上篇文章:【AI大模型入门(二)】提示词工程进阶
目录
[1.AI 接入方式选型:云端 vs 本地](#1.AI 接入方式选型:云端 vs 本地 "1.AI 接入方式选型:云端 vs 本地")
[2.API 接入](#2.API 接入 "2.API 接入")
导语: 作为开发者,光会在网页端和 AI 聊天是不够的。我们需要让 AI 融入到我们的业务流、脚本和后端服务中。本文将带你实战大模型接入的三种核心方式:API 远程调用、开源模型本地部署和SDK与官方客户端库。
1.AI 接入方式选型:云端 vs 本地
我们要将大模型能力接入自己的应用,通常面临两个选择:
-
API 接入(闭源/商业大模型):
-
优势: 速度快、无需关心硬件(不用买显卡)、模型智商通常最高(如 GPT-5、Claude 3.7)。
-
劣势: 数据需出境/上云(有隐私合规风险),按 Token 消耗计费。
-
-
本地部署(开源大模型):
-
优势: 绝对的数据隐私,断网可用,一次性硬件投资后无限次使用。
-
劣势: 需要高性能 GPU,运维成本高,模型能力受限于本地算力(通常使用蒸馏版本如 8B、14B 级别模型)。
-
2.API 接入
这是目前最主流,最便捷的接⼊⽅式,尤其适用于快速开发、集成到现有应⽤以及不想管理硬件资源的场景。
通过 HTTP 请求(通常是 RESTful API)直接调用模型提供商部署在云端的模型服务。代表厂商:OpenAI (GPT),Anthropic (Claude),Google (Gemini),百度文心⼀⾔,阿⾥通义千问,智谱 AI等。
典型流程就是:
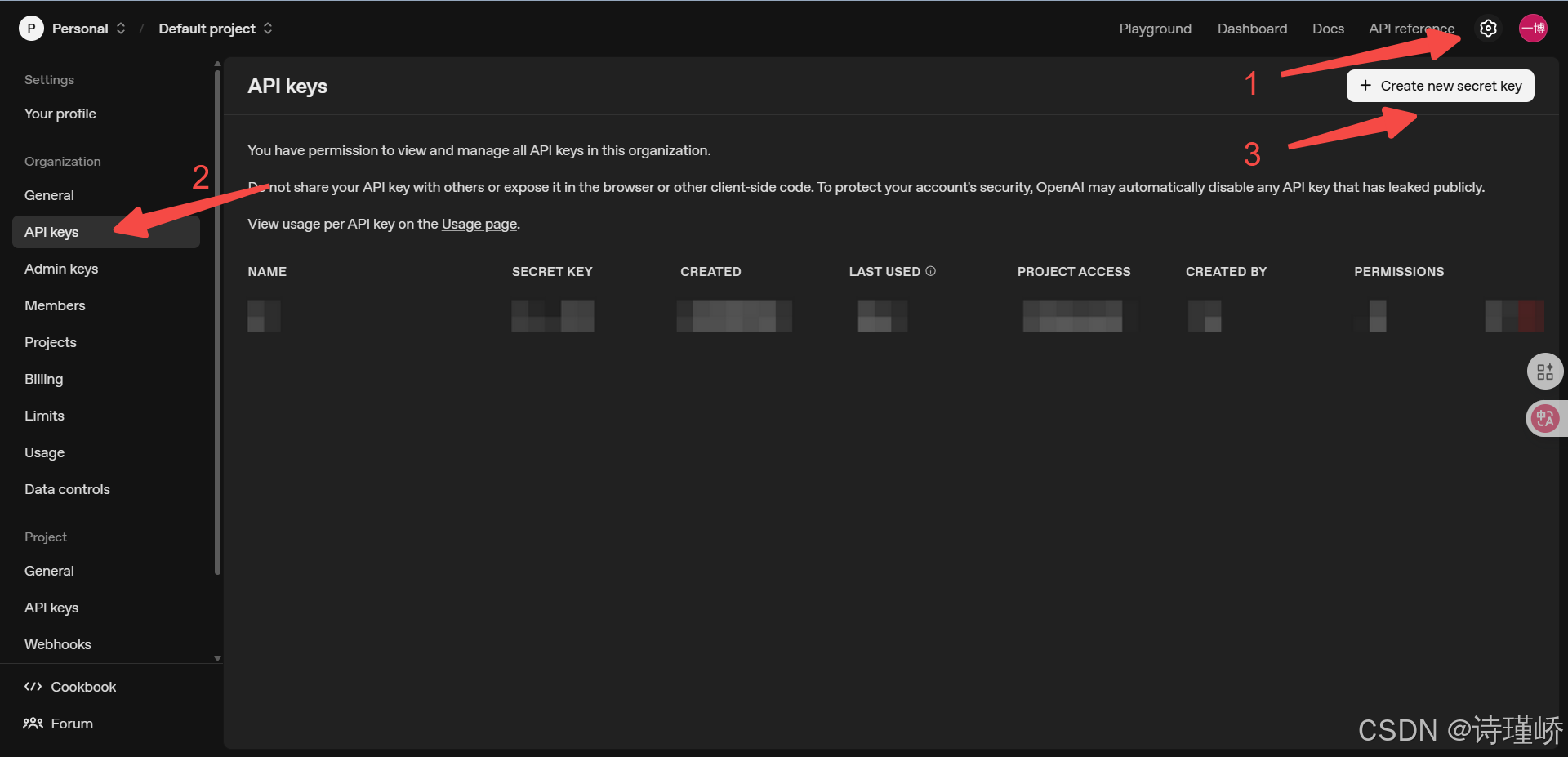
- 注册账号并获取API Key:在模型提供商的平台上注册,获得身份验证的密钥。
- 查阅API文档:了解请求的端点、参数(如模型名称,提示词,温度,最大生成长度等)和返回的数据格式。
- 构建HTTP请求:在你的代码中,使用HTTP客户端库(如Python的request)构建一个包含API Key(通常在Header中)和请求体(JSON格式,包含你的提示和参数)的请求。
- 发送请求并处理响应:将请求发送到提供商指定的API地址,然后解析返回的JSON数据,提取生成的文本。
以OpenAI为例,官网:https://platform.openai.com/home
接入流程文档:https://developers.openai.com/api/docs/quickstart
调用:
curl "https://api.openai.com/v1/responses" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "gpt-5",
"input": "Write a one-sentence bedtime story about a unicorn."
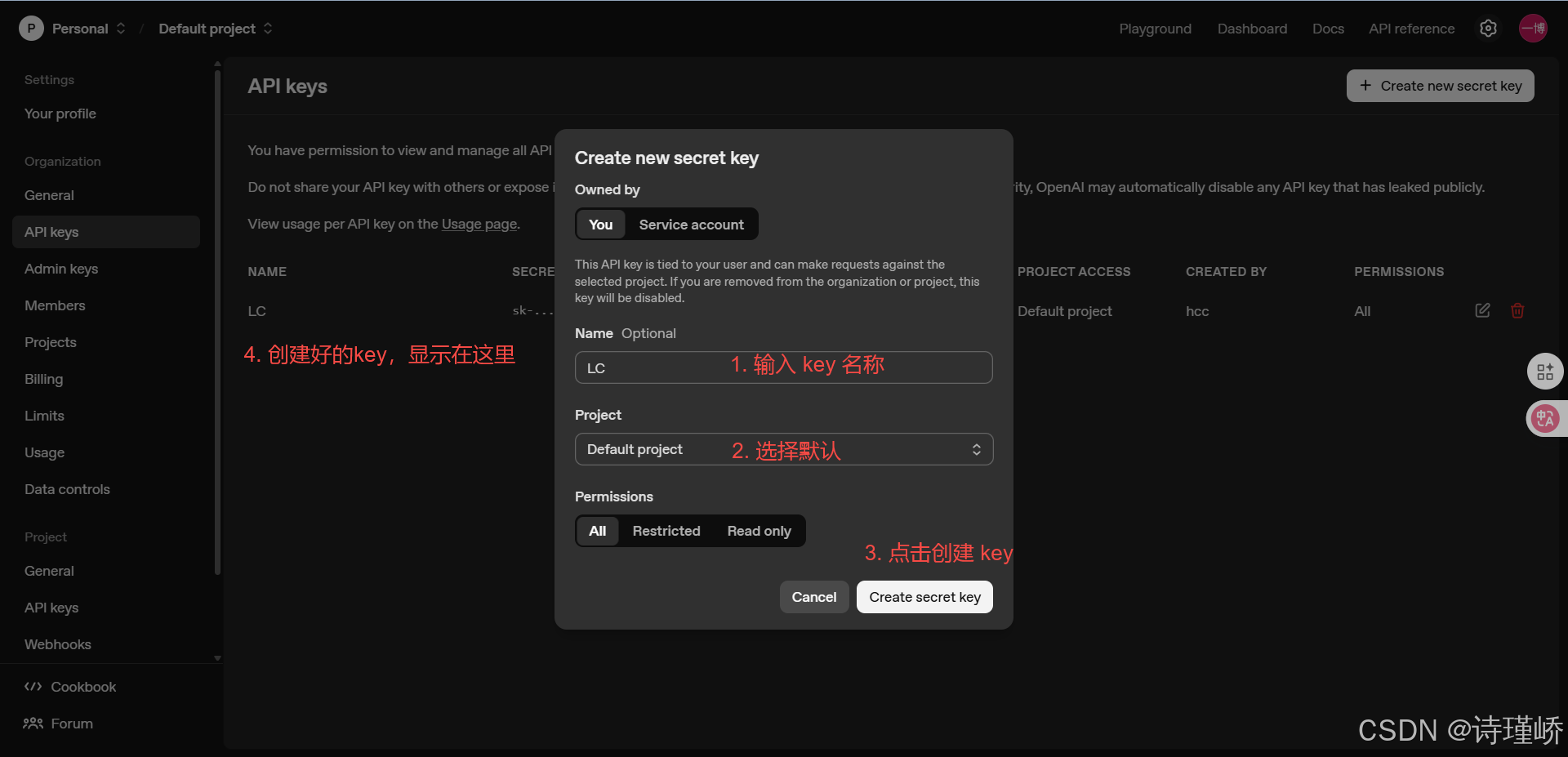
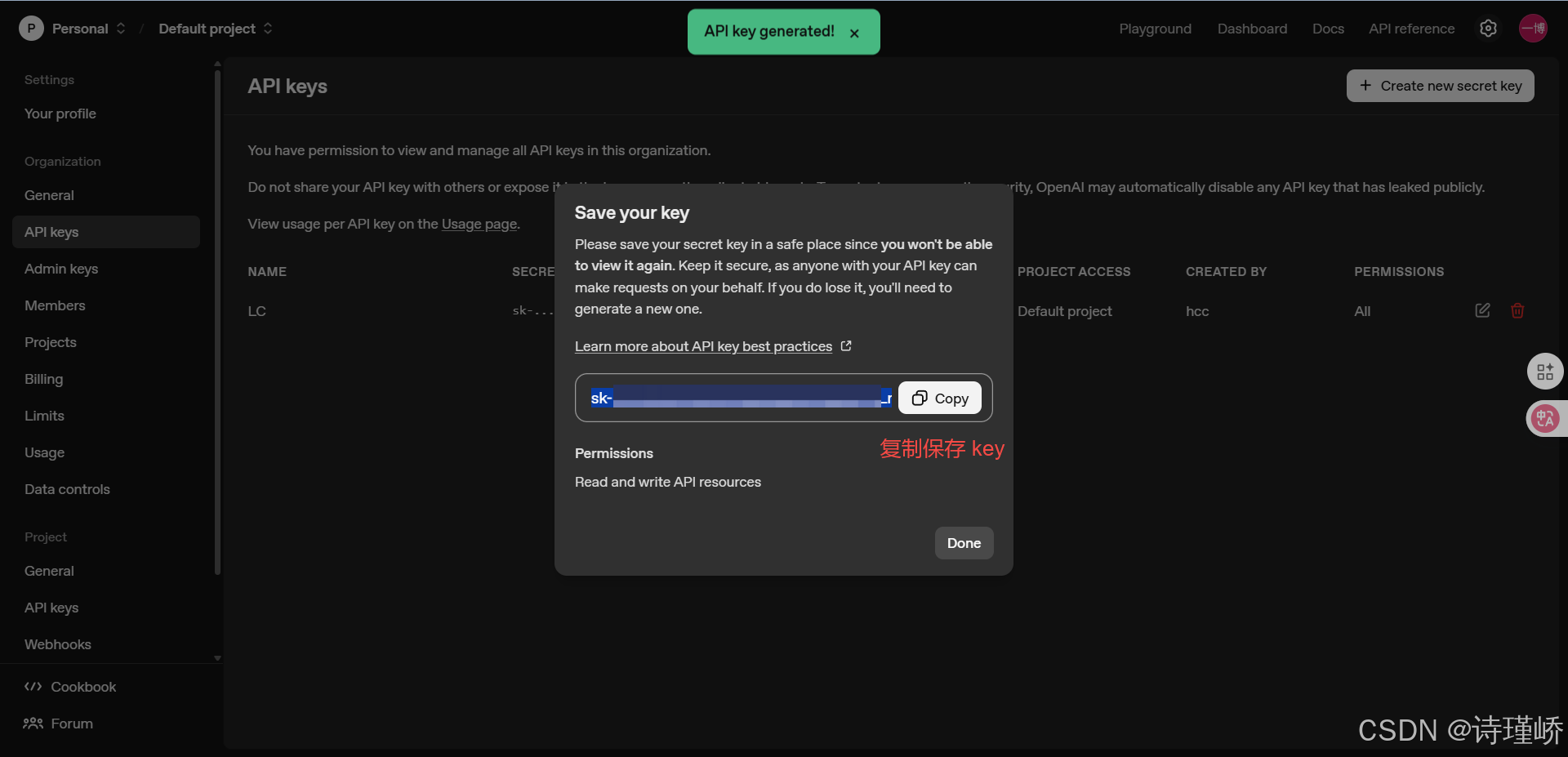
}'或者使用HTTP客户端,此处以Apifox(Apifox官网)
为例:
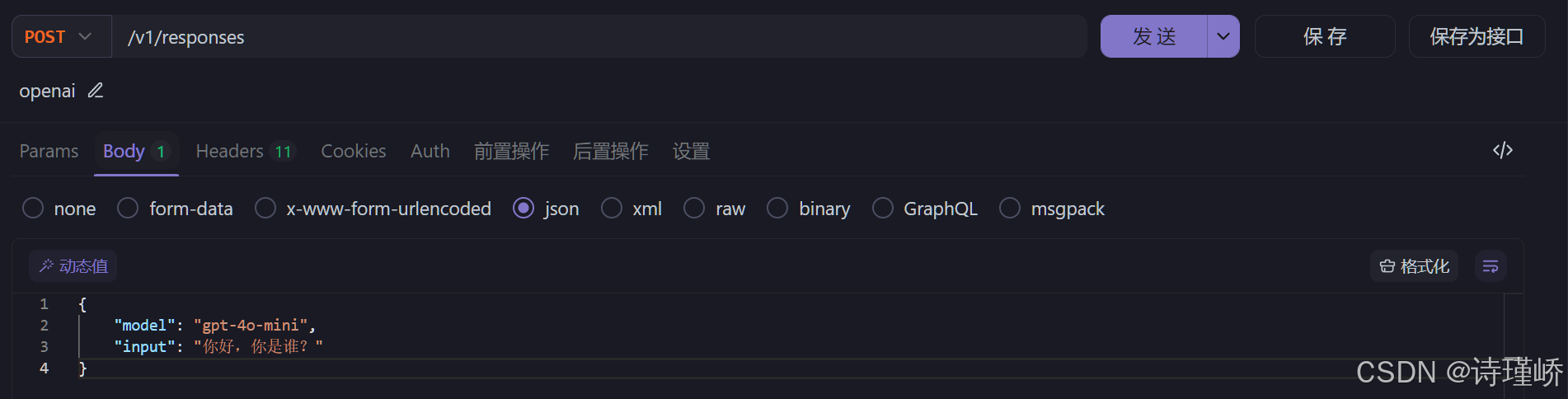
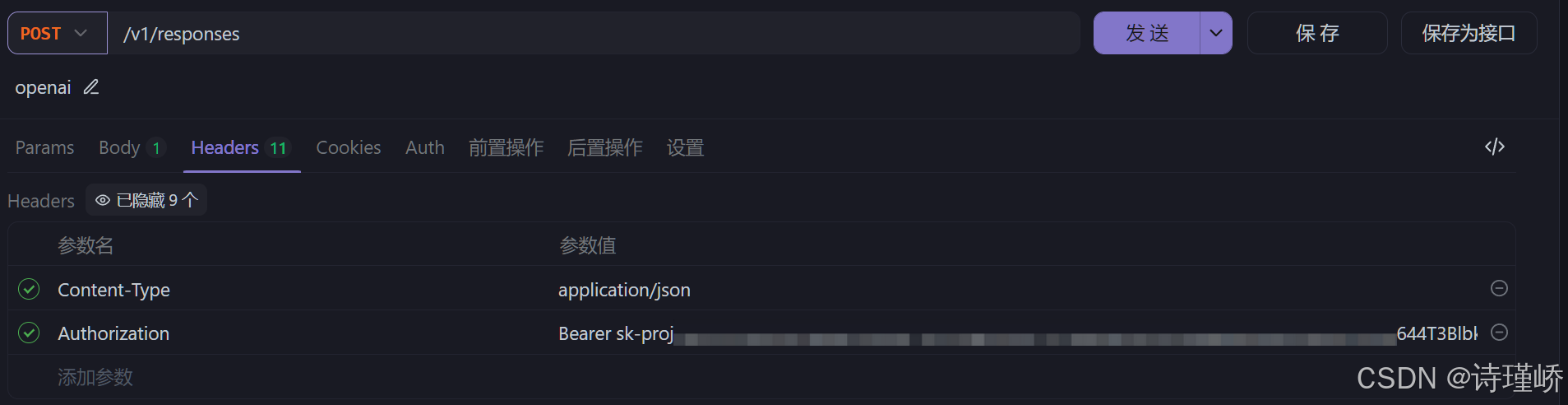
API参考:https://developers.openai.com/api/reference/overview
3.本地私有化部署
大模型本地部署,这种方式就是将开源的大型语言模型(如:qwen,kimi,Gemma等)部署在自己的硬件环境(本地服务器或私有云)中。核心概念就是,将下载模型的文件(权重或配置文件),使用专门的推理框架在本地服务器或GPU上加载并运行模型,然后通过类似API的方式进行交互。
如果你公司的数据极其敏感,不允许上传给第三方接口,那么本地部署开源模型是唯一选择。
流程是:
- 获取模型:从 Hugging Face(国外)、魔搭社区(国内)等平台下载开源模型的权重
- 准备环境:配置具有⾜够显存(如 NVIDIA GPU)的服务器,安装必要的驱动和推理框架
- 选择推理框架:使用专为⽣产环境设计的框架来部署模型,例如
vLLM:特别注重⾼吞吐量的推理服务,性能极佳。
TGI:Hugging Face 推出的推理框架,功能全⾯。
Ollama:⾮常用户友好,可以⼀键拉取和运⾏模型,适合快速入门和本地开发。
LM Studio:提供图形化界⾯,让本地运⾏模型像使⽤软件⼀样简单。
- 启动服务并调⽤:框架会启动⼀个本地 API 服务器(如 http://localhost:8000 ),你可以像调⽤云端 API ⼀样向这个本地地址发送请求。
Ollama 是目前最好用的本地 LLM 运行与管理工具。
3.1下载并安装Ollama
安装 Ollama: 访问 Ollama 官网 下载对应系统(Windows/Mac/Linux)的安装包并傻瓜式安装。
验证: 安装完成后,Ollama默认会启动,访问:http://127.0.0.1:11434/
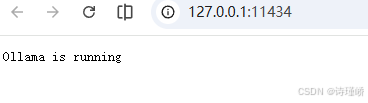
或者使用cmd访问:

3.2一键拉取并运行模型
Ollama可以管理和部署模型,我们使用之前要先拉取模型。
修改模型存储路径
1.配置系统环境变量:
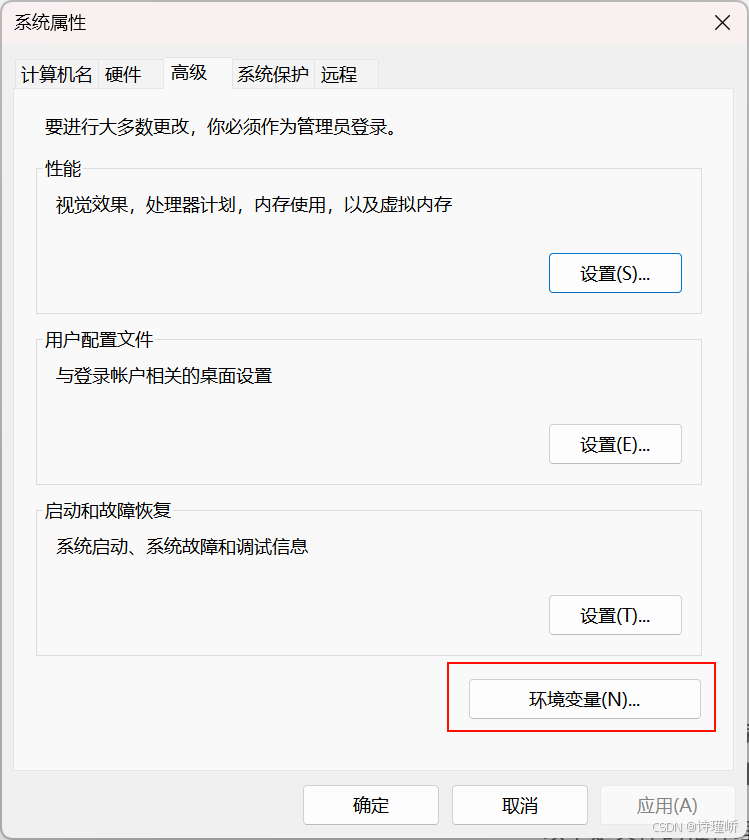
变量名: OLLAMA_MODELS
变量值: ${⾃定义路径}2.通过Ollama界面来进行设置
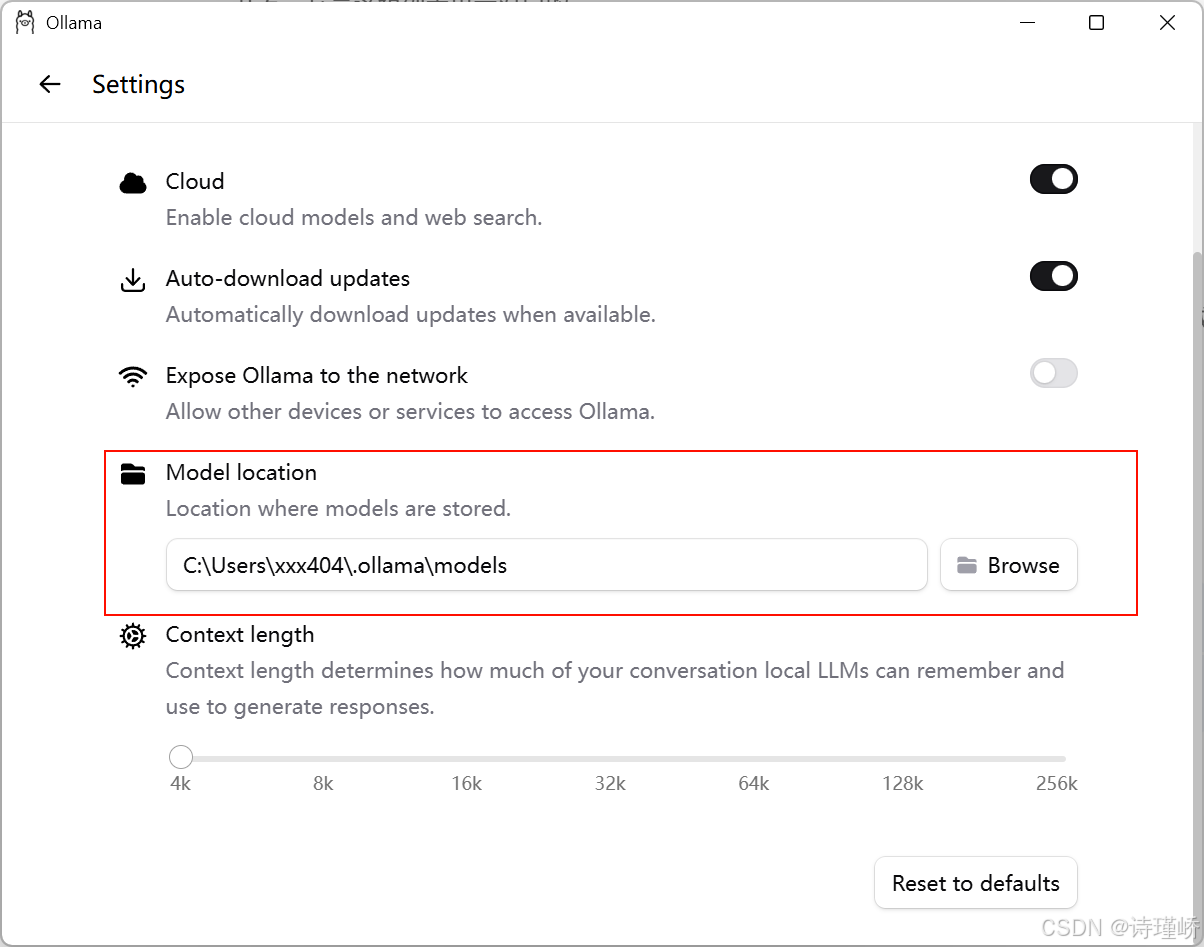
设置完成后,重启Ollama。
拉取模型
查找模型:https://ollama.com/search
以拉取表现惊艳的qwen3.6:35b为例。
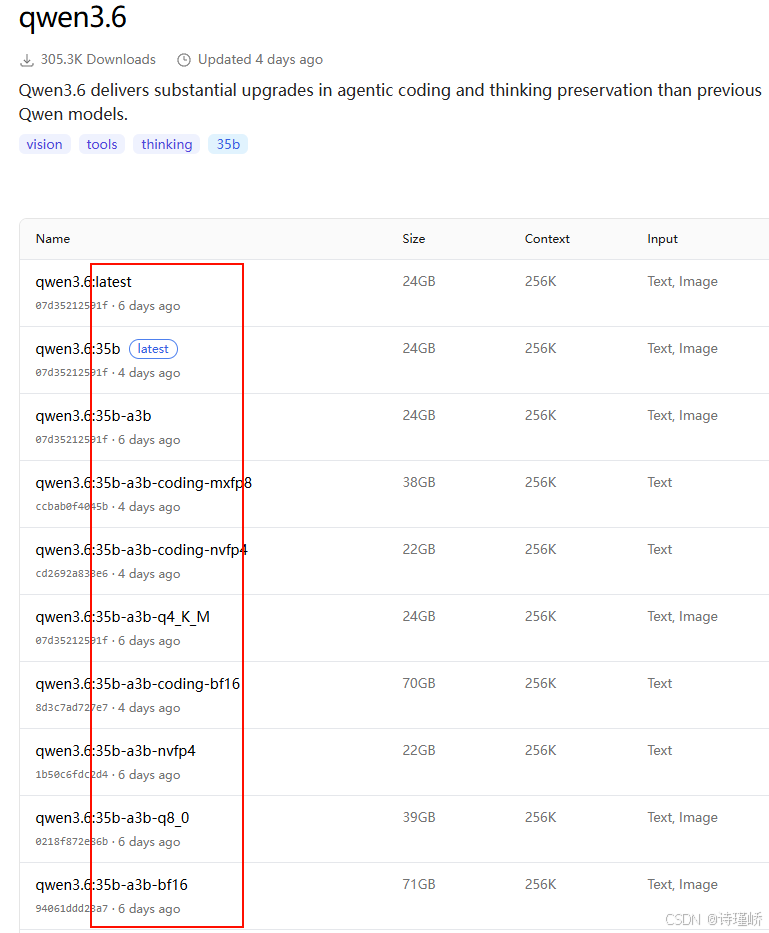
这后面的数组是参数大小,参数越大,能力越强。
-
35b: 350 亿参数。
-
q4_K_M: 代表使用了 4-bit 的中等(Medium)量化技术。就像把一张 4K 的高清原图稍微压缩了一下,肉眼看不出画质损失,但文件体积直接缩小了三分之二。
打开命令行,输入:
ollama run qwen3.6:35bOllama 会自动下载权重并加载到内存/显存中。下载完成后,直接在终端就能和它对话了!
API 调用本地模型: Ollama 默认会在本地 11434 端口提供兼容 API。你的代码可以无缝切换为本地模型:
curl http://localhost:11434/api/chat \
-d '{
"model": "qwen3.6",
"messages": [{"role": "user", "content": "Hello!"}]
}'4.SDK接入
这并非⼀种独立的接⼊⽅式,而是对第⼀种 API 接⼊的封装和简化。模型提供商通常会发布官方编程语⾔SDK,为我们封装好了底层的 HTTP 请求细节,提供⼀个更符合编程习惯的、语⾔特定的函数库。
目前业界大多遵循了 OpenAI 的接口规范格式(包括 DeepSeek、Qwen 很多接口也完全兼容)使用官方 Python SDK 调用极其简单。
1. 安装依赖:
pip install openai2. 在PyCharm中创建一个.py文件
from openai import OpenAI
# 很多国内大模型也兼容这套 API,只需替换 base_url 和 api_key
client = OpenAI(
api_key="your-api-key",
base_url="[https://api.deepseek.com/v1](https://api.deepseek.com/v1)" # 假设使用 DeepSeek 的 API
)
response = client.chat.completions.create(
model="deepseek-reasoner", # 调用带思考过程的推理模型
messages=[
{"role": "system", "content": "你是一个资深的 Python 架构师。"},
{"role": "user", "content": "请解释一下什么是协程?"}
]
)
# 打印回复
print(response.choices[0].message.content)仅仅十几行代码,你就可以把顶级大模型的智力接入到你自己的系统、微信机器人或者数据处理脚本中。
5.问题与思考
对于以上三种接入方式,我们该如何选择?
**看数据敏感性:**如果数据极其敏感,必须留在内部,本地部署是唯⼀选择。
**看技术实力和资源:**如果团队没有强⼤的 MLops(机器学习运维)能⼒,也没有预算购买和维护
GPU 服务器,云端 API 是更实际的选择。
**看成本和规模:**如果应用规模很大,长期来看,本地部署的固定成本可能低于持续的 API 调⽤费
⽤。反之,⼩规模应⽤ API 更划算。
**看定制需求:**如果只是使⽤模型的通⽤能⼒,云端 API ⾜够。如果需要用自己的数据微调模型,则 需要选择⽀持微调的 API 或直接本地部署。
实际上,只要是原生LLM,⽆论怎么接⼊都有限制。
- 输⼊⻓度限制:所有 LLM 都有固定的输⼊⻓度(如4K、8K、128K、400K Token)。我们⽆法将⼀本⼏百⻚的 PDF 或整个公司知识库直接塞给模型
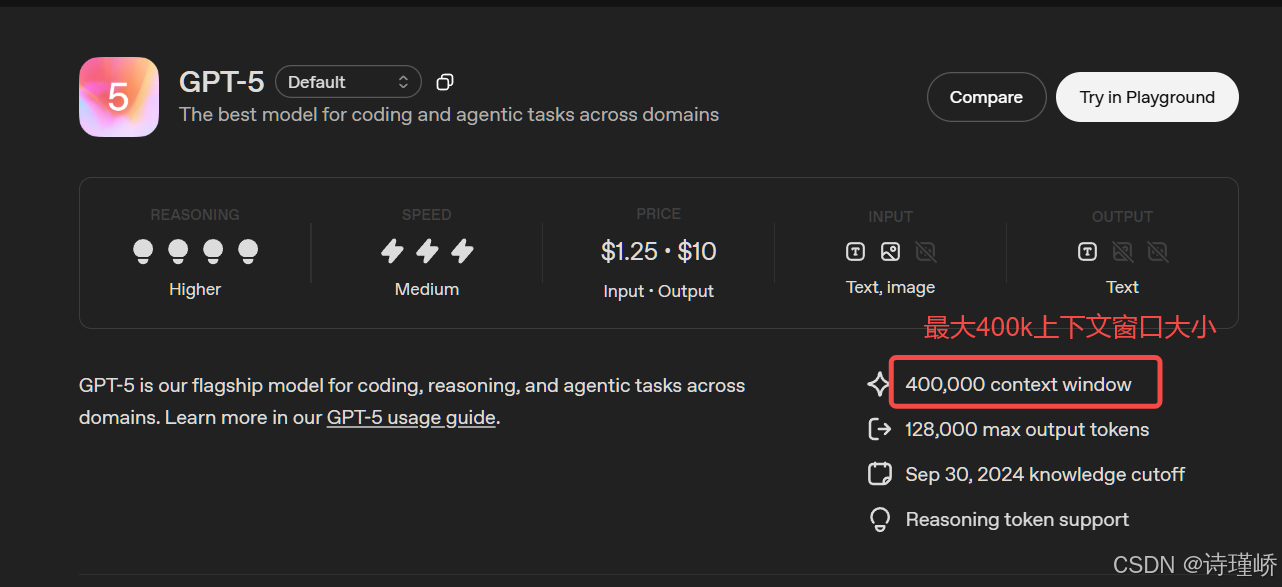
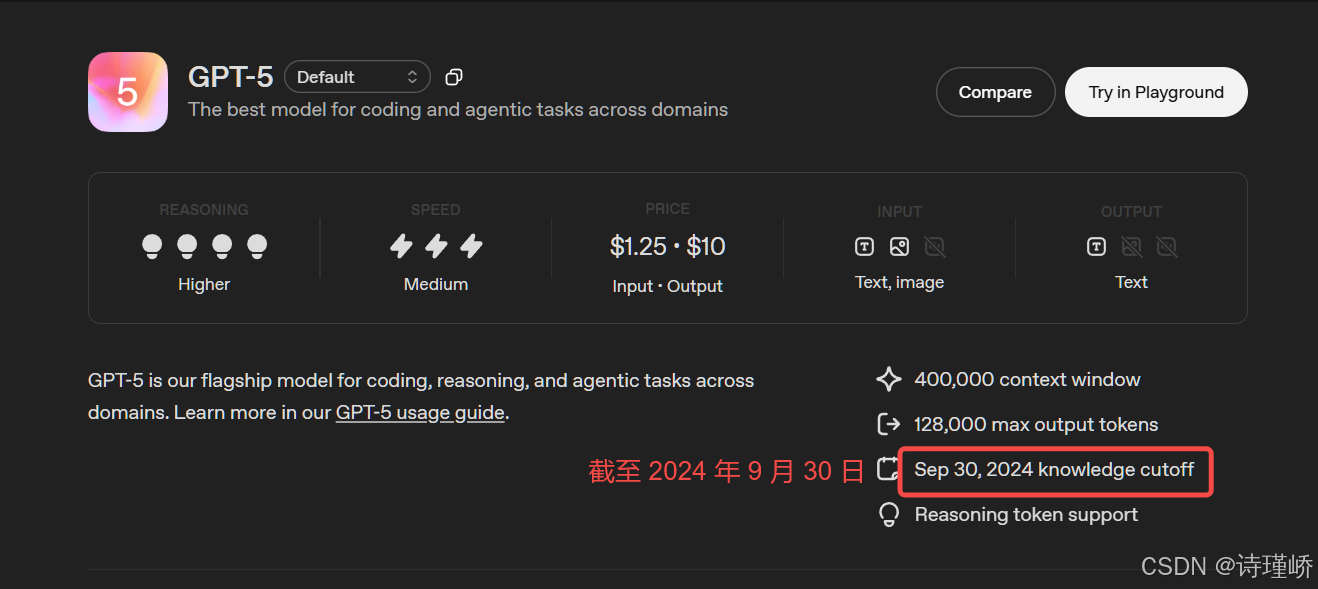
- 缺乏私有知识:模型的训练数据有截⽌日期,且不包含我们的私⼈数据(如公司内部⽂档、个⼈笔记等)。让它基于这些知识回答问题,⾮常困难。
- 复杂任务处理能⼒弱:原⽣ API 本质是⼀个"⼀问⼀答"的接口。对于需要多个步骤的复杂任务(如"分析这份财报,总结要点,并⽣成⼀份PPT⼤纲"),我们需要⾃⼰编写复杂的逻辑来拆解任务、多次调⽤ API 并管理中间状态。
- 输出格式不可控:虽然可以通过提⽰词要求模型输出 JSON 或特定格式,但它仍可能产⽣格式错误或不合规的内容,需要我们⾃⼰编写后处理代码来校验和清洗。
像 LangChain 这样的框架,正是为了系统性地解决这些问题⽽诞⽣的。