面试里经常被问到一个问题:什么是Spring Bean?
工作三五年的开发者,大部分人的回答是「被Spring管理的对象」。这个回答不算错,但信息量约等于零。所有关键的东西都藏在「管理」这两个字里。管理了什么?怎么管理的?为什么需要管理?追问一层就接不住了。
问题出在哪里?这个定义是用Spring来解释Bean,没有跳出框架去理解它。你记住了一个说法,但追问一层你会发现自己说不清楚。
要搞清楚Bean到底是什么,得先把Spring放到一边,回到一个更根本的问题:在没有Spring的时候,我们是怎么写代码的,遇到了什么麻烦。
想象一个典型的订单系统,三层架构:OrderController处理请求,OrderService处理业务逻辑,OrderRepository和UserRepository负责数据库操作,底层共用一个DataSource。没有任何框架,全靠手动组装,启动代码大概长这样:
Java
public class Application {
public static void main(String[] args) {
// 创建数据源
DataSource dataSource = new HikariDataSource();
dataSource.setJdbcUrl("jdbc:mysql://localhost:3306/demo");
dataSource.setUsername("root");
dataSource.setPassword("123456");
// 创建数据访问层
OrderRepository orderRepository = new OrderRepository(dataSource);
UserRepository userRepository = new UserRepository(dataSource);
// 创建业务层
OrderService orderService = new OrderService(orderRepository, userRepository);
// 创建控制层
OrderController orderController = new OrderController(orderService);
// 启动服务器,把controller注册进去...
}
}这段代码功能上完全没问题,小项目跑得很稳。问题出在规模增长之后。现在只有4个对象,手动组装还看得清楚。一个真实的Spring Boot项目里,几十上百个Service、Repository、Controller、各种配置类、中间件客户端,它们之间的依赖关系是一张网。OrderService依赖OrderRepository和UserRepository,PaymentService依赖OrderService和PaymentGateway,NotificationService依赖UserRepository和EmailClient......每加一个新类,你都得回到这个启动代码里,搞清楚它依赖谁、谁依赖它,然后手动把依赖关系对接好。改一个类的构造器签名,所有创建它的地方都要跟着改。
很多人以为Spring的价值是「省了几行new的代码」。不是。手动new十几个对象不费事。费事的是几百个对象之间的依赖关系全靠你自己理清楚,每一次变动都可能牵连好几处。真正的痛点不是对象的创建,而是对象之间依赖关系的管理。
面对这个问题,解决的思路可以是这样子:搞一个统一的地方,专门负责创建所有对象、管理它们之间的依赖关系。你只需要告诉这个地方「我有哪些类、它们各自需要什么」,剩下的创建和组装工作全交给它。
这个思路就是容器的雏形。Spring容器干的事:你告诉我有哪些类需要管理,我来负责创建它们、把它们之间的依赖关系接好、在合适的时机销毁它们。
光说概念太抽象,不如自己写一个最简版本的容器,看看它的核心到底是什么。下面这段代码大概50行,能注册类、创建对象、自动注入依赖:
Java
public class SimpleContainer {
// 存储注册信息:Bean名字 → 类的Class对象
private Map<String, Class<?>> registry = new HashMap<>();
// 存储已经创建好的单例对象
private Map<String, Object> singletonCache = new HashMap<>();
// 注册一个类,告诉容器需要管理它
public void register(String name, Class<?> clazz) {
registry.put(name, clazz);
}
// 获取Bean:先查缓存,没有就创建
public Object getBean(String name) {
// 先查单例缓存,有就直接返回
if (singletonCache.containsKey(name)) {
return singletonCache.get(name);
}
Class<?> clazz = registry.get(name);
if (clazz == null) {
throw new RuntimeException("没有找到名为 " + name + " 的Bean定义");
}
try {
// 通过反射创建对象
Object instance = clazz.getDeclaredConstructor().newInstance();
// 扫描这个对象的所有字段,尝试自动注入依赖
for (Field field : clazz.getDeclaredFields()) {
// 在registry里找类型匹配的Bean
for (Map.Entry<String, Class<?>> entry : registry.entrySet()) {
if (field.getType().isAssignableFrom(entry.getValue())) {
field.setAccessible(true);
// 递归获取依赖的Bean(触发依赖的创建和注入)
field.set(instance, getBean(entry.getKey()));
}
}
}
// 放入单例缓存
singletonCache.put(name, instance);
return instance;
} catch (Exception e) {
throw new RuntimeException("创建Bean失败: " + name, e);
}
}
}用起来是这样的:
Java
SimpleContainer container = new SimpleContainer();
// 告诉容器有哪些类
container.register("dataSource", HikariDataSource.class);
container.register("orderRepository", OrderRepository.class);
container.register("userRepository", UserRepository.class);
container.register("orderService", OrderService.class);
container.register("orderController", OrderController.class);
// 直接从容器拿,依赖自动接好了
OrderController controller = (OrderController) container.getBean("orderController");对比之前手动组装的代码,变化在哪?你不再关心「谁该传给谁」这件事了。你只管告诉容器有哪些类,容器自己分析它们的字段类型,去registry里找匹配的Bean,递归地完成整条依赖链的创建和注入。
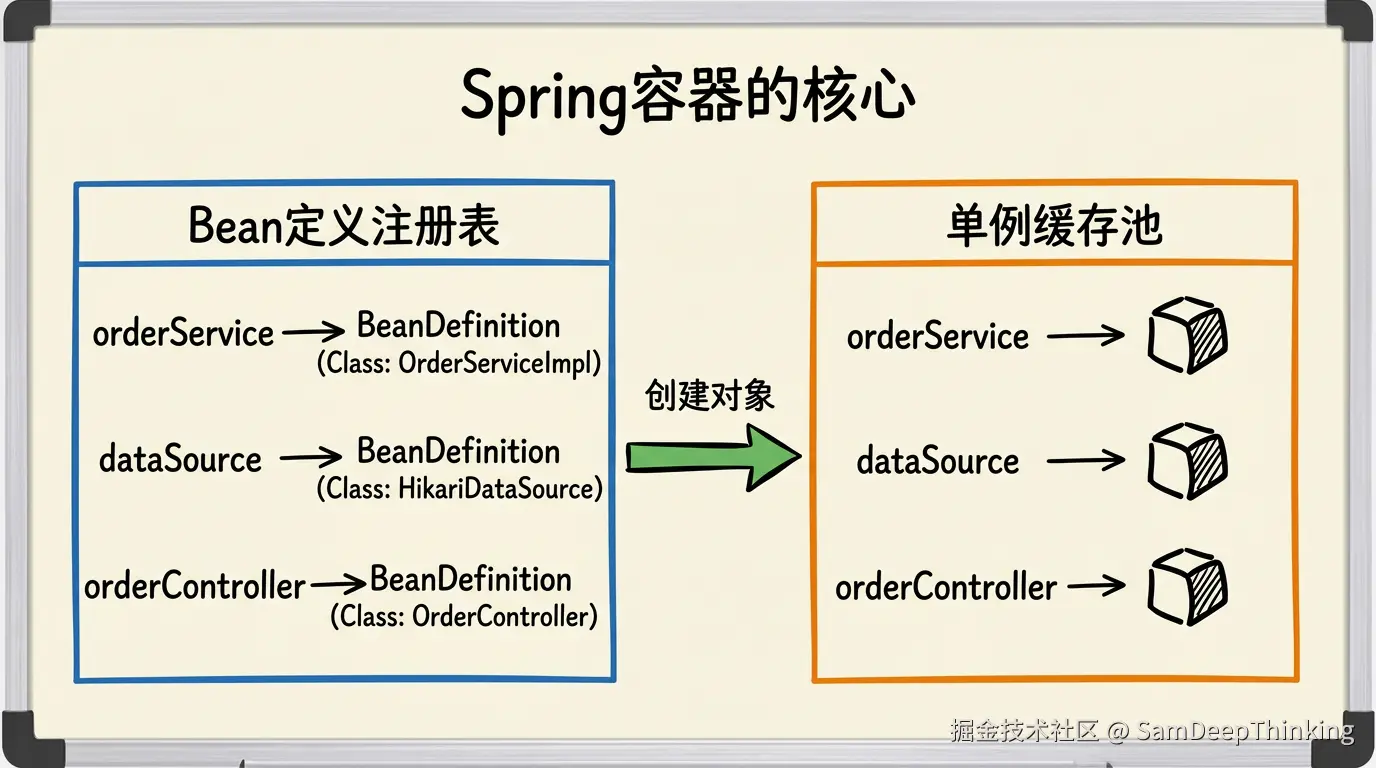
这段代码虽然粗糙,但它揭示了Spring容器最核心的骨架:一个Map存「有哪些东西需要管理」,另一个Map存「已经创建好的成品」。 所有Spring容器的复杂性,生命周期回调、作用域管理、循环依赖处理、AOP代理,都是在这个骨架上叠加的特性。骨架没变过,只是功能越来越丰富。
有人会说,这也太简化了吧?Spring的真实实现比这复杂得多。确实。这个简化版忽略了很多东西:构造器参数怎么选择、同一个类型有多个Bean怎么办、延迟加载怎么处理、循环依赖怎么解决。这些都是工程实践中必须面对的问题。
但理解一个框架,要先把骨架看清楚,再去看长在骨架上的血肉。
你知道了核心是两个Map,后面接触到每一个高级特性,都能定位到它是在修改哪个Map、在哪个环节介入。
上面的简化容器有一个明显的不足:registry里只存了一个Class对象。也就是说,容器只知道「创建什么」,但不知道很多其他信息。实际场景中,一个对象被容器管理,容器需要知道更多的事情:
- 这个对象是整个应用只要一份(单例),还是每次请求都新建一份?
- 它需不需要延迟创建(应用启动时不创建,等真正用到时再创建)?
- 它依赖其他哪些Bean,这些Bean必须先创建好?
- 创建完成后,有没有什么初始化动作要执行(比如连接池要预热、缓存要加载)?
- 应用关闭时,有没有什么清理动作要做(比如关闭连接池、释放文件句柄)?
- 同一个类型有多个Bean时,哪个是默认优先使用的?
这些信息需要一个结构化的地方来存储。在Spring里,这个结构叫Bean定义,你可以理解成一份「制造说明书」。用代码来表达,大概是这样的结构:
Java
public class BeanDefinition {
// 这个Bean对应的类
private Class<?> beanClass;
// 作用域:singleton表示全局一份,prototype表示每次新建
private String scope = "singleton";
// 是否延迟初始化
private boolean lazyInit = false;
// 依赖的其他Bean名字,这些Bean必须在它之前创建
private String[] dependsOn;
// 初始化时要调用的方法名
private String initMethodName;
// 销毁时要调用的方法名
private String destroyMethodName;
// 同类型多个Bean时,是否优先使用这个
private boolean primary = false;
}有了这个视角,Bean和普通Java对象的区别就清晰了。你在代码里写new OrderService(),JVM只是调一下构造器,创建一个对象放在堆上,别的什么都不管。而容器管理的Bean,背后有一份完整的制造说明书,容器知道它什么时候创建、怎么创建、创建之后做什么、销毁之前做什么。Bean = 对象 + 制造说明书 + 容器的全程托管。 三样东西少了任何一个,都不叫Bean。
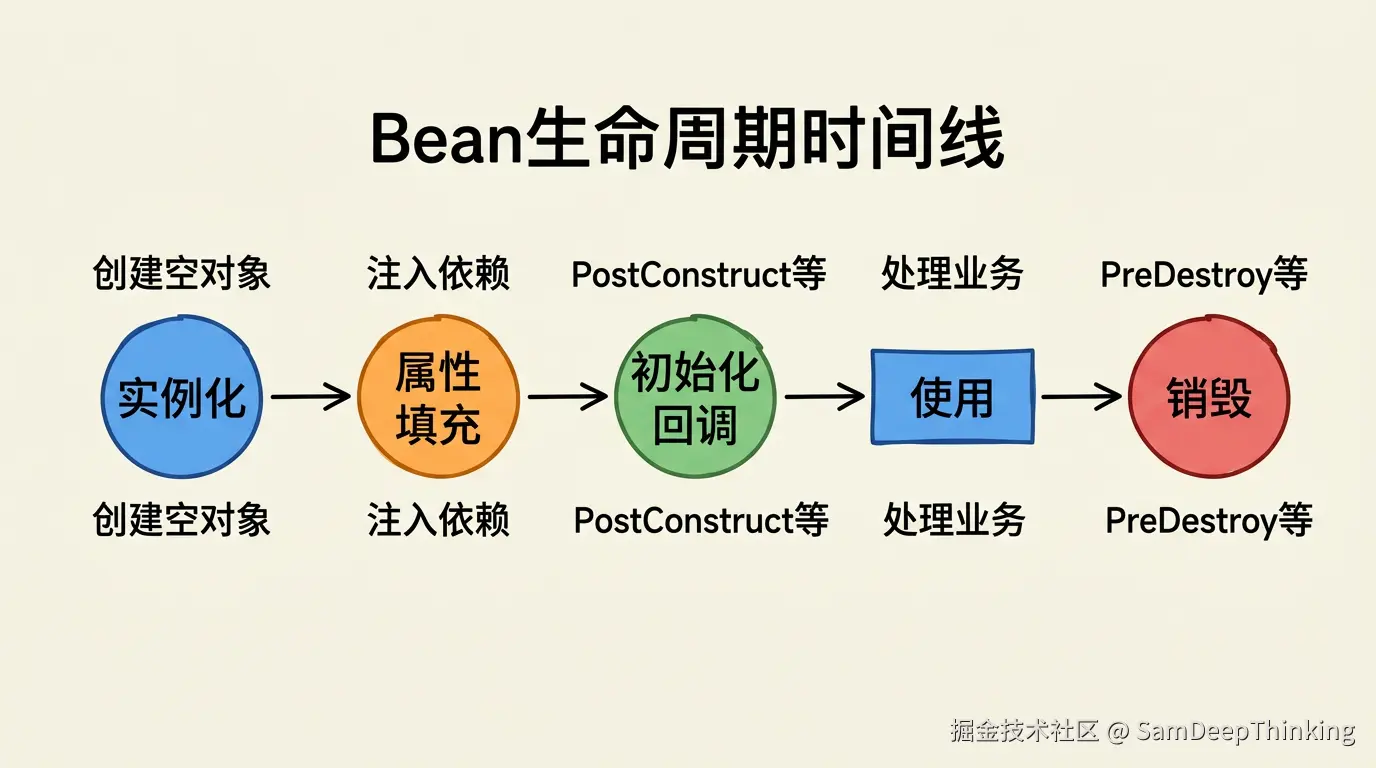
容器有了说明书,创建一个Bean的过程也就不是简单地调一下构造器了。它有一整套标准化的流程。这里不展开每一步的实现细节,只画一条时间线,先有个整体印象:
用一个不太严格但方便理解的类比:
这个过程像装修一套房子。买到毛坯房是实例化,这时候房子有了,但什么都没有。接水电气是属性填充,把它需要的各种依赖(水、电、网络)接进来。验收检查是初始化回调,确认一切就绪,做最后的调试和测试。然后是入住使用。最后是拆迁,清理所有资源,把占用的东西归还。
生命周期不是框架在故弄玄虚。一个对象从创建到真正可用之间,确实有很多事情要做。DataSource需要初始化连接池,缓存需要预热,消息监听器需要注册到消息队列。这些不是构造器能一步搞定的。容器把这些步骤标准化,每个步骤还留了扩展点,让你在特定阶段插入自己的逻辑。
回到一个更实际的问题:你怎么告诉Spring,你的哪些类需要被当成Bean来管理?
最常见的方式是在类上面加注解。Spring提供了四个用来标记Bean的注解:@Component、@Service、@Repository、@Controller。很多教程告诉你,Service层用@Service,Controller层用@Controller,DAO层用@Repository。但很少有人解释为什么。
这四个注解之间的关系,简单说就是:@Service、@Repository、@Controller都是@Component的「派生版」。它们的定义方式类似这样:
Java
// @Service的定义上面标注了@Component
@Component
public @interface Service {
String value() default "";
}
// @Repository的定义上面标注了@Component
@Component
public @interface Repository {
String value() default "";
}
// @Controller的定义上面标注了@Component
@Component
public @interface Controller {
String value() default "";
}Spring在扫描包路径的时候,查找的是带有@Component注解的类。因为@Service、@Repository、@Controller上面都标注了@Component,所以它们也会被扫描到。从「把一个类注册成Bean」这件事来看,这四个注解完全等价。你把所有@Service换成@Component,项目一样能正常跑。
那为什么不全用@Component?
从两个角度看。一是语义表达。其他开发者看到@Repository就知道这是数据访问层,看到@Service就知道这是业务层。注解在这里承担了代码文档的角色。在三五个人的小团队里,这点区别可能感受不明显。几十人的项目里,注解的语义信号对代码理解效率的影响比想象中大得多。
二是框架层面的区别对待。虽然注册Bean时这四个注解等价,但Spring在后续处理中会对特定注解做额外的事情。@Repository标记的类,Spring会给它加一层异常转译,把数据访问层抛出的底层异常(比如JDBC的SQLException)自动包装成Spring统一的数据访问异常体系。@Controller标记的类,Spring MVC会把它识别为请求处理器,扫描里面的@RequestMapping方法来建立请求映射。这些特殊处理不在Bean注册阶段,而是在各自模块的后处理阶段。
@Component系列注解适用于你自己写的类。遇到第三方库的类,比如你想把一个RestTemplate注册成Bean,没法去改RestTemplate的源码加@Component。这时候用@Bean注解,在一个配置类里写一个方法,方法返回值就是你要注册的Bean:
Java
@Configuration
public class AppConfig {
@Bean
public RestTemplate restTemplate() {
return new RestTemplate();
}
}@Component是标记一个类让Spring自动扫描并注册,@Bean是在方法上手动告诉Spring怎么创建一个对象。两种方式的终点相同:往容器的注册表里写入一条Bean定义。
这里有一个容易忽略的细节:上面这个配置类用的是@Configuration,不是@Component。虽然@Configuration本身也是@Component的派生注解(也会被扫描为Bean),但它有一个@Component不具备的特殊行为。
看这个场景:
Java
@Configuration
public class AppConfig {
@Bean
public DataSource dataSource() {
HikariDataSource ds = new HikariDataSource();
ds.setJdbcUrl("jdbc:mysql://localhost:3306/demo");
ds.setUsername("root");
ds.setPassword("123456");
return ds;
}
@Bean
public OrderRepository orderRepository() {
// 注意:这里调用了dataSource()方法
return new OrderRepository(dataSource());
}
@Bean
public UserRepository userRepository() {
// 这里也调用了dataSource()方法
return new UserRepository(dataSource());
}
}orderRepository()和userRepository()各调用了一次dataSource()。如果这是普通的Java方法调用,两次调用会执行两次new HikariDataSource(),创建出两个不同的数据源对象。两个Repository各持有一个独立的连接池,这显然不是你想要的。
实际运行时,两个Repository拿到的是同一个DataSource实例。原因是Spring在启动时给@Configuration类生成了一个动态子类(通过CGLIB字节码技术)。这个子类覆盖了所有@Bean方法的执行逻辑:当你在方法内部调用dataSource()时,执行的不是原始的new逻辑,而是先去容器的单例缓存里查。如果dataSource这个Bean已经创建过了,直接返回缓存里的实例。
我以前一直觉得@Configuration和@Component没什么本质区别,直到在一个项目里踩了坑。排查一个连接池告警,发现数据库连接数莫名其妙翻倍了。查到最后,是有人把一个配置类的@Configuration改成了@Component(可能是觉得既然都能注册Bean,用哪个都一样)。改完之后,两个Repository各自持有了一个独立的DataSource,连接池被创建了两份。这才意识到@Configuration的CGLIB代理在保证@Bean方法的单例语义上是不可少的。
有一个相关的优化值得提一下:如果你的@Configuration类里的@Bean方法之间没有互相调用的情况,可以用@Configuration(proxyBeanMethods = false)主动关掉CGLIB代理。Spring Boot的很多自动配置类就是这么做的,能加快应用启动速度。这是一个知道原理之后才能做出的优化判断。
容器创建好了Bean,接下来的问题是怎么把它们之间的依赖关系接好。这就是依赖注入。日常开发中最常用的两个注入注解是@Autowired和@Resource,它们的核心行为差异用一句话就能说清:@Autowired按类型找,@Resource按名字找。
@Autowired的匹配逻辑是:先按字段的类型去容器里查,如果只找到一个,直接注入。如果同一个类型有多个Bean,再看字段名是否和某个Bean的名字匹配。@Resource正好反过来,默认按字段名去容器里查Bean名字,名字匹配不上再按类型找。
实际项目里选哪个?团队保持一致就好。Spring官方现在更推荐构造器注入,连@Autowired注解都可以不写。当一个类只有一个构造器时,Spring会自动把构造器参数从容器中注入:
Java
@Service
public class OrderService {
private final OrderRepository orderRepository;
private final UserRepository userRepository;
// 只有一个构造器,Spring自动注入参数,不需要写@Autowired
public OrderService(OrderRepository orderRepository, UserRepository userRepository) {
this.orderRepository = orderRepository;
this.userRepository = userRepository;
}
}构造器注入有一个好处:依赖字段可以声明为final,对象创建之后依赖关系不可变。字段注入做不到这一点。
日常开发中的Bean
讲了这么多原理,回到一个实际的问题:你每天写的代码里,哪些东西是Bean?
下面这张表覆盖了一个典型Spring Boot项目中常见的Bean来源:
| 分类 | 典型代表 | 谁注册的 | 你需要做什么 |
|---|---|---|---|
| 你自己写的业务类 | XxxService、XxxController、XxxRepository | 你加@Component系列注解 | 在类上标注注解 |
| 你手动配置的Bean | RestTemplate、ObjectMapper、线程池、拦截器 | 你在@Configuration里写@Bean方法 | 写配置类和@Bean方法 |
| Spring Boot自动配置的 | DataSource、JdbcTemplate、RedisTemplate、事务管理器 | spring-boot-autoconfigure里的自动配置类 | 引入对应的starter依赖即可,不需要写任何代码 |
| Spring MVC基础设施 | DispatcherServlet、HandlerMapping、参数解析器 | Spring MVC自动注册 | 引入spring-boot-starter-web |
| AOP相关 | 你写的@Aspect类、各种通知 | Spring AOP框架 | 加@Aspect和切点表达式 |
| 事件机制 | ApplicationEventPublisher、你写的@EventListener方法所在的类 | Spring容器 | 实现接口或加注解 |
| 你以为不是Bean但其实是的 | @Configuration类本身、@Aspect类本身 | Spring自动识别并注册 | 通常不需要额外感知 |
一个容易产生误区的地方:不是所有Java对象都应该注册成Bean。Entity、DTO、VO这些数据传输对象不该是Bean。它们的生命周期跟随请求或业务流程,每次请求可能产生不同的实例,这和容器管理单例的模式是冲突的。工具类如果全是静态方法,也不需要注册成Bean。
判断标准就两条:这个对象需不需要被别的Bean依赖注入?需不需要容器管理它的生命周期(初始化、销毁)?两个答案都是否,它不该是Bean。
下面这张对比表可以帮你快速区分Bean和普通对象:
| 维度 | Spring Bean | 普通Java对象 |
|---|---|---|
| 创建方式 | 容器根据Bean定义创建 | 代码里直接new |
| 生命周期 | 容器全程托管(创建→注入→初始化→使用→销毁) | 创建者管理,GC回收 |
| 依赖注入 | 容器自动完成 | 手动通过构造器或setter传参 |
| 默认实例数 | 单例(整个应用一份) | 每次new都是新对象 |
| AOP支持 | 可以被代理增强(事务、日志、权限等) | 不支持 |
| 能否被其他Bean依赖 | 可以,容器知道它的存在 | 不行,容器感知不到 |
| 典型代表 | Service、Controller、Repository、配置类、中间件客户端 | Entity、DTO、VO、工具类 |
小结
回到开头那个面试问题。读到这里,对Bean的认知应该不再停留在「被Spring管理的对象」这个层面了。容器的核心是两个Map:一个存制造说明书,一个存创建好的成品。Bean是容器基于说明书创建、组装依赖、管理全生命周期的对象。你用@Component告诉容器哪些类需要管理,用@Bean告诉容器怎么创建第三方类的实例,容器负责剩下的一切。
做了十几年项目,我觉得理解Bean这个概念有一个容易走偏的方向:过度关注容器的内部实现细节,去追每一行源码的执行路径,反而忘了停下来想一想「什么该交给容器管理、什么不该」。项目里见过不少把DTO、值对象甚至临时变量都注册成Bean的代码,容器里塞了一堆不需要被管理的东西,代码反而更难读了。Bean的设计初衷是让你专注于业务逻辑,把对象的创建和组装交给框架。如果一个对象被注册成Bean之后,代码没有因此变得更简单,那它可能不该是Bean。
希望这篇内容可以帮到你。
最近在知乎出了秒杀专栏,感兴趣的可以订阅一下。至于知识星球的,可以搜:
老码头的技术浮生录
它是一个能实际帮你解决难题的星球。有问题的,找知心的Sam哥。
我的知乎账号:
- SamDeepThinking