认识深度学习与 PyTorch
一. 深度学习、机器学习与人工智能的关系
人工智能、机器学习与深度学习并非并列关系,而是一层套一层的包含关系:
- 人工智能 (AI):最宽泛的概念,旨在让机器展现出智能。
- 机器学习 (ML):实现 AI 的一种手段,核心在于"从数据中学习"。
- 深度学习 (DL) :机器学习的一个子集,主要利用多层神经网络来解决更为复杂的非线性问题。
- 神经网络 (NN):深度学习的算法架构基础,灵感源于生物大脑的神经元连接。
二. 机器学习中的基本概念
在正式建模前,必须明确数据的组成结构:
1. 样本、特征与标签
- 样本 (Sample):数据集中的每一行,代表一个独立的对象或事件。
- 特征 (Feature) :描述样本属性的维度(即矩阵的列,XXX)。
- 标签 (Label) :我们要预测的目标结果(即向量 yyy)。
- 在这个数据表中,横向的每一行就是"样本"(samples),是我们收集到的一条条数据。(每条样本就是一朵花)
- 每一行前的数字是样本的索引(Index),也就是每一朵花的编号,这个编号对于每一个样本而言是独一无二的。
- 数据表中的列,表示每个样本的一些属性,在机器学习中我们称其为"特征"(features),也叫做"字段"或"维度",注意,这里的维度与二维表的维度可不是相同的含义,前者指的是n的大小(特征的个数),后者指的是.shape后返回的数字的个数(2维表的维度就是2)。
- 最后的一列是"标签"(label),也叫做目标变量(target,或者target variable)。标签也是样本的一种属性,通常来说,它是我们希望算法进行预测、判断的问题的正确答案。如问题是"一朵花是什么类型的花?",这个数据表中的标签就是"是哪一种花"。
在经典机器学习中,因为数据表总是由一个个的特征组成,所以我们一般把数据表(不包括标签的部分)称之为特征矩阵,往往使用大写且加粗的XXX来表示,同样的,我们使用字母xxx表示每个特征。
在深度学习的高维张量的操作中,我们一般不会再区分"行列",而是认为每个索引对应的对象就是一个样本。比如结构32,1,28,28,实际上就是32个三维Tensor所组成的四维Tensor,这32个三维Tensor就是32张图片,也就是32个样本,而这些三维Tensor所包含的内容,也就是32个样本分别对应的特征。由于我们所使用的张量往往是高于两个维度的,因此我们不能称其为"矩阵",因此对于深度学习,我们一般称特征所在的张量叫做特征张量。同样的,我们还是用大写且加粗的XXX来表示特征张量。
由于数据是非结构化的,所以标签也不会位于数据的最后一列之列的。在深度学习中,标签几乎100%是和数据集分开的,不过这些标签看起来都很普通,和机器学习中的标签差不多:
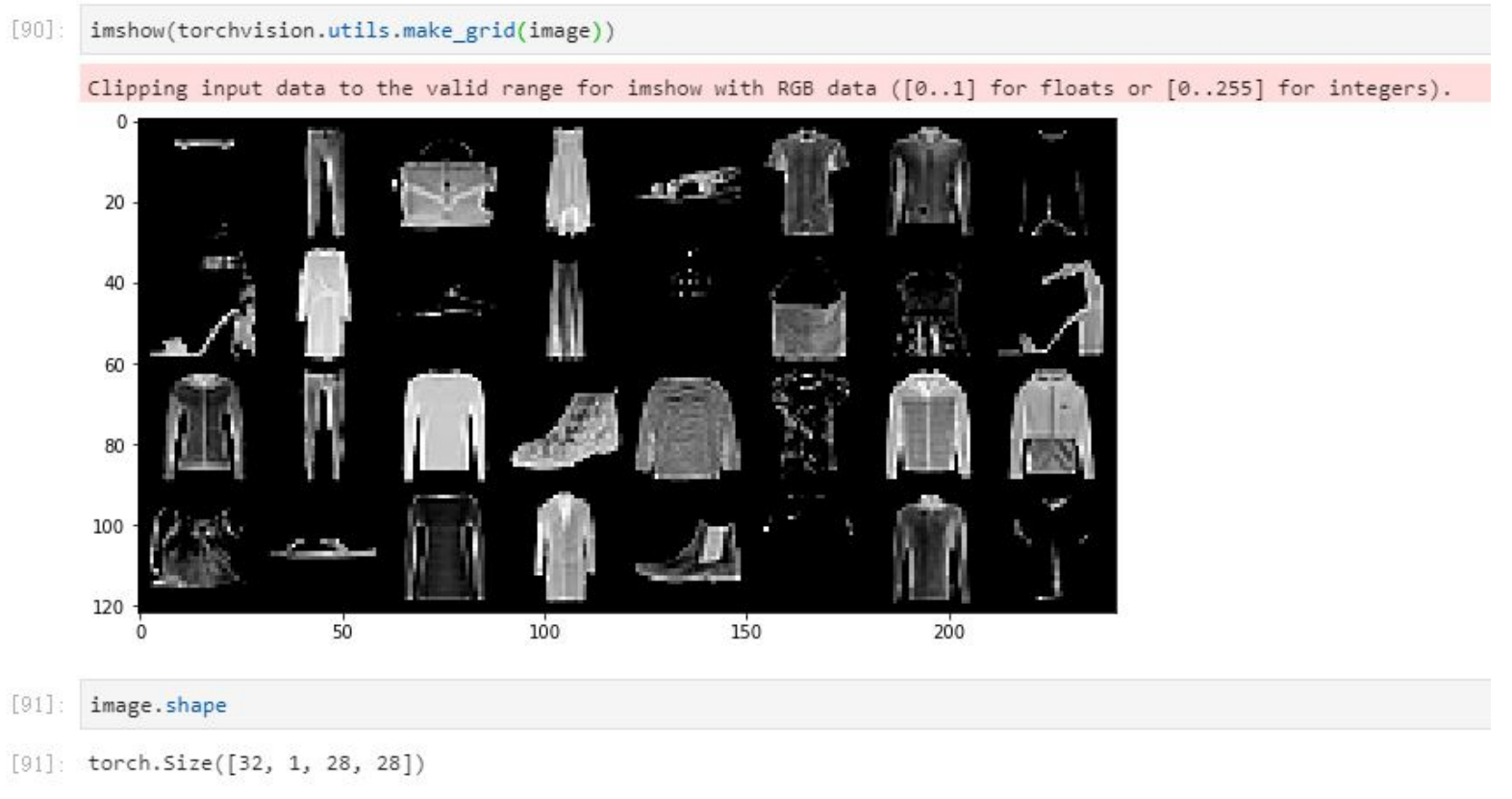
2. 算法分类:有监督 vs 无监督
- 有监督学习 (Supervised Learning) :数据有标签。模型通过特征预测标签(如房价预测、猫狗分类)。
- 无监督学习 (Unsupervised Learning) :数据无标签。模型自动寻找数据内部的结构(如聚类分析)。
3. 任务类型:分类 vs 回归
- 回归 (Regression):标签是连续数值(如预测具体的股价、温度)。
- 分类 (Classification):标签是离散类别(如判断是"男"还是"女",是"猫"还是"狗")。
4. 如何判断我的模型是一个好模型?
现代机器学习算法大约有几十个,每年还有许多新的算法在被提出,从中选出效果优秀、符合需求的模型也是机器学习中的重要课题。为此,我们需要模型的评价机制。如何判断模型是一个好模型呢?在这里,我们提出模型的评估三角:

- 模型预测效果
在机器学习能够落地的场景,模型进行判断/预测的效果一定是我们追求的核心目标。在工业场景,如人脸识别中,如果模型效果不能达到几乎100%准确,那我们就无法使用算法代替人工检查,因为没有人可以承担算法判断失败之后的责任。因为相似的理由,深度学习在医疗领域的应用永远只能处于"辅助医务人员进行判断"的地位。在一些其他场景,如推荐系统,虽然模型的效果可能不需要达到近乎100%的准确,但优秀的推荐系统所带来的效应是非常强大的,而效果不够好的算法则是又昂贵又失败的代码罢了。
对于不同类型的算法,我们有不同的模型评估指标,我们依据这些评估指标来衡量模型的判断/预测效果。如线性回归的评估指标之一:SSE,也就是真实值与预测值的差异的平方和。在之后的学习中,我们会展开来谈不同算法的评估指标。 - 运算速度
能够同时处理大量数据、可以在超短时间内极速学习、可以实时进行预测,是机器学习的重要优势。如果机器学习的判断速度不能接近/超越人类,那规模化预测就没有了根基。如果算法的运算速度太慢,也不利于调优和实验。同时,运算缓慢的算法可能需要占用更多的计算和储存资源,对企业来说成本会变得更高。事实上,现代神经网络做出的许多改进,以及算法工程师岗位对于数据结构方面的知识要求,都是为了提升神经网络的运算速度而存在的的。在模型效果不错的情况下保障运算速度较快,是机器学习中重要的一环。 - 可解释性(深度学习属于锦上添花,要求不高)
机器学习是一门技术,是一门有门槛的技术,曲高客寡,大众注定不太可能在3、5分钟之内就理解机器学习甚至深度学习算法的计算原理。但是技术人员肩负着要向老板,客户,同事,甚至亲朋好友解释机器学习在做什么的职责,否则算法的预测结果很可能不被利益相关人员所接受。尤其是在算法做出一些涉及到道德层面的判断时,可解释性就变得更加重要------例如前段时间闹得沸沸扬扬的UBER算法解雇UBER司机事件,UBER算法在司机们违规之前就预测他们会违约,因而解雇了他们,从算法的角度来看没什么问题,但由于UBER无法向司机们解释算法具体的运行规则,司机们自然也不会轻易接受自己被解雇的事实。幸运的是,随着人工智能相关知识的普及,人们已经不太在意深度学习领域的可解释性了(因为神经网络在预测效果方面的优势已经全面压倒了它在其他方面的劣势)。但在机器学习的其他领域,可解释性依然是非常关键的问题。 - 服务于业务
只有服务于业务,或服务于推动人类认知的研究,算法才会具有商业价值。一个能100%预测你明天午饭内容的算法,或许对个人而言非常有用(解决了人生三大难题之一:午饭吃什么),但不会有公司为它投资,也不会有人希望将它规模化。机器学习算法的落地成本很高,因此企业会希望看到算法落地后确定的商业价值。只有资金流动,技术才能持续发展,算法才能继续发光发热。在传统机器学习领域,评估三角的因素缺一不可,但在深度学习领域,没有什么比效果好、速度快更加重要。如果还能有一部分可解释性,那就是锦上添花了。当我们在训练深度学习模型时,我们会最优先考虑模型效果的优化,同时加快模型的运算速度。每时每刻,我们都是为了模型效果或预算速度而行动的。记住这一点,它会成为日后我们学习任何新知识时的动力。
三. 模型的评估与泛化能力
一个好的模型不应只是在已知数据上表现好,更重要的是在未知数据上的泛化能力。
1. 数据集的划分
为了客观评价模型,通常将数据分为:
- 训练集 (Train Set):用于训练模型,让模型学习特征与标签的关系。
- 测试集 (Test Set):模型从未见过的"新数据",用于验证模型的真实水平。
2. 避坑提醒:过拟合
- 如果模型在训练集上评分极高,但在测试集上评分极低,说明模型"记住了答案"而非"学会了规律",这种现象称为过拟合 (Overfitting)。
四. 深入认识 PyTorch 框架
PyTorch 能够成为目前主流的深度学习框架,核心在于其"动态性"与"易用性"。
1. PyTorch 的核心优势
- 动态计算图 (Dynamic Computational Graph):代码即运行,调试方便,符合 Python 程序员的习惯。
- 原生支持 OOP:模型构建基于面向对象思想,结构清晰。
- 强大的生态:拥有 torchvision, torchtext 等丰富的扩展库。
- 支持eager model:类似在jupyter notebook的运行方式,可以每写几行代码就运行,并返回相应的结果,通常在研究原型时使用。
- 天生支持巨量数据和巨大神经网络的高速运算
- 灵活性高,足以释放神经网络的潜力,并且在保留灵活性的同时,又有Python语法简单易学的优势
- 支持研究环境与生产环境无缝切换,调试成本很低
2. PyTorch 核心模块梳理
现在PyTorch中的模块主要分为两大类:原生Torch库下,用于构建灵活神经网络的模块;以及成熟AI领域中,用以辅助具体行业应用的模块。
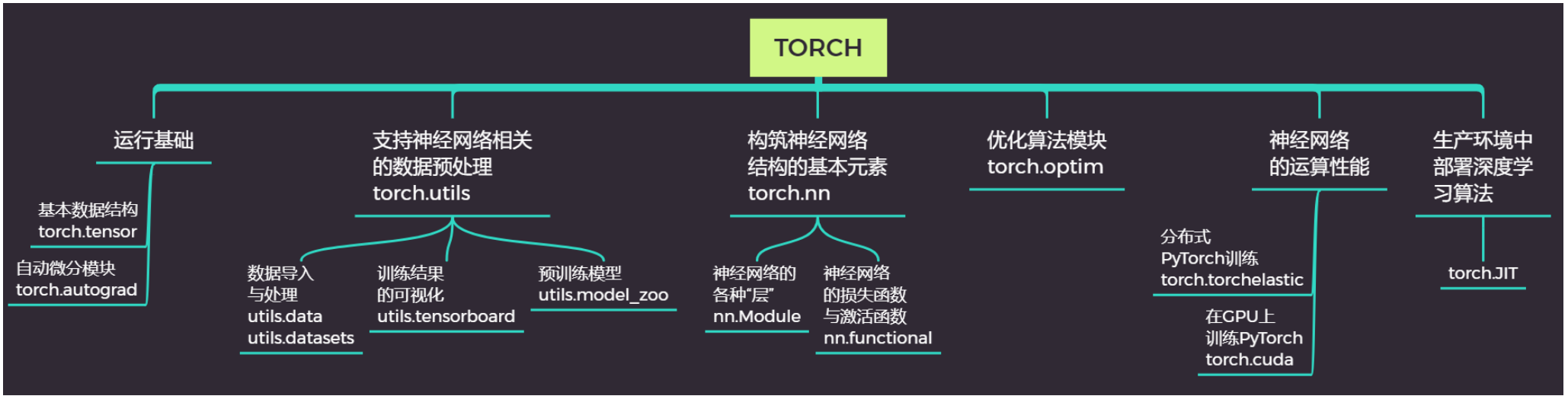
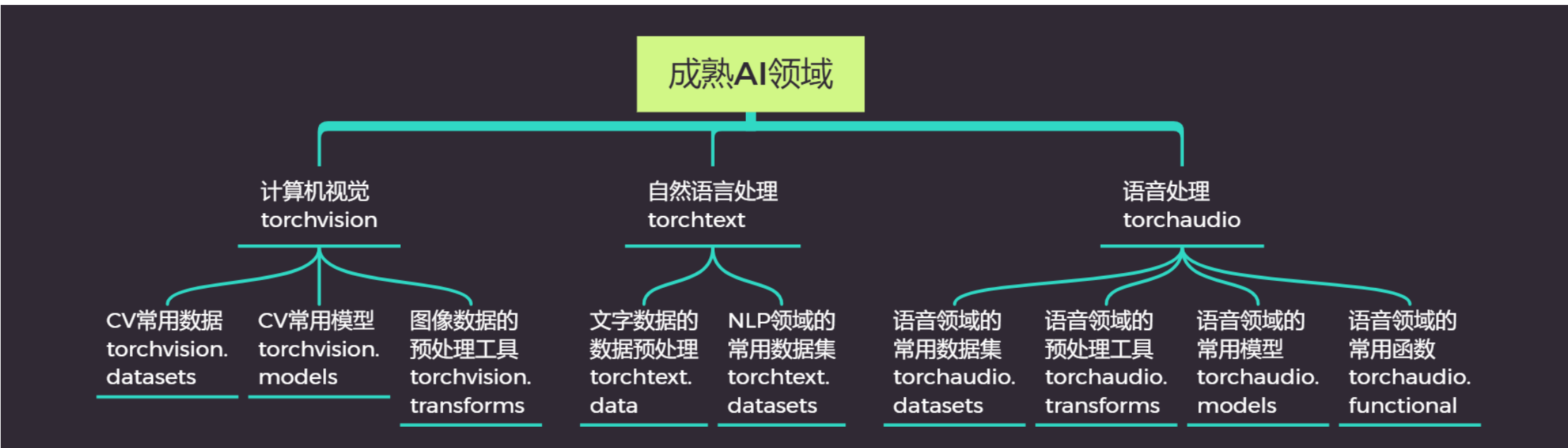
两大模块的层次是并列的,当我们导入库的时候,我们是这样做:
python
import torch
import torchvision实际上在我们对PyTorch进行安装的时候,我们也是同时安装了torch和torchvision等模块。
当我们需要优化算法时,我们运行的是:
python
from torch import optim五. 深度学习建模的一般流程
python
# 1. 数据准备 (使用 torch.utils.data)
# 2. 定义模型结构 (继承 torch.nn.Module)
# 3. 定义损失函数与优化器 (torch.nn & torch.optim)
# 4. 训练循环:
# - 前向传播 (Forward Propagation)
# - 计算损失 (Calculate Loss)
# - 反向传播 (Backward Propagation)
# - 参数更新 (Optimizer Step)
# 5. 模型评估与部署总结:深度学习的本质就是通过海量数据,利用反向传播和梯度下降,不断迭代优化神经网络中的权重参数,从而实现对复杂规律的逼近。