Apache Doris 是一款 MPP 分析型数据库,以亚秒级查询和简单运维著称。在 AWS 生态中,Doris 可以扮演多种角色------独立的分析引擎、弹性计算层、或数据湖加速层。根据业务场景的不同,我们在实践中总结出三种部署方案,各有取舍。
方案总览
| 方案一:存算一体 | 方案二:存算分离 + S3 | 方案三:Multi-Catalog 湖仓联邦 | |
|---|---|---|---|
| 核心思路 | FE/BE 部署在 EC2,数据存本地磁盘 | BE 无状态,数据持久化到 S3 | Doris 不存数据,直接读数据湖 |
| 额外组件 | 无 | FoundationDB + Meta Service | 无(需已有 Glue/HMS) |
| 弹性扩缩容 | 差,需手动迁移数据 | 强,BE 无状态可秒级扩缩 | 不涉及(Doris 独立部署) |
| 存储成本 | 高(EBS gp3) | 低(S3) | 最低(复用已有数据湖) |
| 数据搬迁 | 需导入 Doris | 需导入 Doris(写入 S3) | 零搬迁 |
| 适用场景 | 快速验证、小规模分析 | 大规模生产、弹性需求高 | 已有数据湖,加速报表查询 |
下面逐一展开。
存算一体部署
这是最经典的 Doris 部署形态。FE(Frontend)负责 SQL 解析、查询规划和元数据管理;BE(Backend)负责数据存储和计算执行。数据以多副本形式存储在 BE 节点的本地 EBS 磁盘上。
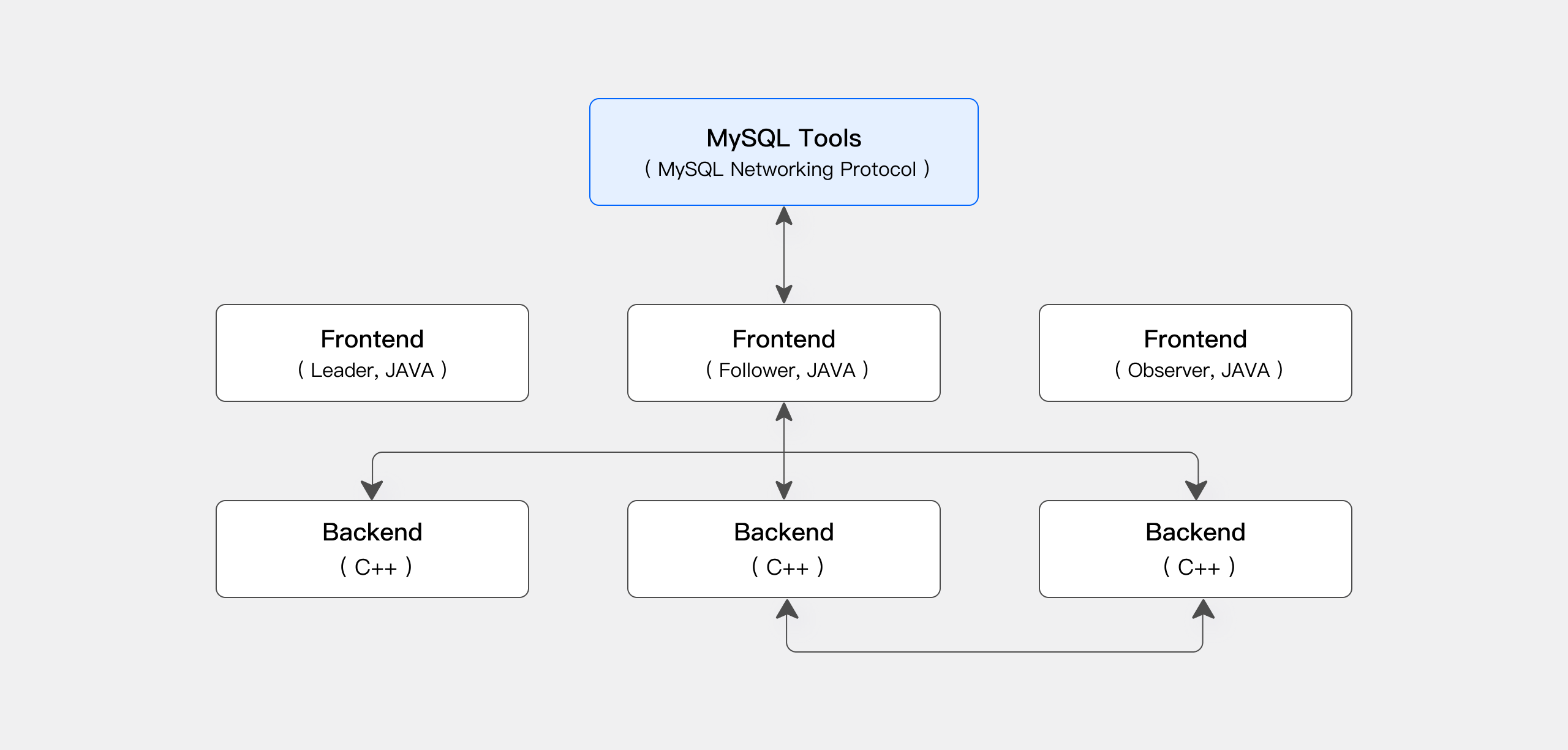
FE 和 BE 之间通过心跳端口(默认 9050)保持连接。FE 对外暴露 MySQL 协议端口(9030),用户通过标准 MySQL 客户端即可连接。
关键配置
OS 层调优是 Doris 部署的前置条件,主要包括:
- 关闭 swap:Doris 是内存密集型应用,swap 会导致查询延迟剧增
- 透明大页设为 madvise:Doris 4.x 推荐此设置,允许应用按需使用大页而非全局开启
- vm.max_map_count=2000000:Doris BE 会创建大量内存映射文件,默认值 65536 远远不够
- 文件句柄数调至 100 万:BE 在高并发场景下会打开大量文件描述符
bash
swapoff -a
echo madvise > /sys/kernel/mm/transparent_hugepage/enabled
sysctl -w vm.max_map_count=2000000fe.conf 核心配置:
priority_networks是部署中最容易踩的坑。EC2 实例通常有多个网络接口,如果不指定网段,Doris 可能绑定到 loopback 或错误的 ENI 上,导致节点间无法通信。
properties
# 指定 Doris 绑定的网段,避免绑到错误网卡
priority_networks = 172.31.0.0/16
# 表名大小写不敏感,兼容 MySQL 习惯
lower_case_table_names = 1
# Doris 4.x 要求 JDK 17+
JAVA_HOME=/usr/lib/jvm/java-17-amazon-correttobe.conf 核心配置:
properties
priority_networks = 172.31.0.0/16
# 数据目录指向数据盘
storage_root_path = /data/doris-storage
JAVA_HOME=/usr/lib/jvm/java-17-amazon-correttostorage_root_path 必须指向独立的数据盘(而非系统盘),否则数据增长会撑满根分区。我们使用 gp3 EBS 卷挂载到 /data,格式化为 XFS 文件系统XFS 在大文件顺序读写场景下性能优于 ext4。
部署流程
以 1 FE + 2 BE 的最小集群为例,完整走一遍部署过程。
创建 EC2 实例
每台实例需要两块磁盘:系统盘(20GB gp3)和数据盘(FE 50GB / BE 100GB gp3)。数据盘挂载为 /dev/xvdb,后续会格式化并挂载到 /data。
实例类型选择建议为,FE 主要消耗内存(元数据常驻内存),4C16G 起步;BE 是计算密集型,8C32G 起步。
bash
# FE 节点:m6i.xlarge (4C/16G)
aws ec2 run-instances --region cn-north-1 \
--image-id ami-xxxx --instance-type m6i.xlarge \
--key-name your-key --subnet-id subnet-xxxx --security-group-ids sg-xxxx \
--iam-instance-profile "Name=YourProfile" \
--block-device-mappings '[
{"DeviceName":"/dev/xvda","Ebs":{"VolumeSize":20,"VolumeType":"gp3"}},
{"DeviceName":"/dev/xvdb","Ebs":{"VolumeSize":50,"VolumeType":"gp3"}}
]' \
--tag-specifications '[{"ResourceType":"instance","Tags":[{"Key":"Name","Value":"doris-fe-1"}]}]'
# BE 节点:m6i.2xlarge (8C/32G),创建 2 台
aws ec2 run-instances --region cn-north-1 \
--image-id ami-xxxx --instance-type m6i.2xlarge \
--key-name your-key --subnet-id subnet-xxxx --security-group-ids sg-xxxx \
--iam-instance-profile "Name=YourProfile" \
--block-device-mappings '[
{"DeviceName":"/dev/xvda","Ebs":{"VolumeSize":20,"VolumeType":"gp3"}},
{"DeviceName":"/dev/xvdb","Ebs":{"VolumeSize":100,"VolumeType":"gp3"}}
]' \
--tag-specifications '[{"ResourceType":"instance","Tags":[{"Key":"Name","Value":"doris-be-1"}]}]'安全组需要开放以下端口(集群内部互通):
| 组件 | 端口 | 用途 |
|---|---|---|
| FE | 8030 | HTTP Server(Web UI) |
| FE | 9010 | FE 内部通信(edit_log_port) |
| FE | 9020 | Thrift RPC |
| FE | 9030 | MySQL 协议端口(客户端连接) |
| BE | 8040 | HTTP Server |
| BE | 8060 | BRPC 端口 |
| BE | 9050 | 心跳端口 |
| BE | 9060 | Thrift Server |
所有节点通用初始化
SSH 到每台实例,以 root 执行以下操作。这一步在 FE 和 BE 节点上完全相同。
bash
# 关闭 swap
swapoff -a
sed -i '/swap/d' /etc/fstab
# 透明大页设为 madvise
echo madvise > /sys/kernel/mm/transparent_hugepage/enabled
echo madvise > /sys/kernel/mm/transparent_hugepage/defrag
# 内核参数
cat >> /etc/sysctl.conf << 'EOF'
vm.max_map_count=2000000
vm.overcommit_memory=1
net.ipv4.tcp_abort_on_overflow=1
EOF
sysctl -p
# 文件句柄数
cat >> /etc/security/limits.conf << 'EOF'
soft nofile 1000000
hard nofile 1000000
EOF注意:以上配置追加操作不是幂等的,重复执行会产生重复条目。生产脚本中应先用 grep -q 检查是否已存在再追加。
Doris 4.x 强制要求 JDK 17+,不兼容 JDK 8 或 JDK 11。Amazon Linux 2023 可以直接从 yum 安装 Amazon Corretto:
bash
yum install -y java-17-amazon-corretto-devel
echo 'export JAVA_HOME=/usr/lib/jvm/java-17-amazon-corretto' > /etc/profile.d/doris.sh
source /etc/profile.d/doris.sh格式化并挂载数据盘
bash
# 格式化为 XFS(生产脚本应先检查 blkid 避免重复格式化)
mkfs.xfs /dev/xvdb
mkdir -p /data
mount /dev/xvdb /data
echo "/dev/xvdb /data xfs defaults,noatime 0 2" >> /etc/fstab创建 Doris 用户并下载安装包。Doris 进程不应以 root 运行,创建专用用户:
bash
useradd -m doris
chown doris:doris /data
# 从 S3 下载安装包(也可以从 Doris 官网下载)
aws s3 cp s3://your-bucket/apache-doris-4.0.5-bin-x64.tar.gz /data/
cd /data
tar -zxf apache-doris-4.0.5-bin-x64.tar.gz
mv apache-doris-4.0.5-bin-x64 doris
chown -R doris:doris /data/doris
rm -f apache-doris-4.0.5-bin-x64.tar.gz解压后的目录结构:
/data/doris/
├── fe/ # Frontend
│ ├── bin/ # start_fe.sh, stop_fe.sh
│ ├── conf/ # fe.conf
│ └── lib/ # jar 包
├── be/ # Backend
│ ├── bin/ # start_be.sh, stop_be.sh
│ ├── conf/ # be.conf
│ └── lib/ # so 库
└── ms/ # Meta Service(存算分离才用)启动 FE
在 FE 节点上执行:
bash
# 安装 MySQL 客户端(后续注册 BE 和日常管理需要)
yum install -y mariadb105
FE_HOME=/data/doris/fe
# 元数据目录放到数据盘(避免撑满系统盘)
mkdir -p /data/doris-meta
ln -sfn /data/doris-meta ${FE_HOME}/doris-meta
# 追加配置(生产脚本应先检查避免重复追加)
cat >> ${FE_HOME}/conf/fe.conf << 'EOF'
priority_networks = 172.31.0.0/16
lower_case_table_names = 1
JAVA_HOME=/usr/lib/jvm/java-17-amazon-corretto
EOF
# 以 doris 用户启动
chown -R doris:doris /data
su - doris -c "${FE_HOME}/bin/start_fe.sh --daemon"启动后验证:
bash
# 等待约 10 秒后检查
mysql -uroot -P9030 -h127.0.0.1 -e "show frontends\G"看到 Alive: true 和 IsMaster: true 表示 FE 启动成功。
启动 BE
在每台 BE 节点上执行:
bash
BE_HOME=/data/doris/be
# 数据目录放到数据盘
mkdir -p /data/doris-storage
ln -sfn /data/doris-storage ${BE_HOME}/storage
cat >> ${BE_HOME}/conf/be.conf << 'EOF'
priority_networks = 172.31.0.0/16
storage_root_path = /data/doris-storage
JAVA_HOME=/usr/lib/jvm/java-17-amazon-corretto
EOF
chown -R doris:doris /data
su - doris -c "${BE_HOME}/bin/start_be.sh --daemon"注册 BE 并验证集群
回到 FE 节点,将 BE 注册到集群:
bash
# 逐个注册(9050 是 BE 的心跳端口)
mysql -uroot -P9030 -h127.0.0.1 -e "ALTER SYSTEM ADD BACKEND '172.31.x.x:9050';"
mysql -uroot -P9030 -h127.0.0.1 -e "ALTER SYSTEM ADD BACKEND '172.31.y.y:9050';"
# 验证所有 BE 状态
mysql -uroot -P9030 -h127.0.0.1 -e "select Host, Alive, TabletNum from backends();"所有 BE 的 Alive 为 1 即表示集群就绪。创建一张测试表验证端到端:
sql
CREATE DATABASE testdb;
CREATE TABLE testdb.test_table (
k1 INT,
k2 VARCHAR(50)
)
DISTRIBUTED BY HASH(k1) BUCKETS 32
PROPERTIES ("replication_num" = "2"); -- 2 台 BE,副本数不能超过 BE 数量
INSERT INTO testdb.test_table VALUES (1, 'hello');
SELECT FROM testdb.test_table;注意事项
- 副本数与 BE 数量的关系:Doris 默认 3 副本,如果 BE 少于 3 台,建表时必须显式指定
replication_num,否则会报错 - 扩缩容代价大:新增 BE 后数据不会自动均衡,需要执行
ALTER SYSTEM DECOMMISSION BACKEND触发数据迁移,过程耗时且占用网络带宽 - 部署完成后立即修改 root 密码:Doris 默认 root 无密码,任何能访问 9030 端口的人都可以执行任意 SQL
sql
SET PASSWORD = PASSWORD('your_strong_password');基于S3存算分离部署
从 Doris 3.0 开始,官方推出了存算分离架构。核心变化是:BE 不再存储数据,数据持久化到 S3。BE 退化为纯计算节点,本地磁盘仅用作热数据缓存。
这个架构引入了两个新组件:
-
FoundationDB(FDB):一个分布式 KV 数据库,用于存储 Doris 的元数据(类似 Hive Metastore 背后的 MySQL)
-
Meta Service(MS):元数据管理服务,FE 和 BE 通过它访问 FDB(类似 Hive Metastore 服务本身)
┌─────────────┐ │ S3 Bucket │ 数据持久层 └──────┬──────┘ │ ┌─────────────────┼─────────────────┐ │ │ │ ┌─────┴─────┐ ┌─────┴─────┐ ┌─────┴─────┐ │ FDB + MS │ │ BE-1 │ │ BE-2 │ │ + FE │ │ 计算+缓存 │ │ 计算+缓存 │ └───────────┘ └───────────┘ └───────────┘
为什么选 FoundationDB 而不是 MySQL?因为 FDB 提供严格的 ACID 事务和极高的写入吞吐,能支撑 Doris 元数据的高频更新(每次 compaction、tablet 迁移都会产生元数据变更)。
关键配置
存算分离模式下,FE 和 BE 的配置都需要额外指定 deploy_mode = cloud:
fe.conf 新增配置:
properties
deploy_mode = cloud
# 集群唯一标识,同一 Meta Service 下可运行多个逻辑集群
cluster_id = <随机生成的整数>
# Meta Service 地址
meta_service_endpoint = <ms_ip>:5000be.conf 新增配置:
properties
deploy_mode = cloud
# 本地文件缓存,加速热数据访问
file_cache_path = [{"path":"/data/file_cache","total_size":85899345920}]
meta_service_endpoint = <ms_ip>:5000file_cache_path 中的 total_size 单位是字节。这里设置 80GB(约 85899345920 字节),在 100GB 的数据盘上为 BE 日志和安装文件预留了空间。缓存采用 LRU 策略,热数据命中缓存时性能接近本地存储。
Storage Vault 是存算分离架构的核心概念------它定义了数据实际存储的位置:
sql
CREATE STORAGE VAULT IF NOT EXISTS s3_vault PROPERTIES (
"type" = "S3",
"s3.endpoint" = "s3.cn-north-1.amazonaws.com.cn",
"s3.region" = "cn-north-1",
"s3.bucket" = "your-bucket",
"s3.root.path" = "doris-data",
"s3.access_key" = "<AK>",
"s3.secret_key" = "<SK>",
"provider" = "S3"
);
SET s3_vault AS DEFAULT STORAGE VAULT;中国区 Doris 的 C++ S3 SDK 不支持 Instance Profile 和 Assume Role。原因是 SDK 内部做 STS 调用时硬编码了全球区的 sts.amazonaws.com endpoint,而中国区的 STS endpoint 是 sts.cn-north-1.amazonaws.com.cn,两者不互通。
因此在中国区必须使用 AK/SK 认证。安全建议:
- 创建专用 IAM User,不要复用管理员账号
- 最小权限原则:仅授予对特定 S3 Bucket 的读写权限,避免使用
AmazonS3FullAccess - 通过环境变量传递凭证,不要写在命令行参数中(会暴露在进程列表和 shell 历史中)
- 定期轮换 AK/SK
bash
# 正确做法:通过环境变量传递
export AWS_ACCESS_KEY_ID=<your_ak>
export AWS_SECRET_ACCESS_KEY=<your_sk>
bash create_vault.sh部署流程
以 1 台 FDB+MS+FE 合并节点 + 2 台 BE 为例。通用初始化(OS 调优、JDK、数据盘、Doris 下载)与方案一完全相同,这里不再重复,只展开存算分离特有的步骤。
创建 EC2 实例
与方案一类似,区别在于 FE 节点需要同时承载 FDB 和 Meta Service:
bash
# FDB+MS+FE 合并节点:m6i.xlarge (4C/16G),数据盘 50GB
aws ec2 run-instances --region cn-north-1 \
--image-id ami-xxxx --instance-type m6i.xlarge \
--block-device-mappings '[
{"DeviceName":"/dev/xvda","Ebs":{"VolumeSize":20,"VolumeType":"gp3"}},
{"DeviceName":"/dev/xvdb","Ebs":{"VolumeSize":50,"VolumeType":"gp3"}}
]' \
--tag-specifications '[{"ResourceType":"instance","Tags":[{"Key":"Name","Value":"doris-fdb-ms-fe"}]}]' \
... # 其余参数同方案一安全组除了方案一的端口外,还需额外开放:
| 组件 | 端口 | 用途 |
|---|---|---|
| FoundationDB | 4500 | FDB 通信端口 |
| Meta Service | 5000 | MS BRPC 端口 |
所有节点通用初始化
与方案一完全相同:OS 调优 → JDK 17 → 数据盘格式化挂载 → 创建 doris 用户 → 下载解压 Doris 安装包。3 台节点可并行执行。
部署 FoundationDB
在 FDB+MS+FE 节点上执行。Doris 官方提供了 Tools 包,内含 FDB 7.1.38 的二进制和部署脚本,无需手动安装 FDB RPM。
bash
# 下载 Doris Tools 包
aws s3 cp s3://your-bucket/apache-doris-3.0.2-tools.tar.gz /tmp/
cd /tmp
tar -zxf apache-doris-3.0.2-tools.tar.gz
cp -r tools/fdb /data/fdb-deploy
cd /data/fdb-deploy配置 FDB 部署参数:
bash
LOCAL_IP=$(hostname -I | awk '{print $1}')
FDB_CLUSTER_ID=$(cat /dev/urandom | tr -dc 'a-zA-Z0-9' | head -c 8)
cat > fdb_vars.sh << EOF
DATA_DIRS=/data/fdb-data
FDB_CLUSTER_IPS=${LOCAL_IP}
FDB_HOME=/fdbhome
FDB_CLUSTER_ID=${FDB_CLUSTER_ID}
FDB_CLUSTER_DESC=dorisfdb
FDB_VERSION=7.1.38
CPU_CORES_LIMIT=2
MEMORY_LIMIT_GB=4
EOF
mkdir -p /data/fdb-data /fdbhomefdb_vars.sh 是 Doris Tools 中 fdb_ctl.sh 的配置文件,关键参数说明:
FDB_CLUSTER_IPS:FDB 节点 IP,多节点用逗号分隔FDB_CLUSTER_ID:集群唯一标识,随机生成即可FDB_VERSION:必须使用 7.1.x 系列,其他版本与 Doris Meta Service 不兼容CPU_CORES_LIMIT/MEMORY_LIMIT_GB:限制 FDB 资源使用,避免与同机的 FE 争抢
部署并启动:
bash
chmod +x fdb_ctl.sh
./fdb_ctl.sh deploy # 生成配置文件和目录结构
./fdb_ctl.sh start # 启动 FDB 进程
# 验证 FDB 状态
/fdbhome/bin/fdbcli -C /fdbhome/conf/fdb.cluster --exec "status"看到 Healthy 表示 FDB 正常运行。fdb.cluster 文件中保存了连接串(格式为 描述:ID@IP:4500),后续 Meta Service 会自动读取。
部署 Meta Service
仍在 FDB+MS+FE 节点上执行。Meta Service 是 Doris 安装包自带的组件,位于 /data/doris/ms/。
bash
# 自动从 FDB 配置文件读取连接串
FDB_CLUSTER=$(grep -v '^#' /fdbhome/conf/fdb.cluster | grep -v '^$' | tail -1)
MS_HOME=/data/doris/ms
# 写入 Meta Service 配置
cat > ${MS_HOME}/conf/doris_cloud.conf << EOF
brpc_listen_port = 5000
fdb_cluster = ${FDB_CLUSTER}
EOF
# 以 doris 用户启动
chown -R doris:doris /data/doris
su - doris -c "export JAVA_HOME=/usr/lib/jvm/java-17-amazon-corretto && ${MS_HOME}/bin/start.sh --daemon"doris_cloud.conf 只需要两个核心配置:监听端口和 FDB 连接串。Meta Service 启动后会自动在 FDB 中初始化元数据 schema。
bash
curl http://localhost:5000/MetaService/http/health
# 返回 OK 表示正常启动 FE(存算分离模式)
与方案一的区别在于 fe.conf 中需要额外配置 deploy_mode、cluster_id 和 meta_service_endpoint:
bash
FE_HOME=/data/doris/fe
CLUSTER_ID=$(echo $(($((RANDOM << 15)) | $RANDOM)))
yum install -y mariadb105
mkdir -p /data/doris-meta
ln -sfn /data/doris-meta ${FE_HOME}/doris-meta
cat >> ${FE_HOME}/conf/fe.conf << EOF
priority_networks = 172.31.0.0/16
lower_case_table_names = 1
JAVA_HOME=/usr/lib/jvm/java-17-amazon-corretto
# 存算分离核心配置
deploy_mode = cloud
cluster_id = ${CLUSTER_ID}
meta_service_endpoint = $(hostname -I | awk '{print $1}'):5000
EOF
chown -R doris:doris /data
su - doris -c "${FE_HOME}/bin/start_fe.sh --daemon"cluster_id 是逻辑集群标识。同一个 Meta Service 下可以运行多个逻辑集群(多租户),每个集群用不同的 cluster_id 区分。单集群场景下随机生成一个正整数即可。
bash
mysql -uroot -P9030 -h127.0.0.1 -e "show frontends\G"启动 BE(存算分离模式)
在每台 BE 节点上执行。与方案一的核心区别:没有 storage_root_path(不存数据),取而代之的是 file_cache_path(本地缓存)。
bash
MS_IP=<fdb-ms-fe节点的IP>
BE_HOME=/data/doris/be
mkdir -p /data/file_cache
cat >> ${BE_HOME}/conf/be.conf << EOF
priority_networks = 172.31.0.0/16
JAVA_HOME=/usr/lib/jvm/java-17-amazon-corretto
# 存算分离核心配置
deploy_mode = cloud
file_cache_path = [{"path":"/data/file_cache","total_size":85899345920}]
meta_service_endpoint = ${MS_IP}:5000
EOF
chown -R doris:doris /data
su - doris -c "${BE_HOME}/bin/start_be.sh --daemon"注册 BE
与一体化部署相同:
bash
mysql -uroot -P9030 -h127.0.0.1 -e "ALTER SYSTEM ADD BACKEND '<be1_ip>:9050';"
mysql -uroot -P9030 -h127.0.0.1 -e "ALTER SYSTEM ADD BACKEND '<be2_ip>:9050';"
mysql -uroot -P9030 -h127.0.0.1 -e "SHOW BACKENDS\G"BE 注册后会自动加入 default_compute_group。
创建 S3 Storage Vault
这是存算分离方案独有的步骤------告诉 Doris 数据存到哪里。凭证通过环境变量传递:
bash
export AWS_ACCESS_KEY_ID=<your_ak>
export AWS_SECRET_ACCESS_KEY=<your_sk>
CREATE STORAGE VAULT IF NOT EXISTS s3_vault PROPERTIES (
"type" = "S3",
"s3.endpoint" = "s3.cn-north-1.amazonaws.com.cn",
"s3.region" = "cn-north-1",
"s3.bucket" = "your-bucket",
"s3.root.path" = "doris-data",
"s3.access_key" = "<AK>",
"s3.secret_key" = "<SK>",
"provider" = "S3"
);
SET s3_vault AS DEFAULT STORAGE VAULT;验证:
bash
mysql -uroot -P9030 -h127.0.0.1 -e "SHOW STORAGE VAULTS\G"创建测试表验证端到端(存算分离模式下无需指定 replication_num,S3 保证持久性):
sql
CREATE DATABASE testdb;
CREATE TABLE testdb.test_table (
k1 INT,
k2 VARCHAR(50)
)
DISTRIBUTED BY HASH(k1) BUCKETS 16;
INSERT INTO testdb.test_table VALUES (1, 'hello');
SELECT FROM testdb.test_table;存算一体 vs 存算分离对比
| 维度 | 存算一体 | 存算分离 |
|---|---|---|
deploy_mode |
不设置 | cloud |
| 额外组件 | 无 | FoundationDB + Meta Service |
| BE 数据存储 | 本地 EBS(storage_root_path) |
S3 + 本地缓存(file_cache_path) |
| 副本策略 | 默认 3 副本,由 Doris 管理 | 由 S3 保证持久性,无需多副本 |
| 扩缩容 | 需数据迁移,耗时长 | BE 无状态,秒级扩缩 |
| 存储成本 | gp3 约 $0.08/GB/月 | S3 约 $0.023/GB/月,便宜约 70% |
| 运维复杂度 | 低 | 中(多了 FDB 和 MS) |
Multi-Catalog 湖仓联邦
这种场景下让 Doris 作为已有数据湖的查询加速层。Doris 通过 Multi-Catalog 功能直接挂载外部数据源的元数据(AWS Glue Data Catalog 或 Hive Metastore),然后用自身的向量化引擎直接读取 S3 上的数据文件。
┌──────────┐ ┌──────────────────┐ ┌───────────┐
│ Doris FE │────→│ AWS Glue Catalog │ │ S3 Bucket │
│ SQL 解析 │ │ 表/库元数据 │ │ 数据文件 │
└────┬─────┘ └──────────────────┘ └─────┬─────┘
│ │
▼ │
┌──────────┐ │
│ Doris BE │────────────────────────────────────┘
│ 向量化查询 │ 直接读取 Parquet / ORC / Iceberg
└──────────┘这个方案的最大优势是零数据搬迁。如果已经有一个成熟的 EMR 数据湖(Spark/Hive 写入 S3,元数据在 Glue),只需一条 SQL 就能让 Doris 读到所有数据。
创建 Glue Catalog
sql
CREATE CATALOG glue_catalog PROPERTIES (
'type' = 'hms',
'hive.metastore.type' = 'glue',
'glue.region' = 'cn-north-1',
'glue.endpoint' = 'https://glue.cn-north-1.amazonaws.com.cn',
'glue.access_key' = '<AK>',
'glue.secret_key' = '<SK>'
);几个要点:
type = 'hms'表示使用 Hive Metastore 兼容协议,Doris 通过这个协议与 Glue 交互hive.metastore.type = 'glue'告诉 Doris 后端是 Glue 而非传统的 Thrift HMS- Glue 和 S3 的认证共用一套 AK/SK(Doris 3.1+ 版本),无需分别配置
s3.参数 - 中国区同样只能用 AK/SK,不支持 IAM Role
对于 Iceberg 表,需要使用 Iceberg Catalog 类型:
sql
CREATE CATALOG iceberg_glue PROPERTIES (
'type' = 'iceberg',
'iceberg.catalog.type' = 'glue',
'warehouse' = 's3://your-bucket/iceberg-warehouse',
'glue.region' = 'cn-north-1',
'glue.endpoint' = 'https://glue.cn-north-1.amazonaws.com.cn',
'glue.access_key' = '<AK>',
'glue.secret_key' = '<SK>'
);使用方式
Multi-Catalog 的使用体验非常自然,就像 MySQL 的多数据库切换:
sql
-- 切换到数据湖
SWITCH glue_catalog;
SHOW DATABASES;
SELECT FROM lake_db.events WHERE dt = '2026-04-21' LIMIT 100;
-- 跨 Catalog 联合查询:Doris 内部表 JOIN 数据湖表
SELECT a.user_id, b.event_name
FROM internal.app_db.users a
JOIN glue_catalog.lake_db.events b ON a.user_id = b.user_id
WHERE b.dt = '2026-04-21';跨 Catalog JOIN 是 Doris 的杀手级特性,用户可以在一条 SQL 中同时查询 Doris 内部表和数据湖表,Doris 会自动优化执行计划。
适用场景
- 已有成熟的 EMR/Glue 数据湖,需要亚秒级报表查询
- 不想搬迁数据,但现有的 Trino/Presto 查询性能不够
- 需要将实时数据(Doris 内部表)和离线数据(数据湖)做联合分析
生产环境注意事项
无论选择哪种方案,以下几点在生产环境中都需要关注:
高可用:FE 至少部署 3 个 Follower 节点(1 Master + 2 Follower),BE 至少 3 台。存算分离方案中 FDB 和 Meta Service 也应各部署 3 节点。
安全加固:
- 部署完成后立即修改 Doris root 密码
- 凭证(AK/SK)通过环境变量传递,不要出现在命令行参数、脚本文件或版本控制中
- 为 Doris 访问 S3/Glue 创建专用 IAM User,遵循最小权限原则
- 安全组仅开放必要端口,FE 的 9030 端口不要暴露到公网
监控:Doris FE 和 BE 都提供 HTTP 接口(默认 8030/8040),可以接入 Prometheus + Grafana 监控集群状态。
备份:存算一体方案中数据在本地 EBS,务必配置 EBS 快照策略。存算分离方案中数据在 S3,天然具备 11 个 9 的持久性,但 FDB 中的元数据仍需备份。