
个人主页:
wengqidaifeng
✨ 永远在路上,永远向前走
个人专栏:
数据结构
C语言
嵌入式小白启动!
重要OJ算法题详解
蓝桥杯备战
文章目录
-
- 前言
- [1. 快速排序 (Quick Sort)](#1. 快速排序 (Quick Sort))
-
- [1.1 基本思想](#1.1 基本思想)
- [1.2 算法步骤](#1.2 算法步骤)
- [1.3 霍尔版本 (Hoare Partition Scheme)](#1.3 霍尔版本 (Hoare Partition Scheme))
-
- [1.3.1 单趟排序过程](#1.3.1 单趟排序过程)
- [1.3.2 相遇位置分析](#1.3.2 相遇位置分析)
- [1.3.3 递归实现](#1.3.3 递归实现)
- [1.3.4 递归深度分析](#1.3.4 递归深度分析)
- [1.4 快速排序的优化策略](#1.4 快速排序的优化策略)
-
- [1.4.1 问题:有序情况下的性能退化](#1.4.1 问题:有序情况下的性能退化)
- [1.4.2 优化一:三数取中法](#1.4.2 优化一:三数取中法)
- [1.4.3 优化二:小区间优化](#1.4.3 优化二:小区间优化)
- [1.5 挖坑法 (Pit Method)](#1.5 挖坑法 (Pit Method))
-
- [1.5.1 方法对比](#1.5.1 方法对比)
- [1.5.2 核心原理](#1.5.2 核心原理)
- [1.5.3 挖坑法优势](#1.5.3 挖坑法优势)
- [1.5.4 代码实现](#1.5.4 代码实现)
- [1.5.5 执行过程示例](#1.5.5 执行过程示例)
- [1.6 前后指针法 (Two Pointers Method)](#1.6 前后指针法 (Two Pointers Method))
-
- [1.6.1 基本思想](#1.6.1 基本思想)
- [1.6.2 算法步骤](#1.6.2 算法步骤)
- [1.6.3 代码实现](#1.6.3 代码实现)
- [1.6.4 三种划分方法对比](#1.6.4 三种划分方法对比)
- [1.7 快速排序的非递归实现](#1.7 快速排序的非递归实现)
-
- [1.7.1 为什么需要非递归实现](#1.7.1 为什么需要非递归实现)
- [1.7.2 用栈模拟递归](#1.7.2 用栈模拟递归)
- [1.7.3 栈操作注意事项](#1.7.3 栈操作注意事项)
- [2. 归并排序 (Merge Sort)](#2. 归并排序 (Merge Sort))
-
- [2.1 基本思想](#2.1 基本思想)
- [2.2 算法特点](#2.2 算法特点)
- [2.3 递归实现](#2.3 递归实现)
- [2.4 重要注意事项](#2.4 重要注意事项)
-
- [2.4.1 区间划分问题](#2.4.1 区间划分问题)
- [2.4.2 递归过程可视化](#2.4.2 递归过程可视化)
- [2.5 非递归实现](#2.5 非递归实现)
-
- [2.5.1 越界情况分析](#2.5.1 越界情况分析)
- [2.6 归并排序优缺点总结](#2.6 归并排序优缺点总结)
- [3. 快速排序 vs 归并排序 对比](#3. 快速排序 vs 归并排序 对比)
- [4. 总结与建议](#4. 总结与建议)
-
- [4.1 算法选择指南](#4.1 算法选择指南)
- [4.2 学习建议](#4.2 学习建议)
前言
在上篇中,我们学习了四种基础排序算法:直接插入排序、希尔排序、直接选择排序和冒泡排序。这些算法的时间复杂度普遍在 O(N²) 级别,虽然在小规模数据上表现尚可,但面对大规模数据时效率较低。
本篇将介绍两种更高效的排序算法------快速排序 和归并排序,它们的平均时间复杂度达到了 O(N log N),是目前应用最广泛的排序算法。
1. 快速排序 (Quick Sort)
1.1 基本思想
快速排序是由图灵奖得主 Tony Hoare 于 1960 年提出的一种基于分治策略的排序算法。
核心思想 :
对于一段序列,先选取一个元素作为基准值(key),通过一趟排序将待排序序列分割成两部分:
- 左子序列:所有元素都小于基准值
- 右子序列:所有元素都大于基准值
然后对左右子序列分别递归地进行快速排序,直到整个序列有序。
1.2 算法步骤
- 从数列中挑出一个元素,称为"基准"(pivot)
- 重新排序数列,所有比基准值小的元素摆放在基准前面,所有比基准值大的元素摆在基准后面
- 递归地把小于基准值元素的子数列和大于基准值元素的子数列排序
1.3 霍尔版本 (Hoare Partition Scheme)
这是快速排序最原始的划分方式,由算法发明者 Tony Hoare 提出。
1.3.1 单趟排序过程
设两个指针:
L(left):指向序列的第一个位置R(right):指向序列的最后一个位置
执行步骤:
- 将
L初始所指的值定为key R先向前移动,找到比key小的位置R找到后保持不动,L向后移动,找比key大的位置- 交换
R和L位置的数值 - 重复步骤 2-4,直到
R和L相遇 - 将相遇位置的值与
key的值交换
此时,key 左边的值都比 key 小,key 右边的值都比 key 大,key 已经排好了。
1.3.2 相遇位置分析
重要结论:左边做 key,右边先走,可以保证相遇位置的值比 key 小。
相遇场景分析:
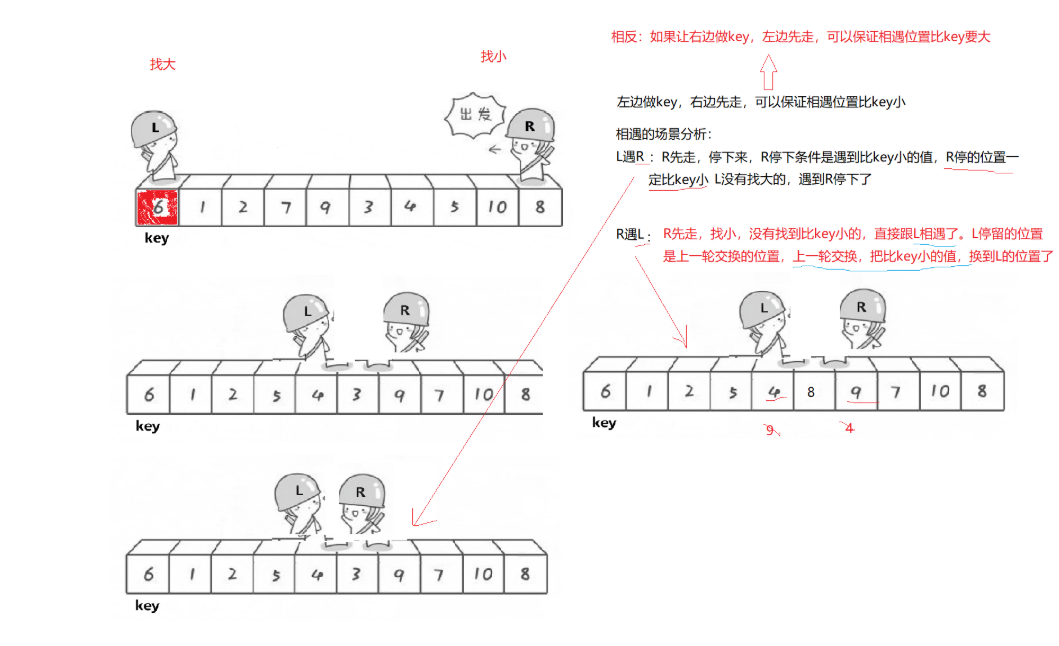
场景一:L 遇到 R
- R 先走,停下来
- R 停下来的条件是遇到比 key 小的值
- 因此 R 停的位置一定比 key 小
- L 没有找到比 key 大的,遇到 R 停下来
场景二:R 遇到 L
- R 先走,找比 key 小的值,没有找到
- 直接跟 L 相遇了
- L 停留的位置是上一轮交换的位置
- 上一轮交换把比 key 小的值换到了 L 的位置
注意:如果让右边的值作为 key,左边先走,可以保证相遇位置比 key 大。这对应的是降序排序的逻辑。
1.3.3 递归实现
cpp
void QuickSort(int* a, int left, int right) {
if (left >= right) {
return; // 区间只剩一个值或者不存在,递归结束
}
int keyi = left;
int begin = left, end = right;
while (begin < end) {
// 右边找小
while (begin < end && a[end] >= a[keyi]) {
--end;
}
// 左边找大
while (begin < end && a[begin] <= a[keyi]) {
++begin;
}
Swap(&a[begin], &a[end]);
}
Swap(&a[keyi], &a[begin]);
keyi = begin;
// 递归处理左右子区间
// [left, keyi-1] keyi [keyi+1, right]
QuickSort(a, left, keyi - 1);
QuickSort(a, keyi + 1, right);
}1.3.4 递归深度分析
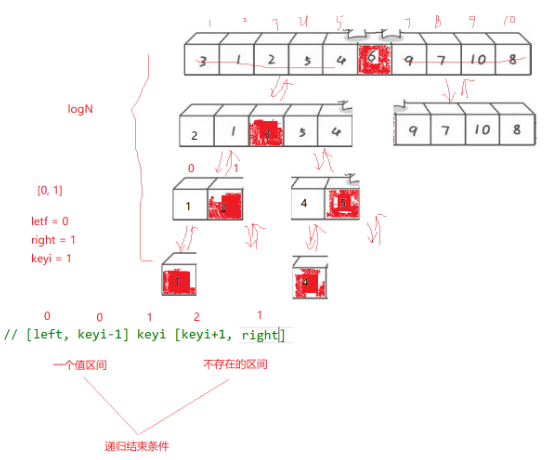
- 最好情况:每次划分均匀,递归树深度为 log N,每层处理 N 个元素,时间复杂度 O(N log N)
- 最坏情况:序列已经有序,每次只划分出一个元素,递归树深度为 N,时间复杂度退化为 O(N²)
1.4 快速排序的优化策略
1.4.1 问题:有序情况下的性能退化
当序列已经有序时,如果固定选择最左边(或最右边)作为 key,会发生:
- 每次划分极不均衡,一边为空,一边为 N-1 个元素
- 递归深度达到 N,可能导致栈溢出
- 时间复杂度退化为 O(N²)
1.4.2 优化一:三数取中法
通过选择合理的基准值来避免最坏情况。选取最左边、最右边和中间三个位置的元素,取其中值的大小处于中间的那个作为基准值。
cpp
// 三数取中:返回三个数中处于中间大小的那个数的索引
int GetMidi(int* a, int left, int right) {
int midi = (left + right) / 2;
// 比较 left, midi, right 三者的大小关系
if (a[left] < a[midi]) {
if (a[midi] < a[right]) {
return midi; // left < midi < right
} else if (a[left] < a[right]) {
return right; // left < right < midi
} else {
return left; // right < left < midi
}
} else { // a[left] > a[midi]
if (a[midi] > a[right]) {
return midi; // left > midi > right
} else if (a[left] < a[right]) {
return left; // midi < left < right
} else {
return right; // midi < right < left
}
}
}使用三数取中优化后的快速排序:
cpp
void QuickSort(int* a, int left, int right) {
if (left >= right) {
return;
}
// 三数取中,避免最坏情况
int midi = GetMidi(a, left, right);
Swap(&a[left], &a[midi]); // 将选中的基准换到最左边
int keyi = left;
int begin = left, end = right;
while (begin < end) {
while (begin < end && a[end] >= a[keyi]) --end;
while (begin < end && a[begin] <= a[keyi]) ++begin;
Swap(&a[begin], &a[end]);
}
Swap(&a[keyi], &a[begin]);
keyi = begin;
QuickSort(a, left, keyi - 1);
QuickSort(a, keyi + 1, right);
}1.4.3 优化二:小区间优化
当递归到区间较小时,快速排序的递归开销相对较大。此时可以改用直接插入排序,减少递归调用次数。
cpp
void QuickSort(int* a, int left, int right) {
if (left >= right) {
return;
}
// 小区间优化:区间长度小于10时,改用插入排序
if ((right - left + 1) < 10) {
InsertSort(a + left, right - left + 1);
return;
}
// 三数取中
int midi = GetMidi(a, left, right);
Swap(&a[left], &a[midi]);
int keyi = left;
int begin = left, end = right;
while (begin < end) {
while (begin < end && a[end] >= a[keyi]) --end;
while (begin < end && a[begin] <= a[keyi]) ++begin;
Swap(&a[begin], &a[end]);
}
Swap(&a[keyi], &a[begin]);
keyi = begin;
QuickSort(a, left, keyi - 1);
QuickSort(a, keyi + 1, right);
}面试技巧:手撕代码时,可以不写三数取中和小区间优化,但在讲解思路时提到这些优化点,能体现你对算法的深入理解。
1.5 挖坑法 (Pit Method)
1.5.1 方法对比
| 对比维度 | 霍尔方法 | 挖坑法 |
|---|---|---|
| 交换方式 | 左右指针找到目标后两两交换 | 用"坑位"概念,找到目标后填入坑位 |
| key 的处理 | 保持在原位,最后与相遇点交换 | 提前保存,形成初始坑位,最后填入相遇坑 |
| 理解难度 | 需要分析"为什么左边做 key 右边先走" | 不需要分析指针顺序,逻辑更直观 |
1.5.2 核心原理
- 将第一个数据保存在临时变量
key中,该位置形成坑位 (hole) R向前移动,找比key小的值- 找到后,将该值放入坑位,原位置成为新坑位
L向后移动,找比key大的值- 找到后,将该值放入坑位,原位置成为新坑位
- 重复步骤 2-5,直到
L和R相遇 - 将
key的值放入最后的坑位
1.5.3 挖坑法优势
- 物理过程直观:想象从序列中"挖走" key 形成坑,然后用符合条件的元素"填坑"
- 无需分析指针顺序:不用纠结左右指针的先后顺序问题
- 相遇即坑位:左右指针相遇的位置必然是当前坑位,直接填入 key 即可
1.5.4 代码实现
cpp
// 挖坑法单趟排序
int PartSort_Hole(int* a, int left, int right) {
// 三数取中
int midi = GetMidi(a, left, right);
Swap(&a[left], &a[midi]);
int key = a[left]; // 保存 key 值
int hole = left; // 初始坑位在 left 位置
int begin = left;
int end = right;
while (begin < end) {
// 右边找小,填入坑位
while (begin < end && a[end] >= key) {
--end;
}
a[hole] = a[end]; // 将小的值填入坑位
hole = end; // end 位置成为新坑
// 左边找大,填入坑位
while (begin < end && a[begin] <= key) {
++begin;
}
a[hole] = a[begin]; // 将大的值填入坑位
hole = begin; // begin 位置成为新坑
}
a[hole] = key; // 将 key 填入最终的坑位
return hole; // 返回 key 的最终位置
}
void QuickSort_Hole(int* a, int left, int right) {
if (left >= right) return;
int keyi = PartSort_Hole(a, left, right);
QuickSort_Hole(a, left, keyi - 1);
QuickSort_Hole(a, keyi + 1, right);
}1.5.5 执行过程示例
以数组 [6, 1, 2, 7, 9, 3, 4, 5, 10, 8] 为例:
| 步骤 | 操作 | 数组状态(_ 表示坑位) | 坑位位置 |
|---|---|---|---|
| 初始 | key=6 | [_, 1, 2, 7, 9, 3, 4, 5, 10, 8] |
0 |
| 右找小(5) | 填入坑0 | [5, 1, 2, 7, 9, 3, 4, _, 10, 8] |
7 |
| 左找大(7) | 填入坑7 | [5, 1, 2, _, 9, 3, 4, 7, 10, 8] |
3 |
| 右找小(4) | 填入坑3 | [5, 1, 2, 4, 9, 3, _, 7, 10, 8] |
6 |
| 左找大(9) | 填入坑6 | [5, 1, 2, 4, _, 3, 9, 7, 10, 8] |
4 |
| 右找小(3) | 填入坑4 | [5, 1, 2, 4, 3, _, 9, 7, 10, 8] |
5 |
| 相遇 | key填入坑5 | [5, 1, 2, 4, 3, 6, 9, 7, 10, 8] |
- |
结果:6 左边的元素 [5,1,2,4,3] 都小于 6,右边的元素 [9,7,10,8] 都大于 6。
1.6 前后指针法 (Two Pointers Method)
1.6.1 基本思想
使用两个指针 prev 和 cur:
prev:指向已处理区间中最后一个小于 key 的元素cur:扫描指针,寻找小于 key 的元素
1.6.2 算法步骤
prev指向序列开头,cur指向prev的后一个位置cur向后遍历:- 如果
a[cur] < key,prev先后移一位,然后交换a[prev]和a[cur] - 如果
a[cur] >= key,cur继续后移
- 如果
- 遍历结束后,交换
a[prev]和key
1.6.3 代码实现
cpp
// 前后指针法单趟排序
int PartSort_TwoPointers(int* a, int left, int right) {
// 三数取中
int midi = GetMidi(a, left, right);
Swap(&a[left], &a[midi]);
int keyi = left;
int prev = left;
int cur = prev + 1;
while (cur <= right) {
// cur 找到小于 key 的值,且 prev 和 cur 不指向同一位置时才交换
if (a[cur] < a[keyi] && ++prev != cur) {
Swap(&a[prev], &a[cur]);
}
cur++;
}
Swap(&a[prev], &a[keyi]);
return prev;
}
void QuickSort_TwoPointers(int* a, int left, int right) {
if (left >= right) return;
int keyi = PartSort_TwoPointers(a, left, right);
QuickSort_TwoPointers(a, left, keyi - 1);
QuickSort_TwoPointers(a, keyi + 1, right);
}1.6.4 三种划分方法对比
| 方法 | 复杂度 | 代码量 | 理解难度 | 适用场景 |
|---|---|---|---|---|
| 霍尔法 | 相同 | 中等 | 较高 | 原始经典实现 |
| 挖坑法 | 相同 | 中等 | 较低 | 易于理解,教学常用 |
| 前后指针法 | 相同 | 简洁 | 中等 | 代码优雅,面试推荐 |
1.7 快速排序的非递归实现
1.7.1 为什么需要非递归实现
递归实现的快速排序在极端情况下可能导致栈溢出(深度达到 N)。使用非递归实现可以:
- 避免栈溢出风险
- 更好地控制内存使用
- 在某些环境(如嵌入式系统)中递归受限
1.7.2 用栈模拟递归
利用栈这种数据结构来存储待排序的区间,模拟递归的过程:
- 将初始区间
[left, right]入栈 - 循环从栈中取出区间进行单趟排序
- 将划分后的左右子区间分别入栈
- 重复步骤 2-3,直到栈为空
cpp
#include "Stack.h"
// 用栈实现非递归快速排序
void QuickSortNonR(int* a, int left, int right) {
ST st;
STInit(&st);
// 初始区间入栈(注意:先入右边界,后入左边界)
STPush(&st, right);
STPush(&st, left);
// 循环每走一次相当于一次递归
while (!STEmpty(&st)) {
int begin = STTop(&st);
STPop(&st);
int end = STTop(&st);
STPop(&st);
// 单趟排序(这里使用前后指针法)
int keyi = PartSort_TwoPointers(a, begin, end);
// 处理划分出的子区间
// [begin, keyi-1] keyi [keyi+1, end]
// 右子区间入栈
if (keyi + 1 < end) {
STPush(&st, end);
STPush(&st, keyi + 1);
}
// 左子区间入栈
if (begin < keyi - 1) {
STPush(&st, keyi - 1);
STPush(&st, begin);
}
}
STDestroy(&st);
}1.7.3 栈操作注意事项
- 入栈顺序:由于栈是后进先出(LIFO),如果希望先处理左区间,应该先入右区间再入左区间
- 区间有效性:入栈前需要判断区间长度是否大于 1,避免无效操作
2. 归并排序 (Merge Sort)
2.1 基本思想
归并排序是采用分治策略的经典排序算法,由冯·诺依曼于 1945 年提出。
核心思想:
- 分割:将数组从中间分成两部分
- 递归排序:对分割后的两部分分别递归排序
- 合并:将两个已排序的子数组合并成一个有序数组
2.2 算法特点
- 时间复杂度:O(N log N),且非常稳定,不受输入数据影响
- 空间复杂度:O(N),需要额外的辅助数组
- 稳定性:稳定
- 适用场景:大量数据的排序,特别是外部排序的基础
2.3 递归实现
cpp
// 时间复杂度:O(N*logN)
// 空间复杂度:O(N)
void _MergeSort(int* a, int* tmp, int begin, int end) {
if (begin >= end) {
return; // 区间只剩一个值或不存在,递归结束
}
int mid = (begin + end) / 2;
// 递归分割并排序
// 注意:必须是 [begin, mid] 和 [mid+1, end] 的划分方式
_MergeSort(a, tmp, begin, mid);
_MergeSort(a, tmp, mid + 1, end);
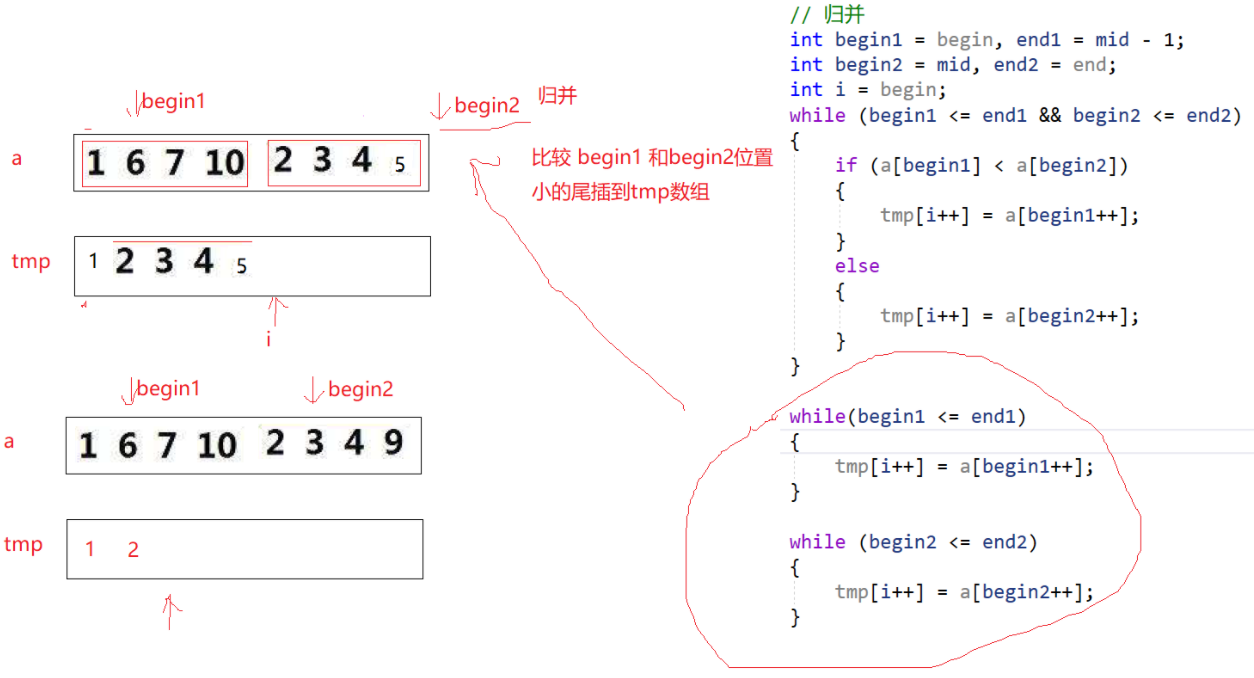
// 归并两个有序子数组
int begin1 = begin, end1 = mid;
int begin2 = mid + 1, end2 = end;
int i = begin;
// 比较两个子数组,将较小的元素放入 tmp
while (begin1 <= end1 && begin2 <= end2) {
if (a[begin1] < a[begin2]) {
tmp[i++] = a[begin1++];
} else {
tmp[i++] = a[begin2++];
}
}
// 将剩余元素直接拷贝
while (begin1 <= end1) {
tmp[i++] = a[begin1++];
}
while (begin2 <= end2) {
tmp[i++] = a[begin2++];
}
// 将归并结果拷贝回原数组
memcpy(a + begin, tmp + begin, (end - begin + 1) * sizeof(int));
}
void MergeSort(int* a, int n) {
// 预先分配辅助空间,避免频繁 malloc
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL) {
perror("malloc fail");
return;
}
_MergeSort(a, tmp, 0, n - 1);
free(tmp);
tmp = NULL;
}2.4 重要注意事项
2.4.1 区间划分问题
错误划分 :[begin, mid-1] 和 [mid, end]
- 这种划分方式在某些情况下会导致死循环
- 例如当
begin = 0, end = 1时,mid = 0,[0, -1]和[0, 1],右区间与原区间相同,陷入无限递归
正确划分 :[begin, mid] 和 [mid+1, end]
- 确保每次递归区间长度严格减小
2.4.2 递归过程可视化

2.5 非递归实现
归并排序的非递归实现通常采用自底向上的方式,使用循环控制每次归并的子数组大小。
cpp
// 归并排序非递归实现(自底向上)
void MergeSortNonR(int* a, int n) {
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL) {
perror("malloc fail");
return;
}
int gap = 1; // gap 表示每组归并数据的个数
while (gap < n) {
// 每轮处理所有长度为 gap 的子数组对
for (int i = 0; i < n; i += 2 * gap) {
// 计算两个子数组的边界
int begin1 = i, end1 = i + gap - 1;
int begin2 = i + gap, end2 = i + 2 * gap - 1;
// 越界处理(关键!)
// 第二组完全不存在,不需要归并
if (begin2 >= n) {
break;
}
// 第二组部分存在,修正结束位置
if (end2 >= n) {
end2 = n - 1;
}
int j = i;
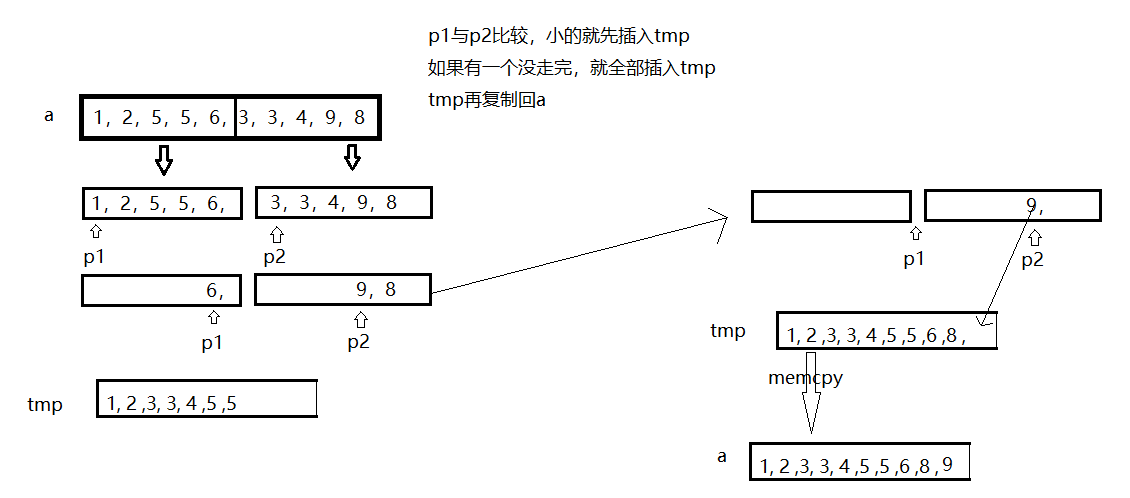
// 归并两个有序子数组
while (begin1 <= end1 && begin2 <= end2) {
if (a[begin1] < a[begin2]) {
tmp[j++] = a[begin1++];
} else {
tmp[j++] = a[begin2++];
}
}
while (begin1 <= end1) {
tmp[j++] = a[begin1++];
}
while (begin2 <= end2) {
tmp[j++] = a[begin2++];
}
// 归并一部分,拷贝一部分
memcpy(a + i, tmp + i, (end2 - i + 1) * sizeof(int));
}
gap *= 2;
}
free(tmp);
tmp = NULL;
}2.5.1 越界情况分析
非递归实现中,由于数组长度 n 不一定是 2 的幂次,边界计算可能出现越界:
| 越界情况 | 条件 | 处理方式 |
|---|---|---|
| 第二组完全越界 | begin2 >= n |
直接 break,不需要归并 |
| 第二组部分越界 | end2 >= n |
修正 end2 = n - 1,继续归并 |
| 第一组部分越界 | end1 >= n |
已包含在上一种情况中 |
2.6 归并排序优缺点总结
优点:
- 稳定的 O(N log N) 时间复杂度,不受输入数据影响
- 稳定排序
- 是外部排序的基础
缺点:
- 需要 O(N) 的额外空间
- 常数因子比快速排序大,实际速度可能稍慢
3. 快速排序 vs 归并排序 对比
| 对比维度 | 快速排序 | 归并排序 |
|---|---|---|
| 平均时间复杂度 | O(N log N) | O(N log N) |
| 最坏时间复杂度 | O(N²)(可优化避免) | O(N log N) |
| 空间复杂度 | O(log N)(递归栈) | O(N)(辅助数组) |
| 稳定性 | 不稳定 | 稳定 |
| 适用场景 | 内存排序,追求平均速度 | 外部排序,需要稳定性 |
| 缓存友好性 | 较好(原地操作) | 较差(需要辅助空间) |
4. 总结与建议
4.1 算法选择指南
| 场景 | 推荐算法 | 原因 |
|---|---|---|
| 小数据量(<50) | 直接插入排序 | 简单高效,常数因子小 |
| 中等数据量(50~10000) | 希尔排序 | 实现简单,性能良好 |
| 大数据量,内存充足 | 快速排序 | 平均性能最优 |
| 需要稳定性 | 归并排序 | 稳定的 O(N log N) |
| 链表排序 | 归并排序 | 不需要随机访问 |
| 外部排序 | 归并排序 | 天然适合分组合并 |
4.2 学习建议
- 理解思想优先:先理解算法的核心思想,再关注实现细节
- 动手实践:每种算法至少手写 3 遍
- 对比记忆:将相似算法放在一起对比学习
- 关注边界条件:排序算法的 Bug 往往出现在边界处理上
(下篇完。至此,常见排序算法的学习已全部完成。)