
kafka是非常依赖zk的,无论是kafka的broker,还是producer,consumer,这些都会有源数据的信息保存在zk上面。
在kafka进程启动了之后,再去连接到zk,这个会去启动一个连接到zk的客户端,可以看到根目录下有这么多的节点生成了。这些节点存储的就是zk集群的元数据信息。

比如在broker目录下的ids节点里面存放的是所有活跃的broker节点。因为是单机版本的,只有一个broker角色,所以这里面只有0号的。

比如有什么样的主题,都是在topics这里面存放着。所以kafka是非常依赖zk的。
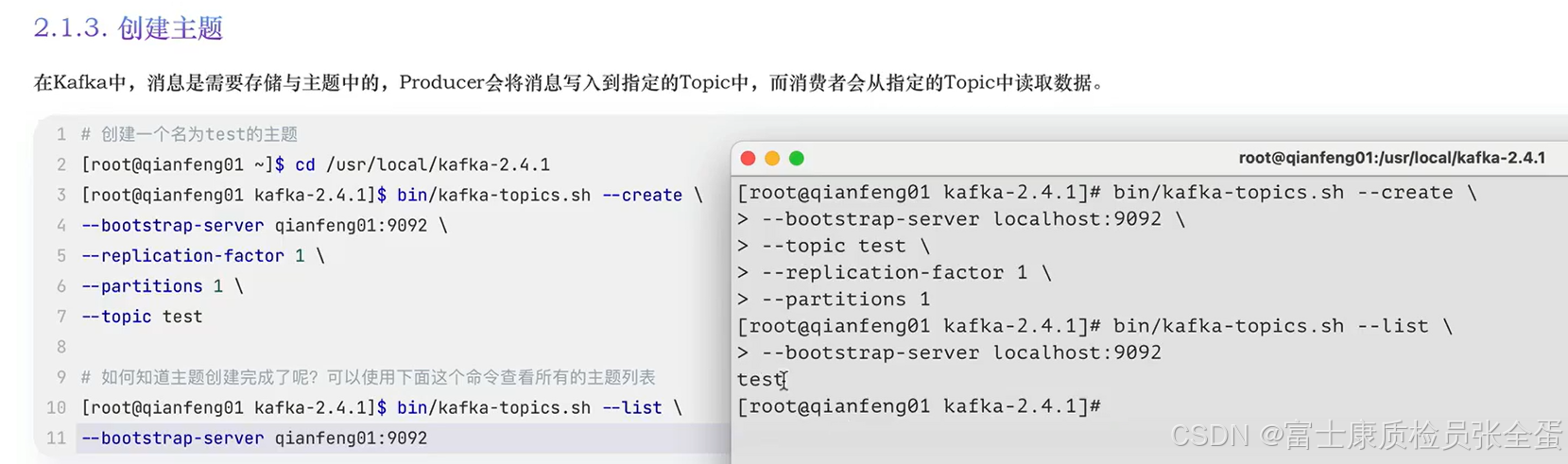
下面是简单的生产和消费消息,但是在生产和消费消息之前,首先要将主题给创建出来,也就是topic,因为生产者生产出来的消息是要在主题当中存储的,而消费者消费的消息也是从主题中进行消费的,所以要将主题给创建出来。
所有关于主题的操作用到的都是kafak-topics.sh这个脚本,--replication-factor这个叫做副本因子,也就是我的一个主题当中的数据文件要做多少个副本。kafka是有这样一个机制做容错的。这里设置一个就可以了,因为只有一个工作节点,单机。
partions表示这个topic多少个分区,在列出topic信息的时候指定broker的信息。
现在主题创建成功,接下来就是要去开启生产者和消费者来生产和消费数据了。
kafka的部署可以分为单机版本和集群版本,单机和集群的区别在于每一个kafka的实例称作为broker。所谓的单机版本意味着只有一个broker。只有一个节点,在这个节点上运行着broker,也就是kafka的实例。这是单机版本。
所谓的集群就是有多个kafka的实例,也就是有多个broker去构成了一个分布式的集群。
需要在3个节点上都去部署kafka的实例。在安装之前需要安装JDK,需要java环境。
每台机器的id都不唯一,kafka其实是一个消息队列。生产者生产的消息存在了topic主题里面。而kafka会将这些消息保存到本地存储。保存在本地的位置使用由logs.dir里面配置。
还有与zk相关的,kafka是非常依赖zk的软件。在运行当中,无论是kafka的服务本身,还是consumer,producer。它们都需要在zk上去维护一些数据。我们称之为元数据。比如broker的信息,topic的信息,消费相关的信息等等,这些都是保存在zk上面的。所以是非常依赖zk的。
kafka内置了zk,但是不使用,可以使用自己已经搭建好的zk。
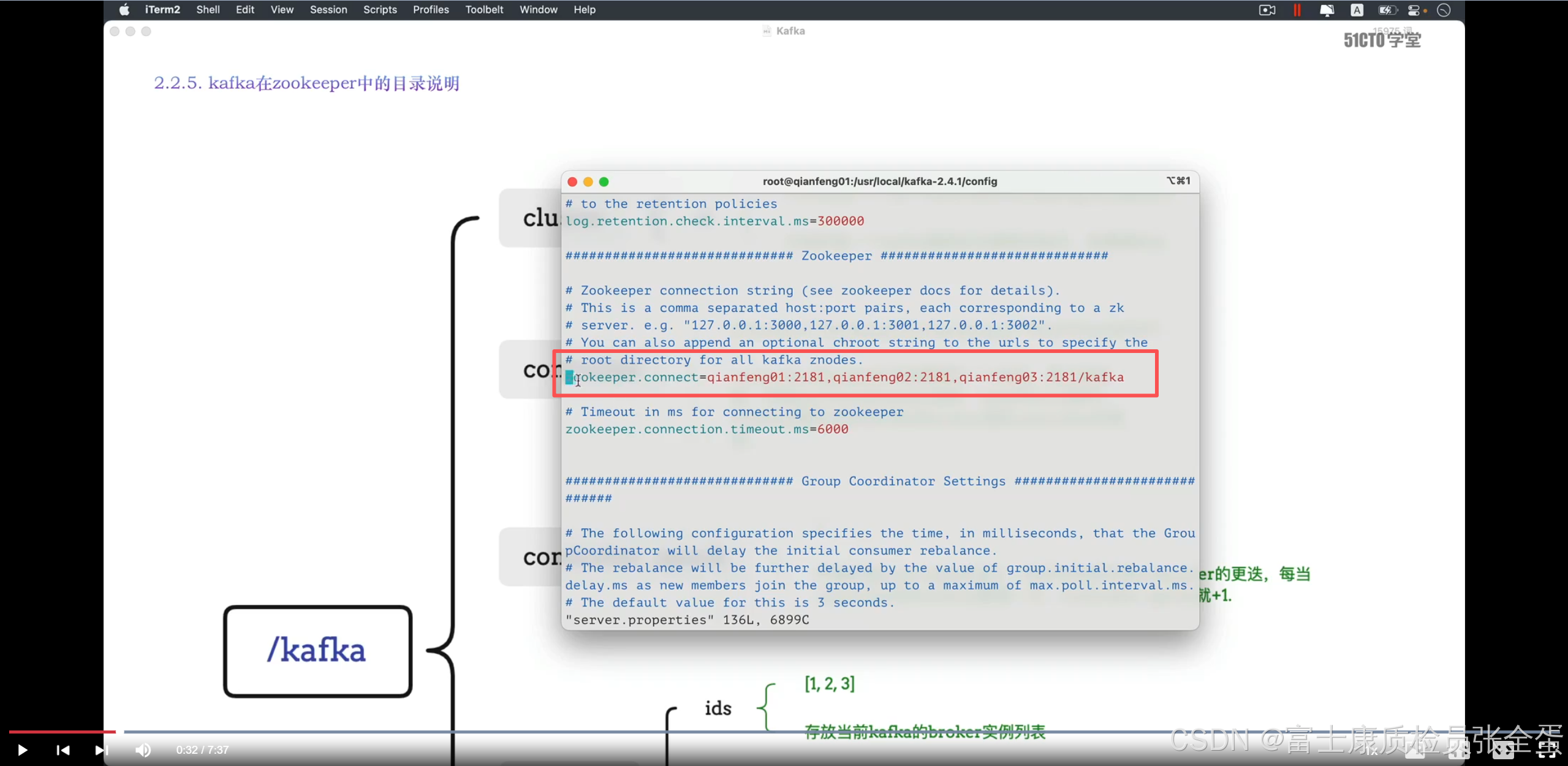
kafka在运行的当中会在zk中维护元数据的信息。默认会在根节点的下面创建很多很多的文件夹。比如brokers,ids,topics,等等。它会有很多的文件夹生成。这些目录直接生成在根目录的下面。这样就会导致zk上面的数据看起来比较乱。
这些节点都放在kafka的节点下作为子节点,这样kafka所有的元数据信息都保存在kafka的节点下面了,这样看zk目录看起来就不会那么乱了。

所以这就是斜线写的kafka的作用。这样表示kafka的所有的元数据信息是保存在了zk的根下的kafka节点下。
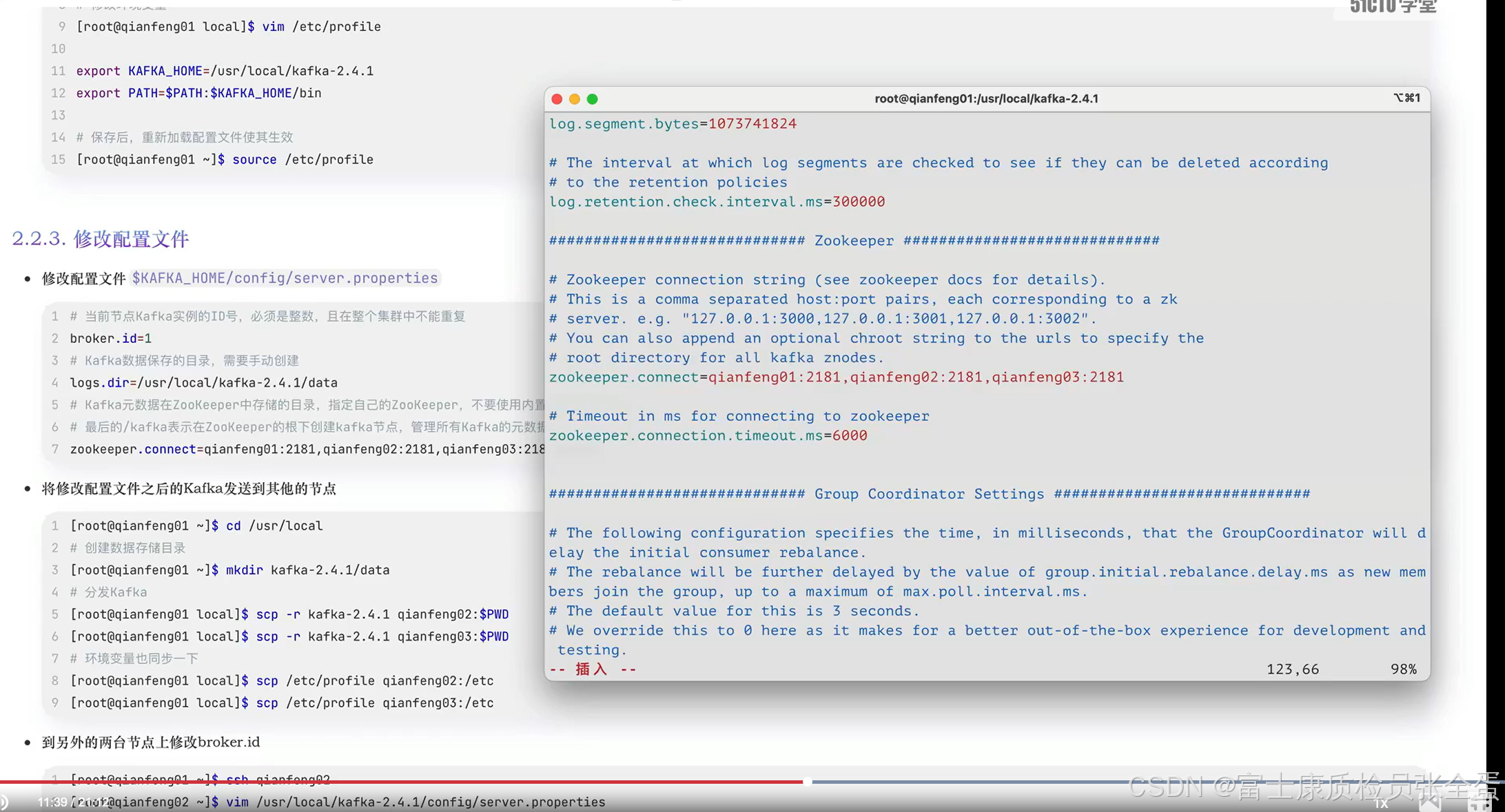
上面就是需要配置文件的地方。修改完之后分发给其他节点。其他节点修改broker.id,把它的值给改一下。这个值是整个集群中唯一的,不能重复的。改为2,3即可,剩余两台机器。
先去启动zk集群,再去启动kafka,kafka启动加上daemon,改为后台启动。同理其他节点依次启动。


这个是一键启停kafka集群脚本。

在kafa启动之后会在zk上面去注册很多的节点去来记录它的元数据信息,而这个节点的位置在配置文件中都配置过。元数据信息需要保存在zk kafka节点的下面。

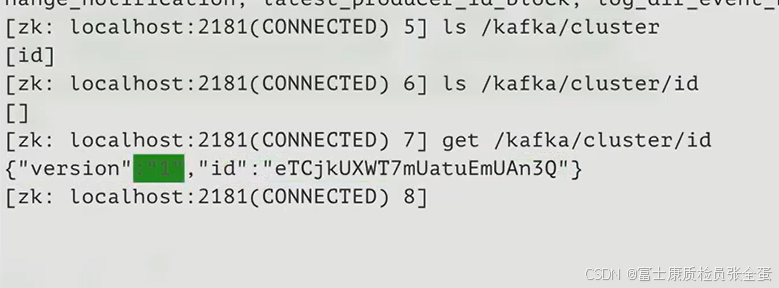
这里包括kafka版本的信息和集群id的信息。
cluster就是和集群相关的配置,
controler在kafka当中是一个非常重要的角色,topic可以分为若干个partition,而每一个partition是有多个副本的,而这些副本之间存在leader和follower这样的角色,而这些角色的选举是由controller来完成的。所以controller可以控制partition的leader选举,也包括topic的crud操作,比如插入一些消息,消费一些消息。
brokerid表示现在哪个broker服务器现在是controller这样的角色。

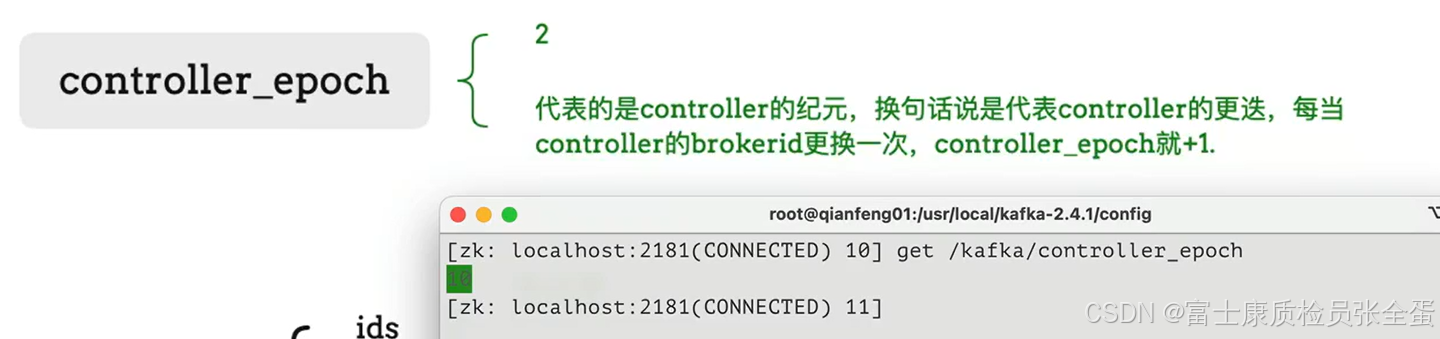
epoch代表朝代的意思,每当controller它的brokerid发生了变更,那么这个值都会+1。其实就是记录了controller迭代了多少次。
brokers的ids记录了当前活跃kafka的实例列表,这是记录的broker信息。


上面就是kafka在启动,运行当中会在zk里面维护的目录结构。