最近在整理 3D Gaussian Splatting SLAM / 3DGS-SLAM 方向的论文和数据集时,我发现一个很现实的问题:论文增长太快了。

今天是 RGB-D Gaussian SLAM,明天是 monocular 3DGS-SLAM,后天又是 LiDAR-Gaussian、semantic Gaussian、dynamic Gaussian、large-scale driving scene Gaussian SLAM。不同论文用的数据集、指标、代码开源情况也不一样。如果只是把链接丢进收藏夹,过一段时间基本就很难维护了。
所以我整理并开源了一个文献调研仓库:
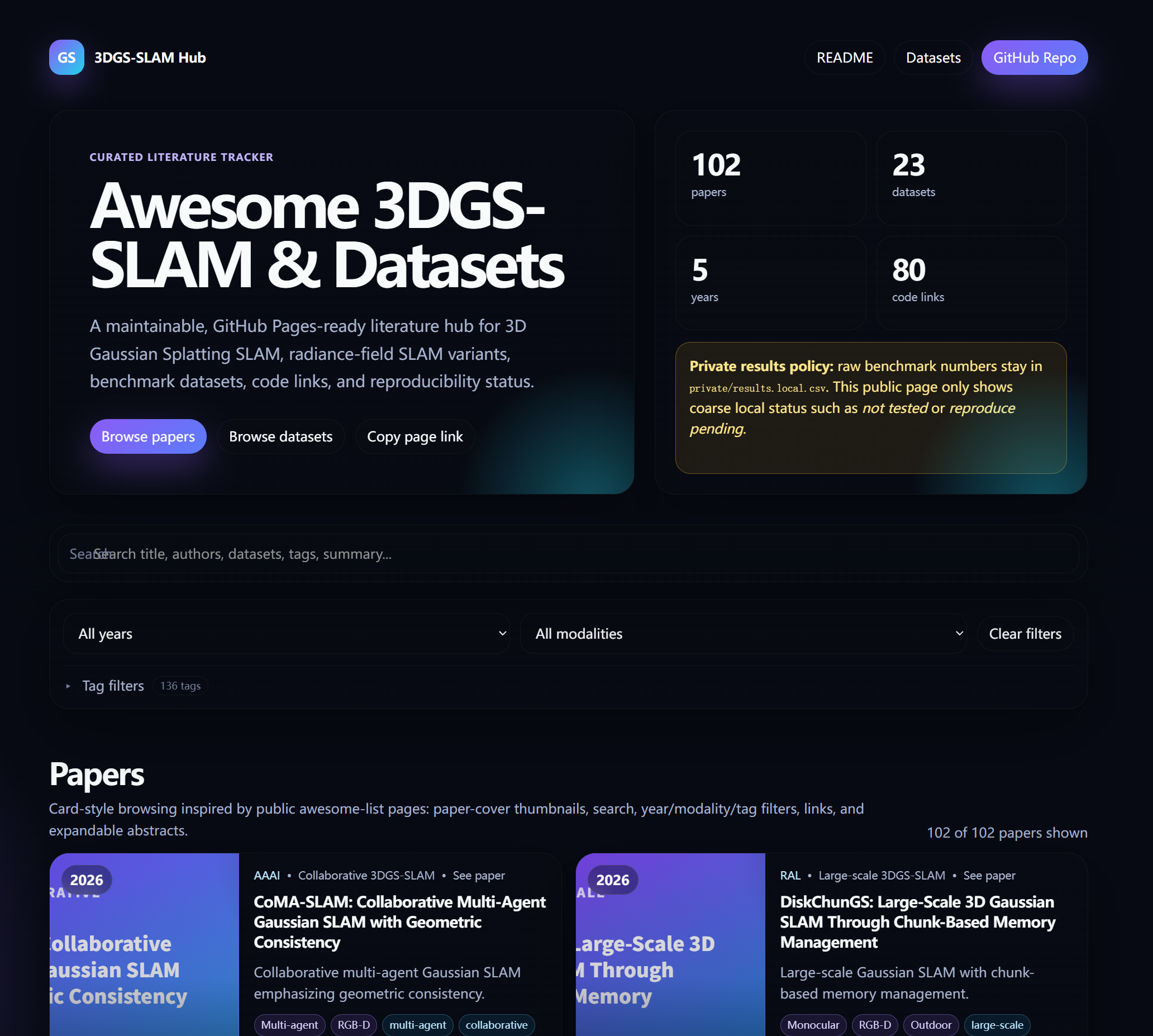
这个仓库主要面向:
-
3DGS-SLAM 文献调研
-
Gaussian Splatting 相关 SLAM / Localization / Mapping 方法整理
-
常用数据集归纳
-
论文代码链接收集
-
本地复现实验记录
-
README 和网页自动生成
-
论文查重和字段检查
也欢迎大家 Star、Fork、PR,一起维护这个方向的文献导航。
一、为什么要做这个项目?
做文献调研时,我最头疼的不是找不到论文,而是:
-
找到了论文,但不知道它属于哪个方向;
-
看到了方法,但不知道用的是 RGB-D、monocular、stereo、LiDAR 还是 multi-sensor;
-
论文里有代码,但忘记仓库地址;
-
同一篇论文在不同 awesome-list 里重复出现;
-
README 表格越写越长,手动维护很痛苦;
-
想做一个网页方便检索,但又不想每次都手改 HTML;
-
自己本地跑过的实验结果不想公开,但又希望在本地记录下来。
所以这个仓库的设计目标就是:
用结构化数据维护文献,用脚本自动生成 README 和网页,把公开信息和私有实验结果分离。
二、项目效果
项目包含两个主要入口。
第一个是 GitHub README,适合快速浏览代表性论文和数据集。
第二个是 GitHub Pages 网页,适合交互式检索:
-
按标题搜索;
-
按作者搜索;
-
按年份筛选;
-
按输入模态筛选;
-
按 tag 筛选;
-
查看论文封面图;
-
查看 paper / code / project 链接;
-
查看摘要;
-
查看数据集信息。
网页效果类似 awesome-list 风格,比纯 README 表格更适合快速找论文。
三、仓库结构
当前项目结构大致如下:
awesome-3DGS-SLAM-and-Datasets/
├── README.md
├── data/
│ ├── papers.yml
│ └── datasets.yml
├── docs/
│ ├── index.html
│ └── assets/
│ └── thumbnails/
├── scripts/
│ ├── build_site.py
│ ├── build_readme.py
│ └── validate_data.py
├── private/
│ └── results.local.csv
└── .gitignore核心思想很简单:
data/papers.yml + data/datasets.yml
↓
scripts/build_readme.py
↓
README.md
data/papers.yml + data/datasets.yml
↓
scripts/build_site.py
↓
docs/index.html
↓
GitHub Pages 网页以后更新论文时,主要改两个文件:
data/papers.yml
data/datasets.yml不需要手动改 README 里的大表格,也不需要手动写网页 HTML。
四、如何使用这个项目?
1. 克隆仓库
git clone https://github.com/sychina/awesome-3DGS-SLAM-and-Datasets.git
cd awesome-3DGS-SLAM-and-Datasets2. 安装依赖
目前脚本主要依赖 Python 和 PyYAML:
pip install pyyaml3. 查看 README
GitHub 首页的 README 里会显示代表性论文和数据集表格。
4. 打开网页
项目支持 GitHub Pages,可以直接打开:
https://sychina.github.io/awesome-3DGS-SLAM-and-Datasets/如果你 fork 了这个仓库,也可以在自己的仓库里开启 GitHub Pages:
Settings -> Pages -> Deploy from a branch
Branch: main
Folder: /docs保存后,GitHub 会自动生成网页地址。
五、如何新增论文?
新增论文只需要修改:
data/papers.yml例如新增一篇论文:
- id: splatam2024
title: "SplaTAM: Splat, Track & Map 3D Gaussians for Dense RGB-D SLAM"
year: 2024
venue: "CVPR"
authors:
- "Author A"
- "Author B"
category: "RGB-D / dense SLAM"
modality:
- "RGB-D"
representation: "3DGS"
datasets:
- "Replica"
- "TUM RGB-D"
- "ScanNet"
metrics:
- "ATE"
- "PSNR"
- "SSIM"
- "LPIPS"
paper: "https://arxiv.org/..."
code: "https://github.com/..."
project: "https://..."
thumbnail: "assets/thumbnails/splatam2024.jpg"
tags:
- "rgb-d"
- "dense-slam"
- "tracking"
- "mapping"
- "3dgs"
summary: "Online RGB-D tracking and mapping with explicit 3D Gaussians."
local_eval: "reproduce pending"
readme_group: "rgbd"其中比较重要的字段有:
| 字段 | 说明 |
|---|---|
id |
论文唯一 ID,建议小写加年份 |
title |
论文标题 |
year |
发表年份 |
venue |
会议、期刊或 arXiv |
category |
论文类别 |
modality |
输入模态,例如 RGB-D、monocular、LiDAR |
representation |
表示方法,例如 3DGS、2DGS、Gaussian surfels |
datasets |
使用的数据集 |
metrics |
评测指标 |
paper |
论文链接 |
code |
代码链接 |
project |
项目主页 |
thumbnail |
论文封面图或 teaser 图 |
tags |
用于网页筛选的标签 |
summary |
一句话简介 |
local_eval |
本地复现状态,只放粗粒度状态 |
readme_group |
README 中的分组 |
六、README 中的论文如何分类?
README 里的 Representative papers 不是简单堆论文,而是按方向分类展示,例如:
Surveys and collections
RGB-D / dense SLAM
Monocular / RGB-only / multi-sensor
Dynamic, semantic, large-scale, and specialized settings可以通过 readme_group 手动控制论文进入哪个小节。
例如:
readme_group: survey会进入:
Surveys and collections
readme_group: rgbd会进入:
RGB-D / dense SLAM
readme_group: mono会进入:
Monocular / RGB-only / multi-sensor
readme_group: specialized会进入:
Dynamic, semantic, large-scale, and specialized settings这样新增论文时,不需要手动移动 README 中的表格行,只需要在 YAML 里写好分组即可。
七、如何新增数据集?
新增数据集只需要修改:
data/datasets.yml例如:
- id: tum_rgbd
name: "TUM RGB-D"
type: "Real indoor RGB-D"
url: "https://cvg.cit.tum.de/data/datasets/rgbd-dataset"
sensors: "RGB, depth, Kinect accelerometer"
gt: "Motion-capture trajectory"
common_use: "ATE tracking benchmark, RGB-D SLAM baseline"
notes: "Include exact sequence and association script."其中 gt 是可选字段。如果某个数据集没有明确 ground truth,可以不写。
推荐字段如下:
| 字段 | 说明 |
|---|---|
id |
数据集唯一 ID |
name |
数据集名称 |
type |
类型,例如 indoor、outdoor、synthetic、driving |
url |
官方链接 |
sensors |
传感器或数据类型 |
gt |
Ground truth,可选 |
common_use |
常见用途 |
notes |
备注 |
八、如何更新 README 表格?
修改完 data/papers.yml 或 data/datasets.yml 之后,运行:
python scripts/build_readme.py这个脚本不会重写整个 README,而是只更新指定区域,例如:
## Representative papers
...
## DatasetsREADME 里的其他内容,比如项目介绍、使用说明、贡献指南、License 等都会保留。
也就是说,README 的结构由人维护,论文表格和数据集表格由脚本维护。
九、如何更新网页?
修改完数据后,运行:
python scripts/build_site.py它会读取:
data/papers.yml
data/datasets.yml然后把最新数据嵌入到:
docs/index.html接着提交并 push:
git add data/*.yml README.md docs/index.html
git commit -m "Update papers and datasets"
git pushGitHub Pages 会自动更新网页。
推荐完整流程:
# 1. 修改数据库
vim data/papers.yml
vim data/datasets.yml
# 2. 检查数据格式和重复论文
python scripts/validate_data.py
# 3. 更新 README
python scripts/build_readme.py
# 4. 更新网页
python scripts/build_site.py
# 5. 提交
git add data/*.yml README.md docs/index.html
git commit -m "Update papers and datasets"
git push十、论文查重方法
文献库维护久了之后,最容易出现的问题就是重复论文。
重复可能来自几种情况:
-
同一篇论文有 arXiv 版本和会议版本;
-
同一篇论文标题大小写不同;
-
标题里有冒号、破折号、缩写,导致看起来不完全一样;
-
同一篇论文从不同 awesome-list 导入多次;
-
项目页和 arXiv 页分别被当成两篇论文;
-
论文更新标题后产生重复条目。
所以我建议至少做三层查重。
1. 按 id 查重
每篇论文都应该有唯一 ID,例如:
id: splatam2024脚本检查是否有重复 ID。
2. 按归一化标题查重
对标题做统一处理:
-
转小写;
-
去掉标点;
-
去掉多余空格;
-
去掉特殊符号;
-
再比较是否重复。
例如:
GS-SLAM: Dense Visual SLAM with 3D Gaussian Splatting
gs slam dense visual slam with 3d gaussian splatting归一化后应该能识别为同一篇。
3. 按 arXiv / DOI / paper URL 查重
如果两条记录有相同的 arXiv ID、DOI 或 paper 链接,也应该视为重复。
十一、私有实验结果如何管理?
我自己在复现论文时,会有一些本地测试结果,比如:
-
ATE;
-
PSNR;
-
SSIM;
-
LPIPS;
-
FPS;
-
GPU 型号;
-
运行失败原因;
-
参数配置;
-
数据集序列;
-
代码修改记录。
这些信息不一定适合公开,所以仓库里采用了公开信息和私有信息分离的方式。
公开字段只保留粗粒度状态:
local_eval: "not tested"或者:
local_eval: "reproduce pending"或者:
local_eval: "tested locally"真实实验结果放在:
private/results.local.csv并且通过 .gitignore 排除:
private/
*.local.csv
*.local.json
docs/index.local.html这样网页和 README 只展示公开状态,不会泄露本地实验数据。
十二、为什么这套流程适合其他方向?
虽然这个仓库目前是为 3DGS-SLAM 做的,但这套流程其实很通用。
任何需要长期维护文献、项目、数据集、工具列表的方向都可以适配,例如:
-
目标检测论文库;
-
多模态大模型论文库;
-
医学影像论文库;
-
自动驾驶数据集导航;
-
机器人 SLAM 文献库;
-
NeRF / 3DGS / Reconstruction 论文库;
-
LLM Agent 工具导航;
-
推荐系统论文整理;
-
强化学习 benchmark 汇总;
-
工业缺陷检测数据集整理。
只需要把 papers.yml 的字段换成你所在领域需要的字段,然后复用:
YAML 数据库
README 自动生成
GitHub Pages 网页
论文查重脚本
私有实验结果隔离就可以快速搭建自己的 awesome-list 项目。
十三、适合谁使用?
这个项目适合:
-
正在做 3DGS-SLAM 的研究生;
-
想快速入门 3DGS-SLAM 的同学;
-
需要找 baseline 的研究者;
-
想追踪 Gaussian Splatting + Robotics 方向的开发者;
-
需要整理论文和数据集的实验室;
-
想搭建自己领域 awesome-list 的同学。
十四、欢迎 Star、Fork 和 PR
这个项目还会持续维护,我也欢迎大家一起补充:
-
新论文;
-
新代码仓库;
-
新项目主页;
-
新数据集;
-
新 benchmark;
-
论文封面图;
-
复现状态;
-
分类建议;
-
查重规则;
-
网页样式优化。
仓库地址:
https://github.com/sychina/awesome-3DGS-SLAM-and-Datasets项目网页:
https://sychina.github.io/awesome-3DGS-SLAM-and-Datasets/欢迎大家 Star、Fork、提 Issue、提 PR。
如果你也在维护某个方向的文献库,可以直接 fork 这个仓库,把数据文件换成你自己的方向,就能得到一个支持 README 自动更新、网页检索、论文查重和私有实验结果隔离的文献导航项目。