一 从线性结构走到层次结构
树最适合表达一种一对多的关系。一个结点可以带出若干孩子,每个孩子又可以继续带出自己的孩子,于是整棵树自然形成层次。根结点像起点,叶子结点像终点,中间结点承担组织和连接的作用。很多初学者在这里会把一堆术语记混,其实最好的办法不是死背,而是盯着一棵具体的树去理解。
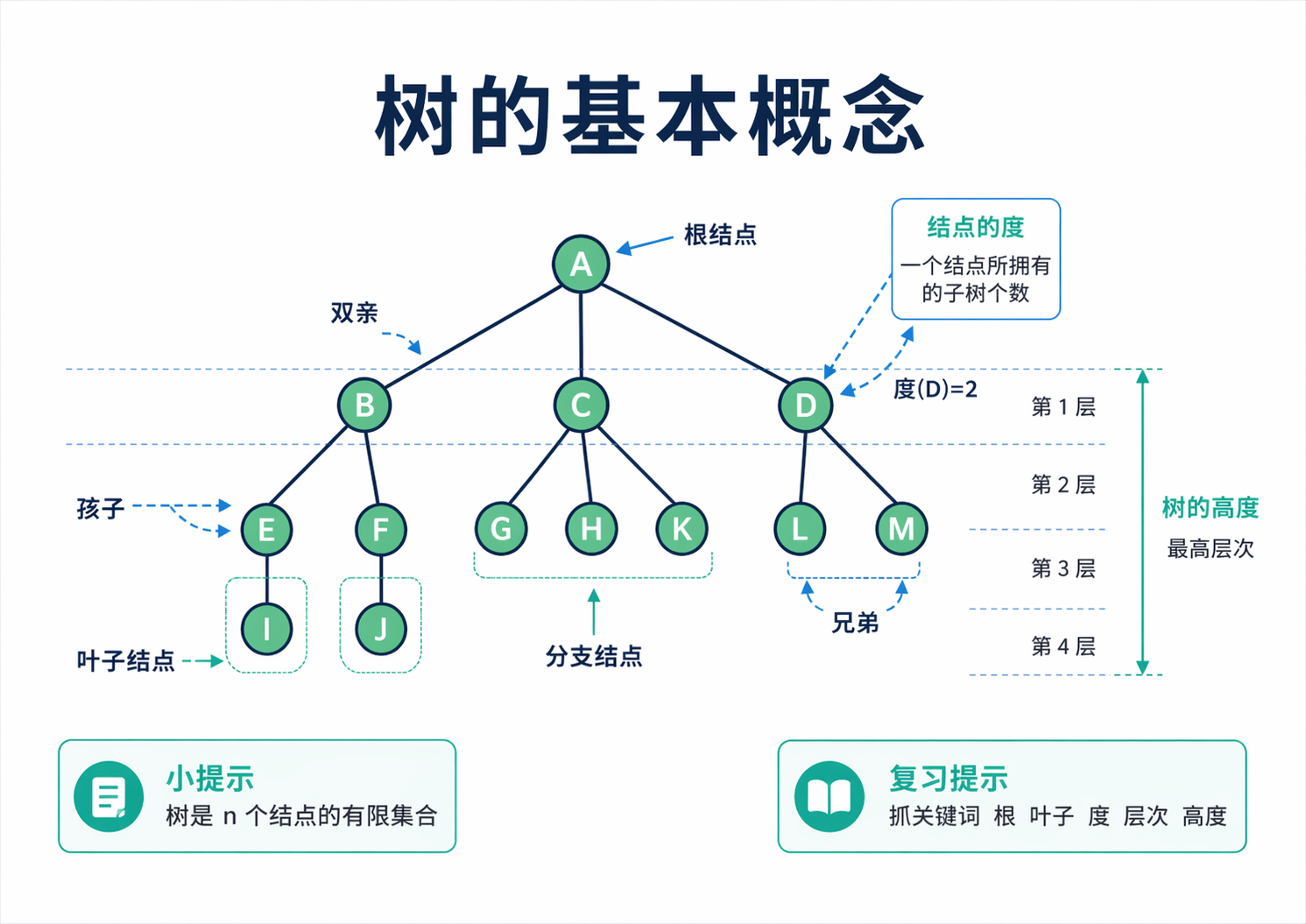
看着上图去想,根结点就是没有前驱的那个起点,叶子结点就是没有孩子的那些末端结点,结点所在的层次表示它离根有多远,整棵树的高度则由最深的那个结点决定。结点的度说的是孩子个数,不是它和多少个结点相连。这个定义非常关键,因为后面很多计数题都靠它。对于一棵有 n 个结点的树,边数一定是 n - 1,所有结点度数之和也一定是 n - 1。这个结论并不神秘,因为除了根结点以外,其他每个结点都恰好对应一条从双亲连下来的边。
二 为什么二叉树会成为整章的重点
树可以有任意多个孩子,但二叉树把这个分支数限制成了最多两个,于是结构一下子规整了很多。这里有一个特别容易考也特别容易错的点。二叉树不是度为 2 的树。它和一般树的区别不只是孩子数上限不同,更在于左右次序是严格区分的,而且某个位置可以空着。只有左孩子和只有右孩子,在一般树里未必需要区分,在二叉树里却是两个不同的结构。
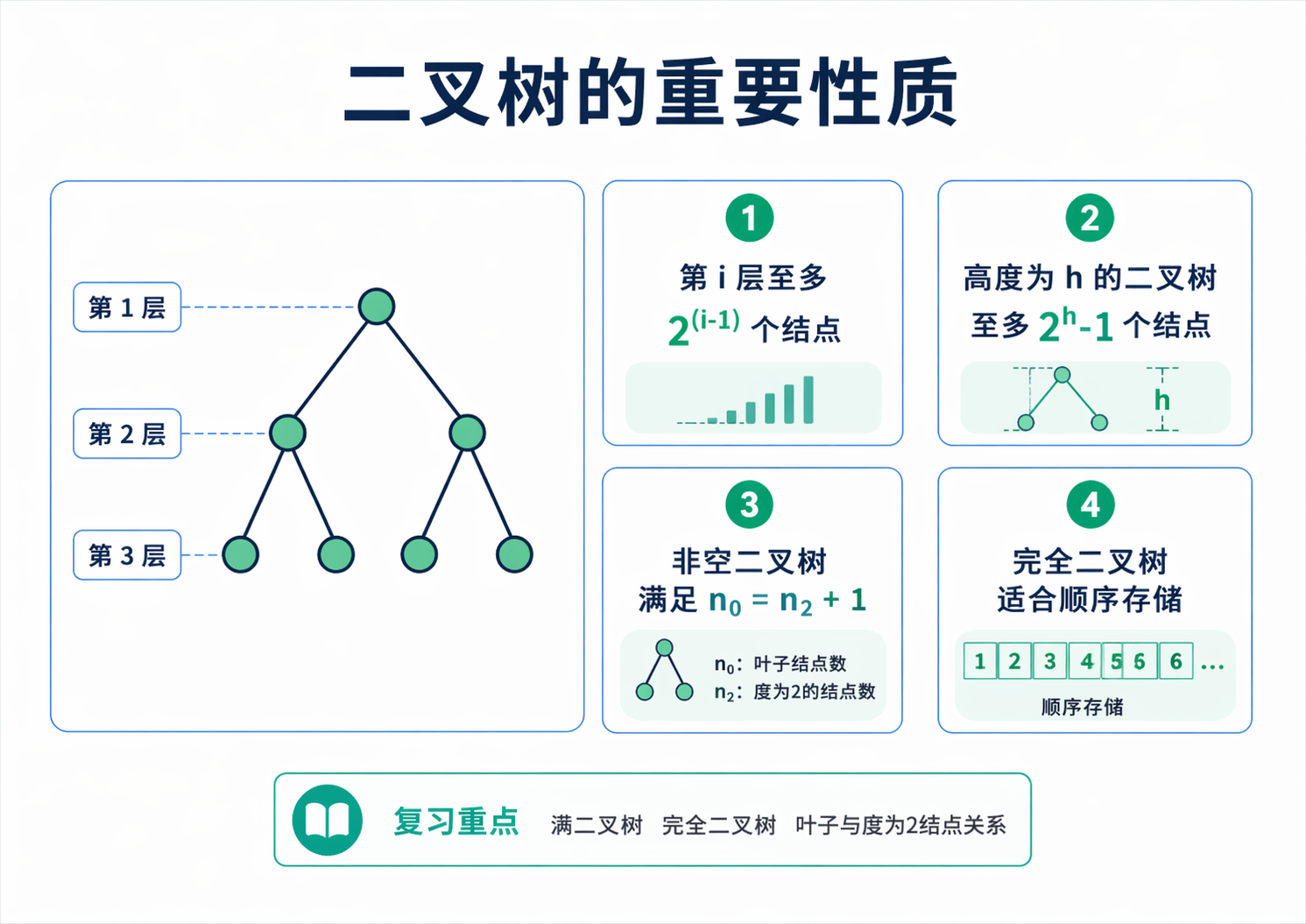
这也是为什么二叉树特别适合做算法分析。结构一旦有序,很多性质就能写成非常整齐的公式。第 i 层最多有 2^(i-1) 个结点,这来自每层最多翻倍的规律。高度为 h 的二叉树最多有 2^h - 1 个结点,这其实就是 1 加 2 加 4 一直到 2^(h-1) 的求和。对任意非空二叉树,还存在一个极常见的关系 n0 = n2 + 1,也就是叶子结点数比度为 2 的结点数多 1。这个式子背后的想法并不复杂,把边数一方面按总结点减一来数,另一方面按每个结点带出的孩子数来数,两边一对上,关系就出来了。
如果题目换成完全二叉树,那么顺序编号立刻变得非常重要。通常把根结点编号为 1,这时结点 i 的双亲就是 i // 2,左孩子是 2i,右孩子是 2i + 1。你会发现,下标本身已经把结构关系编码进去了。所以完全二叉树用顺序存储非常自然,很多题甚至不需要真的把树画出来,直接看编号就能判断父子关系、层次和叶子区间。
三 存储结构决定你怎么看一棵树
学二叉树,不能只停留在纸面结构上,因为算法最终总要落到存储方式上。二叉树最常见的存储方式有两类,一类是顺序存储,一类是链式存储。
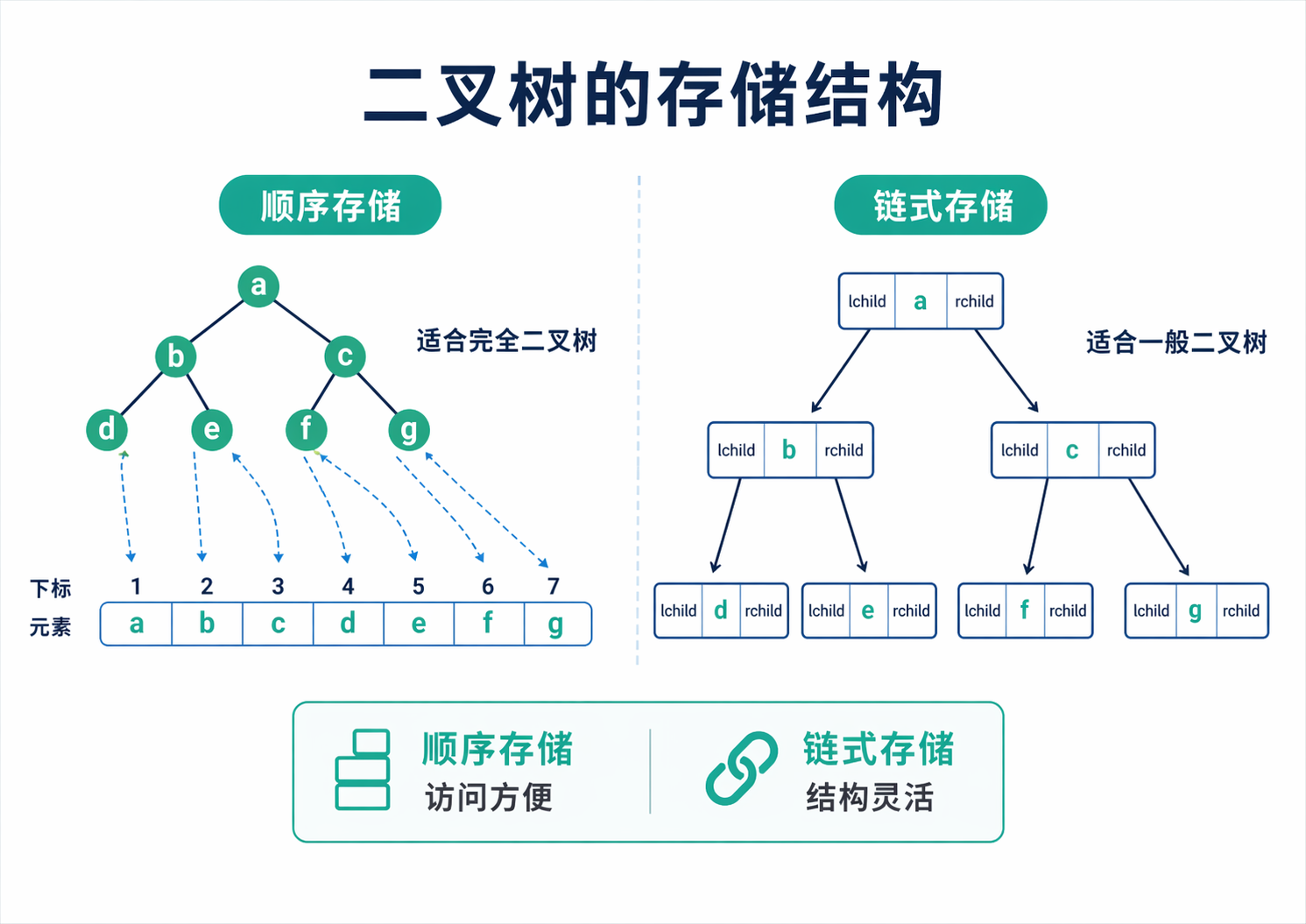
顺序存储最适合完全二叉树,因为它的结构足够紧凑,数组下标和逻辑位置之间几乎可以直接对应。这样做的好处是定位特别快,找双亲、找左右孩子都不需要额外指针。但它有一个明显前提,就是树不能太稀疏。只要大量位置空出来,顺序存储就会浪费很多空间。
链式存储更有普适性。二叉链表把每个结点拆成左指针、数据域和右指针,逻辑关系完全靠指针连接。它不要求树必须连续,也不要求树必须完整,所以一般二叉树更适合用链式存储来表示。到了后面的遍历、建树和很多递归算法里,二叉链表几乎就是默认表示法。理解这一点很重要,因为很多同学会在脑子里把树当成一张静态图,而算法真正操作的其实是指针关系。
四 遍历才是本章算法的真正主线
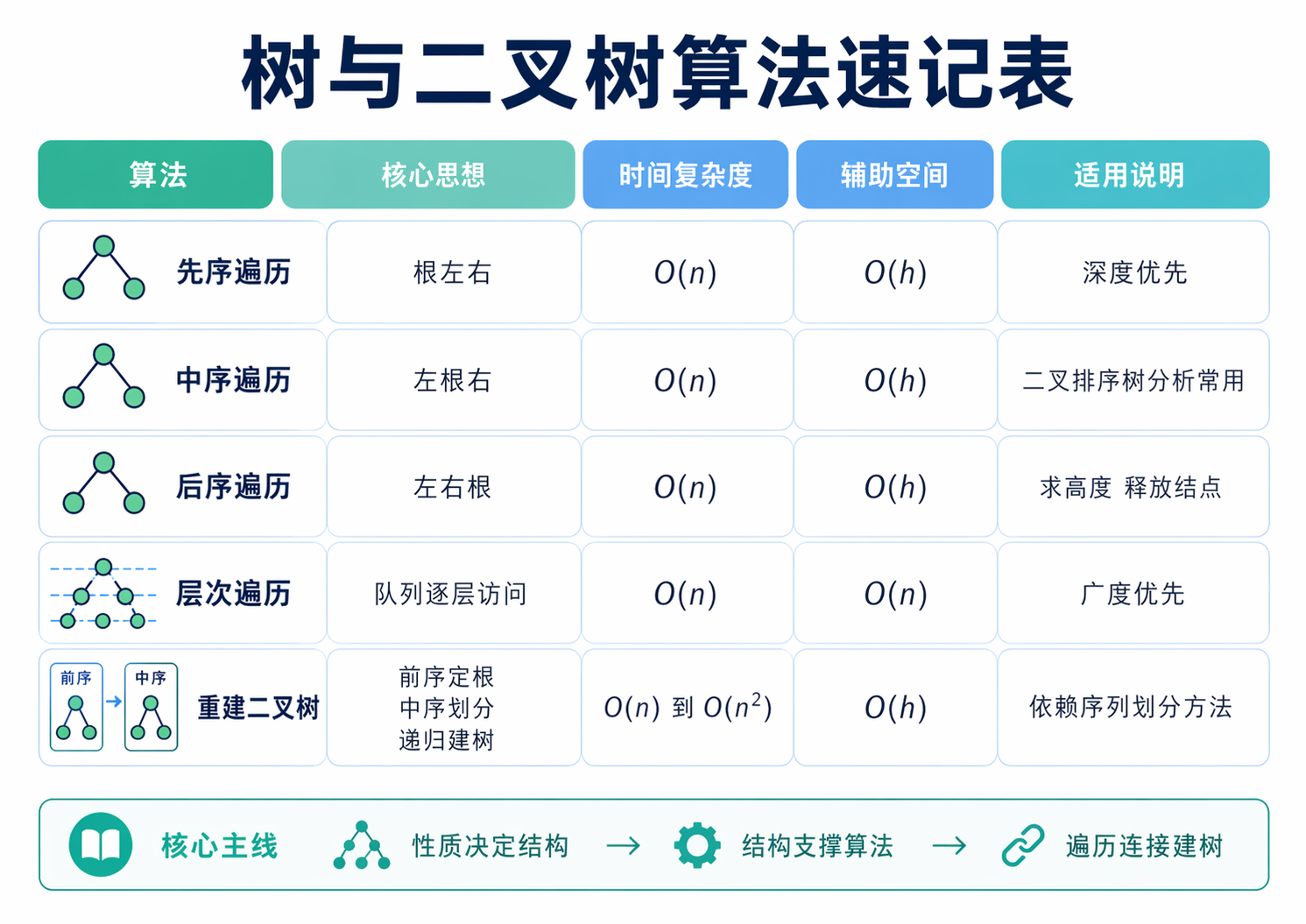
如果说树这一章有什么最核心的算法思想,那一定是遍历。因为树里的很多操作,本质上都要先把整棵树有条理地走一遍。所谓先序、中序、后序,表面上看是三种不同的方法,实际上它们的递归骨架完全一样,变化的只有访问根结点的时机。
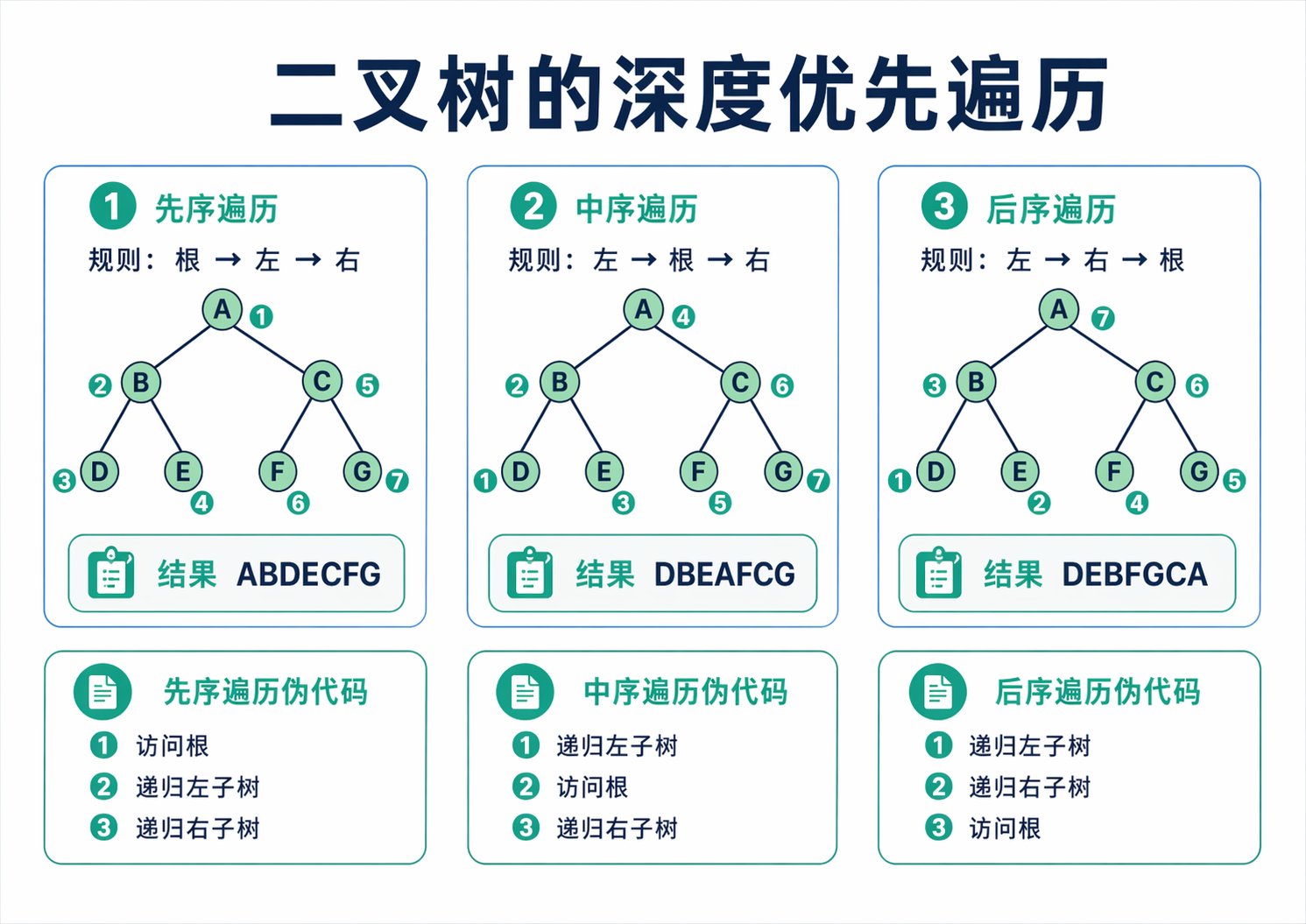
先序遍历是先访问根,再走左子树,再走右子树。中序遍历是先走左子树,再访问根,最后走右子树。后序遍历则把访问根放到最后。真正值得你记住的不是三个口号,而是一种递归视角。对于任意结点来说,左子树本身又是一棵二叉树,右子树本身也又是一棵二叉树,所以整个过程天然适合递归。换句话说,遍历不是在记三个模板,而是在熟悉一种把大问题拆成同类小问题的思维方式。
下面是三种递归遍历的典型写法。代码看起来很像,这恰好说明它们的共同本质。
c
void PreOrder(BiTree T) {
if (T == NULL) return;
visit(T);
PreOrder(T->lchild);
PreOrder(T->rchild);
}
void InOrder(BiTree T) {
if (T == NULL) return;
InOrder(T->lchild);
visit(T);
InOrder(T->rchild);
}
void PostOrder(BiTree T) {
if (T == NULL) return;
PostOrder(T->lchild);
PostOrder(T->rchild);
visit(T);
}这三种遍历的时间复杂度都是 O(n),因为每个结点都只会被访问一次。空间复杂度和递归深度有关,通常写成 O(h),其中 h 是树的高度。树越高,递归栈就可能越深。这个结论在题目里也很常用,因为它提醒我们,二叉树算法的时间未必难,空间有时才是隐藏成本。
还有一个很值得反复体会的点。先序适合先确定根,中序适合表达左右划分,后序适合先处理子树再回到根。这三种特征会在后面的建树、表达式求值、删除释放等场景里不断出现。所以遍历不是孤立知识点,它是这一章连接性质题和代码题的桥。
五 层次遍历看起来不像递归 其实更像队列的胜利
除了深度优先遍历,二叉树还有一种特别重要的走法,就是层次遍历。它按照从上到下、从左到右的顺序访问结点,本质上是一种广度优先搜索。和先中后序最大的不同是,它不再执着于先把某一条分支走到底,而是先把同一层的结点依次处理完。
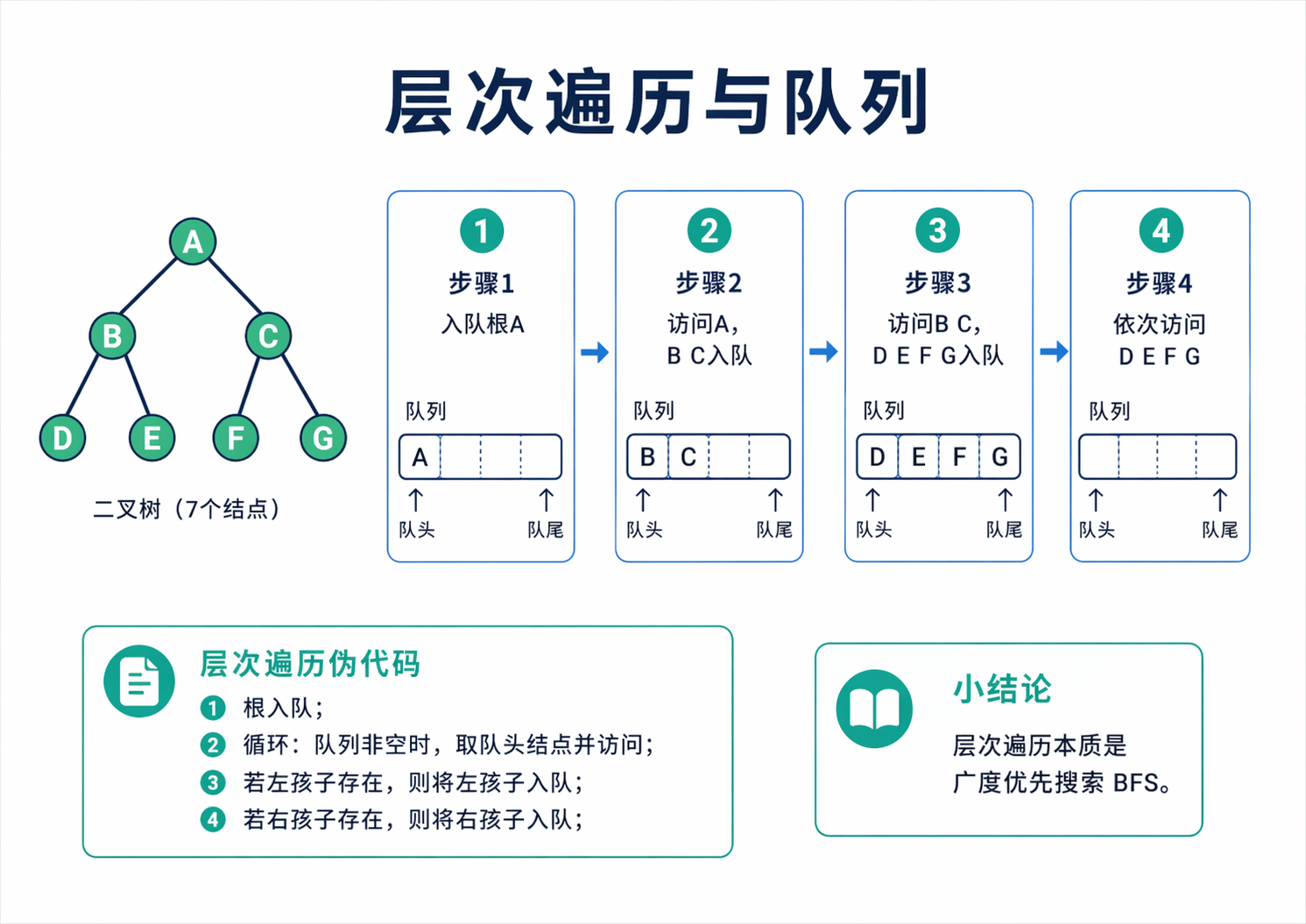
层次遍历最自然的实现工具是队列。先把根结点入队,接着循环执行下面这件事,队头出队并访问它,如果它有左孩子就把左孩子入队,如果它有右孩子就把右孩子入队。队列保证了先到先处理,所以结点会一层一层地被展开。这和图的 BFS 实际上是同一套思想,只不过树里的邻接关系更规整。
c
void LevelOrder(BiTree T) {
if (T == NULL) return;
InitQueue(Q);
EnQueue(Q, T);
while (!IsEmpty(Q)) {
BiTree p;
DeQueue(Q, p);
visit(p);
if (p->lchild != NULL) EnQueue(Q, p->lchild);
if (p->rchild != NULL) EnQueue(Q, p->rchild);
}
}层次遍历的时间复杂度同样是 O(n),因为每个结点依旧只进队出队一次。它的额外空间和某一层可能出现的最大结点数有关,也就是和树的宽度有关。这一点在分析完全二叉树时尤其明显,因为最底层往往最宽。
六 由遍历序列重建二叉树 是最能体现理解深度的题
如果前面的遍历是在问,你能不能把树走出来,那么建树问题就在问,你能不能把已经走出来的结果再还原回去。这类题之所以重要,是因为它把结构、遍历和递归分治三件事放到了同一个问题里。
先序和中序是最经典的一组。先序的第一个结点一定是根,所以根很容易找。真正关键的是中序,因为只有中序能把根的左边和右边清楚地切开。根在中序序列左边的那一段,整体属于左子树,右边那一段,整体属于右子树。这样一来,原问题就被自然拆成了两个更小的同类问题,分别去重建左子树和右子树,递归就能继续下去。
下面是一种非常典型的写法。为了避免每次都在线性表里查根位置,可以先把中序序列里每个字符的位置存到一个索引表里,这样时间复杂度可以从朴素的 O(n^2) 降到 O(n)。
c
BiTree Build(char pre[], int pl, int pr,
char in[], int il, int ir,
int pos[]) {
if (pl > pr) return NULL;
char rootValue = pre[pl];
BiTree root = NewNode(rootValue);
int k = pos[(int)rootValue];
int leftSize = k - il;
root->lchild = Build(pre, pl + 1, pl + leftSize,
in, il, k - 1, pos);
root->rchild = Build(pre, pl + leftSize + 1, pr,
in, k + 1, ir, pos);
return root;
}这里最值得记住的不是代码细节,而是两条判断。第一条,先序和后序可以帮助你快速知道谁是根。第二条,中序负责把左右子树分开。也正因为这样,单独给出先序和后序,通常并不能唯一确定一棵普通二叉树。只有中序参与进来,左右边界才会真正清晰。
如果你把这件事看透了,后面许多题都会变得统一。比如根据中序和后序重建二叉树,本质没有变,只不过根从后序最后一个元素里拿。再比如有的题不要求真的把树建出来,而是让你直接输出另一种遍历序列,那你仍然是在做同一件事,只是把显式建树换成了递归划分。
七 这一章真正该怎么复习
树和二叉树这一章最怕的复习方式,是把定义、性质、存储、遍历、建树拆成互不相干的碎片去背。那样会感觉内容很多,题目一变就乱。更有效的方式,是把它们连成一条因果链。先从一棵具体的树出发,确认根、叶子、层次和高度这些最基本的结构概念。接着过渡到二叉树,理解为什么左右有序、为什么空位置也有意义。然后把数量关系和完全二叉树编号练熟,让自己在不画图时也能快速判断结构。最后把遍历和建树吃透,因为算法题几乎都围绕这两部分展开。
如果非要说这一章最重要的一句话,我会把它概括成这样。树描述的是层次结构,遍历描述的是观察结构的顺序,建树描述的是从顺序重新恢复结构。你一旦把这三层关系理顺,整章就会从一堆定义和公式,变成一套彼此呼应的思维框架。复习到这里时,你不只是会做几道题,而是真正开始理解树这种结构为什么值得单独学习。