从 Function Calling 到 MCP:为什么 AI 工具接入终于开始"像样了"
想象一下,你要做一个"AI 点外卖助手"。
用户说一句:
我想吃辣一点的川菜,预算 50,顺便帮我看看哪家送得最快。
大模型 只是一个语言模型,它不知道怎么和外部交流,这时候Tool就出来了,Tool让大模型知道附近有哪些商家,菜单长什么样,配送系统怎么查。
这里可以先建立一个直观的类比:
- Function Tool 像是菜单上的菜品和服务项
- Function Calling 像是顾客下单时,平台把需求整理成一张结构化订单
- MCP 像是整个外卖平台的接入规则:商家怎么入驻、菜单怎么上架、订单怎么传、平台怎么和商家系统通信
所以,Function Calling 解决的是"这次怎么点单" ;而 MCP 解决的是"平台怎么把大量商家用统一方式接进来" 。Anthropic 对 MCP 的官方定义就是:它是一个开放标准,用来在数据源和 AI 工具之间建立安全的双向连接;其公开介绍里也明确采用了 MCP clients 和 MCP servers 的架构表达。 (Anthropic)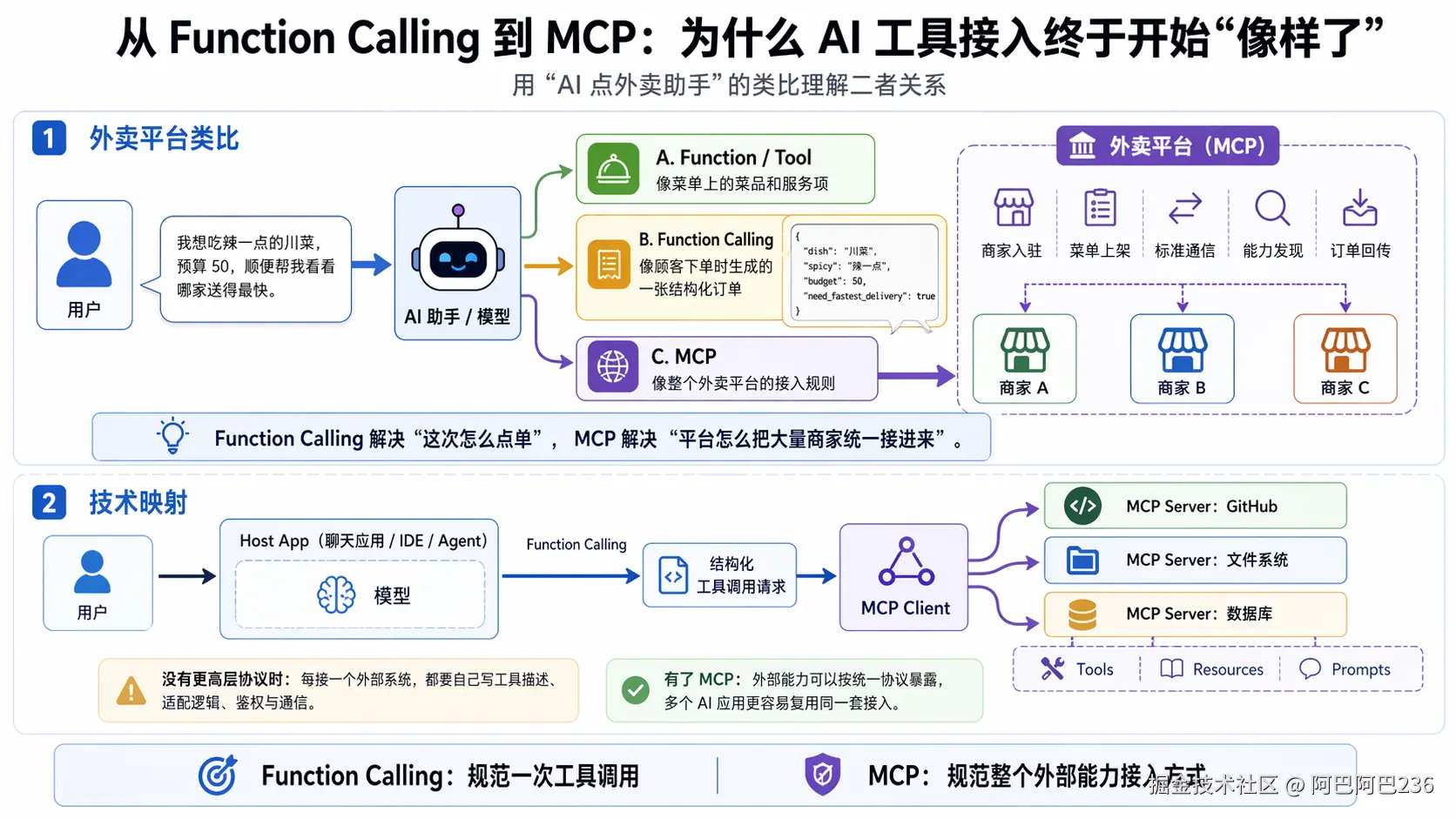
一、在没有 Function Calling 之前:大家都是"一个壶配一个盖"
在 function calling 出现之前,行业里最常见的做法其实很朴素,也很混乱:
- 把工具说明硬塞进 prompt
- 让模型"尽量"输出某种约定格式
- 在代码里用字符串、正则、JSON 解析去猜模型到底想调哪个接口
- 只要 prompt 一变、字段一变、模型输出多说两句,整个流程就可能崩掉
本质上就是:
每接一个工具,就手搓一套协议;每换一个场景,再手搓一套协议。
没有统一 schema,没有稳定的参数结构,也没有真正意义上的标准工具调用流程。OpenAI 后来对 function calling 的官方表述,恰恰说明了这一点:开发者可以先描述应用中的函数,模型再输出一个带参数的 JSON 对象来调用函数。换句话说,在此之前,开发者普遍都得自己解决"如何让模型稳定地产出可执行参数"这个问题。 (OpenAI)
例子 1:靠 prompt 约定调用天气接口
bash
# function calling 之前的常见写法:靠 prompt 约定格式
prompt = f"""
你是助手。
如果用户要查天气,请输出:
WEATHER(city=城市,date=日期)
否则正常回答。
用户:{user_input}
"""
reply = llm(prompt)
if reply.startswith("WEATHER("):
city = parse_between(reply, "city=", ",")
date = parse_between(reply, "date=", ")")
result = get_weather(city, date)
answer = llm(f"天气结果是:{result}。请整理成自然语言。")
else:
answer = reply这段代码的问题不是"不能跑",而是太脆:
- 模型可能输出
weather(...) - 可能多加一句解释
- 可能把字段顺序换掉
- 可能写成中文括号
- 可能漏参数,或者瞎补参数
只要模型输出稍微偏一点,后端就得补一堆 if/else 和容错逻辑。
例子 2:靠 JSON 约定,但 JSON 也是自己发明的
bash
prompt = f"""
你可以调用两个工具:
1. search_restaurant(query, budget)
2. estimate_delivery(store_id)
如果需要调用工具,请严格输出 JSON:
{{"tool": "...", "args": {{...}}}}
用户:{user_input}
"""
reply = llm(prompt)
obj = try_parse_json(reply)
if obj and obj["tool"] == "search_restaurant":
stores = search_restaurant(**obj["args"])
elif obj and obj["tool"] == "estimate_delivery":
eta = estimate_delivery(**obj["args"])
else:
# 解析失败,回退成普通回答
pass这比上一种写法好一点,但问题依旧明显:
这套 JSON 结构是你自己定的,不是一个通用的、模型原生围绕它优化的工具调用机制。
你这次写 tool + args,别人那次写 name + parameters,另一个团队又写 action + payload。看起来都像 JSON,但其实完全不是一回事。
所以在那个阶段,行业的真实状态可以概括成一个词语:群魔乱舞
二、Function Calling 出来后:先把"点单格式"统一起来
后面 OpenAI 推出了 function calling。它做的事情并不困难,但非常关键,它规定了Tool怎么定义:
- 开发者先把可用函数及参数 schema 声明给模型
- 模型根据用户请求,决定要不要调用函数
- 如果要调用,就输出一个结构化参数对象
- 由应用程序真正去执行函数
- 再把函数结果回传给模型,生成最终回答
OpenAI 官方对这一能力的描述是:开发者可以描述应用中的函数,模型会智能地输出一个包含参数的 JSON 对象来调用这些函数。这个能力在 2023 年 6 月 13 日 正式发布。 (OpenAI)
Function Calling 的典型伪代码
bash
tools = [
{
"name": "get_weather",
"description": "查询指定城市和日期的天气",
"parameters": {
"type": "object",
"properties": {
"city": {"type": "string"},
"date": {"type": "string"}
},
"required": ["city", "date"]
}
}
]
resp = llm.chat(
messages=[{"role": "user", "content": user_input}],
tools=tools
)
if resp.tool_call:
name = resp.tool_call.name
args = resp.tool_call.arguments
tool_result = call_tool(name, args)
final = llm.chat(
messages=[
{"role": "user", "content": user_input},
{"role": "tool", "name": name, "content": str(tool_result)}
]
)
else:
final = resp.content这一步真正解决了三个问题。
第一,它把**"调用哪个工具、参数长什么样"**这件事,从"靠 prompt 猜"变成了"靠 schema 约束"。
第二,它让工具调用进入了更稳定的运行时模式:模型负责决策,程序负责执行。
第三,它显著减少了开发者自己发明半吊子调用格式的成本。OpenAI 官方后来也把 function calling 直接描述为一种让模型连接到外部工具和训练数据之外信息的能力。 (OpenAI)
Function calling 出来之后,大家开始围绕"模型如何发起工具调用"形成相对统一的做法,然后再在这个基础上做各自的封装和扩展。
所以更准确地说,Function Calling 并不是发明了"模型调工具"这个想法,而是把这件事行业统一化了。 (OpenAI)
三、但 Function Calling 解决的,还只是"这次怎么点单"
讲到这里,大家可能会自然产生一个疑问:
既然 function calling 已经能让模型调工具了,为什么还需要更高一层的协议?
为什么没有那层协议的时候,大家还要"再写一套"?
答案是:
Function Calling 只标准化了"模型如何发起一次调用";但"外部系统如何被接进来、怎么描述、怎么通信、怎么复用",仍然要每个应用自己写。总而言之,与外部应用的连接问题没有解决
OpenAI 的 function calling 文档重点就是:你定义工具 schema,模型输出结构化参数,再由你的应用去执行实际调用。也就是说,它主要统一的是模型和你自己的应用之间 这一小段。 (OpenAI)
但模型输出完以后,后面的世界还是乱的。
1)工具清单还是你自己整理
假设你要接 GitHub 、Notion、数据库。
你可能要自己写:
bash
{"name":"search_prs","parameters":{...}}
{"name":"search_pages","parameters":{...}}
{"name":"run_sql","parameters":{...}}这些 schema 都能塞给模型,但仍然是你自己手工整理的。
Function calling 不会自动告诉你:
- GitHub 应该暴露哪些能力
- Notion 里哪些能力适合给模型
- 数据库要不要暴露读表、查 schema、跑查询
换句话说,"工具长什么样"这件事,还是每个接入方自己决定。 (OpenAI)
2)真正调用外部系统的适配层还是你自己写
就算模型已经返回:
bash
{"name":"search_prs","arguments":{"repo":"foo/bar","author":"alice"}}你后面仍然得自己处理:
- GitHub 的 REST / GraphQL 接口
- OAuth 或 token
- 分页
- 限流和重试
- 错误码
- 返回结果清洗
换成 Notion、Postgres、本地文件系统,这套适配逻辑又完全不同。
所以重复写的,不是"模型怎么开口",而是:
你的程序怎么和每一个外部系统打交道。
大家可能会想,那每个厂家都直接官方提供function calling以及对应的外部适配系统就行呀,比如搞个SDK,比如搞个包等等等,欸,问题就出现在这里,不同的厂家做了不同的适配系统,所以MCP就规定了不同的厂家怎么提供统一的接口。
3)同一个能力,在不同宿主应用里还会重复接很多次
这才是最痛的地方。
假设你已经给"桌面助手"写好了 GitHub 集成。
现在你要把同样的 GitHub 能力再接到另一个"IDE 助手"里。
在没有更高层 协议 时,常见情况通常是:
- 再写一套 GitHub 工具定义
- 再写一套连接代码
- 再写一套安装配置方式
- 再写一套鉴权和错误处理
因为前一套往往是"某个宿主应用内部的私有接法",不是一个别的 AI 客户端也能直接复用的统一接口。
Anthropic 后来在工程文章里把这个痛点说得很直接:把 agents 连接到工具和数据,传统上需要为每个配对 编写定制集成,这会造成碎片化和重复劳动。MCP 的价值之一,就是让开发者实现一次通用协议 ,再连接一个更大的集成生态。 (Anthropic)
用外卖类比,把这个点讲透
只有 function calling 时,更像平台只是规定了:
"顾客下单时,请把订单写成统一格式。"
比如:
bash
{"dish":"宫保鸡丁","spicy":"extra","budget":50}这很好,订单格式统一了。
但每一家商家,平台仍然要自己单独处理:
- 这家商家的菜单从哪读
- 这家商家的库存接口怎么调
- 这家商家的鉴权方式是什么
- 这家商家的配送状态怎么回传
- 这家商家的后台系统怎么对接
所以:
订单格式统一,不等于商家接入统一。
这就是为什么在没有更高一层协议时,大家还得"再写一套"。
四、MCP 出来后:开始统一"平台怎么接商家"
这时候,MCP 要解决的问题就变得很清楚了。
Anthropic 在 2024 年 11 月 公开发布 MCP,并把它定义为一个开放标准,用来让 AI 工具和数据源之间建立安全的双向连接 。它的官方介绍中明确写到:开发者可以暴露 MCP servers ,AI 应用则可以作为 MCP clients 去连接这些 servers 。 (Anthropic)
如果沿用前面的比喻,那么:
- Function Calling:像订单格式
- MCP:像外卖平台的接入协议
它不只关心"怎么下单",还关心:
- 商家怎么注册
- 菜单怎么上架
- 平台怎么发现商家能力
- 订单和状态怎么来回传递
- 平台和商家后台怎么按统一协议通信
所以,MCP 的价值不在于"替代 function calling",而在于:
把 AI 应用连接外部世界这件事,从单点集成,推进到标准化生态接入。
MCP 风格的伪代码
下面这段不是某个特定 SDK 的精确代码,而是为了表达 MCP 的思想:
bash
# Host 应用里有一个 MCP Client
client = MCPClient()
# 连接多个 MCP Server
client.connect("mcp://filesystem-server")
client.connect("mcp://github-server")
client.connect("mcp://delivery-server")
# 统一发现可用能力:tools / resources / prompts
capabilities = client.list_capabilities()
# 把发现到的能力提供给模型
resp = llm.chat(
messages=[{"role": "user", "content": user_input}],
available_tools=capabilities.tools,
available_resources=capabilities.resources
)
# 模型决定调用哪个能力
if resp.tool_call:
result = client.invoke_tool(
server=resp.tool_call.server,
name=resp.tool_call.name,
arguments=resp.tool_call.arguments
)
final = llm.chat(
messages=[
{"role": "user", "content": user_input},
{"role": "tool", "name": resp.tool_call.name, "content": result}
]
)你会发现,这里关心的已经不只是一个 get_weather() 这种单函数,而是:
- 这个能力来自哪个 server
- client 如何发现它
- 它以什么标准暴露出来
- 应用如何用统一方式访问不同系统
这就是为什么大家会说,MCP 处理的是 client/server 层面的接入问题 ;而 function calling 处理的是 运行时的一次工具调用问题 。Anthropic 官方对 MCP 的公开定义里,client/server 架构以及连接外部工具、数据源的能力,就是最核心的部分。 (Anthropic)
总的来说,就是function calling解决了怎么统一工具,MCP解决了不同厂家怎么统一的提供自家的工具的一种通信协议。