1.软件包管理器
1.1 软件包是什么
Linux下安装软件通常需要通过以下方式:
- 源码安装
- 软件包安装
- 包管理器apt/apt-get(ubuntu)yum(centos)
源代码安装是不推荐的,比如少了如何配置文件找起来会非常麻烦,卸载后配置残留,缺少依赖配置等各种问题, 于是有人就把一些常用的软件提前编译好,做成软件包放到一个服务器上,通过包管理器可以很方便的获取软件包,而所谓软件包管理器简单来说就是Linux的应用商城
包管理器的核心功能:
-
自动解决依赖
-
版本管理
-
干净卸载
-
安全验证
-
统一管理
虽然说源码安装 这么麻烦,但是用途非常特定 ,主要面向开发者 或有特殊需求的专家。
1.2主流的包管理器
1. yum
-
应用发行版:Fedora、RedHat、CentOS 7 及更早版本
-
包格式 :
.rpm -
底层工具 :
rpm
cpp
# yum 常用命令
yum install nginx # 安装
yum update nginx # 更新
yum remove nginx # 卸载
yum search nginx # 搜索
yum info nginx # 查看信息2. apt
-
应用发行版:Debian、Ubuntu 及其衍生版
-
包格式 :
.deb -
底层工具 :
dpkg
bash
# apt 常用命令
apt update # 更新软件源
apt install nginx # 安装
apt upgrade nginx # 更新
apt remove nginx # 卸载
apt purge nginx # 彻底卸载(含配置文件)
apt search nginx # 搜索
apt show nginx # 查看信息1.3 软件仓库(Repository)
- 软件包存放在称为 "软件源"(Repository) 的服务器上。操作系统内部有内置链接,包管理器需要知道去哪里下载。
- 由于大多数 Linux 发行版的官方软件源服务器都设在国外,在国内直接访问时,受限于国际网络带宽和复杂的网络环境,通常会导致两种结果:速度极慢,无法连接
- 为了解决这个问题,国内涌现了许多机构(如阿里云、清华大学、中科大、腾讯云等) ,它们做的事情就是 "镜像"。
镜像(Mirror) 就是把国外的官方源服务器上的所有内容,完整地复制一份到国内的服务器上 。镜像服务器会定时(比如每隔几小时)与官方源同步,保证软件包是最新的。
常见的国内镜像站
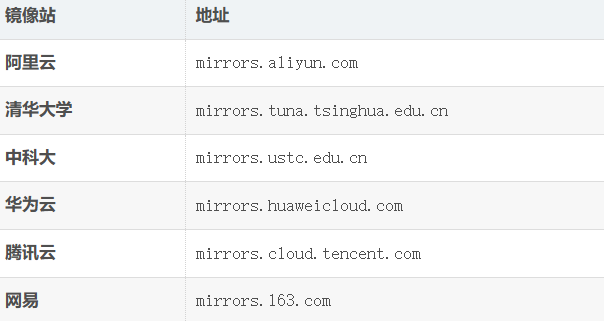
1.4软件包管理器具体操作
- 查看软件包
通过 yum list 命令可以罗列出当前⼀共有哪些软件包. 由于包的数⽬可能⾮常之多, 这⾥我们需要使⽤ grep 命令只筛选出我们关注的包. 例如
bash
# Centos
$ yum list | grep lrzsz
lrzsz.x86_64 0.12.20-36.el7 @base
# Ubuntu
$ apt search lrzsz
Sorting... Done
Full Text Search... Done
cutecom/focal 0.30.3-1build1 amd64
Graphical serial terminal, like minicom
lrzsz/focal,now 0.12.21-10 amd64 [installed]
Tools for zmodem/xmodem/ymodem file transfer
$ apt show lrzsz
Package: lrzsz
Version: 0.12.21-10
Priority: optional
Section: universe/comm
Origin: Ubuntu
Maintainer: Ubuntu Developers <ubuntu-devel-discuss@lists.ubuntu.com>
Original-Maintainer: Martin A. Godisch <godisch@debian.org>软件包命名 = 名称 + 主版本号 + 次版本号 + 平台标识 + 架构 + 软件源
el7 代表 CentOS 7 / RHEL 7
focal 代表 Ubuntu 20.04
x86_64 代表 64 位系统
@base 或 Section 代表软件源名称
- 安装软件
通过 yum/apt, 我们可以通过很简单的⼀条命令完成 gcc 的安装
bash
# Centos
$ sudo yum install -y lrzsz
# Ubuntu
$ sudo apt install- y lrzszyum/apt 会⾃动找到都有哪些软件包需要下载, 这时候敲 "y" 确认安装.
出现 "complete" 字样或者中间未出现报错, 说明安装完成.
注意事项:
- 安装软件时由于需要向系统⽬录中写⼊内容, ⼀般需要 sudo 或者切到 root 账⼾下才能完成.
- yum/apt安装软件只能⼀个装完了再装另⼀个. 正在yum/apt安装⼀个软件的过程中, 如果再尝试⽤yum/apt安装另外⼀个软件, yum/apt会报错.
- 卸载软件
apt(Ubuntu/Debian)
bash
# 卸载但保留配置文件
sudo apt remove 软件名
# 彻底卸载(删除配置文件)
sudo apt purge 软件名
# 卸载 + 自动删除依赖
sudo apt autoremove 软件名
# 组合使用:彻底卸载并清理依赖
sudo apt purge --autoremove 软件名yum/dnf(CentOS/RHEL)
bash
# 卸载软件
sudo yum remove 软件名
sudo dnf remove 软件名
# 卸载并删除依赖
sudo yum autoremove 软件名
sudo dnf autoremove 软件名
2. 编辑器vim2.编辑器Vim
Vim(Vi IMproved)是 Linux 上最常用的终端文本编辑器,功能强大但学习曲线较陡。
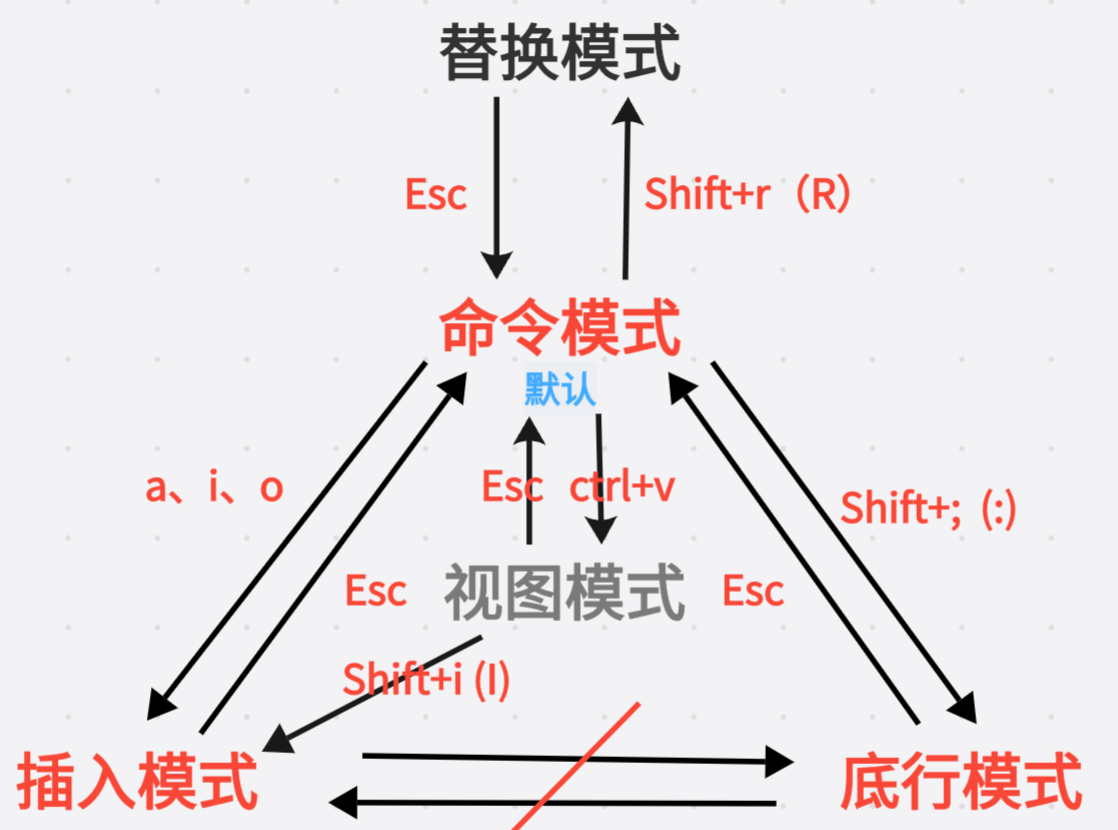
2.1 Vim常见的三种模式
1. 命令模式(Normal Mode)
默认进入的模式,也被叫做正常/普通模式,也是使用最频繁的模式。
核心作用:
-
移动光标
-
删除字符、单词、行
-
复制、粘贴
-
进入插入模式或底行模式
光标移动命令
- 行内移动
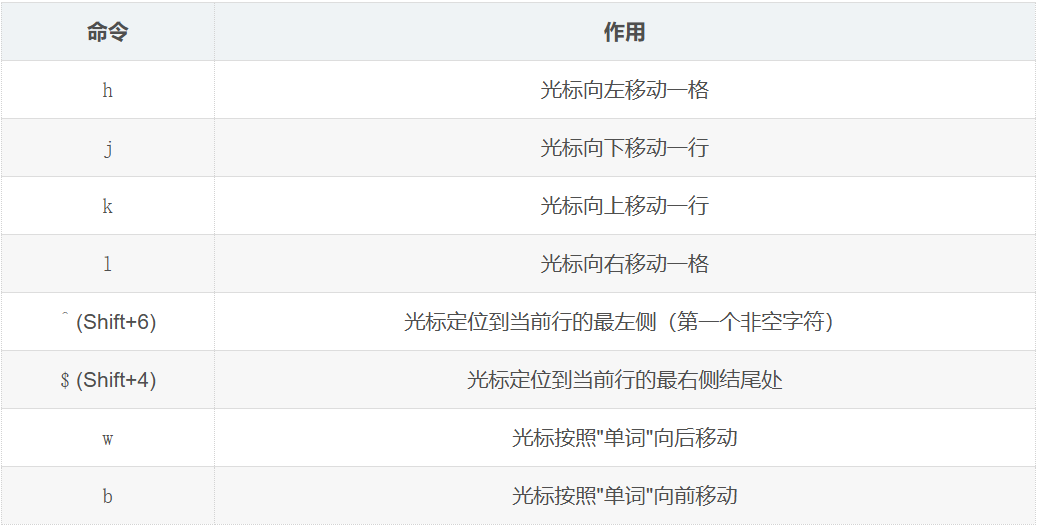
可以在hjklwb前面带数字,如30l就是向右移动30格
- 跨行移动
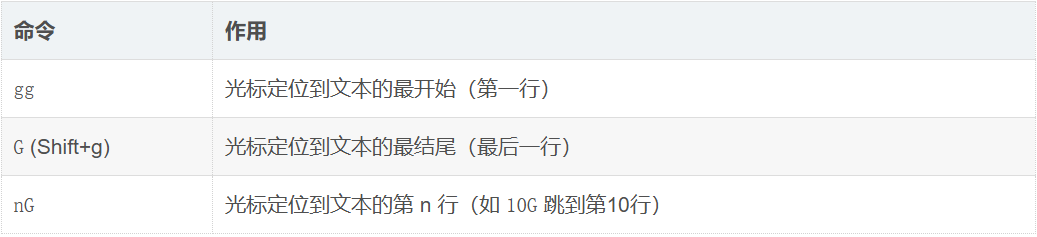
-
打开文件时跳转

-
多窗口操作

删除命令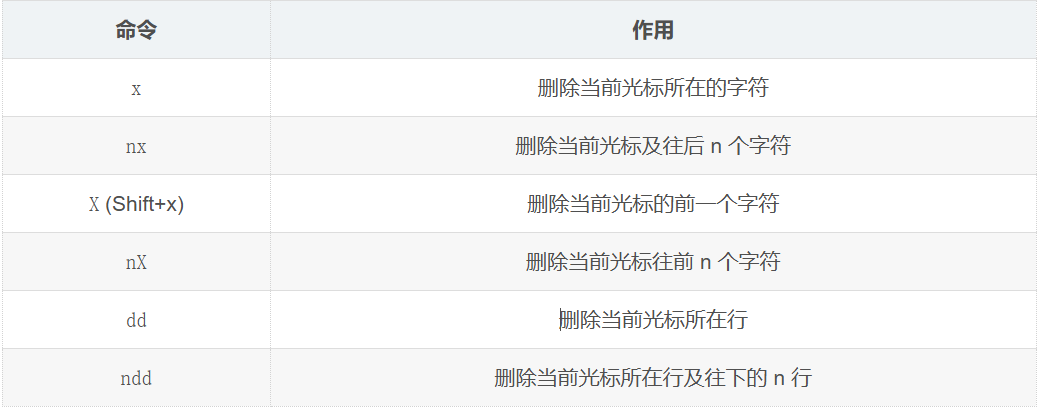
这里的删除其实是剪切的操作,可以配合(n)p来粘贴
复制与粘贴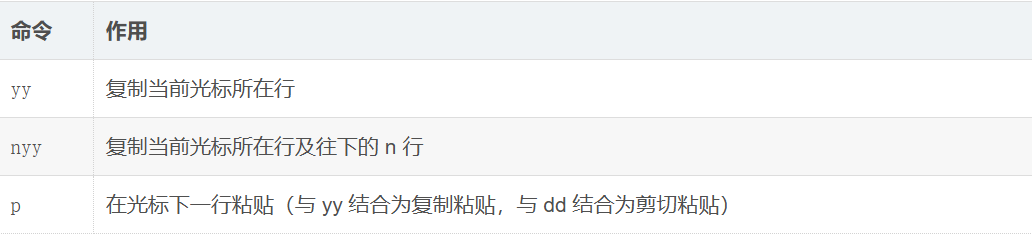
替换命令
撤销与重做
| 命令 | 作用 |
|---|---|
u |
撤销上一步操作 |
Ctrl + r |
对撤销进行撤销(重做) |
查找与保存退出命令
| 命令 | 作用 |
|---|---|
# (Shift+3) |
高亮查找光标所在的单词,按 n 跳到下一个匹配处 |
ZZ (Shift+z+z) |
保存并退出 Vim(等同于 :wq) |
2. 插入模式(Insert Mode)
唯一可以输入文字的模式。
核心作用:用于输入、修改文本。
进入方式:在命令模式下按 i
| 命令 | 作用 |
|---|---|
i |
在当前光标前插入 |
I |
在行首插入 |
a |
在当前光标后插入 |
A |
在行尾插入 |
o |
在下一行插入 |
O |
在上一行插入 |
退出 :按 Esc 回到命令模式
左下角会显示 -- INSERT -- 提示。
3. 底行模式(last line mode)
执行命令的模式,也叫末行模式。
进入方式 :在命令模式下按 :(Shift+;)
核心作用:
-
保存文件
-
退出 Vim
-
查找字符串
-
替换文本
-
显示行号
常用操作:
| 命令 | 作用 |
|---|---|
:w |
保存 |
:q |
退出 |
:wq |
保存并退出 |
:q! |
强制退出(不保存) |
| :wq! | 强制保存退出 |
:/hello |
查找 hello |
:%s/old/new/g |
全局替换 |
:set nu |
显示行号 |
:set nonu |
隐藏行号 |
| ! command(命令) | 不退出vim执行命令如!pwd |
*替换模式(Replace Mode)
覆盖式输入 。在插入模式下,输入新字符会"推着"后面的字符往前走;在替换模式下,输入新字符会逐个覆盖光标后面的字符。
进入方式 :按 R 键(Shift +r)
*视图模式(Visual Mode)
进行文本选中,先选中一段文本,然后对这段选中的文本统一执行某个操作(如删除、复制、缩进、大小写转换等)(类似鼠标拖选功能)。
进入方式:
-
v:进入字符可视模式(按字符选择) -
V:进入行可视模式(按整行选择) -
Ctrl + v:进入块可视模式(按矩形块选择)
特点:
-
用于选中文本区域,类似鼠标拖选
-
状态栏会显示
-- VISUAL --、-- VISUAL LINE --或-- VISUAL BLOCK --
批量注释技巧:在命令模式下ctrl+v 进入视图模式使用hjkl进行区域块选择,接着Shift+i(I)进入插入模式,然后使用//注释一行接着按Esc完成批量注释(退出后在命令模式下)。如果要注释所有内容在视图模式下Shift+g全选接着同理
模式切换图:
3.编译器 gcc g++
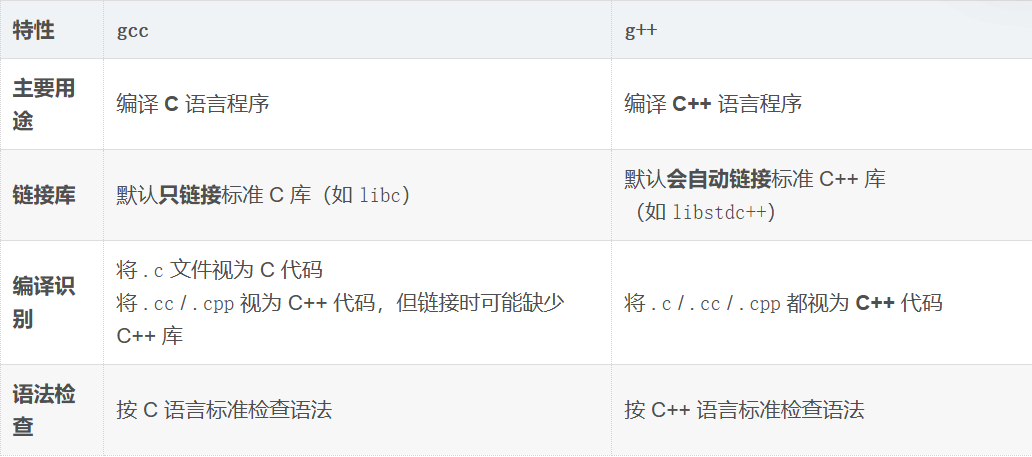
gcc vs g++
 C/C++程序的执行流程:
C/C++程序的执行流程: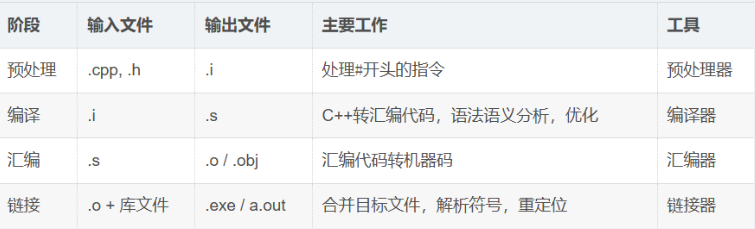 C++模板进阶解析:非类型参数、特化技术与分离编译实战-CSDN博客这篇博客有详细介绍
C++模板进阶解析:非类型参数、特化技术与分离编译实战-CSDN博客这篇博客有详细介绍
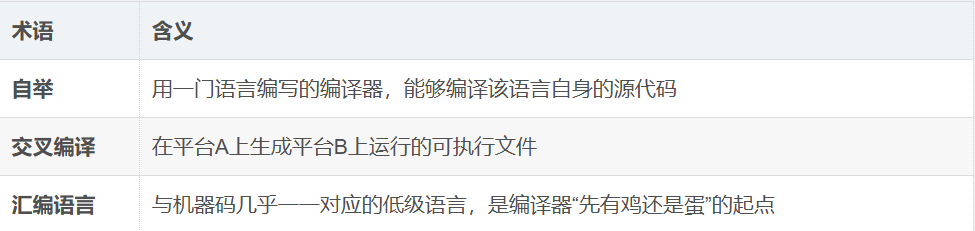
编译器自举
编译器自举是指用某门编程语言的编译器,去编译该语言本身的编译器的过程。简单来说,就是"自己编译自己"。
C语言编译器的自举步骤
设计C语言语法(在文档中定义规则)
用汇编语言写一个"最小C编译器"(功能简陋,仅能编译简单的C程序)
用汇编编译器编译这个最小编译器 → 得到可执行文件(即最小C编译器)
用这个最小编译器,编译一个"更好的C编译器"的源代码(该源代码是用C语言本身写的,功能更全)
得到V1版C编译器(能编译完整C语言)
修改源代码,得到V2版编译器源代码(增加优化、修复bug)
用V1编译器编译V2的源代码 → 生成V2版可执行编译器
自举完成:从此C编译器可以一直用C语言自身来改进
常用命令示例
bash
gcc [选项] 要编译的⽂件 [选项] [⽬标⽂件]编译 C 程序 (gcc)
bash
# 将 main.c 编译成可执行文件 myapp
gcc main.c -o myapp
# 仅编译成目标文件(不链接)
gcc -c main.c -o main.o编译 C++ 程序 (g++)
bash
# 将 main.cpp 编译成可执行文件 myapp
g++ main.cpp -o myapp
# 编译多个文件
g++ main.cpp helper.cpp -o myapp
# 启用警告和 C++11 标准
g++ main.cpp -o myapp -Wall -std=c++11关键选项
-
-o <文件名>:指定输出的可执行文件名。 -
-c:只编译不链接,生成目标文件(.o)。 -
-Wall:显示所有常见的警告信息(强烈推荐)。 -
-g:生成供调试器(如gdb)使用的调试信息。 -
-O2:开启二级优化,提高程序运行效率。
gcc/g++的-D选项用于在编译时在命令行定义宏 ,效果等同于在源代码中使用#define。
cpp
gcc -DDEBUG program.c
//等价于
#define DEBUG
gcc -DVERSION=3 program.c
//等价于
#define VERSION 3
gcc -DNAME=\"John\" program.c
//等价于
#define NAME "John"
# 方式1:多个 -D
gcc -DDEBUG -DVERSION=1 -DNAME=\"test\" program.c
# 方式2:统一写(不推荐,可读性差)
gcc "-DDEBUG -DVERSION=1 -DNAME=\"test\"" program.c接下来我将使用gcc编译器分步编译test.c文件
1.预处理
预处理完成以下任务:
-
**头文件展开:**将头文件内容拷贝到源文件中
-
宏替换
-
**条件编译:**对代码进行动态裁剪,可以用于多版本功能维护如社区版和专业版
-
删除注释
-
添加行号与文件标识
使用 -E 选项,可以让 gcc 或 g++ 在预处理完成后停止。
基本语法:
bash
gcc -E 源文件 -o 输出文件名
bash
xqq@ubuntu-server:~/mydir/test$ ll
total 12
drwxr-xr-x 2 xqq xqq 4096 Apr 16 20:56 ./
drwxr-xr-x 3 xqq xqq 4096 Apr 16 20:54 ../
-rw-r--r-- 1 xqq xqq 140 Apr 16 20:56 test.c
xqq@ubuntu-server:~/mydir/test$ gcc -E test.c -o test.i
xqq@ubuntu-server:~/mydir/test$ ll
total 32
drwxr-xr-x 2 xqq xqq 4096 Apr 16 21:13 ./
drwxr-xr-x 3 xqq xqq 4096 Apr 16 20:54 ../
-rw-r--r-- 1 xqq xqq 140 Apr 16 20:56 test.c
-rw-rw-r-- 1 xqq xqq 18022 Apr 16 21:13 test.i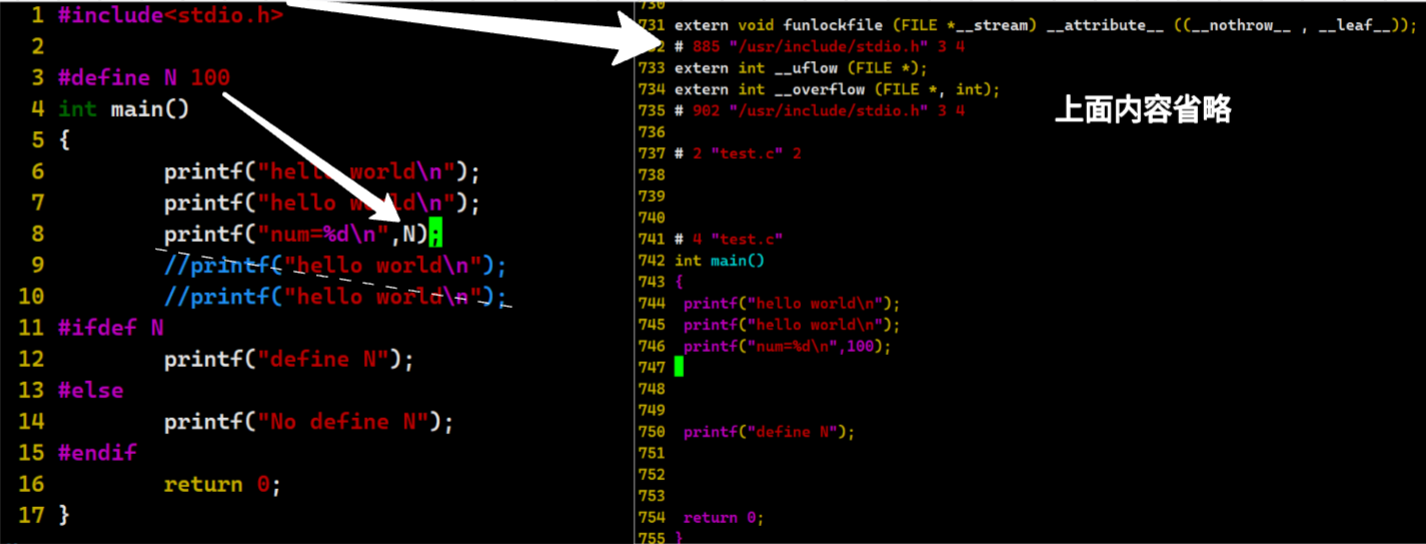
2.编译
在预处理阶段生成了干净的 .i 或 .ii 文件后,编译 阶段的核心任务是将这些预处理后的代码 翻译成汇编语言 。这个阶段是整个编译流程中最复杂、最核心的一步,它由多个子步骤组成,完全是在后台自动完成的:
-
词法分析 :将源代码拆解成一个个有意义的"单词",如关键字
int、标识符main、运算符=、常量0等。 -
语法分析 :根据 C/C++ 的语法规则,将 Token 序列组合成"语法树"(如表达式、语句、函数定义),检查括号是否匹配、语句末尾分号等。绝大多数语法错误(如漏写分号、缺少括号)都在此阶段被捕获。
-
语义分析:检查语法树的含义是否合法。例如:变量是否声明、类型是否匹配、函数调用参数是否正确等。
-
中间代码生成:将语法树转换成平台无关的中间表示,方便后续优化。
-
优化:对中间代码进行优化,例如删除永远不会执行的代码、简化常量计算、提取循环中不变的变量等。
-
目标汇编代码生成 :将优化后的中间代码转换为目标机器架构的汇编指令 ,生成
.s汇编文件。
使用 -S 选项,可以让 gcc 或 g++ 在编译完成后(即生成汇编文件后)停止。
基本语法:
bash
gcc -S 源文件 -o 输出文件名
bash
xqq@ubuntu-server:~/mydir/test$ ll
total 32
drwxr-xr-x 2 xqq xqq 4096 Apr 16 21:43 ./
drwxr-xr-x 3 xqq xqq 4096 Apr 16 20:54 ../
-rw-r--r-- 1 xqq xqq 257 Apr 16 21:26 test.c
-rw-rw-r-- 1 xqq xqq 18032 Apr 16 21:43 test.i
xqq@ubuntu-server:~/mydir/test$ gcc -S test.i -o test.s
xqq@ubuntu-server:~/mydir/test$ ll
total 36
drwxr-xr-x 2 xqq xqq 4096 Apr 16 21:44 ./
drwxr-xr-x 3 xqq xqq 4096 Apr 16 20:54 ../
-rw-r--r-- 1 xqq xqq 257 Apr 16 21:26 test.c
-rw-rw-r-- 1 xqq xqq 18032 Apr 16 21:43 test.i
-rw-rw-r-- 1 xqq xqq 933 Apr 16 21:44 test.s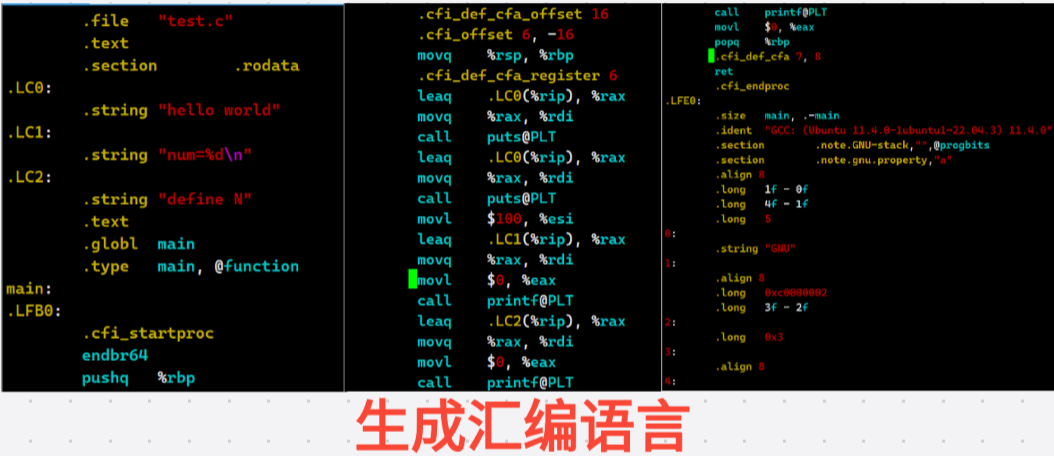
3.汇编
在上一阶段(编译)生成了汇编文件(.s)后,汇编阶段 的任务是将人类可读的汇编代码 翻译成机器可执行的指令 ,生成目标文件 (.o 或 .obj)。
这个阶段相对简单直接,主要做两件事:
-
翻译指令 :将汇编指令(如
movq %rax, %rdi、call puts)逐条翻译成对应的二进制机器码 (如48 89 c7、e8 00 00 00 00)。 -
生成符号表:记录目标文件中的符号信息,例如:
-
定义的符号 :函数名(如
main)、全局变量名及其地址偏移。 -
引用的外部符号 :如
printf、puts,这些函数尚未在本文件中找到定义,需要链接器帮忙解决。
-
关键点:
-
汇编器不检查语法 (语法已在编译阶段检查完毕),它只做机械的翻译。
-
生成的机器码是与 CPU 架构相关的(如 x86、ARM)。
-
目标文件(
.o)已经是二进制格式,不再是文本文件,直接用文本编辑器打开会看到乱码。
使用 -c 选项,可以让 gcc 或 g++ 在汇编完成后停止。
基本语法:
bash
gcc -c 汇编文件 -o 输出文件名
bash
xqq@ubuntu-server:~/mydir/test$ ll
total 36
drwxr-xr-x 2 xqq xqq 4096 Apr 16 21:54 ./
drwxr-xr-x 3 xqq xqq 4096 Apr 16 20:54 ../
-rw-r--r-- 1 xqq xqq 257 Apr 16 21:26 test.c
-rw-rw-r-- 1 xqq xqq 18032 Apr 16 21:43 test.i
-rw-rw-r-- 1 xqq xqq 933 Apr 16 21:44 test.s
xqq@ubuntu-server:~/mydir/test$ gcc -c test.s -o test.o
xqq@ubuntu-server:~/mydir/test$ ll
total 40
drwxr-xr-x 2 xqq xqq 4096 Apr 16 21:55 ./
drwxr-xr-x 3 xqq xqq 4096 Apr 16 20:54 ../
-rw-r--r-- 1 xqq xqq 257 Apr 16 21:26 test.c
-rw-rw-r-- 1 xqq xqq 18032 Apr 16 21:43 test.i
-rw-rw-r-- 1 xqq xqq 1752 Apr 16 21:55 test.o
-rw-rw-r-- 1 xqq xqq 933 Apr 16 21:44 test.stest.o/XXX.obj也叫做可重定位目标文件 ,他是二进制文件直接打开全是乱码
为什么叫"可重定位"?
1. 地址尚未确定
-
目标文件中的代码和数据地址还不是最终的内存地址 ,而是相对于当前模块的偏移量(通常从 0 开始)
-
例如:
call printf的地址还是0x00占位符,不知道printf在内存的哪个位置
2. 链接时需要"重定位"
-
链接器会将多个可重定位文件(
.o/.obj)和库文件合并 -
重新计算每个符号的最终运行时地址 (如
main函数的实际地址、printf的实际地址) -
修改机器码中的地址占位符为真实地址------这个过程就叫重定位
源文件中包含了很多库方法比如printf,但源文件中并没有函数实现,因此还需最后一步:
4.链接
链接阶段做什么?
链接器 (ld)负责将多个目标文件和库文件合并成最终的可执行文件,主要做两件事:
-
符号解析
找到每个符号(函数、全局变量)的定义位置。
例如:
printf在test.o中只是声明(U printf),链接器需要去 C 标准库(如libc.so或libc.a)中找到它的实现。 -
重定位
将所有目标文件的代码和数据段合并,为每个符号分配最终的内存地址,并修正机器码中的地址占位符。
bash
# 链接 XXXX.o 和 C 标准库,生成可执行文件
gcc XXXX.o -o test
bash
xqq@ubuntu-server:~/mydir/test$ ll
total 40
drwxr-xr-x 2 xqq xqq 4096 Apr 16 21:58 ./
drwxr-xr-x 3 xqq xqq 4096 Apr 16 20:54 ../
-rw-r--r-- 1 xqq xqq 257 Apr 16 21:26 test.c
-rw-rw-r-- 1 xqq xqq 18032 Apr 16 21:43 test.i
-rw-rw-r-- 1 xqq xqq 1753 Apr 16 21:58 test.o
-rw-rw-r-- 1 xqq xqq 933 Apr 16 21:44 test.s
xqq@ubuntu-server:~/mydir/test$ gcc test.o -o test
xqq@ubuntu-server:~/mydir/test$ ll
total 56
drwxr-xr-x 2 xqq xqq 4096 Apr 16 22:05 ./
drwxr-xr-x 3 xqq xqq 4096 Apr 16 20:54 ../
-rwxrwxr-x 1 xqq xqq 16000 Apr 16 22:05 test*
-rw-r--r-- 1 xqq xqq 257 Apr 16 21:26 test.c
-rw-rw-r-- 1 xqq xqq 18032 Apr 16 21:43 test.i
-rw-rw-r-- 1 xqq xqq 1753 Apr 16 21:58 test.o
-rw-rw-r-- 1 xqq xqq 933 Apr 16 21:44 test.s
xqq@ubuntu-server:~/mydir/test$ ./test*
hello world
hello world
num=1004.动静态库
4.1动静态库是什么
1.库是什么?
库(Library) 就是已经编译好的、可复用的代码集合,类似于:
-
生活中的"工具箱":里面放着常用的工具(函数),随取随用
-
编程中的"预制件" :别人写好的
printf()、sqrt()、sort(),你直接调用就行
库分为两种:静态库 和 动态库。
2.静态库是什么?
静态库 :在编译链接阶段 ,把库中的代码直接复制到你的可执行文件里。
-
文件后缀 :
.a(Linux)、.lib(Windows) -
特点 :链接后,你的程序就独立了,不再需要库文件
比喻 :你要做一道菜(你的程序),从超市买回现成的调料包 (静态库),拆开倒进去一起炒。最后这盘菜里已经包含了调料,不需要再放调料包了。
3.动态库是什么?
动态库 :编译时只记录"引用" ,不复制代码;运行时 才把库加载到内存,多个程序可以共享同一份。
-
文件后缀 :
.so(Linux)、.dll(Windows) -
特点 :可执行文件很小,但运行时必须依赖库文件存在
比喻 :你做菜时只写了个菜谱 (记录"需要盐"),等吃饭时 再从盐罐里取盐 。而且多个菜可以共用同一个盐罐。
4.为什么要有库?
-
避免重复造轮子
-
没有库 :每个程序都要自己写
printf()→ 100个程序写100遍 -
有库 :
printf()放在库里,所有程序调用即可
-
-
节省磁盘和内存(动态库特有)
-
静态库 :100个程序都用
printf()→ 每个程序里都复制一份 → 浪费几百MB磁盘和内存 -
动态库 :100个程序共享一份
printf()代码 → 极省资源
-
-
方便更新维护
-
静态库 :发现
printf()有bug → 100个程序全部重新编译、重新发布 -
动态库 :只替换一个
.so文件 → 所有程序自动修复
-
-
实现插件化架构
-
动态库特有优势 :主程序运行时动态加载 插件(
.dll/.so) -
用户可随时添加新功能,无需重装软件
-
一图看懂区别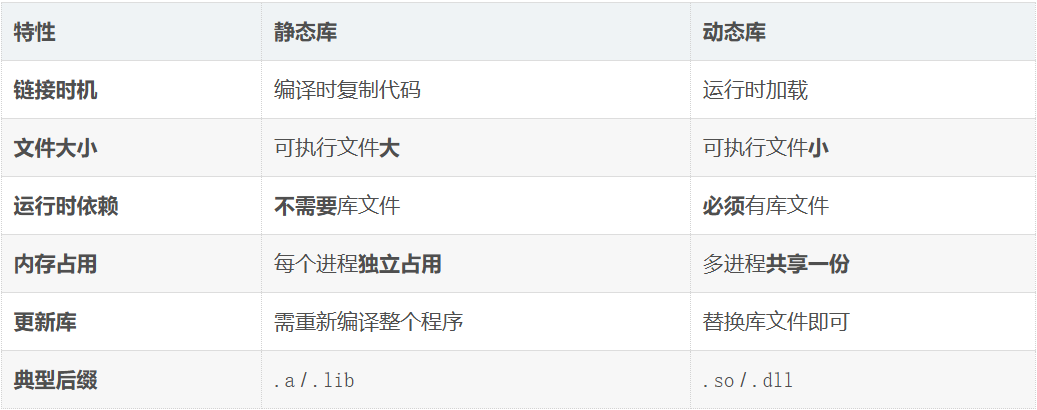
静态解决"代码组织"问题,动态库(共享库)解决"资源浪费"问题,没有库就没有现代软件工程。
4.2库的命名方式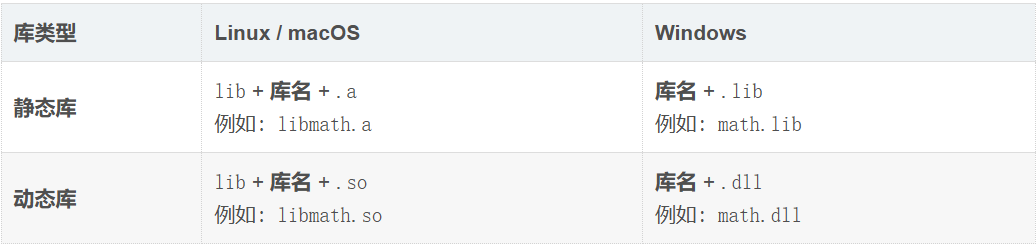
关键点 :Linux下动/静态库都带
lib前缀,而Windows下通常没有。
4.3 静态链接 vs 动态链接
为什么需要链接?
在实际开发中,不可能将所有代码放在一个源文件中。多个源文件之间存在依赖关系(如一个文件调用另一个文件中定义的函数)。每个 *.c 文件独立编译成 *.o 目标文件,链接就是把这些目标文件合并成一个可执行程序的过程。
1. 静态链接
定义 :在编译阶段,将所有需要的目标文件直接合并到最终的可执行文件中。
缺点:
-
浪费空间 :每个可执行程序都有一份目标文件的副本。比如多个程序都调用
printf(),每个程序里都包含一份printf.o,内存中存在多个副本。 -
更新困难 :库函数的代码修改后,所有依赖它的程序都需要重新编译链接。
优点:
- 可执行程序中已具备运行所需的一切,运行时速度快 ,不依赖外部环境。
2. 动态链接
定义 :把程序按模块拆分成相对独立的部分,在程序运行时才将它们链接在一起形成完整程序。
优点:
-
节省空间:多个程序共享同一份动态库的物理内存副本。
-
更新方便:替换动态库文件即可,无需重新编译所有依赖程序。
查看程序依赖的动态库(以Linux为例):
ldd指令
ldd 是 List Dynamic Dependencies 的缩写,用于列出可执行文件或动态库所依赖的动态库。
bash
ldd [选项] 文件名| 选项 | 作用 | 示例 |
|---|---|---|
-v |
显示详细信息(包括版本信息) | ldd -v test |
-u |
显示未使用的直接依赖 | ldd -u test |
-r |
显示重定位信息 | ldd -r test |
bash
xqq@ubuntu-server:~/mydir/test$ ll
total 56
drwxr-xr-x 2 xqq xqq 4096 Apr 16 22:05 ./
drwxr-xr-x 3 xqq xqq 4096 Apr 16 20:54 ../
-rwxrwxr-x 1 xqq xqq 16000 Apr 16 22:05 test*
-rw-r--r-- 1 xqq xqq 257 Apr 16 21:26 test.c
-rw-rw-r-- 1 xqq xqq 18032 Apr 16 21:43 test.i
-rw-rw-r-- 1 xqq xqq 1753 Apr 16 21:58 test.o
-rw-rw-r-- 1 xqq xqq 933 Apr 16 21:44 test.s
xqq@ubuntu-server:~/mydir/test$ ldd test
linux-vdso.so.1 (0x00007ffca5df9000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007fdd55fb1000)
/lib64/ld-linux-x86-64.so.2 (0x00007fdd561e8000)可以看到 test程序依赖了C标准动态库 libc.so.6。
file 指令
file 用于识别文件类型。它会读取文件头信息,告诉你这个文件到底是什么类型的(可执行文件、文本文件、图片、压缩包等)。
bash
file [选项] 文件名
bash
xqq@ubuntu-server:~/mydir/test$ file test
test: ELF 64-bit LSB pie executable, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, BuildID[sha1]=489656c71777e2a0fe3e426365b5d47b7db9f038, for GNU/Linux 3.2.0, not stripped由上面执行的file和ldd可知道test默认是动态连接( dynamically linked)的,想要强制静态要带选项-static
bash
xqq@ubuntu-server:~/mydir/test$ gcc test.c -o test_static -static
xqq@ubuntu-server:~/mydir/test$ ll
total 936
drwxr-xr-x 2 xqq xqq 4096 Apr 20 17:23 ./
drwxr-xr-x 3 xqq xqq 4096 Apr 16 20:54 ../
-rwxrwxr-x 1 xqq xqq 16000 Apr 16 22:05 test*
-rw-r--r-- 1 xqq xqq 257 Apr 16 21:26 test.c
-rw-rw-r-- 1 xqq xqq 18032 Apr 16 21:43 test.i
-rw-rw-r-- 1 xqq xqq 1753 Apr 16 21:58 test.o
-rw-rw-r-- 1 xqq xqq 933 Apr 16 21:44 test.s
-rwxrwxr-x 1 xqq xqq 900440 Apr 20 17:23 test_static*
xqq@ubuntu-server:~/mydir/test$ file test_static
test_static: ELF 64-bit LSB executable, x86-64, version 1 (GNU/Linux), statically linked, BuildID[sha1]=4372dec8e580b8020247048de5f2a18c518a3728, for GNU/Linux 3.2.0, not stripped
xqq@ubuntu-server:~/mydir/test$ ldd test_static
not a dynamic executable
#not a dynamic executable = 这是一个静态链接的程序,它不依赖任何动态库,所以 ldd 无依赖可列。由上面的结果,静态链接(statically linked)版本比动态链接版本大了约56倍 !这就是静态链接"浪费空间"最直观的证据**,因为所有依赖的库代码都被"焊死"进了可执行文件。**