MySQL索引的最左前缀匹配原则是什么?
一句话概括:
当MySQL在使用联合索引时,查询条件必须从索引的最左列开始匹配。
这是因为联合索引在B+树中的排列方式是"从左到右"的顺序。比如联合索引(first_name,last_name,age)会先按 first_name 排序,first_name 相同再按last_name 排序,last_name 相同再按 age 排序。MySQL 查找时会优先用first_name作为匹配依据,然后依次用last_name和 age。跳过最左侧字段,后面的列在B+树中是无序的,压根没法利用索引快速定位。
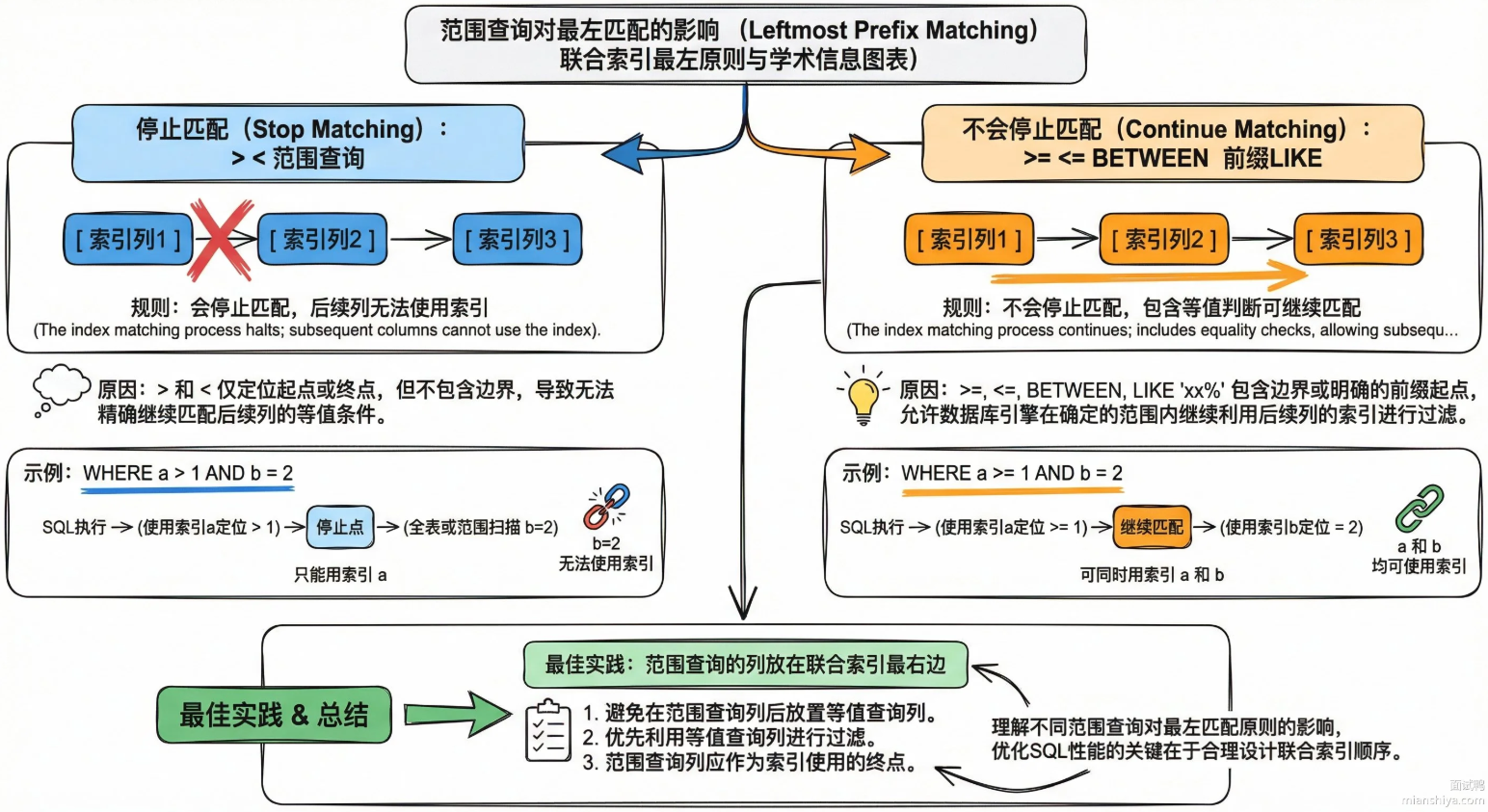
特例:范围查询
当范围查询是:>,<这种,会停止匹配
sql
where a > 1 and b = 2 and c = 3;只有a能用上联合索引,因为a经过查询筛选后,不同a值之间的b和c是无序的。无法走索引。
相反,当遇到>=,<=,前缀 like xx%时,不会停止匹配。因为他们之中包含等值判断
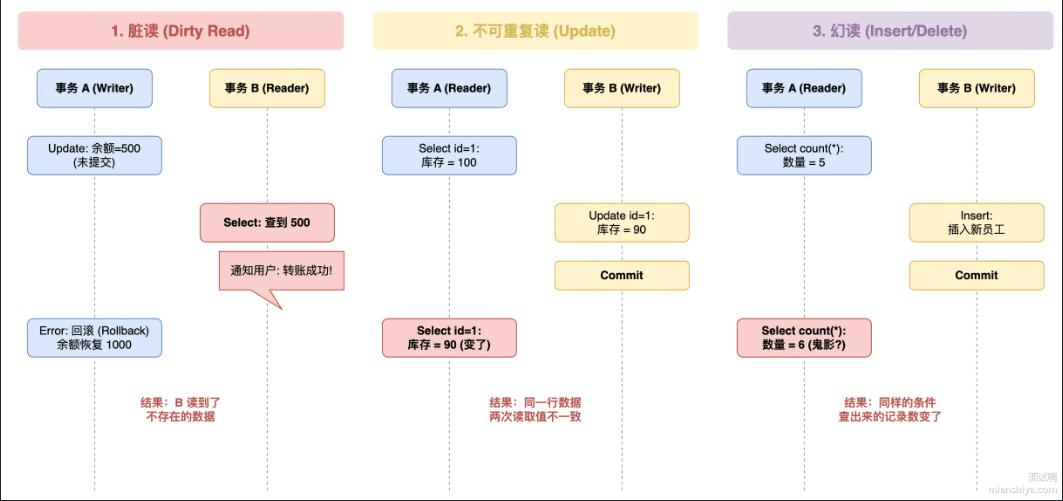
脏读/不可重复读/幻读分别代表什么意思
这三个都是并发事务带来的数据一致性问题,严重程度递减
- 脏读:指数据库中一个事务查询了一个还没提交的数据,万一那个数据回滚了,读到的数据不存在
- 不可重复读:指一个事务查询两次同一行数据,两次获得的数据不一样。因为中间有别是事务修改并提交了这行数据。强调数据的内容改变
- 幻读:指一个事务执行两次同样的范围查询,返回的数据行数不一样。因为中间有别是事务执行了插入或删除操作。强调数据的行数变化。
不同隔离级别下会出现的问题
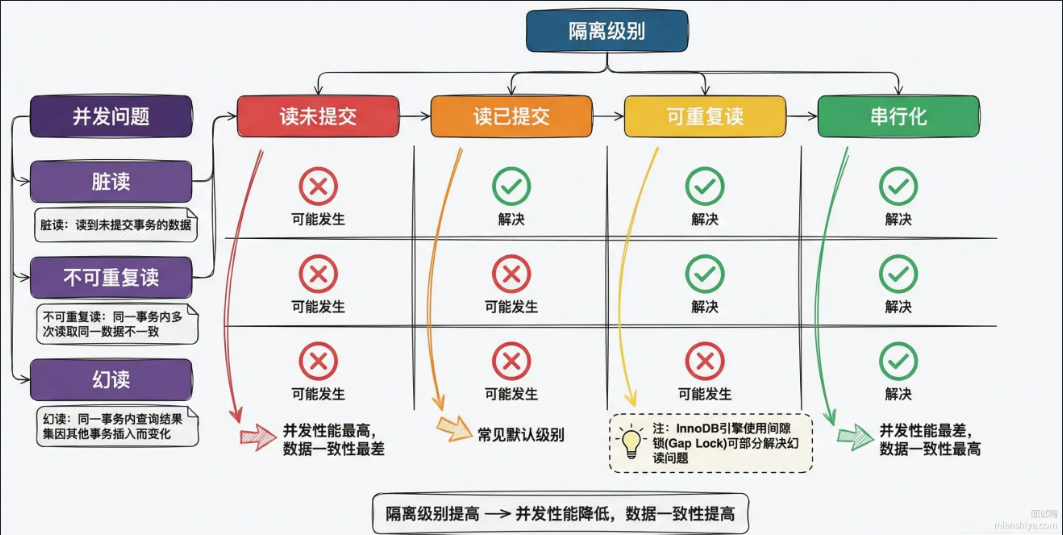
安全程度:读未提交>读已提交>可重复读>串行化
性能依次递减,InnoDB存储引擎默认的就是可重复读。
如何解决的
- 脏读:MVCC天然解决,读的是快照,看不到未提交的数据
- 不可重复读:在可重复读隔离级别下,ReadView在事务一开始就固定了,后续复查读取的是同一个ReadView。
- 幻读:快照读走MVCC,看不到新插入行,当前读用间隙锁所著范围,别的事务插不进来。当快照读和当前都混用时,还会出现幻读。
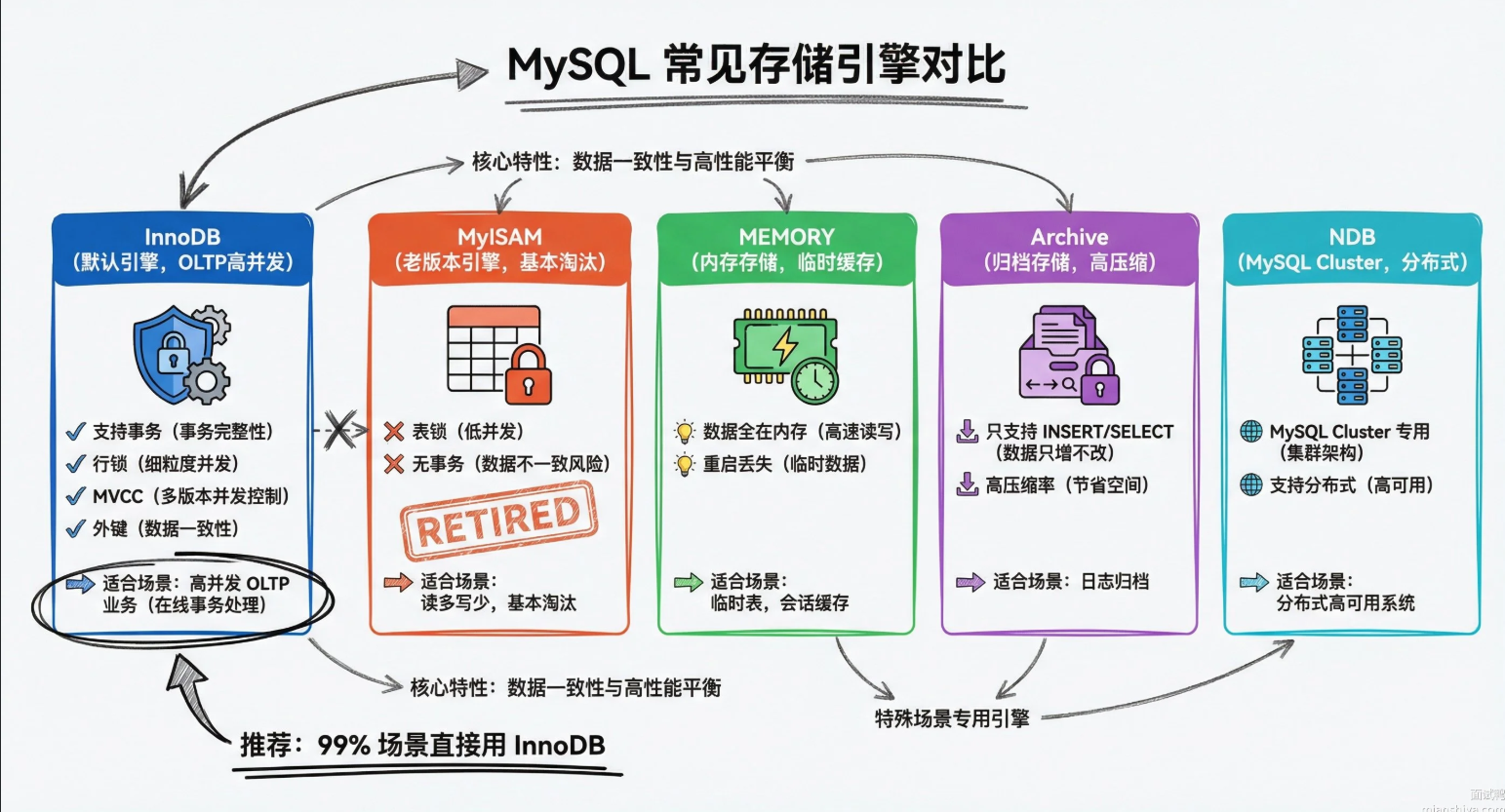
MySQL的存储引擎有哪些,他们之间有什么区别
MySQL的存储引擎是可插拔的,不同引擎辅助数据的存储与读取。实际场景中95%都是使用的InnoDB,面试主要讲InnoDB与MyISAM进行区分就行了
MySQL8.4版本一共提供了10个引擎,常见的有这几个:
1)InnoDB:MySQL5.5 之后的默认引擎,支持事务、行级锁、外键,MVCC也有,适合高并发的OLTP场景。数据按聚簇索引组织,主键查询贼快。
2)MyISAM:老版本的默认引擎,不支持事务,只有表级锁,但读性能不错。适合那种写少读多、对一致性要求不高的场景,比如早年的一些报表系统。
3)MEMORY:数据全放内存里,速度快但MySQL重启数据就没了。一般拿来做时表或者会话级缓存。4)Archive:专门存归档数据的,只支持INSERT 和 SELECT,不支持索引I,但压缩率高。日志归档、历史订单这种场景用得上。
5)NDB:MySQLCluster用的引擎,支持分布式和高可用,数据自动分片,适合电信级别的大规模集群。
MySQL的覆盖索引
覆盖索引指的是查询内容包含在了二级索引内部,查询时直接从索引里拿数据,无需再次执行回表操作。
本质是:索引中有的数据直接拿,减少回表操作。
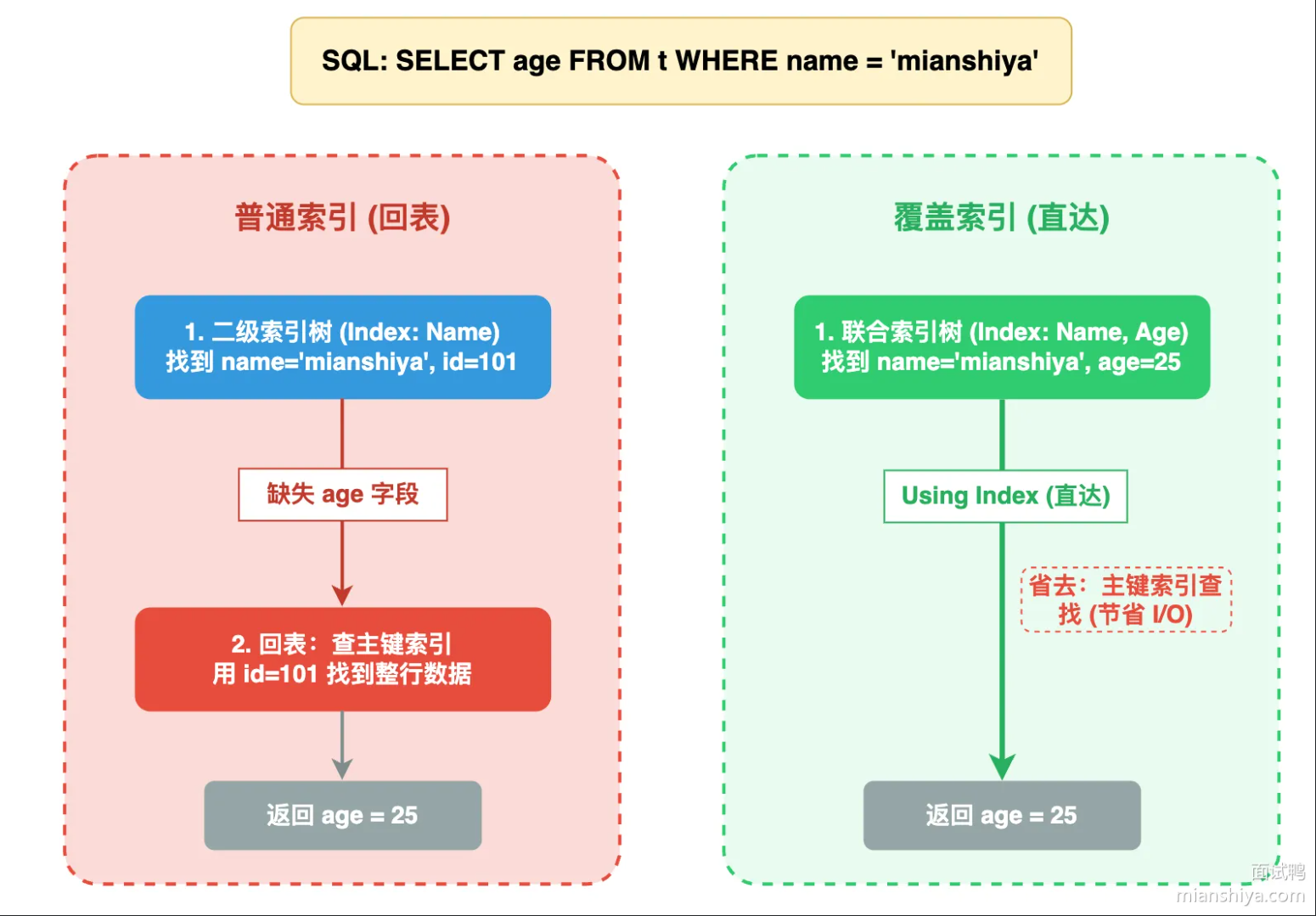
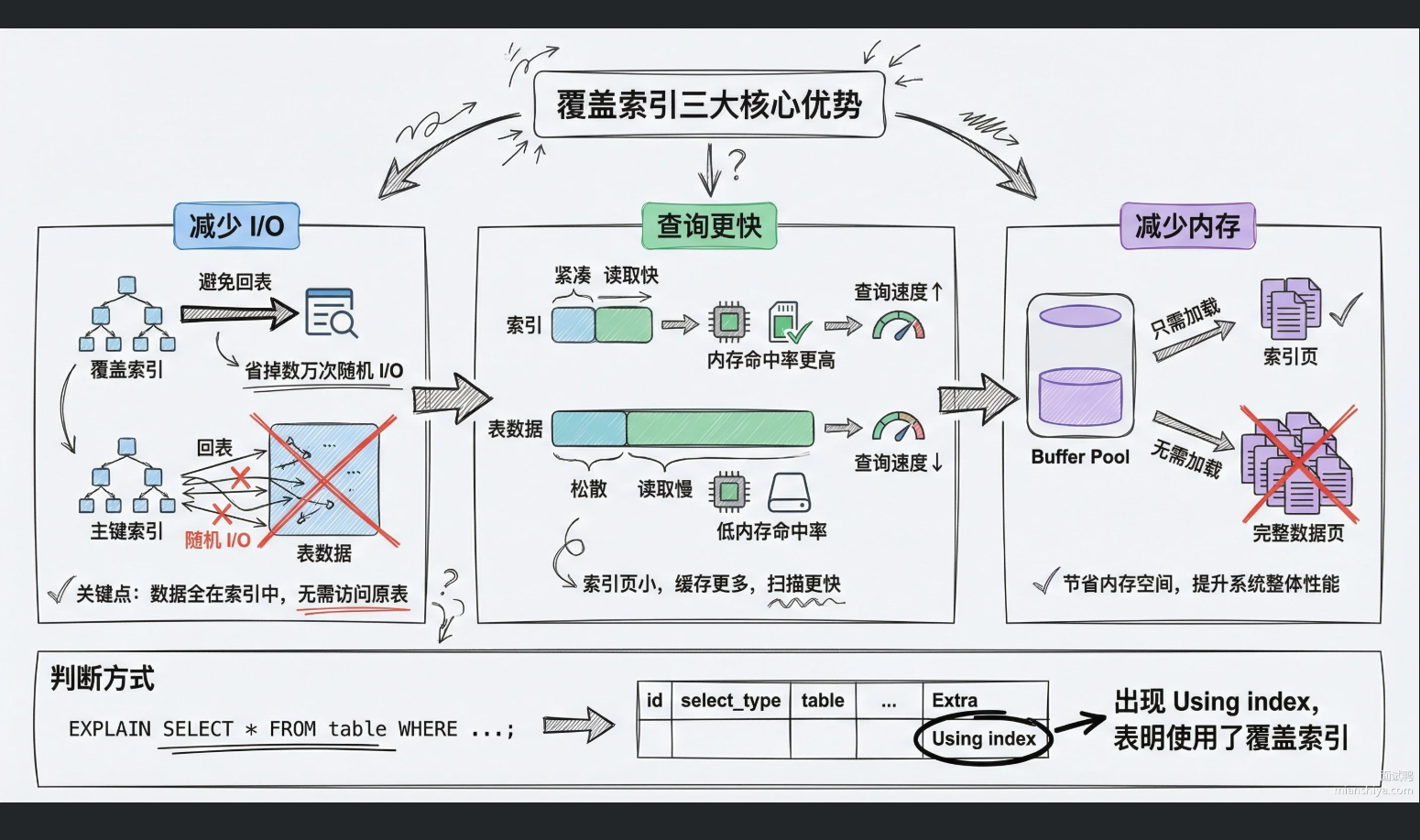
优点:
- 减少I/O操作:查询直接从索引中拿数据,避免访问主键索引的数据页。
- 查询更快:索引页小,结构紧凑,缓存命中率更高
- 减少内存占用:Buffer Poll只需加载索引页,不用加载更大的数据页
设计覆盖索引的哲学
主要分四点来设计:
- 高频查询优先:分析业务哪些查询频率高,针对这些设计覆盖索引
- 权衡读写比列:覆盖索引不是越多越好。索引列越多,索引越大,写入维护成本高。
- 利用联合索引:把where条件的列与select的列创建为一个联合索引。例如:select a,b from t where c=1,可以键(c,a,b)索引
覆盖索引和索引下推的区别
覆盖索引是完全不回表,索引里有查询需要的所有数据。索引下推是减少回表次数,把过滤条件下推到引擎层提前过滤,但最终还是要回表拿完整数据。两种解决的问题不一样
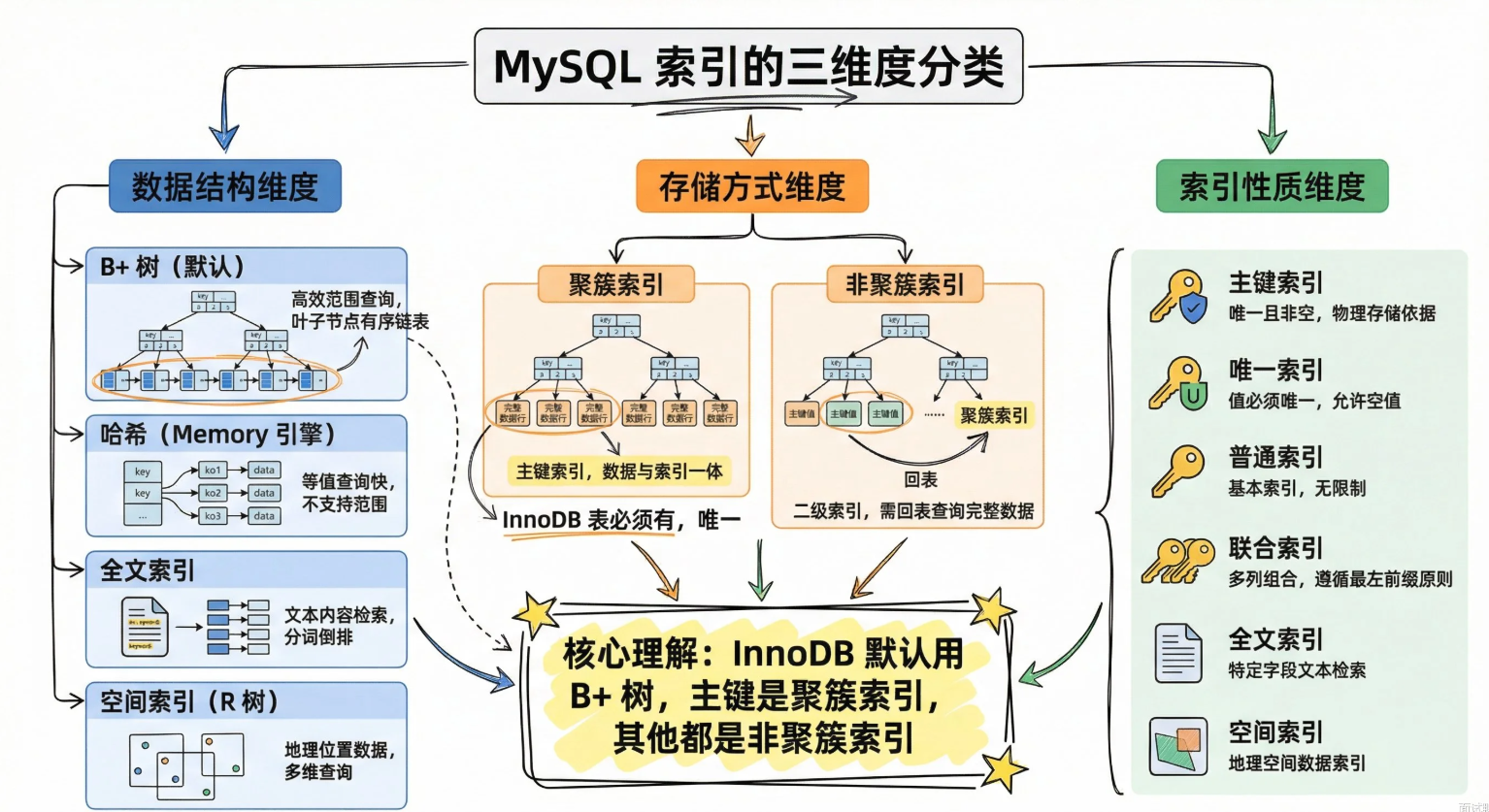
索引类型有哪些
MySQL索引可以从三个维度来分类:数据结构,存储方式,索引性质。我们先从数据结构来切入,重点讲解B+树,然后展开讲解聚簇索引和非聚簇索引的区别。
数据结构:
- B+树索引:叶子节点存储数据,叶子节点通过链表串起来:保证了快速定位单条记录和高效做出范围扫描。
- 哈希索引:通过哈希函数直接算出数据位置,等值查询O(1),不支持范围查询和排序。
- 全文索引
- 空间索引
存储方式: - 聚簇索引:又叫主键索引,叶子节点世界存放完整的行数据,数据按主键顺序物理存储,一张表只能由一个主键索引
- 非聚簇索引:也叫二级索引,叶子节点只存储索引字段值和主键值。查完二级索引还得拿着主键取主键索引获取具体数据。
索引性质 :
1)主键索引:唯一且非空,每张表只能有一个。InnoDB里主键索引就是聚簇索引。2)唯一索引:保证列值不重复,但允许有NULL,可以有多个NULL。
3)普通索引:没有唯一约束,纯粹为了加速查询。
4)联合索引:多列组合成一个索引,遵循最左前缀原则,列顺序很重要。5)全文索引:文本搜索用。
6)空间索引:GIS数据用。
衍生
B+树厉害在哪
数据库查询由两大类构成:等职查询和范围查询。哈希索引等值查询速度快,但是无法进行范围查询。B+树两个都行,并且叶子节点用双向链表连接,范围扫描的时候顺着链表走,不用回溯。
另外,B+树特点是树矮,一个三层的B+树就能存储2000万左右的数据。查询一条数据最多3次I/O。
索引下推
索引下推是MySQL 5.6之后引入的技术。核心思路是把部分查询条件从Service层下推到存储引擎层,在引擎层就把不符合查询条件的数据过滤,不用在将这些数据进行回表操作。作用是:减少回表操作,提升查询效率。
没有索引下推的流程是:引擎层用索引定位数据,返回主键给Service层,Service层回表拿到完整数据,再用剩余条件过滤。有了索引下推,引擎层能直接用索引里的列来过滤,不符合条件的不会回表,减少了I/O
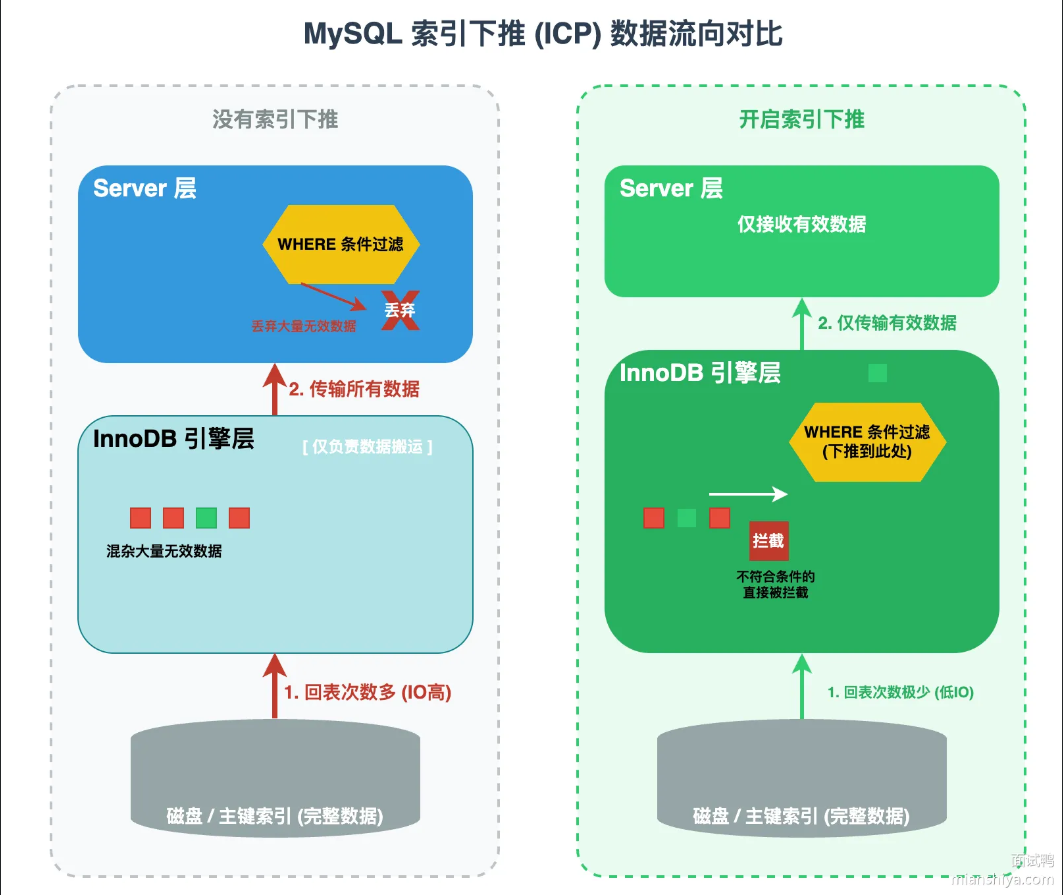
如何判断索引是否生效
在SQL语句的前面加上EXPLAIN,如果显示Usingindexcondition,说明用上了索引下推。
sql
EXPLAIN SELECT * FROM people
WHERE zipcode='95054'
AND lastname LIKE '%etrunia%';Extra 显示Usingindex condition就表示 lastname 条件被下推到引擎层了。`
关于联合索引,覆盖索引,索引下推的区分
联合索引是基础,有了联合索引才有覆盖索引和索引下推。
索引下推和覆盖索引是技术。
这两个优化都能减少I/O,但原理不同:
| 特性 | 索引下推 | 覆盖索引 |
|---|---|---|
| 解决的问题 | 减少回表次数 | 完全避免回表 |
| 是否回表 | 需要回表,但次数少 | 不需要回表 |
| EXPLAIN 标识 | Using index condition | Using index |
| 适用场景 | select * 且有额外过滤条件 | select 的列都在索引里 |
两者可以同时存在吗?不能。如果走了覆盖索引,压根不回表,索引下推就没有用武之地了。
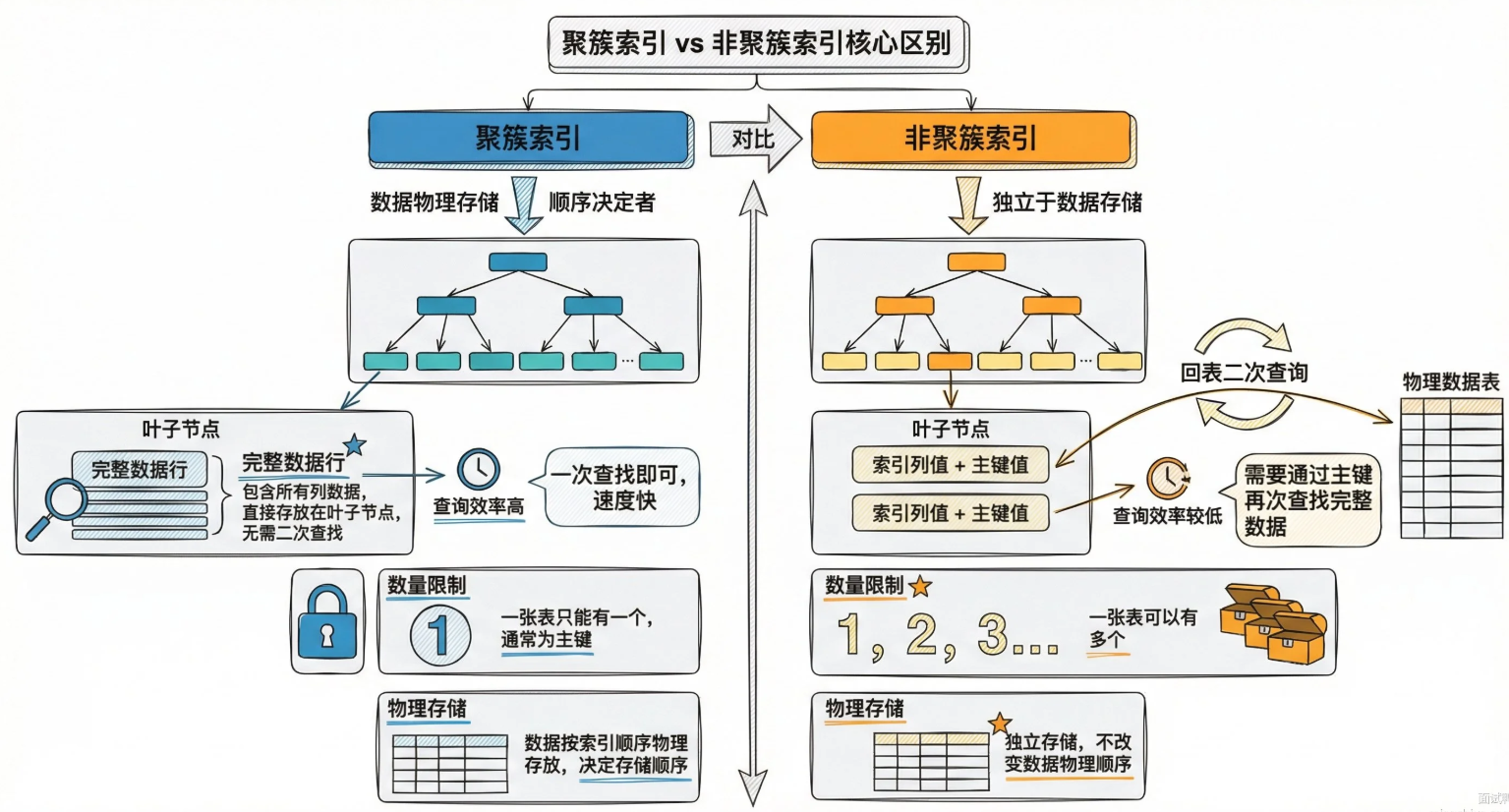
InnoDB存储引擎中聚簇索引和非聚簇索引有什么区别
在 InnoDB 引擎中,聚簇索引的叶子节点直接存储完整的数据行,一张表只能有一个聚簇索引I,默认就是主键索引。非聚簇索引的叶子节点只存储索引列的值和主键,要拿到完整数据得先查主键再回表,一张表可以有多个非聚簇索引。
核心区别就是叶子节点存的东西不一样:聚簇索引存完整数据,非聚簇索引存主键值。这导致聚簇索引查询能一步到位拿到数据,非聚簇索引可能要多一次回表操作。
MySQL中使用索引一定有效吗?如何排查索引效果
索引不一定生效 。建了索引不低啊表查询会用,用来索引不代表查询就快。
MySQL最终是否走索引,靠的是优化器的成本计算。优化器会评估走索引和全表扫描各自的I/O成本和cpu成本。优势全表扫描确实成本低,比如表就几百行数据,走索引不如直接扫;有时统计信息不准,导致优化器算错账。
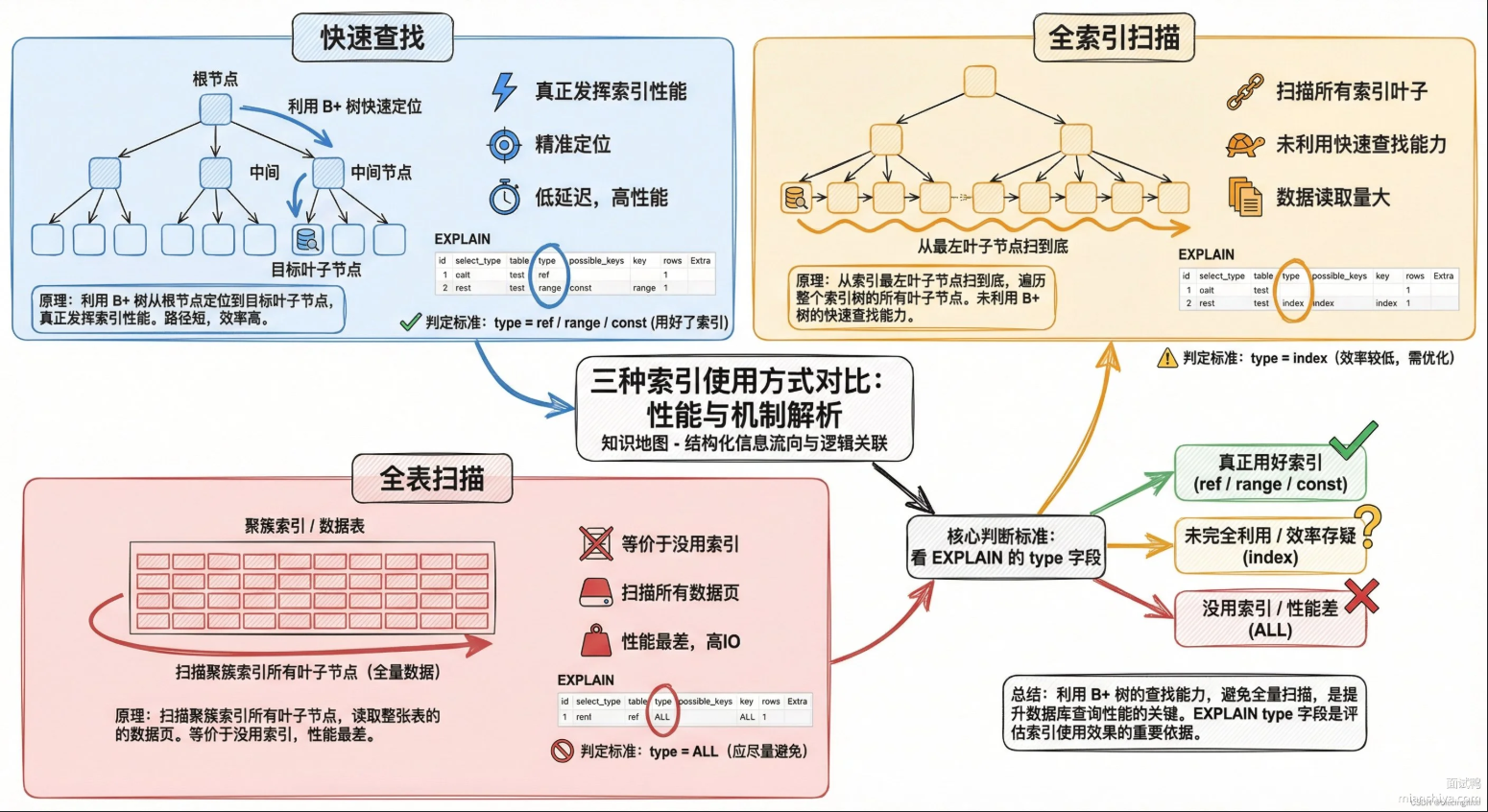
用EXPLAIN命令来排查索引。在SQL语句前面加上EXPLAIN,就能看到MySQL选择的执行计划,重点看:
- type:访问类型,all是全表扫描,range是范围扫描,ref是等值匹配,index是全索引扫描。
- key:实际用的索引名称,NULL就是没用上索引
- rows:预估扫描行数,这个数字越大说明查询代价越高。
索引失效常见场景
基本原因分为两类:1.查询条件导致索引树的快速查找能力用不上 2.优化器觉得不划算
1)联合索引不符合最左前缀
假设有个联合索引idx_name_age_id,查询写成WHERE age= 10 AND id = 1,跳过了 name字段,最左缀匹配失败,索引树的有序性利用不上,退化成全索引扫描甚至全表扫描。
2)索引列上做了运算
WHEREid+3=8这种写法,MySQL得把每行的id 拿出来算一遍,没法直接在索引|树上定位,只能全录扫描。
3)索引列上用了函数
WHERELOWER(name)='cong',对索引列套了函数,索引树里存的是原始值,函数处理后的值根本不在树里,还是得全表扫。MySQL8.0 可以建函数索引来解决这个问题。
4)LIKE左侧带通配符
WHEREnameLIKE%cong%'这种写法,索引是按字符顺序排的,左边不确定就没法定位起始位置,只能全扫。LIKE'cong%'是可以走索引的。
5)OR连接了非索引字段
WHEREname='cong'ORage= 18,如果age没索引l,MySQL没法通过索引l快速过滤 age 条件,整个查询可能退化成全表扫描。
6)隐式类型转换
name是Varchar 类型,查询写成 WHERE name = 1,MySQL会做隐式转换,相当于 WHERE CAST(nameAsignedint)=1,索引列上套了函数,索引失效。联表查询时两边字段编码不一致也有同样的问题。7)优化器认为全表扫描更划算
同一个索引,查热点数据可能走全表,查冷门数据走索引。比如订单表按商品ID 查,热门商品占了80%的订单,走索引反而要回表几十万次,不如直接全表扫描。
8)ORDER BY没配合好
ORDER BY 后面的字段不是主键,也不是覆盖索引,MySQL 可能选择全表扫描再排序,而不是走索引。