目录
[3.1 惰性删除](#3.1 惰性删除)
[3.2 定期删除](#3.2 定期删除)
[5.1 rdb生成快照](#5.1 rdb生成快照)
[5.2 aof](#5.2 aof)
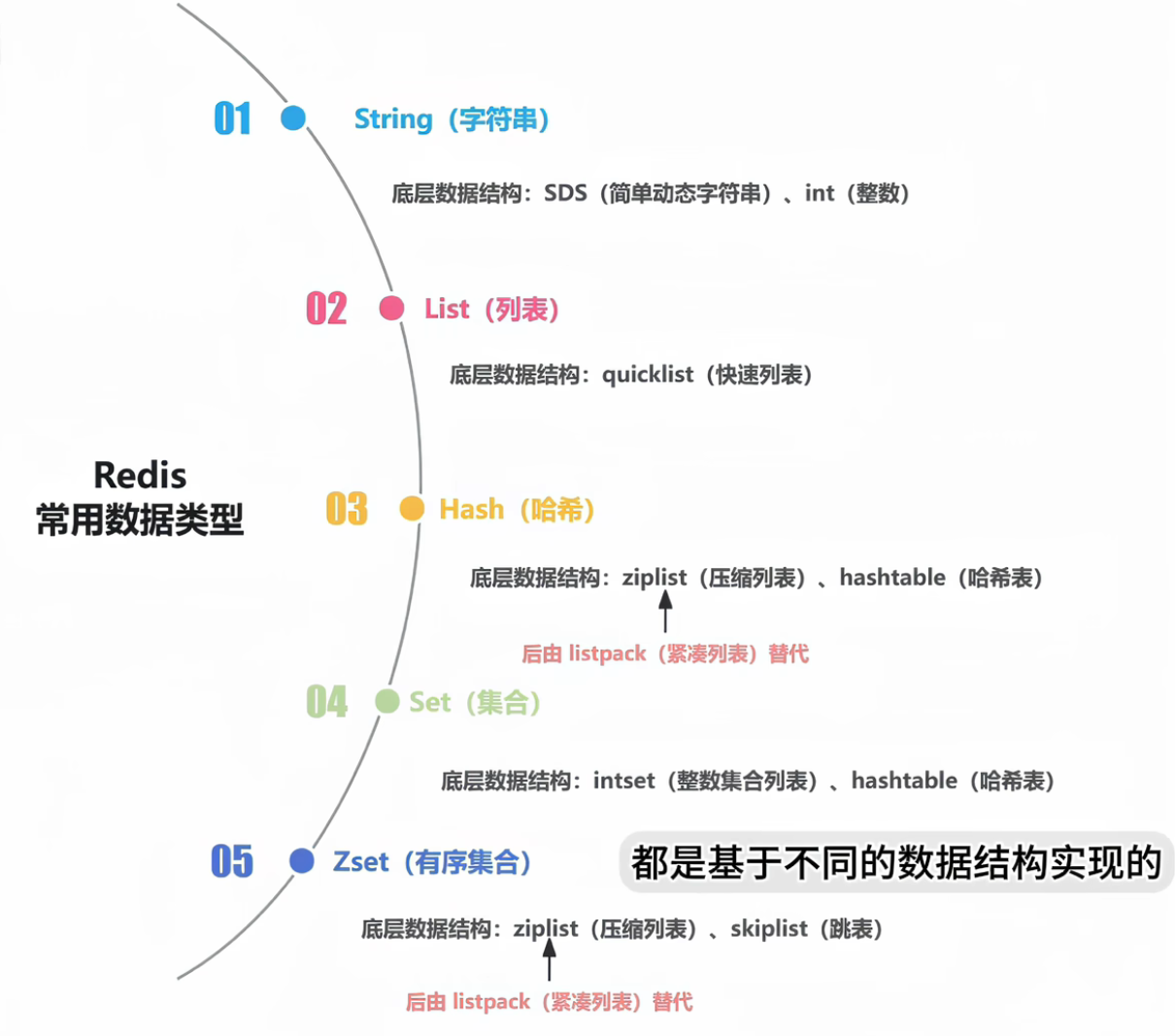
前提:redis项目之存储类型
b站仙可程序员的总结
一、redis源码如何做的
cpptypedef struct dict { dictType *type; // 函数指针表:哈希函数、键对比函数等 void *privdata; // 私有数据:传给 type 里的函数 dictht ht[2]; // 【核心】两个哈希表!ht[0] 是主表,ht[1] 是 rehash 临时表 long rehashidx; // rehash 进度:-1 表示没在 rehash,≥0 表示当前 rehash 到的桶索引 unsigned long iterators; // 安全迭代器数量 } dict; typedef struct dictht { dictEntry **table; // 哈希桶数组:每个元素是指向 dictEntry 的指针 unsigned long size; // 桶数组的大小(必须是 2^n) unsigned long sizemask; // 桶数组的掩码:size-1(用于快速计算哈希值对应的桶索引) unsigned long used; // 已存储的键值对数量 } dictht; typedef struct dictEntry { void *key; // 键(通常是 SDS) union { // 【核心】值用 union 节省内存 void *val; uint64_t u64; int64_t s64; double d; } v; struct dictEntry *next; // 指向下一个节点(链地址法处理哈希冲突) } dictEntry; //注意dictEntry中的联合体中的val实际指向一个redisObject(里面存储实际value) typedef struct redisObject { unsigned type:4; // 【核心标记】4位,标记 Value 的类型 unsigned encoding:4; // 4位,标记 Value 的底层数据结构 unsigned lru:LRU_BITS; // LRU 时间(用于内存淘汰) int refcount; // 引用计数(用于对象共享) void *ptr; // 指向实际的底层数据结构 } robj;一句话说清楚:采用了链地址法,hash桶,每个桶都是一条链子,避免了hash冲突
dict里面有两个hash表,其中一个是为了rehash的,哈希表里面是哈希桶,每个桶存储的是dictEntry*(也就是链头节点),然后每个节点存储的是key-value
1.最核心设计亮点:渐进式 rehash
这是 Redis
dict最经典的设计,解决了 大哈希表扩容时的阻塞问题。1.1 为什么需要渐进式 rehash?
普通哈希表(比如
std::unordered_map)扩容时是一次性的:
当
used > size * load_factor(通常 0.75)时,分配新的桶数组;把所有节点从旧桶数组一次性拷贝到新桶数组;
如果哈希表很大(比如 1000 万个键),这一步会阻塞几百毫秒甚至几秒,Redis 作为实时数据库绝对不能接受。
1.2 Redis 的解决方案:渐进式 rehash
核心思路:不一次性拷贝所有节点,而是分多次、逐步拷贝,把扩容开销分摊到每次操作中。
具体步骤
触发扩容 :当
ht[0].used > ht[0].size * load_factor时:
给
ht[1]分配新的桶数组(大小是ht[0].size的 2 倍,且是 2 的幂);把
rehashidx设为 0(表示开始 rehash)。逐步迁移 :每次对
dict进行增删改查时:
顺便把
ht[0].table[rehashidx]这个桶里的所有节点从ht[0]拷贝到ht[1];
rehashidx++;如果
rehashidx达到ht[0].size,说明所有节点都迁移完了。完成迁移:
把
ht[1]设为ht[0];释放旧的
ht[0];把
rehashidx设为 -1(表示 rehash 结束)。效果
扩容的开销被分摊到每次操作中,单次操作的延迟只有几纳秒,完全不会阻塞;
用户感知不到扩容的存在。
2. 哈希冲突处理:链地址法
和
std::unordered_map类似,Redis 用 链地址法 处理哈希冲突:
当两个键的哈希值落在同一个桶里时,用链表把它们串起来;
查找时,先算哈希值找到桶,再遍历链表对比键。
3. 哈希函数和桶大小的选择
3.1 哈希函数
Redis 用 MurmurHash2 哈希函数:
计算速度快;
哈希值分布均匀,减少哈希冲突;
适合字符串、整数等多种类型的键。
3.2 桶大小的选择
桶大小必须是 2 的幂;
配合
sizemask(size-1)用位运算快速计算桶索引:hash & sizemask;比取模运算(
hash % size)快很多。
4. Redis
dictvs C++std::unordered_map核心对比
维度 Redis dictC++ std::unordered_map扩容方式 渐进式 rehash(分多次,不阻塞) 一次性扩容(可能阻塞) 桶大小 必须是 2^n(位运算快速计算索引) 通常是质数(取模计算索引) 值存储 用 union 节省内存 直接存储对象(或指针) 迭代器安全性 支持安全迭代器(迭代时不 rehash) 迭代时修改可能导致迭代器失效 内存开销 更小(自研,无 C++ 标准库的额外元数据) 更大(有标准库的额外元数据) 代码复杂度 高(需要自己实现哈希表、渐进式 rehash) 低(直接用标准库)
总结
宏观作用:全局哈希表是 Redis KV 存储的核心骨架,所有 Key 都存在这里;
三层结构 :
dict(管理两个哈希表)→dictht(实际哈希表)→dictEntry(哈希节点);最核心亮点:渐进式 rehash,解决大哈希表扩容阻塞问题;
哈希冲突处理:链地址法;
性能优化:MurmurHash2 哈希函数、桶大小 2^n、位运算计算索引。
编码的作用:如果所有的key、redisObject、value都分开存,那会造成内存离散,所以编码的作用就是在一些value非常小的情况下,让redisObject和value一块存(也就是开同一块大的内存空间,前面存redisObject,后面存value),这样能够避免内存离散
但是注意不能都开一块,如果value很大,你都开一块了,会造成连续的很大,有时候没有内存分配,内存总量可能还剩很多,但都是 "小块碎片",没有足够大的连续块;
不是不想都开连续内存,而是大数据下连续内存的 "操作效率、扩容成本、分配成功率" 都太差了,所以 Redis 做了权衡:
- 小数据:连续内存(省内存、Cache 好);
- 大数据:离散内存(操作快、分配易、扩容灵活)。
这次项目我们主要采用unordered_map实现这个复杂的hash表
维度 Redis dictstd::unordered_map最大亮点 ✅ 渐进式 rehash(不阻塞) ❌ 一次性扩容(可能阻塞) 内存统计 ✅ 内置( zmalloc)❌ 无(需自己封装) 值存储优化 ✅ union节省内存❌ 无 安全迭代器 ✅ 支持 ❌ 不支持 哈希函数 ✅ MurmurHash2(均匀、快) ⚠️ 取决于标准库 桶大小 ✅ 必须 2^n(位运算快) ⚠️ 通常 2^n,但非必须 内存碎片 ✅ 少(jemalloc/tcmalloc) ⚠️ 较多(libc malloc) 适用场景 ✅ 高性能内存数据库 ✅ 通用场景
redis在各个能够优化的地方都做了优化处理
二、获取当前时间
cpp
int64_t KeyValueStore::nowMs()
{
using namespace std::chrono; // 简化 chrono 库的命名空间
// 核心逻辑:获取当前时间 → 转换为从"纪元"开始的毫秒数 → 返回
return duration_cast<milliseconds>( // 步骤3:把时间间隔转换成「毫秒」单位
steady_clock::now() // 步骤1:获取当前系统的稳定时钟时间点
.time_since_epoch() // 步骤2:计算从"纪元时间"到当前时间的总间隔
).count(); // 步骤4:取出毫秒数的数值(转成 int64_t)
}
steady_clock(稳定时钟):系统的 "单调递增时钟",不会因系统时间修改(比如手动调时间、NTP 同步)而跳变,适合计算「时间间隔」;time_since_epoch():计算从 "纪元时间"(不同系统略有差异,通常是 1970-01-01 00:00:00 UTC 或系统启动时间)到当前时间的总时间间隔;duration_cast<milliseconds>:把时间间隔强制转换成「毫秒」单位(也可以转成秒seconds、微秒microseconds);.count():取出时间间隔的 "数值部分"(比如 1710000000000 毫秒),返回整数。
steady_clock::now()返回的不是 "普通数值",而是std::chrono::time_point类型的时间点对象 ------.time_since_epoch()是这个对象的成员函数,作用是把 "时间点" 转换成 "从纪元开始的时间间隔",最终才能换算成毫秒数。核心就是为了避免有人修改系统时间而导致key的定时删除出现问题
三、掌握容器的查找
find_if
四、关于redis的过期策略
3.1 惰性删除
惰性删除 :不主动轮询所有 Key 检查过期,而是在「访问 / 操作 Key 前」先检查是否过期,若过期则直接删除,保证用户获取的永远是未过期的有效数据;
简单来说在get等函数的获取key的时候,先检查一下key是否过期,如果过期直接删除,然后返回nil即可
3.2 定期删除
这是一种主动的删除策略。Redis 会周期性地随机从数据库中取出一定数量的键,检查它们是否过期,并删除其中过期的键。Redis 会通过配置文件中的 hz 参数(默认值是 10 ,表示每秒执行 10 次过期扫描)来控制定期删除操作的执行频率。每次扫描时,Redis 会随机选择一些数据库,然后从每个数据库中随机取出一定数量的键进行检查。这种策略能有效减少过期键对内存的占用 ,不过如果执行过于频繁,会消耗较多 CPU 资源;如果执行频率过低,又会导致过期键长时间占用内存。
五、关于redis的持久化策略
5.1 rdb生成快照
- 定义
RDB(Redis Database)是一种结构化二进制文件 ,用于将内存中的 KV 数据序列化后持久化到磁盘,服务重启后可通过加载 RDB 文件恢复数据。
- 关键澄清:不是 "内存 01 直接拷贝"
对比项 内存直接拷贝(原始二进制) RDB(结构化二进制) 跨平台性 差(依赖操作系统 / CPU 内存布局) 优(按统一协议序列化) 压缩性 无(直接存内存字节) 有(可对短字符串、整数做编码压缩) 兼容性 差(代码修改后内存布局变化,无法恢复) 优(有版本号,可向前 / 向后兼容) 安全性 差(无校验,数据损坏无法检测) 优(有 CRC64 校验和,可检测数据完整性)
cpp+----------------+----------------+----------------+----------------+----------------+ | 魔数头部 | 版本号 | 数据库数据块 | 结束标记 | 校验和 | | "MINIREDIS" | 4字节整数 | 多个 Key-Value | 1字节(0xFF) | 8字节CRC64 | | (8字节) | (如 0x00000001)| 对(带类型) | | | +----------------+----------------+----------------+----------------+----------------+ // 单个 Key-Value 数据块结构(以 String 为例) +------------+------------+------------+------------+------------+ | 数据类型 | Key长度 | Key内容 | Value长度 | Value内容 | | 1字节 | 变长整数 | 字节流 | 变长整数 | 字节流 | | (0x00=String)| | | | | +------------+------------+------------+------------+------------+ // Hash 数据块结构 +------------+------------+------------+------------+------------+------------+ | 数据类型 | Key长度 | Key内容 | Field数量 | Field1-Value1 | ... | | 1字节(0x02) | 变长整数 | 字节流 | 4字节整数 | (变长+变长) | ... | +------------+------------+------------+------------+------------+------------+ // ZSet 数据块结构(区分 vector/跳表,统一按有序存储) +------------+------------+------------+------------+------------+------------+ | 数据类型 | Key长度 | Key内容 | 成员数量 | Member1-Score1 | ... | | 1字节(0x03) | 变长整数 | 字节流 | 4字节整数 | (变长+8字节double) | ... | +------------+------------+------------+------------+------------+------------+简单来说就是按照一定的格式,序列化存储起来
5.2 aof
AOF(Append Only File)是 Redis 另一种核心持久化方式,本质是 "追加式写命令日志" ------ 和 RDB(快照)不同,AOF 不保存内存数据的副本,而是把每一条写操作命令 (如
set/hset/zadd/zrem)按顺序追加到文件末尾;服务重启后,通过重放(Replay) AOF 中的所有写命令来恢复数据,数据安全性比 RDB 更高(可配置秒级持久化)。
维度 AOF(Append Only File) RDB(Redis Database) 保存内容 写操作命令(如 set key value)内存数据的结构化快照 保存方式 追加写入(Append) 全量覆盖写入 数据安全性 高(可配置每秒 / 每次写同步) 中(全量快照,可能丢失最后一次快照后的数据) 文件大小 大(记录所有写命令,需重写压缩) 小(结构化二进制,可压缩) 恢复速度 慢(需重放所有命令) 快(直接加载快照) 典型场景 数据安全性要求高(如金融、交易) 备份、快速恢复、数据迁移 Redis 的 AOF 默认使用 RESP(Redis Serialization Protocol) 文本协议记录命令,可读性比 RDB 高(Vim 打开能直接看懂命令)。
简单来说,采用我们之前写的resp协议进行写进硬盘存储起来
六、跳表
以下是b站仙可程序员的总结
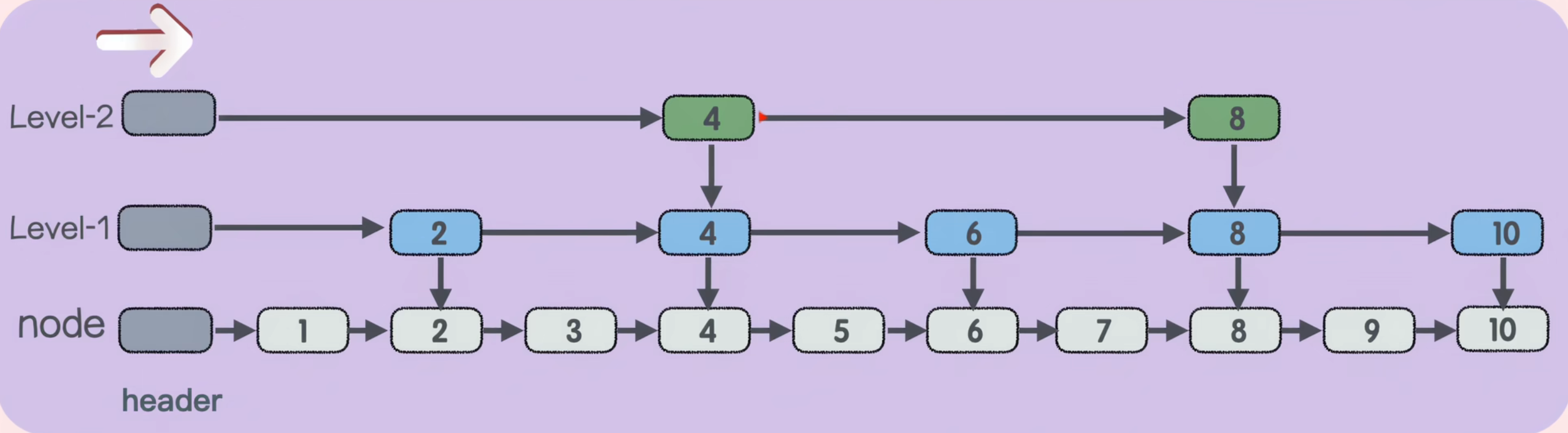
常规链表不便于查找,所以我们在常规链表的基础上增加多级索引,即跳表
决定底层元素能否成为level的索引取决于随机概率p(晋升概率),如果p=0.5,说明每个节点都有一半的机会往上跃迁
注意每一层都有一个头节点
比如查找4,先进入level-2查找,刚好可以则返回
比如查找5,先进入level-2查找,比4大,去下一个节点,即8,因为8比5大,回退上一个节点,然后由节点4进入level-1查找,往右,因为6比5大,所以回退上一个节点,进入node层
然后往右查,5==5,然后返回即可
总结:建立多级索引,达到时间复杂度O(logN),
p越大,查询越快但内存越高;p越小,内存越省但查询越慢。p=0.25 的查询性能和 p=0.5 几乎无感知差异(差 1 倍查询次数,但每次查询都是内存操作,微秒级)。redis选择了0.25
注意p:这里指的是每个节点都有机会往上晋升的概率,真实的跳表(如 Redis)就是通过 "每个节点有 25% 概率晋升一层" 的规则,在概率上实现 "高层节点数≈底层的 1/4"