摘要 :本文解读 Google Research 提出的 Vision Transformer(ViT) (Dosovitskiy et al., 2021):在不改动 Transformer 编码器 主干的前提下,将图像切成固定大小的 Patch ,经线性嵌入与 可学习位置编码 组成序列,配合 类别 Token(class token) 做图像分类。文中说明 ViT 与 CNN 在 归纳偏置 上的差异、为何依赖 大规模预训练 、序列长度与 patch 尺寸 对算力的影响,并给出与张量形状、单层计算相对应的直觉与公式。可与本系列中 Transformer 3. Transformer的整体架构、Transformer 6. Encoder 模块总结 以及 Autoencoder 介绍、Transformer 2. Attention 注意力机制、Transformer 4. Embedding层与位置编码技术 对照阅读,作为后续 CLIP 等视觉塔 的前置知识。
关键词:Vision Transformer;ViT;图像块(Patch);线性嵌入;可学习位置编码;class token;Transformer Encoder;自注意力;归纳偏置;图像分类;大规模预训练
系列文章:
- Transformer 26. Gated DeltaNet 架构详解与 Qwen 3.5 的联系:把「精准改写」的 Delta Rule 和「一键清空」的 Gating 组合起来
- Transformer 25. Gemma 2 架构详解:交替局部/全局注意力、GQA、双层 RMSNorm 与 Logit Soft-Capping
- Transformer 24. Linear Transformer(Linear Attention)详解:用核技巧把 O(L^2) 注意力变成 O(L)
- Transformer 23. Qwen 3.5 架构介绍:混合线性/全注意力、MoE 与相对 Qwen 1 / 2 / 3 的演进
- Transformer 22. Gemma 1 架构详解:Decoder-only、GeGLU、RoPE 与每一步计算
- Transformer 21. 从 LLaMA 到 Qwen:Rotary Position Embedding(RoPE)与 YaRN 一文读懂
- Transformer 20. Qwen 3 架构介绍:模块详解与相对 Qwen 1 / Qwen 2 的演进
- Transformer 19. Qwen 2 架构介绍:相对 Qwen 1 / Qwen 1.5 的演进与 MoE 扩展
- Transformer 18. DeepSeek-R1 解析:用强化学习激励推理能力------架构、训练与「为什么看起来更聪明」
- Transformer 17. Qwen 1 / Qwen 1.5 架构介绍以及与 Transformer、LLaMA 的对比
- Transformer 16. DeepSeek-V3 架构解析:在 MLA + DeepSeekMoE 上的规模化与训练/系统创新
- Transformer 15: DeepSeek-V2 架构解析:MLA + DeepSeekMoE 与主流架构对比
- Transformer 14. DeepSeekMoE 架构解析:与 LLaMA 以及 Transformer 架构对比
- Transformer 13. DeepSeek LLM 架构解析:与 LLaMA 以及 Transformer 架构对比
- Transformer 12. LLaMA 架构介绍以及与 Transformer 架构对比
- Transformer 11. Encoder-Decoder Transformer 经典架构以及每一步骤的详细计算
- Transformer 10. Decoder Only Transformer 架构以及每一步骤的详细计算
- Transformer 9. Decoder-Encoder 层多头自注意力机制
- Transformer 8. Decoder: 掩码注意力机制以及数学推导
- Transformer 7. Decoder:架构选择、Teacher Forcing 与并行计算
- Transformer 6. Encoder 模块总结 以及 Autoencoder 介绍
- Transformer 5. Transformer中的残差连接、归一化与前馈神经网络
- Transformer 4. Embedding层与位置编码技术
- Transformer 3. Transformer的整体架构
- Transformer 2. Attention 注意力机制
- Transformer 1. 讲在 Transformer 之前:序列模型的基本思路与根本诉求
1. 为什么需要 ViT:把「图像」翻译成 Transformer 能读的序列
在 NLP 里,我们已经习惯把一句话看成 token 序列 ,再交给 Transformer Encoder 做全局交互(见 Transformer 6. Encoder 模块总结 以及 Autoencoder 介绍)。计算机视觉里长期占主导的是 卷积神经网络(CNN) :局部卷积、层次化感受野、平移等变性等 归纳偏置(inductive bias) 很强,样本效率往往更好。
ViT 的核心想法 :尽量 少改 NLP 里那套标准 Transformer,把图像改成 一串向量 ,剩下的交给 多头自注意力。
💡 理解要点 :可以把它想象成「把一张照片剪成许多小方块,每个方块写成一段话的第一个词 」。模型不再先靠卷积在局部滑窗里攒特征,而是让 任意两个方块 在注意力里直接「对话」------全局关系来得非常直接。
🔍 实际例子 :若输入是 224×224 的 RGB图,patch 大小 16×16 ,则每边有 224 / 16 = 14 224/16=14 224/16=14 个 patch,共 14 × 14 = 196 14\times14=196 14×14=196 个 patch。再加上论文中的 1 个 class token ,送入 Encoder 的序列长度为 197 197 197 (196 196 196 个 patch + 1 1 1 个 class token;实现细节因是否使用 CLS 等略有差异)。
2. ViT 在做什么:从像素到 Encoder 输入
2.1 Patch 切分与展平
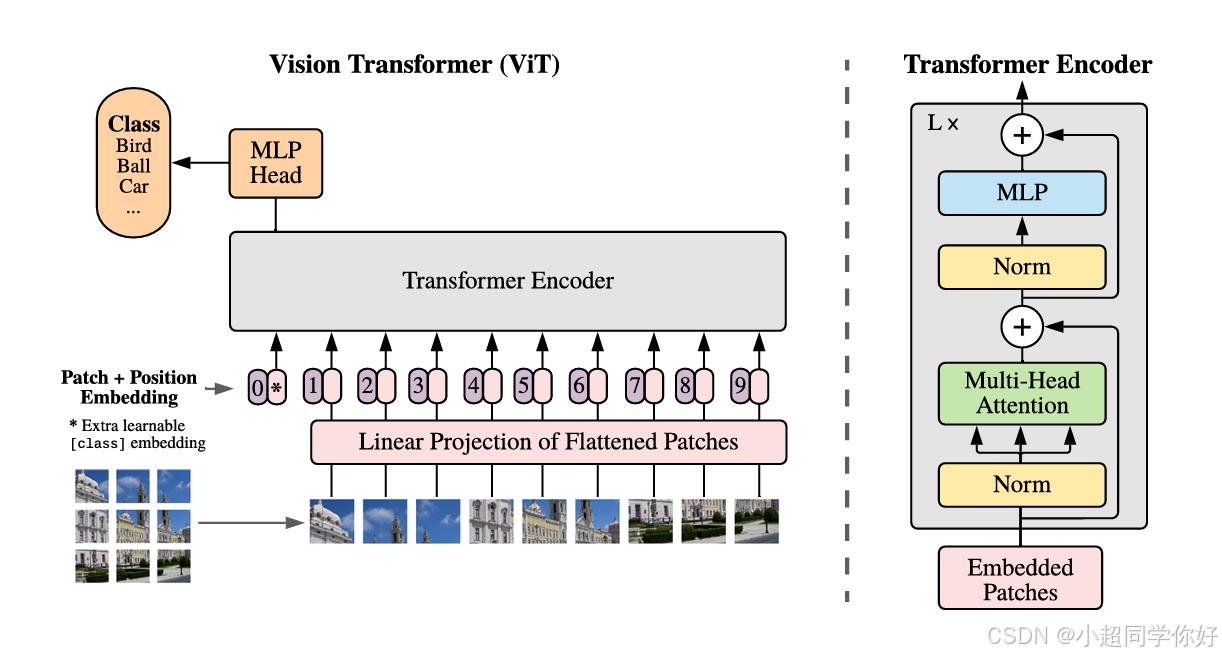
设输入图像为 H × W × C H\times W\times C H×W×C (如 224 × 224 × 3 224\times224\times3 224×224×3)。选定 patch 边长 P P P (常用 16 ),得到网格大小 H / P H/P H/P 与 W / P W/P W/P,patch 个数:
N = H P ⋅ W P . N = \frac{H}{P}\cdot\frac{W}{P}. N=PH⋅PW.
每个 patch 是 P × P × C P\times P\times C P×P×C 的张量,按固定顺序 (通常从左到右、从上到下)展平成 长度为 P 2 C P^2C P2C 的向量。
💡 理解要点 :顺序 本身不携带「左边/上边」的几何信息------几何要靠后面的 位置编码 补回来。这与 NLP 里「词序 + 位置编码」是同一套路。
2.2 Patch Embedding 嵌入(线性投影)
论文将每个展平后的 patch 向量乘以一个 可学习的线性层 E ∈ R ( P 2 C ) × D E\in\mathbb{R}^{(P^2C)\times D} E∈R(P2C)×D,映射到与 Transformer 一致的隐维度 D D D 。对所有 patch 得到 N N N 个 D D D 维向量。
矩阵视角 :若将 N N N 个 patch 的原始展平向量堆成 X p ∈ R N × ( P 2 C ) X_p \in \mathbb{R}^{N\times(P^2C)} Xp∈RN×(P2C),则 patch 嵌入为:
X patch = X p E ⇒ X patch ∈ R N × D . X_{\text{patch}} = X_p E \quad\Rightarrow\quad X_{\text{patch}}\in\mathbb{R}^{N\times D}. Xpatch=XpE⇒Xpatch∈RN×D.
这与 Transformer 4. Embedding层与位置编码技术 中「离散 ID 查表」不同,这里是 对连续像素块做线性投影 ,但角色等价:每个 patch 变成一个 token 向量。
2.3 Class token 与 Positional Enbedding 位置编码
- Class token :在序列最前面拼接一个 可学习的「类别向量」 x class ∈ R D x_{\text{class}}\in\mathbb{R}^{D} xclass∈RD(与 BERT 的
[CLS]类比)。最终分类头只取 该 token 经 Encoder 后的表示。 - 位置编码 :对每个位置(含 class token 对应位置)加上 可学习的 1D 位置嵌入 E pos ∈ R ( N + 1 ) × D E_{\text{pos}}\in\mathbb{R}^{(N+1)\times D} Epos∈R(N+1)×D(论文实现为一套可学习向量;长度与 N + 1 N+1 N+1 对齐)。
初始输入(论文记号)可概括为:
z 0 = x class ; x p 1 E ; ... ; x p N E + E pos , \mathbf{z}0 = \bigx_{\\text{class}};\\; x_p\^1 E;\\; \\ldots;\\; x_p\^N E\\big + E{\text{pos}}, z0=xclass;xp1E;...;xpNE+Epos,
其中分号表示在序列维上拼接, z 0 ∈ R ( N + 1 ) × D \mathbf{z}_0 \in \mathbb{R}^{(N+1)\times D} z0∈R(N+1)×D。
🔍 实际例子 :ViT-B/16 常取 D = 768 D=768 D=768。若 N = 196 N=196 N=196,则进入第一层 Encoder 的张量形状为 ( 1 + N ) × D = 197 × 768 (1+N)\times D = 197\times768 (1+N)×D=197×768。
2.4 与 CNN 特征图作为序列(混合模型)
论文还讨论 Hybrid 结构:先用 CNN 得到 粗特征图 ,再把特征图上的每个「空间位置」展平/投影为 token。直觉是:CNN 提供局部与平移先验 ,Transformer 负责 长程混合 。这与「纯 ViT」形成对照实验,便于理解 归纳偏置从哪来。
3. Encoder 内部:与标准 Transformer 的对应关系
ViT 的主体是 L L L 层 Transformer Encoder (与 Transformer 6. Encoder 模块总结 以及 Autoencoder 介绍 中编码器块同族)。论文采用 Pre-Layer Normalization (Pre-LN):先 LN,再子层,再残差。这与原始 Transformer 论文的 Post-LN 不同,训练更稳定。
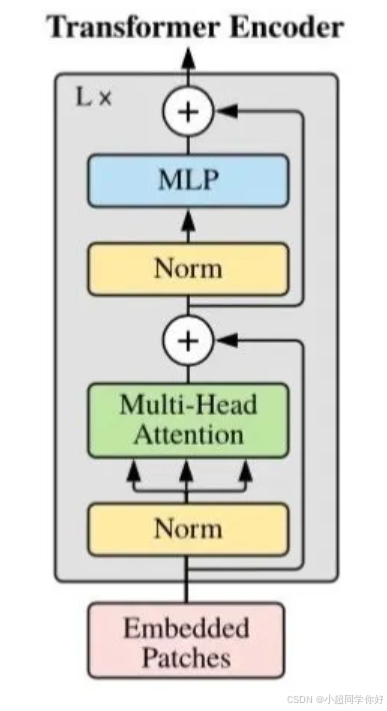
3.1 单层 Encoder 的递推公式
用论文中的递推形式(略去多头拆分细节),第 ℓ \ell ℓ 层的计算为:
z ℓ ′ = M S A ( L N ( z ℓ − 1 ) ) + z ℓ − 1 , z ℓ = M L P ( L N ( z ℓ ′ ) ) + z ℓ ′ . \begin{aligned} \mathbf{z}'\ell &= \mathrm{MSA}\big(\mathrm{LN}(\mathbf{z}{\ell-1})\big) + \mathbf{z}{\ell-1}, \\ \mathbf{z}\ell &= \mathrm{MLP}\big(\mathrm{LN}(\mathbf{z}'\ell)\big) + \mathbf{z}'\ell. \end{aligned} zℓ′zℓ=MSA(LN(zℓ−1))+zℓ−1,=MLP(LN(zℓ′))+zℓ′.
其中:
- MSA: Multihead Self-Attention 多头自注意力机制
- z ℓ − 1 ∈ R ( N + 1 ) × D \mathbf{z}_{\ell-1} \in \mathbb{R}^{(N+1) \times D} zℓ−1∈R(N+1)×D:第 ℓ − 1 \ell-1 ℓ−1 层的输出,序列长度 N + 1 N+1 N+1( N N N 个 patch + 1 个 class token),特征维度 D D D
- L N \mathrm{LN} LN:Layer Normalization,对每个 token 的特征做归一化,保持形状不变
- z ℓ ′ \mathbf{z}'_\ell zℓ′:MSA 子层后的中间输出
- z ℓ \mathbf{z}_\ell zℓ:MLP 子层后的最终输出
3.2 矩阵形状变化全景图
以 ViT-B/16 为例( N = 196 N=196 N=196, D = 768 D=768 D=768),单层的张量流动如下:
输入: z_{ℓ-1} → shape: (197, 768)
↓
LayerNorm → shape: (197, 768) [对每个token的768维做归一化]
↓
MSA (多头自注意力) → shape: (197, 768)
↓
残差连接 (+z_{ℓ-1}) → z'_ℓ shape: (197, 768)
↓
LayerNorm → shape: (197, 768)
↓
MLP (前馈网络) → shape: (197, 768)
↓
残差连接 (+z'_ℓ) → z_ℓ shape: (197, 768)💡 理解要点 :整个 Encoder 中序列长度始终保持 N + 1 N+1 N+1 不变,只有特征维度在 MLP 内部先扩后缩。
3.3 多头自注意力(MSA)的详细计算
MSA 将输入映射为查询(Query)、键(Key)、值(Value),通过注意力权重聚合信息。
3.3.1 单头注意力的矩阵形式
设单头的维度为 d k = D / h d_k = D / h dk=D/h,其中 h h h 是头数(ViT-B 中 h = 12 h=12 h=12, d k = 64 d_k=64 dk=64)。
对于输入 X ∈ R ( N + 1 ) × D \mathbf{X} \in \mathbb{R}^{(N+1) \times D} X∈R(N+1)×D:
Q = X W Q , W Q ∈ R D × d k K = X W K , W K ∈ R D × d k V = X W V , W V ∈ R D × d k \begin{aligned} \mathbf{Q} &= \mathbf{X} \mathbf{W}^Q, \quad \mathbf{W}^Q \in \mathbb{R}^{D \times d_k} \\ \mathbf{K} &= \mathbf{X} \mathbf{W}^K, \quad \mathbf{W}^K \in \mathbb{R}^{D \times d_k} \\ \mathbf{V} &= \mathbf{X} \mathbf{W}^V, \quad \mathbf{W}^V \in \mathbb{R}^{D \times d_k} \end{aligned} QKV=XWQ,WQ∈RD×dk=XWK,WK∈RD×dk=XWV,WV∈RD×dk
得到的矩阵形状:
- Q , K , V ∈ R ( N + 1 ) × d k \mathbf{Q}, \mathbf{K}, \mathbf{V} \in \mathbb{R}^{(N+1) \times d_k} Q,K,V∈R(N+1)×dk
注意力分数计算:
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V \mathrm{Attention}(\mathbf{Q}, \mathbf{K}, \mathbf{V}) = \mathrm{softmax}\left(\frac{\mathbf{Q}\mathbf{K}^T}{\sqrt{d_k}}\right)\mathbf{V} Attention(Q,K,V)=softmax(dk QKT)V
其中:
- Q K T ∈ R ( N + 1 ) × ( N + 1 ) \mathbf{Q}\mathbf{K}^T \in \mathbb{R}^{(N+1) \times (N+1)} QKT∈R(N+1)×(N+1):这就是注意力矩阵 , ( i , j ) (i,j) (i,j) 位置表示第 i i i 个 token 对第 j j j 个 token 的关注程度
- 除以 d k \sqrt{d_k} dk 是为了防止点积过大导致 softmax 梯度消失
- softmax 按行归一化,每行和为 1
- 最终输出形状: R ( N + 1 ) × d k \mathbb{R}^{(N+1) \times d_k} R(N+1)×dk
3.3.2 多头拼接与输出投影
h h h 个头的输出在特征维上拼接,再做一个线性投影:
M S A ( X ) = C o n c a t h e a d 1 , ... , h e a d h W O h e a d i = A t t e n t i o n ( X W i Q , X W i K , X W i V ) \begin{aligned} \mathrm{MSA}(\mathbf{X}) &= \mathrm{Concat}\\mathrm{head}_1, \\ldots, \\mathrm{head}_h \mathbf{W}^O \\ \mathrm{head}_i &= \mathrm{Attention}(\mathbf{X}\mathbf{W}^Q_i, \mathbf{X}\mathbf{W}^K_i, \mathbf{X}\mathbf{W}^V_i) \end{aligned} MSA(X)headi=Concathead1,...,headhWO=Attention(XWiQ,XWiK,XWiV)
其中 W O ∈ R D × D \mathbf{W}^O \in \mathbb{R}^{D \times D} WO∈RD×D 是输出投影矩阵。
形状变化:
- 每个 head 输出: ( N + 1 ) × d k (N+1) \times d_k (N+1)×dk
- 拼接后: ( N + 1 ) × ( h ⋅ d k ) = ( N + 1 ) × D (N+1) \times (h \cdot d_k) = (N+1) \times D (N+1)×(h⋅dk)=(N+1)×D
- 投影后: ( N + 1 ) × D (N+1) \times D (N+1)×D(保持与输入相同)
3.3.3 MSA 的参数量
每个头有 3 个投影矩阵(Q, K, V),加上输出投影:
MSA 参数量 = 4 ⋅ h ⋅ D ⋅ d k = 4 ⋅ D 2 \text{MSA 参数量} = 4 \cdot h \cdot D \cdot d_k = 4 \cdot D^2 MSA 参数量=4⋅h⋅D⋅dk=4⋅D2
对于 ViT-B( D = 768 D=768 D=768):
- MSA 参数量 ≈ 4 × 768 2 = 2 , 359 , 296 ≈ 2.36 M \approx 4 \times 768^2 = 2,359,296 \approx 2.36\text{M} ≈4×7682=2,359,296≈2.36M
3.4 MLP 层的详细结构
MLP 对每个 token 独立 施加两层全连接网络,采用 GELU 激活。
3.4.1 计算公式
M L P ( X ) = σ ( X W 1 + b 1 ) W 2 + b 2 \mathrm{MLP}(\mathbf{X}) = \sigma(\mathbf{X}\mathbf{W}_1 + \mathbf{b}_1)\mathbf{W}_2 + \mathbf{b}_2 MLP(X)=σ(XW1+b1)W2+b2
其中:
- σ \sigma σ:GELU 激活函数, G E L U ( x ) = x ⋅ Φ ( x ) \mathrm{GELU}(x) = x \cdot \Phi(x) GELU(x)=x⋅Φ(x), Φ \Phi Φ 是标准正态分布的 CDF
- W 1 ∈ R D × 4 D \mathbf{W}_1 \in \mathbb{R}^{D \times 4D} W1∈RD×4D:第一个线性层,将维度扩展 4 倍
- W 2 ∈ R 4 D × D \mathbf{W}_2 \in \mathbb{R}^{4D \times D} W2∈R4D×D:第二个线性层,将维度压缩回原大小
- b 1 ∈ R 4 D \mathbf{b}_1 \in \mathbb{R}^{4D} b1∈R4D, b 2 ∈ R D \mathbf{b}_2 \in \mathbb{R}^{D} b2∈RD:偏置项
3.4.2 矩阵形状变化
输入 X → shape: (197, 768)
↓
X @ W1 + b1 → shape: (197, 3072) [扩展4倍]
↓
GELU 激活 → shape: (197, 3072)
↓
@ W2 + b2 → shape: (197, 768) [压缩回原大小]3.4.3 MLP 的参数量
MLP 参数量 = D ⋅ 4 D + 4 D + 4 D ⋅ D + D = 8 D 2 + 5 D ≈ 8 D 2 \text{MLP 参数量} = D \cdot 4D + 4D + 4D \cdot D + D = 8D^2 + 5D \approx 8D^2 MLP 参数量=D⋅4D+4D+4D⋅D+D=8D2+5D≈8D2
对于 ViT-B( D = 768 D=768 D=768):
- MLP 参数量 ≈ 8 × 768 2 = 4 , 718 , 592 ≈ 4.72 M \approx 8 \times 768^2 = 4,718,592 \approx 4.72\text{M} ≈8×7682=4,718,592≈4.72M
3.5 Layer Normalization 与残差连接
3.5.1 Pre-LN 的结构
ViT 采用 Pre-LN:在子层之前做归一化,区别于原始 Transformer 的 Post-LN。
L N ( x ) = γ ⊙ x − μ σ 2 + ϵ + β \mathrm{LN}(\mathbf{x}) = \gamma \odot \frac{\mathbf{x} - \mu}{\sqrt{\sigma^2 + \epsilon}} + \beta LN(x)=γ⊙σ2+ϵ x−μ+β
其中:
- μ , σ 2 \mu, \sigma^2 μ,σ2:对输入特征的均值和方差(沿特征维度计算)
- γ , β ∈ R D \gamma, \beta \in \mathbb{R}^D γ,β∈RD:可学习的缩放和平移参数
- ϵ \epsilon ϵ:数值稳定的小常数
- ⊙ \odot ⊙:逐元素乘法
形状 :输入 ( N + 1 ) × D (N+1) \times D (N+1)×D,LN 对每个 token 的 D D D 维特征做归一化,输出形状不变。
3.5.2 残差连接的作用
残差连接(Skip Connection)让梯度可以直接回传:
z ℓ ′ = M S A ( L N ( z ℓ − 1 ) ) ⏟ 子层变换 + z ℓ − 1 ⏟ 恒等映射 \mathbf{z}'\ell = \underbrace{\mathrm{MSA}(\mathrm{LN}(\mathbf{z}{\ell-1}))}{\text{子层变换}} + \underbrace{\mathbf{z}{\ell-1}}_{\text{恒等映射}} zℓ′=子层变换 MSA(LN(zℓ−1))+恒等映射 zℓ−1
这保证了即使子层参数初始化不当,网络也能保持identity mapping,训练更稳定。
3.6 复杂度分析
3.6.1 计算复杂度
| 操作 | 计算复杂度 | 说明 |
|---|---|---|
| MSA(QKV投影) | O ( 3 ( N + 1 ) ⋅ D 2 ) O(3(N+1) \cdot D^2) O(3(N+1)⋅D2) | 三个矩阵乘法 |
| MSA(注意力) | O ( ( N + 1 ) 2 ⋅ D ) O((N+1)^2 \cdot D) O((N+1)2⋅D) | 核心是 ( N + 1 ) × ( N + 1 ) (N+1)\times(N+1) (N+1)×(N+1) 注意力矩阵计算 |
| MSA(输出投影) | O ( ( N + 1 ) ⋅ D 2 ) O((N+1) \cdot D^2) O((N+1)⋅D2) | 单个矩阵乘法 |
| MLP | O ( 8 ( N + 1 ) ⋅ D 2 ) O(8(N+1) \cdot D^2) O(8(N+1)⋅D2) | 两个线性层,维度 D → 4 D → D D \to 4D \to D D→4D→D |
单层总复杂度:
O ( ( N + 1 ) 2 ⋅ D + ( N + 1 ) ⋅ D 2 ) O\big((N+1)^2 \cdot D + (N+1) \cdot D^2\big) O((N+1)2⋅D+(N+1)⋅D2)
其中二次项 ( N + 1 ) 2 ⋅ D (N+1)^2 \cdot D (N+1)2⋅D 来自注意力矩阵,是 ViT 的主要瓶颈。
3.6.2 内存复杂度
需要存储的中间结果:
- 注意力矩阵: O ( ( N + 1 ) 2 ) O((N+1)^2) O((N+1)2),对于 N = 196 N=196 N=196 约为 197 2 ≈ 39 K 197^2 \approx 39K 1972≈39K 个元素
- 每层激活: O ( ( N + 1 ) ⋅ D ) O((N+1) \cdot D) O((N+1)⋅D)
3.6.3 实际对比(ViT-B/16 vs ViT-L/16)
| 配置 | N N N | D D D | 注意力矩阵大小 | MSA参数量 | MLP参数量 |
|---|---|---|---|---|---|
| ViT-B | 197 | 768 | 197 2 ≈ 39 K 197^2 \approx 39K 1972≈39K | ~2.36M | ~4.72M |
| ViT-L | 197 | 1024 | 197 2 ≈ 39 K 197^2 \approx 39K 1972≈39K | ~4.19M | ~8.39M |
💡 理解要点 :增加层数 L L L 线性增加总参数量,但注意力的二次复杂度 O ( N 2 ) O(N^2) O(N2) 使得增大图像分辨率(减小 patch 尺寸)的代价远高于增加隐藏维度 D D D。
💡 矩阵形状演变速查表(Best practice 代入) :以 ViT-B/16 的常用输入设置为例:输入图像 224×224×3 ,patch 尺寸 P=16 ,因此 (H/P=W/P=14),patch 数 (N=14\times14=196)。隐藏维度 D=768 ,多头数 h=12,每头维度 (d_{\text{head}}=D/h=64)。下面的"形状"默认忽略 batch 维(即省略 (B))。
| 步骤 | 张量/矩阵 | 形状(带入数值) | 一般形式 | 备注(可对照 3.7 参数量) |
|---|---|---|---|---|
| 输入 | 图像 x \mathbf{x} x | 224 × 224 × 3 224\times224\times3 224×224×3 | H × W × C H\times W\times C H×W×C | H = W = 224 , C = 3 H=W=224,\,C=3 H=W=224,C=3 |
| 切 patch | patch 网格 | 14 × 14 14\times14 14×14 | ( H / P ) × ( W / P ) (H/P)\times(W/P) (H/P)×(W/P) | P = 16 ⇒ 224 / 16 = 14 P=16\Rightarrow 224/16=14 P=16⇒224/16=14 |
| 展平 patch | patch 向量序列(未投影) | 196 × 768 196\times768 196×768 | N × ( P 2 C ) N\times(P^2C) N×(P2C) | P 2 C = 16 2 ⋅ 3 = 768 P^2C=16^2\cdot3=768 P2C=162⋅3=768 |
| 线性投影 | patch embedding X \mathbf{X} X | 196 × 768 196\times768 196×768 | N × D N\times D N×D | 这一步对应 3.7 的 P 2 ⋅ C ⋅ D P^2\cdot C\cdot D P2⋅C⋅D 参数 |
| 加 cls | x c l s ; X \\mathbf{x}_{cls};\\mathbf{X} xcls;X | 197 × 768 197\times768 197×768 | ( N + 1 ) × D (N+1)\times D (N+1)×D | cls token 形状 1 × D 1\times D 1×D,参数量为 D D D |
| 加位置编码 | Z 0 \mathbf{Z}_0 Z0 | 197 × 768 197\times768 197×768 | ( N + 1 ) × D (N+1)\times D (N+1)×D | pos embed 参数量为 ( N + 1 ) ⋅ D (N+1)\cdot D (N+1)⋅D |
| (单层)LN | L N ( Z ) \mathrm{LN}(\mathbf{Z}) LN(Z) | 197 × 768 197\times768 197×768 | ( N + 1 ) × D (N+1)\times D (N+1)×D | LN 不改形状;参数量每个 LN 为 2 D 2D 2D |
| (单层)Q/K/V | Q , K , V \mathbf{Q},\mathbf{K},\mathbf{V} Q,K,V | 197 × 768 197\times768 197×768 | ( N + 1 ) × D (N+1)\times D (N+1)×D | 由三组线性层产生,合计与 3.7 的 4 D 2 4D^2 4D2 对应(含输出投影) |
| (单层)分头 reshape | Q h , K h , V h \mathbf{Q}_h,\mathbf{K}_h,\mathbf{V}_h Qh,Kh,Vh | 12 × 197 × 64 12\times197\times64 12×197×64 | h × ( N + 1 ) × d head h\times(N+1)\times d_{\text{head}} h×(N+1)×dhead | 12 ⋅ 64 = 768 12\cdot64=768 12⋅64=768 |
| (单层)注意力分数 | A h = Q h K h ⊤ \mathbf{A}_h=\mathbf{Q}_h\mathbf{K}_h^\top Ah=QhKh⊤ | 12 × 197 × 197 12\times197\times197 12×197×197 | h × ( N + 1 ) × ( N + 1 ) h\times(N+1)\times(N+1) h×(N+1)×(N+1) | 二次项来自这里( N 2 N^2 N2) |
| (单层)注意力输出 | O h = s o f t m a x ( A h ) V h \mathbf{O}_h=\mathrm{softmax}(\mathbf{A}_h)\mathbf{V}_h Oh=softmax(Ah)Vh | 12 × 197 × 64 12\times197\times64 12×197×64 | h × ( N + 1 ) × d head h\times(N+1)\times d_{\text{head}} h×(N+1)×dhead | 与 V h \mathbf{V}_h Vh 同形状 |
| (单层)拼回 | c o n c a t h ( O h ) \mathrm{concat}_h(\mathbf{O}_h) concath(Oh) | 197 × 768 197\times768 197×768 | ( N + 1 ) × D (N+1)\times D (N+1)×D | 重新拼接各头 |
| (单层)输出投影 | Z ′ \mathbf{Z}' Z′ | 197 × 768 197\times768 197×768 | ( N + 1 ) × D (N+1)\times D (N+1)×D | MSA 输出投影(对应 3.7 的 4 个投影矩阵之一) |
| (单层)MLP 中间层 | H \mathbf{H} H | 197 × 3072 197\times3072 197×3072 | ( N + 1 ) × 4 D (N+1)\times 4D (N+1)×4D | ViT-B 的 MLP 隐层维度通常取 4 D 4D 4D |
| (单层)MLP 输出层 | Z ′ ′ \mathbf{Z}'' Z′′ | 197 × 768 197\times768 197×768 | ( N + 1 ) × D (N+1)\times D (N+1)×D | 对应 3.7 里的两层 FC(约 8 D 2 8D^2 8D2) |
| L 层堆叠 | Z L \mathbf{Z}_L ZL | 197 × 768 197\times768 197×768 | ( N + 1 ) × D (N+1)\times D (N+1)×D | 形状不变,但参数量随层数 L L L 线性增长 |
3.7 完整 Encoder 的参数量估算
以 ViT-B/16 为例( L = 12 L=12 L=12, N = 196 N=196 N=196, D = 768 D=768 D=768):
| 组件 | 参数量 | 计算方式 |
|---|---|---|
| Patch Embedding | P 2 ⋅ C ⋅ D = 16 2 ⋅ 3 ⋅ 768 = 589 , 824 P^2 \cdot C \cdot D = 16^2 \cdot 3 \cdot 768 = 589,824 P2⋅C⋅D=162⋅3⋅768=589,824 | 投影矩阵 |
| Position Embedding | ( N + 1 ) ⋅ D = 197 ⋅ 768 = 151 , 296 (N+1) \cdot D = 197 \cdot 768 = 151,296 (N+1)⋅D=197⋅768=151,296 | 可学习向量 |
| Class Token | D = 768 D = 768 D=768 | 可学习向量 |
| 每层 MSA | 4 D 2 = 2 , 359 , 296 4D^2 = 2,359,296 4D2=2,359,296 | 4个投影矩阵 |
| 每层 MLP | ≈ 8 D 2 = 4 , 718 , 592 \approx 8D^2 = 4,718,592 ≈8D2=4,718,592 | 两个FC层 |
| 每层 LN | 2 ⋅ 2 D = 3 , 072 2 \cdot 2D = 3,072 2⋅2D=3,072 | 两个LN,每层2参数 |
| 单层合计 | ~7.08M | |
| 12层 Encoder | ~85M | 不含分类头 |
| 分类头 | D ⋅ num_classes = 768 ⋅ 1000 = 768 , 000 D \cdot \text{num\_classes} = 768 \cdot 1000 = 768,000 D⋅num_classes=768⋅1000=768,000 | ImageNet-1k |
总计 :约 86M 参数,与论文 Table 1 中的 86.6M 吻合。
3.8 分类头的处理
最后一层 Encoder 输出 z L ∈ R ( N + 1 ) × D \mathbf{z}_L \in \mathbb{R}^{(N+1) \times D} zL∈R(N+1)×D,取其中 class token(索引 0 位置):
y = L N ( z L 0 ) ∈ R D \mathbf{y} = \mathrm{LN}(\mathbf{z}_L0) \in \mathbb{R}^D y=LN(zL0)∈RD
然后接分类头:
logits = y W cls + b cls , W cls ∈ R D × K \text{logits} = \mathbf{y} \mathbf{W}{\text{cls}} + \mathbf{b}{\text{cls}}, \quad \mathbf{W}_{\text{cls}} \in \mathbb{R}^{D \times K} logits=yWcls+bcls,Wcls∈RD×K
其中 K K K 是类别数(如 ImageNet-1k 的 1000 类)。
💡 理解要点 :ViT 不是 Decoder ,没有因果掩码;它做的是 全局可见 的自注意力,和 BERT 式 Encoder 更像。你在多模态里看到的 ViT 视觉塔 ,往往就是「到某一层 Encoder 输出为止 」的特征抽取器,比如取 z L \mathbf{z}_L zL 或中间某层的输出作为图像表征。
4. 模型规模与命名:ViT-B / L / H 与 /16 的含义
论文沿用类似 BERT 的命名:Base / Large / Huge ,并在名字里标明 patch 尺寸:
- ViT-L/16 :Large 配置,16 × 16 16\times16 16×16 patch。
- ViT-L/32 :同一「宽度/深度」量级下,patch 更大 → patch 数更少 → 序列更短,单步注意力更省,但空间分辨率更粗。
🔍 实际例子 :同样 224×224 输入,/16 有 196 个 patch;/32 只有 7 × 7 = 49 7\times7=49 7×7=49 个 patch。序列长度几乎 平方级变化,算力与显存压力差很多。
更细的层数、头数、维度等请以论文 Table 1 为准(阅读原始表格有助于和后文 CLIP 选用的 ViT 变体对齐)。
5. 与 CNN 的关键差异:归纳偏置与数据规模
5.1 归纳偏置
CNN 通过 局部连接、权值共享、池化 等引入 局部性 与 平移等变性 ;ViT 的 自注意力 是 全局 的,没有卷积那种硬编码的局部先验。结果是:
- 优点 :长程依赖路径短,结构简单,堆规模时潜力大。
- 代价 :在小数据、从头训练时,可能不如强归纳偏置的 CNN 省数据。
论文实验表明:在中等规模数据上,ResNet 类模型 仍可能更强;而在 大规模预训练 后,ViT 的 迁移 表现可以非常突出------这与「用数据换先验」的直觉一致。
5.2 自注意力的二次复杂度
序列长度 N N N (patch 数)增大时,注意力代价按 O ( N 2 ) O(N^2) O(N2) 增长。高分辨率图像若仍用较小 patch,N N N 会迅速膨胀,这是 ViT 系结构在分割、检测等任务里常配合 金字塔 、窗口注意力 或 CNN 混合 stem 的原因之一(属于后话,本文不展开)。
💡 理解要点 :读 ViT 时心里要同时记住两件事:(1)它让图像变成标准 Encoder 输入;(2)全局注意力的代价随 patch 数平方增长 。二者共同决定了它为何常作为 大模型里的视觉前端 出现,而不是所有场景的唯一最优解。
6. 训练与推理:你在论文里应抓的主线
为保持与原文一致,这里只列 读论文时建议对照的实验主线(细节以 PDF 为准):
- 监督训练 :在 ImageNet 等数据集上做分类,观察 不同规模、不同 patch、是否混合 CNN 的结果。
- 大规模预训练 + 微调 :先在更大数据上预训练,再迁移到 ImageNet 等基准------对应上文「规模」叙事。
- 表示的可视化 :例如位置嵌入的相似度、注意力图等,帮助建立 几何直觉(Medium 一文中的插图思路与此相近)。
7. 在多模态路线中的位置(衔接说明)
按仓库中的 多模态经典论文路线(若路径变动请以当前计划文件为准),ViT 是「视觉侧的 Transformer 接口」 :后续 CLIP 等模型往往以 ViT 作为图像编码器(image tower) ,在 patch 序列上做自注意力,再与文本塔做 对比学习。读完本文,建议你带着下面三个问题进入下一篇:
- Patch 嵌入 + 位置编码 与 文本 token 嵌入 + 位置编码 在形式上如何「对齐」?
- class token 的表示 在对比学习里通常如何取用(全局池化还是专用 token)?
- 序列长度 / 下采样 如何在 精度与算力 之间折中?
8. 小结
- ViT 将 H × W H\times W H×W 图像切成 P × P P\times P P×P patch,展平后 线性嵌入 为 D D D 维,加上 可学习位置编码 与 class token ,形成 标准 Transformer Encoder 的输入序列。
- Encoder 内为 多头自注意力 + MLP ,采用 Pre-LN与残差 ;分类只读 class token 经 LN 后的向量。
- 相对 CNN,ViT 弱化局部归纳偏置 ,更依赖 数据规模与训练配方 ;注意力 O ( N 2 ) O(N^2) O(N2) 使 patch 尺寸与分辨率 成为工程关键。
- 作为多模态前置,ViT 提供了 与 NLP Transformer 「同一套积木」 的视觉表征,是理解 CLIP /视觉-语言模型 的自然第一站。
推荐阅读顺序(本系列) :Transformer 3. Transformer的整体架构 → Transformer 6. Encoder 模块总结 以及 Autoencoder 介绍 → Transformer 2. Attention 注意力机制 → 本文(ViT) →(后续)CLIP 与视觉-语言对齐。
参考与引用: