大家好,我是Java1234_小锋老师。
当 Python 世界里 LangChain 已经成为构建大模型应用的事实标准时,Java 开发者手边却长期缺少一款足够成熟、贴合企业级工程规范的 LLM 应用框架。LangChain4j 的出现,恰好填补了这块空白。本文将从它的设计理念讲起,带你从零上手,再深入它的核心抽象与整体架构,力求让你读完之后,既能快速写出第一个 AI Service,也能看懂它在一个真实系统里应该扮演什么角色。
一、LangChain4j 是什么
1.1 它要解决什么问题
过了 2023 之后,任何一个稍微像样的后端系统,几乎都绕不开"要不要接一下大模型"这个问题。但只要你真动手写过,就会发现接入 LLM 是一件挺琐碎的事:
- 要手写一堆 HTTP 请求去调 OpenAI、Azure、Anthropic;
- 要自己拼 Prompt,自己处理 token、处理 SSE 流式响应;
- 要实现多轮对话,就得自己维护一份历史消息;
- 想做 RAG,就得自己做分块、做向量化、再写一次向量检索;
- 想让模型能"调用函数",还得自己设计 JSON Schema、解析返回、执行方法......
这些工作不难,但琐碎、重复,且每换一家模型提供商就要再写一遍。LangChain4j 做的,就是把这些通用流程抽象出来,提供一套统一的、面向对象的、Java 味十足的 API,让你把精力放回到业务逻辑本身。
1.2 与 Python 版 LangChain 的关系
LangChain4j 在灵感上确实来自 Python 的 LangChain,但它不是简单翻译。Java 世界有自己的工程习惯------强类型、注解驱动、依赖注入、显式接口,LangChain4j 在 API 设计上充分尊重了这些特征。你会看到:
- 用
@AiService、@SystemMessage、@UserMessage、@Tool这样的注解声明能力; - 用
ChatLanguageModel、EmbeddingModel、EmbeddingStore这种清晰的接口做抽象; - 用 Spring Boot Starter / Quarkus Extension 原生接入 IoC 容器。
一句话:它是 Java 工程师看了会觉得"就应该这么写"的那种框架。
1.3 适合什么样的项目
LangChain4j 大致适合以下几类场景:
- 企业内部智能问答 / 知识库:结合 RAG,把 Confluence、PDF、数据库中的资料变成可问答的助手。
- 客服 / 营销对话机器人:多轮会话、记忆、上下文,天然适合 ChatMemory + Tools 的组合。
- 业务系统里的 AI 小能手:比如自动生成周报、自动提取合同字段、自动打标签、自动写 SQL。
- Agent / Copilot 类应用:模型不仅答题,还会调用系统内的工具完成任务。
如果你的系统已经是 Spring Boot / Quarkus 生态,再要接入 LLM,用 LangChain4j 几乎是目前最顺手的选择。
二、快速入门
2.1 环境准备
LangChain4j 对运行环境的要求不高,但有几条硬性前提:
- JDK 17 及以上(新版本已将 21 作为推荐版本)。
- Maven 3.8+ 或 Gradle 7+。
- 一个可用的 LLM 调用通道:OpenAI API Key、Azure OpenAI、Ollama 本地模型等任选其一。
本文示例以 Maven + OpenAI 兼容接口 为主,其他模型提供商的切换成本非常低------基本只换一个依赖、一个实现类。
2.2 引入依赖
在 pom.xml 中加入核心依赖:
xml
<properties>
<langchain4j.version>0.35.0</langchain4j.version>
</properties>
<dependencies>
<!-- 核心抽象 -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j</artifactId>
<version>${langchain4j.version}</version>
</dependency>
<!-- OpenAI 接入 -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai</artifactId>
<version>${langchain4j.version}</version>
</dependency>
<!-- 可选:本地嵌入模型,做 RAG 不想花钱买 embedding 时很好用 -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-embeddings-all-minilm-l6-v2</artifactId>
<version>${langchain4j.version}</version>
</dependency>
</dependencies>如果你使用 Spring Boot,额外加一个 Starter 会更舒服:
xml
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai-spring-boot-starter</artifactId>
<version>${langchain4j.version}</version>
</dependency>2.3 第一个程序:5 行代码对话 GPT
先来最小可运行示例,感受一下这个框架的"克制":
typescript
import dev.langchain4j.model.openai.OpenAiChatModel;
import dev.langchain4j.model.chat.ChatLanguageModel;
public class HelloLangChain4j {
public static void main(String[] args) {
ChatLanguageModel model = OpenAiChatModel.builder()
.apiKey(System.getenv("OPENAI_API_KEY"))
.modelName("gpt-4o-mini")
.build();
String answer = model.generate("用一句话解释什么是 LangChain4j?");
System.out.println(answer);
}
}跑起来就能看到模型的回复。这里的关键点是:ChatLanguageModel 是一个接口。你今天用 OpenAI,明天换成 Ollama 本地跑 Qwen、DeepSeek,业务代码一行都不用改,只需换 Builder。
2.4 使用高级 AI Services
原始接口虽然好用,但真实业务里你一般不想满屏都是字符串拼接。LangChain4j 提供了一种叫 AI Services 的声明式写法,用接口 + 注解来描述"我要一个会做什么的 AI"。
less
import dev.langchain4j.service.SystemMessage;
import dev.langchain4j.service.UserMessage;
import dev.langchain4j.service.AiServices;
interface Translator {
@SystemMessage("你是一位资深的中英互译专家,翻译力求准确、自然、避免直译腔。")
String translate(@UserMessage String text);
}
public class TranslatorDemo {
public static void main(String[] args) {
ChatLanguageModel model = OpenAiChatModel.withApiKey(System.getenv("OPENAI_API_KEY"));
Translator translator = AiServices.create(Translator.class, model);
System.out.println(translator.translate("LangChain4j makes building LLM apps feel native to Java."));
}
}注意这段代码的意味:我们没有写任何 HTTP 请求、没有拼任何 JSON,只是用 Java 接口声明了一个业务能力。背后 LangChain4j 会自动生成动态代理,把方法调用翻译成对 LLM 的调用。这就是它"Java 味"的核心体现。
2.5 在 Spring Boot 里开箱即用
在 application.yml 中:
yaml
langchain4j:
open-ai:
chat-model:
api-key: ${OPENAI_API_KEY}
model-name: gpt-4o-mini
temperature: 0.3
log-requests: true
log-responses: true然后任意 Service 里直接注入:
arduino
@Service
public class ChatService {
private final ChatLanguageModel chatModel;
public ChatService(ChatLanguageModel chatModel) {
this.chatModel = chatModel;
}
public String ask(String question) {
return chatModel.generate(question);
}
}Bean 自动装配、配置统一托管,这些 Spring 玩家熟悉的待遇,LangChain4j 都给足了。
三、核心技术剖析
理解一个框架的最好方法,不是死记每个 API,而是搞清楚它有哪几个核心抽象。LangChain4j 的核心其实就七件事:模型、AI Services、记忆、工具、检索增强、流式、结构化输出。我们一个个看。
3.1 ChatLanguageModel:所有对话的起点
ChatLanguageModel 是整个框架最底层也最关键的接口。几乎你看到的任何高层 API,最后都会落到它身上。
typescript
public interface ChatLanguageModel {
Response<AiMessage> generate(List<ChatMessage> messages);
default String generate(String userMessage) { ... }
default Response<AiMessage> generate(ChatMessage... messages) { ... }
}它的设计意图非常明确: "你给我一串对话消息,我还你一条 AI 的回复" 。所有模型提供商(OpenAI、Anthropic、Gemini、Ollama、Azure...)都只需要实现这一个接口,上层业务就能无感切换。
消息类型也很规整:
SystemMessage:设定角色、设定约束;UserMessage:用户输入;AiMessage:模型回复;ToolExecutionResultMessage:工具执行结果。
这与 OpenAI Chat Completions 的 role 模型一致,但被翻译成了强类型 Java 对象。
3.2 AI Services:声明式的"魔法"
AI Services 是 LangChain4j 的招牌特性,也是它区别于同类框架最大的亮点之一。它的哲学可以概括为一句:
"接口描述需求,框架生成实现。"
你可以用注解声明 Prompt:
less
interface ArticleAssistant {
@SystemMessage("你是一位科技博客的主编,擅长把复杂概念讲成故事。")
@UserMessage("""
请根据下面的关键词写一段不少于 200 字的引言:
关键词:{{keywords}}
目标读者:{{audience}}
""")
String writeIntro(@V("keywords") String keywords,
@V("audience") String audience);
}底层原理是动态代理 + 模板渲染 :方法入参通过 @V 绑定到 Prompt 模板的变量,框架拼好最终文本,调用 ChatLanguageModel,再根据返回类型把字符串解析成 String / POJO / List<T> 等。
这层抽象的价值在于:业务代码不再关心 Prompt 怎么写、怎么调模型、怎么解析结果,它只看到一个干净的 Java 接口。
3.3 ChatMemory:让模型拥有"上下文"
LLM 本身是无状态的,每一次调用都是独立的。想让它"记得"你上一轮说过什么,就必须把历史消息再塞回去。LangChain4j 把这件事抽象成了 ChatMemory:
less
ChatMemory memory = MessageWindowChatMemory.withMaxMessages(20);
interface Assistant {
String chat(@MemoryId String userId, @UserMessage String message);
}
Assistant assistant = AiServices.builder(Assistant.class)
.chatLanguageModel(model)
.chatMemoryProvider(userId -> MessageWindowChatMemory.withMaxMessages(20))
.build();这里有两个小细节值得注意:
@MemoryId用来区分不同用户 / 会话,每个 ID 对应一条独立记忆;MessageWindowChatMemory是滑动窗口策略,除此之外还有TokenWindowChatMemory,按 token 预算裁剪更精准。
生产环境里,记忆是需要持久化 的。ChatMemoryStore 接口允许你把历史消息落到 Redis、MySQL 或你自家的数据库里,这样应用重启、用户切机都不会丢上下文。
3.4 Tools / Function Calling:让模型调用你的方法
当你希望模型不仅"回答",还能"做事"------查天气、查订单、发邮件------就需要 Tools 能力。LangChain4j 的写法非常 Java:
less
class OrderTools {
@Tool("根据订单号查询订单状态")
public String getOrderStatus(@P("订单号") String orderId) {
return orderRepository.findById(orderId)
.map(o -> "订单 " + orderId + " 当前状态:" + o.getStatus())
.orElse("订单不存在");
}
@Tool("根据用户手机号查询最近一次订单")
public String getLatestOrder(@P("手机号") String phone) {
return orderRepository.findLatestByPhone(phone).toString();
}
}
Assistant assistant = AiServices.builder(Assistant.class)
.chatLanguageModel(model)
.tools(new OrderTools())
.build();仅仅是加了几个注解,LangChain4j 就会在背后完成这一整套动作:解析方法签名、生成 JSON Schema、交给模型、拿到 function call 结果、用反射调用你的方法、把结果再喂回模型......直到模型给出最终答复。
这个过程在框架内部是一个自动循环,我们用一张 Mermaid 流程图来表达更直观:
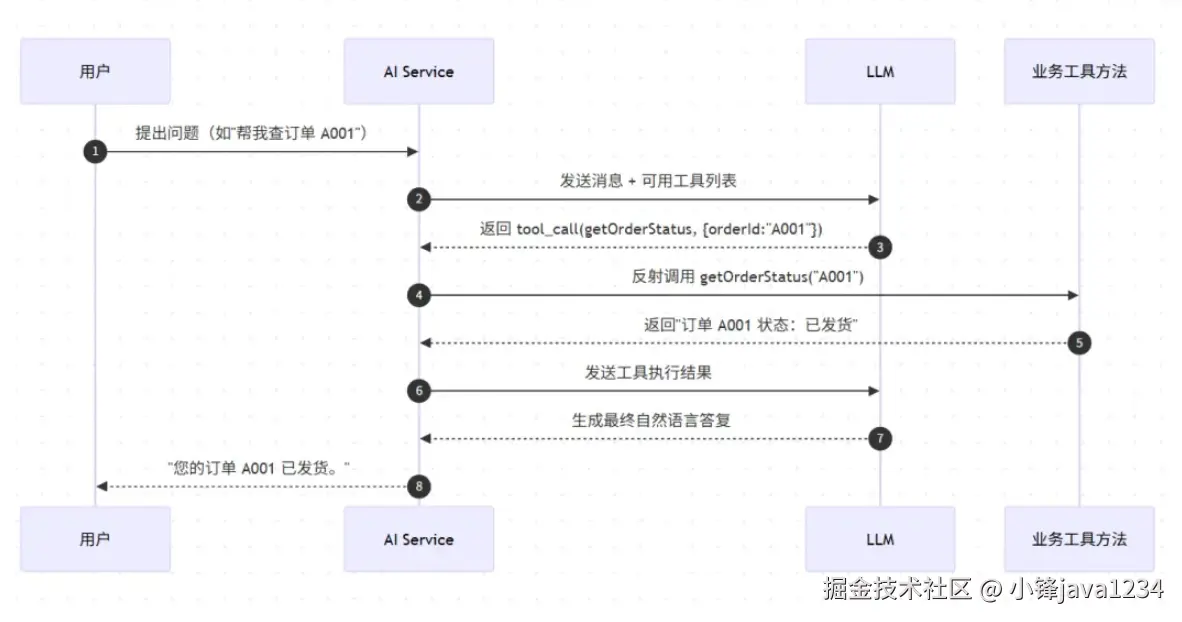
对业务来说这个过程是完全透明的------你只管写普通 Java 方法,模型会自己决定什么时候调用。
3.5 RAG:给模型外挂一个"知识库"
模型再强大,也不可能知道"你司昨天刚发布的内部规范"。解决这个问题的标准姿势就是 RAG(Retrieval-Augmented Generation) :把资料切成小块、向量化存进向量库;提问时先检索相关片段,再拼进 Prompt 给模型。
LangChain4j 把 RAG 拆成了几个高度解耦的接口:
DocumentLoader:从文件、URL、数据库加载原始文档;DocumentSplitter:切块(按段落、按句子、按 token);EmbeddingModel:把文本变成向量;EmbeddingStore:向量库(Pinecone、Milvus、PgVector、Elasticsearch...);ContentRetriever:把以上组合起来,对外提供"检索"这一件事。
最简 RAG 示例:
ini
EmbeddingModel embeddingModel = new AllMiniLmL6V2EmbeddingModel();
EmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>();
Document document = FileSystemDocumentLoader.loadDocument(
Path.of("docs/company-handbook.pdf"), new ApachePdfBoxDocumentParser());
DocumentSplitter splitter = DocumentSplitters.recursive(500, 50);
List<TextSegment> segments = splitter.split(document);
List<Embedding> embeddings = embeddingModel.embedAll(segments).content();
embeddingStore.addAll(embeddings, segments);
ContentRetriever retriever = EmbeddingStoreContentRetriever.builder()
.embeddingModel(embeddingModel)
.embeddingStore(embeddingStore)
.maxResults(5)
.minScore(0.6)
.build();
Assistant assistant = AiServices.builder(Assistant.class)
.chatLanguageModel(model)
.contentRetriever(retriever)
.build();
String answer = assistant.chat("公司年假政策是怎样的?");对应的内部流程(后面架构章节还会用一张高清图展示):

3.6 Streaming:打字机式的流式输出
要做 ChatGPT 那种"一个字一个字往外蹦"的效果,需要的是 StreamingChatLanguageModel:
typescript
StreamingChatLanguageModel streamingModel = OpenAiStreamingChatModel.builder()
.apiKey(apiKey)
.modelName("gpt-4o-mini")
.build();
streamingModel.generate("讲一个 100 字的程序员笑话", new StreamingResponseHandler<AiMessage>() {
@Override public void onNext(String token) { System.out.print(token); }
@Override public void onComplete(Response<AiMessage> resp) { System.out.println("\n[END]"); }
@Override public void onError(Throwable error) { error.printStackTrace(); }
});在 Web 场景下,配合 Spring WebFlux / SSE 就能把 token 实时推到前端。AI Services 也支持流式------把方法返回值声明成 TokenStream 即可,写法保持一致。
3.7 结构化输出:把字符串"变成"对象
模型返回的是自然语言,但业务系统需要结构化数据。LangChain4j 会根据 AI Service 方法的返回类型,自动帮你把模型的回复解析为目标 POJO:
vbnet
record Resume(String name, int age, List<String> skills, String summary) {}
interface ResumeParser {
@UserMessage("请从下面这段简历文本中提取结构化信息:\n{{it}}")
Resume parse(String resumeText);
}
Resume r = AiServices.create(ResumeParser.class, model)
.parse("李雷,29 岁,掌握 Java / Spring / Kafka,负责过......");背后发生了两件事:
- 框架会把目标类型的 JSON Schema 以"请严格按这个格式返回"的方式写进 Prompt;
- 收到回复后自动反序列化为
Resume对象。失败时还能触发一次 LLM 自修复。
这对减少"字符串解析地狱"的帮助非常大。
四、整体架构
讲完了"零件",我们再退一步看"整车"。LangChain4j 在架构上追求的是模块清晰、单一职责、可替换。
4.1 总体架构图
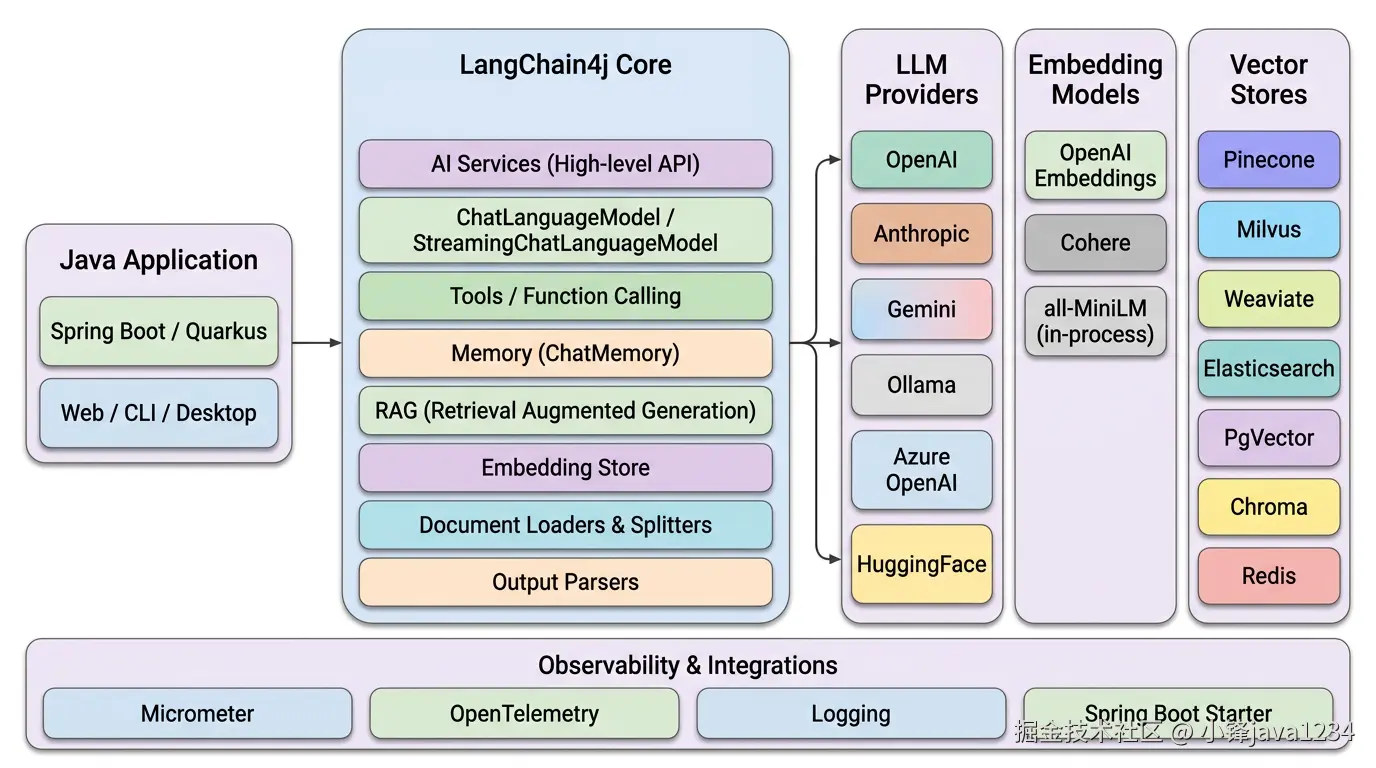
可以从图中一眼看出几层意思:
- 最左侧是你的 Java 应用,通常是 Spring Boot 或 Quarkus。
- 中间的 LangChain4j Core 把所有关键抽象都放在一个蓝色大块里------AI Services、ChatLanguageModel、Tools、Memory、RAG、Embedding Store、Document 处理、输出解析。
- 右侧是三列可插拔的外部能力:LLM 提供商、嵌入模型、向量数据库。每一列都是"同一个接口、多个实现"的典型 SPI 风格。
- 底部则是面向企业工程化的横切关注点:Micrometer、OpenTelemetry、日志、Spring Boot Starter。
这种结构决定了一件事:你随时可以把 OpenAI 换成 Ollama,把 Pinecone 换成 PgVector,而业务代码几乎不需要改动。这是 LangChain4j 最值得称道的地方。
4.2 分层架构
如果把 LangChain4j 按"技术栈高度"重新梳理一下,会得到下面这张分层图:
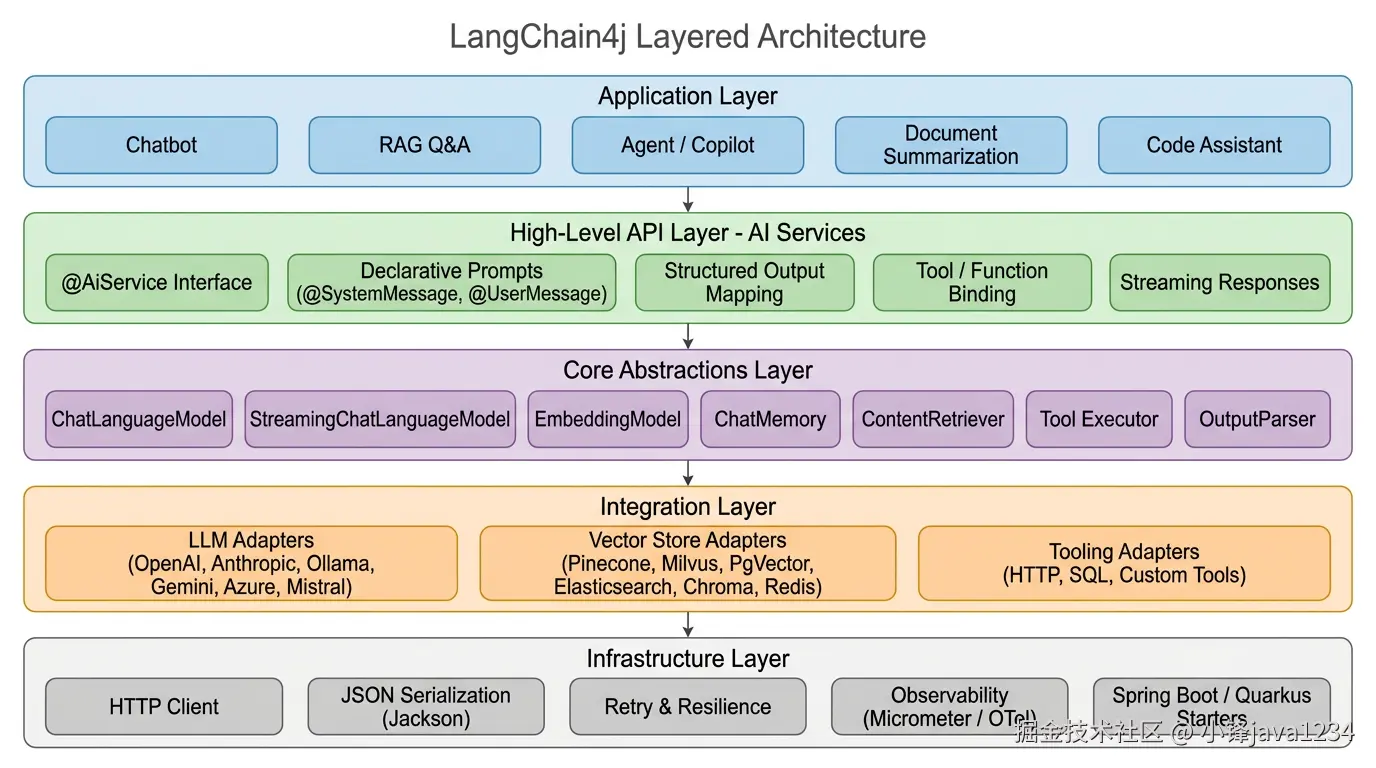
从上往下可以这样理解:
- 应用层:真正面向用户的产品形态------聊天机器人、RAG 问答、Agent、文档总结、代码助手。
- 高级 API 层(AI Services) :用声明式方式描述 AI 能力,让业务代码保持干净。大多数项目写到这一层就够了。
- 核心抽象层:框架的"骨架"------ChatLanguageModel、EmbeddingModel、ChatMemory、ContentRetriever、ToolExecutor、OutputParser。这层决定了设计品味,也决定了可替换性。
- 集成层:对接各种外部系统的适配器,分三类------LLM 适配器、向量库适配器、工具适配器。
- 基础设施层:HTTP Client、JSON 序列化、重试与熔断、可观测性、Spring / Quarkus 启动器。
一个好的架构设计,通常要做到"每一层都只依赖下一层的抽象,不依赖实现"。LangChain4j 在这一点上完成得相当工整。
4.3 RAG 工作原理
RAG 是目前企业落地 LLM 最普遍的一条路,有必要单独放一张高清图来讲清楚:
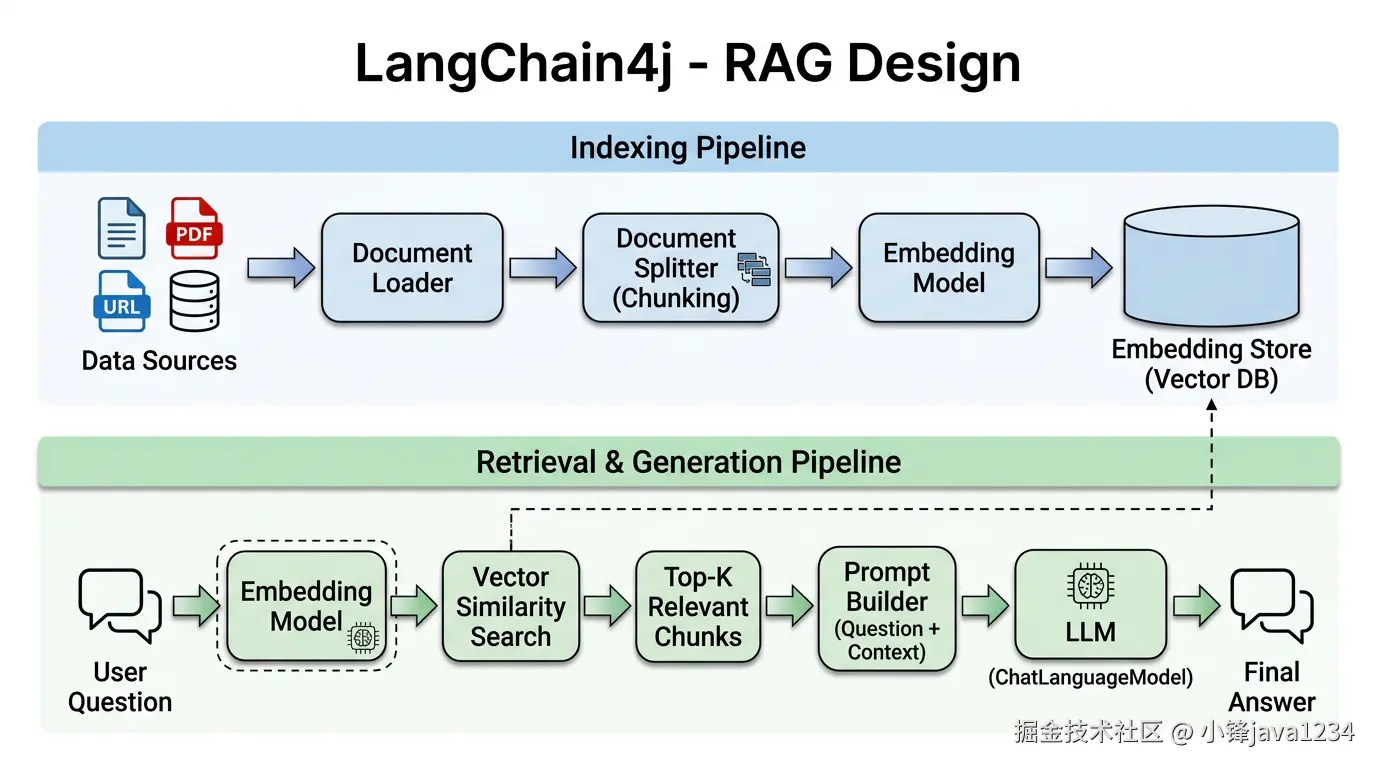
上下两条流水线含义非常明确:
- 上半条(Indexing Pipeline)是"离线"流程:原始数据源 → 加载文档 → 切块 → 向量化 → 写入向量库。这一步通常在数据接入时或定时任务里做。
- 下半条(Retrieval & Generation Pipeline)是"在线"流程:用户的问题 → 同样走向量化 → 去同一个向量库里做相似度检索 → 取 Top-K → 拼入 Prompt → 交给 LLM → 返回答案。
两条流水线共享同一个 Embedding 模型和同一个向量库------这是图中那条虚线想表达的重点。如果两端用的向量化方式不一致,检索效果会直接崩掉,这是很多人做 RAG 常踩的坑。
4.4 一次 AI Service 调用的完整生命周期
我们把前面讲到的所有核心概念揉到一起,看看当你调用一个 AI Service 方法时,框架内部到底发生了什么:
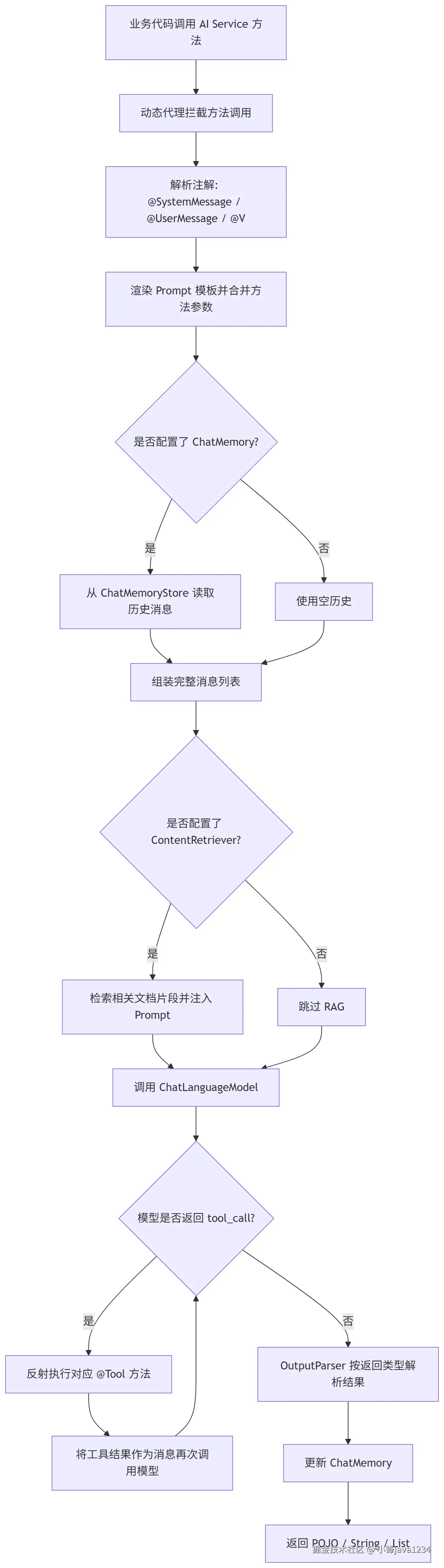
把这张图看懂,整个 LangChain4j 的"思考链路"也就基本了然了。
五、一个更完整的实战案例:企业知识库问答
下面是一个相对完整、可以直接套进 Spring Boot 项目的示例。场景是:运维同学把若干 PDF 丢进目录,我们启动时自动建索引,对外暴露一个 /chat 接口,支持多轮对话 + 知识库检索。
less
@Configuration
public class AiConfig {
@Bean
public EmbeddingModel embeddingModel() {
return new AllMiniLmL6V2EmbeddingModel();
}
@Bean
public EmbeddingStore<TextSegment> embeddingStore() {
return new InMemoryEmbeddingStore<>();
}
@Bean
public ContentRetriever contentRetriever(EmbeddingModel embeddingModel,
EmbeddingStore<TextSegment> store) {
return EmbeddingStoreContentRetriever.builder()
.embeddingModel(embeddingModel)
.embeddingStore(store)
.maxResults(6)
.minScore(0.55)
.build();
}
@Bean
public KnowledgeAssistant knowledgeAssistant(ChatLanguageModel chatModel,
ContentRetriever retriever) {
return AiServices.builder(KnowledgeAssistant.class)
.chatLanguageModel(chatModel)
.contentRetriever(retriever)
.chatMemoryProvider(uid -> MessageWindowChatMemory.withMaxMessages(30))
.build();
}
}
public interface KnowledgeAssistant {
@SystemMessage("""
你是公司内部知识库助手。回答时请遵循:
1. 只使用提供的资料,不要编造;
2. 如资料不足,请明确告诉用户"暂无相关资料";
3. 回答结尾附上引用的文档来源。
""")
String chat(@MemoryId String userId, @UserMessage String question);
}
@Component
public class KnowledgeIndexer {
private final EmbeddingModel embeddingModel;
private final EmbeddingStore<TextSegment> store;
public KnowledgeIndexer(EmbeddingModel embeddingModel,
EmbeddingStore<TextSegment> store) {
this.embeddingModel = embeddingModel;
this.store = store;
}
@PostConstruct
public void indexAtStartup() throws IOException {
DocumentSplitter splitter = DocumentSplitters.recursive(500, 80);
try (Stream<Path> files = Files.walk(Path.of("./knowledge"))) {
files.filter(p -> p.toString().endsWith(".pdf")).forEach(p -> {
Document doc = FileSystemDocumentLoader.loadDocument(p, new ApachePdfBoxDocumentParser());
List<TextSegment> segs = splitter.split(doc);
List<Embedding> embs = embeddingModel.embedAll(segs).content();
store.addAll(embs, segs);
});
}
}
}
@RestController
@RequestMapping("/chat")
public class ChatController {
private final KnowledgeAssistant assistant;
public ChatController(KnowledgeAssistant assistant) {
this.assistant = assistant;
}
@PostMapping
public Map<String, String> chat(@RequestHeader("X-User-Id") String userId,
@RequestBody Map<String, String> body) {
String answer = assistant.chat(userId, body.get("q"));
return Map.of("answer", answer);
}
}这几十行代码,已经是一个可上线 的最小可行知识库问答系统了------启动时自动建索引,运行时多用户隔离记忆、支持 RAG、对外提供 REST 接口。真上生产时再把 InMemoryEmbeddingStore 换成 Milvus / PgVector,把 ChatMemoryStore 换成 Redis 持久化,就完成度很高了。
六、工程化实践建议
写 Demo 和上生产之间,永远隔着一条叫"工程化"的河。几点经验供参考:
- Prompt 与代码分离 。长 Prompt 不要硬编码在注解里,用
PromptTemplate+ 配置文件(甚至数据库)管理,便于运营迭代。 - 对 LLM 调用做幂等与重试。网络抖动、Token 限流是常态,用重试策略 + 退避算法,别让一次抖动毁掉整次用户请求。
- 可观测性必须跟上。至少接入 Micrometer,把每次调用的 token 数、延迟、失败率打出来;更进一步,可以接 OpenTelemetry 做链路追踪,这样一条 RAG 请求从问题进来到答案出去的每一段耗时都看得见。
- 做好内容审查与越狱防御 。在
SystemMessage里显式规定"不回答的话题",并在入口处对用户输入做一次过滤。 - 把"模型选型"做成配置。不同场景用不同模型:简单分类任务用小模型省钱,复杂问答用大模型保质量。LangChain4j 的接口抽象让这件事非常容易。
- RAG 的关键不是框架,而是切分策略。段落语义是否完整、块大小是否合理、是否做了重叠,往往比换一套向量库影响更大。
- 保护你的数据。企业内部文档不要随意发到外部模型;必要时用 Azure OpenAI、私有 Ollama、或本地化的通义千问 / DeepSeek。
七、写在最后
LangChain4j 的好,不在于它"实现了多么复杂的算法",而在于它给 Java 世界提供了一套恰到好处的抽象:
- 用
ChatLanguageModel抹平了所有大模型的差异; - 用 AI Services 把 Prompt 工程藏在注解背后;
- 用 ChatMemory、Tools、RAG 把高频场景标准化;
- 用 Spring Boot / Quarkus Starter 把集成成本降到几乎为零。
如果你是一个 Java 工程师,正在为如何优雅地把 AI 塞进业务系统而发愁,那我的建议是:别犹豫,花一个下午把它跑一遍。你会发现,原来让大模型走进企业系统,可以不那么痛苦。
真正重要的从来不是框架本身,而是它让你重新把注意力放回------你要解决什么业务问题。LangChain4j 做得最好的一件事,就是悄悄完成这件事。