动机
claude code网上解读狠多,思路方向都比较全,AI时代 代码和信息密度都太大了,但是决策力、判断力、创新力、深度思考是我们更需要关注的,这里不讲千篇一律,让我们深挖细节,还是那句话想法和思路终归是纸上谈兵,AI 帮你coding也不一定是事半功倍,因为大模型经常会把简单代码复杂化,所以你需要深度掌握每一个细节去完全驾驭,以此核心开讲本系列差异化解读,简单来说你看懂了长篇大论的概念理解,也有一个ai coding你真的能复刻一个完整的等价Claude code 设计的agent harness嘛?以此为动机笔者在清明假期,对着CC用vibe coidng方式+harness 理念重构了一套,但是在此过程中,我发现了一些很有趣的事情------高级缓存协议。
再结合近期codex\cursor等软件也提到过这个,我才发现其实好的Agent 软件一定是模型端、推理端具备深度绑定的。
商业角度来说这种技术是非常有价值的,就是大家经常看到的"高级缓存命中"。CODEX、cursor都在不同程度实现了这个协议,但是目前还是CC、codex是能从源码和博客推敲出他们实现度是最好的,本章从基础到进阶 ,从前缀命中到高级缓存协议进行快速讲解。
文章目录
- 动机
- 一、前缀缓存命中是什么?
-
- [这个机制需要你的模型推理测,支持kv cc 的缓存命中,目前如VLLM开源框架都默认支持。](#这个机制需要你的模型推理测,支持kv cc 的缓存命中,目前如VLLM开源框架都默认支持。)
- [二、为什么要做Kvcache 命中?](#二、为什么要做Kvcache 命中?)
-
- [接下来,自然就是在实际的复杂agent环境中,你的上下文前缀跟每一个Agent设计是强相关的,也就是很难保证你的前缀一定稳定,因为涉及到工具、压缩 等各种各种Runtime的变更信息来影响,agent越复杂这种情况越常见,因此在claude code源码泄露之前,关于这类型问题基本上网上并没有完整系统化的解决方案。](#接下来,自然就是在实际的复杂agent环境中,你的上下文前缀跟每一个Agent设计是强相关的,也就是很难保证你的前缀一定稳定,因为涉及到工具、压缩 等各种各种Runtime的变更信息来影响,agent越复杂这种情况越常见,因此在claude code源码泄露之前,关于这类型问题基本上网上并没有完整系统化的解决方案。)
- 三、为什么前缀缓存并不稳定
- [四 cluade code 前缀稳定性解决方案(缓存协议)](#四 cluade code 前缀稳定性解决方案(缓存协议))
-
- [4.1 基础前提:明确"前缀"的定义与拆分](#4.1 基础前提:明确“前缀”的定义与拆分)
- [4.2 核心准备:将输入标准化,避免"语义同、字节异"](#4.2 核心准备:将输入标准化,避免“语义同、字节异”)
- 三、关键设计:定义合理的缓存键(前缀身份标识)
- 四、优化手段:将请求分块,提升缓存复用率
- 五、规则定义:明确缓存策略(时效、范围、淘汰机制)
- 六、如何解决工具信息变化引起的前缀缓存失效
-
-
-
- [example------有的工程师会有上下文膨胀的管理意识,因此他们会选择动态加载工具,这样你的提示词schema就不会全都堆在system promt里,来达到瘦身的目的,但是:](#example——有的工程师会有上下文膨胀的管理意识,因此他们会选择动态加载工具,这样你的提示词schema就不会全都堆在system promt里,来达到瘦身的目的,但是:)
-
-
- [七、工具结果长输出处理(重点 下篇单讲 )](#七、工具结果长输出处理(重点 下篇单讲 ))
- 八、高级原则:增量更新不重写旧正文
- 九、分支场景:确保多分支共享统一前缀表面
- 十、观测体系:缓存不是"开了就完了",需可观测
- 十一、故障诊断:不止关注未命中,还要做断裂归因
- 十二、流程顺序
- 十三、完成度判断标准
- [重点------推理模型服务端到底怎么处理 cache_control 语义并确定边界?](#重点——推理模型服务端到底怎么处理 cache_control 语义并确定边界?)
-
- [服务端Cache Control边界确定流程](#服务端Cache Control边界确定流程)
- 关键设计原则
在了解提示缓存协议之前,我们需要知道提示缓存命中的基本用处。
一、前缀缓存命中是什么?
前缀缓存的核心目的,是通过缓存请求中"重复度高、变化慢"的部分,降低系统开销、提升响应速度,其通用设计可梳理为清晰的工程链
可视化理解:
第一次请求(全量处理)
████████████████████████████████████████ 100% 耗时
↑ ↑
前缀(辛苦计算) 尾巴(辛苦计算)
第二次请求(缓存命中)
░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░ 0% 耗时 (直接复用)
████ 5% 耗时 (只算尾巴)
↑ ↑
前缀(瞬间跳过) 尾巴(新增计算)
这个机制需要你的模型推理测,支持kv cc 的缓存命中,目前如VLLM开源框架都默认支持。
二、为什么要做Kvcache 命中?
节省TOKEN和提高推理速度和首Token延迟,比如大家用Opus-4.6这种就按Token计费的话 每次多轮交互都会消耗大量TOKEN,如果利用前缀缓存,那么推理端就会缓存上一次的TOKEN block的KV值复用,所以你会看到有高级缓存命中就是这个功能。它的实现需要客户端和模型推理端联合支持,比如VLLM具备前缀缓存 就可以用空间换时间。
接下来,自然就是在实际的复杂agent环境中,你的上下文前缀跟每一个Agent设计是强相关的,也就是很难保证你的前缀一定稳定,因为涉及到工具、压缩 等各种各种Runtime的变更信息来影响,agent越复杂这种情况越常见,因此在claude code源码泄露之前,关于这类型问题基本上网上并没有完整系统化的解决方案。
三、为什么前缀缓存并不稳定
system prompt 文本变了,包括任何附加的 system injection,这个最近几年做过agent的都能体会,为了做上下文优化,我们可能会进行动态编排,但是多轮下前缀就不稳定了。
userContext 或 systemContext 变了,比如重算了 git 状态、CLAUDE.md、日期,虽然这里源码已经尽量用 memoize 把它们冻结了,比如有人会把time.time()写进system promot 直接崩盘。
工具列表或工具 schema 变了,尤其是 MCP 工具动态接入、late connect、defer_loading 策略变化。
model 变了。
thinking 配置变了。源码里多次强调 maxOutputTokens 会连带改变 thinking budget(包含token预算),进而打断缓存。
effort、某些 beta headers、某些 body 参数变了。
cache_control 的 TTL 或 scope 变了超过 TTL。诊断器默认就按 5 分钟和 1 小时两档来判断。
总之,一切在历史上下文中有动态成分信息都会打断前缀缓存,平时你们用的很多中转API不具备这个条件就烧TOKEN烧的飞起,龙虾openclaw等这种demo 开源项目,是不会具备这种产品级细粒度的设计的。
思考以下:
那么claude code是怎么解决的呢?真实长程任务中,前缀缓存因为GPU存储能力有限并不是无限扩充的,当进行上下文压缩时,缓存崩溃怎么办?
四 cluade code 前缀稳定性解决方案(缓存协议)
首先我们市面上用到的比如cc\codex,他们都是有自己推理端的缓存协议实现的,这和自己独立部署VLLM是不同的,为什么?
因为原生VLLM只是有固定的block size,但是上下文很长的时候,你就要有取舍了,那么clude code思路就是定义什么该缓存,什么可以舍弃,沿着这个思路进行设计实现的。
因此其实前缀缓存工程核心思路就是:是尽一切办法保证"可缓存前缀"稳定、可重复、字节级一致;只要前缀一字不差,服务端就能直接复用已经算过的那一大段上下文。
4.1 基础前提:明确"前缀"的定义与拆分
claude code思路是:前缀缓存并非缓存整次请求,而是聚焦"每轮请求中高度重复、变化最慢的输入片段"。第一步需先将单次请求拆分为3个核心部分,这是保证缓存命中率的基础,拆分不清晰会直接导致缓存失效:
-
稳定前缀:长期不变的内容,比如系统提示词(system prompt)、固定的工具定义、全局稳定规则等,是缓存的核心载体。
-
半稳定区域:偶尔变化的内容,比如会话摘要、技能列表、部分固定上下文块,变化频率低于动态内容,可选择性缓存。
-
动态尾部:每轮必变的内容,比如用户最新消息、最新工具调用结果、临时状态等,无需缓存,也是每轮请求的核心变化点。
你可以把它理解成一本很厚的书。
第一次请求时,Claude Code 把"系统提示词 + 工具定义 + 历史消息 + 上下文"整本书交给服务端。服务端第一次要完整读完,所以会出现 cache creation,也就是建立缓存。 第二次请求时,如果前面那 95% 内容完全一样,只是最后多了一小段新问题,那服务端不用再重读前 95%,直接从"书签"后面继续,这就是 cache read,也就是缓存命中。 所以命中的核心不是"语义差不多",而是"前缀字节完全一致"。源码里大量设计,都是围绕这四个字:字节完全一致。
一个非常直观的示例:
假设第一次请求的可缓存前缀是下面这段:
<系统前缀>
Anthropic billing header
CLI sysprompt prefix
静态大段系统规则
用户上下文快照
系统上下文快照
工具 schema
历史对话 1 到 20 轮
最后一条用户消息
请分析 auth 模块的 session 失效问题
最后一条用户消息末尾挂 cache_control 这时服务端第一次见到它,所以建立缓存。 然后第二次请求变成: 前缀完全相同 还是上面那一大段 <新增尾巴> , 顺便检查一下 token 缓存会不会导致旧 session 被误用
如果前缀一字不差,那么服务端就不需要重新编码前面那一大段,只需要处理新尾巴。这就是命中
但是问题来了?你给模型怎么识别你的这些标记,其实核心壁垒就在这里了:这就是各家C端爆款产品引入的背后服务端缓存协议,这是语义级别的协议,需要在推理端做设计和实现。这块也是我认为整个文章 最核心的点 我放在文章末尾描述推理端怎么处理的 来说,因为这块各家是闭源的,也就是说Claude code所有的高级缓存技术都需要其推理服务的能力支撑,所以我不敢说自己100%是正确的。
尽力去做最能稳定的部分,其余完全不可控的就放弃,这也是harness理念投影。
4.2 核心准备:将输入标准化,避免"语义同、字节异"
前缀缓存最忌讳"逻辑语义没变,但输入的字节串不一样"------缓存系统会判定为不同前缀,导致缓存失效。因此第二步必须对输入进行"规范化处理",确保同一份逻辑输入,产出完全一致的字节串,具体做法包括:
-
固定system prompt的分块顺序,不随意调整段落、语句排列;
-
工具 schema(工具定义)的序列化顺序固定,避免字段乱序;
-
JSON等结构化数据的字段顺序固定,去除多余空白、换行、分隔符,保证格式稳定;
-
禁止将动态字段(如临时状态、实时参数)混入稳定前缀区域。
三、关键设计:定义合理的缓存键(前缀身份标识)
缓存键是区分不同前缀的"身份凭证",本质是"请求签名",不能只简单对prompt文本做哈希,需包含所有影响推理结果的维度,避免"假命中"(文本相同但配置不同,导致缓存复用错误)。通用缓存键需包含以下核心维度:
-
模型ID(不同模型的推理逻辑不同,缓存不可复用);
-
规范化后的system prompt和tool schema结果;
-
关键功能开关(如beta版本、特性头部信息);
-
输出配置中影响推理行为的字段(如输出长度、温度值等);
-
服务相关字段(如服务提供商、区域、路由信息);
-
可选的缓存时效(TTL)、复用范围(scope)相关维度。
想象下模型真实ID等很多关键参数对推理结果产生影响的信息,是不能仅仅通过文本匹配就复用kv cache的
cache_key = f"{model_id}:{temperature}:{tools_hash}:{system_prompt_hash}"
示例: "claude-4-5-sonnet:0.7:9f2a:8b1c"
安检口:
游客 A:拿着"护照"(Prompt),想进"VIP 通道"(低温度参数)。
缓存系统:拦住!虽然脸(Prompt)一样,但你没带"VIP 票"(参数不匹配),不能验证通过刚才那个人的结果。
四、优化手段:将请求分块,提升缓存复用率
成熟的前缀缓存不会将整个输入当作一个大字符串处理,而是拆分为多个可独立缓存的块,这样既能避免"一块变化导致全量缓存失效",也能实现"部分块命中",提升复用率。通用分块方式如下:
-
Block 0:不可缓存或弱缓存头部(如临时请求标识);
-
Block 1:最稳定的system前缀(核心缓存块,几乎不变);
-
Block 2:静态上下文(如固定技能说明,长期不变);
-
Block 3:半动态上下文(如会话摘要,偶尔变化);
-
Tail:当前轮新消息、新工具结果等动态内容(不缓存)。
假设你有 100 轮对话历史。
第 101 轮请求:
Block 1 (System): 命中
Block 2 (History 1-50): 命中
Block 3 (History 51-100): 命中
Tail (New Msg): 计算
第 102 轮请求:
Block 1, 2, 3: 全部直接命中!。
五、规则定义:明确缓存策略(时效、范围、淘汰机制)
前缀缓存不是"临时优化",而是工程化系统,必须明确3个核心规则,否则会导致缓存混乱、资源浪费:
-
缓存时效(TTL):定义缓存保留时间,典型档位为5分钟、30分钟、1小时,需平衡"缓存收益"和"数据新鲜度"(如高频变化的半稳定区,TTL可设短一些)。
-
复用范围(scope):定义缓存可被哪些对象复用,常见范围从窄到宽为:请求级(仅当前请求)→会话级(同一用户会话)→用户级(同一用户)→组织级(同一团队/组织)→全局级(所有用户)。
-
淘汰策略(eviction):定义缓存满了之后如何清理,常见策略包括:LRU(最近最少使用)、TTL过期淘汰、成本优先淘汰、大对象优先淘汰、冷热分层淘汰(优先保留高频命中的缓存块)。
六、如何解决工具信息变化引起的前缀缓存失效
很多系统的前缀缓存做不起来,不是因为哈希逻辑有问题,而是"影响缓存键的状态中途翻转",导致缓存键频繁变化(缓存漂移)。因此需增加"状态冻结"层:
一旦某些影响缓存键的配置(如功能开关、beta头部、工具列表顺序、可选配置)在当前会话中确认,就不要中途频繁切换。核心原则:缓存最怕的不是大,而是不稳定。
常见易漂移的状态:fast mode开关这种模型自定义的路由选择、beta header有无、tool列表顺序、上下文摘要每轮微调等,需通过"会话级冻结"避免漂移。
example------有的工程师会有上下文膨胀的管理意识,因此他们会选择动态加载工具,这样你的提示词schema就不会全都堆在system promt里,来达到瘦身的目的,但是:
第 1 轮:用户问天气 -> 加载 Weather_Tool -> 缓存键 A。
第 2 轮:用户问时间 -> 加载 Time_Tool -> 缓存键 B(A 失效)。
第 3 轮:用户又问天气 -> 加载 Weather_Tool -> 缓存键 A(B 失效)。额外的MCP这种热插拔也会引入不稳定情况,那么claude code怎么做的?
解决思路:固定住,如果少量就是全量固定加载;如果多了这里就要按照检索思路去做。这里claude code用的是延迟增量更新的思路:
以前的做法是每轮都把当前的工具列表"广播"一遍,导致只要工具列表有微小变动,整个 System Prompt 前缀就全废了。现在的做法是"状态审计 + 增量补丁"
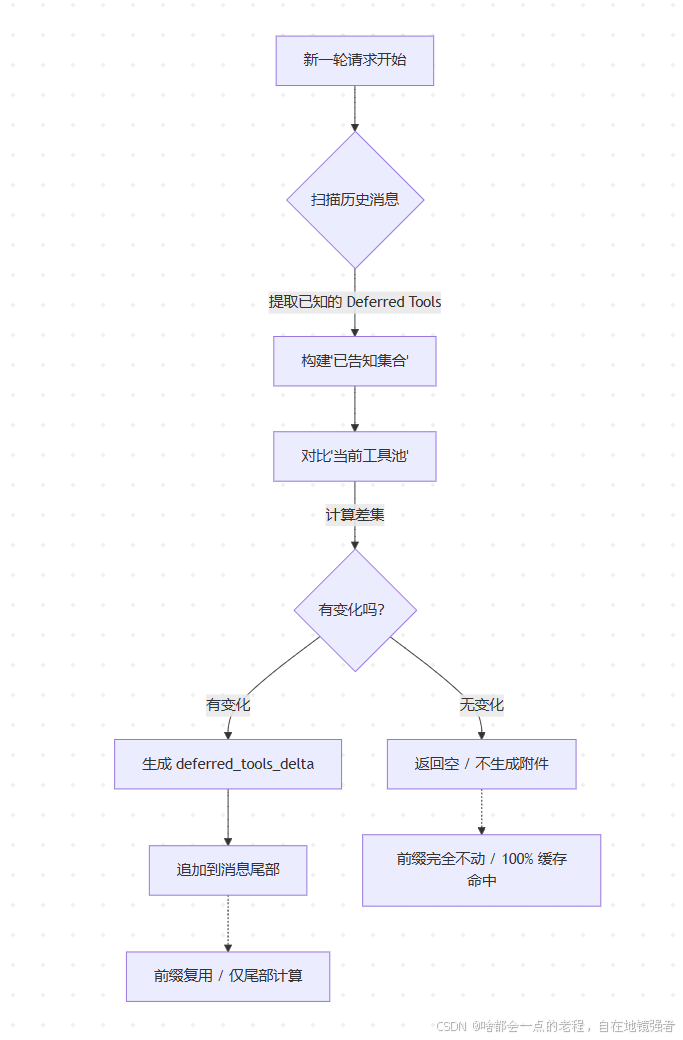
因此这样对比下来:
旧模式(重写):
第 1 轮:System... Tools: A, B -> Miss (建立缓存)
第 2 轮:System... Tools: A, B, C -> Miss (前缀变了,缓存失效)
第 3 轮:System... Tools: A, C -> Miss (前缀又变了)
新模式(追加):
第 1 轮:System... + Tail: Delta(+A, +B) -> Miss (建立缓存)
第 2 轮:System... + Tail: Delta(+C) -> Hit (前缀未动,只算尾部)
第 3 轮:System... + Tail: Delta(-B) -> Hit (前缀未动,只算尾部)
七、工具结果长输出处理(重点 下篇单讲 )
只要系统涉及工具调用、文件读取、检索结果,就会遇到"大对象回灌prompt"的问题(如大文件读取结果、大量检索内容),处理不当会导致前缀字节变化,缓存失效。通用处理流程:
-
先定义单个对象的大小上限(如单条工具结果不超过20k文本);
-
再定义单轮消息/单轮请求的聚合上限(如单轮所有工具结果总和不超过50k);
-
超限时,采用"持久化+引用"或"摘要化"处理(如将大对象存到外部文件,prompt中只保留引用标记);
-
最关键:同一个对象的压缩/处理结果必须稳定(比如同一个工具结果,处理成摘要A,下一轮不能变成摘要B),否则会导致前缀字节漂移,缓存失效。
example
当你在多步长程任务或者多轮交互情况下,对过去历史产生的某些长工具输出(联网搜索的内容)进行压缩后,那么你下一次的前缀缓存就会出现问题,这里目前最极限的做法就是在工具结果压缩处进行标记,后面需要从新计算kvcache,但是一般不考虑的那么你当前缀就完全崩溃了。
claude code是做了更极限的做法,这也是很难完全复刻的一个因素,但这个值得单独拿出来仔细品品,故我写在了下篇文章,这里你知道知道它做了cache edit ,服务端进行了分层kv cache 可以更高程度复用。
八、高级原则:增量更新不重写旧正文
如果历史内容已经进入缓存,后续对历史内容的删除、压缩、摘要、隐藏,不要直接修改原始正文------一改正文,后续所有前缀的字节都会变化,旧缓存会从改动点起全部失效。
通用优化思路:
-
尽量保持历史正文稳定,不轻易修改;
-
将删除、压缩等增量操作,放到"侧载文件(sidecar)、编辑日志(edit log)"等独立结构中;
-
后续请求重复携带这个独立结构,维持请求形态的一致性,避免缓存失效。
九、分支场景:确保多分支共享统一前缀表面
如果系统存在子智能体(subagent)、分支会话(forked branch)、并行规划、推测执行等场景,需保证:所有分支对历史内容的格式化、压缩、摘要、替换决策完全一致。
原因:如果主线程和子线程对同一段历史生成不同的前缀格式,会导致缓存命中分裂(同一历史对应多个缓存键),缓存复用率大幅下降。
解决方案:所有"影响prompt表面格式"的状态(如压缩规则、摘要逻辑),支持克隆(clone)、继承(inherit)、重放(replay),避免每个分支重新计算。
十、观测体系:缓存不是"开了就完了",需可观测
前缀缓存必须建立完善的观测体系,否则无法判断缓存效果、定位失效原因。通用观测指标至少包含:
-
缓存读取/创建的token数、字节数;
-
缓存命中次数、未命中次数、命中率(hit ratio);
-
未命中发生在哪个缓存块(如Block 1未命中、Block 3未命中);
-
前后轮前缀差异原因(如TTL过期、配置翻转、tool schema变化等);
-
缓存失效的具体原因(如服务端驱逐、scope变化、配置修改)。
没有观测体系,只能感知"系统变快/变慢",无法定位缓存问题,也无法优化命中率。
在Claude code 客户端会收到缓存的命中数,这是推理服务的设计
十一、故障诊断:不止关注未命中,还要做断裂归因
成熟的前缀缓存系统,不会只报"缓存未命中",还会对"未命中原因"做精准归因,找到缓存断裂的根源------大部分缓存问题,不是"没有缓存能力",而是"命中条件被不小心破坏"。
常见断裂归因维度:
-
prompt文本本身发生变化;
-
tool schema(工具定义)修改;
-
模型ID切换;
-
功能开关(header/beta)变化;
-
缓存TTL过期;
-
缓存复用范围(scope)调整;
-
服务端缓存驱逐。
十二、流程顺序
若需从零搭建前缀缓存系统,推荐按以下顺序落地,兼顾合理性和效率:
-
拆分请求:将单次请求拆分为稳定前缀、半稳定区、动态尾部;
-
输入规范化:对稳定区做严格的格式、顺序规范,确保字节稳定;
-
定义缓存键:纳入所有影响推理结果的签名字段,避免假命中;
-
分块缓存:将请求拆分为多个独立缓存块,而非整坨缓存;
-
制定缓存策略:明确TTL、scope、eviction三大规则;
-
状态冻结:对会话中易漂移的配置做会话级冻结;
-
大对象处理:实现大对象的确定性压缩/引用化,不重写旧正文;
-
观测与归因:搭建观测体系,实现缓存断裂的精准归因。
十三、完成度判断标准
一个前缀缓存设计是否成熟,无需复杂校验,应该满足以下:
-
同一个会话连续10轮请求,前80%的请求字节是否保持一致?(验证前缀稳定性)
-
当功能开关、配置发生变化时,系统是否有机制阻止缓存键中途漂移?(验证状态冻结有效性)
-
当缓存命中率下降时,系统是否能明确说明"哪一层、什么原因导致未命中"?(验证观测与归因能力)
若这3个问题无法明确回答,说明缓存仍处于"临时优化"阶段,未形成成熟的工程化系统。
最后结尾,很现实的问题你客户端agent侧做了半天设计和切分,但是任一一款推理引擎无法解析你的协议,所以这块是双向的。
重点------推理模型服务端到底怎么处理 cache_control 语义并确定边界?
协议核心:思路之前说过"明确缓存边界",服务端去解析,难点在于如何解析,这里透露下个人的思考方案:
服务端Cache Control边界确定流程
-
语义边界提供
- 在agent
中指定stable_prefix_message_count`(如"前3条消息为稳定前缀"),放入协议。
- 在agent
-
请求透传
- 注入模型服务请求的
extra_body,传递至vLLM等推理服务端。
- 注入模型服务请求的
-
服务端Token重计算
- 不直接使用 客户端提供的token数,而是重新渲染稳定前缀部分消息(应用chat template、tool schema、Harmony规则等)。
- 统计真实生成的prompt tokens数,作为权威cutoff值。
-
内部参数转换
- 将cutoff值定义
sampling_params.extra_args(字段名)。 - Request读取该值,作为"允许写入cache的最大token边界"。
- 将cutoff值定义
-
Block粒度截断
- 在
single_type_kv_cache_manager.py中,按公式计算最终缓存边界:
c a c h e a b l e _ f u l l _ b l o c k s = ⌊ c u t o f f _ t o k e n s b l o c k _ s i z e ⌋ cacheable\_full\_blocks = \left\lfloor \frac{cutoff\_tokens}{block\_size} \right\rfloor cacheable_full_blocks=⌊block_sizecutoff_tokens⌋
c u t o f f t o k e n s :服务端算出的真实截断点(例如 125 )。 b l o c k s i z e :块大小(例如 16 )。 ⌊ . . . ⌋ :向下取整。结果: 125 ÷ 16 = 7.81125 ÷ 16 = 7.81 ,向下取整得到 7 。这意味着只有前 7 个块是"安全"且"可缓存"的。 e f f e c t i v e _ c a c h e d _ t o k e n s = c a c h e a b l e _ f u l l _ b l o c k s × b l o c k _ s i z e cutoff_tokens:服务端算出的真实截断点(例如 125)。 block_size:块大小(例如 16)。 ⌊ ... ⌋:向下取整。 结果: 125 ÷ 16 = 7.81 125÷16=7.81 ,向下取整得到 7。这意味着只有前 7 个块是"安全"且"可缓存"的。 effective\_cached\_tokens = cacheable\_full\_blocks \times block\_size cutofftokens:服务端算出的真实截断点(例如125)。blocksize:块大小(例如16)。⌊...⌋:向下取整。结果:125÷16=7.81125÷16=7.81,向下取整得到7。这意味着只有前7个块是"安全"且"可缓存"的。effective_cached_tokens=cacheable_full_blocks×block_size - 不完整block不缓存(如cutoff=125,block_size=128,则缓存0 tokens)。
- 在
关键设计原则
- 服务端权威性 :缓存边界必须由服务端在真实prompt上计算,避免客户端错误导致缓存污染。
- 语义与执行分离 :
- 语义层:
cache_control提供"消息级"边界(如"前3条消息")。 - 执行层:服务端将其转换为"token级"cutoff,再降级为"block级"写入边界。
- 语义层:
- **当前实现可扩展至多段缓存,只需将"单稳定前缀"改为"多cache segment"语义解析。
下篇我们会讲更高级的语义细粒度缓存