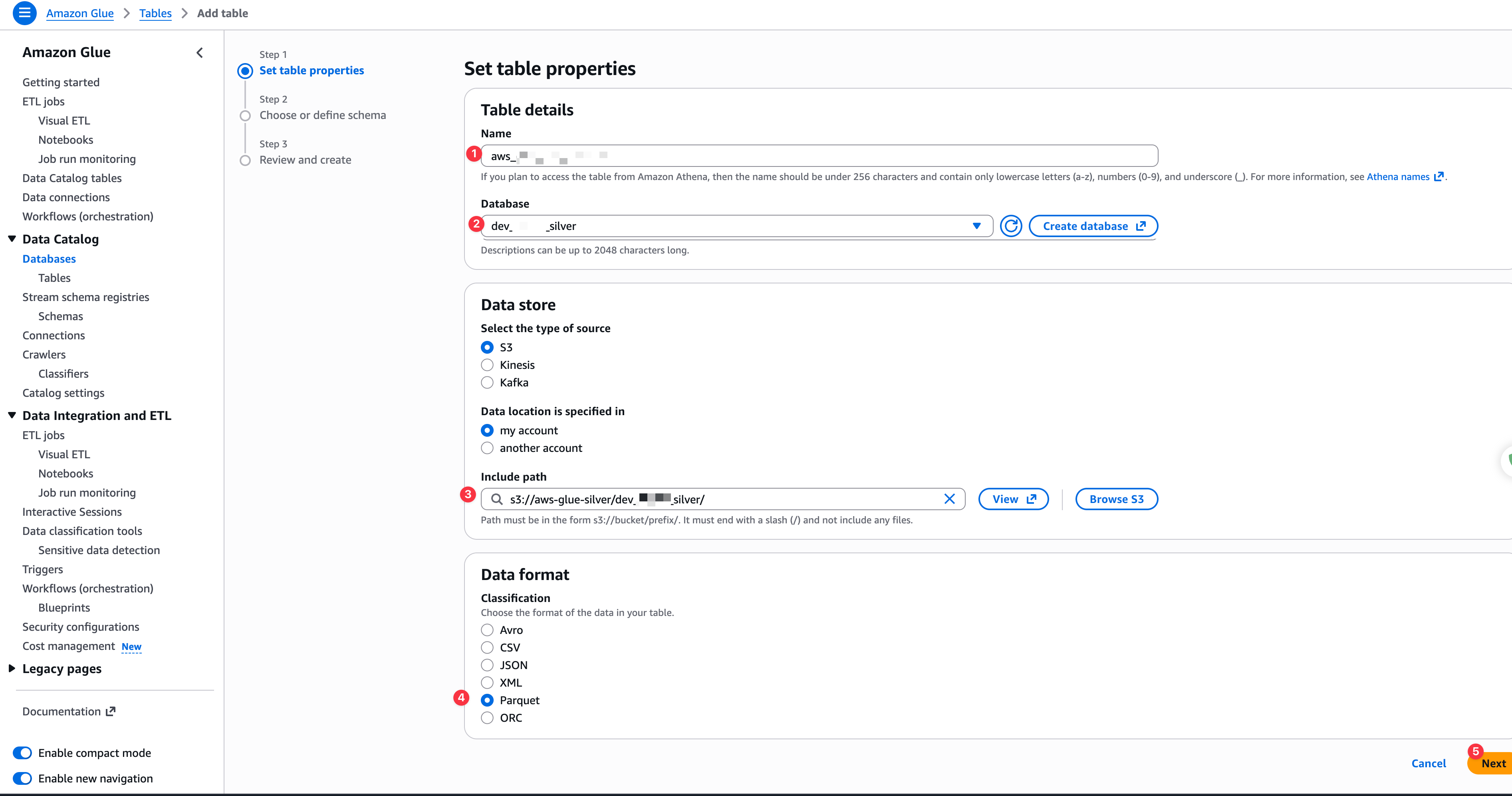
可以不用设置字段有哪些,如下图:
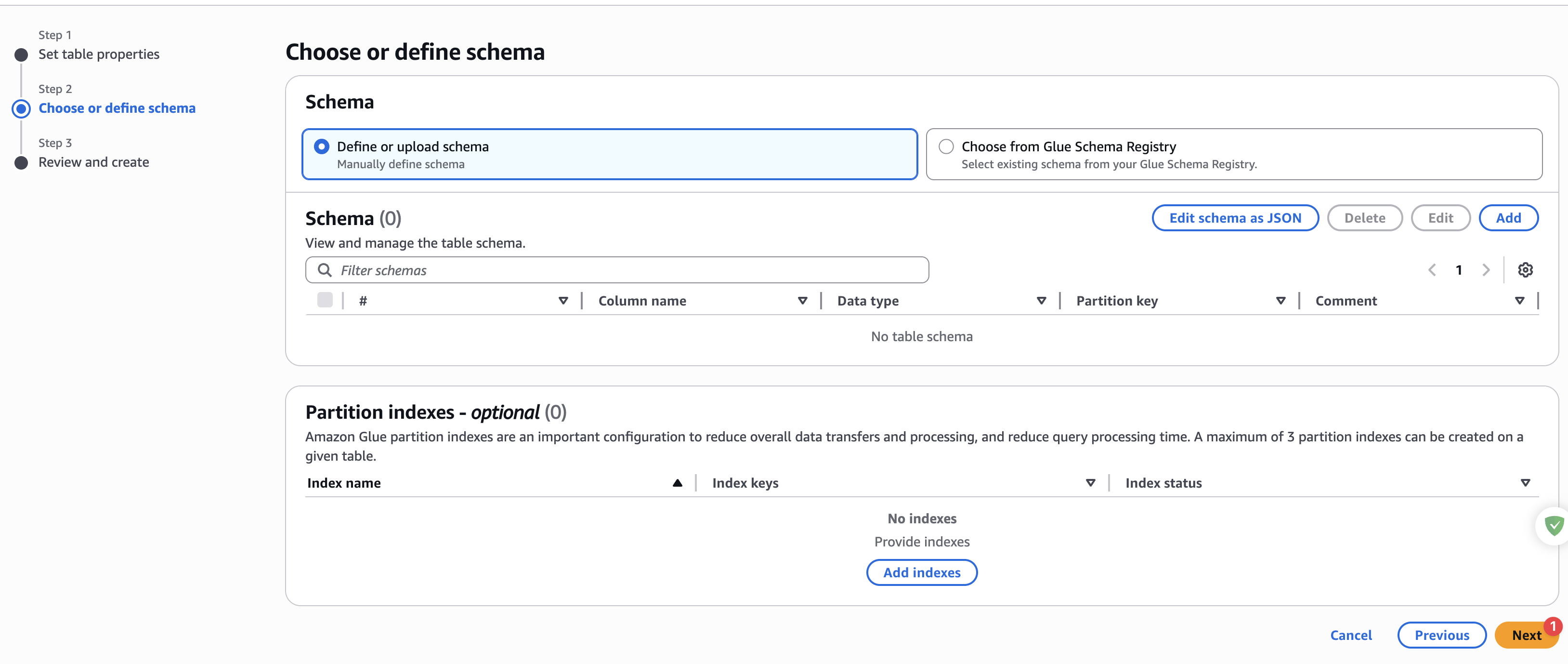
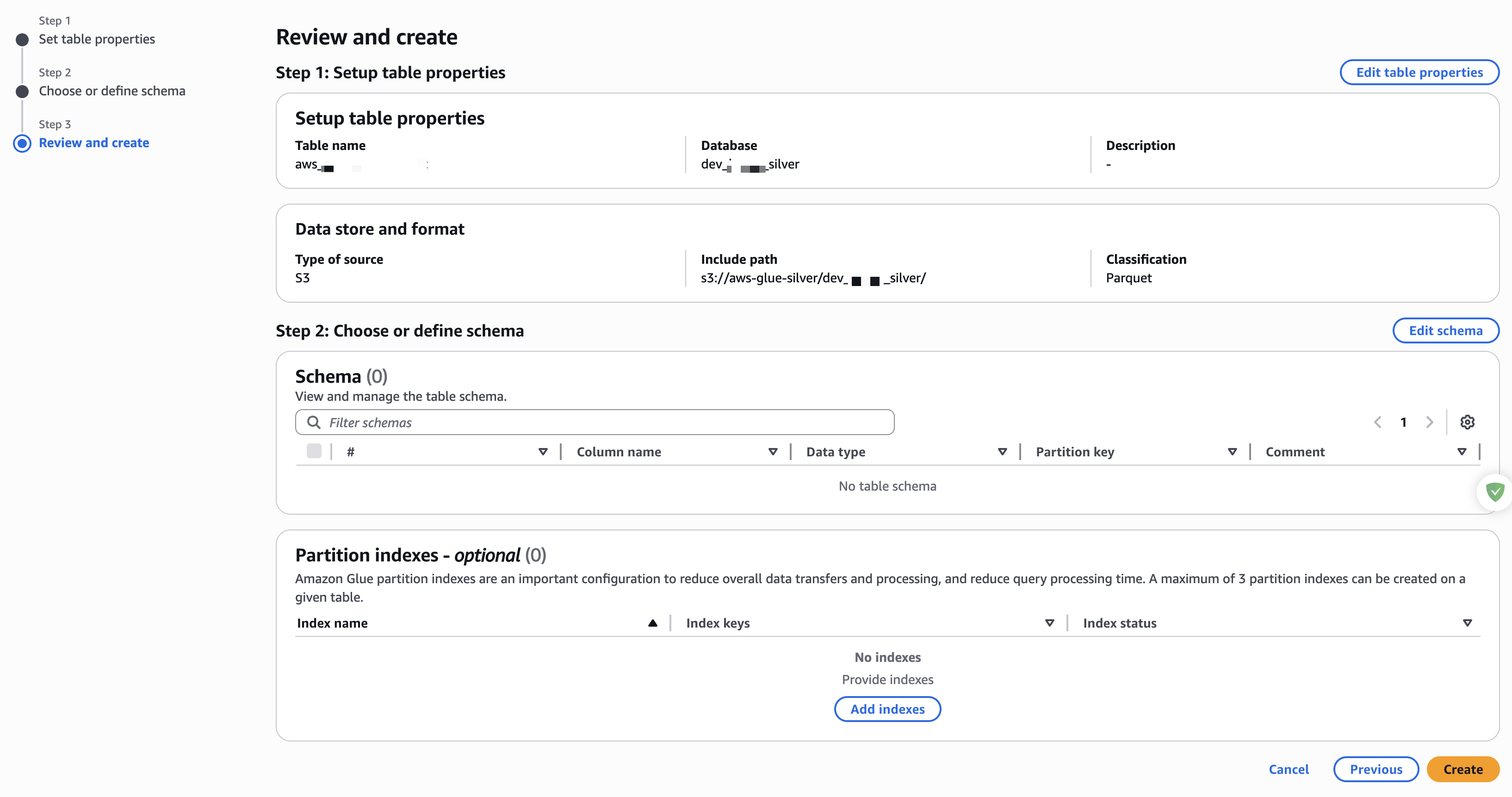
表创建成功之后,还需要设置表属性,如下图:
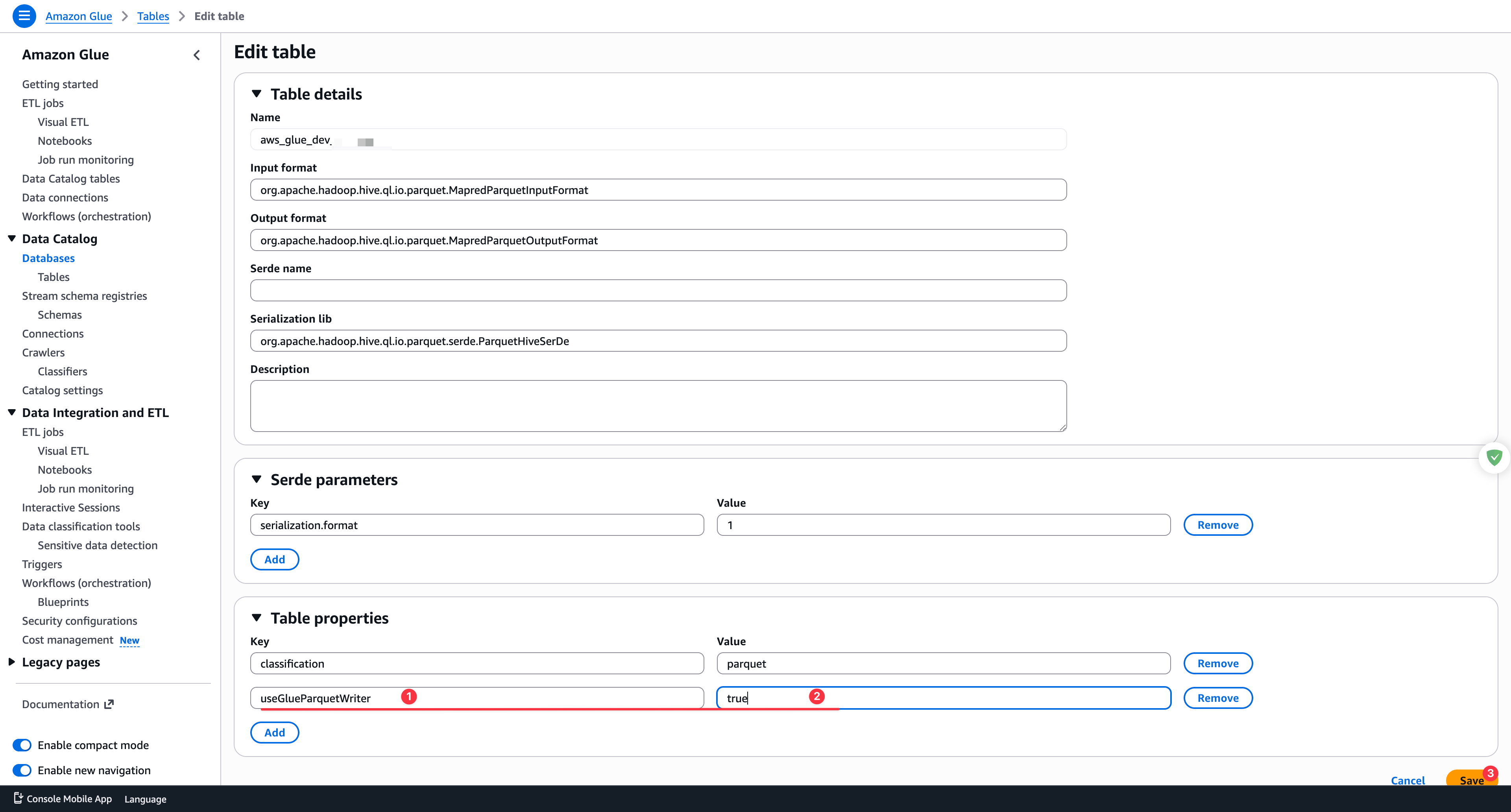
设置表属性,如下:
useGlueParquetWriter:true
AWS Glue PySpark 任务
python
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from awsglue.dynamicframe import DynamicFrame
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
## @params: [JOB_NAME]
args = getResolvedOptions(sys.argv, ['JOB_NAME', 'SOURCE_DB_NAME', 'SOURCE_TABLE_NAME', 'TARGET_DB_NAME', 'TARGET_TABLE_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
# 1. 从第一个 Catalog 表加载数据
source_dyf = glueContext.create_dynamic_frame_from_catalog(
database = args['SOURCE_DB_NAME'],
table_name = args['SOURCE_TABLE_NAME']
)
# 2. 转换与过滤 (转换为 Spark DataFrame 处理更方便)
df = source_dyf.toDF()
filtered_df = df.filter("year = 2026 AND month = 4 AND day = 20") # 指定日期
# 3. 写回到另一个 Catalog 表
# 转回 DynamicFrame
target_dyf = DynamicFrame.fromDF(filtered_df, glueContext, "target_dyf")
# 4. 写入目标 Catalog 数据库和表
glueContext.write_dynamic_frame_from_catalog(
frame = target_dyf,
database = args['TARGET_DB_NAME'], # 你的新库名
table_name = args['TARGET_TABLE_NAME'],
additional_options = {
"enableUpdateCatalog": True,
"updateBehavior": "UPDATE_IN_DATABASE",
"partitionKeys": ["year", "month", "day"] # 如果你有分区字段(如日期),建议加上
},
transformation_ctx = "write_ctx"
)
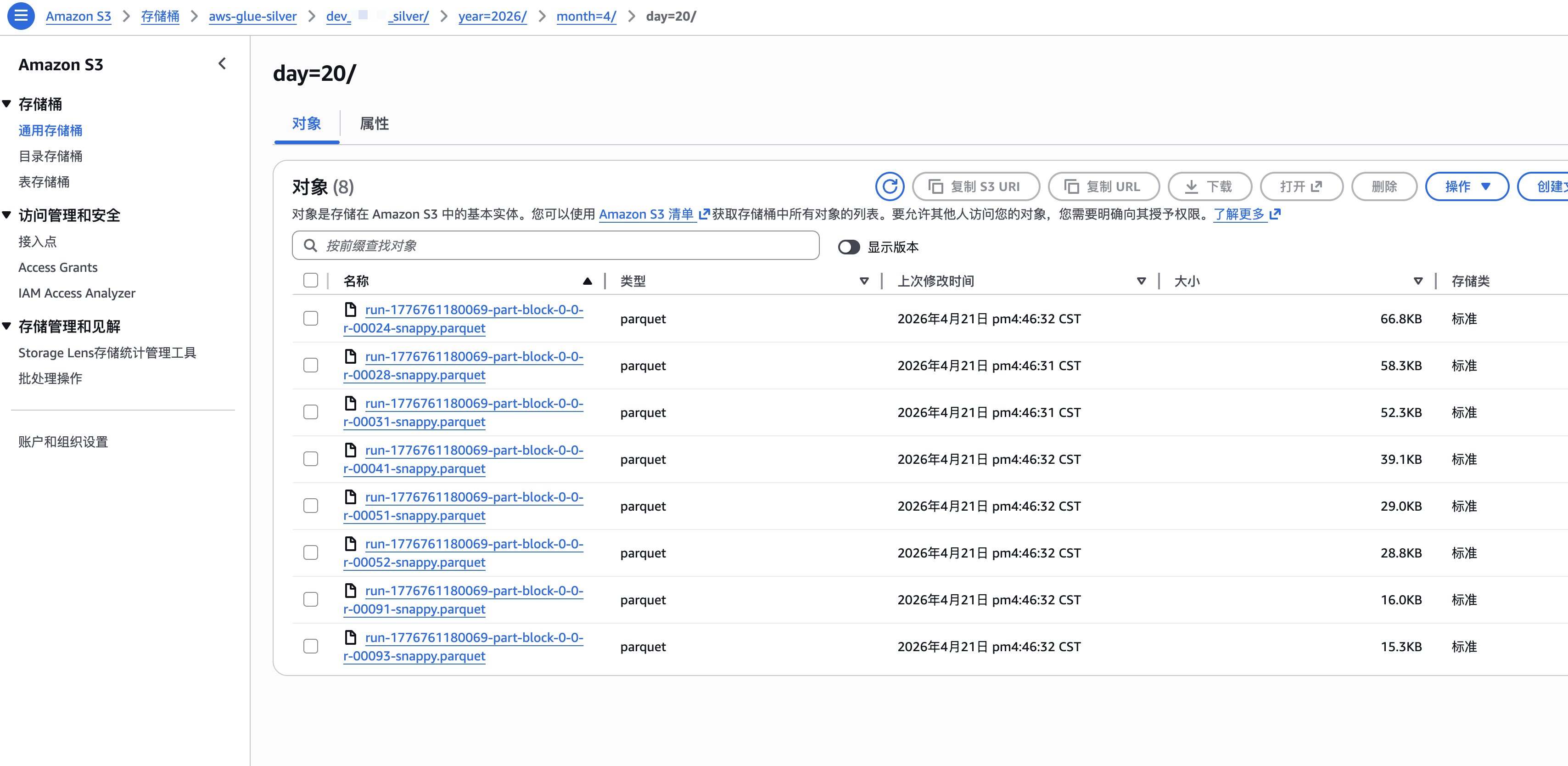
job.commit()效果

s3中的文件:
总结
青铜,白银,黄金。算是大数据里面的三层架构了。有云作为支撑,普通人使用大数据还是比较容易的,只是公司用云有点贵。