前言
RAG流程中,向量库是一个重要的节点。
- 离线流程:知识和信息 --> 向量嵌入(向量化) --> 存入向量库
- 在线流程:用户的提问 --> 向量嵌入(向量化) --> 在向量库中匹配
什么是向量?
什么是向量
概念:
向量(Vector)就是文本的 "数学身份证":它把一段文字的语义信息 ,转换成一串固定长度的数字列表 ,让计算机能 "看懂" 文字的含义并做相似度计算。
简单来说,就是让计算机更方便的理解不同的文本内容,是否表述的是一个意思。
例如这两句话:
- 如何快速学习RAG
- RAG如何快速学会
人类可能知道是一个意思,但是计算机却不知道
可以参考下图理解
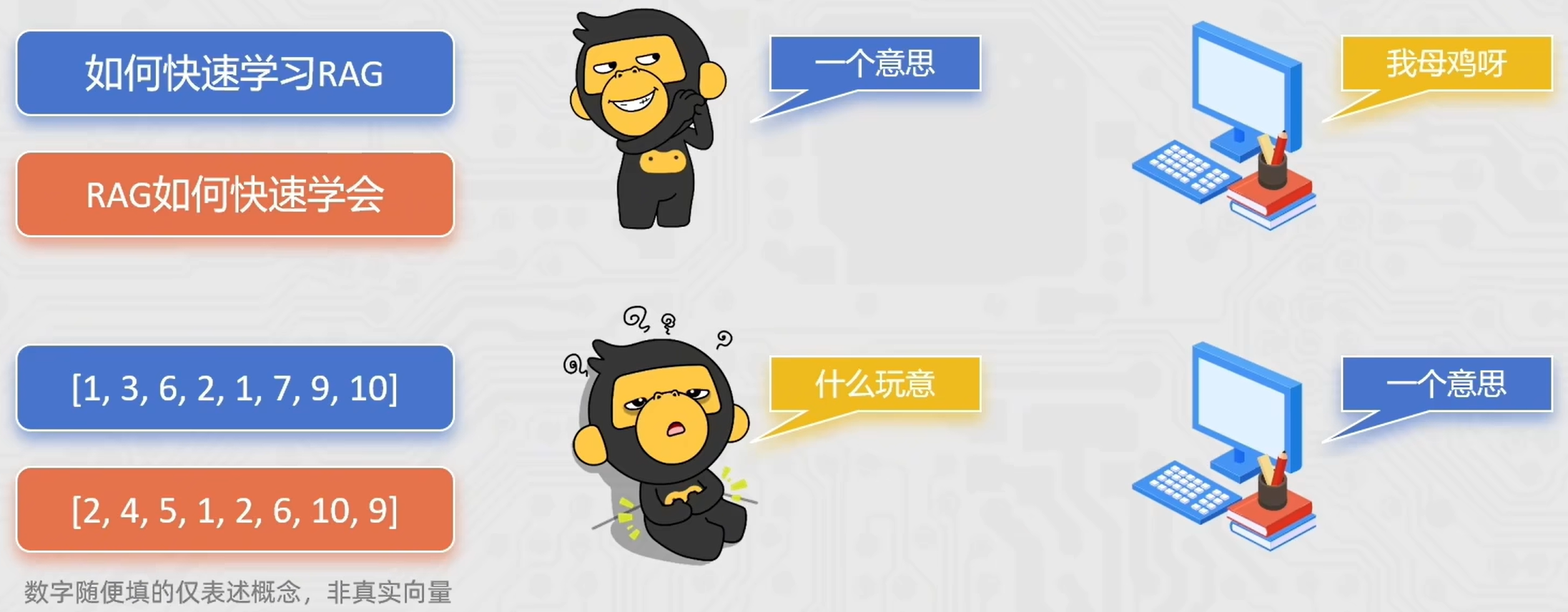
如何把文本转化为数字向量
通过文本嵌入模型 (如text-embedding-v1)通过深度学习等技术,从文本提取语义特征并映射为固定长度的数字序列。
具体原理这里不深究,因为会牵扯到深度学习。
只需要记得可以使用文本嵌入模型来实现即可
如何通过向量匹配每句话意义
在向量匹配的过程中,如何识别2段文本是否表述相似的含义,主要可以通过如余弦相似度等算法来完成。
比如(下列案例中向量为示例,仅描述概念,非真实向量):
- A: "如何快速学打篮球" → 0.2, 0.5, 0.8
- B: "打篮球怎么学得快" → 0.18, 0.52, 0.79
- C: "运动后吃什么好呢" → 0.9, 0.1, 0.2
通过余弦相似度算法可以计算得到:A和B相似度0.999789,A和C相似度0.361446,其中相似度越靠近1,相似度越高
由此可通过精确的数学计算,去匹配2段文本是否描述同一个意思,提高语义匹配的效率和精度。
向量维度
如何更为精准的完成语义匹配,生成向量的维度是一个很重要的指标。
如text-embedding-v1模型,可以生成1536维的向量(一段文本固定得到1536个数字序列),比较实用。
- 1536个数字表示,这段文本在1536个主题(抽象的语义特征)方向上的得分(强度)

- 生成向量的维度越多,就更好的记录文本的语义特征,做语义匹配会更加精准。
- 更多的向量会在计算、存储和匹配过程中,带来更大的压力。
选择合适的向量维度需要在精确和性能之间做平衡。
一般1536维算是比较好的选择。
这里有点抽象,后面还是需要再深入研究下
例如:一段文本是如何拆分成维度的,这个可能涉及到了模型底层了。。
总结
向量(Vector)就是文本的 "数学身份证"
它把一段文字的语义信息,转换成一串固定长度的数字列表,让计算机能"看懂" 文字的含义并做相似度计算。
- 向量的计算(文本嵌入过程),可借助文本嵌入模型实现,如text-embedding-v1
- 向量的匹配通过算法实现,如余弦相似度
- 向量的维度表示一段文本在多个抽象语义特征方面的强度
- 维度数代表模型用多少个抽象语义特征来描述文本
- 维度越多,做语义匹配越精准
- 但性能压力也会增大