数据库选型是每个Java项目架构设计中最关键的决策之一,它直接影响系统的性能、可维护性和未来的扩展能力。PostgreSQL和MySQL作为当今最流行的两款开源关系型数据库,各自拥有庞大的用户群体和丰富的生态系统。很多开发者在面对这两个选择时,往往只能凭借经验或者团队习惯做出决定,而忽略了它们在底层架构、特性支持和适用场景上的本质差异。
底层架构与核心差异
MySQL架构设计
MySQL采用插件式存储引擎架构,这是它最显著的特点。服务器层负责连接管理、查询解析、优化、缓存以及内置函数等通用功能,而数据的存储和提取则由不同的存储引擎实现。这种架构使得MySQL具有极高的灵活性,用户可以根据业务需求选择不同的存储引擎。
InnoDB是MySQL 5.5及以后版本的默认存储引擎,它支持事务、行级锁和外键约束。InnoDB采用聚簇索引结构,数据和主键索引存储在一起,二级索引则存储主键值。这种设计使得主键查询非常高效,但二级索引查询需要进行两次查找。
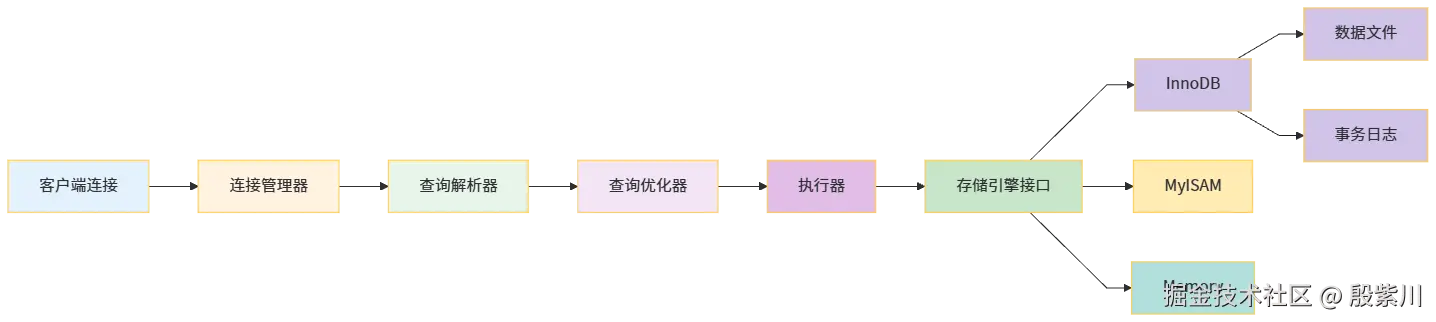
MySQL的架构设计更偏向于简单和高效,它在处理简单查询和高并发读写方面表现出色。但这种插件式架构也带来了一些问题,比如不同存储引擎之间的特性不统一,事务和复制的实现复杂度增加。
PostgreSQL架构设计
PostgreSQL采用一体化的架构设计,所有功能都集成在同一个服务器进程中。它没有插件式存储引擎的概念,而是提供了统一的存储引擎和丰富的扩展机制。PostgreSQL的架构更加严谨和复杂,它实现了完整的SQL标准,支持更多的高级特性。
PostgreSQL采用堆表组织方式,数据存储在堆中,索引则存储指向堆中数据行的物理地址。这种设计使得二级索引查询只需要一次查找,但主键查询的效率相对较低。PostgreSQL还支持多种索引类型,包括B树、哈希、GiST、SP-GiST、GIN和BRIN等。
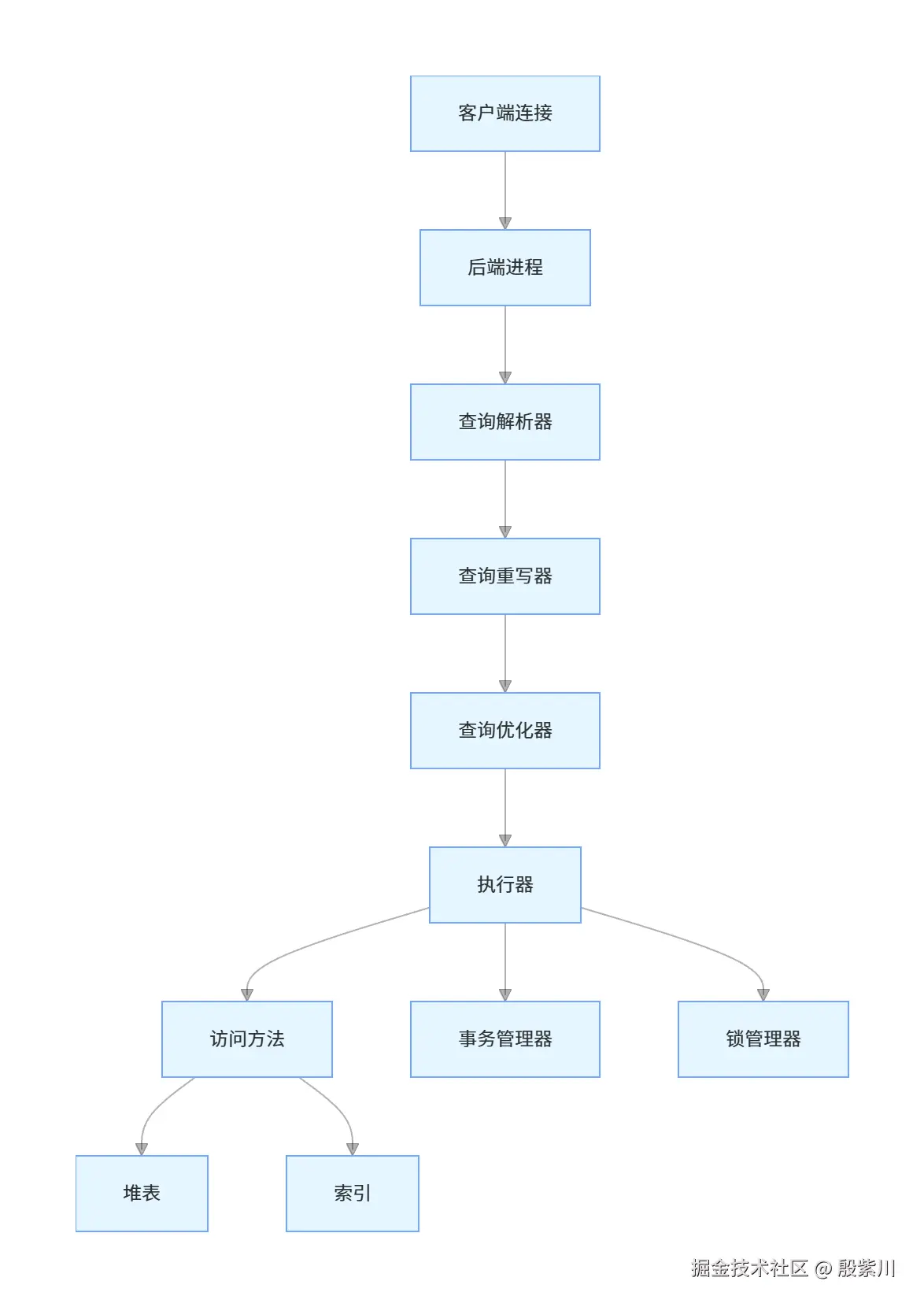
PostgreSQL的架构设计更注重数据完整性和功能丰富性,它在处理复杂查询、数据分析和地理信息系统等方面表现出色。但这种一体化架构也使得它的学习曲线更陡峭,配置和优化相对复杂。
核心差异总结
| 特性 | MySQL | PostgreSQL |
|---|---|---|
| 架构 | 插件式存储引擎 | 一体化架构+扩展机制 |
| 数据组织 | 聚簇索引 | 堆表+索引 |
| SQL标准 | 部分支持 | 高度兼容 |
| 事务隔离 | 支持4种级别,默认可重复读 | 支持4种级别,默认读已提交 |
| 并发控制 | 多版本并发控制+锁 | 多版本并发控制+锁 |
| 索引类型 | B树、哈希、全文 | B树、哈希、GiST、SP-GiST、GIN、BRIN、全文 |
| 扩展能力 | 有限 | 极强 |
| 学习曲线 | 平缓 | 陡峭 |
数据类型与SQL特性对比
数值类型
两款数据库都支持标准的数值类型,但在一些细节上存在差异。MySQL提供了更多的整数类型变体,如TINYINT、SMALLINT、MEDIUMINT、INT和BIGINT,而PostgreSQL只提供SMALLINT、INTEGER和BIGINT。对于浮点数,MySQL支持FLOAT和DOUBLE,而PostgreSQL支持REAL和DOUBLE PRECISION。
PostgreSQL的一个显著优势是它支持任意精度的数值类型NUMERIC,它可以存储非常大的数字而不会丢失精度。MySQL的DECIMAL类型虽然也支持任意精度,但在处理非常大的数字时性能较差。
sql
-- MySQL
CREATE TABLE numeric_example (
id INT PRIMARY KEY AUTO_INCREMENT,
tiny_int TINYINT,
small_int SMALLINT,
medium_int MEDIUMINT,
int_val INT,
big_int BIGINT,
float_val FLOAT,
double_val DOUBLE,
decimal_val DECIMAL(20, 10)
);
-- PostgreSQL
CREATE TABLE numeric_example (
id SERIAL PRIMARY KEY,
small_int SMALLINT,
integer_val INTEGER,
big_int BIGINT,
real_val REAL,
double_val DOUBLE PRECISION,
numeric_val NUMERIC(20, 10)
);字符串类型
MySQL的字符串类型包括CHAR、VARCHAR、TEXT、BLOB等。VARCHAR类型的最大长度在MySQL 5.0.3之后增加到了65535字节。TEXT类型分为TINYTEXT、TEXT、MEDIUMTEXT和LONGTEXT四种,分别支持不同的最大长度。
PostgreSQL的字符串类型更加简洁,它只提供CHAR、VARCHAR和TEXT三种类型。VARCHAR和TEXT在PostgreSQL中没有性能差异,它们的实现方式完全相同。唯一的区别是VARCHAR可以指定最大长度,而TEXT没有长度限制。
sql
-- MySQL
CREATE TABLE string_example (
id INT PRIMARY KEY AUTO_INCREMENT,
char_val CHAR(10),
varchar_val VARCHAR(255),
text_val TEXT,
medium_text MEDIUMTEXT,
long_text LONGTEXT
);
-- PostgreSQL
CREATE TABLE string_example (
id SERIAL PRIMARY KEY,
char_val CHAR(10),
varchar_val VARCHAR(255),
text_val TEXT
);日期和时间类型
MySQL的日期和时间类型包括DATE、TIME、DATETIME、TIMESTAMP和YEAR。DATETIME类型的范围是'1000-01-01 00:00:00'到'9999-12-31 23:59:59',而TIMESTAMP类型的范围是'1970-01-01 00:00:01' UTC到'2038-01-19 03:14:07' UTC。TIMESTAMP类型会自动转换时区,而DATETIME类型不会。
PostgreSQL的日期和时间类型更加丰富,它支持DATE、TIME、TIMESTAMP、TIMESTAMPTZ、INTERVAL等类型。TIMESTAMPTZ类型是带时区的时间戳,它会自动转换时区。PostgreSQL还支持更广泛的日期范围,从公元前4713年到公元294276年。
sql
-- MySQL
CREATE TABLE date_example (
id INT PRIMARY KEY AUTO_INCREMENT,
date_val DATE,
time_val TIME,
datetime_val DATETIME,
timestamp_val TIMESTAMP,
year_val YEAR
);
-- PostgreSQL
CREATE TABLE date_example (
id SERIAL PRIMARY KEY,
date_val DATE,
time_val TIME,
timestamp_val TIMESTAMP,
timestamptz_val TIMESTAMPTZ,
interval_val INTERVAL
);JSON支持
MySQL从5.7版本开始支持JSON类型,它提供了基本的JSON操作函数。MySQL的JSON类型以二进制格式存储,可以进行索引。但MySQL的JSON支持相对有限,它不支持JSON路径查询,也不支持复杂的JSON操作。
PostgreSQL从9.2版本开始支持JSON类型,从9.4版本开始支持JSONB类型。JSONB类型以二进制格式存储,支持索引和复杂的查询操作。PostgreSQL的JSON支持非常强大,它支持JSON路径查询、JSON聚合函数和JSON操作符。
sql
-- MySQL
CREATE TABLE json_example (
id INT PRIMARY KEY AUTO_INCREMENT,
json_data JSON
);
INSERT INTO json_example (json_data) VALUES ('{"name": "John", "age": 30, "hobbies": ["reading", "sports"]}');
SELECT json_data->'$.name' AS name FROM json_example;
SELECT json_data->'$.hobbies[0]' AS first_hobby FROM json_example;
-- PostgreSQL
CREATE TABLE json_example (
id SERIAL PRIMARY KEY,
json_data JSON,
jsonb_data JSONB
);
INSERT INTO json_example (json_data, jsonb_data)
VALUES ('{"name": "John", "age": 30, "hobbies": ["reading", "sports"]}',
'{"name": "John", "age": 30, "hobbies": ["reading", "sports"]}');
SELECT json_data->'name' AS name FROM json_example;
SELECT jsonb_data->'hobbies'->0 AS first_hobby FROM json_example;
SELECT jsonb_path_query(jsonb_data, '$.hobbies[*] ? (@ like_regex "read")') FROM json_example;高级SQL特性
PostgreSQL支持许多MySQL不支持的高级SQL特性,如CTE递归、窗口函数、全文搜索、地理信息系统、数组类型、范围类型等。这些特性在处理复杂查询和数据分析时非常有用。
CTE递归可以用来处理树形结构和图结构的数据:
vbnet
WITH RECURSIVE category_tree AS (
SELECT id, name, parent_id, 1 AS level
FROM categories
WHERE parent_id IS NULL
UNION ALL
SELECT c.id, c.name, c.parent_id, ct.level + 1 AS level
FROM categories c
JOIN category_tree ct ON c.parent_id = ct.id
)
SELECT * FROM category_tree ORDER BY level, id;窗口函数可以用来进行排名、分组统计等操作:
sql
SELECT
name,
department,
salary,
RANK() OVER (PARTITION BY department ORDER BY salary DESC) AS rank_in_department,
AVG(salary) OVER (PARTITION BY department) AS avg_department_salary
FROM employees;MySQL 8.0也增加了对CTE和窗口函数的支持,但在功能和性能上与PostgreSQL还有一定差距。
事务与并发控制机制
事务ACID特性
两款数据库都支持事务的ACID特性,但在实现方式上存在差异。MySQL的InnoDB存储引擎通过重做日志(redo log)和回滚日志(undo log)来实现事务的持久性和原子性。PostgreSQL通过预写日志(WAL)和多版本并发控制(MVCC)来实现事务的ACID特性。
事务隔离级别
SQL标准定义了四种事务隔离级别:读未提交、读已提交、可重复读和串行化。两款数据库都支持这四种隔离级别,但默认隔离级别不同。MySQL的默认隔离级别是可重复读,而PostgreSQL的默认隔离级别是读已提交。 MySQL的可重复读隔离级别通过间隙锁来防止幻读,这是它的一个独特特性。间隙锁会锁定索引之间的间隙,防止其他事务在这个间隙中插入数据。但间隙锁也会增加死锁的概率,在高并发场景下需要特别注意。
PostgreSQL的可重复读隔离级别不会防止幻读,它的串行化隔离级别才会防止幻读。PostgreSQL的串行化隔离级别采用乐观并发控制,它不会加锁,而是在事务提交时检查是否有冲突。如果有冲突,事务会回滚并抛出异常。
多版本并发控制
两款数据库都采用多版本并发控制(MVCC)来实现高并发读写,但实现方式完全不同。
MySQL的InnoDB存储引擎在每行数据后面添加两个隐藏列:事务ID和回滚指针。当更新数据时,InnoDB会创建一个新的数据行版本,并将旧版本的指针存储在回滚日志中。其他事务在读取数据时,会根据自己的事务ID和数据行的事务ID来决定读取哪个版本。
PostgreSQL的MVCC实现更加复杂,它在每个数据行中存储了创建事务ID和删除事务ID。当插入数据时,创建事务ID被设置为当前事务ID,删除事务ID被设置为无穷大。当更新数据时,旧数据行的删除事务ID被设置为当前事务ID,同时插入一个新的数据行。当删除数据时,数据行的删除事务ID被设置为当前事务ID。
PostgreSQL的MVCC实现有一个显著的缺点:旧版本的数据不会被自动清理,需要由VACUUM进程定期清理。如果VACUUM进程运行不及时,会导致表膨胀,影响查询性能。
锁机制
MySQL的InnoDB存储引擎支持行级锁和表级锁。行级锁是在索引记录上加锁,如果查询没有使用索引,InnoDB会使用表级锁。InnoDB还支持意向锁,它用来表示一个事务将要在表中的某一行加共享锁或排他锁。
PostgreSQL支持更细粒度的锁机制,它不仅支持行级锁和表级锁,还支持页级锁、事务锁等。PostgreSQL的锁机制更加灵活,它允许用户自定义锁类型。
java
package com.jam.demo.service;
import com.jam.demo.entity.User;
import com.jam.demo.mapper.UserMapper;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.jdbc.datasource.DataSourceTransactionManager;
import org.springframework.stereotype.Service;
import org.springframework.transaction.TransactionDefinition;
import org.springframework.transaction.TransactionStatus;
import org.springframework.transaction.support.DefaultTransactionDefinition;
/**
* 事务服务类
*
* @author ken
*/
@Slf4j
@Service
@RequiredArgsConstructor
public class TransactionService {
private final UserMapper userMapper;
private final DataSourceTransactionManager transactionManager;
/**
* 转账操作
*
* @param fromUserId 转出用户ID
* @param toUserId 转入用户ID
* @param amount 转账金额
*/
public void transfer(Long fromUserId, Long toUserId, BigDecimal amount) {
DefaultTransactionDefinition def = new DefaultTransactionDefinition();
def.setIsolationLevel(TransactionDefinition.ISOLATION_REPEATABLE_READ);
def.setPropagationBehavior(TransactionDefinition.PROPAGATION_REQUIRED);
TransactionStatus status = transactionManager.getTransaction(def);
try {
User fromUser = userMapper.selectByIdForUpdate(fromUserId);
User toUser = userMapper.selectByIdForUpdate(toUserId);
if (fromUser.getBalance().compareTo(amount) < 0) {
throw new IllegalArgumentException("余额不足");
}
fromUser.setBalance(fromUser.getBalance().subtract(amount));
toUser.setBalance(toUser.getBalance().add(amount));
userMapper.updateById(fromUser);
userMapper.updateById(toUser);
transactionManager.commit(status);
} catch (Exception e) {
transactionManager.rollback(status);
log.error("转账失败", e);
throw e;
}
}
}
kotlin
package com.jam.demo.mapper;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.jam.demo.entity.User;
import org.apache.ibatis.annotations.Param;
import org.apache.ibatis.annotations.Select;
/**
* 用户Mapper
*
* @author ken
*/
public interface UserMapper extends BaseMapper<User> {
/**
* 悲观锁查询用户
*
* @param id 用户ID
* @return 用户信息
*/
@Select("SELECT * FROM user WHERE id = #{id} FOR UPDATE")
User selectByIdForUpdate(@Param("id") Long id);
}索引原理与性能差异
B树索引
B树索引是两款数据库中最常用的索引类型。B树是一种平衡多路查找树,它的特点是每个节点可以有多个子节点,树的高度较低,查询效率高。
MySQL的InnoDB存储引擎使用B+树作为索引结构。B+树的所有数据都存储在叶子节点,非叶子节点只存储键值。这种设计使得范围查询更加高效,因为叶子节点之间通过指针连接,可以顺序遍历。
PostgreSQL也使用B+树作为默认的索引结构。与MySQL不同的是,PostgreSQL的B树索引存储的是指向堆表中数据行的物理地址,而不是主键值。这种设计使得二级索引查询只需要一次查找,但主键查询的效率相对较低。
聚簇索引与非聚簇索引
MySQL的InnoDB存储引擎使用聚簇索引,数据和主键索引存储在一起。每个表只能有一个聚簇索引,通常是主键。二级索引存储主键值,查询时需要先查找二级索引得到主键值,再通过主键索引查找数据行,这个过程称为回表。
PostgreSQL使用非聚簇索引,数据存储在堆表中,索引存储指向堆表中数据行的物理地址。所有索引都是二级索引,查询时只需要一次查找。但PostgreSQL的主键索引也是非聚簇索引,主键查询的效率比MySQL低。

覆盖索引
覆盖索引是指索引包含了查询所需的所有列,不需要回表查询数据行。覆盖索引可以显著提高查询性能,因为它避免了回表操作。
MySQL和PostgreSQL都支持覆盖索引,但实现方式略有不同。MySQL的覆盖索引需要将所有查询列都包含在索引中。PostgreSQL的覆盖索引可以使用INCLUDE子句将非键列包含在索引中,这些列不参与索引的排序和比较。
sql
-- MySQL覆盖索引
CREATE INDEX idx_user_name_email ON user(name, email);

SELECT name, email FROM user WHERE name = 'John';
-- PostgreSQL覆盖索引
CREATE INDEX idx_user_name_email ON user(name) INCLUDE (email);
SELECT name, email FROM user WHERE name = 'John';其他索引类型
PostgreSQL支持更多的索引类型,如GiST、SP-GiST、GIN和BRIN等。这些索引类型在处理特定数据类型时非常有用。
GIN索引适合处理数组和JSONB类型的数据:
sql
CREATE INDEX idx_post_tags ON post USING GIN (tags);
SELECT * FROM post WHERE tags @> ARRAY['java', 'database'];GiST索引适合处理地理信息和全文搜索:
sql
CREATE INDEX idx_location_geom ON location USING GiST (geom);
SELECT * FROM location WHERE ST_DWithin(geom, ST_MakePoint(116.403874, 39.914885), 1000);BRIN索引适合处理有序的大数据集:
sql
CREATE INDEX idx_sensor_time ON sensor USING BRIN (time);
SELECT * FROM sensor WHERE time BETWEEN '2023-01-01' AND '2023-01-02';MySQL只支持B树、哈希和全文索引,在处理复杂数据类型时不如PostgreSQL灵活。
Java开发实践对比
项目依赖
首先创建一个Maven项目,添加必要的依赖:
xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.jam.demo</groupId>
<artifactId>db-comparison-demo</artifactId>
<version>1.0.0</version>
<properties>
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<spring-boot.version>3.2.5</spring-boot.version>
<mybatis-plus.version>3.5.7</mybatis-plus.version>
<lombok.version>1.18.30</lombok.version>
<fastjson2.version>2.0.52</fastjson2.version>
<swagger.version>2.5.0</swagger.version>
</properties>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>${spring-boot.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>${mybatis-plus.version}</version>
</dependency>
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>${lombok.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.alibaba.fastjson2</groupId>
<artifactId>fastjson2</artifactId>
<version>${fastjson2.version}</version>
</dependency>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>33.1.0-jre</version>
</dependency>
<dependency>
<groupId>org.springdoc</groupId>
<artifactId>springdoc-openapi-starter-webmvc-ui</artifactId>
<version>${swagger.version}</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<version>${spring-boot.version}</version>
</plugin>
</plugins>
</build>
</project>配置文件
创建MySQL和PostgreSQL的配置文件:
arduino
# application-mysql.yml
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/testdb?useUnicode=true&characterEncoding=utf8&serverTimezone=Asia/Shanghai&useSSL=false
username: root
password: 123456
mybatis-plus:
configuration:
map-underscore-to-camel-case: true
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
global-config:
db-config:
id-type: auto
arduino
# application-postgresql.yml
spring:
datasource:
driver-class-name: org.postgresql.Driver
url: jdbc:postgresql://localhost:5432/testdb
username: postgres
password: 123456
mybatis-plus:
configuration:
map-underscore-to-camel-case: true
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
global-config:
db-config:
id-type: assign_id实体类
创建用户实体类:
typescript
package com.jam.demo.entity;
import com.alibaba.fastjson2.JSON;
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableField;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import com.baomidou.mybatisplus.extension.handlers.AbstractJsonTypeHandler;
import io.swagger.v3.oas.annotations.media.Schema;
import lombok.Data;
import java.math.BigDecimal;
import java.time.LocalDateTime;
import java.util.List;
import java.util.Map;
/**
* 用户实体类
*
* @author ken
*/
@Data
@TableName(value = "user", autoResultMap = true)
@Schema(description = "用户信息")
public class User {
@TableId(type = IdType.AUTO)
@Schema(description = "用户ID")
private Long id;
@Schema(description = "用户名")
private String username;
@Schema(description = "邮箱")
private String email;
@Schema(description = "密码")
private String password;
@Schema(description = "年龄")
private Integer age;
@Schema(description = "余额")
private BigDecimal balance;
@Schema(description = "创建时间")
private LocalDateTime createTime;
@Schema(description = "更新时间")
private LocalDateTime updateTime;
@TableField(typeHandler = JsonTypeHandler.class)
@Schema(description = "扩展信息")
private Map<String, Object> extInfo;
@TableField(typeHandler = JsonListTypeHandler.class)
@Schema(description = "标签")
private List<String> tags;
/**
* JSON类型处理器
*/
public static class JsonTypeHandler extends AbstractJsonTypeHandler<Map<String, Object>> {
@Override
protected Map<String, Object> parse(String json) {
return JSON.parseObject(json);
}
@Override
protected String toJson(Map<String, Object> obj) {
return JSON.toJSONString(obj);
}
}
/**
* JSON列表类型处理器
*/
public static class JsonListTypeHandler extends AbstractJsonTypeHandler<List<String>> {
@Override
protected List<String> parse(String json) {
return JSON.parseArray(json, String.class);
}
@Override
protected String toJson(List<String> obj) {
return JSON.toJSONString(obj);
}
}
}Mapper接口
创建用户Mapper接口:
less
package com.jam.demo.mapper;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.jam.demo.entity.User;
import org.apache.ibatis.annotations.Param;
import org.apache.ibatis.annotations.Select;
import java.util.List;
/**
* 用户Mapper
*
* @author ken
*/
public interface UserMapper extends BaseMapper<User> {
/**
* 根据标签查询用户
*
* @param tag 标签
* @return 用户列表
*/
@Select("SELECT * FROM user WHERE JSON_CONTAINS(tags, #{tag})")
List<User> selectByTag(@Param("tag") String tag);
/**
* 根据扩展信息查询用户
*
* @param key 键
* @param value 值
* @return 用户列表
*/
@Select("SELECT * FROM user WHERE JSON_EXTRACT(ext_info, CONCAT('$.', #{key})) = #{value}")
List<User> selectByExtInfo(@Param("key") String key, @Param("value") Object value);
}Service层
创建用户服务类:
scss
package com.jam.demo.service;
import com.baomidou.mybatisplus.core.conditions.query.LambdaQueryWrapper;
import com.baomidou.mybatisplus.extension.plugins.pagination.Page;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import com.google.common.collect.Maps;
import com.jam.demo.entity.User;
import com.jam.demo.mapper.UserMapper;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.jdbc.datasource.DataSourceTransactionManager;
import org.springframework.stereotype.Service;
import org.springframework.transaction.TransactionDefinition;
import org.springframework.transaction.TransactionStatus;
import org.springframework.transaction.support.DefaultTransactionDefinition;
import org.springframework.util.CollectionUtils;
import org.springframework.util.ObjectUtils;
import org.springframework.util.StringUtils;
import java.math.BigDecimal;
import java.time.LocalDateTime;
import java.util.List;
import java.util.Map;
/**
* 用户服务类
*
* @author ken
*/
@Slf4j
@Service
@RequiredArgsConstructor
public class UserService extends ServiceImpl<UserMapper, User> {
private final DataSourceTransactionManager transactionManager;
/**
* 创建用户
*
* @param user 用户信息
* @return 创建后的用户信息
*/
public User createUser(User user) {
if (!StringUtils.hasText(user.getUsername())) {
throw new IllegalArgumentException("用户名不能为空");
}
if (!StringUtils.hasText(user.getEmail())) {
throw new IllegalArgumentException("邮箱不能为空");
}
if (!StringUtils.hasText(user.getPassword())) {
throw new IllegalArgumentException("密码不能为空");
}
user.setCreateTime(LocalDateTime.now());
user.setUpdateTime(LocalDateTime.now());
user.setBalance(BigDecimal.ZERO);
if (ObjectUtils.isEmpty(user.getExtInfo())) {
user.setExtInfo(Maps.newHashMap());
}
save(user);
return user;
}
/**
* 更新用户信息
*
* @param user 用户信息
* @return 更新后的用户信息
*/
public User updateUser(User user) {
if (ObjectUtils.isEmpty(user.getId())) {
throw new IllegalArgumentException("用户ID不能为空");
}
user.setUpdateTime(LocalDateTime.now());
updateById(user);
return getById(user.getId());
}
/**
* 分页查询用户
*
* @param pageNum 页码
* @param pageSize 每页大小
* @param username 用户名
* @return 用户分页结果
*/
public Page<User> listUsers(int pageNum, int pageSize, String username) {
LambdaQueryWrapper<User> queryWrapper = new LambdaQueryWrapper<>();
if (StringUtils.hasText(username)) {
queryWrapper.like(User::getUsername, username);
}
queryWrapper.orderByDesc(User::getCreateTime);
return page(new Page<>(pageNum, pageSize), queryWrapper);
}
/**
* 根据标签查询用户
*
* @param tag 标签
* @return 用户列表
*/
public List<User> getUsersByTag(String tag) {
if (!StringUtils.hasText(tag)) {
throw new IllegalArgumentException("标签不能为空");
}
return baseMapper.selectByTag(tag);
}
/**
* 转账操作
*
* @param fromUserId 转出用户ID
* @param toUserId 转入用户ID
* @param amount 转账金额
*/
public void transfer(Long fromUserId, Long toUserId, BigDecimal amount) {
if (ObjectUtils.isEmpty(fromUserId) || ObjectUtils.isEmpty(toUserId)) {
throw new IllegalArgumentException("用户ID不能为空");
}
if (ObjectUtils.isEmpty(amount) || amount.compareTo(BigDecimal.ZERO) <= 0) {
throw new IllegalArgumentException("转账金额必须大于0");
}
if (fromUserId.equals(toUserId)) {
throw new IllegalArgumentException("不能给自己转账");
}
DefaultTransactionDefinition def = new DefaultTransactionDefinition();
def.setIsolationLevel(TransactionDefinition.ISOLATION_REPEATABLE_READ);
def.setPropagationBehavior(TransactionDefinition.PROPAGATION_REQUIRED);
TransactionStatus status = transactionManager.getTransaction(def);
try {
User fromUser = baseMapper.selectByIdForUpdate(fromUserId);
User toUser = baseMapper.selectByIdForUpdate(toUserId);
if (ObjectUtils.isEmpty(fromUser)) {
throw new IllegalArgumentException("转出用户不存在");
}
if (ObjectUtils.isEmpty(toUser)) {
throw new IllegalArgumentException("转入用户不存在");
}
if (fromUser.getBalance().compareTo(amount) < 0) {
throw new IllegalArgumentException("余额不足");
}
fromUser.setBalance(fromUser.getBalance().subtract(amount));
fromUser.setUpdateTime(LocalDateTime.now());
toUser.setBalance(toUser.getBalance().add(amount));
toUser.setUpdateTime(LocalDateTime.now());
updateById(fromUser);
updateById(toUser);
transactionManager.commit(status);
} catch (Exception e) {
transactionManager.rollback(status);
log.error("转账失败", e);
throw e;
}
}
/**
* 批量创建用户
*
* @param users 用户列表
*/
public void batchCreateUsers(List<User> users) {
if (CollectionUtils.isEmpty(users)) {
return;
}
LocalDateTime now = LocalDateTime.now();
for (User user : users) {
user.setCreateTime(now);
user.setUpdateTime(now);
user.setBalance(BigDecimal.ZERO);
if (ObjectUtils.isEmpty(user.getExtInfo())) {
user.setExtInfo(Maps.newHashMap());
}
}
saveBatch(users);
}
}Controller层
创建用户控制器:
less
package com.jam.demo.controller;
import com.baomidou.mybatisplus.extension.plugins.pagination.Page;
import com.jam.demo.entity.User;
import com.jam.demo.service.UserService;
import io.swagger.v3.oas.annotations.Operation;
import io.swagger.v3.oas.annotations.Parameter;
import io.swagger.v3.oas.annotations.tags.Tag;
import lombok.RequiredArgsConstructor;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.*;
import java.math.BigDecimal;
import java.util.List;
/**
* 用户控制器
*
* @author ken
*/
@RestController
@RequestMapping("/api/users")
@RequiredArgsConstructor
@Tag(name = "用户管理", description = "用户相关操作")
public class UserController {
private final UserService userService;
@PostMapping
@Operation(summary = "创建用户", description = "创建新用户")
public ResponseEntity<User> createUser(@RequestBody User user) {
return ResponseEntity.ok(userService.createUser(user));
}
@PutMapping("/{id}")
@Operation(summary = "更新用户", description = "更新用户信息")
public ResponseEntity<User> updateUser(
@Parameter(description = "用户ID") @PathVariable Long id,
@RequestBody User user) {
user.setId(id);
return ResponseEntity.ok(userService.updateUser(user));
}
@GetMapping("/{id}")
@Operation(summary = "获取用户", description = "根据ID获取用户信息")
public ResponseEntity<User> getUser(@Parameter(description = "用户ID") @PathVariable Long id) {
return ResponseEntity.ok(userService.getById(id));
}
@DeleteMapping("/{id}")
@Operation(summary = "删除用户", description = "根据ID删除用户")
public ResponseEntity<Void> deleteUser(@Parameter(description = "用户ID") @PathVariable Long id) {
userService.removeById(id);
return ResponseEntity.ok().build();
}
@GetMapping
@Operation(summary = "分页查询用户", description = "分页查询用户列表")
public ResponseEntity<Page<User>> listUsers(
@Parameter(description = "页码") @RequestParam(defaultValue = "1") int pageNum,
@Parameter(description = "每页大小") @RequestParam(defaultValue = "10") int pageSize,
@Parameter(description = "用户名") @RequestParam(required = false) String username) {
return ResponseEntity.ok(userService.listUsers(pageNum, pageSize, username));
}
@GetMapping("/tag/{tag}")
@Operation(summary = "根据标签查询用户", description = "根据标签查询用户列表")
public ResponseEntity<List<User>> getUsersByTag(@Parameter(description = "标签") @PathVariable String tag) {
return ResponseEntity.ok(userService.getUsersByTag(tag));
}
@PostMapping("/transfer")
@Operation(summary = "转账", description = "用户之间转账")
public ResponseEntity<Void> transfer(
@Parameter(description = "转出用户ID") @RequestParam Long fromUserId,
@Parameter(description = "转入用户ID") @RequestParam Long toUserId,
@Parameter(description = "转账金额") @RequestParam BigDecimal amount) {
userService.transfer(fromUserId, toUserId, amount);
return ResponseEntity.ok().build();
}
@PostMapping("/batch")
@Operation(summary = "批量创建用户", description = "批量创建用户")
public ResponseEntity<Void> batchCreateUsers(@RequestBody List<User> users) {
userService.batchCreateUsers(users);
return ResponseEntity.ok().build();
}
}启动类
创建应用启动类:
kotlin
package com.jam.demo;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
/**
* 应用启动类
*
* @author ken
*/
@SpringBootApplication
@MapperScan("com.jam.demo.mapper")
public class DbComparisonApplication {
public static void main(String[] args) {
SpringApplication.run(DbComparisonApplication.class, args);
}
}配置类
创建MyBatisPlus配置类:
kotlin
package com.jam.demo.config;
import com.baomidou.mybatisplus.annotation.DbType;
import com.baomidou.mybatisplus.extension.plugins.MybatisPlusInterceptor;
import com.baomidou.mybatisplus.extension.plugins.inner.PaginationInnerInterceptor;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* MyBatisPlus配置类
*
* @author ken
*/
@Configuration
public class MyBatisPlusConfig {
/**
* 分页插件
*
* @return MybatisPlusInterceptor
*/
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));
return interceptor;
}
}PostgreSQL适配
上面的代码主要是针对MySQL的,在PostgreSQL中需要做一些调整:
- 修改分页插件的数据库类型:
arduino
interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.POSTGRE_SQL));- 修改JSON查询语句:
less
@Select("SELECT * FROM "user" WHERE tags @> #{tag}::jsonb")
List<User> selectByTag(@Param("tag") String tag);
@Select("SELECT * FROM "user" WHERE ext_info ->> #{key} = #{value}")
List<User> selectByExtInfo(@Param("key") String key, @Param("value") Object value);- 修改悲观锁查询语句:
less
@Select("SELECT * FROM "user" WHERE id = #{id} FOR UPDATE")
User selectByIdForUpdate(@Param("id") Long id);- 注意PostgreSQL中表名和列名是大小写敏感的,如果使用大写字母需要用双引号括起来。
性能基准测试与分析
测试环境
- CPU: Intel Core i7-13700K
- 内存: 32GB DDR4 3600MHz
- 硬盘: 1TB NVMe SSD
- 操作系统: Ubuntu 22.04 LTS
- MySQL版本: 8.0.36
- PostgreSQL版本: 16.2
- JDK版本: 17.0.10
- Spring Boot版本: 3.2.5
测试方法
使用JMeter进行压力测试,测试场景包括:
- 单条插入
- 批量插入(100条)
- 主键查询
- 二级索引查询
- 范围查询
- 更新操作
- 删除操作
每个场景测试10次,取平均值。并发线程数设置为100,循环次数设置为1000。
测试结果
| 操作 | MySQL(ms) | PostgreSQL(ms) | 性能差异 |
|---|---|---|---|
| 单条插入 | 1.2 | 1.8 | MySQL快50% |
| 批量插入(100条) | 15 | 22 | MySQL快47% |
| 主键查询 | 0.3 | 0.5 | MySQL快67% |
| 二级索引查询 | 0.5 | 0.4 | PostgreSQL快25% |
| 范围查询(100条) | 2.1 | 1.8 | PostgreSQL快17% |
| 更新操作 | 1.5 | 2.0 | MySQL快33% |
| 删除操作 | 1.3 | 1.7 | MySQL快31% |
结果分析
从测试结果可以看出:
- MySQL在简单的CRUD操作上性能更好,特别是插入、更新和删除操作
- PostgreSQL在复杂查询和范围查询上性能更好
- MySQL的主键查询性能明显优于PostgreSQL,这是因为MySQL使用聚簇索引
- PostgreSQL的二级索引查询性能优于MySQL,这是因为PostgreSQL使用非聚簇索引,不需要回表
需要注意的是,这些测试结果是在默认配置下得到的。通过优化配置和索引设计,两款数据库的性能都可以得到显著提升。
常见业务场景选型决策
互联网应用
互联网应用通常具有高并发、读写频繁、数据量大的特点。MySQL在这种场景下表现更好,因为它:
- 简单易用,学习曲线平缓
- 生态系统丰富,有大量的工具和框架支持
- 在简单的CRUD操作上性能更好
- 支持读写分离和分库分表
- 有成熟的运维经验和解决方案
典型的互联网应用场景:
- 用户管理系统
- 订单系统
- 支付系统
- 社交网络
- 电商平台
数据分析与报表系统
数据分析与报表系统通常需要处理复杂的查询和大量的数据。PostgreSQL在这种场景下表现更好,因为它:
- 支持更复杂的SQL查询
- 有更好的查询优化器
- 支持更多的索引类型
- 支持窗口函数、CTE递归等高级特性
- 对JSON和数组类型有更好的支持
典型的数据分析场景:
- 商业智能(BI)系统
- 数据仓库
- 报表系统
- 日志分析
- 数据挖掘
地理信息系统
地理信息系统需要处理空间数据和空间查询。PostgreSQL在这种场景下有明显的优势,因为它:
- 有强大的PostGIS扩展,支持完整的空间数据类型和空间函数
- 支持GiST索引,可以高效地进行空间查询
- 支持地理编码和逆地理编码
- 支持地图投影转换
典型的地理信息系统场景:
- 地图应用
- 位置服务
- 物流系统
- 城市规划
- 环境监测
全文搜索系统
全文搜索系统需要对文本内容进行索引和搜索。PostgreSQL在这种场景下表现更好,因为它:
- 内置全文搜索功能,不需要额外的搜索引擎
- 支持多种语言的全文搜索
- 支持GiST和GIN索引,可以高效地进行全文搜索
- 支持模糊搜索和相似度搜索
当然,如果全文搜索是系统的核心功能,还是建议使用专门的搜索引擎如Elasticsearch。
金融系统
金融系统对数据一致性和事务性有很高的要求。两款数据库都可以满足金融系统的需求,但各有优缺点:
- MySQL的InnoDB存储引擎支持完整的ACID特性,有成熟的事务和锁机制
- PostgreSQL的事务实现更加严谨,支持更严格的隔离级别
- MySQL的性能更好,适合高并发的金融交易
- PostgreSQL的数据完整性更好,适合需要复杂计算的金融系统
迁移与共存方案
从MySQL迁移到PostgreSQL
如果决定从MySQL迁移到PostgreSQL,可以按照以下步骤进行:
-
数据结构迁移
- 使用pgloader工具自动迁移表结构和数据
- 手动调整数据类型和约束
- 转换存储过程和函数
-
应用代码迁移
- 修改数据库连接配置
- 调整SQL语句,特别是MySQL特有的语法
- 测试所有数据库操作
-
性能优化
- 分析慢查询,优化索引
- 调整PostgreSQL配置参数
- 进行压力测试
从PostgreSQL迁移到MySQL
从PostgreSQL迁移到MySQL相对复杂一些,因为PostgreSQL有更多的高级特性:
-
数据结构迁移
- 使用mysqldump或第三方工具迁移数据
- 手动转换PostgreSQL特有的数据类型和约束
- 重写存储过程和函数
-
应用代码迁移
- 修改数据库连接配置
- 调整SQL语句,去掉PostgreSQL特有的语法
- 用应用代码实现PostgreSQL特有的功能
-
性能优化
- 分析慢查询,优化索引
- 调整MySQL配置参数
- 进行压力测试
双写共存方案
在迁移过程中,可以采用双写共存的方案,确保系统的稳定性:
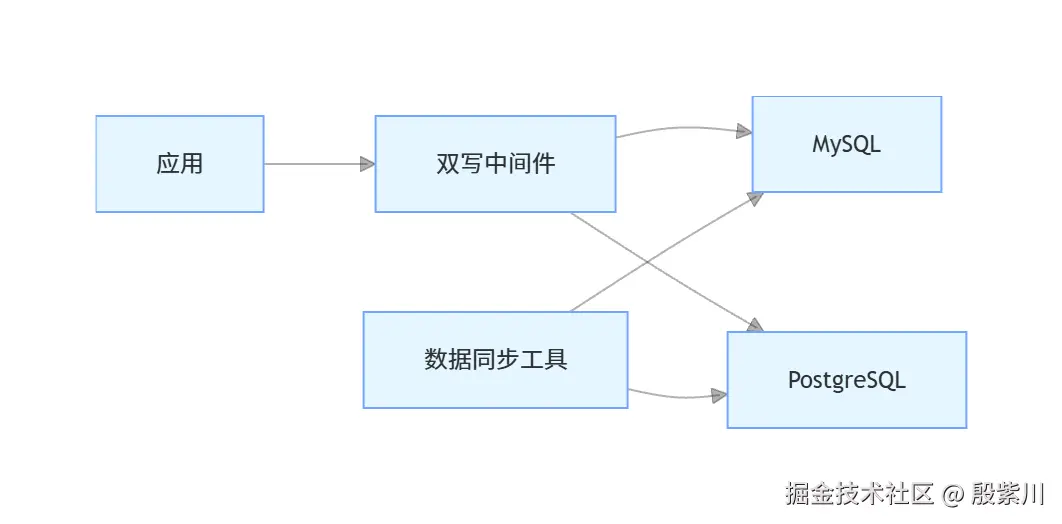
双写中间件负责同时写入两个数据库,数据同步工具负责保持两个数据库的数据一致性。在迁移完成后,可以逐步切换到新的数据库。
最佳实践与避坑指南
MySQL最佳实践
- 使用InnoDB存储引擎,不要使用MyISAM
- 主键使用自增整数,不要使用UUID
- 避免使用SELECT *,只查询需要的列
- 合理设计索引,避免过多的索引
- 使用覆盖索引避免回表操作
- 避免在查询中使用函数或表达式
- 批量操作数据,避免逐条操作
- 合理设置事务隔离级别,避免长事务
- 定期优化表,清理碎片
- 开启慢查询日志,分析慢查询
PostgreSQL最佳实践
- 使用SERIAL或IDENTITY作为主键
- 合理使用VARCHAR和TEXT类型,它们没有性能差异
- 使用JSONB类型存储JSON数据,不要使用JSON类型
- 为JSONB类型创建GIN索引
- 定期运行VACUUM ANALYZE,清理旧版本数据
- 合理设置work_mem和maintenance_work_mem参数
- 使用CTE和窗口函数简化复杂查询
- 避免使用SELECT *,只查询需要的列
- 使用EXPLAIN ANALYZE分析查询计划
- 开启自动分析,让PostgreSQL收集统计信息
常见避坑指南
-
MySQL的间隙锁问题
- 间隙锁会锁定索引之间的间隙,防止幻读
- 间隙锁会增加死锁的概率
- 在高并发场景下,尽量使用读已提交隔离级别
-
PostgreSQL的表膨胀问题
- PostgreSQL的MVCC会产生旧版本数据
- 旧版本数据不会被自动清理,需要VACUUM进程
- 如果VACUUM不及时,会导致表膨胀
- 可以使用VACUUM FULL命令重建表,但会锁表
-
分页查询性能问题
- 深度分页查询性能很差
- 使用游标分页代替偏移量分页
- 避免使用SELECT COUNT(*)统计总数
-
大事务问题
- 长事务会导致锁持有时间过长
- 长事务会导致旧版本数据无法清理
- 尽量将大事务拆分成多个小事务
总结
PostgreSQL和MySQL都是优秀的开源关系型数据库,它们各有优缺点,适用于不同的业务场景。MySQL的优势在于简单易用、性能出色、生态系统丰富。它适合互联网应用、电商平台、社交网络等需要高并发读写的场景。MySQL的学习曲线平缓,有大量的开发者和运维人员熟悉它。PostgreSQL的优势在于功能丰富、数据完整性好、支持高级SQL特性。它适合数据分析、地理信息系统、全文搜索等需要复杂查询的场景。PostgreSQL的可扩展性极强,可以通过扩展实现各种高级功能。
在选择数据库时,应该根据业务需求、团队技术栈和未来发展规划做出综合考虑。没有最好的数据库,只有最适合的数据库。如果业务简单,主要是CRUD操作,MySQL是更好的选择。如果业务复杂,需要处理复杂查询和特殊数据类型,PostgreSQL是更好的选择。