一、镜像和虚拟环境有什么不一样?
- Python 虚拟环境(venv / conda)
它主要解决的是:
同一台机器上,不同 Python 项目的包版本冲突
比如:
-
项目A要
torch==2.1 -
项目B要
torch==1.13
你就可以给它们分别建不同虚拟环境。
虚拟环境通常只包含:
-
Python解释器
-
pip安装的包
-
一些环境配置
但它依赖宿主机很多东西:
-
宿主机操作系统
-
宿主机系统库
-
宿主机 CUDA / 驱动
-
宿主机 shell、路径、权限等
所以虚拟环境只是:
Python层面的隔离
它不是完整环境打包。
- Docker 镜像,8个
Docker 镜像更大,它不是只管 Python 包,而是可以把这些一起打包:
-
操作系统基础层(如 Ubuntu)
-
Python
-
PyTorch
-
CUDA runtime / toolkit
-
你的
.py代码 -
配置文件
-
启动命令
-
甚至模型权重
所以镜像是:
应用运行环境的整体快照/模板
比虚拟环境范围大得多。
一句话对比
虚拟环境
只隔离 Python 包
镜像
打包 系统环境 + Python + 依赖 + 代码 + 运行方式
⚪完整流程
| 步骤 | 它在做什么 | 产物是什么 |
|---|---|---|
| 写 FastAPI / 模型代码 | 把业务功能写出来 | 源码 |
| 写 requirements.txt | 固定 Python 依赖版本 | 依赖清单 |
| 写 Dockerfile | 规定怎么构建运行环境 | 构建说明书 |
| docker build | 按 Dockerfile 做出镜像 | image |
| docker run / compose | 把镜像跑起来测试 | container |
| CI 自动测试 + 构建镜像 | 自动检查代码并打包 | 测试结果 + 新镜像 |
| push 到镜像仓库 | 把镜像上传到远程仓库 | 仓库中的镜像版本 |
| 生产服务器 / K8s 部署 | 在线上机器运行镜像 | 线上服务 |
| health check + 监控 + 回滚 | 保证线上服务稳定 | 健康状态 / 可恢复能力 |
1)写 FastAPI / 模型代码
原话
写 FastAPI / 模型代码
人话翻译
先把你真正要提供的服务写出来。
比如:
-
一个
/predict接口 -
一个
/health接口 -
模型加载逻辑
-
数据预处理逻辑
-
推理输出逻辑
它在干什么?
这是在定义:
你的服务到底要做什么事
输入是什么?
你的业务需求。
比如:
-
输入一张图
-
输出缺陷类别
-
或输入 10 维特征
-
输出类别 ID
输出是什么?
Python 源码文件。
比如:
-
main.py -
model.py -
schemas.py
没这一步会怎样?
后面一切都没意义,因为根本没有服务可打包。
假设你训练好了 SFDNet,你想让导师 / 同事 / 国外合作者都能用。
没有 FastAPI:
-
你把代码打包发给每个人;
-
每个人自己装环境、自己装 CUDA、自己调 bug;
-
每个人跑的结果可能略有差异(环境不一样);
-
你改了模型要通知所有人重新拉代码;
-
国外合作者可能根本没 GPU,用不了。
有 FastAPI + Docker:
-
你部署一个服务到学校服务器,地址
http://sfdnet.dhu.edu.cn:8000; -
任何人(包括没 GPU 的)发 HTTP 请求就能用;
-
所有人用的是同一个模型版本,结果完全一致;
-
你升级模型,所有人下次调用自动用上新版;
-
国外合作者在笔记本上点一下按钮就能跑。
这就是"服务"对"脚本"的本质超越------从"一份代码"变成"一项能力"。
下次你看到"写 FastAPI / 模型代码"这句话,脑子里应该浮现的不是"一段处理数据的程序",而是:
一家准备开张营业的店铺,门口挂着菜单(API 接口),后厨备着厨师(模型),定好接单和出餐的规矩(schemas),接下来就等客人上门。
2)写 requirements.txt 固定依赖
原话
写 requirements.txt 固定依赖
人话翻译
把项目运行所需的 Python 包,以及它们的版本,明确写下来。
例如
fastapi==0.115.0
uvicorn==0.30.6
torch==2.4.1
numpy==1.26.4
它在干什么?
这是在回答:
这个项目到底依赖哪些 Python 库,版本是多少
输入是什么?
你的代码用了哪些包。
输出是什么?
一份依赖清单。
为什么要"固定版本"?
因为如果不固定:
-
你今天装到 torch 2.4.1
-
别人明天可能装到 torch 2.5.0
-
结果行为可能不同
所以 requirements.txt 的本质是:
把 Python 依赖配方写死
3)写 Dockerfile 固定运行环境
原话
写 Dockerfile 固定运行环境
人话翻译
告诉 Docker:
你应该拿什么基础环境开始,装什么依赖,拷什么代码,最后怎么启动服务
例如:
FROM python:3.10.13-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install -r requirements.txt
COPY . .
CMD "uvicorn", "app.main:app", "--host", "0.0.0.0", "--port", "8000"
它在干什么?
这是在写:
镜像怎么做出来的说明书
输入是什么?
-
你的项目代码
-
requirements.txt
-
你想用的基础镜像
-
你希望的启动命令
输出是什么?
一个 Dockerfile 文本文件。
为什么它重要?
因为 Dockerfile 决定了:
-
容器里 Python 版本是多少
-
装哪些依赖
-
代码放在哪里
-
服务启动命令是什么
它相当于"标准化生产流程"。
4)docker build 生成镜像
原话
docker build 生成镜像
人话翻译
让 Docker 按 Dockerfile 的说明,真的把环境做出来。
命令例如:
docker build -t vision-infer:1.0.0 .
它在干什么?
就是把:
-
基础镜像
-
Python 依赖
-
系统包
-
项目代码
打包成一个 image(镜像)
输入是什么?
-
Dockerfile
-
requirements.txt
-
项目代码目录
输出是什么?
一个 image,比如:
vision-infer:1.0.0
为什么叫"镜像"?
因为它像一个静态模板,
还没真正跑起来,但已经把运行所需内容都准备好了。
镜像是一种"包",但和代码包的区别在于------它不只包含你的代码,还包含了一整套"能让这些代码跑起来的环境":操作系统层、系统库、CUDA、Python、依赖包、模型权重、启动配置。镜像 = "代码 + 完整运行环境"的不可变快照。
你说"输出是相对于只有所有代码的包"------这个方向对,但不够完整。准确的说法是:
镜像 = 代码 + 所有依赖 + 操作系统层 + 运行配置,打包成一个"随时能变成活容器"的文件。
把"镜像"和"代码包"做个对比你就懂了:
| 打包方式 | 里面有什么 | 能直接运行吗 |
|---|---|---|
| ZIP 代码包 | 只有源代码 | 不能,对方要装 Python、装依赖、装 CUDA |
| Wheel / pip 包 | 代码 + Python 依赖声明 | 不能,对方要有 Python 环境和系统库 |
| 虚拟环境(venv) | 代码 + Python + 依赖 | 能,但仅限同操作系统、同硬件架构 |
| Docker 镜像 | 代码 + 依赖 + 完整 Linux 环境 + 运行配置 | 能,任何装了 Docker 的机器上都能跑,结果完全一致 |
所以"镜像"不只是"代码的包",而是**"整个运行环境的快照"**。它包含的东西远超你写的那几行代码。
二、镜像里到底装了什么------拆开看一下
还是用 SFDNet 那个例子。当你执行完 docker build -t sfdnet-inference:v1.0.0 .,生成的这个镜像文件(大约 4GB)里面实际上是这些东西堆起来的:
sfdnet-inference:v1.0.0 (4.2 GB)
│
├─── 第 1 层:Ubuntu 22.04 基础系统(约 70 MB)
│ └── 包含 /bin, /lib, /etc 等基本系统目录
│
├─── 第 2 层:CUDA 12.1 + cuDNN 8(约 2 GB)
│ ├── /usr/local/cuda/
│ ├── CUDA runtime 库
│ └── cuDNN 库
│
├─── 第 3 层:apt 装的系统包(约 100 MB)
│ ├── python3.10
│ ├── libglib2.0-0
│ └── libgl1 等
│
├─── 第 4 层:pip 装的 Python 依赖(约 1.8 GB)
│ ├── torch 2.1.0(最大的一个)
│ ├── fastapi
│ ├── uvicorn
│ ├── pillow
│ └── ...
│
├─── 第 5 层:你的代码(约 50 KB)
│ └── /app/main.py, model.py, inference.py
│
├─── 第 6 层:模型权重(约 200 MB)
│ └── /app/weights/sfdnet_best.pth
│
└─── 元数据(metadata)
├── 启动命令:CMD ["uvicorn", "app.main:app", ...]
├── 暴露端口:EXPOSE 8000
├── 环境变量:PYTHONUNBUFFERED=1 等
├── 工作目录:WORKDIR /app
└── 健康检查配置你的代码只占整个镜像的 0.001%(50KB / 4.2GB),剩下的 99.999% 都是为了让你的代码能跑起来的各种依赖和环境。这就是镜像和"代码包"最大的区别。
三、用 VMware 镜像做类比,最容易懂
你可能用过 VMware 或 VirtualBox------如果你从朋友那里拷来一个 Windows 虚拟机镜像,打开就是一个完整的 Windows 系统,里面装好的软件、文件、设置都在。
Docker 镜像概念上完全一样------它是一个"迷你 Linux 系统的快照",只不过:
-
VMware 镜像:完整虚拟机,几十 GB,启动慢;
-
Docker 镜像:只含必要组件,共享宿主机内核,几 GB,启动毫秒级。
所以镜像的本质是:"一台随时可以复刻出来的虚拟电脑的快照"。里面包含的不只是代码,而是"代码 + 能让代码跑起来的一切东西"。
5)docker run / docker compose 本地测试
原话
docker run / docker compose 本地测试
人话翻译
把刚才 build 出来的 image 真的启动起来,看看它能不能跑。
例如:
docker run -p 8000:8000 vision-infer:1.0.0
或者:
docker compose up --build
它在干什么?
这是把 image 变成一个运行中的 container。
输入是什么?
一个 image。
输出是什么?
一个正在运行的 container。
为什么要本地测试?
因为你刚 build 出来的镜像,未必真能工作。
常见问题有:
-
启动命令写错
-
缺包
-
端口没暴露
-
路径不对
-
health 接口报错
所以这一步是在做:
上线前的第一轮验证
6)CI 自动测试 + 自动构建镜像
原话
CI 自动测试 + 自动构建镜像
人话翻译
CI = Continuous Integration,持续集成。
意思是:
你一提交代码,系统就自动帮你做检查
比如 GitHub Actions、GitLab CI、Jenkins。
它在干什么?
自动完成这些事情:
-
拉代码
-
安装依赖
-
跑单元测试
-
构建 Docker image
输入是什么?
你 push 到 Git 仓库的新代码。
输出是什么?
-
测试通过 / 失败结果
-
一个新的镜像版本
为什么要自动做?
因为如果全靠人手动:
-
容易漏测
-
容易忘 build
-
每个人操作不一致
CI 的价值就是:
把检查流程机器化、稳定化
7)push 到镜像仓库
原话
push 到镜像仓库
人话翻译
把刚才 build 出来的 image 上传到远程仓库,方便别人拉取。
比如:
-
Docker Hub
-
Harbor
-
AWS ECR
-
GitHub Container Registry
它在干什么?
相当于把"产品成品"放进仓库。
输入是什么?
本地 build 好的 image。
输出是什么?
远程仓库里的一份镜像版本。
例如:
registry.example.com/vision-infer:1.0.0
为什么需要这一步?
因为生产服务器不可能从你电脑里拿镜像。
它必须从一个统一的远程仓库去拉。
所以这一步本质是:
把镜像从开发机交付给部署系统
8)生产服务器 / Kubernetes 拉取镜像部署
原话
生产服务器 / Kubernetes 拉取镜像部署
人话翻译
让线上机器真正去运行这个镜像,对外提供服务。
两种常见方式
方式 A:服务器直接 docker run
适合小项目。
方式 B:Kubernetes 部署
适合更工业化场景,支持:
-
多副本
-
自动重启
-
滚动更新
-
自动扩缩容
它在干什么?
这是在把"准备好的成品"真正上线。
输入是什么?
远程镜像仓库里的 image。
输出是什么?
线上运行中的服务实例。
为什么不能直接用开发机上的 container?
因为开发机不是生产环境:
-
不稳定
-
不可持续
-
不适合对外服务
生产部署这一步,才是把服务正式交付给用户。
9)health check + 监控 + 回滚
原话
health check + 监控 + 回滚
人话翻译
服务上线后,不是就完了,
还要持续盯着它有没有出问题。
9.1 health check 是什么?
健康检查。
比如系统定时访问:
GET /health
如果返回正常,就说明服务活着。
它解决什么问题?
不是"进程还在"就说明服务能用。
可能进程没死,但:
-
模型没加载成功
-
数据库连不上
-
接口卡死
-
内存爆了快不行了
所以 health check 是在判断:
服务是不是健康可用
9.2 监控是什么?
持续收集运行指标。
比如:
-
CPU 使用率
-
内存使用率
-
接口响应时间
-
错误率
-
QPS
-
容器重启次数
它的作用是什么?
让你知道:
-
服务有没有变慢
-
有没有异常增多
-
有没有资源快耗尽
9.3 回滚是什么?
如果新版本上线后出问题,
快速切回旧版本。
例如:
-
从
vision-infer:1.0.1 -
切回
vision-infer:1.0.0
为什么回滚很重要?
因为生产事故时,
最快的修复方式往往不是"现场改代码",
而是:
直接切回上一个稳定镜像
这就是 Docker 版本化带来的巨大价值。
⚪Docker 到底统一了什么?
Docker 统一的是应用运行时依赖的 user space 环境,不是把整个操作系统和硬件都复制一遍。
| 层 | 具体内容 | Docker image 会不会带上 | 是否统一 |
|---|---|---|---|
| 应用层 | 你的代码、程序 | ✅ | 能统一 |
| 依赖层 | Python、torch、libc、系统包 | ✅ | 能统一 |
| 文件系统层 | /app、/usr、/bin 这些目录内容 |
✅ | 能统一 |
| Kernel 层 | Linux kernel / Windows kernel | ❌ | 不能由 image 自带 |
| 硬件层 | CPU、GPU、驱动 | ❌ | 不能完全统一 |
不用 Docker vs 用 Docker
| 问题维度 | 不用 Docker | 用 Docker |
|---|---|---|
| Python 版本 | 每台机器自己装,可能不同 | image 里固定 |
| 第三方库版本 | 可能冲突 | image 里固定 |
| 系统包依赖 | Ubuntu/CentOS/macOS 差异很大 | image 里固定 |
| 目录结构 | 各自不同 | image 里固定 |
| Kernel 差异 | 存在 | 仍然存在 |
| GPU / 驱动差异 | 存在 | 仍然存在 |
⚪如果没有 Docker,会出什么问题?
假设两个人都开发同一个 Python 服务。
员工 A(Windows)
-
Python 3.11
-
某个 wheel 安装方式
-
路径分隔符
\ -
本地自己配的环境变量
员工 B(Linux)
-
Python 3.9
-
gcc / libc 版本不同
-
路径分隔符
/ -
pip 装的库版本也不同
结果:
-
A 能跑
-
B 不能跑
-
部署机又是 Ubuntu,还是第三套环境
这时候问题通常不是 kernel 先出事 ,
而是前面这些更高频的东西先炸:
-
Python 版本
-
torch 版本
-
依赖包
-
系统库
-
路径
-
命令工具
-
文件系统布局
⚪所以 Docker 在解决什么?
Docker 在解决的是:
绝大多数"应用级、依赖级、用户空间级"的环境不一致问题。
它不是在说:
"我连内核都给你变得一模一样"
它是在说:
"至少你应用最常碰到的那一层,我给你钉死了。"
⚪"假设两个员工 a 和 b 一起做项目,a 创了一个 Docker,b 也创了一个 Docker,那是不是相当于在这个 Docker 里面他俩包装的版本都一样?"
人话翻译
不一定。
这取决于他们是不是:
-
用同一个 Dockerfile
-
用同一个基础镜像
-
用同一个 requirements.txt
-
把版本锁死了
-
用同一个项目代码快照
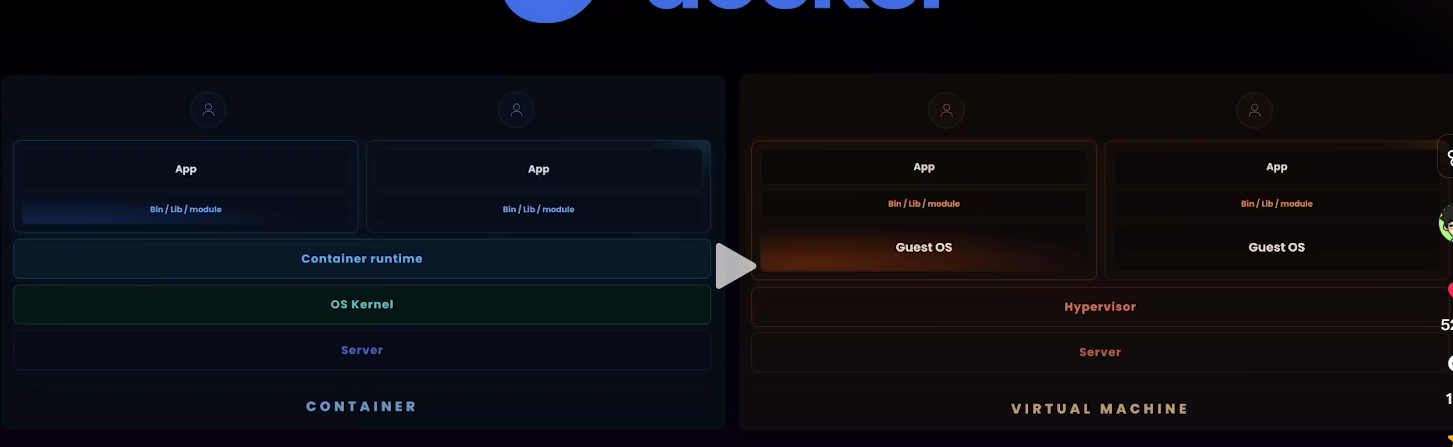
左边:Container
Server
↓
真实硬件:CPU / 内存 / 磁盘 / 网卡
OS Kernel
↓
宿主机内核,负责调度进程、分配内存、管理文件和网络
Container runtime
↓
负责把容器创建出来,做好隔离、挂载、网络、资源限制
Bin / Lib / module
↓
这个应用自己需要的解释器、依赖库、模块
App
↓
真正要运行的业务程序
右边:Virtual Machine
Server
↓
真实硬件
Hypervisor
↓
把一台真实机器切成多台虚拟机器
Guest OS
↓
每个 VM 自己的操作系统
Bin / Lib / module
↓
这个 VM 内应用自己的依赖
App
↓
真正运行的业务程序
最后再给你一个"逐词秒懂版"
左边容器图
-
App:应用程序
-
Bin / Lib / module:应用依赖
-
Container runtime:容器运行管理层
-
OS Kernel:宿主机内核
-
Server:真实物理服务器
右边虚拟机图
-
App:应用程序
-
Bin / Lib / module:应用依赖
-
Guest OS:虚拟机自己的操作系统
-
Hypervisor:虚拟化管理层
-
Server:真实物理服务器