26年5月来自上海交大和上海创智学院的论文"ARIS: Autonomous Research via Adversarial Multi-Agent Collaboration"。
本报告介绍 Aris(即"通过对抗性多智体协作实现的自主研究"),这是一个专为自主机器学习研究设计的开源研究框架。报告详细阐述其架构、保障机制以及早期的部署经验。基于大语言模型构建的智体系统的性能,不仅取决于模型的权重参数,还取决于其周边的"驾驭"(harness)------即负责管理应存储、检索及向模型呈现何种信息的系统逻辑。对于涉及长周期、跨时段的研究工作流而言,其核心的失效模式并非显而易见的系统崩溃,而是那种看似合理实则缺乏依据的"成功":一个长期运行的智体可能会产出某些论断,但这些论断的证据支持可能并不完整、存在误报,或者是在无形中继承执行智体预设的思维框架。鉴于此,将 Aris 设计为一个研究驾驭,旨在通过"跨模型对抗性协作"这一默认配置来协调机器学习研究工作流:由一个"执行模型"负责推动研究进程,同时建议引入一个来自不同模型家族的"审阅模型"来对中间产物进行批判性审视并提出修改建议。
Aris 的架构由三个层次构成:执行层提供超过 65 种可复用的、基于 Markdown 定义的技能;通过 MCP 实现模型集成;提供一个用于迭代复用既往研究发现的持久化研究 Wiki;并支持确定性的图表生成功能。编排层负责协调五种端到端的研究工作流,并允许用户调整资源投入程度以及配置向审阅模型进行任务路由的规则。保障层包含一套三阶段的流程,用于核验实验性论断是否具备充分的证据支持------具体包括:完整性验证、结果-论断的映射,以及针对手稿陈述内容与"论断查账"及原始证据进行交叉比对的论断审计;此外,该层还包含一套五轮迭代的科学编辑流水线、数学证明核验机制,以及对渲染后的 PDF 文档进行视觉检查的功能。此外,系统还内置一个原型化的"自我改进循环"机制,该机制能够记录研究过程中的各项轨迹数据,并据此提出针对驾驭本身的改进建议;这些改进建议仅在获得审阅智体的批准后方会被正式采纳。
如图所示:工作流 1 - 想法发现,工作流 1.5 - 实现和部署,工作流 2 - 主动评审环, 工作流 3 - 论文写作(从叙述初稿到精雕细琢PDF), 工作流 4 - 反驳(接收审阅意见,给出有理有据的回应)
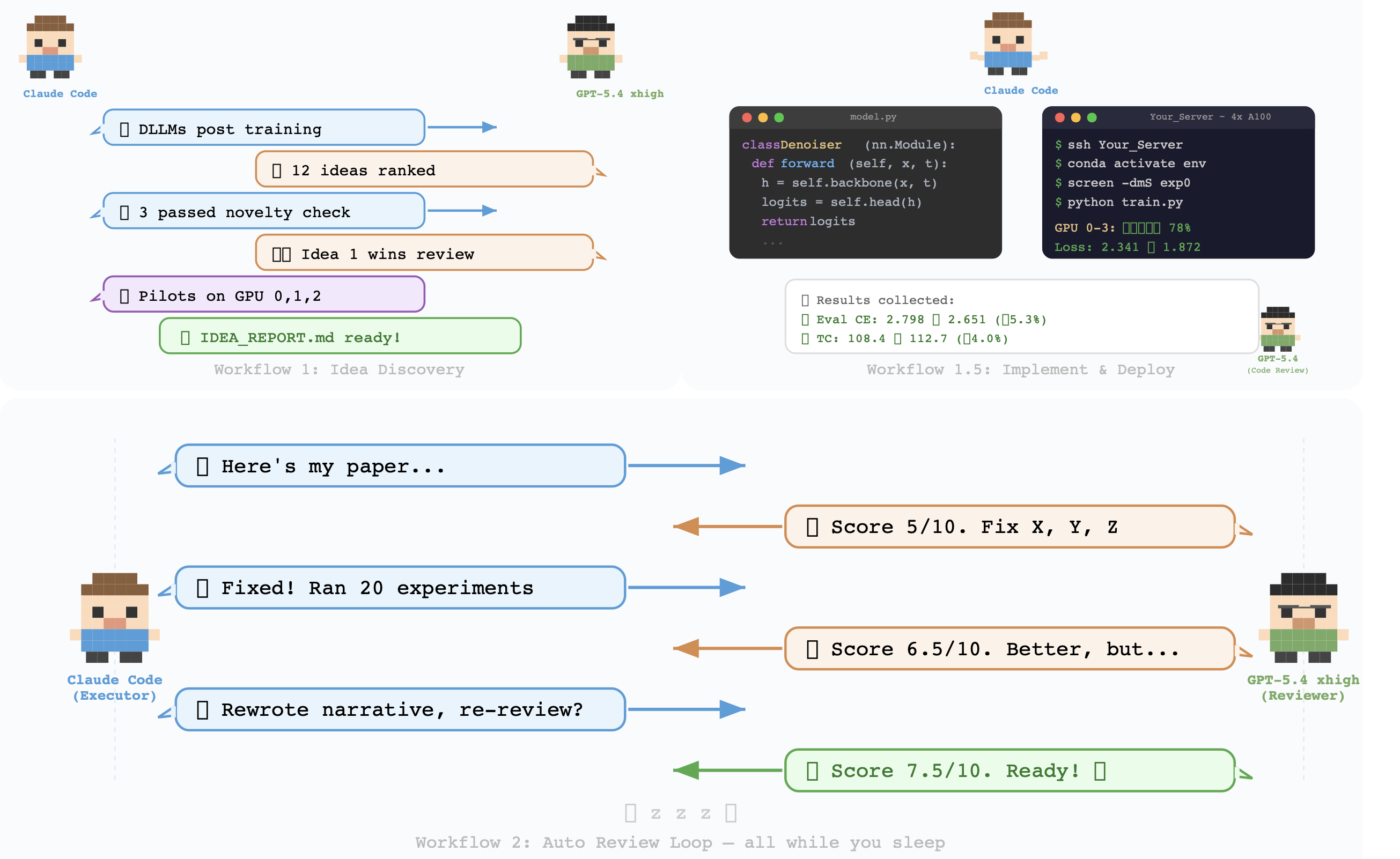


近期关于"驾驭工程"(harness engineering)的研究(Lee et al., 2026)表明,大语言模型(LLM)系统的性能在很大程度上不仅取决于模型权重,还取决于其"驾驭"------即负责管理数据存储、检索与呈现的周边系统逻辑。机器学习研究领域面临着一个异常复杂的套件工程难题:其工作流程涵盖从文献综述、假设生成,到实验验证、内部审阅、论文撰写,乃至对外部反馈进行回应的整个过程。在许多研究环境中,这一研究套件至今仍需人工组装:研究人员必须在相互独立的各个系统之间,协调计算资源、参考文献、论文撰写工具以及反馈处理流程(Lu et al., 2024; Schmidgall et al., 2025)。
目前,已有若干自主研究智体(agents)致力于解决这一工作流程中的特定环节。例如,"AI Scientist"(Lu et al., 2024)及其升级版"AI Scientist v2"(Yamada et al., 2025)实现从构思生成到论文初稿撰写的全流程自动化。"Agent Laboratory"(Schmidgall et al., 2025)则在工作流程中引入"人机协作"(human-in-the-loop)的检查点机制。然而,这些系统普遍存在三项反复出现的局限性,而正是这些局限性促成本文的设计理念:(1) 许多系统在执行任务和进行审阅时,均依赖于同一系列或紧密关联的模型家族------这体现一种效仿 Madaan et al. (2023) 和 Shinn et al. (2024) 思想的"同模型自优化"模式;这种模式的弊端在于,当内容生成模块与验证模块共享相同的归纳偏差(inductive biases)时,系统往往无法捕捉到那些相互关联的错误(这一弊端正是推动"异构多智体辩论"研究------如 Du et al., 2024; Liang et al., 2024a------诞生的动因);(2) 其工作流程呈现出紧耦合的端到端结构,导致难以单独替换流程中的特定阶段,也难以从已保存的中间状态处恢复任务;(3) 鲜有系统能够针对实验的完整性及论文的质量,提供明确且系统层级的检查机制。
随着当前智体在执行"长周期任务"(long-horizon tasks)方面的能力日益增强,如今已有可能仅凭一个直觉或一个基础构想,便开展完全自主化的研究工作。然而,若仅凭单一智体去执行此类长期且极具挑战性的任务,该智体往往会表现出"偷懒"(laziness)、产生"幻觉"(hallucinations),甚至呈现出具有欺骗性的行为。自主研究驾驭(harness)面临的核心风险,不仅在于彻底的失败,更在于那种看似合理却缺乏佐证的"成功":研究结果可能确为真事,却被错误地呈现;研究主张可能超出其所依据的证据范畴;而下游则可能在不知不觉中,全盘承袭执行者预设的认知框架。
驾驭工程与智体框架。Meta-Harness(Lee,2026)对驾驭代码的"外层循环搜索"过程进行形式化定义;而 Aris 则是一个经过人工精心构建的研究型驾驭(harness),其包含一个原型化的外层循环,可视为朝着该方向迈出的探索性一步。AutoGen(Wu,2023)、CAMEL(Li,2023)、OpenHands(Wang,2025)、SWE-agent(Yang,2024)、MetaGPT(Hong,2023)以及 ChatDev(Qian,2024)均为通用型智体框架或软件工程框架。相比之下,Aris 则专注于针对特定研究场景的工作流、具备域-觉察能力的技能定义,以及跨不同模型家族的"审查者与执行者分离"机制。下表 4 提供上述各项工具的结构化对比。

鉴于此,本文提出如下一条严格的假设:凡由单一智体(Agent)独立执行的长期任务,皆不可靠。因此,需要将整体工作流拆解为若干子工作流,并引入跨模型族(cross-family models)的协作机制,以便对每一个步骤的产出进行独立且客观的审查。
尽管这一假设可能低估当前智体的实际能力,但在像科学研究这样对严谨性要求极高的领域中,这种"宁严勿宽"的权衡取舍是值得的:引入一位"对抗性"的审查者,能够显著提升研究质量------即便这种对抗性审查会给执行者带来更为棘手的优化难题。不妨将此情境类比为"对抗性多臂老虎机"(Adversarial Bandits)与"随机性多臂老虎机"(Stochastic Bandits)之间的差异:单一模型进行的自我审查属于"随机性"情境(即回报中的噪声具有可预测性);而跨模型族进行的相互审查则属于"对抗性"情境(即审查者会主动探查执行者意料之外的薄弱环节)------从根本上讲,对抗性情境下的博弈难度要远高于随机性情境。此外,引入两个智体(即执行者与审查者)也是打破"自我博弈盲点"所需的最低配置;且相比于多方参与的 N 人博弈,双人博弈能够更高效地收敛至纳什均衡状态。
从操作层面来看,上述那条严格假设具体拆解为三大瓶颈(或曰必要条件)。首先,必须确立"持久化的研究状态"(i):若系统无法妥善保存那些串联起前后子工作流的"研究产物、决策记录、佐证证据及研究主张",那么所谓的"逐级审查"便将沦为无源之水、毫无意义。其次,必须实现"模块化的执行机制"(ii):漫长的研究历程必须被拆分为若干可替换的阶段,而不能被深埋于单一智体那条不透明、不可拆解的执行轨迹之中。第三,必须确保"独立的质量保障"(iii):审查者绝不能仅仅顺着执行者的既有逻辑继续推演,而必须从截然不同的模型族、情境策略或审计视角出发,对所生成的研究产物进行审视与检验。上述三项要素并非事后追加的额外需求,而是源于那条核心假设------即"默认视单一智体主导的长期研究为不可靠"------所必然导出的系统级设计要求。
针对上述挑战,Aris 框架采取如下应对策略:它将"质量保障"(Assurance)提升为工作流中的一个"一级核心层级",而非仅仅将其视为一次简单的末端审查环节;通过这种设计,它将"研究产物的生成"过程与"证据核查、主张映射及文稿审查"等环节彻底解耦。具体而言,系统中预置大量可复用的、基于 Markdown 格式定义的"技能模块";这些技能模块在默认的"跨模型族执行者/审查者"配对机制下协同运作,并在关键的实验阶段及文稿撰写阶段,嵌入明确且强制性的质量保障(审查)检查点。默认采用跨系列配对,因为既往研究表明,混合模型智体配置能够生成相关性较低且更具多样性的评论(Du et al., 2024; Liang et al., 2024a);将此作为一种推荐配置,而非强制性的系统约束。
依据 Lee (2026)提出的"驾驭工程"(harness-engineering)分类法,Aris 属于一种"研究驾驭"(research harness):这是一个有状态的系统,通过在研究工作流的各个阶段中选择并呈现给大语言模型(LLMs)的上下文、工具及反馈,来协调与这些模型之间的交互。如图 1 展示其"工作流库":该库包含五个工作流------构思探索、实验衔接、自动审阅、论文撰写及审稿答辩------这些工作流通过纯文本的"工件契约"(artifact contracts)相互串联,并被归类至四个研究阶段之下(即:探索阶段、实验阶段、文稿阶段及投稿后阶段)。
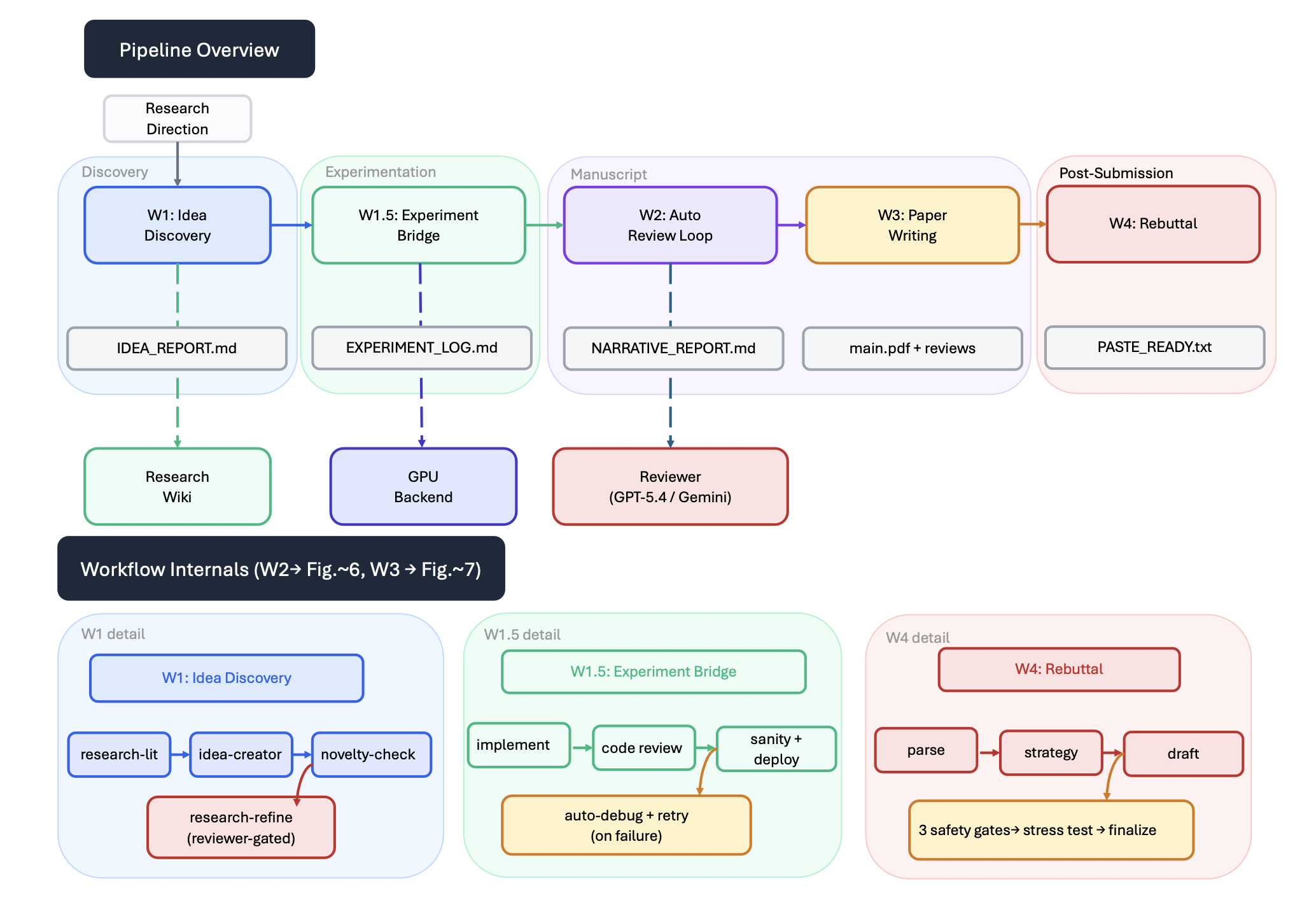
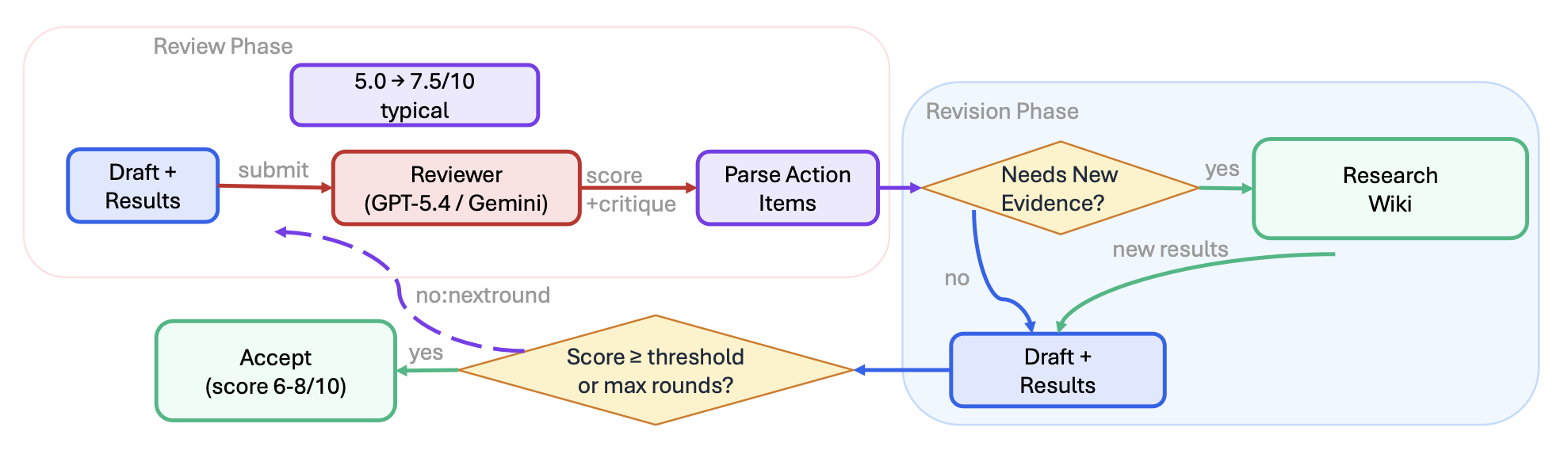
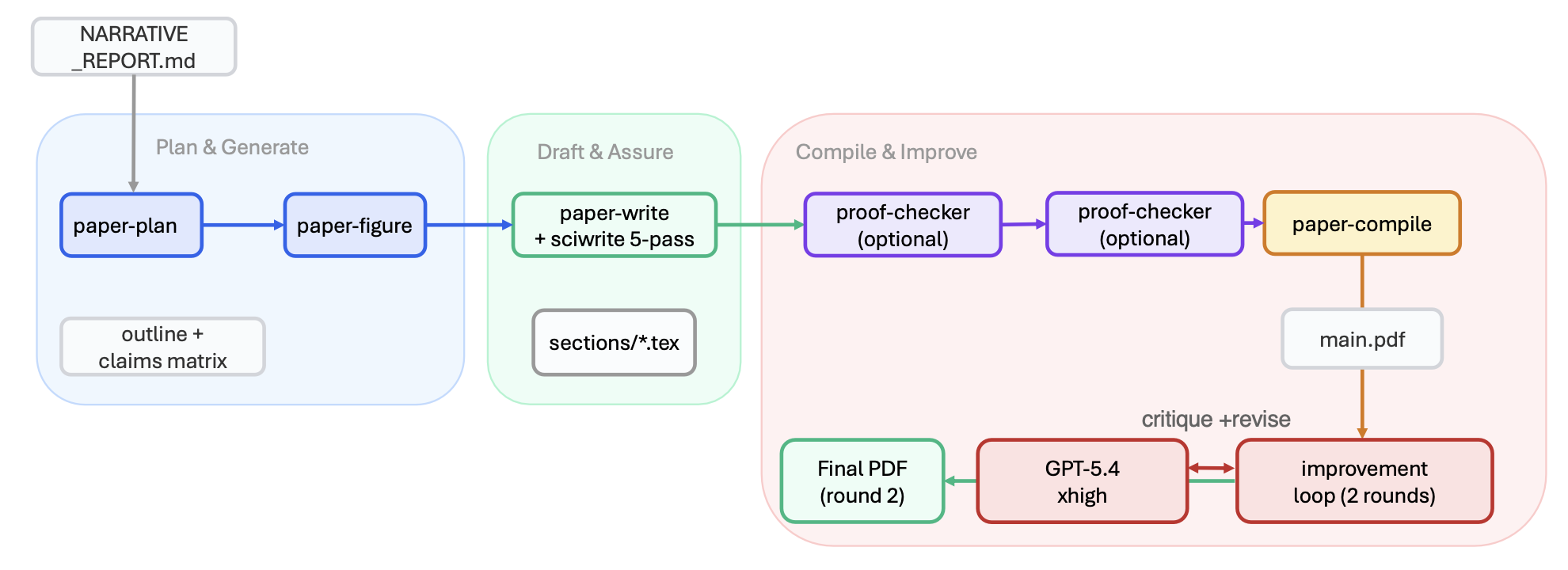
图 2 和图 3 聚焦展示两个对"保障性"(assurance)要求极高的工作流------即工作流 2(自动审阅循环)与工作流 3(论文撰写)。
如图 4 描绘该系统的三层架构,表 1 则对本报告所描述的系统实现细节进行归纳总结。
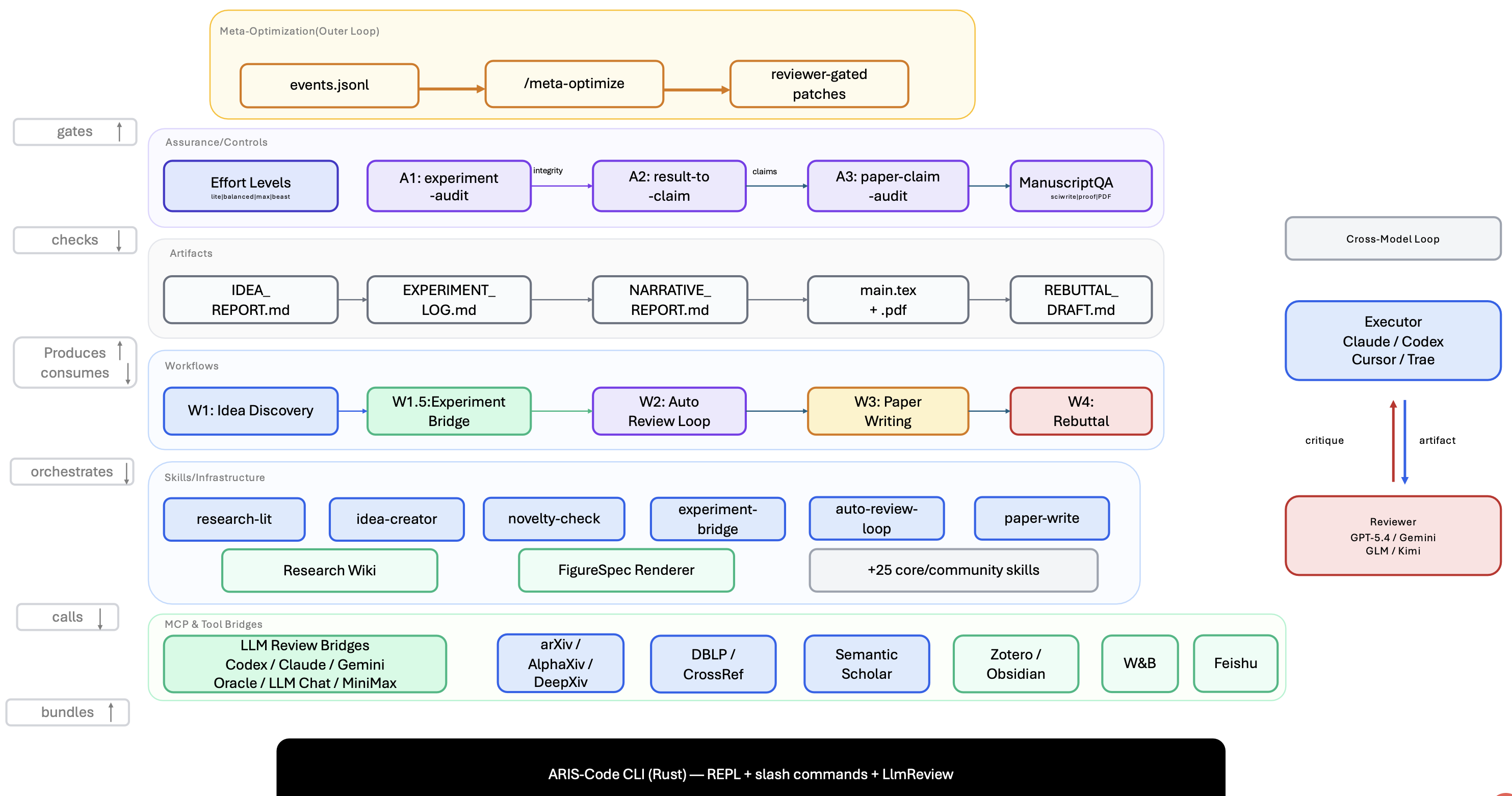

这些层级分别对应于三个瓶颈:持久化状态 (i) 通过"项目专属研究 Wiki"及"可版本化产物合约"来实现;模块化执行 (ii) 通过图1所示工作流所协调的、自包含的 Markdown 技能文件来实现;而独立保障 (iii) 则通过"保障层"来实现,该层运作于"跨模型族执行者/审查者配对"机制之下。
1 设计原则
Aris 的设计遵循五项原则。原则 (1)、(3) 和 (5) 分别具体落实瓶颈 (iii)、(ii) 和 (i);原则 (2) 是一种实现选择,旨在提升 (ii) 的易用性(人体工学);而原则 (4) 则是一项工程约束,确保上述控制机制能够在不同的执行环境中保持有效。
(1) 优先采用异构模型,而非单一模型的自我精炼。单一模型的自我精炼循环(Madaan,2023;Shinn,2024)中,其生成器与验证器共享相同的归纳偏差;相比之下,据报道,异构的多智体辩论机制能够激发比同构配置更为多元化的批判性意见(Liang,2024a;Du,2024)。Aris 默认将执行者与审查者配对为来自不同模型族的产品,并将其作为推荐配置。在此语境下,"模型族"特指共享同一模型谱系或由同一供应商提供的模型类别(例如,Claude 系列模型构成一个模型族;GPT 系列模型则构成另一个)。随产品发布并载入文档的默认配置方案是:选用 Claude 系列模型作为执行者,搭配 GPT 系列模型作为审查者(即 Codex MCP 或 Oracle MCP),反之亦可;此外,用户还可以通过专用的 MCP 桥接器配置 Gemini 或 MiniMax 模型,亦可通过表1所列的通用型、兼容 OpenAI 接口的 llm-chat 桥接器,将 GLM、Kimi 或 DeepSeek 等模型配置为审查者。
(2) 模块化的技能文件,而非单体式智体。每一项研究能力主要由一个 SKILL.md 文件定义;这是一个纯文本的 Markdown 规范,可被多个基于大语言模型(LLM)的编程智体所解析,从而支持独立开发、特定域的扩展以及组件层面的更新。
(3) 可组合性,而非固定的流水线。各项技能可以串联成工作流,支持针对单次调用的参数重写,并可通过检查点机制实现跨会话的恢复。
(4) 可移植性,而非厂商锁定。技能库以纯文本文件的形式分发,不依赖于特定平台的运行时环境;在当前的配置中,同一套 SKILL.md 文件无需进行任何文件层面的修改,即可在 Claude Code、Codex CLI 和 Cursor 等工具中通用。
(5) 持久化记忆,而非瞬时上下文。每个项目都维护着一份"研究维基"(Research Wiki),用于跨会话存储论文、构思、实验记录以及追踪的论断;这使得系统能够回顾并迭代先前的成果,而非在每次会话开始时都从一个无状态的提示词(Prompt)重新起步(Karpathy, 2026)。
2 跨模型对抗协作
其核心机制是一个"批评-行动"循环。执行器首先产出一个工件(如代码、文稿章节或实验设计)。随后,一名审阅者------根据推荐配置,该审阅者通常选自不同的模型家族------依据预定义的评分标准给出审阅分数,并返回结构化的行动项。执行器负责处理这些行动项;处理完毕后,系统会进行收敛性检查,以决定是继续运行下一轮循环,还是将该工件视为暂时符合要求予以接受。该循环在以下两种情况下终止:一是审阅分数超过预设阈值(默认为 6/10)且所有关键审阅问题均已解决;二是循环轮次达到预设的最大上限(默认为 4 轮)。
审阅者的独立性。执行器仅提供文件路径和审阅目标。随后,审阅者直接读取所引用的工件,并形成独立的评估意见。如果执行器预先对工件进行摘要归纳,审阅者便会转而评估执行器的归纳视角,而非工件本身的实质内容,从而增加产生"共同错误"(shared errors)的风险。这一协作协议已在共享协议文档中进行明确规定,凡是涉及审阅环节的各项技能(skills)均须严格遵照执行。
审阅者的访问权限与上下文策略。Aris 系统依据两个正交的维度来配置审阅者。第一个维度是"访问范围":仅文档级(审阅者仅读取文稿文本)、工件增强级(审阅者除文稿外,还读取结果文件等辅助工件),以及代码库级(审阅者通过代码库访问工具,直接检查代码库内容及生成的输出结果)。第二个维度是"上下文策略":全新会话(每一轮审阅均开启一个全新的线程,不保留上一轮的任何上下文信息,旨在防止"确认偏差")与跨轮次会话(审阅者在各轮次之间保留状态信息,并明确核查上一轮提出的问题是否已得到解决)。
自动调试与回退诊断。当实验执行失败时,系统会将该故障归入预定义的错误类别,继而应用针对该类别的特定修复策略,并进行重试操作,重试次数受可配置的上限约束(默认为 3 次)。在将某项审阅问题标记为"未解决"之前,执行器必须至少尝试两种不同的修复策略。若上述两次修复尝试均告失败,系统将启用第三个独立配置的模型,通过专门的"救援"环节提供独立的故障诊断意见。
如图 5 所示:
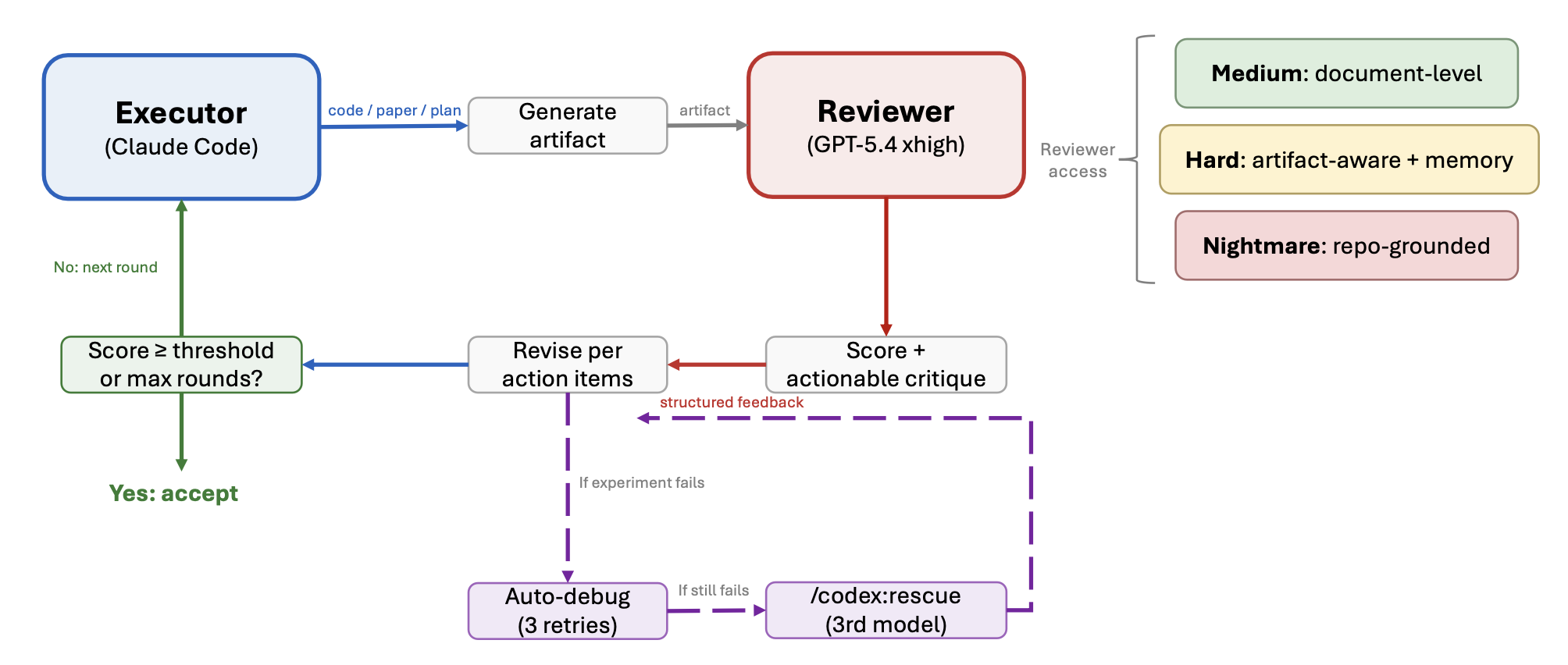
对抗性协作机制提供一个通用的审阅循环。直观来看,执行智体似乎只需基于文章内容与审阅智体进行对抗性交互即可。然而,实际情况要复杂得多。为了尽快提高同行评审得分,执行智体在交互过程中会利用各种手段试图蒙蔽审阅者。因此,需要建立一套严格的保障体系(assurance stack)。
Aris 为该审阅循环所增设的保障体系包含三个部分:针对实验完整性的三阶段"证据-主张"审计级联;针对文笔、论证及呈现质量的手稿保障层;以及两项系统级控制机制------"工作投入层级"与"审阅者路由"------用于设定审计深度及指定审阅者后端模型。
1 "证据-主张"审计级联
社区反馈及内部调试结果显示,执行智体可能会生成具有误导性的实验输出,具体表现包括:引用标签源自模型输出、指标数值经过"自我归一化"处理,以及提出的主张缺乏输出文件的实际支持。Aris 针对上述失效模式,设计一套三阶段的审计流程(如图6所示)。第一阶段负责审计评估过程的完整性;第二阶段负责将实验结果与手稿中明确提出的主张进行对应;第三阶段则利用独立的审阅者,依据原始数据及佐证材料,对文稿中的各项主张进行交叉验证------根据推荐配置,该审阅者所采用的模型族系应有别于执行智体所使用的模型族系。
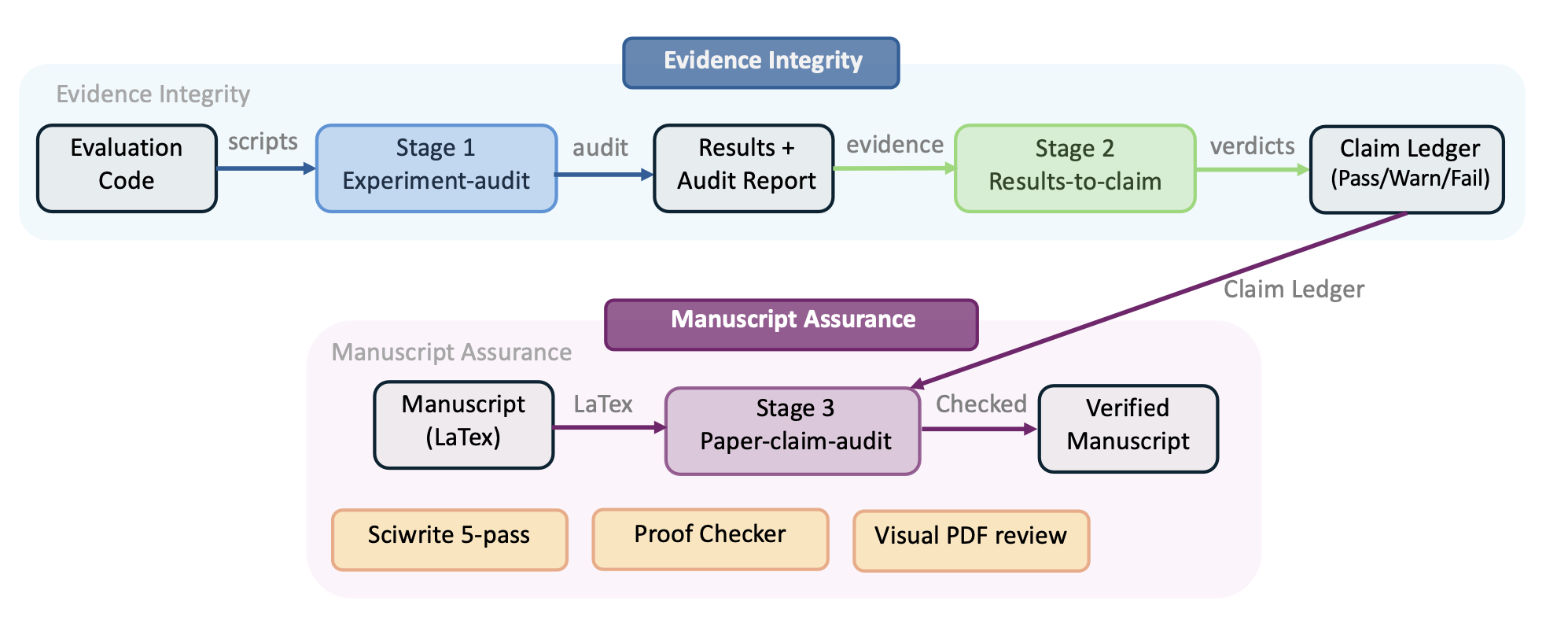
阶段 1:实验完整性审计(/experiment-audit)。由跨模型审阅者负责对评估代码及输出结果进行审计,重点排查以下几类完整性失效模式:(1) 模型衍生引用标签------即作为参照基准的目标标签并非取自数据集或已声明的外部来源,而是由模型输出结果反向合成而成;(2) 自我归一化得分------即在计算指标时,其分母项(归一化基准)源自模型自身的预测结果,从而可能导致报告的性能数据被虚高或扭曲;(3) 虚构结果------即文稿中声称的数值与实际生成的输出文件中的数据不相吻合;(4) "死代码"或闲置指标导致的虚增------即评估代码中定义额外的指标计算逻辑或分支代码,但这些代码在实际运行中从未被执行过,却被当作分析内容的一部分写入了文稿;(5) 范围过度泛化------即文稿中提出的主张其适用范围超出实际测试所涵盖的数据集、随机种子(seeds)或实验配置的边界。审计过程会生成一份结构化报告(EXPERIMENT_AUDIT.md)以及一份机器可读的 JSON 摘要。在工作流层面,此项审计仅起建议作用:它不会中断程序的执行,但下游阶段会将警告或失败状态传递至后续的断言判定环节。
阶段 2:结果与断言的映射(/result-to-claim mapping)。系统会依据现有证据对每一个候选实验断言进行评估,并赋予其以下三种判定结果之一:已获支持、部分支持或已被证伪。若阶段 1 的审计报告可用,其"完整性状态"(integrity_status)将被传递至每一条断言记录中;对于那些状态显示为"失败"(fail)的断言,除非其完整性问题得到解决,否则无法被标记为"已获完全支持"。本阶段的输出是一份"断言账本",其中将每一项实验断言与其对应的支持性证据、限定性证据或反驳性证据进行映射。
阶段 3:论文与断言的审计(/paper-claim-audit)。一位"零-上下文"的全新审阅者------具体实现为一个不包含任何既往对话历史的全新 Codex 线程------将通读论文的 LaTeX 源代码,并结合原始实验结果文件及配置文件,对论文中涉及定量数据的断言进行交叉核验。这种"全新线程"的设计旨在降低因执行器残留的既往上下文信息,或审阅者累积的预期心理而导致审计结果产生偏差的风险。典型的核验项目包括:数值不一致、对"最佳随机种子"结果进行选择性截取(cherry-picking)、论文稿件与实验配置文件之间存在差异、数据聚合或增量计算错误,以及断言范围超出实际(scope overclaim)等。每一项断言都将获得一个结构化的审计状态标签,例如:exact_match(精确匹配)、rounding_ok(舍入无误)、number_mismatch(数值不符)、config_mismatch(配置不符)或 missing_evidence(证据缺失)等。
从概念上看,这三个阶段的演进路径依次为:从代码层面的完整性核验,过渡到基于证据对断言进行解读,最终落实到论文稿件层面的报告准确性核验。每一个阶段均可独立调用执行。在完整的科研工作流中,阶段 1 通常在实验运行结束后执行;阶段 2 负责依据实验结果汇编断言记录;而阶段 3 则主要应用于论文撰写及最终稿件的审阅环节。
2 稿件质量保障
除了证据完整性之外,Aris 还引入四种稿件质量保障机制。
五轮科学编辑流程。受科学写作教学原则(Sainani, 2019)的启发,/paper-write 技能在初稿完成后会执行五轮自动化编辑:(1) 清理冗余:移除填充短语、赘词及不必要的模糊修饰;(2) 主动语态:在恰当之处将被动语态结构转换为主动语态;(3) 句子结构:在不强行套用单一句子模板的前提下,优化句子主题的置放位置及局部连贯性;(4) 术语一致性:若"方法"部分引入诸如"验证拆分"(validation split)之类的术语,后续章节应沿用该术语而非使用非正式的变体------系统会提取特定领域的关键术语,并核查其在各章节中的使用是否一致;(5) 数值一致性:交叉核对文中重复出现的数值陈述,确保其与相应的表格、图表或引用的结果文件相吻合。
证明验证(/proof-checker)。对于理论色彩浓厚的论文,证明验证工具采用一套包含 20 个类别的错误分类体系,并辅以双轴严重程度评估机制------该机制将"证明状态"(例如:无效、缺乏依据、表述不清)与"影响范围"(全局性、局部性、排版外观)区分开来。该验证工具会依据预设的"附带条件清单"来核查定理的应用是否得当,并针对关键引理及主要保障性结论执行一轮"反例红队测试"。最终输出一份"证明义务台账",详实记录每一条定理、引理及衍生义务的验证状态。
PDF 视觉审阅。/auto-paper-improvement-loop 模块会将 LaTeX 源代码及其编译生成的 PDF 文档一并发送给审阅者。审阅者通过源代码评估论文的实质性内容,并通过 PDF 文档评估其视觉呈现效果:包括图表的可读性、图注与图表内容的对应关系、版面布局质量(如孤立的标题行、浮动对象位置错乱)、表格格式规范性,以及所有图表之间的色彩一致性。这种基于"双输入源"的审阅模式能够捕捉到仅凭源代码审阅所遗漏的排版呈现类问题。
引用核查(/citation-audit)。作为稿件质量保障体系的第四个组成部分,该模块会对论文中每一处引用(\cite)进行核查,核查维度涵盖三个相互独立的轴向:(i) 存在性核查------确认所引用的论文确实存在,且可通过其声称的 arXiv ID、DOI 或发表刊物/会议信息进行定位;(ii) 元数据准确性核查------确认作者姓名、发表年份、刊物/会议名称及论文标题等元数据与权威数据源(如 DBLP、arXiv、ACL Anthology、Nature、OpenReview 等)中的记录完全吻合; (iii) 上下文适切性------被引用的论文确实确立其被用来佐证的那项主张。这第三个维度最具诊断价值:若一篇真实的论文被用来佐证一项错误的主张,便构成一种"可信度失效"------而仅凭元数据检查是无法捕捉到此类错误的。验证环节由具备互联网访问权限的、来自不同模型家族的全新审阅者负责;审阅结论将被记录在逐条条目的账簿中,并以"保留/修正/替换/移除"(KEEP/FIX/REPLACE/REMOVE)的建议形式呈现出来,待人工审批通过后方可提交。
3 工作量层级与审阅者路由
工作量层级。Aris 提供四种预设的工作量层级,这些层级通过调整涉及广度、深度及迭代次数的相关设置来实现伸缩,但同时保持核心审阅的不变量(invariant)不变:Lite(≈0.4倍)模式旨在实现快速探索,它减少需查阅的论文数量、需构思的创意数量以及审阅的轮次;Balanced(1倍,默认)模式提供标准化的运行行为;Max(≈2.5倍)模式增加搜索深度、审阅详尽度以及实验重复次数;Beast(≈5--8倍)模式则将广度及迭代相关的设置推向其上限。用户可以通过诸如 effort: max 这样的行内指令来覆盖默认设置。此处的一个关键不变量在于:无论整体工作量层级预设为何,基于 Codex 的审阅者调用始终采用"极高"(xhigh)级别的推理工作量;因此,工作量层级的伸缩调整仅改变覆盖范围与迭代次数,而并未改变审阅者所获分配的推理计算资源(预算)。
审阅者路由。在当前的实现版中,审阅请求通过 Codex MCP 桥接器路由至 GPT-5.4 模型。对于那些重要性极高(高风险)的审阅任务,用户可以通过诸如 reviewer: oracle-pro 这样的行内指令,利用 Oracle MCP 桥接器将特定支持的技能显式路由至 GPT-5.4 Pro 模型。在当前的实现版中,仅有一部分涉及调用审阅者的技能启用 Oracle 路由功能。此外,用户还可以通过 llm-chat 桥接器接入其他的审阅者后端模型,但这些模型同样必须遵循"审阅者独立性"协议,并应采纳那条建议------即审阅者与执行者应分别选用来自不同模型家族的成员。
1 技能层
Aris 的基础是一个包含 65 种以上面向研究的技能库,每项技能均编码为一个独立的 SKILL.md 文件。每个 SKILL.md 文件包含一个 YAML 元数据头(包含名称、描述、触发条件及允许使用的工具),紧随其后的是一份自然语言编写的工作流规范:包括输入、输出、分步操作流程、质量关卡以及故障处理指令。这些技能涵盖范围广泛:既有像 /arxiv 这样用于检索论文元数据的简单实用工具,也有像 /auto-review-loop 这样包含多个步骤的复杂工作流------后者能够迭代地执行审阅、修订,并在必要时开展后续实验。
此外,系统还提供五份共享的参考文档,具体包括 reviewer-independence.md(审阅独立性)、experiment-integrity.md(实验完整性)、citation-discipline.md(引用规范)以及 writing-principles.md(写作原则)。
这些文档对全系统通用的不变规则进行统一编纂,从而避免在各个技能文件中重复定义规则。
技能之间通过支持版本控制的文本文件和结构化的 Markdown 页面来交换中间产物。例如,IDEA_REPORT.md 文件在"构思探索"阶段生成,随后被"实验桥接"模块所调用;EXPERIMENT_LOG.md 文件则由"自动审阅循环"模块调用;而 NARRATIVE_REPORT.md 文件最终由"论文撰写"模块调用。这种设计极大地提升系统的可审计性、基于检查点的故障恢复能力,以及在不同模型后端之间的可移植性。综合来看,正是凭借这种"单文件技能"与"纯文本产物契约"相结合的架构,Aris 成功化解瓶颈 (ii):即原本漫长的研究历程被拆解为一系列可供检查与替换的独立调用单元;这些调用单元的输入与输出均可独立进行审阅,而不再像传统模式那样,被深埋于某个单一且不透明的智能体交互记录之中。
2 研究 Wiki:持久化的项目记忆库
针对瓶颈 (i)------即在跨越漫长周期、包含多个会话的工作流中实现研究状态的持久化------Aris 采用四层机制予以解决:(1) "研究 Wiki":它以结构化知识图谱的形式,对论文、构思、实验及研究主张等各类信息进行记录与归档;(2) 技能之间相互交换的"纯文本产物契约":这些契约作为载体,在不同的技能调用环节之间传递并维系着中间状态; (3) 一种"文件系统即状态"(file-system-as-state)的设计选择(设计原则 5),它将所有的会话状态存储在可版本化的文本文件中,而非记忆缓存或外部数据库中,从而使任何新会话都能基于前一次会话留下的产物继续工作;以及 (4) 基于检查点的恢复机制(设计原则 3),通过该机制,任何工作流都能从早期运行所保存的产物处恢复执行。该 Wiki 是整个系统的核心组件,其余三种机制则会在相关上下文中被引用。
该研究 Wiki 通过四种实体类型------论文、构思、实验和主张------提供持久且跨会话的记忆功能;这些实体均以带有规范节点 ID 的结构化 Markdown 页面形式进行存储。八种类型化的关系(包括:扩展/extends、矛盾/contradicts、填补空白/addresses_gap、受启发/inspired_by、验证/tested_by、支持/supports、证伪/invalidates、取代/supersedes)共同构建一个轻量级的知识图谱。
共有三项技能与该 Wiki 相集成:/research-lit 技能负责将发现的论文摄取并转化为结构化页面;/idea-creator 技能在构思阶段开始前,会读取一份压缩后的 query_pack.md 摘要(字数上限为 8,000 字符),并利用其中列出的研究空白点作为搜索种子,同时参考此前被否决的构思以避免重复探索那些无望的方向;/result-to-claim 技能则在每次实验结束后,负责更新相应主张的状态。其中的一项关键设计决策在于保留那些已被否决的构思:若缺乏这种持久化的记忆功能,构思流水线在跨越不同会话时,可能会反复提出同一条已被证实为死胡同的研究方向;而借助该 Wiki,系统能够识别出该方向此前已被探索过,从而转而探索其他方向(参见图 7)。
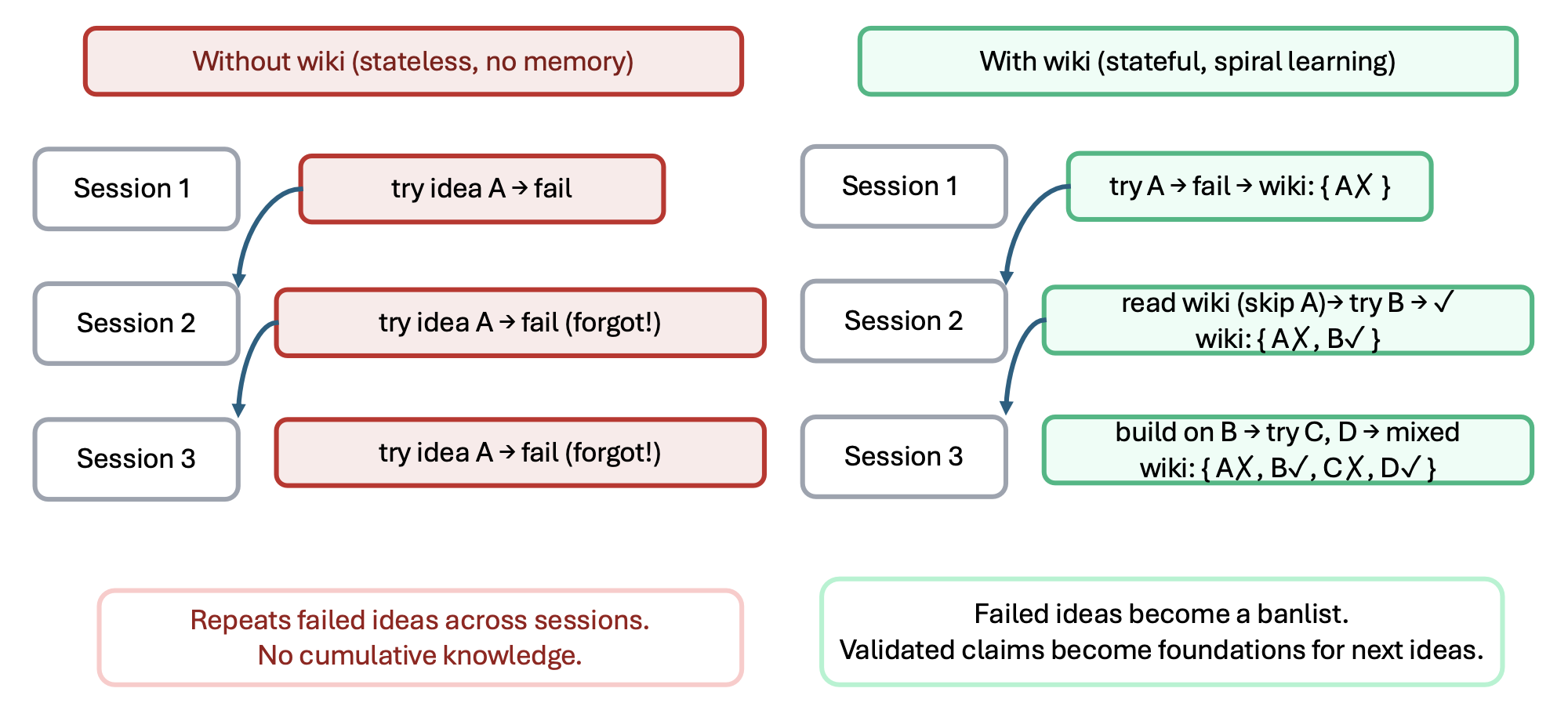
3 工作流编排
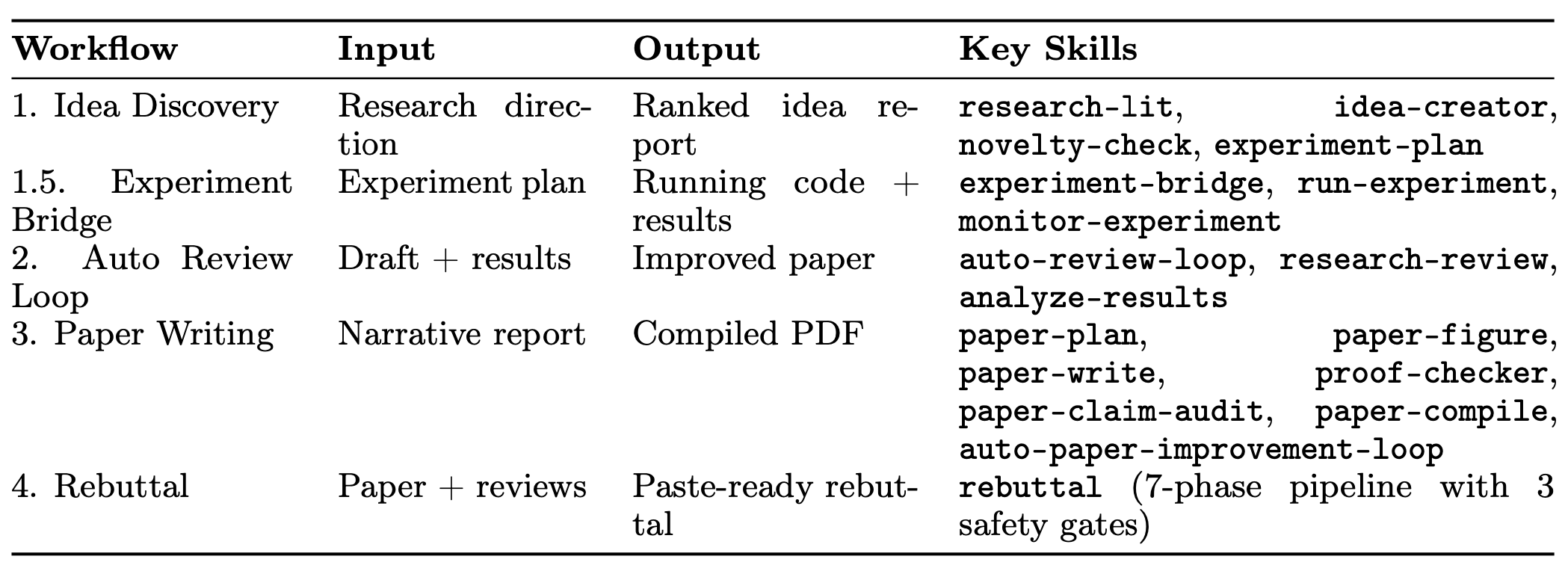
系统通过五种工作流将各项技能串联起来,从而构建出端到端的自动化流水线。其整体架构布局已在前图 1中展示;表 2 列出各工作流的输入、输出及关键技能。
自动审阅循环(工作流 2)。在每一轮循环中(参见图 2所示),系统会将文稿草稿发送给一个来自不同模型家族的"审阅者模型"进行结构化评分;随后,系统会从中提取出可执行的待办事项,若审阅者要求提供新的佐证材料且系统获准执行实验,系统便会运行相应的后续实验,接着修订文稿中受影响的章节,并重新提交文稿以供再次审阅。该审阅循环最多运行四轮,或者直至审阅者评分达到预设的可配置阈值之上为止。
论文撰写流程(工作流3)。该工作流(图3所示)整合质量保障组件。该流程目前串联七项核心子技能,针对理论性较强的论文,还会额外调用 /proof-checker 工具:/paper-plan 负责生成结构大纲及"论点-证据"对照矩阵;/paper-figure 负责生成可直接用于稿件的图表及对比表格;/paper-write 负责使用 LaTeX 撰写各章节初稿,并包含参考文献检索及五轮迭代修订机制;可选组件 /proof-checker 负责对理论性较强的章节进行审计;/paper-claim-audit 负责执行独立的数值一致性检查;/paper-compile 负责执行多轮编译,并自动修复常见的 LaTeX 错误;最后,/auto-paper-improvement-loop 负责启动两轮基于"审稿人模型"的自动审阅与修订循环。
用户可以通过 /research-pipeline 调用完整的写作流程栈;通过设置 auto_write: true,可以将"工作流 2"的输出直接馈送至"工作流 3"。
4 工具集
模型桥接器。Aris 目前开放六个 MCP 桥接器,用于执行器和审阅器的路由:包括针对 Codex、GPT-5.4 Pro 审阅、Gemini、Claude 和 MiniMax 的专用桥接器,以及一个通用的、兼容 OpenAI 的聊天桥接器。此外,还有其他工具桥接器,涵盖引用查找(DBLP/CrossRef)、文献检索(Semantic Scholar)、参考文献库同步(Zotero/Obsidian)、实验追踪(W&B)以及移动端通知(飞书)。
FigureSpec 渲染器。Aris 内置 figure_renderer.py,这是一个能够将结构化的 JSON 格式 FigureSpec 描述转换为 SVG 图形的渲染器。该渲染器支持感知形状的边缘裁剪(适用于矩形、圆形、椭圆形和菱形节点)、自环连接、曲线边缘、支持 CJK(中日韩)字符宽度估算的跨行标签,以及全面的输入验证功能。FigureSpec 的设计旨在让 LLM 智体能够以编程方式生成相应的 JSON 数据;在渲染器版本和字体配置保持固定的前提下,相同的 FigureSpec 输入总能生成完全一致的 SVG 输出。本报告中所有的架构图和工作流图均是通过这一流程生成的。
ARIS-Code CLI。除了作为"技能"集成到现有 IDE 中之外,Aris-Code 还是一款独立的、基于 Rust 语言开发的命令行工具(CLI);它构建于 claw-code 项目(UltraWorkers, 2026)之上,将所有的技能功能打包为一系列斜杠命令(slash commands)。该工具以单一二进制文件的形式发布,集成交互式 REPL 环境、设置向导、对五种不同 LLM 服务商的支持,以及一个用于实现跨模型互评的原生 LlmReview 工具。
5 元优化(Meta-Optimization)
"工作流 1"至"工作流 4"主要利用一套固定的"驾驭"(harness)来优化研究产出。而"元优化"的目标则是针对这套驾驭本身进行优化------具体包括其中的技能提示词(prompts)、默认参数设置以及收敛规则(Lee et al., 2026)。
Aris 实现一个包含三个组件的"外层循环"(outer loop)原型系统:(1) 被动事件日志记录:在当前的原型版本中,Claude Code 的钩子程序会在系统正常运行期间,自动将结构化的事件数据记录至 .aris/meta/events.jsonl 文件中;这些记录内容涵盖时间戳、工具名称、任务执行成功或失败的状态,以及参数覆盖(overrides)情况,整个过程无需任何人工干预即可自动完成。 (2) 模式分析:/meta-optimize 技能会分析使用统计数据------例如用户最常覆盖哪些参数(这往往暗示默认设置存在优化空间)、哪些工具反复运行失败、以及哪些环节的评审得分已陷入停滞------并针对相应的 SKILL.md 文件提出具有针对性的修补建议。(3) 评审门控式应用:每一项拟议的修补建议均须经由 GPT-5.4 xhigh 进行评审;唯有得分达到 7/10 或以上的建议,才会被呈现给用户作为推荐候选项。最终决策权归用户所有;Aris 绝不会自动应用任何针对驾驭(harness)的变更。
1 生态系统与应用采纳
下表3总结当前的部署现状。技能库已从初次发布时的21项核心技能扩展至超过65项,涵盖机器人技术、硬件设计、通信、数学证明、科研资助申请撰写以及演示文稿生成等多个领域。此外,已有三类额外的执行环境通过社区维护的适配指南(托管于外部代码库中)得到详细记录。

为了展示自动评审循环在实际运行条件下的动态机制,对一次通宵运行的全过程进行端到端的记录。在大约八小时的时间里,该系统完成四轮"评审---修订"循环,将内部评审得分从5.0提升至7.5分(满分10分),启动超过20项GPU实验,并删除那些缺乏现有证据支持的论断。这仅是针对单篇论文的一次运行轨迹。
此次运行应被视为一项证据,表明该驾驭(harness)确实能够在一次实际运行轨迹中,成功实现"论断剪枝"和"评审驱动式修订"的操作化;但这并非因果性证据,不足以证明"跨家族模型评审"优于"同家族模型评审",也无法证明"两名跨家族评审员"即为最优的评审委员会规模。"多臂老虎机"与"博弈论"视角,仅作为一种设计类比,旨在为"双角色模式"提供理论动机;若要将该模式的实际效用与其他因素(如研究人员的专业知识、模型的选择以及任务难度)隔离开来并进行独立评估,则需要采用受控基准测试协议------这也是未来的工作方向。
2 局限性与负责任的使用
无法保证正确性。Aris无法保证其产生的任何输出内容是完全正确、具有原创性或在科学上严谨无误的。大语言模型(LLM)的输出中可能包含事实性幻觉(即虚构信息)以及方法论上的疏漏;尽管引入跨模型评审机制有助于减少某些类型的故障模式,但并不能将其彻底消除。通过DBLP和CrossRef数据库对参考文献进行溯源验证,有助于减少(但无法完全杜绝)虚构参考文献的现象。
审计工作的局限性。尽管三阶段级联审计机制能够捕捉到常见的完整性缺陷,但它无法检测出所有的错误、逻辑不一致之处或虚构内容。该机制仅作为一种提供建议的"安全网"而存在,并非一套正式的验证系统。
评审员偏见的放大效应。评审循环机制可能会放大评审员的既有偏见:如果评审员始终坚持要求采用某种特定的方法论,系统在迭代过程中可能会过度迎合该评审员模型的偏好,而非致力于提升论文整体的科学质量。若在收益递减点之后仍持续进行过度迭代,反而可能导致论文质量的下降。
人类的责任。 Aris 负责自动化执行与审查的循环流程;人类则负责提供研究方向、验证证据,并做出最终的提交决策。通过配置检查点(例如:human checkpoint: true),可以实现在工作流的每一个步骤中强制要求人工审批。
安全性。仓库层级的审查功能可能会将源代码发送至外部的大语言模型(LLM)API,从而引发保密性方面的担忧。除非已有经批准的"仅限本地"审查路径可用,否则用户不应在包含敏感代码或机密信息的仓库上启用仓库层级的审查功能。目前,"仅限本地"的审查路由功能尚处于规划阶段,尚未正式实现。