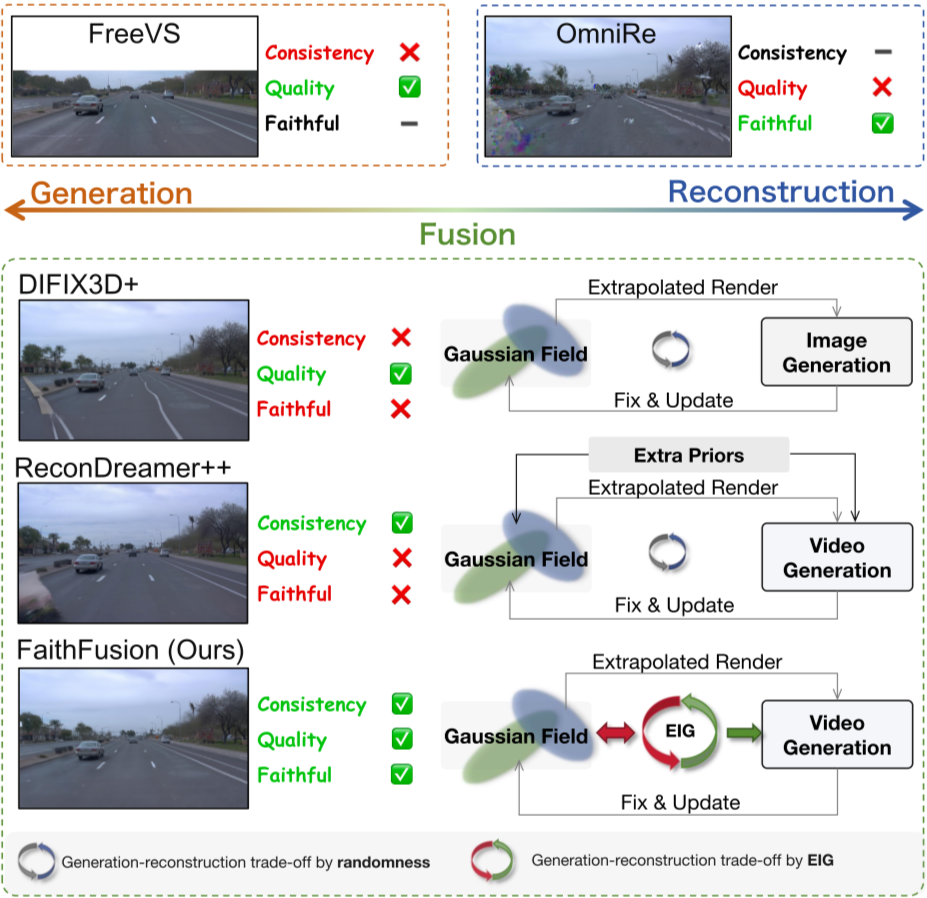
这篇论文题为"FaithFusion: Harmonizing Reconstruction and Generation via Pixel-wise Information Gain",由百度和南京大学的研究人员提出。该论文聚焦于可控驾驶场景重建与3D场景生成领域,旨在解决在保持几何保真度的同时,在大视角偏移下合成视觉真实外观的关键挑战。
核心问题与挑战
现有的神经渲染方法(如NeRF和3DGS)在稀疏观测、严重遮挡或远离训练轨迹的视角下,往往会导致几何不一致和伪影。尽管Diffusion模型在图像和视频生成与修复方面表现出色,但由于缺乏像素级别的、与几何一致的指导,它们容易导致过度修复和几何漂移。当前融合重建-生成方法(遵循"渲染-修复-反馈"流程)通常依赖视图级别的启发式判断来决定"何时、何地、如何进行编辑",这导致对生成过程的控制不足,Diffusion模型常会覆盖正确区域,引发过度修复和几何漂移。因此,急需一个原则性的决策机制来确定哪些区域需要生成,哪些需要保留。
FaithFusion核心贡献与方法
FaithFusion引入了一个由像素级**预期信息增益(Expected Information Gain, EIG)**驱动的3DGS-Diffusion融合框架,以解决上述问题。EIG被重新定义为一种前瞻性的信息论度量,用于衡量编辑操作能减少多少后验不确定性,从而作为时空合成的统一策略。
像素级EIG的计算(Expected Information Gain in 3DGS)
论文首先介绍了3D高斯飞溅(3D Gaussian Splatting, 3DGS)的参数化,它使用世界坐标系中的位置 、旋转
和尺度
来表示场景中的高斯球,并通过球谐系数
和不透明度 o \\in \\mathbb{R} 建模外观。渲染过程通过
-blending 计算图像像素颜色:
为了量化3DGS参数 的不确定性并估计新观测的潜在信息增益,FaithFusion采用了拉普拉斯近似(Laplace approximation),将参数的后验分布建模为高斯分布:
其中 是负对数似然在
处的Hessian矩阵。
EIG的定义是先验熵与观测后预期后验熵之间的差值:
通过利用拉普拉斯近似、Fisher信息(Fisher information)的性质以及不等式
论文推导出了EIG的一个可计算的迹形式上界:
为了实现像素级指导,FaithFusion将EIG扩展到每个像素,通过沿每条渲染光线累积高斯球的Fisher信息贡献。这使得EIG图能够精确反映局部渲染质量,高EIG值对应低质量或不确定区域。
EIGent: EIG引导的双分支可控生成
EIGent是一个视频修复模型,利用EIG作为空间先验,实现可控修复。它区分:
高增益区域(High-gain regions):渲染质量低或信息缺失,需要重点修复和内容生成。
低增益区域(Low-gain regions):背景内容可靠,模型应保留原有结构。
EIGent采用双分支控制架构,将轻量级EIG引导的上下文编码器与预训练的DiT主干网络并行操作。
其多尺度指导策略通过EIG引导的上下文注入融合信号:
其中 是降采样的EIG图,
是噪声潜在表示,
是VAE潜在表示,
是上下文编码器,M 是二值掩码,用于抑制极度不确定区域(EIG高于阈值)。
通过与DIFIX分支的交叉注意力融合外部修复线索(如DIFIX潜在特征),EIGent在确保稳定背景的同时,也能生成时间一致的前景,提升修复视频的感知质量和时空一致性。
渐进式EIG感知Diffusion-to-3DGS知识整合
为了将EIGent生成的高质量内容可控地注入3DGS,FaithFusion采用了渐进式知识整合策略。
不同于依赖启发式或视图级控制的现有方法,FaithFusion以像素级EIG作为指导信号,实现更精细和可解释的融合。
在3DGS的优化过程中,引入新视角损失 ,其关键在于EIG像素级加权:归一化的EIG图作为像素级权重矩阵
调制图像损失:
,使3DGS将优化重点放在信息增益最高的区域(即最不确定的区域)。
此外,还利用从邻近帧聚合的点云投影作为稀疏深度监督 L_{novel}\^{depth},以保持新视角的几何一致性。
这种微调过程在早期阶段使用EIGent修复的视图来优先处理空间结构和跨帧连贯性,当扩展达到最大范围并稳定后,再使用DIFIX3D+精炼的视图进行进一步优化。
实验结果
FaithFusion在Waymo数据集上进行了全面的实验。结果显示,该方法在NTA-IoU、NTL-IoU和FID等指标上取得了显著提升,即使在6米的车道偏移下,FID仍能保持在107.47,达到了SOTA性能。消融研究进一步证实了EIG指导的各个组件对改善模型性能的贡献,特别是在欠约束区域和高置信度区域的FID指标(FID-UCR和FID-HPR)上均有显著下降。
总结
FaithFusion通过将启发式编辑决策转化为信息论量,引入了像素级EIG驱动的3DGS-Diffusion融合范式,统一了保真重建和可控生成。这种跨模态EIG指导在生成侧用作内容抑制的空间权重,在重建侧用作选择性知识蒸馏的损失权重,展现出强大的通用性和可解释性。它有效地解决了在动态驾驶场景中大视角偏移下几何保真度与视觉真实性之间的矛盾,为统一、可控的3D场景建模提供了新的框架。