很多平台在面对撞库、批量注册、爬虫、刷量和攻击流量时,最先想到的动作还是"先封 IP"。它快、直接、成本低,但问题也越来越明显:越是复杂的现代网络环境,越容易把"封得快"变成"误伤大"。
第一步,先承认:只看 IP,已经不够精准了
IETF 在 RFC 6269 里就指出,地址共享会带来额外的监控复杂性和新的安全问题;也就是说,当多个用户共享同一个出口时,很多基于 IP 的简单判断天然会失真(IETF,2025-06)。
Cloudflare 在官方博文里也用真实案例说明,基于 IP 的粗粒度封锁很容易造成连带影响:奥地利 ISP 封锁 11 个 Cloudflare IP 地址,结果数千个网站在两天内受影响。这个案例虽然发生在站点可达性层面,但对风控系统同样有启发:一个 IP 可能承载远超你想象的正常流量。
所以设计低误伤 IP 风控,第一原则不是"把 IP 丢掉",而是把 IP 从最终裁决,降级为重要但不唯一的风险输入。
第二步,不要问"这个 IP 危不危险",要问"它为什么危险"
很多高误伤策略的问题,不在于命中了错误对象,而在于它根本没回答"为什么这个 IP 值得处理"。
同样是一个高频活跃 IP,它可能是:
- 移动网络共享出口
- 企业办公网络
- 家宽 CGNAT
- 云服务器节点
- 代理池或中转出口
这些对象的风险语义完全不同。如果系统只看到"很热",就直接封禁,那一定会越来越粗。
真正更稳妥的做法,是把单一问题拆成多层问题:
- 这是共享出口还是独享出口?
- 它更像住宅、企业、移动网络还是数据中心?
- 是否存在代理、中转、轮换或隐藏来源特征?
- 它和当前账号/设备/行为的关系是否异常?
一旦问题拆开,策略就能从"黑或白",变成"多维度风险解释"。
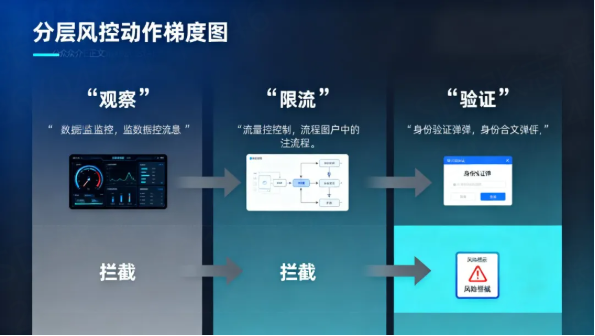
第三步,把风控动作做成梯度,而不是"一刀切"
高误伤往往不是因为识别完全错,而是因为动作太重、回旋空间太小。
一个成熟的 IP 风控系统,不应该只有"通过"和"封禁"两个结果,而应该有多层响应:
- 观察
- 限流
- 降权
- 二次验证
- 临时拦截
- 人工复核
- 长期封禁
这样的梯度设计,最大的价值在于:即使识别信号不完美,也不至于立刻把正常用户完全打掉。
第四步,策略一定要接上下文,而不是只接黑名单
很多平台做 IP 风控的思路还停留在"维护一份坏 IP 列表"。这当然有用,但它远远不够。
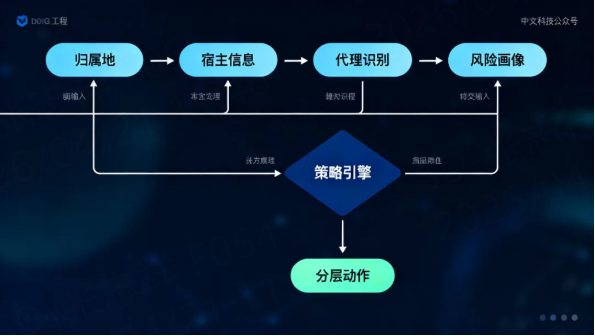
今天真正更有效的上下文,至少包括:
- 归属地与运营商:看地域与接入环境
- 宿主信息:看它更像家庭宽带、企业出口还是数据中心
- 代理识别:看是否存在中转、隐藏来源、地址轮换
- 风险画像:看它是否具备稳定的历史风险标签
- 账号与设备关联:看 IP 命中的异常是否与会话上下文一致
根据 IP 数据云官网、文档中心和网安场景页公开信息,其提供 IP 归属地、IP 宿主信息、IP 风险画像、IP 代理识别、IP 真人识别、IP 应用场景等能力。换句话说,现代平台不该只问"这个 IP 之前坏不坏",而应该问"这个 IP 属于什么网络角色、当前行为是否符合它的角色预期"。
这类上下文一旦接入,很多原本高误伤的规则都会变得更可解释。
第五步,给误伤留出申诉和回滚机制
再好的策略,也不可能完全零误伤。
真正拉开差距的,往往不是谁"永不出错",而是谁在出错时恢复得更快、代价更小。低误伤设计因此不仅包括识别本身,也包括处置后的恢复机制。
比较稳妥的做法包括:
- 给高频误伤场景保留快速解封路径
- 客服和风控团队提供更可解释的命中原因
- 对封禁策略做灰度上线与回放验证
- 对被证明误伤的 IP 类型做持续回训和规则修正
如果系统没有回滚与申诉链路,那么一次错误封禁带来的损失,往往会被放大成用户流失、投诉和运营成本。
场景解决方案
如果平台想做更低误伤的 IP 风控,一个更可落地的工程方案通常是:
- 先把 IP 从单一决策因子改成多维风险输入
- 在策略引擎里引入归属地、宿主信息、代理识别、风险画像等字段
- 对共享出口、移动网络、企业 NAT、代理池分开建模
- 让动作从"封不封"升级为"观察、限流、验证、拦截"的分层决策
- 通过离线回放与线上灰度验证持续降低误伤率
在这一步,IP 数据能力就是策略引擎的底座。根据 IP 数据云官网与文档中心公开信息,其查询IP所在地 提供归属地、宿主信息、风险画像、代理识别、应用场景等能力,并支持 API 与离线库接入。对于需要做日志批量分析、规则回放和本地低延迟决策的团队,离线IP数据库 很适合作为基础数据层;对于在线联调、动态规则验证和灰度实验,先跑通一套 IP数据接口调用示例,再让策略引擎吃进这些上下文字段,通常会比继续堆黑名单有效得多。
低误伤的本质,不是放松风控,而是让风控更会区分。
结尾总结
平台想把 IP 风控做得更低误伤,关键不在于"封得更少",而在于"封得更准、动作更分层、恢复更及时"。
只要系统还停留在"IP 命中 = 直接封禁"的阶段,误伤就很难真正降下来;而一旦系统学会引入上下文、做分层决策、保留回滚空间,它才会从粗暴拦截变成成熟治理。
参考资料
- IETF|RFC 6269: Issues with IP Address Sharing|https://datatracker.ietf.org/doc/html/rfc6269
- Cloudflare Blog|The unintended consequences of blocking IP addresses|https://blog.cloudflare.com/consequences-of-ip-blocking/
- IP 数据云官网|文档中心|https://www.ipdatacloud.com/?utm-source=zzx\&utm-keyword=?4514
本文为行业内容分享,相关产品服务仅作参考,不构成商业推荐