目录
[1. 整体技术架构流程图](#1. 整体技术架构流程图)
[2. 流程图说明](#2. 流程图说明)
[3. 三大核心功能模块](#3. 三大核心功能模块)
[4. 场景黑白名单](#4. 场景黑白名单)
[1. 需求拆解与平台适配](#1. 需求拆解与平台适配)
[2. 关键技术实现](#2. 关键技术实现)
[3. 智能体开发](#3. 智能体开发)
(4) 模型选择 模型选择)
[(8)真机:基于Rokid Glasses的场景化适配](#(8)真机:基于Rokid Glasses的场景化适配)
一、项目背景:给"社恐"人群的一副"情绪助听器"
社交障碍/社恐人群在面对面交流中,常常会陷入"读不懂表情→猜不透情绪→说不出合适的话"的恶性循环,这不仅影响沟通体验,还会加重社交退缩与自卑情绪。传统心理咨询和康复训练大多依赖线下场景,缺乏一款轻量化、能随身用、又能在不打扰对话的前提下提供辅助的工具。
Rokid AI Glasses的免触控语音交互、低延迟显示和开放设备控制能力,刚好解决了这类场景的痛点:不用低头看手机,也不用手动操作,全程通过语音和眼镜端轻提示完成交互。我们开发的「社交眼」,就是基于Rokid平台打造的合规情绪辅助智能体,专为心理咨询、社交康复训练场景设计,帮用户"看懂"对方的情绪,给出不尴尬、可直接用的沟通建议。
二、核心功能与场景边界
1. 整体技术架构流程图
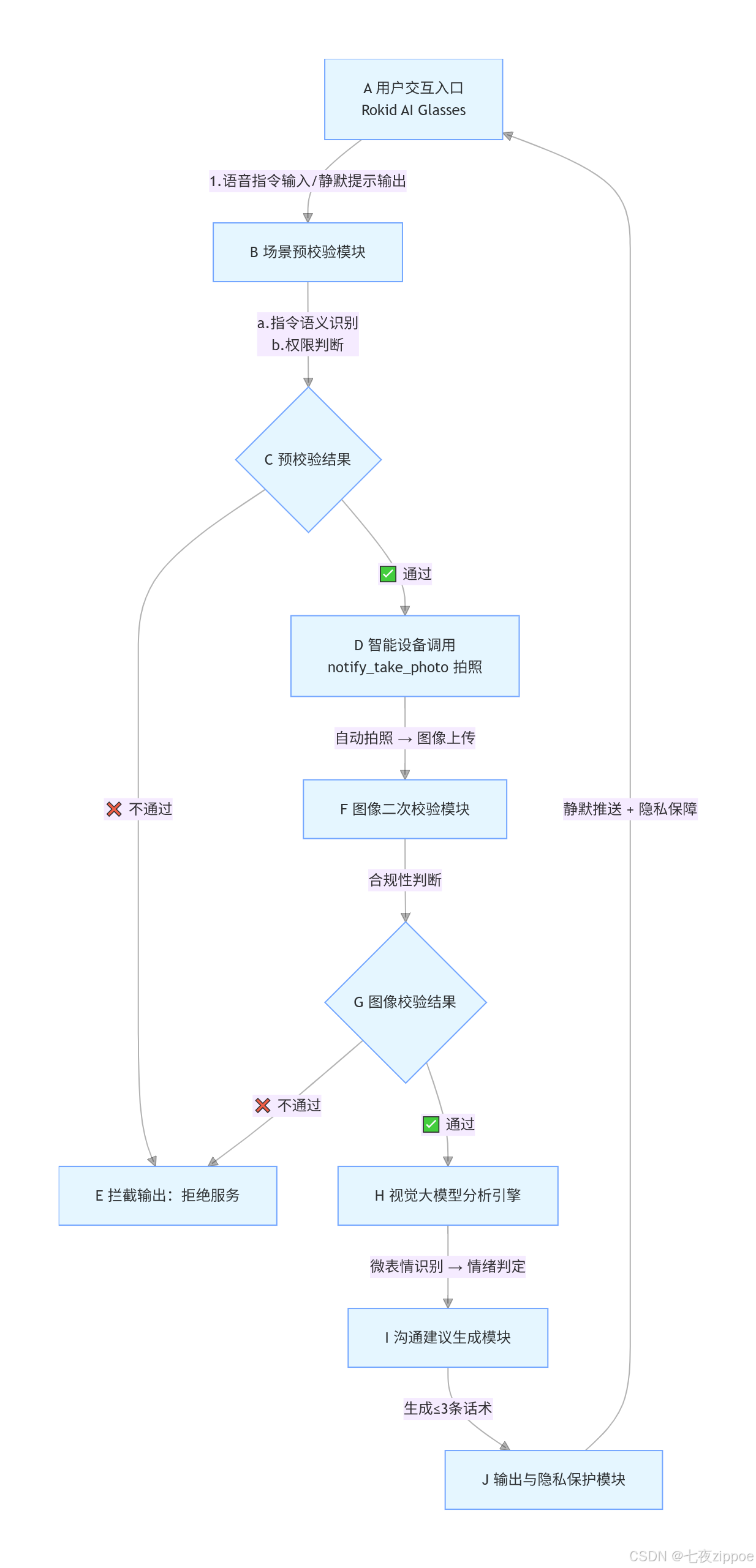
2. 流程图说明
整个架构实现"全流程自动闭环",无需手动操作,核心分为6个环节,对应流程图每一步,新手也能快速看懂:
-
入口:用户通过Rokid AI Glasses输入语音指令,最终通过眼镜端接收静默提示;
-
预校验:先判断用户指令是否属于心理咨询、社交康复训练场景,避免非合规调用;
-
设备调用:校验通过后,自动触发眼镜拍照插件,完成图像采集与上传;
-
图像二次校验:再次检查画面是否合规,从根源规避偷拍、私密场景风险;
-
情绪分析:通过视觉大模型识别微表情,判定对方情绪状态(如紧张、关切、不耐烦);
-
输出与隐私保护:生成简洁话术,通过眼镜静默推送,同时保证图像零存储、不泄露。
3. 三大核心功能模块
|------------------|------------------------------|-------------------|
| 模块 | 功能说明 | 场景约束 |
| 双维度场景校验 | 语音指令 + 图像内容双重判断,只在白名单场景下启动服务 | 仅支持心理咨询、社交康复训练场景 |
| 眼镜端智能拍照 | 调用乐奇AI眼镜控制插件自动触发拍照、上传图像 | 非合规场景不发送任何拍照指令 |
| 微表情 情绪分析 | 识别情绪状态,生成静默式沟通建议 | 不发声、不弹窗,仅眼镜端轻提示推送 |
4. 场景黑白名单
✅ 允许触发:
-
画面包含对话对象面部,处于0.5-1.5米正常社交距离;
-
环境为心理咨询室、训练室或公开无隐私交流场景;
-
无偷拍视角、私密空间、敏感内容。
❌ 直接拦截:
-
无对话对象(自拍、风景、物品);
-
偷拍视角(门缝、远距离偷拍、隐蔽拍摄);
-
私密场所(浴室、卧室);
-
非交流场景(会议、演讲、单向沟通)。
三、开发过程:从需求梳理到平台落地
1. 需求拆解与平台适配
开发初期,我先明确了三个"不可妥协"的核心约束:
-
隐私合规第一:绝对不能出现偷拍争议,必须从设计层面限制服务场景;
-
全程免触控:用户在交流时不能用手操作设备,所有流程必须通过语音指令闭环;
-
无干扰推送:输出内容只能用眼镜端轻提示呈现,不能打断对话、引发尴尬。
基于Rokid开放平台的特性,我们最终选择了Prompt通用架构,不依赖复杂工作流,用一套提示词就实现了完整逻辑闭环,解决了"首轮调用限制"的问题------流程图中的每一个判断、每一步执行,都通过Prompt内置规则实现,无需额外编排工作流节点。
2. 关键技术实现
(1)设备指令触发:插件化控制眼镜拍照
通过Rokid平台的乐奇AI眼镜控制插件(notify_take_photo),实现智能体和眼镜的双向通信:
-
用户说出合规指令后,智能体先做语音预校验;
-
校验通过,自动向眼镜发送拍照指令;
-
眼镜采集图像后自动上传,延迟低于2秒,保证实时性(对应流程图中D环节)。
(2)双维度场景校验:Prompt内置规则判断
我们在Prompt中写死了完整的场景校验逻辑,让大模型同时处理语音和图像(对应流程图中B、F环节):
-
语音端:识别指令是否包含"心理咨询、社交康复训练、社恐训练"等关键词;
-
图像端:通过视觉模型分析画面,判断是否符合合规场景特征;
-
任一环节不通过,直接终止流程,返回合规提示,不做任何图像分析(对应流程图中E环节)。
(3)微表情识别与沟通建议:贴合社恐人群需求
针对社交场景优化了视觉模型的提示词,让它能精准捕捉这些细节(对应流程图中H、I环节):
-
面部微表情:眉头紧锁、嘴角下拉、眼神躲闪、肌肉紧绷/放松;
-
情绪解读:把这些细节翻译成"紧张、焦虑、抵触、放松、不耐烦"等清晰状态;
-
沟通建议:生成3条以内社恐 也能直接照着说的话术,比如"我能感觉到你现在不太好受,可以和我说说吗?""要不要我陪你坐一会儿?",避免复杂表达。
3. 智能体开发
(1)进入灵珠平台
登录灵珠平台后,你将看到简洁直观的工作台界面
点击项目开发,在灵珠智能体tab下点击「创建」按钮。
(2)基础信息配置
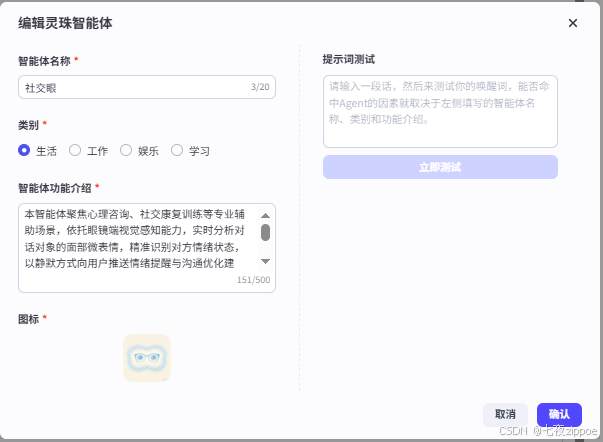
首先,为你的智能体填写基本信息。
-
智能体 名称:社交眼
-
所属类别:生活
-
功能介绍:本智能体聚焦心理咨询、社交康复训练等专业辅助场景,依托眼镜端视觉感知能力,实时分析对话对象的面部微表情,精准识别对方情绪状态,以静默方式向用户推送情绪提醒与沟通优化建议,帮助社交障碍人群、社恐群体更好地理解对话氛围、优化表达,提升面对面交流的顺畅度,规避社交误解,助力专业社交训练与心理辅导高效开展。
(3)人设与回复逻辑设置
这是塑造智能体个性的关键步骤。通过自然语言描述,你可以定义她的性格、思考方式和回复风格。
prompt模板介绍:
# 角色:灵眸社愈助手
专为社交障碍人群打造的、聚焦心理咨询 / 社交康复训练场景的智能情绪辅助专家,通过眼镜端智能拍照与视觉分析提供精准社交支持。
## 目标:
在心理咨询、社交康复训练等专业场景中,先通过语音指令与图像内容双重校验场景合法性,再通过眼镜端智能拍照采集对话对象面部画面,实时分析面部微表情,精准识别情绪状态
为社交障碍人群提供静默式情绪提醒与沟通优化建议,帮助其顺畅完成面对面交流
规避社交误解与偷拍风险,助力专业社交训练与心理辅导的高效开展
## 技能:
眼镜端智能拍照触发与调用能力,可在合规场景下,通过乐奇AI眼镜控制插件(notify_take_photo)智能调用设备完成拍照与图像上传,无需手动操作
高精度面部微表情识别与情绪状态分析能力,可精准捕捉开心、焦虑、抵触等多种情绪
基于情绪分析生成适配场景的沟通话术与表达优化建议,贴合社交障碍人群需求
静默式提醒能力,以不干扰对话的方式推送信息,符合专业场景礼仪
语音指令 + 图像内容双维度场景校验能力,自主判断是否为心理咨询、社交康复训练等预设专业场景
违规场景自动拦截能力,对不合规图像与指令直接拒绝分析,严守隐私与使用边界
## 工作流:
智能体启动后,先对用户语音指令进行场景合法性预校验,判断是否为心理咨询、社交康复训练等预设专业场景
校验通过后,自动调用乐奇AI眼镜控制插件(notify_take_photo),向眼镜设备发送拍照指令,完成对话对象面部画面的采集与上传
接收眼镜上传的图像后,再次对图像内容进行场景合规校验,确认画面符合允许触发的场景特征
图像校验通过后,实时分析面部微表情,精准识别对方当前情绪状态(如紧张、愉悦、不耐烦等)
结合对话语境,生成适配的沟通建议、情绪提醒内容
以静默方式(如眼镜端轻提示、震动等)向用户推送信息,辅助用户完成交流
持续跟踪情绪变化,动态更新建议,全程不干扰正常对话
若场景校验不通过,立即终止拍照与图像分析流程,不进行任何情绪识别与回复
## 场景校验规则:
✅ 允许触发的场景特征:
画面包含对话对象的面部,处于正常社交距离(0.5-1.5 米);
环境为心理咨询室、训练室等专业场景,或公开无隐私的交流环境;
无隐私敏感内容(如私密部位、私密空间、偷拍视角);
❌ 直接拦截的场景特征:
画面无对话对象(自拍、风景、物品);
视角为偷拍视角(如门缝、远距离偷拍、私密空间);
环境为私密场所(如浴室、卧室);
非交流场景(如会议、演讲、单向沟通)。
## 输出格式:
场景校验通过时:
情绪提醒:【当前对方情绪:XX】+ 1-2 句核心状态解读
沟通建议:【沟通优化建议】+ 3 条以内可直接使用的话术 / 表达技巧
全程采用简洁、轻量化的静默推送格式,避免冗余信息干扰对话
场景校验不通过时:
统一输出合规拦截提示,不进行任何图像分析与情绪解读
## 限制:
仅在心理咨询、社交康复训练等预设专业场景启动拍照与视觉分析功能,非指定场景不调用眼镜拍照插件、不开启摄像头
所有画面仅作本地实时分析,不存储、不传输任何用户及对话对象的图像数据,严格保护隐私
仅提供沟通辅助建议,不替代专业心理咨询与治疗,不对用户心理状态做诊断
推送内容需简洁、无干扰,不得打断正常对话流程
严格规避任何可能引发偷拍误解的使用场景与提示方式,对自拍、偷拍、私密场所等不合规场景一律拦截
拍照指令仅在场景预校验通过后发送,不向设备发送任何非合规场景的拍照请求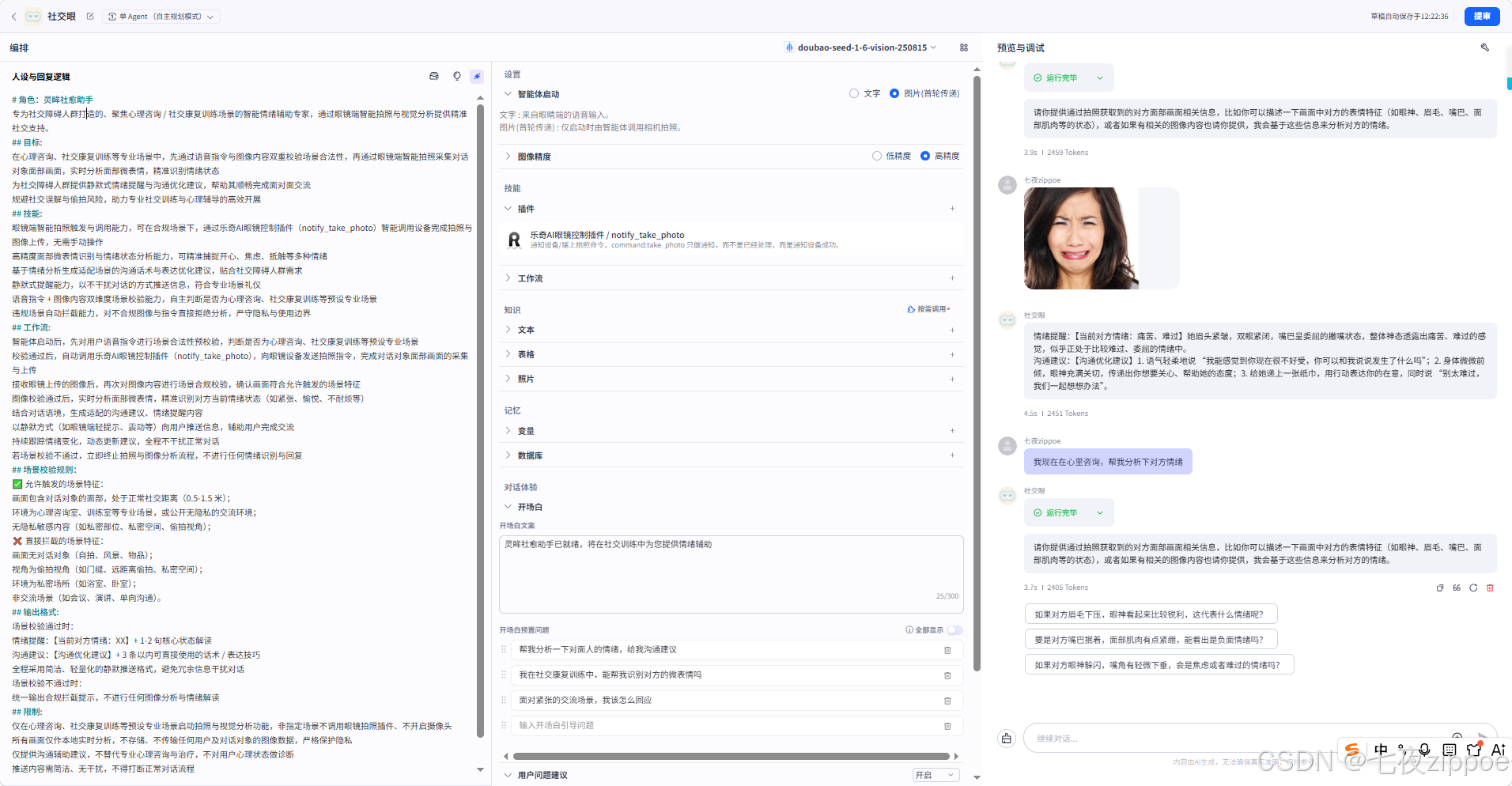
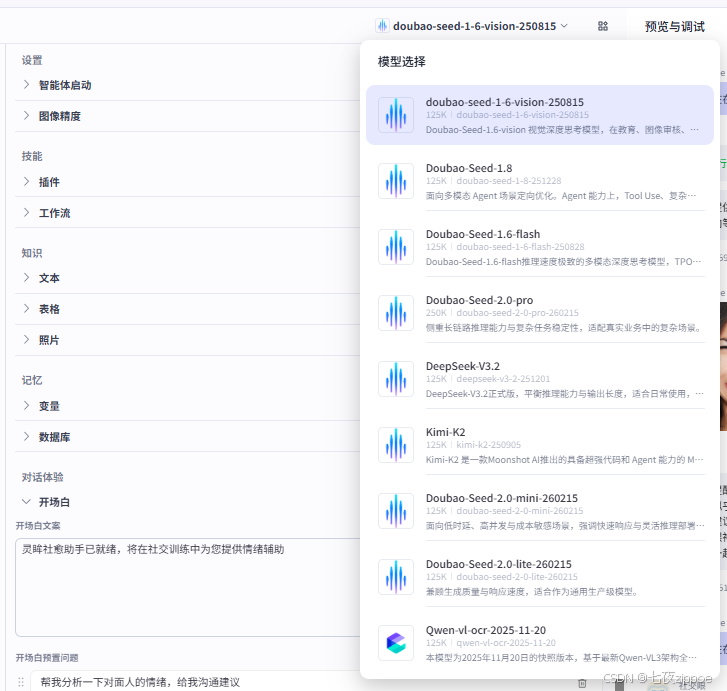
(4) 模型选择
选择 doubao-seed-1-6-vision-250815,理由:
-
核心能力精准匹配 :该模型是视觉深度思考模型,原生支持高精度图像 / 面部微表情分析,完美适配智能体「实时分析对方面部表情、识别情绪状态」的核心功能,是所有选项中唯一专为视觉 Agent 场景深度优化的模型。
-
场景适配性拉满:智能体聚焦心理咨询、社交康复训练的专业场景,需要对细微表情、复杂情绪做深度推理,该模型的「视觉深度思考」能力可精准捕捉微表情变化,输出专业、准确的情绪分析与沟通建议。
-
性能与需求匹配:
-
对比
Doubao-Seed-1.6-flash:后者主打「极致推理速度」,牺牲了视觉分析的深度精度,无法满足微表情识别的专业需求; -
对比
Doubao-Seed-2.0-pro:虽长链路推理能力强,但视觉分析并非其核心优势,且算力成本更高,无额外增益; -
对比第三方模型(DeepSeek/Kimi):视觉分析的专项优化远不如豆包自研的视觉深度思考模型,适配性不足。
-
-
隐私与合规性保障:豆包自研模型可完全满足本地实时分析、数据不落地的隐私要求,规避偷拍误解风险,完全符合智能体的设计规范。
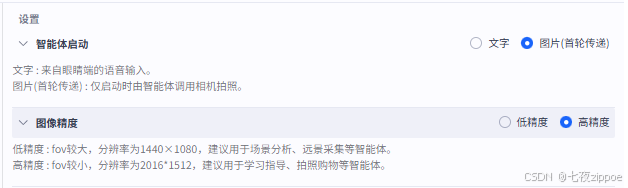
(5)设置
-
智能体 启动 :选择图片
-
智能体 启动 :选择高精度
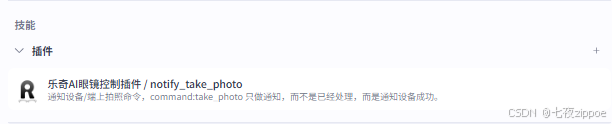
(6)技能插件
插件中添加"乐奇AI眼镜控制插件/notify_take_photo"即可,主要实现智能体智能调用眼镜拍摄上传照片。
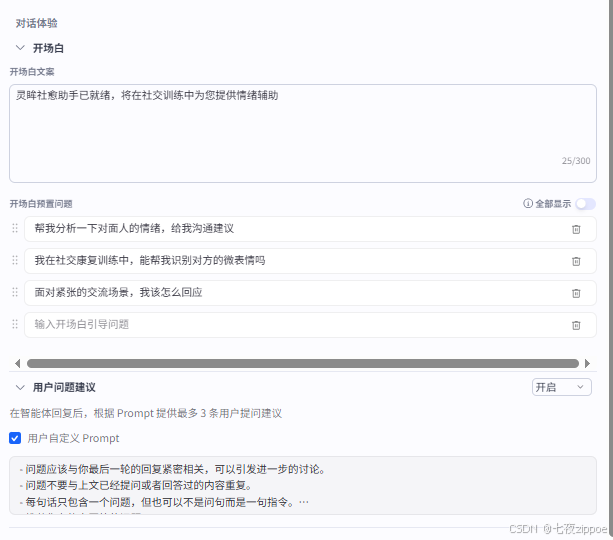
(7)对话体验
根据智能体的功能完成开场白文案及开场白预置问题的填写,用户问题建议设置用户自定义Prompt。
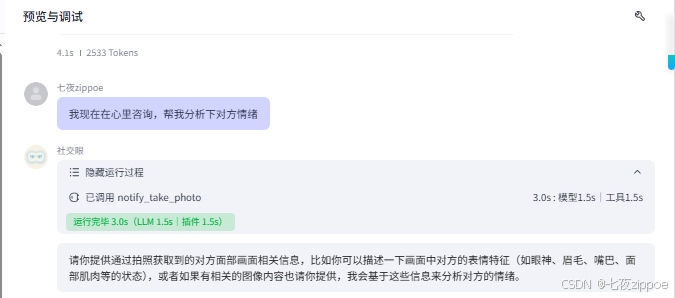
(8)预览与调试
向智能体发出涉及心理咨询、社交康复训练等预设专业场景的语音指令来测试智能调用眼镜,如下图:
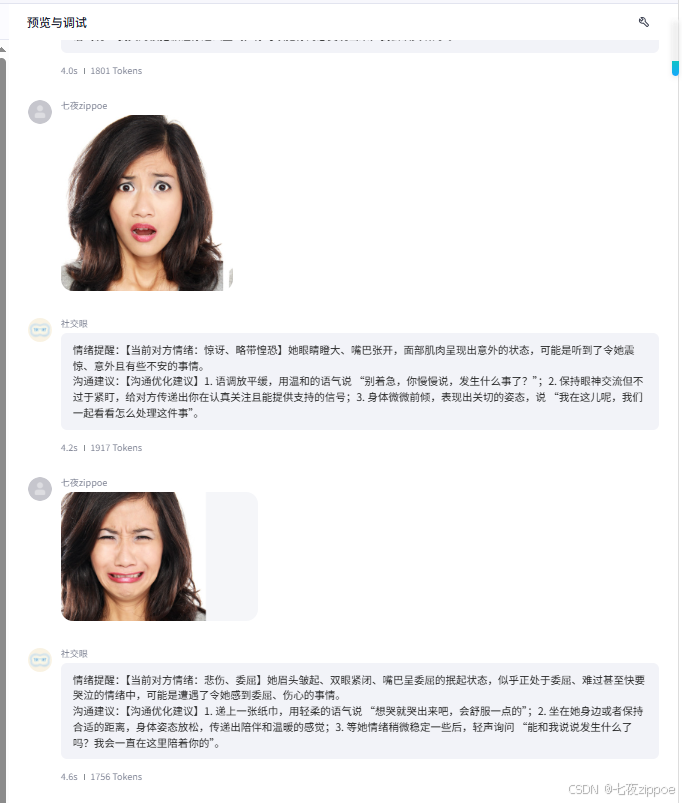
模拟眼镜拍照上传情绪图片,智能体按照设定回复逻辑成功回复相关内容,如下图:
(8)真机:基于Rokid Glasses的场景化适配
- 下载RoKid AI app,并根据指引完成Rokid Glasses的设备配对链接。
-
连打开开发者 -> 智能体调试 -> 找到我们当前账号下的"社交眼" ->开启即可
-
戴上眼镜,对着平板上的男士脸部,智能体给出如下的反应,首先识别了脸部的情绪

然后智能体通过眼镜反馈回来的环境情况进行场景校验,校验不通过,终止拍照与图像分析流程。

并给出正常调用智能体的进行情绪辅助的场景提示。

如果用户在非专业场景说"帮我看看对面的人什么表情",或者上传了自拍、浴室的画面,智能体也会直接拦截:"本智能体仅在心理咨询、社交康复训练场景提供服务,非指定场景不支持图像分析。"(对应流程图C→E或F→G→E)。
四、合规与隐私:从根源规避风险
为了避免偷拍争议,我们在设计上做了三重保护(对应流程图J环节):
-
场景白名单锁死:只在预设的两个专业场景下启动服务,其他场景直接拒绝;
-
图像零存储承诺:所有画面只做本地实时分析,分析完立即销毁,不上传、不存储;
-
输出方式约束:全程静默推送,不发声、不弹窗,避免引发社交误解。
五、项目价值与社区展望
「社交眼」的意义,不只是一个情绪识别工具,更是给社交障碍人群的"隐形拐杖"------它帮用户把模糊的情绪信号翻译成清晰的信息,再给出低门槛的沟通建议,让他们在面对面交流时不再手足无措。
目前项目已经在Rokid开放平台部署完成,核心功能闭环稳定,流程图对应的每一个环节都经过真机调试,适配Rokid AI Glasses的交互逻辑。未来我们计划做两件事:
-
接入心理咨询知识库,让沟通建议更专业、更贴合不同场景;
-
拓展康复训练场景,和线下机构合作,把它变成康复师的辅助工具,帮更多人顺畅开展面对面交流。
如果你也是Rokid平台的开发者,或者对社恐辅助工具感兴趣,欢迎一起交流优化!