
⭐️在这个怀疑的年代,我们依然需要信仰。
个人主页 :YYYing.
⭐️高并发内存池项目专栏:C++项目之高并发内存池
系列下期内容:暂无
目录
[📖 池化技术介绍](#📖 池化技术介绍)
[📖 项目介绍](#📖 项目介绍)
[📖 内存池的作用](#📖 内存池的作用)
[📖 简单内存池的简单工作原理](#📖 简单内存池的简单工作原理)
[📖 tcmalloc和malloc的关系](#📖 tcmalloc和malloc的关系)
[📖 定长内存池](#📖 定长内存池)

前言:
在构建高性能服务器、游戏引擎或任何对延迟敏感的系统时,内存管理往往是那个"看不见的瓶颈"。我们习惯了使用 malloc 和 new 来分配内存,但在高并发场景下,这些看似简单的操作却可能成为性能的"噩梦",所以我们这次就将带领大家进行高并发内存池的学习。
本项目只是把tcmalloc中特别核心的内容拿出来讲一讲,并不是为了完全复刻tcmalloc的源码,不要想着自己一个人复刻数位顶尖大佬做出的tcmalloc出来,源码中的tcmalloc得要好几万行的,本项目最终代码量也才不过两千行,只是为了学习大佬的研究成果与总结,从而提升自己而已,如果你对于tcmalloc的源码感兴趣,那请随**传送门**。
📖 池化技术介绍
那么什么是池化技术?通俗来讲就是我们程序先向系统申请过量的资源,然后自行管理,以备不时之需。
比如虽然我还没有讲过,但很多人应该早都学过的 线程池,其主要思想为先启动若干数量的线程,让它们处于睡眠状态,当接收到客户端的请求时,唤醒池中某个睡眠的线程,让它来处理客户端的请求,当处理完这个请求,线程又进入睡眠状态。
📖 项目介绍
当前项目是实现一个高并发的内存池,原型是google的一个开源项目tcmalloc,tcmalloc全称Thread-Caching Malloc,即线程缓存的malloc,实现了高效的多线程内存管理,用于替代系统的内存分配相关的函数(malloc、free)。
本篇所讲的项目是把tcmalloc最核心的框架简化后拿出来,模拟实现出一个化简版的高并发内存池,目的就是学习tcamlloc的精华。不过tcmalloc的代码量和复杂度程度是非常之高的,但即使难度很高,里面的知识对于我们的提升是很有帮助的。
另一方面,tcmalloc是全球大厂google开源的,可以认为是由当时顶尖的C++高手写出来的,其的知名度也是非常高的,不少公司都在用它,Go语言直接用它做了自己内存分配器。所以很多程序员是熟悉这个项目的,那么有好处,也有坏处。好处就是把这个项目理解扎实了,会很受面试官的认可。坏处就是面试官可能也比较熟悉项目,对项目会问得比较深,比较细。如果你对项目掌握得不扎实,那么就容易碰钉子。
📖 内存池的作用
我们使用内存池的目的主要是解决两个问题:
- 效率问题
- 内存碎片问题
效率问题
为什么池化技术效率会更高呢?我们不妨举个生活中的例子来看
此处我们不妨把向操作系统申请内存空间想作向父母要取生活费
如果我们没有池化技术,那么按照概念,我们就是每顿饭花了多少都要向父母要一次钱,如果早上花了5块就打电话给你爸说 "早饭花了5块钱,给我转一下。" 假如中午花了20大洋,再找你爸要,下午又是这样......这样每次花钱都要找父母要一下,这样的操作一两次还行,次数多了你不烦你爸妈都能烦死,按照这个过程不难看出效率十分低下,每次要钱都要进行沟通,非常不方便。
那用上我们的池化技术呢?
那比如一个月大概就是1500左右,那父母在月初的时候给你转1500,这1500就是你的money池,用钱的时候就去money池中取,下个月再给你转1500,这样每次要用钱的时候就不需要沟通了,去money池中拿就行,这样就高效了很多。
我们内存池就是这样的道理,每次用空间时都要向os申请一下效率太低了,建一个内存池,提前预留一大块空间,这样就解决了效率上的问题。
内存碎片
平时我们动态申请内存都是在堆上进行申请,假如说现在申请的资源如下:
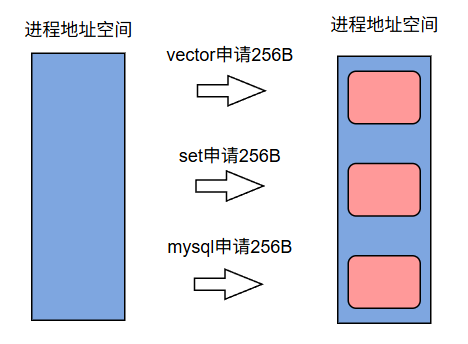
申请时空间由低到高申请(堆),但是释放的时候谁先释放或谁后释放是无法确定的。
动态申请的空间是非常自由的,谁不用了谁就直接释放,比如说:
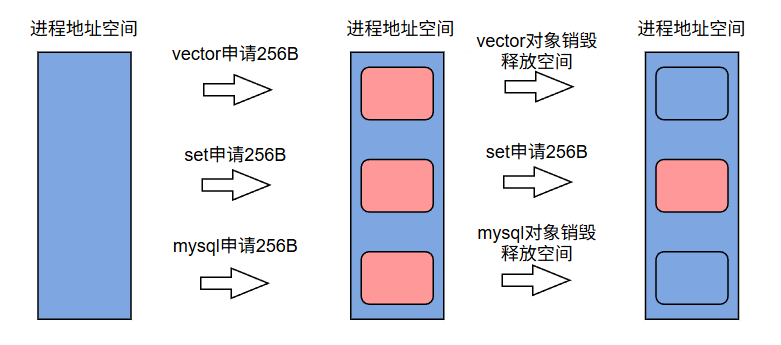
虽然此时 vector 和 mysql 的空间释放了,总共回收了512B的空间,但是从当前的图中来看的话,如果此时我们再去申请空间就无法申请超过256B(vector或mysql的那一块)的连续空间,因为动态申请的空间得要连续,但是这里上面的256B和下面的256B是不连续的,这就是所谓的碎片化,申请的空间只要大于256B就会失败,无法申请出来。导致看起来空间虽然够,但是不连续,申请不出来完整的空间也是白瞎。
所以如果我们直接从堆上申请就会存在这样的内存碎片的问题,而内存池就可以想办法去解决这样的问题,至于怎么实现,等后面讲的时候就知道了。
补充一点小知识,内存碎片其实分两种,一种叫外碎片,一种叫内碎片。
刚刚这里将的就是外碎片。
内碎片是指已经有一块空间开好了,但是这块空间中可能会因一些对齐的问题导致用不上,注意是已经开好的空间,内碎片的问题这里不太方便解释,之后项目中会遇到,遇到了之后我们再细说,到时候再正好与外碎片做一下对比。
📖 简单内存池的简单工作原理
1. 初始化:批量申请,化整为零
在内存池启动时,它不会等你需要内存时才去申请,而是一次性向操作系统申请一大块连续的内存(我们称之为一个"内存块"或"Chunk")。
然后,它会像切蛋糕一样,把这一大块内存预先切割成许多个大小相等的小单元(我们称之为"块"或"Block")。每个块的大小,正好是你需要的那个对象的大小。
2. 管理:用"空闲链表"串联
切分好的所有小块,在初始状态下都是空闲的。内存池会用一个非常巧妙的数据结构------空闲链表(Free List)------把它们全部串联起来。
这个链表的精髓在于,它不需要额外的内存来存储指针。它直接利用每个空闲块自己的前几个字节来存储一个指向下一个空闲块的指针。
- 结构示意 :
[块1的next指针] -> [块2的next指针] -> [块3的next指针] -> ... -> nullptr
这样,整个内存池就通过一个头指针(free_list)管理了所有可用的内存块。
3. 分配与回收:O(1)的指针游戏
这是内存池性能飞跃的关键。
-
分配内存 (Allocate)
当程序需要一块内存时,内存池只需要做两件事:
- 从
free_list指向的第一个空闲块中取出内存,返回给调用者。 - 将
free_list指针更新为链表的下一个节点。
这个过程只涉及指针操作,速度极快,时间复杂度是 O(1)。
- 从
-
释放内存 (Deallocate)
当程序用完一块内存并归还时,内存池也只做两件事:
- 将这块内存的前几个字节(现在已不再需要)重新用作指针,让它指向当前的
free_list。 - 将
free_list指针更新为这块刚刚归还的内存。
这个过程同样是 O(1),并且这块内存立刻就可以被下一次分配复用。
- 将这块内存的前几个字节(现在已不再需要)重新用作指针,让它指向当前的
📖 tcmalloc和malloc的关系
tcmalloc是用于优化C++写的多线程应用,比glibc2.3的malloc快(在多线程的场景下),所以tcmalloc是比malloc更好的一个东西,但不仅有tcmalloc,还有jemalloc等各种内存池,这些都是很优秀的内存池。学完tcmalloc后你们也可以去看看。此外有可能面试时会问malloc的底层。推荐项目学完之后再看,尤其是当问到为什么tcmalloc更快的时候,可以大致了解一下malloc。
📖 定长内存池
前面也说了实现内存池的方式各有不同。而malloc就是一个实现了通用的,针对各种场景的,各种大小的内存池,就是因为是通用的,设计的相对复杂,这也就意味着在大多数场景下都不会具有很好的性能。
那么现在如果有人需要固定大小的内存池,那该如何设计呢?能不能设计简单一点,还能让效率达到极致的内存池呢?
有的兄弟,有的,就是我们现在的开胃菜------定长内存池
注意事项
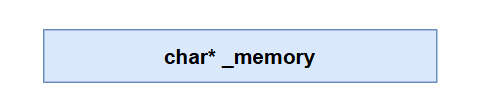
1、我们首先需要一个池子,将申请的一大块内存存起来,这里用一个char*的指针来实现
2、其次内存池的管理肯定不能只有申请,也需要有释放,用户用完的空间还到内存池中又该如何处理呢?也不能直接丢了,也不能把还回来的空间直接还给操作系统,因为正如我们之前演示的那样------向OS申请和释放是有要求的,申请的时候假如申请了1MB,那还回去的时候就要把这些空间全还回去。但现在我们申请了一大块内存,把它切成一小块一小块的拿去用,用完了还回来怎么处理呢?诶!我们可以用链表来解决。

每个内存小块中提取出一个指针的大小,然后指向其他的内存小块,这样就能将所有的内存小块串成一个串。这样这些内存小块还可以重复利用。具体怎么实现等会写代码的时候就知道了。
编写代码
这里我们准备好main文件与头文件
两个变量
再创建一个对象和俩变量,用法图中也写了。此处你也可以写为非类型模版,但考虑到我们此处的定长内存池也算作后面高并发内存池的一个小部件,故我们此处选择一个普通的通用类模版。

当然这里的_memory是不能用void*来定义的,因为我们是需要进行对内存的切分的,当然我们此处的切分不是真的切分,而是对_memory指针进行移动,如果_memory类型是void*的,那就没有办法往后挪动(也不是没有办法,只不过麻烦了点),因为用void*是没法进行+=或者解引用的操作的,所以直接给成char*会更加方便:
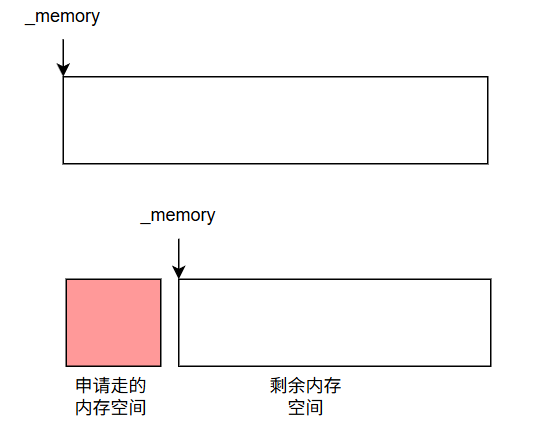
我们申请的空间就是一个T(模版类型)的大小,然后我们memory指针也要往后移动一个T的大小,当我们剩余空间不够的时候就再向os申请一块等大的定长空间。
我们再看我们另一个成员变量------_freelist
当然,不难发现,我们此处的链表并不像之前我们讲的那样,以结构体的形式串起来,我们此处直接用我们空间中的剩余空间不就行了吗,当然聪明的小伙伴也一定会想到------那回收的空间块万一比指针还小那该怎么办,没事我们一步一步来,先看看这个_freelist指针到底是怎么用的
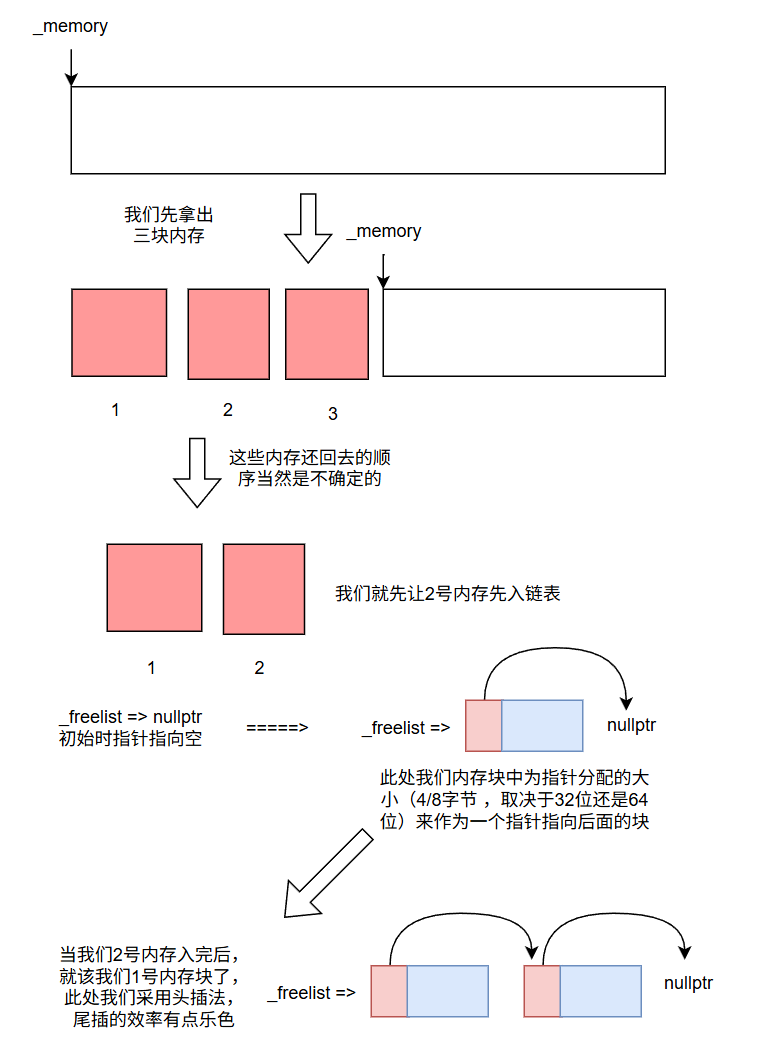
然后这里_freelist直接给成void*就行,因为这里不会对_freelist进行解引用或者增减操作,只是单纯的指向而已。
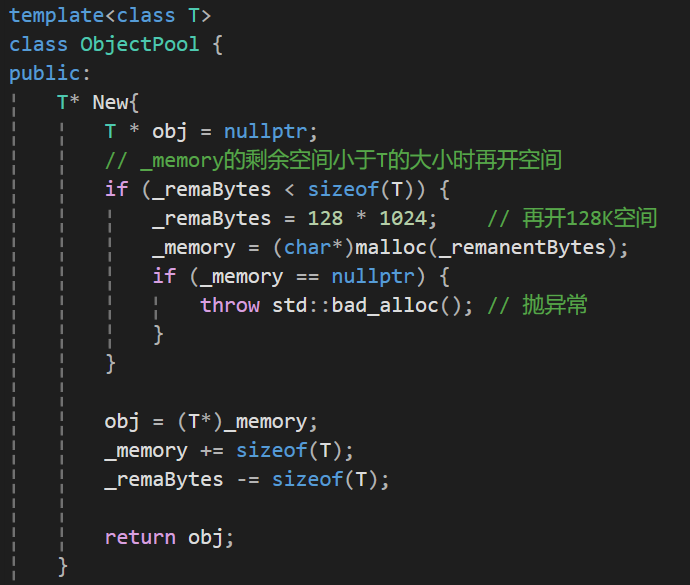
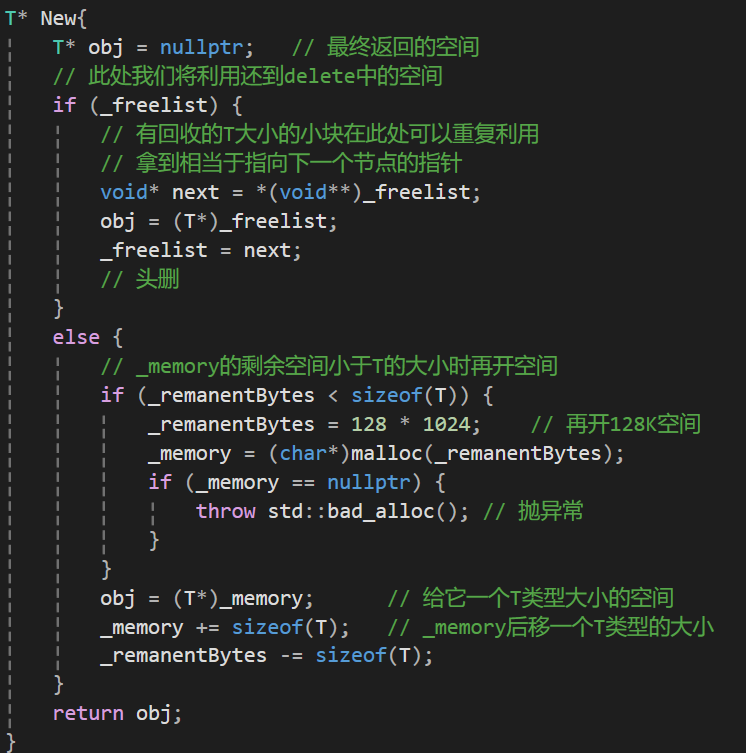
接口New------申请T类型大小的内存空间
此处我们又新加了一个成员变量------remaBytes,这个变量的作用是标明内存空间剩余的字节数,因为我们如果剩余的内存空间要比T小的话,我们的空间是没办法再开的,这时候我们就必须要扩容了。
接口Delete------回收还回来的小空间
此处就要用到我们刚才说的_freelist了,刚刚我们也画了图,但对于我们的指针来说如何取出块中的前几个字节并进行赋值呢?
对于32位的电脑而言,直接将块强转成int*就行,这样再解引用拿到的就是4个字节的大小,也就是这样:*(int*)obj = nullptr。
但对于64位的电脑而言我们可以直接强转为long long*,我们可以事先用sizeof(void*)去判断一下我们电脑是32位还是64位,但这样确实有点麻烦了,大佬们研究出来一种好方法:
使用二级指针 void**
- 代码 :
*(void**)obj = nullptr; - 原理详解 :
obj是这块内存的地址(假设类型是void*)。(void**)obj:把obj强转成一个**"指向 void指针 的 指针"**。*(void**)obj:对这个二级指针进行解引用。- 关键点 :解引用一个
void**类型,意味着你要操作一个void*类型的数据。而void*的大小天然就是当前平台的指针大小(32位是4字节,64位是8字节)。
那么我们目前Delete函数的代码就应该是这样:
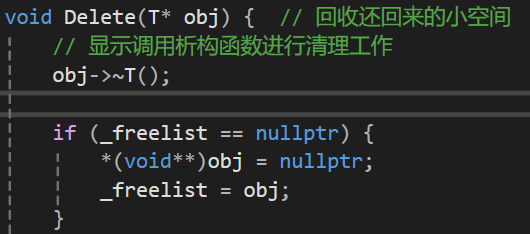
不过这只是_freelist为空的情况,那_freelist不为空呢?我相信如果你的链表部分学的没问题,那么这块也一定难不倒你。
我们现在将之前画的那个插入图再画的更加仔细一点点
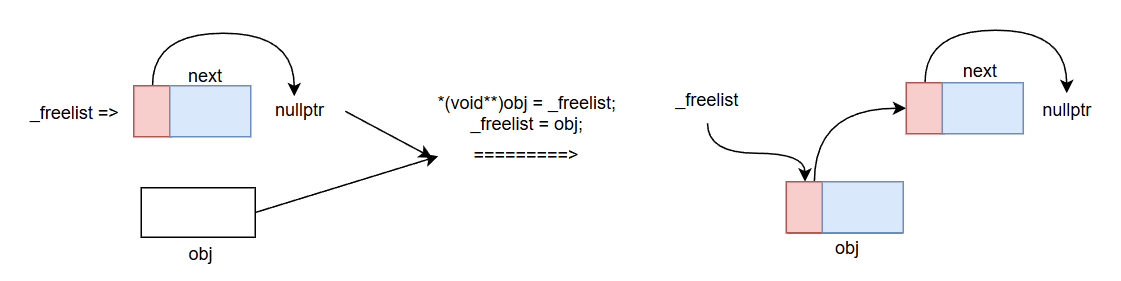
所以我们的代码应该如下:
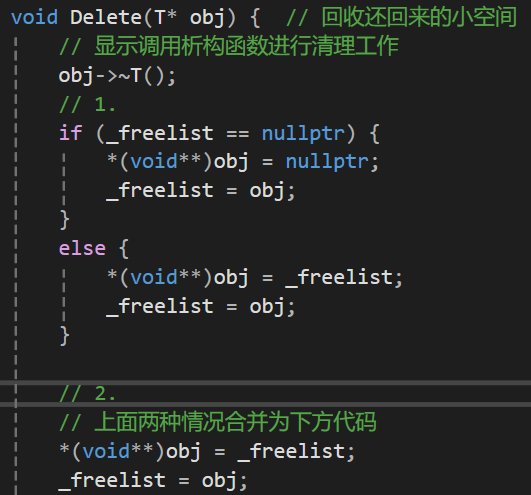
不难发现我们的代码还能继续优化成图中的2.代码块
New中利用Delete回收的内存空间
我们Delete可以将还回来的内存块进行管理,这些内存块都还可以重复利用,此时我们就可以在New中再利用这些内存,看图。
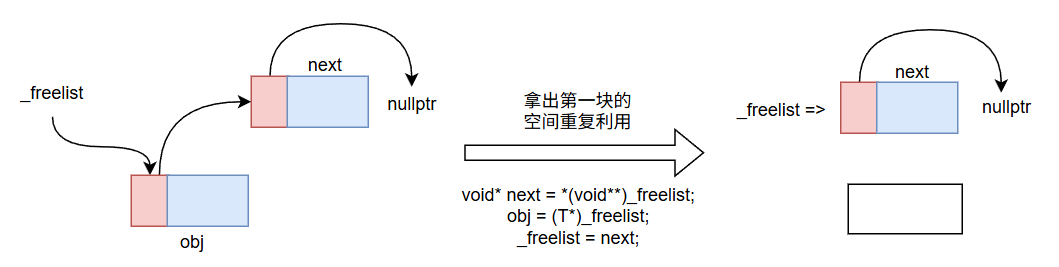
所以我们需要再New的开头加上一个特判:
sizeof(T) 小于指针大小的问题
到这其实我们还有一个很大的问题尚未解决,就是我们开始说的sizeof(T) 小于指针大小的问题,这个时候我们就得去按照我们电脑是32还是64位去进行补全了。
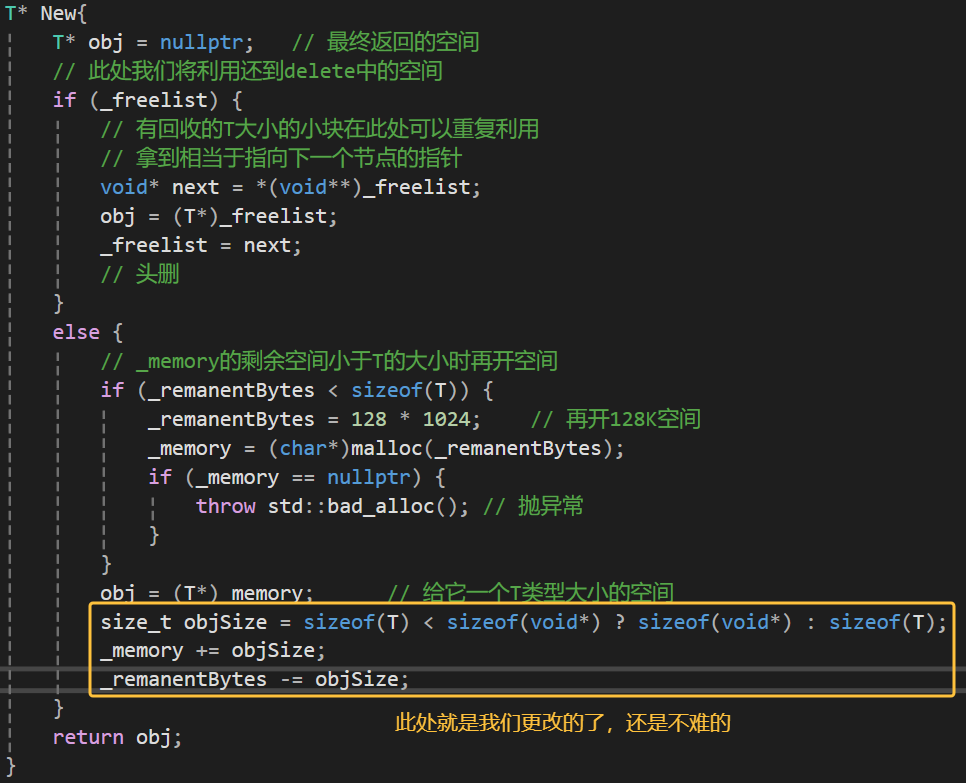
这里只需要改一下_memory指向的空间就行,_freelist的空间就是来自_memory指向的空间的,不用改。
初始化与malloc优化
我们还剩两个比较小的问题:
1、New中虽然申请了一块内存(Raw Memory),但并没有让对象真正"活"过来。我们需要通过**定位 new,**让对象富有生命。
2、这里定长内存池还是调用了malloc去申请大块的空间,能不能直接调用系统申请空间的接口呢?
我们先来看第一个问题:
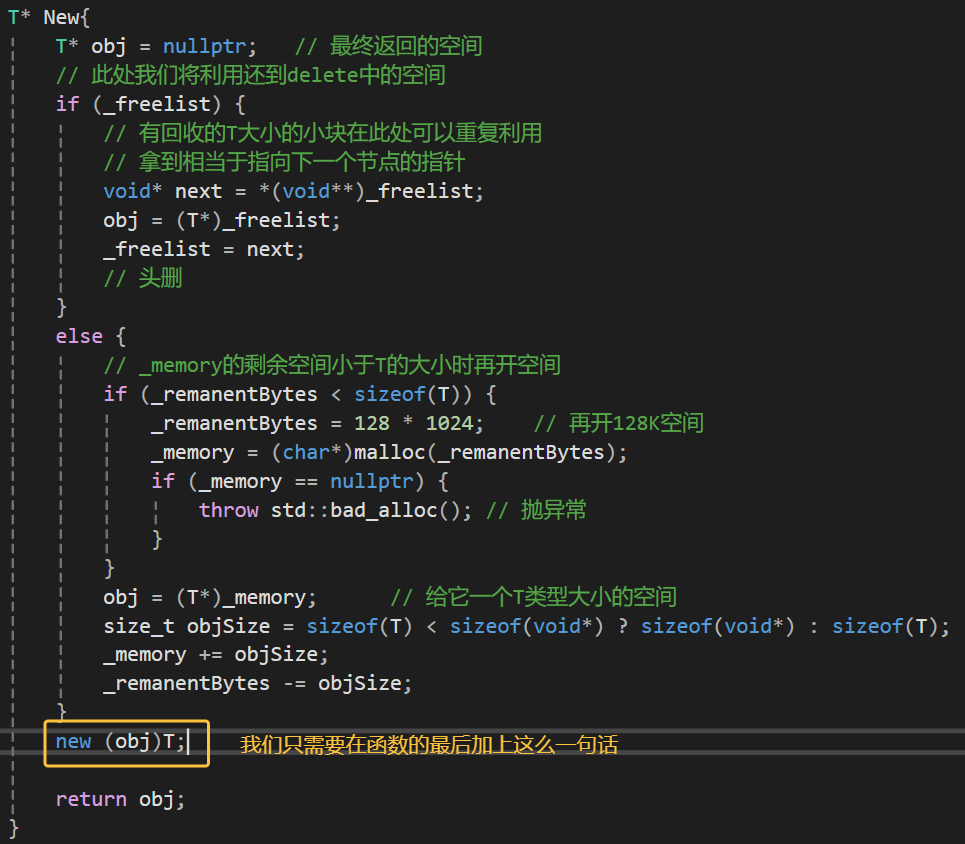
橙框部分:定位 new
代码:new(obj) T;
这行代码叫做定位 new。
- 普通 new :
new T;- 动作:自动申请内存 + 调用构造函数。
- 定位 new :
new(地址) T;- 动作:不申请内存,直接在指定的"地址"上调用构造函数。
在代码中的作用:
New()函数前面通过_memory指针或者_freelist拿到了一块原始内存 ,赋值给了obj。- 此时
obj指向的内存是"脏"的,或者说只是一个空壳。 new(obj) T;这一行,手动在obj这块内存上执行了T的构造函数。- 结果 :
obj现在是一个完全初始化、合法的对象了,可以安全返回给用户使用。
然后我们再看看第二个问题:
我们Windows和Linux下的接口不同,Windows下用的是VirtualAlloc函数,Linux下是brk和mmap,brk是把堆往上推,mmap是从共享区中取虚存。关于系统调用接口我这里就不做过多的详细介绍了,想要了解的同学可以自行查找一下资料。
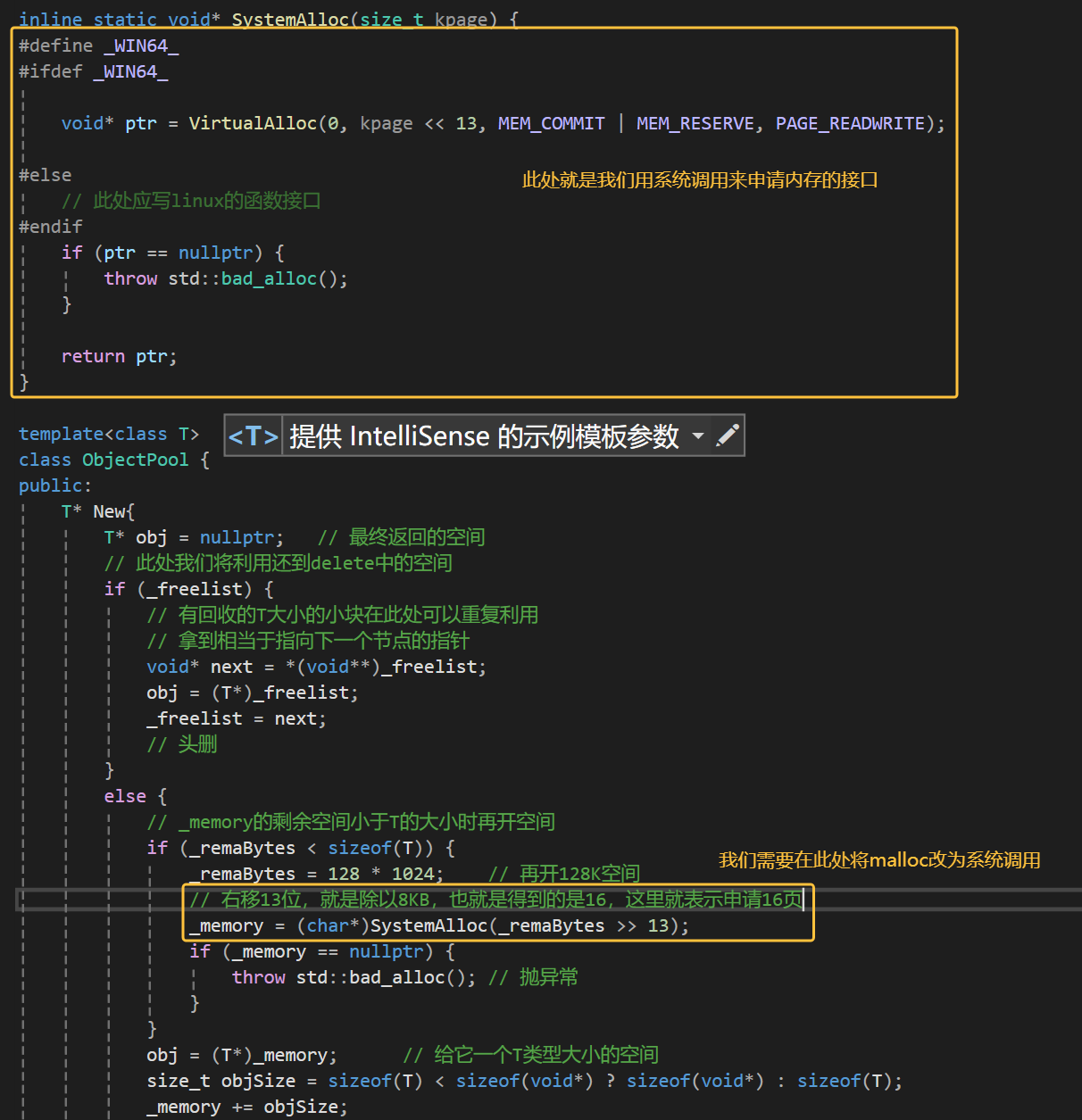
到此处就正式完成了我们定长内存池的代码,我们现在可以来测试测试了
测试代码如下:
cpp
#include"ObjectPool.h"
struct TreeNode
{
int _val;
TreeNode* _left;
TreeNode* _right;
TreeNode()
:_val(0)
, _left(nullptr)
, _right(nullptr)
{}
};
void TestObjectPool()
{
// 申请释放的轮次
const size_t Rounds = 5;
// 每轮申请释放多少次
const size_t N = 100000;
// 这里总共申请和释放的次数就是Rounds * N次,测试这么些次谁更快
std::vector<TreeNode*> v1;
v1.reserve(N);
// 测试malloc的性能
size_t begin1 = clock();
for (size_t j = 0; j < Rounds; ++j)
{
for (int i = 0; i < N; ++i)
{
v1.push_back(new TreeNode); // 这里虽然用的是new,但是new底层用的也是malloc
}
for (int i = 0; i < N; ++i)
{
delete v1[i]; // 同样的,delete底层也是free
}
v1.clear();
// capacity保持不变,这样才能循环上去重新push_back
}
size_t end1 = clock();
std::vector<TreeNode*> v2;
v2.reserve(N);
// 定长内存池,其中申请和释放的T类型就是树节点
ObjectPool<TreeNode> TNPool;
size_t begin2 = clock();
for (size_t j = 0; j < Rounds; ++j)
{
for (int i = 0; i < N; ++i)
{
v2.push_back(TNPool.New()); // 定长内存池中的申请空间
}
for (int i = 0; i < N; ++i)
{
TNPool.Delete(v2[i]); // 定长内存池中的回收空间
}
v2.clear();
// capacity保持不变,这样才能循环上去重新push_back
}
size_t end2 = clock();
cout << "new cost time:" << end1 - begin1 << endl; // 这里可以认为时间单位就是ms
cout << "object pool cost time:" << end2 - begin2 << endl;
}
int main() {
TestObjectPool();
return 0;
}可以看到我们两者之间的性能差距都快接近5倍了。
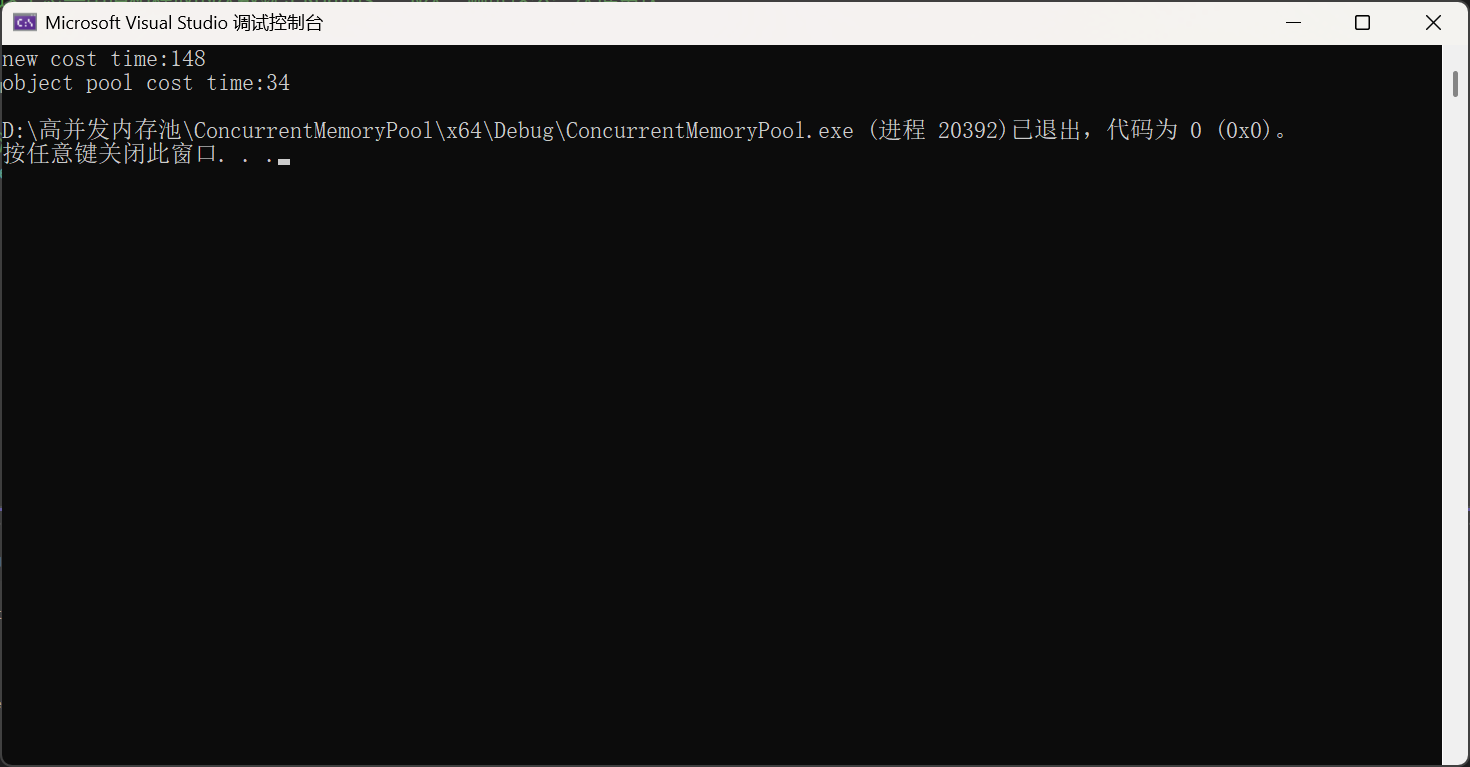
定长内存池的代码给出:
cpp
#define OBJECT_POOL_
#ifdef OBJECT_POOL_
#include<iostream>
#include<vector>
#include<Windows.h>
using std::cout;
using std::endl;
inline static void* SystemAlloc(size_t kpage) {
#define _WIN64_
#ifdef _WIN64_
void* ptr = VirtualAlloc(0, kpage << 13, MEM_COMMIT | MEM_RESERVE, PAGE_READWRITE);
#else
// 此处应写linux的函数接口
#endif
if (ptr == nullptr) {
throw std::bad_alloc();
}
return ptr;
}
template<class T>
class ObjectPool {
public:
T* New(){
T* obj = nullptr; // 最终返回的空间
// 此处我们将利用还到delete中的空间
if (_freelist) {
// 有回收的T大小的小块在此处可以重复利用
// 拿到相当于指向下一个节点的指针
void* next = *(void**)_freelist;
obj = (T*)_freelist;
_freelist = next;
// 头删
}
else {
// _memory的剩余空间小于T的大小时再开空间
if (_remaBytes < sizeof(T)) {
_remaBytes = 128 * 1024; // 再开128K空间
// 右移13位,就是除以8KB,也就是得到的是16,这里就表示申请16页
_memory = (char*)SystemAlloc(_remaBytes >> 13);
if (_memory == nullptr) {
throw std::bad_alloc(); // 抛异常
}
}
obj = (T*)_memory; // 给它一个T类型大小的空间
size_t objSize = sizeof(T) < sizeof(void*) ? sizeof(void*) : sizeof(T);
_memory += objSize;
_remaBytes -= objSize;
}
new (obj)T;
return obj;
}
void Delete(T* obj) { // 回收还回来的小空间
// 显示调用析构函数进行清理工作
obj->~T();
*(void**)obj = _freelist;
_freelist = obj;
// 那么此时这块空间都还可以重复利用,我们就在new中重新利用一下
}
private:
char* _memory = nullptr; // 指向内存块的指针,因为要进行+-运算故用char定义
void* _freelist = nullptr; // 自由链表,用来管理归还的内存空间
size_t _remaBytes = 0; // 大块内存存在切分过程中的剩余字节数
};
#endif;结语
今天我们只是打探打探了有关内存池的基本思路,通过固定大小 避免了内存碎片,通过空闲链表实现了 O(1) 的分配与回收。
当你理解了这套"批量申请 + 链表管理"的核心机制后,再去理解多线程、可变大小等更复杂的设计,就会容易得多。它们都是在这个基础模型上,为了解决并发安全和灵活性等问题而做的扩展和优化。我们下篇博客就将正式开始我们高并发内存池的学习了。
我是YYYing,后面还有更精彩的内容,希望各位能多多关注支持一下主包。
无限进步,我们下次再见!
---⭐️ 封面自取 ⭐️---
