先简单说下Vosk这款工具,Vosk 是一款由 Alpha Cephei 团队开发的开源离线语音识别工具包,基于 Kaldi 框架构建,支持20 多种语言的本地化语音转写,具有低资源占用和高隐私安全性的核心优势。
核心概念与准备工作
1、核心组件:
Vosk-API:开源离线语音识别库,支持 40 + 语言,纯本地运行,无需联网
语言模型:Vosk 提供多种预训练模型,中文推荐使用 vosk-model-small-cn-0.22(轻量)或 vosk-model-cn-0.22(标准)
音频要求:必须为 PCM 16 位 单声道 16000Hz 格式(Vosk 标准输入格式)
2、环境要求
JDK 8+(注意:一定要用1.8,本人遇到的坑就是JDK17识别出来会乱码,转码以后也会出现 "浣犲ソ 浠婂ぉ 澶╂皵 寰堝ソ 鏄� 鍜� 鍑哄幓 娓哥帺" 这种的)
Maven/Gradle 构建工具
系统依赖:Windows 需 libvosk.dll,Linux 需 libvosk.so,macOS 需 libvosk.dylib(Maven 依赖自动处理)
话不多说,上代码:
1、先添加 Maven 依赖
xml
<!-- Vosk 核心依赖 -->
<dependency>
<groupId>com.alphacephei</groupId>
<artifactId>vosk</artifactId>
<version>0.3.45</version>
</dependency>
<!-- JNA 依赖(Vosk 底层使用) -->
<dependency>
<groupId>net.java.dev.jna</groupId>
<artifactId>jna</artifactId>
<version>5.13.0</version>
</dependency>2、官网下载语言模型
轻量模型(约 40MB):https://alphacephei.com/vosk/models/vosk-model-small-cn-0.22.zip
标准模型(约 1.8GB):https://alphacephei.com/vosk/models/vosk-model-cn-0.22.zip
轻量级的适合集成到项目中,准确率稍微低点,标准版准确率高占用空间大,根据需求自行选择
为了方便下载,网盘地址如下:
链接: https://pan.baidu.com/s/10oOsSd5fQE_IPES3WBbqng
提取码: cwnv
先看看测试Demo
java
import org.vosk.Model;
import org.vosk.Recognizer;
import javax.sound.sampled.AudioFormat;
import javax.sound.sampled.AudioInputStream;
import javax.sound.sampled.AudioSystem;
import java.io.File;
/**
* description 语音识别
*
* @author yan
* @version 1.0
* @date 2026/4/20 17:02
*/
public class VoskSpeech {
// 采样率
private static final int SAMPLE_RATE = 16000;
// 模型路径
private static final String MODEL_FOLDER = "D:/vosk/vosk-model-cn-0.22";
// 音频文件路径
private static final String audioPath = "D:/vosk/test.wav";
public static void main(String[] args) {
try (Model model = new Model(MODEL_FOLDER);
Recognizer recognizer = new Recognizer(model, SAMPLE_RATE);
AudioInputStream ais = AudioSystem.getAudioInputStream(new File(audioPath))) {
// 转换音频格式为 Vosk 要求的格式:16kHz, 16bit, 单声道
AudioFormat targetFormat = new AudioFormat(16000, 16, 1, true, false);
AudioInputStream convertedAis = AudioSystem.getAudioInputStream(targetFormat, ais);
byte[] buffer = new byte[4096];
int bytesRead;
while ((bytesRead = convertedAis.read(buffer)) != -1) {
recognizer.acceptWaveForm(buffer, bytesRead);
}
String result = recognizer.getFinalResult();
System.out.println("识别结果:" + result);
} catch (Exception e) {
e.printStackTrace();
}
}
}注意:音频文件只支持.wav格式的,音频为16000Hz
运行结果:

这是我提前生成好的音频,一个字不差全部识别出来了
3、现有需求,需要在浏览器实时监测说话的内容,并转换成文字,下面是代码示例:
xml
<!-- Vosk 核心依赖 -->
<dependency>
<groupId>com.alphacephei</groupId>
<artifactId>vosk</artifactId>
<version>0.3.45</version>
</dependency>
<!-- JNA 依赖(Vosk 底层使用) -->
<dependency>
<groupId>net.java.dev.jna</groupId>
<artifactId>jna</artifactId>
<version>5.13.0</version>
</dependency>
<!-- SpringBoot WebSocket 支持 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-websocket</artifactId>
</dependency>WebSocketConfig 配置类
java
import cn.cecep.szkj.zhzf.websocket.AudioWebSocketHandler;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.socket.config.annotation.EnableWebSocket;
import org.springframework.web.socket.config.annotation.WebSocketConfigurer;
import org.springframework.web.socket.config.annotation.WebSocketHandlerRegistry;
/**
* description WebSocket配置类
*
* @author yan
* @version 1.0
* @date 2026/4/20 11:23
*/
@Configuration
@EnableWebSocket
public class WebSocketConfig implements WebSocketConfigurer {
private final AudioWebSocketHandler audioWebSocketHandler;
public WebSocketConfig(AudioWebSocketHandler audioWebSocketHandler) {
this.audioWebSocketHandler = audioWebSocketHandler;
}
@Override
public void registerWebSocketHandlers(WebSocketHandlerRegistry registry) {
// 将 AudioWebSocketHandler 映射到 /audio 路径,并允许跨域
// 注册端点:ws://localhost:8810/audio
registry.addHandler(audioWebSocketHandler, "/audio").setAllowedOrigins("*");
}
}语音实时处理器
java
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Component;
import org.springframework.web.socket.*;
import org.vosk.LibVosk;
import org.vosk.LogLevel;
import org.vosk.Model;
import org.vosk.Recognizer;
import javax.annotation.PostConstruct;
import javax.annotation.PreDestroy;
import java.io.File;
import java.io.UnsupportedEncodingException;
import java.nio.ByteBuffer;
import java.nio.charset.StandardCharsets;
/**
* description 语音实时处理器
*
* @author yan
* @version 1.0
* @date 2026/4/20 11:23
*/
@Component
public class AudioWebSocketHandler implements WebSocketHandler {
// 这里我先写死了,正常是写到配置文件,这样比较直观,下面分别是下载的模型目录和采样率
@Value("${vosk.path}")
private String voskPath = "D:/vosk/vosk-model-cn-0.22";
@Value("${vosk.sampleRate}")
private int sampleRate = 16000;
private Model voskModel;
@PostConstruct
public void init() throws Exception {
// 使用模型绝对路径
File modelFile = new File(voskPath);
if (!modelFile.exists()) {
throw new RuntimeException("模型文件夹不存在: " + voskPath);
}
// 设置 Vosk 日志级别(可选)
LibVosk.setLogLevel(LogLevel.WARNINGS);
// 加载模型
voskModel = new Model(voskPath);
System.out.println("✅ Vosk 模型加载成功,路径:" + voskPath);
}
@PreDestroy
public void destroy() {
if (voskModel != null) {
voskModel.close();
System.out.println("✅ Vosk 模型已关闭");
}
}
@Override
public void afterConnectionEstablished(WebSocketSession session) throws Exception {
// 为每个 WebSocket 会话创建一个独立的 Recognizer 实例
Recognizer recognizer = new Recognizer(voskModel, sampleRate);
session.getAttributes().put("recognizer", recognizer);
System.out.println("✅ 客户端已连接,Session ID: " + session.getId());
}
@Override
public void handleMessage(WebSocketSession session, WebSocketMessage<?> message) throws Exception {
if (message instanceof BinaryMessage) {
BinaryMessage binaryMessage = (BinaryMessage) message;
ByteBuffer buffer = binaryMessage.getPayload();
byte[] audioData = new byte[buffer.remaining()];
buffer.get(audioData);
Recognizer recognizer = (Recognizer) session.getAttributes().get("recognizer");
// 处理音频数据
if (recognizer.acceptWaveForm(audioData, audioData.length)) {
String rawJson = recognizer.getResult();
System.out.println("原始 JSON: " + rawJson);
session.sendMessage(new TextMessage(rawJson));
} else {
// 打印部分识别结果
String partial = recognizer.getPartialResult();
if (partial != null && !partial.isEmpty()) {
System.out.println("部分结果: " + partial);
}
}
}
}
@Override
public void handleTransportError(WebSocketSession session, Throwable exception) throws Exception {
System.err.println("❌ WebSocket 传输错误,Session ID: " + session.getId());
exception.printStackTrace();
}
@Override
public void afterConnectionClosed(WebSocketSession session, CloseStatus status) throws Exception {
Recognizer recognizer = (Recognizer) session.getAttributes().get("recognizer");
if (recognizer != null) {
recognizer.close();
}
System.out.println("❌ 客户端已断开,Session ID: " + session.getId());
}
@Override
public boolean supportsPartialMessages() {
return false;
}
/**
* 修复 Vosk 返回的 JSON 字符串中的中文乱码(从 GBK 乱码恢复为 UTF-8)
*/
private String fixGarbledText(String garbledJson) {
int start = garbledJson.indexOf("\"text\" : \"") + 10;
int end = garbledJson.lastIndexOf("\"");
if (start <= 10 || end <= start) {
return garbledJson;
}
String garbledText = garbledJson.substring(start, end);
String tempPlaceholder = "___TEMP___";
String tempText = garbledText.replace("\uFFFD", tempPlaceholder);
try {
byte[] utf8Bytes = tempText.getBytes("GBK");
String correctText = new String(utf8Bytes, StandardCharsets.UTF_8);
correctText = correctText.replace(tempPlaceholder, "�");
return garbledJson.substring(0, start) + correctText + garbledJson.substring(end);
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
return garbledJson;
}
}
}前端Demo
html
<!DOCTYPE html>
<html>
<head>
<title>实时语音识别 - Java Vosk</title>
</head>
<body>
<button id="startBtn">开始录音</button>
<button id="stopBtn" disabled>停止录音</button>
<h3>识别结果:</h3>
<div id="result" style="border:1px solid #ccc; min-height:100px; padding:5px;"></div>
<script>
const startBtn = document.getElementById('startBtn');
const stopBtn = document.getElementById('stopBtn');
const resultDiv = document.getElementById('result');
let audioContext;
let mediaStream;
let sourceNode;
let ws;
startBtn.onclick = async () => {
// 获取麦克风权限
const stream = await navigator.mediaDevices.getUserMedia({ audio: true });
mediaStream = stream;
// 建立 WebSocket 连接
ws = new WebSocket('ws://localhost:8810/audio');
ws.binaryType = 'arraybuffer';
ws.onopen = () => {
console.log('WebSocket 连接已建立');
// 创建 AudioContext,并配置采样率为 16000
audioContext = new AudioContext({ sampleRate: 16000 });
sourceNode = audioContext.createMediaStreamSource(stream);
// 创建一个 ScriptProcessorNode 来处理原始 PCM 数据
// bufferSize: 4096, 输入通道: 1, 输出通道: 1
const processor = audioContext.createScriptProcessor(4096, 1, 1);
processor.onaudioprocess = (event) => {
// 获取 PCM 数据 (Float32Array, 范围 -1 到 1)
const inputData = event.inputBuffer.getChannelData(0);
// 转换为 16-bit PCM 的 ArrayBuffer
const pcmBuffer = convertFloat32ToInt16(inputData);
if (ws && ws.readyState === WebSocket.OPEN) {
// 发送 PCM 数据
ws.send(pcmBuffer);
}
};
sourceNode.connect(processor);
processor.connect(audioContext.destination);
startBtn.disabled = true;
stopBtn.disabled = false;
};
ws.onmessage = (event) => {
const result = JSON.parse(event.data);
if (result.text) {
resultDiv.innerText = result.text;
}
};
};
stopBtn.onclick = () => {
if (sourceNode) sourceNode.disconnect();
if (audioContext) audioContext.close();
if (mediaStream) {
mediaStream.getTracks().forEach(track => track.stop());
}
if (ws && ws.readyState === WebSocket.OPEN) {
ws.close();
}
startBtn.disabled = false;
stopBtn.disabled = true;
};
// 辅助函数:将 Float32Array 的音频数据转换为 16-bit PCM 的 ArrayBuffer
function convertFloat32ToInt16(float32Array) {
const length = float32Array.length;
const buffer = new ArrayBuffer(length * 2);
const view = new DataView(buffer);
for (let i = 0; i < length; i++) {
let sample = Math.max(-1, Math.min(1, float32Array[i]));
view.setInt16(i * 2, sample < 0 ? sample * 0x8000 : sample * 0x7FFF, true);
}
return buffer;
}
</script>
</body>
</html>下面看看运行效果:
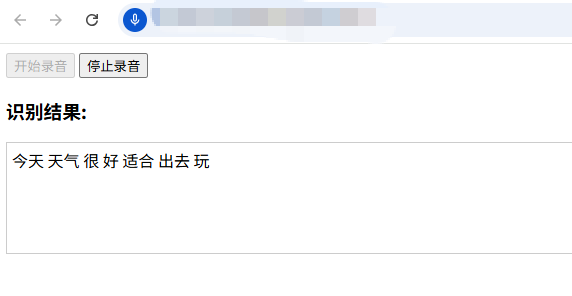
可以看到识别率还是很高的,Vosk还支持多种方言,对中文方言的支持主要体现在粤语上,普通话模型难以准确识别其他方言,因此,在实际应用中,需要根据你的具体方言需求,选择或训练对应的专用模型。