这两年,业务相关一直在关注low level视觉领域的相关内容,NTIRE比赛是权威又全面。25年超分赛道百花齐放,值得关注。
原文链接https://arxiv.org/pdf/2506.02197
本次挑战赛的目标包括:(1)恢复存在模糊和噪声退化的RAW图像;(2)在未知噪声和模糊条件下,将RAW图像放大2倍。
一些想法
1.主流损失:
损失函数用charbonnier loss最多,有的加入frequency loss共同训练,
2.主流架构:
efficient赛道里面,第四章节nafnet\transformer\mamba的方案都有
第五章节也是,nafnet\transformer等的方案都有:
|--------------|-------------------------|-------------------|--------------|-----------------------------|
| 团队名称 | 模型名称 | 核心架构基座 | 损失函数 | 关键策略 |
| Samsung AI | ERIRNet-S/T | NAFNet | L1 Loss | 知识蒸馏 (Teacher: X-Restormer) |
| Miers | (Modified) SwinFIR-Tiny | Swin Transformer | Charbonnier | 四阶段渐进训练, 重参数化 |
| WIRTeam | Multi-PromptIR | Encoder-Decoder | - | 多尺度Prompt机制 |
| WIRTeam | LMPR-Net | MPRNet | Charbonnier | 多阶段结构, DO-Conv (轻量化) |
| ChickenRun | ER-NAFNet | U-Net (NAFBlocks) | L2 Loss | Mixup + Channel Shift 增强 |
在我们团队的实际工程应用中,基于cnn的nafnet这种结构在bpu/npu等边缘端部署非常有优势。
3.训练策略:
在实际工程应用中,将多个任务合并到一个模型中,是非常有用的提效策略,以前需要部署3个模型:超分,去噪,去模糊,现在一个模型就能搞定,对于节省算力至关重要,在这样的目标下,融合任务的同时进一步提升模型的效果,兼顾去噪的平滑度、去模糊的细节,所以训练策略显得尤为重要,在正确的训练策略的指导下,模型既能在结构上 "和多为一",又能在功能上"分而治之"!
策略一: 逐步进行,逐步增加模型复杂度

策略二:不同阶段使用不同损失,比如第一阶段用charbonnier loss,第二阶段用fft loss训练;这样不同阶段由损失引导模型倾向于不同目标
策略三: 逐步进行,逐步增加任务难度。

或者一阶段,先训练不加增强的模型,二阶段再加入bsraw等增强策略,思想也是类似的,逐步增加任务难度!
4. 提示学习:
----一个很好用,很灵活的思想,用起来方法可以五花八门,场景也可以很广泛,很值得关注。
《iterative prompt learning for unsupervised backlit image enhancement》--这篇是把提示学习用到了背光图像增强的任务,我们实际测试过效果不错。
《Multi-PromptIR: Multi-scale Prompt-base Raw Image Restoration》-这篇是本次比赛把提示学习用到了图像修复的任务
轻量化模型整理
1. 比赛中核心轻量化模型与架构
| 模型名称 | 所属团队/来源 | 核心轻量化技术与特点 |
|---|---|---|
| DSCLoRA | 传音多媒体 & 上海交大 | 卷积低秩适应 (Conv-LoRA):借鉴大模型微调技术,将 LoRA 模块嵌入预训练卷积层;结合知识蒸馏,在不增加推理计算成本的前提下提升性能。 |
| EMSR | 竞赛优胜方案 | Conv-LoRA + SPAN:结合了低秩更新和无参数注意力机制(Swift Parameter-free Attention);通过重参数化和网络剪枝实现极致轻量化(约26通道)。 |
| SMFFRaw | Team XJTU | HAFEB 模块:包含重参数化卷积(RepConv)和混合注意力;采用多阶段渐进式训练,在保持高性能的同时通过结构重参数化加速推理。 |
| NAFBN | Team NJU | BN 融合:基于 NAFSSR 改进,用 Batch Normalization 替换 Layer Normalization,推理时将 BN 层融合进卷积层,显著降低 FLOPs。 |
| ECAN | Team CUEE-MDAP | 深度可分离卷积 + SE Block:仅 93K 参数量;使用倒残差结构和通道注意力机制,专为极低资源设备设计。 |
| RepRawSR | Team EiffLowCVer | 重参数化设计:基于 SYEnet 二次开发,训练时多分支,推理时融合为单路卷积;包含 RepTiny(极轻量)和 RepLarge 两个变体。 |
2. 通用轻量化技术手段
除了具体的模型架构,参赛队伍还广泛使用了以下通用技术手段来压缩模型:
- 知识蒸馏 (Knowledge Distillation):利用大模型(教师模型)指导小模型(学生模型)学习,例如 DSCLoRA 和 Samsung AI 的方案,让小模型获得接近大模型的性能。
- 重参数化 (Re-parameterization):在训练时使用复杂的多分支结构(如多尺度卷积),在推理时将其数学等价转换为单路卷积,实现"训练强、推理快"。
RAW图像超分赛道-文章第四章
以下内容按团队分类整理了各方法的损失函数、模型结构和训练策略。
各团队方法详情
4.1 RawRTSR: Raw Real-Time Super Resolution (Team Samsung AI)
表格
| 维度 | 详细内容 |
|---|---|
| 模型结构 | 基于 CASR 改进,分为两个变体: 1. Efficient (RawRTSR) :最大特征通道数为 48 。包含去噪模块(下采样-卷积-上采样)和细节增强模块(5层卷积)。 2. General (RawRTSR-L) :通道数增加至 64 ,并引入 Channel Attention 机制防止信息冗余。 核心策略 :采用知识蒸馏 ,教师模型为 X-Restormer,学生模型使用重参数化卷积(Re-parameterized Conv)。 |
| 训练策略 | 三阶段训练 : 1. 独立训练 :教师和学生模型分别训练(800 epochs, 256x256 patches)。 2. 特征蒸馏 :使用第一阶段权重初始化,进行特征蒸馏(800 epochs)。 3. 最终训练 :使用 512x512 patches 进行训练。 参数:AdamW优化器,初始学习率 5e-4 (阶段1) / 5e-5 (阶段2)。 |
| 损失函数 | Stage 1 : �1L1 Loss。 Stage 2: �2L2 Loss (用于特征蒸馏)。 |
4.2 Streamlined Transformer Network... (Team USTC-VIDAR)
表格
| 维度 | 详细内容 |
|---|---|
| 模型结构 | 基于 RBSFormer 的轻量化流线型版本。 1. 主分支 :1个 3x3 卷积 + N个级联 Transformer 块 + 上采样块。 2. 残差分支 :仅包含上采样块。 3. 改进点 :采用 InceptionNeXt 块(部分卷积+深度卷积)替代自注意力,使用 ShuffleNet 策略减少 MLP 参数。 配置:N=8, 分组数 G=4。 |
| 训练策略 | 两阶段训练 : 1. Stage 1 :Batch Size=8, Patch Size=192, 训练 300k 步。 2. Stage 2 :Batch Size=64, Patch Size=256, 训练 147k 步。 增强 :随机水平/垂直翻转、转置。 降质:BSRAW 流水线 + 额外 PSF 核。 |
| 损失函数 | 组合损失函数 : Charbonnier Loss + Frequency Loss (权重 0.5)。 |
4.3 SMFFRaw: Simplified Multi-Level Feature Fusion... (Team XJTU)
表格
| 维度 | 详细内容 |
|---|---|
| 模型结构 | SMFFRaw 网络,包含三个部分: 1. 浅层特征提取 :3x3 卷积。 2. 深层特征提取 :堆叠 HAFEB (Hybrid Attention Feature Extraction Block) 模块。 - 模块内包含:PConv, DWConv, RepConv (推理时重参数化), CA, LKA。 3. 重建 :上采样 + 双线性插值输入残差连接。 变体:Small (0.18M params) / Large (1.99M params)。 |
| 训练策略 | 五阶段渐进式训练 (Progressive Training) : 逐步引入 Mixup、下采样、噪声、模糊等退化因素。 增强 :旋转、翻转、Mixup。 降质 :BSRAW 流水线。 参数:Cosine Annealing 调度器。 |
| 损失函数 | Stage 1-4 : Charbonnier Loss + Frequency Loss。 Stage 5 : MSE + Frequency Loss。 |
4.4 An Enhanced Transformer Network... (Team EGROUP)
表格
| 维度 | 详细内容 |
|---|---|
| 模型结构 | 基于 RBSFormer 架构。 1. 流程 :浅层特征提取 -> Transformer Blocks (深层特征) -> 3x3 卷积 -> 重建。 2. 设计 :保持 RBSFormer 的三组件结构,直接处理 RAW 图像的 RGGB 排列。 参数:3.3M 参数。 |
| 训练策略 | 端到端训练 。 参数 :Batch Size=8, Patch Size=192。 增强 :随机噪声和模糊退化模式。 硬件:2块 NVIDIA 4090 GPU。 |
| 损失函数 | 两阶段 Loss 切换 : 1. 前 100k 次迭代:L1 Loss 。 2. 后 20k 次迭代(微调):FFT Loss (频率域损失)。 |
4.5 A fast neural network... (Team NJU)
表格
| 维度 | 详细内容 |
|---|---|
| 模型结构 | 基于 NAFSSR 改进,命名为 NAFBN 。 1. 修改点 :重设计 Simple-Gate (CNN+GeLU),移除 FFN 组件。 2. 加速策略 :用 Batch Normalization (BN) 替换 Layer Normalization,以便在推理时融合到卷积层中。 3. 配置:12个 NAFBlocks,宽度为 48。 |
| 训练策略 | 单阶段训练 。 参数 :AdamW 优化器,Batch Size=未明确 (通常由平台决定),训练 50k 次迭代。 增强 :随机裁剪 (32x32)、随机白平衡、随机翻转/旋转、曝光调整、随机下采样 (AvgPool2d 或 Bicubic)。 注意:BN 的动量设为 0.03 以适应小 Batch。 |
| 损失函数 | L1 Loss。 |
4.6 A efficient neural network baseline report using Mamba (Team TYSL)
表格
| 维度 | 详细内容 |
|---|---|
| 模型结构 | 基于 MambaIRv2 的实现(首次用于RAW数据)。 1. 架构 :Embedding dim=32, m=4, n=2(极轻量级)。 2. 核心 :利用 Mamba 模型(State Space Model)的潜力。 3. 特殊设计 :提出了一种针对 Bayer 阵列的中心像素插值下采样法(区别于传统的 AvgPool2d 或 Bicubic)。 |
| 训练策略 | 端到端训练 。 参数 :Batch Size=64, 学习率 8e-4。 降质 :遵循官方流水线(除下采样外),未使用图像增强。 硬件:A100 GPU。 |
| 损失函数 | 文档中未明确列出(通常此类任务默认为 L1 或 MSE,但文中仅提及训练设置)。 |
4.7 RepRawSR: Accelerating Raw Image Super-Resolution... (Team EiffLowCVer)
表格
| 维度 | 详细内容 |
|---|---|
| 模型结构 | 基于 SYEnet 的二次开发,采用重参数化 设计。 1. RepTiny-21k (极轻量):4个特征提取模块,通道数 16,加入 Skip Connections 防止梯度消失。 2. RepLarge-97k :通道数 32,加入 FEBlock 预处理模块。 特点:训练时多分支,推理时融合为单路卷积。 |
| 训练策略 | 多尺度/多阶段策略 : 1. Stage 1 :256x256 patches, 100,000 步。 2. Stage 2 :384x384 patches, 50,000 步。 增强 :随机旋转、翻转。 技巧:训练时使用额外的"Tail"分支生成辅助图像以稳定训练(推理时移除)。 |
| 损失函数 | 文档中未明确列出(文中仅提及 "L1 loss" 出现在表格对比中,但正文未详述具体训练Loss,通常此类轻量模型用 L1)。 |
4.8 ECAN: Efficient Channel Attention Network... (Team CUEE-MDAP)
表格
| 维度 | 详细内容 |
|---|---|
| 模型结构 | CNN-based ,无外部预训练。 1. 结构 :浅层提取 -> 深层提取 (8个 EfficientResidualBlock ) -> 上采样 -> 重建。 2. Block设计 :倒残差结构(Inverted Residual)+ 深度可分离卷积 (Depthwise separable conv) + SE Block (Squeeze-and-Excitation) 用于通道注意力。 参数:仅 93K 参数。 |
| 训练策略 | 端到端训练 。 参数 :Batch Size=64, Patch Size=128x128, 训练 600 个 epoch。 增强 :旋转、翻转。 降质 :高斯模糊 ( �≤4.0σ≤4.0 ) + 高斯噪声 (level ≤0.04≤0.04 )。 技术:使用 Automatic Mixed Precision (AMP)。 |
| 损失函数 | L1 Loss (文中提及 "L1 Loss" 并配合梯度裁剪)。 |
RAW图像恢复-文章第五章
各团队方法简介
5.1 Efficient RAW Image Restoration (Team Samsung AI)
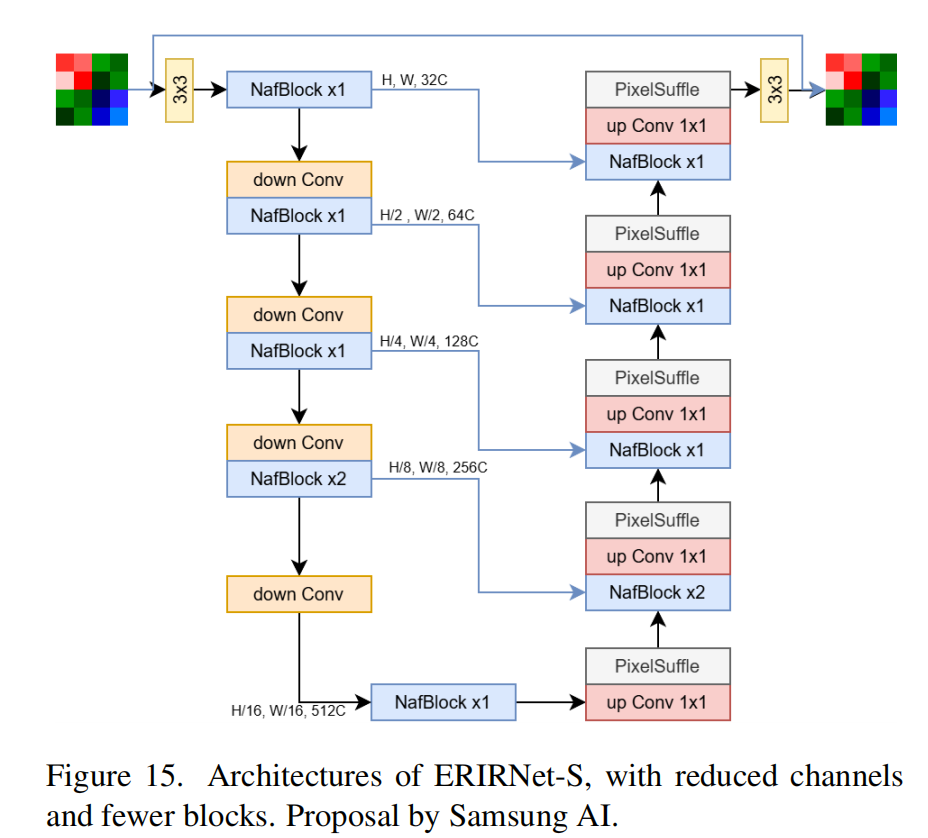
| 维度 | 详细内容 |
|---|---|
| 模型结构 | 基于 NAFNet 架构改进,设计了两个变体: 1. ERIRNet-S (General):简化版NAFNet,减少通道数和编解码块数量。 2. ERIRNet-T (Efficient):进一步减少Block数量,使用更小的FFN扩展比,将PixelUnshuffle替换为ConvTranspose以适应参数限制。 核心组件:NAFBlock(用于去噪和去模糊)。 |
| 训练策略 | 采用 三阶段训练策略: 1. 基础模型训练:独立训练两个变体。 2. 教师模型训练:训练基于 X-Restormer 的教师模型。 3. 知识蒸馏:利用教师模型指导 ERIRNet-S 和 ERIRNet-T 的训练。 参数设置:Batch Size=16, Patch Size=512x512, 使用 MultiStepLR 调度器。 |
| 损失函数 | L1 Loss (用于监督训练)。 |
5.2 Modified SwinFIR-Tiny for Raw Image Restoration (Team Miers)
| 维度 | 详细内容 |
|---|---|
| 模型结构 | 基于 SwinFIR-Tiny 改进。 1. 核心架构:包含 4个 RSTB (Residual Swin Transformer Blocks),每个包含 5或6个 HAB (Hybrid Attention Blocks)。 2. 改进点:引入 CAB (Channel Attention Block) 和 ConvRep5(重参数化卷积)模块。 3. 特征融合:聚合不同RSTB模块的输出以增强特征表达。 |
| 训练策略 | 四阶段渐进式训练: 1. 基线训练 (250K iters)。 2. 添加特征融合、通道注意力和ConvRep5 (170K iters)。 3. 引入CAB模块(零卷积)并增加噪声强度 (140K iters)。 4. 微调(降低学习率,减小Batch Size至2,增大输入尺寸至360x360)。 增强:使用 Mixup 数据增强。 |
| 损失函数 | Charbonnier Loss。 |
5.3 Multi-PromptIR: Multi-scale Prompt-base Raw Image Restoration (Team WIRTeam)
| 维度 | 详细内容 |
|---|---|
| 模型结构 | Encoder-Decoder 架构(4层)。 1. 核心组件:结合了 CNN 和 Transformer Blocks。 2. Prompt机制:包含 PGM (Prompt Generation Module) 和 PIM (Prompt Interaction Module)。 3. 多尺度信息:在编码阶段引入了下采样图像(1/2, 1/4, 1/8 尺寸)作为额外信息流。 |
| 训练策略 | 端到端(End-to-End)训练。 参数:训练 700 个 epoch,Batch Size 未明确提及(通常在DataLoader中处理),Patch Size=256x256。 增强:随机水平/垂直翻转。 硬件:1 * NVIDIA A100 (80G)。 |
| 损失函数 | 文档中未明确列出具体Loss名称,仅提及使用 AdamW 优化器。 |
5.4 LMPR-Net: Lightweight Multi-Stage Progressive RAW Restoration (Team WIRTeam)
| 维度 | 详细内容 |
|---|---|
| 模型结构 | 基于 MPRNet 改进。 1. 架构:多阶段(Multi-stage)结构,分解为多个子任务。 2. 组件:ORB (Original Resolution Block) 结合卷积和通道注意力提取跨通道特征。 3. 轻量化设计:隐藏维度设为 8,引入 Depthwise Over-parameterized Convolution (DO-Conv)。 4. SAM (Supervised Attention Module):在每个阶段精炼特征。 |
| 训练策略 | 端到端(End-to-End)训练。 参数:训练 600 个 epoch,Patch Size=256x256。 增强:水平和垂直翻转。 硬件:NVIDIA RTX 4090。 |
| 损失函数 | Charbonnier Loss(用于约束,避免图像过度平滑)。 |
5.5 ER-NAFNet Raw Restoration (Team ChickenRun)
| 维度 | 详细内容 |
|---|---|
| 模型结构 | U-Net 形状的架构。 1. 核心组件:NAFNet Block(非注意力特征网络)。 2. 结构细节:使用 SimpleGate 和 Simple Channel Attention (SCA) 模块。 3. 配置:宽度为16,编码器块 2, 2, 4, 8,解码器块 2, 2, 2, 2,中间块数为6。 4. 输入:4通道 RGGB RAW 数据。 |
| 训练策略 | 数据增强:结合了简单的水平/垂直翻转、Channel Shifts(通道移动)和 Mixup 增强。 参数:Batch Size=12, Patch Size=512, 总迭代次数 300,000。 降质模型:使用复杂的模糊和噪声降质流水线(AISP),包含暗电流噪声建模。 |
| 损失函数 | L2 Loss (MSE)。 |