1. 定位导航
前面已经学习了分治、递归树和主方法。
这些内容都在帮助我们分析算法的运行时间。
接下来进入另一个重要思想:
text
随机化。随机化不是为了让算法变得不可控,而是为了避免算法总是被某些固定输入拖入最差路径。
一个典型例子是快速排序。
如果每次都固定选第一个元素作为主元,那么在某些输入下可能表现很差。
但如果每次随机选择主元,输入就很难稳定地"针对"算法。
2. 概念术语
| 术语 | 定义 | 举例 |
|---|---|---|
| 随机算法 | 执行过程中使用随机选择的算法 | 随机化快速排序 |
| 随机化 | 主动引入随机性改变执行路径 | 随机选择主元 |
| 确定性算法 | 同样输入下执行路径固定 | 固定选择第一个元素 |
| 期望运行时间 | 多次随机运行的平均运行时间 | 平均划分成本 |
| 坏输入 | 会触发算法差表现的输入 | 已有序数组对某些快速排序实现不友好 |
| Las Vegas 型 | 结果一定正确,运行时间随机 | 随机化排序 |
| Monte Carlo 型 | 运行时间可控,但结果可能小概率出错 | 部分随机测试 |
关键澄清:
- 随机算法不是随便乱做选择。
- 随机性通常只出现在关键决策点。
- 很多随机算法结果仍然是正确的,只是运行时间会随机波动。
- 分析随机算法时,经常看期望运行时间。
3. 为什么需要随机算法
确定性算法有一个特点:
text
同样输入下,它永远走同一条执行路径。这有好处:稳定、可复现。
但也有风险:如果某类输入刚好让这条路径很差,那么算法每次都会很差。
随机算法的思路是:
text
不让输入完全决定算法路径,而是在算法内部主动加入随机选择。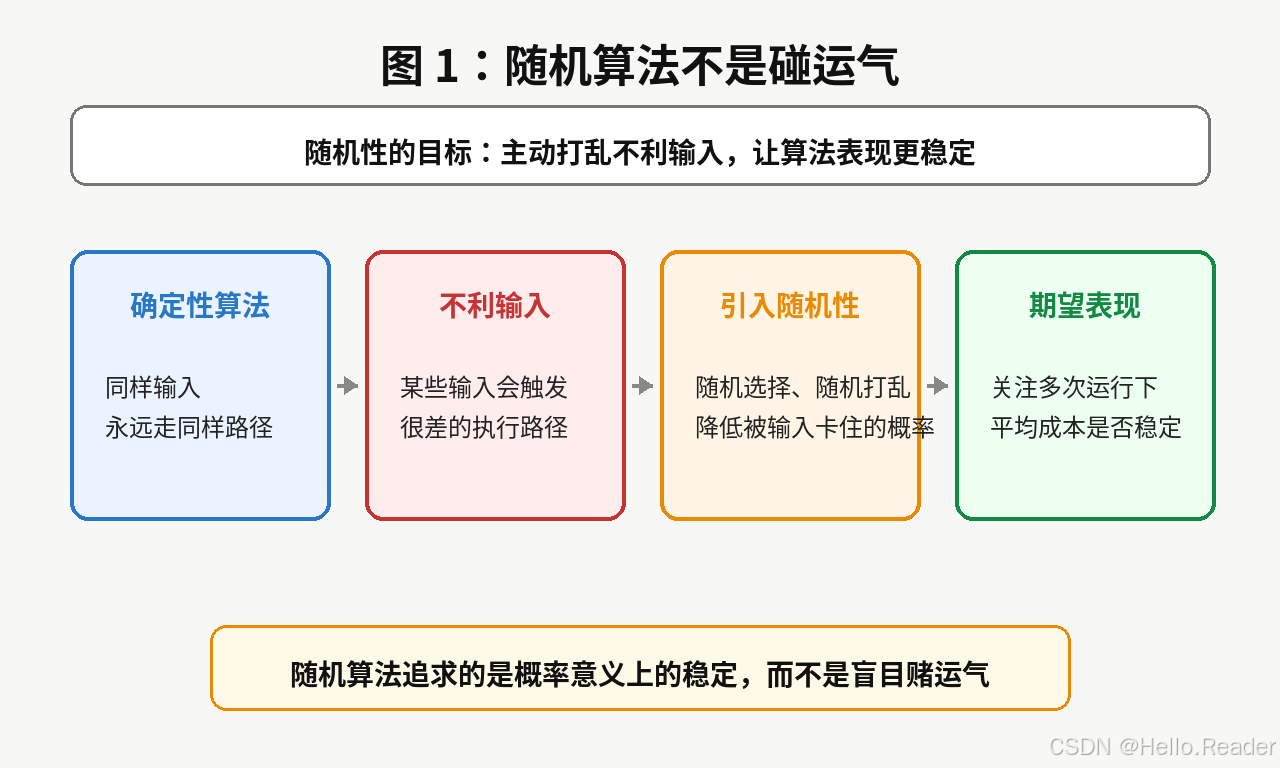
随机性的作用不是让结果变得混乱,而是让算法不容易被固定输入"卡死"。
4. 确定性算法的问题
假设一个排序算法每次都固定选择第一个元素作为划分点。
如果输入刚好是:
text
[1, 2, 3, 4, 5, 6, 7]每次选到的主元都可能导致很不均衡的划分。
这种情况下,递归树可能变得很高,运行时间变差。
确定性策略的问题在于:
text
只要输入模式固定,坏情况就会稳定重现。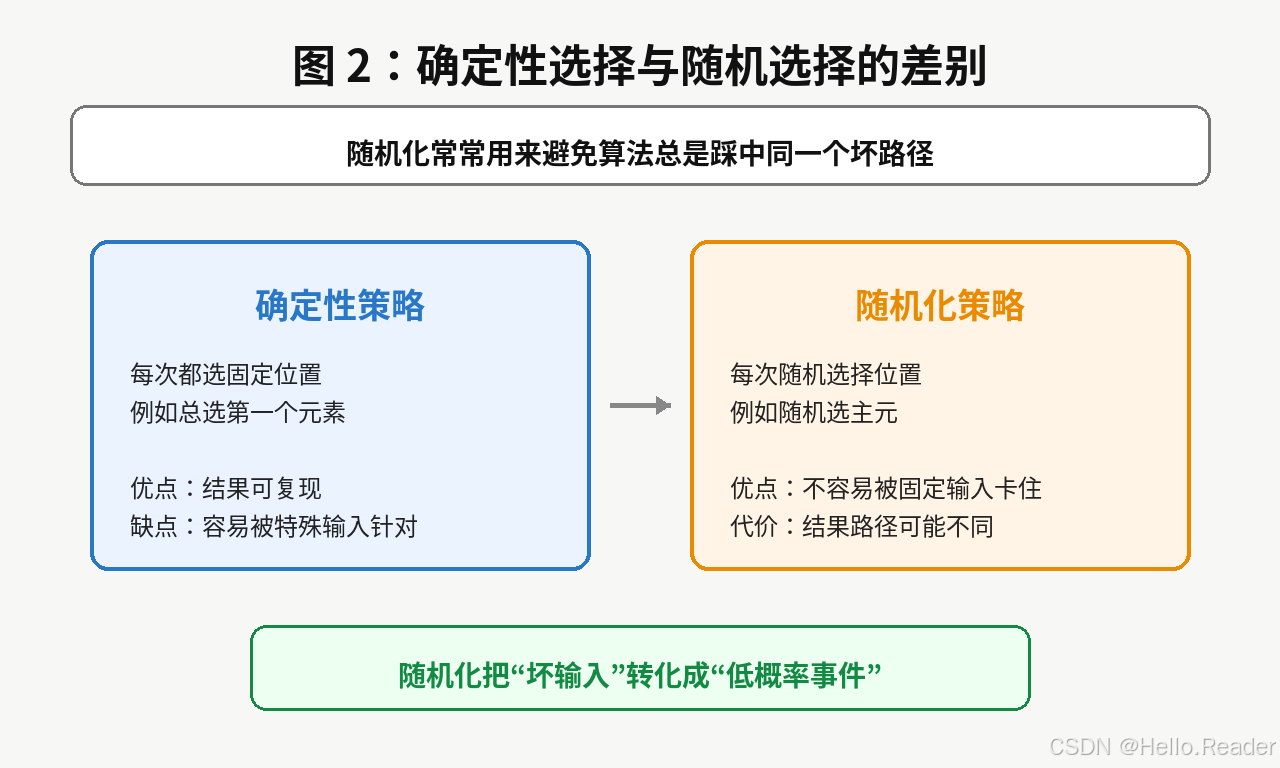
随机化策略则会让主元位置变化。
即使输入固定,执行路径也可能不同,从而降低连续踩中坏划分的概率。
5. 随机性通常加在哪里
随机算法不是在所有地方都随机。
通常只在关键决策点加入随机性。
常见位置包括:
| 随机位置 | 作用 |
|---|---|
| 随机选择主元 | 避免快速排序总选到坏主元 |
| 随机打乱输入 | 把输入顺序的影响打散 |
| 随机采样 | 用较小样本估计整体情况 |
| 随机哈希 | 降低冲突被针对的概率 |
| 随机重试 | 避免固定路径失败 |
这些随机选择的目标都是类似的:
text
让算法不要过度依赖某个固定输入形态。6. 动态推演:随机选择主元
下面用动态图看一个简单例子。

假设数组是:
text
[9, 1, 8, 2, 7, 3, 6]如果每次都固定选第一个元素,主元就是 9。
但如果随机选择,主元可能是:
text
9、7、8、2 ...这样做的目的不是保证每次都选到最好主元,而是降低每次都选到最差主元的概率。
7. 期望运行时间
随机算法的运行时间可能每次不一样。
所以分析它时,不能只看单次结果,而要看:
text
多次运行的平均表现。这就是期望运行时间。
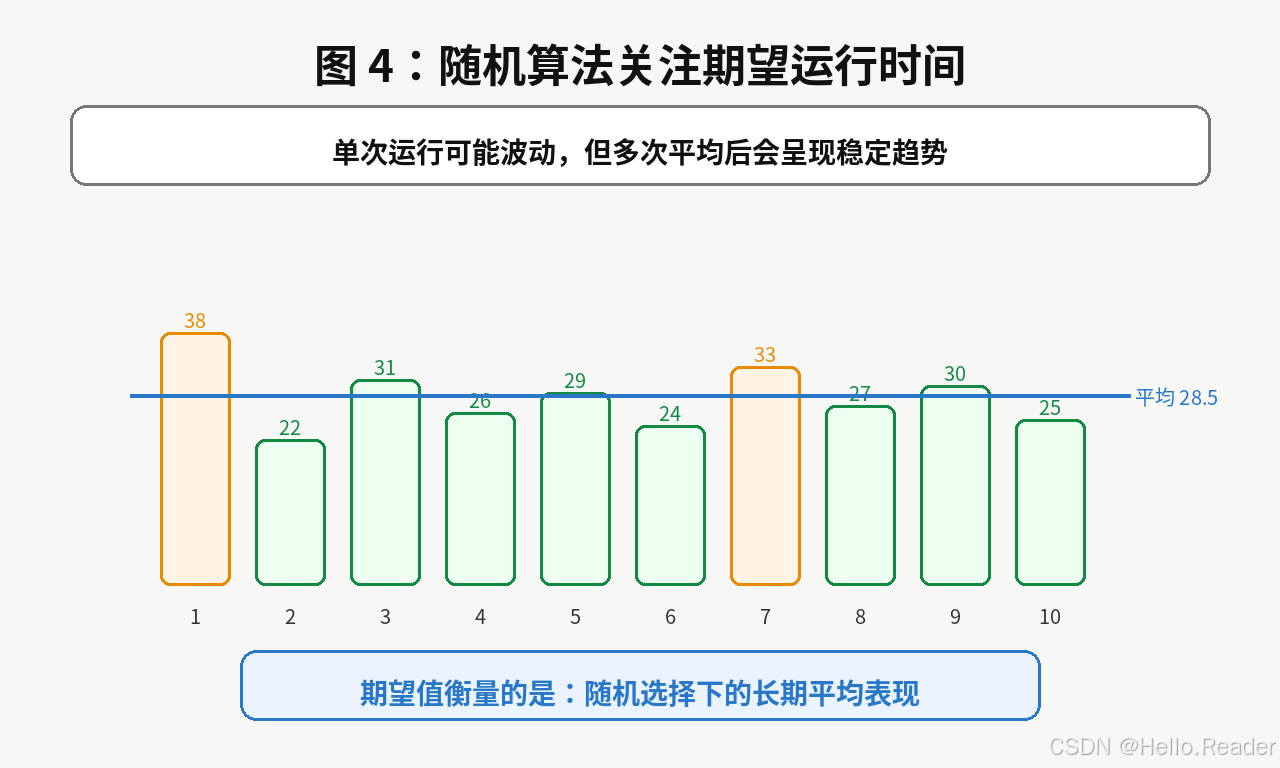
比如某个随机算法运行 10 次,成本分别是:
text
38, 22, 31, 26, 29, 24, 33, 27, 30, 25单次结果有波动,但平均值可能比较稳定。
随机算法的分析重点通常是:
text
期望运行时间是否足够好?
坏情况发生概率是否足够低?8. 两类随机算法
随机算法常见有两种视角。

8.1 Las Vegas 型
这类算法的特点是:
text
结果一定正确,但运行时间是随机的。随机化快速排序可以从这个角度理解。
它最终一定能排好序,但因为主元选择不同,运行时间可能不同。
8.2 Monte Carlo 型
这类算法的特点是:
text
运行时间通常可控,但结果可能有小概率错误。这类算法常用于快速测试、近似判断、随机采样等场景。
入门阶段可以先重点理解第一类:结果正确,时间随机。
9. 代码实践:随机选择主元
下面用 Python 演示随机选择主元。
python
import random
def randomized_partition_demo(nums):
arr = nums[:]
pivot_index = random.randint(0, len(arr) - 1)
pivot = arr[pivot_index]
less = []
equal = []
greater = []
for x in arr:
if x < pivot:
less.append(x)
elif x > pivot:
greater.append(x)
else:
equal.append(x)
return pivot, less, equal, greater
nums = [9, 1, 8, 2, 7, 3, 6]
for _ in range(5):
pivot, less, equal, greater = randomized_partition_demo(nums)
print(f"pivot={pivot}")
print(f"less={less}")
print(f"equal={equal}")
print(f"greater={greater}")
print()可能输出:
text
pivot=7
less=[1, 2, 3, 6]
equal=[7]
greater=[9, 8]
pivot=2
less=[1]
equal=[2]
greater=[9, 8, 7, 3, 6]
pivot=8
less=[1, 2, 7, 3, 6]
equal=[8]
greater=[9]可以看到,同一个输入,多次运行可能选到不同主元,划分结果也不同。
这就是随机化执行路径的效果。
10. 常见误区
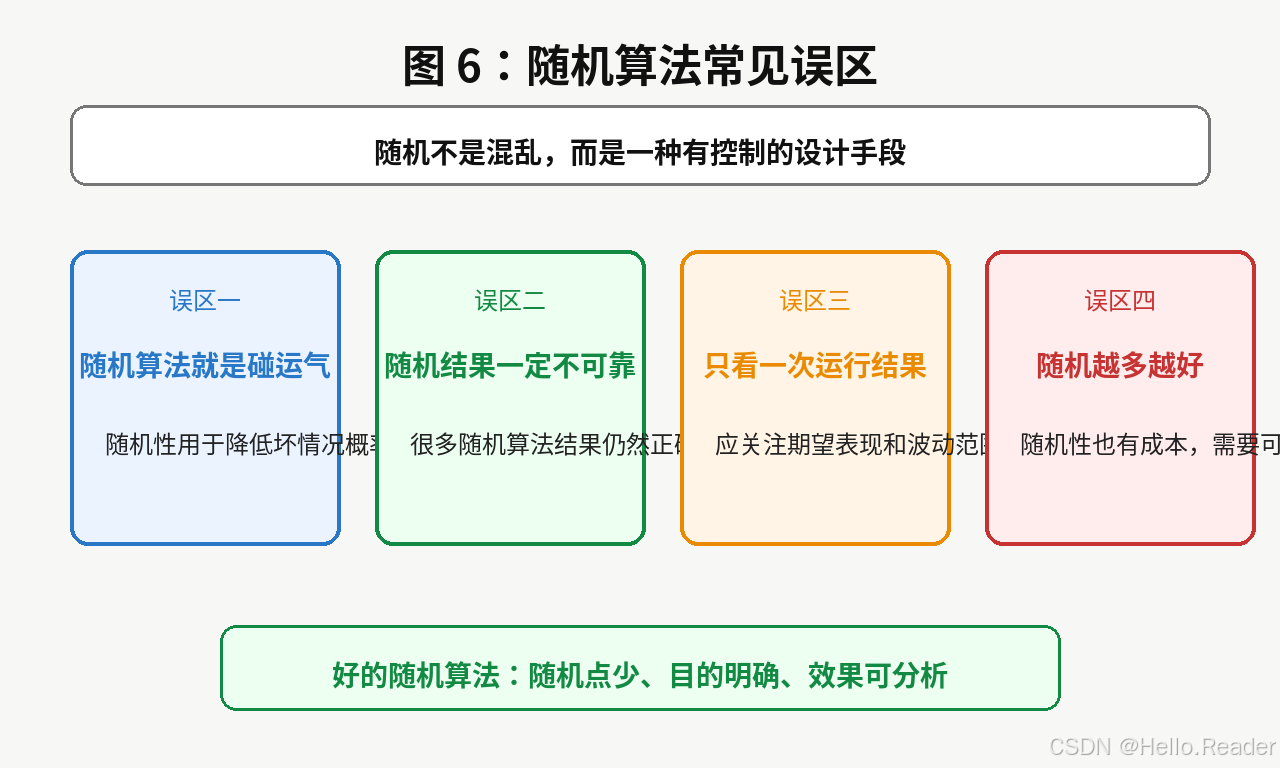
误区一:随机算法就是碰运气
不是。
好的随机算法会明确控制随机发生的位置,并能分析期望表现。
误区二:随机算法结果一定不可靠
不一定。
有些随机算法结果一定正确,只是运行时间随机。
例如随机化排序最终仍然会得到正确有序结果。
误区三:只看一次运行结果
随机算法单次运行可能波动。
要关注多次运行的平均表现,也就是期望运行时间。
误区四:随机越多越好
不是。
随机性也有成本,比如随机数生成、不可复现、调试困难。
真正好的随机化,是少量、关键、可分析的随机化。
11. 现代延伸
随机化思想在现代工程中非常常见。
| 场景 | 随机化作用 |
|---|---|
| 快速排序 | 随机主元降低坏划分概率 |
| 哈希表 | 随机哈希降低碰撞被针对概率 |
| 负载均衡 | 随机分配请求避免热点 |
| 抽样统计 | 用样本估计整体情况 |
| A/B 测试 | 随机分组降低偏差 |
| 机器学习 | 随机初始化、随机梯度下降 |
| 分布式系统 | 随机退避避免同时重试 |
例如分布式系统中,如果所有客户端失败后都立刻重试,可能造成雪崩。
加入随机退避后,每个客户端重试时间错开,就能降低瞬时压力。
这也是随机化思想的典型工程应用。
12. 思考题
- 为什么随机算法不是"碰运气"?
- 随机化快速排序为什么要随机选择主元?
- 什么是期望运行时间?
- Las Vegas 型随机算法和 Monte Carlo 型随机算法有什么区别?
- 在工程系统中,你见过哪些地方使用随机化来降低风险?
13. 本篇小结
本篇主要讲了随机算法的基础思想:
- 随机算法是在执行过程中主动使用随机选择;
- 随机性通常用于打散坏输入带来的固定风险;
- 随机算法不是乱来,而是有目的地降低坏情况概率;
- 分析随机算法时,经常关注期望运行时间;
- 有些随机算法结果一定正确,只是运行时间随机;
- 随机化思想在排序、哈希、负载均衡、机器学习、分布式系统中都很常见。
后面学习随机化快速排序时,要重点抓住一句话:
text
随机主元不是为了每次都选最好,而是为了不总是选到最差。