一、行业背景:数据孤岛的成本正在失控
去年阿里云年度报告揭示了一个触目惊心的数据:中国企业因数据孤岛问题,生产效率平均下降23%。这个数字在2026年只会更高,不会更低。
当每个业务部门都在喊"实时同步",当业务方对T+1批处理的容忍度归零,当AI应用需要毫秒级新鲜数据------传统的ETL批处理模式正在被历史淘汰。
这不是危言耸听。根据IDC最新报告,2025年全球企业年处理数据量已超过120ZB,其中80%的企业将实时数据集成列为数字化转型的核心战略。
趋势已经清晰:2026年,数据集成正在发生结构性重构。
二、趋势一:CDC从"可选"变成"必须"
1CDC(Change Data Capture)------从幕后走向前台
CDC并不是新技术,但2026年它终于从"高级特性"变成了"基础设施标配"。
传统ETL的工作方式是定时全量扫描------每天凌晨2点,把数据库翻一遍,把变化的数据挑出来。这种方式有三个致命问题:
-
延迟高:数据从产生到可见,最少间隔数小时
-
资源消耗大:全表扫描对源库造成持续压力
-
难以扩展:数据量增长时,扫描时间线性增加
CDC的解法是日志解析------直接监听数据库的变更日志(Binlog、WAL、Redo Log),以毫秒级延迟捕获每一次INSERT/UPDATE/DELETE。这不是优化,是架构层面的降维打击。
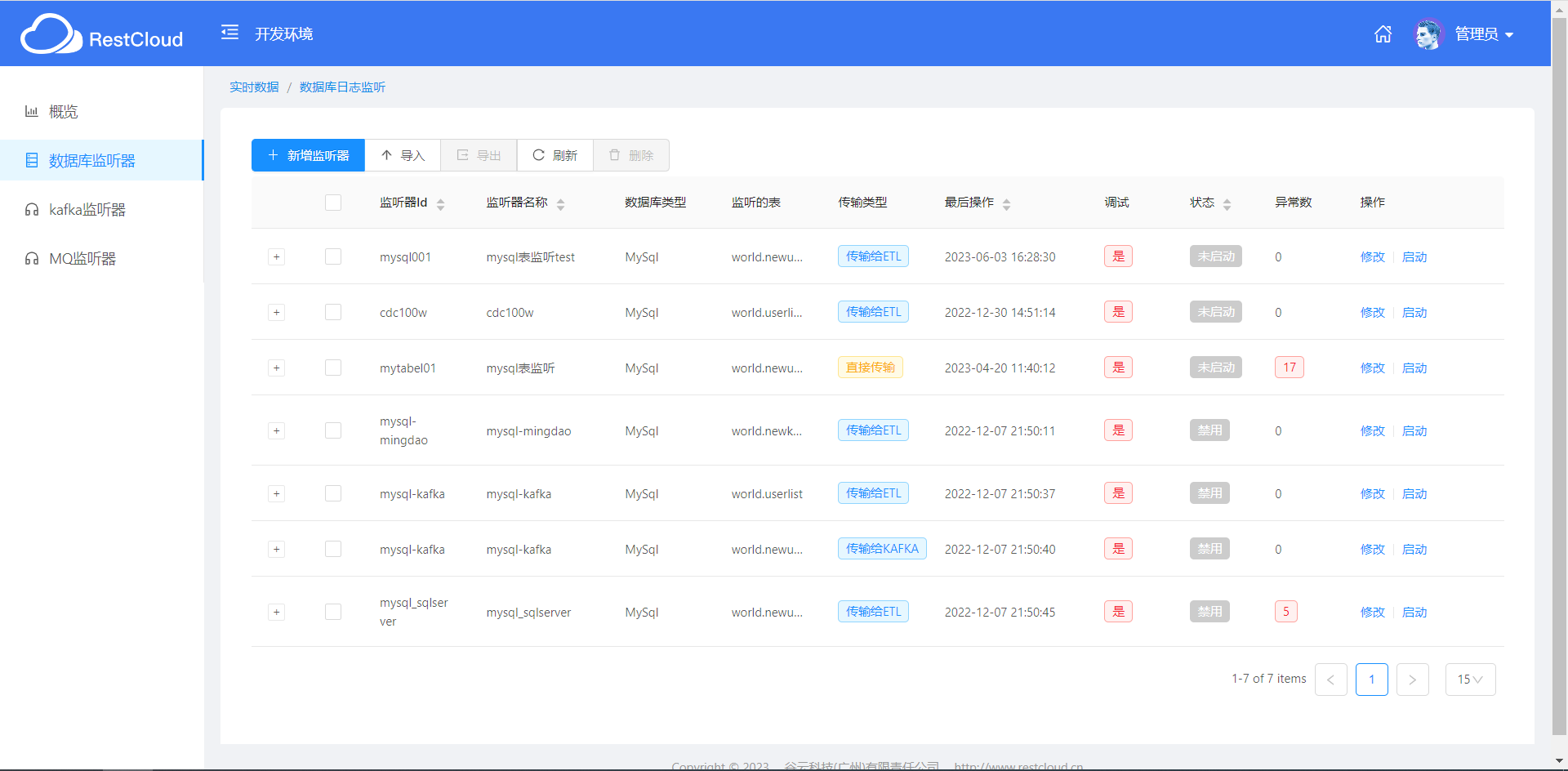
图1:CDC通过数据库日志解析实现毫秒级实时同步
2026年,主流CDC工具的能力边界已经大幅扩展:
| 能力维度 | 2024年水平 | 2026年水平 |
|---|---|---|
| 同步延迟 | 秒级~分钟级 | 毫秒级(≤500ms) |
| 支持数据库 | MySQL/Oracle/PostgreSQL | +MongoDB/SQL Server/SQLite/达梦/人大金仓 |
| 断点续传 | 部分支持 | 全链路保障,任意节点可恢复 |
| Schema变更 | 需手动处理 | 自动感知,DDL自动同步 |
三、趋势二:ELT云原生化------计算迁移到数据侧
2ELT(Extract-Load-Transform)------云数仓时代的新范式
如果说CDC解决的是"数据怎么来"的问题,ELT解决的是"数据怎么算"的问题。
传统ETL的流程是:Extract → Transform → Load。数据在ETL服务器上完成清洗转换,再写入数据仓库。这个模式的局限在于------ETL服务器成了性能瓶颈。
ELT的思路是反过来的:Extract → Load → Transform。先把原始数据一股脑儿拉进数仓(Snowflake/BigQuery/Redshift/华为MRS),然后用数仓的分布式计算能力做清洗转换。
2026年,这个趋势加速了三个原因:
-
云数仓成本下降:按量计费让中小型企业也能用上PB级数仓
-
SQL everywhere:数据工程师不需要学Python/Java,用SQL搞定一切
-
AI原生支持:大模型直接查询数仓,数据无需出库
四、趋势三:AI正在重塑数据管道
3AI驱动的数据集成------从"手动配置"到"自然语言生成"
这是2026年最激动人心的变化,也是争议最大的领域。
过去,数据工程师需要手动配置每一个数据源连接器、每一条转换规则、每一个调度依赖。光是维护一个中等规模企业的数据管道,就需要3-5人的专职团队。
现在,AI正在改变这个游戏:
-
智能连接器生成:输入"连接我的SAP系统和SQL Server",AI自动生成适配器
-
自然语言转换规则:说人话"把日期格式统一成YYYY-MM-DD",AI生成对应SQL
-
异常自愈:数据质量异常时,AI自动诊断原因并尝试修复
-
智能调度优化:AI根据数据特征自动推荐最优调度窗口
这不是取代数据工程师,而是让他们的效率提升10倍。
五、技术选型:2026年数据集成工具全景图
趋势是方向,但落地需要工具。以下是2026年主流数据集成工具的定位分析:
| 类别 | 代表工具 | 核心优势 | 适用场景 |
|---|---|---|---|
| 开源批处理 | DataX、Kettle | 免费、社区活跃、成熟稳定 | 离线数据同步、简单ETL场景 |
| 开源实时 | Debezium + Kafka | 架构灵活、扩展性强 | 大规模实时CDC、需要深度定制 |
| 云原生SaaS | Fivetran、Airbyte | 开箱即用、免运维 | 快速接入云应用(Salesforce等) |
| 国产一体化平台 | ETLCloud(谷云科技) | ETL+CDC+API+编排全栈、国产信创支持 | 需要全链路管控的政企客户 |
六、架构演进路径:怎么从T+1迁移到实时?
很多企业的现状是:核心业务跑在Kettle/Informtica上,想迁移到CDC实时架构,但又不敢动生产系统。这里提供一个三阶段灰度迁移的实践路径:
阶段一:并行验证(1-2个月)
在不影响主流程的前提下,部署CDC链路作为"影子系统",与原有批处理并行运行。对比数据一致性,验证CDC链路质量。
阶段二:非核心切换(2-3个月)
选取报表延迟要求高的业务场景(如实时大屏、销售监控),切换到CDC链路。积累运维经验,培养团队能力。
阶段三:全量迁移(持续)
核心系统分批切换,每次切换后观察1-2周,无异常再继续。保留回滚能力,灰度发布。
图2:可视化流程编排让架构迁移更可控
七、总结:2026年数据集成选型建议
趋势已经明确,但每家企业的起点不同。以下是三种典型场景的选型建议:
-
中小企业,快速验证:优先选择Fivetran/Airbyte,快速接入云端数据源,零运维
-
中大型企业,国产替代:考虑ETLCloud等国产平台,一体化覆盖ETL+CDC+API+调度,兼容信创环境
-
技术团队,强定制需求:开源路线(Debezium+Kafka+Airbyte自建),追求架构灵活性
核心结论:
-
CDC不是"高级功能",是2026年的基础设施标配
-
ELT云原生化让数据集成成本降低50%以上
-
AI辅助不是取代人,是让数据工程师聚焦更高价值的工作
-
选型没有最优解,只有最适合------评估团队能力、数据规模、业务需求后再决策