假设我们有一个 Point3d 指针和对象:
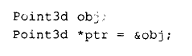
问题在于,当我们写下:

时,实际会发生什么?其中 Point3d::normalize() 的实现如下:


而 Point3d::magnitude() 的实现为:

答案是:我们尚不得而知。C++ 支持三类成员函数:静态、非静态和虚函数。三者的调用方式各不相同,这些差异正是下一节要讨论的主题(小测验一则:尽管我们无法断言 normalize() 和 magnitude() 究竟是虚函数还是非虚成员,但可以放心地将它们排除在静态函数之外,因为这两者(a)都直接访问了非静态的坐标数据成员,(b)且均声明为 const 成员。静态成员函数既不允许直接访问非静态数据,也不能带有 const 限定)。
4.1 成员的各种调用方式
历史上看,最初的"带类的 C"(C with Classes)仅支持非静态成员函数(关于该语言的首次公开描述,请参阅 STROUP82)。虚函数于 20 世纪 80 年代中期被引入,且显然遭到了不少质疑(部分质疑之声在 C 社区中至今犹存)。Bjarne 在 STROUP94 中写道:当时一种普遍的观点是,虚函数不过是一种功能受限的函数指针,因而纯属多余......于是,按此论点,虚函数无非是一种低效的表现形式罢了。
静态成员函数则是最后引入的。它们于 1987 年 Usenix C++ 大会的实现者研讨会上被正式提上议程,并随 cfront 2.0 版本一同问世。
非静态成员函数
C++ 的一项设计准则是:非静态成员函数至少在效率上必须与其功能对等的非成员函数相当。也就是说,如果让我们在以下两者之间做出选择:

选用成员函数版本不应带来任何额外开销。这一目标是通过在内部将成员函数实例转换为等价的非成员函数实例来实现的。
例如,下面是 magnitude() 的一个非成员函数实现:

单从表面上看,非成员版本似乎效率稍逊一筹------它需要通过参数间接访问坐标成员,而成员版本则是直接访问。然而在实际编译中,成员函数会在内部被转换为与上述非成员函数等价的形式。下面列出成员函数的转换步骤:
1.改写函数签名,为成员函数额外添加一个参数,用以指代调用该函数的类对象。这就是所谓的隐式 this 指针:

若成员函数带有 const 限定,则签名变为:

2.改写函数体内对非静态数据成员的直接访问,将其改为通过 this 指针进行访问:

3.将成员函数改写为外部函数,并对其名称进行修饰(mangling),以保证该名称在整个程序中具有唯一性:

既然函数本身已被转换,那么它的每一次调用也必然需要相应转换。因此:

变成了:
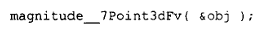
而:
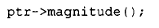
变成了:
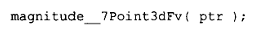
normalize() 函数在内部会被转换成类似下面这样的形式,这里假定已声明 Point3d 的拷贝构造函数,并且应用了具名返回值(NRV)优化(关于 NRV 优化的讨论请参见第 2.3 节):

一种稍高效些的normalize方法的实现方式是直接构造 normal 局部对象,如下所示:

该实现会在内部转换为类似下面这样的形式(同样假设 Point3d 的拷贝构造函数已声明,并应用了 NRV 优化):

这样做省去了先执行默认构造函数初始化、随后又被覆写的额外开销。
名称的特殊处理(Name Mangling,也可称为名称修饰)
通常,成员名称的唯一性是通过将成员名与类名拼接在一起来实现的。例如,给定以下声明:
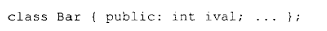
ival 会变成类似这样的名称:

编译器为什么要这样做呢?考虑以下派生关系:
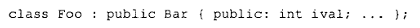
请记住,Foo 对象的内部表示是其基类成员与派生类成员的拼接:

通过名称修饰,我们就能无歧义地访问到任意一个 ival 成员。至于成员函数,由于它们可以被重载,因此需要更为精细的修饰手段,以便为每一个重载版本赋予独一无二的名称。
将:

转换为:

这种处理方式最终会为那两个重载实例生成相同的名称。真正让这些实例具备唯一性的,是它们的参数列表(即函数签名)。编译器通过内部编码函数签名中的类型信息,并将编码后的结果拼接到函数名上,来为函数生成唯一的名称(使用 extern "C" 声明可以抑制对非成员函数的名称修饰,该声明告诉编译器,这一段代码按C语言的规则处理)。这样一来,那对 x() 成员函数的转换结果就变得更切实可行了:

在向您展示了这套具体的编码方案(即 cfront 内部所采用的方案)之后,现在我得坦白说,目前业界在编码方案上并没有达成统一的规范,尽管旨在制定行业标准的种种努力时有起伏。不过,虽然具体细节因编译器实现而异,但名称修饰本身却是每一个 C++ 编译器都不可或缺的组成部分。
通过在函数名中编码参数列表,编译器在分别编译的多个模块之间实现了一种有限形式的类型检查。例如,假设有一个 print 函数定义如下:
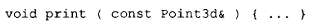
却不慎被声明并调用成了:

由于两种声明对应的名称修饰结果互不相同,任何针对错误声明版本的调用,在链接阶段都将无法解析------这种现象有时被乐观地称为类型安全链接。我说"乐观",是因为这个过程只能捕获函数签名错误;如果返回类型声明有误,则依然会被忽略。
在当今的编译系统中,"解码"(demangling)工具会拦截并转换这些修饰名,用户得以浑然不觉其内部实际名称为何。然而,用户的日子并非向来如此舒坦。在 1.1 版本时期,我们的系统还远没有这么周到。cfront 倒是始终同时保存着修饰前后的两个名字,其错误信息里引用的也是源码层面的函数名。可链接器就不一样了------它只会原封不动地回显交给它的那些内部修饰名。
我至今仍记得那位红头发、满脸雀斑的开发者------那天傍晚时分,他踉跄着闯进我的办公室,一副又气又急的样子,非要弄明白 cfront 到底对他的程序干了什么好事。当时我对这种与用户面对面的场面还略显生疏,所以脑海中冒出的第一个念头是回答他:"当然什么都没干。呃,就算干了什么,那也是为您好。反正,我也不知道。要不您去问问 Bjarne?"第二个念头则是先沉住气,问问他究竟出了什么问题(名声这玩意儿,就是这么来的。😃)。
"就这个,"他几乎是吼出来的,一边把编译打印稿塞到我手里。那意思分明是在说:这简直是种令人发指的暴行。链接编辑器报告了一个无法解析的函数:
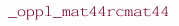
或者是其他类似的、对用户绝对称不上友好的名称修饰结果。这其实对应的是一个 4x4 矩阵类的加法运算符:
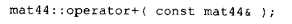
这位程序员声明并调用了这个运算符,却忘了去定义它。"哦,"他说。"嗯,"他又补了一声。接着他便强烈建议,往后可别再让用户看到这种内部名称了。总的说来,我们后来一直遵循着他的建议。
虚拟成员函数(Virtual Member Function)
如果 normalize() 是一个虚成员函数,那么调用:
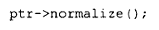
将在内部被转换为:
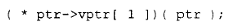
其中各项含义如下:
1.vptr 表示由编译器内部生成的虚函数表指针,它被插入到每一个声明或继承了一个或多个虚函数的类对象之中(在实际实现中,该指针的名称是经过修饰的;在复杂的类派生体系中,一个对象内部可能存在多个 vptr)。
2.1 是虚函数表中与 normalize() 相关联的表项索引。
3.第二次出现的 ptr 则代表 this 指针。
类似地,若 magnitude() 也是一个虚函数,它在 normalize() 内部的调用将被转换为:

此时,由于 Point3d::magnitude() 是在 Point3d::normalize() 内部被调用的(而后者本身已通过虚机制完成解析),显式调用 Point3d 的实例(从而抑制不必要的虚机制二次调用)将更为高效:

倘若 magnitude() 被声明为内联函数,这种写法带来的效率提升会更加显著。通过类作用域操作符显式调用虚函数,其解析方式与非静态成员函数无异:

尽管以下调用在语义上是正确的:

但编译器若将其内部转换为:
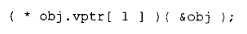
则是毫无必要的。回顾一下,对象本身并不支持多态(见第 1.3 节)。因此,通过 obj 所调用的实例只能是 normalize() 的 Point3d 版本。通过类对象调用虚函数,在编译器处始终应当被解析为一次普通的非静态成员函数调用:
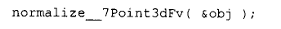
这项优化带来的额外好处是,虚函数的内联实例因此得以展开,从而带来显著的性能提升。
关于虚函数,尤其是它们在继承体系中的行为,将在第 4.2 节中作更详细的讨论。
静态成员函数(Static Member Functions)
如果 Point3d::normalize() 是一个静态成员函数,那么它的两种调用形式:

都将被内部转换为"普通的"非成员函数调用,例如:

在静态成员函数被引入语言之前,高阶用户的代码中时不时会出现下面这种------平心而论堪称古怪的------惯用手法:
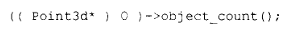
前贝尔实验室成员 Jonathan Shopiro,是我所知晓的第一位运用此惯用法的人,同时也是将静态成员函数引入语言的主要倡导者。关于静态成员函数的首次正式展示,发生在 1988 年 Usenix C++ 大会实现者研讨会上------当时我正作一场关于成员指针的演讲,却进展得磕磕绊绊。我未能说服 Tom Cargill 相信多重继承并不那么复杂,这或许并不令人意外,但也由此机缘巧合地引出了 Jonathan 和他关于静态成员函数的构想。谢天谢地,他跳上讲台,向我们慷慨陈词他的想法,而我也趁机喘了口气(在 STROUP94 中,Bjarne 提到他最早是从 Martion O'Riordan 那里听到静态成员函数这一提案的)。
其中 object_count() 仅仅是返回静态数据成员 _object_count 的值。这种惯用法是如何演变而来的?
在静态成员函数被引入之前,语言规定所有成员函数都必须通过该类的一个对象来调用。实际上,只有当成员函数内部直接访问了某个非静态数据成员时,那个类对象才是必不可少的。类对象为此次调用提供了 this 指针的值。this 指针将成员函数内所访问的非静态类成员,与包含在该对象内部的那些成员绑定起来。如果没有任何成员被直接访问,那么实际上也就不需要 this 指针了,进而也就没必要非得通过一个类对象来调用该成员函数。然而,当时的语言规范并未考虑到这种情况。
这在访问静态数据成员时造成了一种反常的局面。倘若类的设计者按照公认的良好风格,将静态数据成员声明为非公有,那么他就必须同时提供一个或多个成员函数,以供对该成员进行读写访问。于是乎,尽管你可以在不依赖类对象的情况下访问静态数据成员,但要调用它的访问成员函数,却又不得不将这些函数绑定到该类的某个对象上。
当类的设计者希望支持"尚无任何类对象存在"这一情况时(正如 object_count() 所面临的情形),能够独立于类对象进行访问就显得尤为重要了。编程上的一种变通方案,便是那个怪异的惯用法------将 0 强制转换为类指针,以此提供一个虽非必要、但语言却强制要求的 this 指针实例:

语言层面的解决方案,则是随 cfront 2.0 正式版本一同引入的静态成员函数。静态成员函数的主要特征在于它没有 this 指针。以下次要特征皆源于这一主要特征:
1.它不能直接访问其所属类的非静态成员。
2.它不能被声明为 const、volatile 或 virtual。
3.它无需通过其所属类的对象来调用,尽管为便利起见,也允许这样做。
使用成员选择语法不过是一种书写上的便利;它在内部会被转换为直接调用:

那么,如果类对象是作为某个表达式(例如一次函数调用)的副作用而获得的,又当如何呢?例如:

此时该表达式仍需被求值:

静态成员函数自然也会被提升至类声明之外,并赋予一个经过适当修饰的名称。例如:

在 cfront 内部会被转换为:

其中 SFv 表示它是一个参数列表为空(void)的静态成员函数。
获取静态成员函数的地址,得到的总是该函数在内存中的实际位置,也就是它的地址。由于静态成员函数没有 this 指针,其地址值的类型并非指向类成员函数的指针,而是非成员函数指针的类型。也就是说:

产生的值类型为:
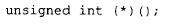
而不是:
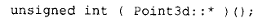
静态成员函数由于没有 this 指针,因而与功能对等的非成员函数类型相同,这还为混合使用 C++ 与基于 C 的 X Window 系统时涉及回调函数的难题,提供了一个意想不到的解决方案(相关讨论可参阅 YOUNG95)。它们也被成功地用于实现 C++ 与 C 语言多线程 API 的对接(见 SCHMIDT94a)。
4.2 虚拟成员函数(Virtual Member Functions)
我们已经见识过虚函数实现的一般模型:一个特定于类的虚函数表,内含该类所有活跃虚函数的地址集合;以及一个指向该表的 vptr 指针,它被安插在每一个类对象的内部。本节中,我将带领大家遍历一系列可能的设计方案,并逐步演进至上述模型;随后,再分别在单继承、多继承和虚继承的语境下,对该模型进行详尽的剖析。
为了支撑虚函数机制,必须提供某种形式的、作用于多态对象的运行时类型解析。也就是说,倘若我们写下调用:
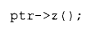
就必须有某些信息在运行时与 ptr 相关联,从而使得 z() 的恰当实例能够被识别、找到并调用。
也许最为直截了当、却代价高昂的解决方案,是将所需信息直接附加到 ptr 上。采用这种策略的话,一个指针(以及隐含地,一个引用也同理)将携带两样信息:
1.它所指向对象的地址(当然,这是它目前本就持有的内容)。
2.对象类型的某种编码信息,或者是一个包含着该类型信息的数据结构的地址(这正是解析 z() 正确版本所需要的东西)。
这种方案的问题具有双重性。首先,它会给指针的使用带来显著的空间开销,不论程序是否实际用到了多态。其次,它会破坏与 C 语言的链接兼容性。
如果这份额外信息不能存放在指针内部,那么下一个合乎逻辑的存放位置便是对象自身之中。这样一来,存储开销就被限定在了那些确有需要的对象身上。但究竟哪些对象才真正需要这些信息呢?我们是否应当把这信息塞进每一个将来有可能被继承的聚合体里?或许该如此。然而,请考虑下面这个 C 结构体的声明:
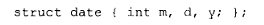
严格来说,它倒是符合上述条件。可实际上,它永远不会有需要用到那些信息的时候。平白加上那些信息,只会让这个 C 结构体膨胀起来,并再次破坏链接兼容性,却带不来任何明显的补偿性收益。
"好吧,"你或许会说,"那些额外的运行时信息,理应只在一个类声明明确使用了 class 关键字的时候才加上去。"这么做虽然保住了语言兼容性,却依然是一条毫无灵性的策略。比方说,下面这个类声明就符合新的标准:
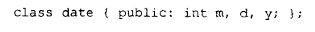
可是在实际应用中,它照样不需要这些信息。更有甚者,下面这个使用了 struct 关键字的类声明,虽然不符合我们的新标准,但它确实用得上这些信息:
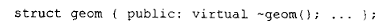
我们所需要的是一个更恰当的判定依据------一个立足于类的用法,而非仅仅看 class 或 struct 关键字有无出现的依据(见第 1.2 节)。如果一个类从本质上就需要这些信息,那么信息就在;倘若不需要,那就没有。那么,究竟在何时才真正需要这些信息呢?答案很明确:当需要支持某种形式的运行时多态操作的时候。
在 C++ 中,多态性的"展现"形式,体现为可以通过一个公有基类的指针或引用来指代某个派生类对象。举例来说,给定如下声明:
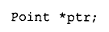
我们可以把 ptr 赋值为一个 Point2d 对象的地址:
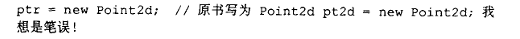
也可以让它指向一个 Point3d 对象:
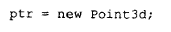
ptr 的多态性主要充当一种运输机制,借助它,我们得以在程序各处携带着一整套从它公有派生出来的类型集合。这种形式的多态支持,不妨定性为被动的,而且------除了虚基类的情形是个例外------它在编译阶段就已经完成了。
当被指代的对象真正投入使用时,多态性便进入了主动状态。虚函数的调用便是这样一种使用形式:
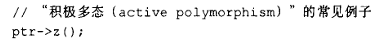
在 1993 年运行时类型识别(RTTI)被引入语言之前,C++ 为主动多态性提供的唯一支持,就是虚函数调用的解析。而有了 RTTI 之后,针对多态指针或引用的运行时查询也得到了支持(RTTI 将在第 7.3 节中详细讨论):

至此,问题已被归结为:如何辨识出那些展现多态性、并因而需要额外运行时信息的类集合。正如我们所见,单单靠 class 和 struct 这两个关键字本身,并不能帮上什么忙。在缺乏引入一个新关键字------比如 polymorphic------的前提下,要确切识别一个意图支持多态的类,唯一可靠的办法就是看它是否声明了一个或多个虚函数。因此,至少存在一个虚函数,便成了判定哪些类需要额外运行时信息的准绳。
接下来的问题显而易见:我们究竟需要存储哪些额外的信息呢?也就是说,倘若我们写下调用:
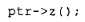
其中 z() 是一个虚函数,那么要调用 z() 在运行时的正确实例,究竟需要哪些信息?
我们需要知道:
1.ptr 所指对象的实际类型。这让我们能够选择 z() 的正确实例;
2.以及该 z() 实例的存放位置,以便调用它。
一种初步的实现方案,或许是为每一个多态类对象增添两个成员:
1.一个表示类型的字符串或数值编码;
2.一个指针,指向某张存放着程序虚函数运行时地址的表。
这张存放着虚函数地址的表该如何构建呢?在 C++ 中,通过某个类的对象所能调用的虚函数集合,在编译时就已经确定了。而且,这个集合是固定不变的------它既不能在运行时增添新项,也不允许替换其中已有的虚函数实例。因此,这张表仅仅充当一个被动的存储仓库。既然它的大小和内容在程序执行期间都不会改变,那么它的构建和访问就可以完全交由编译器来处理,无需任何运行时介入。
然而,在运行时能够拿到地址,还只是解决方案的一半。另一半则是找到这个地址。这通过两个步骤来实现:
1.找到表:在每个类对象内部,安插一个由编译器内部生成的虚表指针。
2.找到函数地址:为每一个虚函数分配一个在表中的固定索引。
这一切都由编译器安排妥当。待到运行时,唯一要做的事情,就是调用那个位于特定虚表槽位中的函数。
虚函数表是以类为单位生成的。每张表存放着与该表所属类之对象相关的、所有"活跃"虚函数实例的地址。这些活跃函数由以下几类构成:
1.在该类内部定义的、可能覆盖了基类版本的函数实例;
2.从基类继承而来、派生类未予覆盖的函数实例;
3.一个名为 pure_virtual_called() 的库函数实例,它既充当纯虚函数的占位符,又能在该函数万一被调用时抛出运行时异常。
每个虚函数在虚表中都被分配了一个固定的索引。在整个继承体系中,该索引始终与对应的特定虚函数保持关联。以我们的 Point 类体系为例:

虚析构函数极有可能被分配在槽位 1,mult() 被分配在槽位 2(在此例中,mult() 并无定义,因此槽位中放置的是库函数 pure_virtual_called() 的地址;倘若该函数因意外被调用,通常会导致程序终止)。y() 分配在槽位 3,z() 分配在槽位 4。那么 x() 被分配在哪个槽位呢?答案是哪个都没有,因为它并未被声明为虚函数。图 4.1 展示了 Point 类的布局及其虚表:
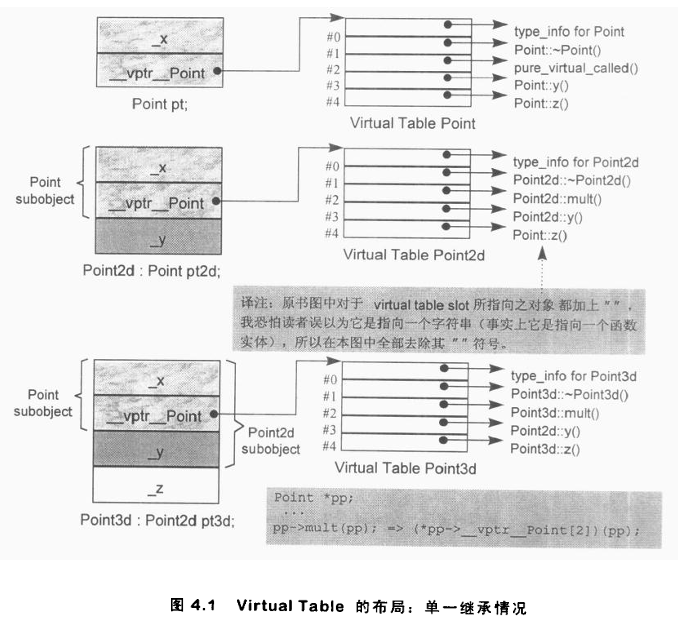
当随后有类从 Point 派生出来时------比如 Point2d 类:


这里存在三种可能的情形:
1.它可以继承基类中声明的虚函数实例。确切地说,该实例的地址会被复制到派生类虚表中的对应槽位。
2.它可以用自己的实例覆盖基类版本。此时,派生类自己的实例地址会被放入对应的槽位中。
3.它可以引入一个基类中未曾出现的、新的虚函数。在这种情况下,虚表会新增一个槽位,并将该函数的地址放入其中。
Point2d 的虚表在槽位 1 中放置其析构函数的地址,在槽位 2 中放置其 mult() 实例的地址(替换了纯虚函数实例)。它在槽位 3 中放置其 y() 实例的地址,并在槽位 4 中保留从 Point 继承来的 z() 实例的地址。图 4.1 同样展示了 Point2d 类的布局及其虚表。
类似地,从 Point2d 派生出 Point3d 的代码如下:

它所生成的虚表中,Point3d 的析构函数位于槽位 1,Point3d 的 mult() 实例位于槽位 2。它把从 Point2d 继承来的 y() 实例放在槽位 3,并将 Point3d 自己的 z() 实例放在槽位 4。图 4.1 展示了 Point3d 类的布局及其虚表。
因此,倘若我们写下表达式:
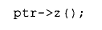
编译器在编译阶段如何能掌握足够的信息,来构建这次虚函数调用呢?
一般而言,我们无法在每次调用 z() 时都知晓 ptr 所指对象的确切类型。但我们确实知道,通过 ptr 我们能够访问到与该对象所属类相关联的虚表。
此外,尽管我们通常也不知道该调用 z() 的哪一个实例,但我们明确知道,每一个实例的地址都存放在槽位 4 中。
凭借这些信息,编译器便能在内部将该调用转换为:
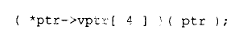
在此转换中,vptr 表示由编译器内部生成、并被安插在每个类对象中的虚表指针;4 则表示在与 Point 继承体系相关联的虚表中,为 z() 所分配的槽位编号。在运行之前,我们唯一不得而知的事情,便是槽位 4 中实际存放的究竟是哪一个 z() 实例的地址。
在单继承体系中,虚函数机制的表现可谓中规中矩:它既高效,又易于建模。然而,在多继承和虚继承之下,对虚函数的支持就没那么规整了。
多重继承下的虚函数
多继承对虚函数支持所带来的复杂性,主要围绕在第二个及其后的基类上,以及运行时调整 this 指针的必要性。考虑如下简单的类体系:


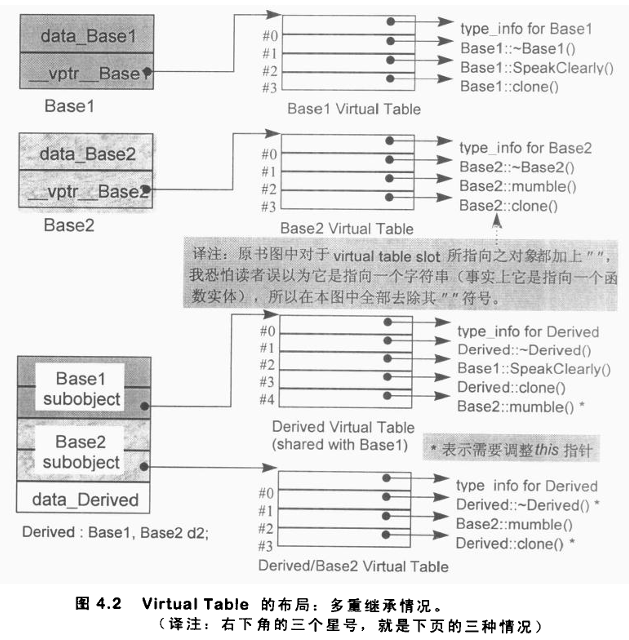
在 Derived 类内部,虚函数支持的全部复杂性都集中在了 Base2 子对象上。主要有三种情形需要特别支持,本例中分别体现为:(1)虚析构函数,(2)继承而来的 Base2::mumble() 实例,以及(3)一组 clone() 函数实例。我将逐一加以考察。
首先,让我们将一个 Base2 指针指向在堆上分配的 Derived 类对象:
新生成的 Derived 对象地址必须经过调整,方能指向其内部的 Base2 子对象。完成这一调整的代码在编译时即已生成:

倘若不做这一调整,任何对该指针的非多态性使用都将失败,例如:

现在,当程序员想要删除 pbase2 所指的对象时:

该指针必须再次调整,以重新指向 Derived 类对象的起始位置(假设它指向的依然是 Derived 类对象)。然而,这一偏移量的累加操作无法在编译时直接设定妥当,因为 pbase2 实际所指的对象,一般而言,只有在运行时才能确定下来。
总的原则是:当通过指向第二基类(或其后基类)的指针(或引用)来调用派生类的虚函数时,this 指针的调整必须在运行时完成。也就是说,所需偏移量的大小,以及将其累加到 this 指针上的代码,都必须由编译器妥善存放在某个地方。随之而来的第一个问题自然是:究竟存放在哪里?
Bjarne 在 cfront 中的原始解决方案是扩展虚表,使其能够容纳(可能需要的)this 指针调整信息。具体而言,每个虚表槽位不再仅仅是一个指针,而是变成了一个聚合体,其中既包含可能用到的偏移量,也包含函数地址。相应地,虚函数调用也就从:
演变成了:

其中 faddr 存放虚函数的地址,而 offset 则存放必要的 this 指针调整量。
对这种方案的批评在于,它给所有虚函数的调用都带来了额外负担------无论是否真的需要调整偏移量。这既体现在额外的访问操作和偏移量累加所带来的开销上,也体现在每个虚表槽位增大的尺寸上。
更为高效的解决方案是使用 thunk(形实转换程序)(我头一回听说 thunk 这个词时,教授开玩笑地告诉我们,thunk 就是 Knuth 倒过来拼写,所以他把这项技术归功于 Knuth 博士)。就我所知,thunk 最早是在编译器技术中为支持 ALGOL 语言独有的"按名传递"语义而引入的。它是一个短小的汇编代码桩,用于(a)按适当的偏移量调整 this 指针,然后(b)跳转到虚函数本体。举例来说,通过 Base2 指针调用 Derived 类析构函数时,与之关联的 thunk 看起来可能像这样:

(这倒不是说 Bjarne 不知道 thunk 这回事。问题在于,thunk 只有以汇编代码桩的形式存在时才高效,而一旦做成完整的函数调用就会大打折扣。由于 cfront 当时是用 C 语言作为目标代码生成语言的,它无法提供高效的 thunk 实现。)
采用 thunk 实现方案后,虚表的槽位就可以继续保留为单一的指针,从而消除了为支持多继承而在虚表中增加的空间开销。每个槽位中存放的地址,要么直接指向虚函数本体,要么------如果需要调整 this 指针------就指向一个与之关联的 thunk。这样一来,对于不需要调整 this 指针的虚函数,也就不必再承担额外的性能损失了(据信这类函数占绝大多数,尽管我本人尚未见过确切的数据统计)。
this 指针调整带来的另一项开销,是对于同一个函数,需要根据其是通过派生类(或最左端的基类)调用,还是通过第二个(或后续的)基类调用,在虚表中设置不同的条目。举例来说:

尽管两处 delete 调用最终执行的都是同一个 Derived 类析构函数,但它们却需要虚表中两个彼此独立的表项:
1.对于 pbase1,无需调整 this 指针(作为最左端基类,它已经指向 Derived 类对象的起始处)。其虚表槽位需要存放的是真实的析构函数地址。
2.对于 pbase2,则必须调整 this 指针。其虚表槽位需要存放的是相应 thunk 的地址。
在多继承下,一个派生类会额外包含 n - 1 张虚表,其中 n 代表其直接基类的数量(因此,单继承引入的附加虚表数量为零)。对于 Derived 类而言,就会生成两张虚表:
1.一张是与其最左端基类 Base1 共享的主虚表实例;
2.另一张是与其第二基类 Base2 相关联的辅助虚表实例。
Derived 类对象中,为每一张与其关联的虚表都配备了一个 vptr(如图 4.2 所示)。这些 vptr 在构造函数内部,经由编译器生成的代码来完成初始化。
为支持一个类关联多张虚表,传统做法是将每一张虚表生成为具有唯一名称的外部对象。例如,与 Derived 相关联的两张虚表,其名称很可能会是:

这样一来,当把一个 Derived 类对象的地址赋给一个 Base1 指针或 Derived 指针时,所访问的虚表就是主虚表 vtbl__Derived。而当把 Derived 类对象的地址赋给一个 Base2 指针时,所访问的虚表则是第二张虚表 vtbl__Base2__Derived。
随着支持动态共享库的运行时链接器的出现,符号名称的链接过程可能会变得极其缓慢------例如,在 SparcStation 10 上,每个名称的链接耗时可达 1 毫秒。为了更好地适应运行时链接器的性能需求,Sun 编译器将多张虚表合并为一张。指向辅助虚表的指针,则是通过在主虚表名称上增加一个偏移量来生成的。采用这种策略后,每个类仅拥有一张具名虚表。"在 Sun 的若干项目中,使用该方案的代码在速度提升方面效果相当显著"(引自与 Sun C++ 编译器架构师 Mike Ball 的通信)。
在本章前文中我曾写道,第二基类(或后续基类)的存在会在三种情形下对虚函数的支持产生影响。在第一种情形中(即调用虚析构函数的情形),派生类的虚函数是通过指向第二基类的指针来调用的。例如:

从图 4.2 中可以看到,在调用点,ptr 指向的是 Derived 类对象内部的 Base2 子对象。为使 delete 正确执行,ptr 必须被调整以指向 Derived 类对象的起始地址。
第二种情形(即调用从第二个基类中继承而来的虚函数)是第一种情形的变体,它涉及通过派生类指针来调用第二基类中继承而来的虚函数。此时,派生类指针必须重新调整,以指向第二基类的子对象。例如:

第三种情形(即调用两个基类、派生类中都存在的虚函数)则源自一项语言扩展,该扩展允许虚函数的返回类型在继承体系的基类类型与公有派生类型之间有所变化。Derived::clone() 实例便是一例。Derived 的 clone() 实例返回一个 Derived 类指针,同时仍然覆盖了其两个基类的 clone() 实例。当通过指向第二基类的指针来调用 clone() 时,this 指针偏移问题便会显现:

Derived 类的 clone() 实例被调用,并通过 thunk 将 pb1 重新调整,使其指向 Derived 类对象的起始处。随后,clone() 返回一个指向新分配的 Derived 类对象的指针;而在将该地址赋给 pb2 之前,它还必须经过调整,以指向其中的 Base2 子对象。
Sun 编译器针对那些被判定为"短小"的函数,实现了一种称为"分裂函数"(split functions)的策略:它会生成两个包含相同算法代码的函数版本。其中第二个版本会在返回指针之前,将必要的偏移量累加上去。这样一来,通过 Base1 指针或 Derived 指针发起的调用,就会使用那个不带返回值调整的版本;而通过 Base2 指针发起的调用,则使用另一个版本。
当函数被判定为"并不短小"时,分裂函数策略便让位于另一种方案------在函数内部设立多个入口点。据 Mike Ball 估计,这一方案每个入口点大约需要消耗三条指令。
对面向对象范式经验尚浅的程序员,或许会质疑分裂函数的实用性,因为它仅局限于短小的函数。然而,面向对象编程所倡导的风格,恰恰是将操作局部化,封装在众多短小的虚函数之中,这些函数的平均长度往往在八行左右(虚函数平均长度为八行这一说法,是我在某处读到的------当然,出处我已无从考证。不过,这倒是与我自身的经验相吻合)。
对多入口点函数的支持,可以省去大量 thunk 的生成。例如,IBM 的做法是将 thunk 直接融入实际被调用的虚函数之中。this 指针的调整操作在函数顶部执行,随后执行流程便落入函数的用户代码部分;而那些无需调整的调用,则会跳过顶部代码直接进入。
微软则已为其基于所谓"地址点"(address points)的 thunk 消除策略申请了专利。该策略让覆盖函数所预期的地址并非派生类对象的地址,而是引入该虚函数的那个类的地址------这便是该函数的"地址点"(详细讨论请参阅 MICRO92)。
虚拟继承下的虚函数
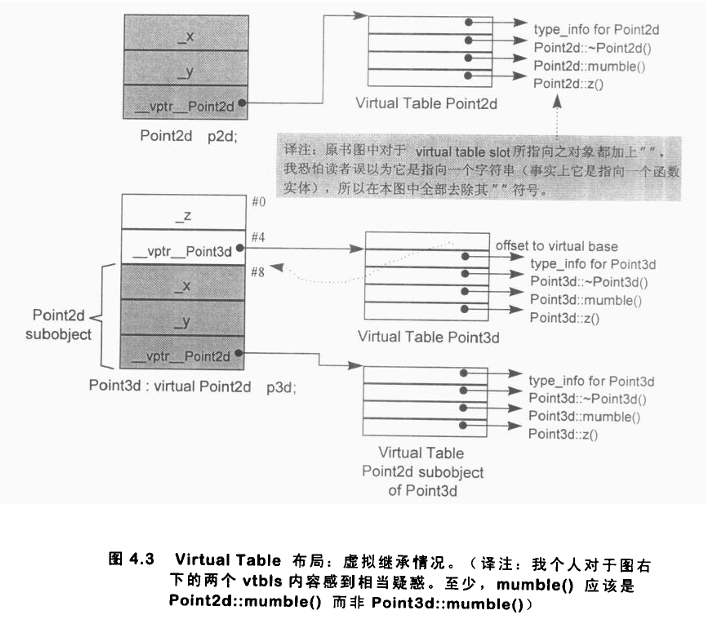
考虑如下 Point3d 虚继承自 Point2d 的派生关系:

尽管 Point3d 只有一个最左端基类------Point2d------但 Point3d 对象与 Point2d 对象的起始地址不再重合(而在非虚单继承下二者是重合的)。这一情形如图 4.3 所示。由于 Point2d 对象和 Point3d 对象不再重叠,二者之间的相互转换也就需要调整 this 指针。总体而言,在虚继承下消除 thunk 的努力已被证明要困难得多。
当某个虚基类本身又派生自另一个虚基类,并且同时支持虚函数和非静态数据成员时,对虚基类的支持便会陷入一种拜占庭式的繁复境地。尽管我手头的文件夹里塞满了详尽推演过的例子,以及不止一套用于确定正确偏移量与调整量的算法,但这份材料实在过于深奥冷僻,不宜放在本书中展开讨论。我的建议是:不要在虚基类中声明非静态数据成员。这样做能极大程度地驯服其中的复杂性。