前言
前文我们是将Java 桌面端技术(Swing)结合火山引擎(豆包大模型) ,开发了一款属于自己的"智能美颜相机"与"AI P图智能体" 。但为了体验沉浸感和真实感,今天我们借助Vibe Coding,将其改为一个全栈项目,并部署在本地的Web应用。
项目结构
AI-Image-Pro/
├── frontend/ # 前端静态资源
│ ├── index.html # 页面骨架:三栏式布局
│ ├── style.css # 样式:毛玻璃特效、CSS Grid 响应式布局
│ └── app.js # 前端核心逻辑:摄像头控制、DOM 操作、网络请求
├── backend/ # Node.js 后端服务
│ ├── server.js # 核心服务逻辑:图片上传接口、AI 生成接口
│ ├── package.json # 依赖管理
│ └── package-lock.json
└── 相册/ # (自动生成) 用于存储用户上传和 AI 生成的图片技术栈
-
前端:HTML5, CSS3 (拟态玻璃风格 UI), Vanilla JavaScript (原生 JS)
-
后端:Node.js, Express (Web 框架)
-
核心中间件/库 :
multer(处理多部分表单数据,用于图片上传),axios(处理 HTTP 请求),cors(跨域处理) -
AI 接口 :火山引擎 Ark API (
doubao-seedream-5-0-260128模型)
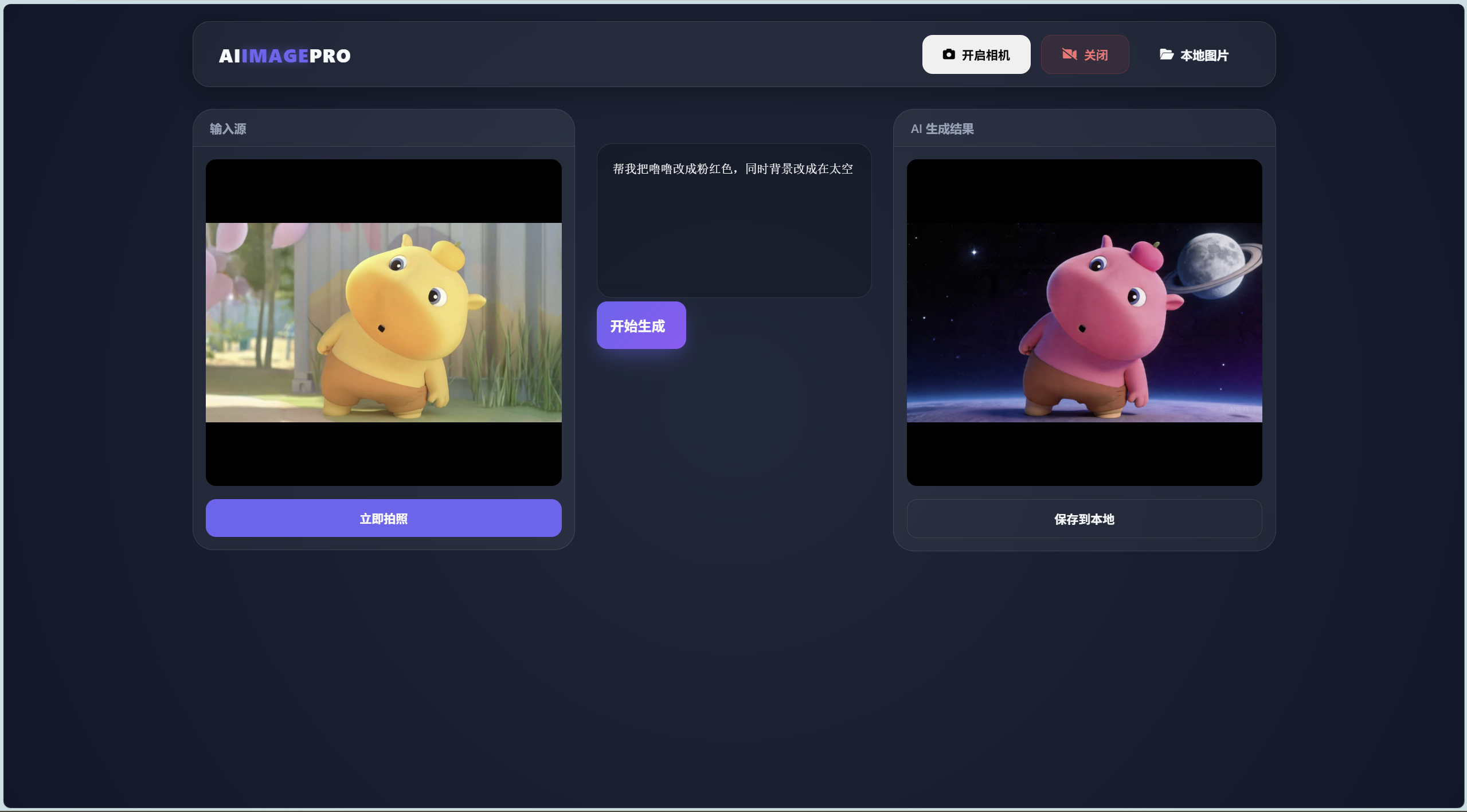
项目展示
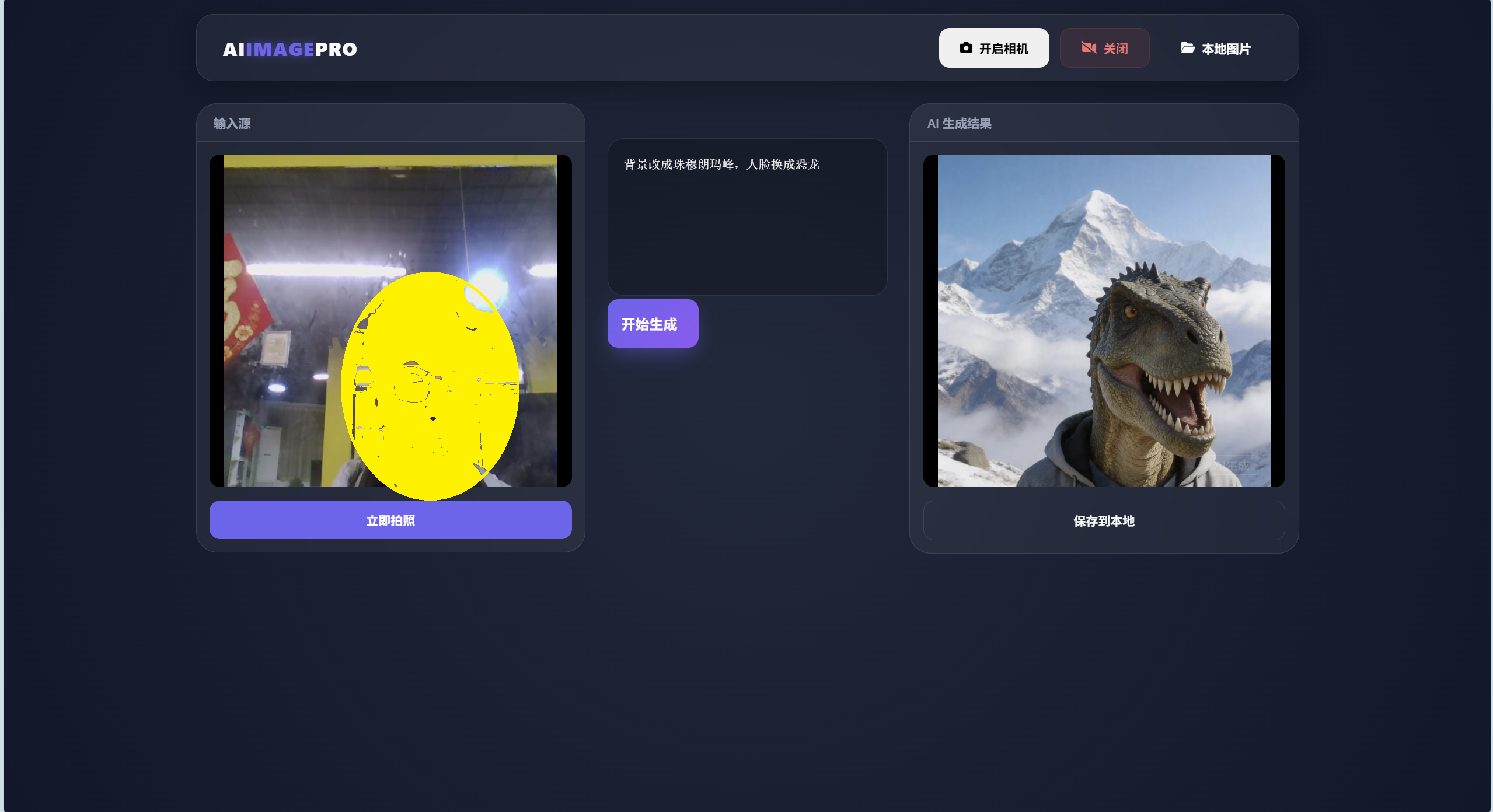
核心代码解析
第一部分:前端核心逻辑剖析 (app.js)
前端除了基础的 DOM 获取和 CSS 样式切换,最核心的技术难点在于如何将实时视频流转化为可上传的图片文件。
1. 唤起摄像头与实时预览
思路 :利用现代浏览器的 navigator.mediaDevices API 获取硬件设备的音视频流,并将其绑定到 HTML 的 <video> 标签上进行实时渲染。
javascript
// 唤起摄像头的核心代码
btnOpenCam.addEventListener('click', async () => {
try {
// 请求视频权限,获取媒体流
const stream = await navigator.mediaDevices.getUserMedia({ video: true });
currentStream = stream;
// 将流媒体数据赋值给 video 标签进行预览
videoPreview.srcObject = stream;
showLeftContent('video'); // UI 切换视图
} catch (err) {
alert("无法访问摄像头:" + err.message);
}
});为什么这么做?
- 传统的 Web 交互多依赖文件上传(
<input type="file">),而引入getUserMedia可以极大地提升用户操作的连贯性,实现"即拍即生成"。
2. 视频帧抓取与数据流转换
思路 :视频流是连续的动态数据,无法直接作为图片发送给后端。我们需要一个"定格"机制。浏览器中处理像素级图像唯一且最强大的工具就是 <canvas>。我们利用 Canvas 捕获当前的 Video 帧,再将其序列化为二进制大对象(Blob),最后通过 FormData 模拟表单上传。
javascript
btnTakePhoto.addEventListener('click', () => {
// 1. 获取 Canvas 上下文
const ctx = captureCanvas.getContext('2d');
// 2. 将 video 当前播放的这一帧,绘制到 canvas 画布上
// 这里的 captureCanvas.width/height 决定了抓取图片的分辨率
ctx.drawImage(videoPreview, 0, 0, captureCanvas.width, captureCanvas.height);
// 3. 将 Canvas 中的像素数据转换为 Blob (二进制文件对象)
captureCanvas.toBlob(async (blob) => {
// 4. 封装为 FormData 准备发送
const formData = new FormData();
// 伪装成一个名为 'camera_capture.png' 的文件
formData.append('image', blob, 'camera_capture.png');
try {
// 5. 发送 Fetch 请求到后端 /api/upload 接口
const res = await fetch('/api/upload', {
method: 'POST',
body: formData
});
const data = await res.json();
// ... 成功后保存后端返回的 fileName,用于后续 AI 生成
selectedImageFileName = data.fileName;
} catch (err) {
console.error(err);
}
}, 'image/png'); // 指定导出格式为 PNG
});为什么这么设计?
- 这是一套标准的
Video -> Canvas -> Blob -> FormData的 WebRTC 截图处理链路。使用 Blob 而不是 Base64 (toDataURL) 发送,是因为 Blob 的数据体积更小,传输效率更高,且更符合后端 Multer 处理multipart/form-data的规范。技术细节和实现思路学习详见:实时屏幕截图技术:基于 WebRTC 和 Canvas 的创新实践 - 知乎
https://zhuanlan.zhihu.com/p/29762353805
第二部分:后端核心逻辑剖析 (server.js)
后端的职责是接管前端发来的文件,并与外部的大模型 API 进行通信。
1. 本地文件持久化(Multer 中间件)
思路 :前端发来的文件流需要被正确地解析并保存在服务器的特定目录中。Express 本身不支持多部分表单解析,因此引入 multer。
javascript
const multer = require('multer');
const path = require('path');
const fs = require('fs');
const IMAGE_DIR = "D:\\代码库\\AIimgpro\\相册"; // 统一存储目录
// 自定义存储策略
const storage = multer.diskStorage({
destination: function (req, file, cb) {
cb(null, IMAGE_DIR); // 告诉 multer 文件存放到哪里
},
filename: function (req, file, cb) {
// 为什么自定义文件名?防止高并发下文件名冲突导致覆写
// 采用精准到秒的时间戳命名机制
const ext = file.mimetype.split('/')[1] || 'png';
cb(null, `${getFormattedTime()}.${ext}`);
}
});
const upload = multer({ storage: storage });
// 暴露上传接口
app.post('/api/upload', upload.single('image'), (req, res) => {
res.json({ success: true, fileName: req.file.filename, url: `/images/${req.file.filename}` });
});功能亮点 :通过
getFormattedTime()结合 MIME 类型动态生成文件名(如2026-4-21-18-30.png),确保了文件系统的整洁,并方便后期排查功能异常。
2. 代理大模型请求与图像拉取(核心功能)
思路 :前端发起"生成"指令时,仅传递提示词 (Prompt) 和本地文件名。后端需要读取该文件,按 API 要求转码,发起带身份验证的 HTTP 请求,最后将云端生成的图片下载到本地。
javascript
app.post('/api/generate', async (req, res) => {
const { prompt, fileName } = req.body;
const filePath = path.join(IMAGE_DIR, fileName);
try {
// 步骤 A:读取本地文件并转换为 Base64
// 为什么转 Base64?因为火山引擎的图像生成 API 通常要求通过 JSON payload 传递图像数据
const fileBuffer = fs.readFileSync(filePath);
const base64Image = fileBuffer.toString('base64');
const dataUri = `data:image/png;base64,${base64Image}`;
// 步骤 B:构建请求体并调用 AI 接口
const requestBody = {
model: "doubao-seedream-5-0-260128", // 指定大模型版本
prompt: prompt,
image: dataUri // 传入原图作为参考(图生图核心)
};
const response = await axios.post(API_URL, requestBody, {
headers: {
'Content-Type': 'application/json',
'Authorization': `Bearer ${API_KEY}` // 密钥在后端保管,绝对安全
},
timeout: 120000 // AI 绘图较慢,必须显式放宽超时限制至 120 秒
});
const imageUrl = response.data.data?.[0]?.url; // 提取云端图片 URL
// 步骤 C:主动下载云端图片到本地服务器
// 为什么不直接把 imageUrl 返回给前端?
// 1. 云端 URL 可能有时效性(比如 1 小时后过期)。
// 2. 防盗链机制可能导致前端直接加载跨域图片失败。
const imgResponse = await axios.get(imageUrl, { responseType: 'arraybuffer' });
const generatedFileName = `${getFormattedTime()}-generated.png`;
const generatedFilePath = path.join(IMAGE_DIR, generatedFileName);
// 将二进制数据写入本地磁盘
fs.writeFileSync(generatedFilePath, imgResponse.data);
// 步骤 D:返回本地静态资源路径给前端
res.json({ success: true, url: `/images/${generatedFileName}` });
} catch (error) {
// 严谨的错误拦截与冒泡
res.status(500).json({ error: error.message });
}
});基础功能补充:UI 设计与状态管理
在保证核心逻辑严谨的同时,项目也兼顾了前端的交互体验(UI 设计)。
-
视觉反馈 :生成图片是一个耗时操作(通常需要 5-15 秒)。在
app.js中,点击生成按钮后会立即执行btnGenerate.disabled = true; loadingOverlay.style.display = 'flex';。这不仅给用户提供了明确的"等待中"视觉反馈(Loading 遮罩),还有效防止了用户不耐烦导致的重复点击(防抖控制),避免了后端的并发灾难。 -
CSS 布局 :
style.css中大量使用了 CSS 变量(:root)统一色调,并配合backdrop-filter: blur(10px);和background: rgba(255, 255, 255, 0.05);实现毛玻璃效果,使得整个控制面板充满科技感。
项目涉及知识点
1. 前端交互层 (原生 JS + HTML5 + CSS3)
-
WebRTC 与媒体设备调用:
-
掌握
navigator.mediaDevices.getUserMedia()的使用,获取用户摄像头的视频流。 -
理解如何将
MediaStream对象绑定到<video>标签的srcObject属性进行实时预览。
-
-
Canvas 图像处理技术(核心):
-
利用
canvas.getContext('2d').drawImage()截取视频流的当前帧(实现"拍照"功能)。 -
格式转换 :掌握
HTMLCanvasElement.toBlob()方法,将 Canvas 像素数据异步转换为 Blob(二进制大对象)文件,为网络传输做准备。
-
-
现代网络请求与表单构建:
-
使用
FormDataAPI 构建多部分表单数据(Multipart form-data),实现无刷新的文件伪装上传。 -
熟练使用
Fetch API进行异步网络请求,并处理 JSON 响应。
-
-
UI/UX 与异步状态管理:
-
防抖与状态锁定 :在发起 AI 生成请求时,通过禁用按钮(
disabled = true)和展示 Loading 遮罩,防止用户重复提交导致服务器雪崩。 -
CSS3 毛玻璃效果 :利用
backdrop-filter: blur()与半透明rgba背景色实现现代感十足的 Glassmorphism UI。
-
2. 后端服务层 (Node.js + Express)
-
文件上传与中间件机制:
-
multer中间件的工作原理。 -
掌握
multer.diskStorage的自定义配置,包括动态目录路径(destination)和防冲突的文件重命名策略(filename结合时间戳与 MIME 类型)。
-
-
文件系统 (fs) 与路径计算 (path):
-
利用
fs.existsSync和fs.mkdirSync实现服务器启动时的目录自动初始化。 -
使用
fs.readFileSync读取物理文件,以及fs.writeFileSync将网络拉取的二进制流落盘。
-
-
Buffer 与 Base64 编解码:
- 理解 AI 大模型 API 的要求,将本地图片文件流(Buffer)转化为
Base64字符串,并拼接为标准的Data URI格式(data:image/png;base64,...)。
- 理解 AI 大模型 API 的要求,将本地图片文件流(Buffer)转化为
-
HTTP 代理与外部 API 交互:
-
使用
axios发起携带鉴权(Bearer Token)的 POST 请求。 -
流式响应处理 :设置
responseType: 'arraybuffer',通过 Axios 将云端图片直接作为二进制缓冲池下载到本地,突破防盗链和跨域限制。
-
架构思考:为什么选择 Node.js 作为后端?
面对 Java (Spring Boot)、Python (Django/FastAPI)、Go 等众多后端语言,为什么这个"AI 图像代理"项目,Node.js 是最完美的初创与实战选择?原因有以下几点:
1. 极其契合"I/O 密集型"场景 (核心优势)
这个项目的后端绝大部分时间在干两件事:读写文件 和等待 AI 接口响应 。 AI 绘图是一个非常耗时的操作(通常需要几十秒甚至几分钟,代码中我们甚至把超时设置到了 120000ms)。
-
如果是传统的同步多线程模型(如早期的 Java/PHP),一个请求就会阻塞一个线程,并发一高,服务器内存和线程池直接被撑爆。
-
Node.js 天生采用"单线程 + 事件循环 (Event Loop) + 异步非阻塞 I/O"机制 。当它把请求发给火山引擎 API 后,当前执行栈会立刻被释放去处理其他用户的图片上传请求。等到 AI 图片生成完毕,底层系统会通过事件回调唤醒 Node.js 继续执行下载逻辑。这使得 Node.js 在处理这种高延迟的网络请求代理时,具有极高的并发吞吐量。
2. BFF 架构的最佳实践
在这个项目中,后端并不处理复杂的业务逻辑、分布式事务或沉重的数据清洗,它的本质是一个 BFF(服务于前端的后端)。 前端开发者使用同一门语言(JavaScript)就能快速搭建起一个中间层,用来:
-
隐藏敏感信息 :把
API_KEY藏在服务端,防止前端暴露。 -
跨域转发:突破浏览器的 CORS 限制,由服务器代发请求。
-
Node.js + Express 只需几十行代码就能跑起这个 BFF 层,没有繁杂的类定义和配置文件,敏捷高效。
3. 数据格式的无缝衔接 (JSON 原住民)
AI 大模型的 API 交互高度依赖 JSON 格式的 Payload。 在 Java 或 Go 中,你需要定义一堆实体类(Entity/Struct)来进行序列化和反序列化。而在 Node.js 中,JavaScript 对象本身就可以无缝转为 JSON (JSON.stringify / JSON.parse),大幅降低了代码量和心智负担。
可优化方向
错误处理边界 :摄像头调用时,如果用户设备没有摄像头或者拒绝了权限,代码虽然有
catch并alert,但在 UI 层最好能有一个更友好的降级展示。文件清理机制 :由于每次生成都会在本地保留两张图片(原图和生成图),随着时间推移,硬盘空间会被挤占。建议增加定时清理脚本(如利用
cron定期清理 7 天前的文件)。
总结
这个项目对我来说是一次很新的尝试,使用了HTML5 摄像头 API 与 Canvas 的联动,同时配置部署了Node.js 处理文件系统,并将API接口成功调用。虽然使用了Vibe Coding,但其中涉及的过程与处理思想给了我很大启发,同时也有了查缺补漏的方向。
希望这篇实战笔记能对你有所启发。如果你对代码细节有疑问,或者在配置时遇到问题,欢迎在评论区一起讨论!
最后,我已将项目完整代码上传至GitHub: fanxing222/ai-image-web![]() https://github.com/fanxing222/ai-image-web 包含前后端源码等部署文档,欢迎Star交流。
https://github.com/fanxing222/ai-image-web 包含前后端源码等部署文档,欢迎Star交流。